El valor de los datos es sensible al tiempo. El procesamiento en tiempo real hace que las decisiones basadas en datos sean precisas y procesables en segundos o minutos en lugar de horas o días. La captura de datos modificados (CDC) se refiere al proceso de identificar y capturar los cambios realizados en los datos en una base de datos y luego entregar esos cambios en tiempo real a un sistema posterior. Capturar todos los cambios de las transacciones en una base de datos de origen y moverlos al destino en tiempo real mantiene los sistemas sincronizados y ayuda con los casos de uso de análisis en tiempo real y las migraciones de bases de datos sin tiempo de inactividad. Los siguientes son algunos beneficios de los CDC:
- Elimina la necesidad de actualizaciones de carga masiva y ventanas de lotes inconvenientes al permitir la carga incremental o la transmisión en tiempo real de cambios de datos en su repositorio de destino.
- Garantiza que los datos en múltiples sistemas permanezcan sincronizados. Esto es especialmente importante si está tomando decisiones sensibles al tiempo en un entorno de datos de alta velocidad.
Conexión Kafka es un componente de código abierto de Apache Kafka que funciona como un centro de datos centralizado para una integración de datos simple entre bases de datos, almacenes de clave-valor, índices de búsqueda y sistemas de archivos. El Registro de esquemas de AWS Glue le permite descubrir, controlar y desarrollar esquemas de flujo de datos de forma centralizada. Kafka Connect y Schema Registry se integran para capturar información de esquema de los conectores. Kafka Connect proporciona un mecanismo para convertir datos de los tipos de datos internos utilizados por Kafka Connect en tipos de datos representados como Avro, Protobuf o JSON Schema. AvroConverter, ProtobufConverter y JsonSchemaConverter registran automáticamente los esquemas generados por los conectores de Kafka (fuente) que generan datos para Kafka. Los conectores (sumidero) que consumen datos de Kafka reciben información del esquema además de los datos de cada mensaje. Esto permite que los conectores receptores conozcan la estructura de los datos para proporcionar capacidades como mantener un esquema de tabla de base de datos en un catálogo de datos.
La publicación demuestra cómo construir un CDC de extremo a extremo usando Conexión de Amazon MSK, un servicio administrado por AWS para implementar y ejecutar aplicaciones de Kafka Connect y AWS Glue Schema Registry, que le permite descubrir, controlar y desarrollar esquemas de flujo de datos de forma centralizada.
Resumen de la solución
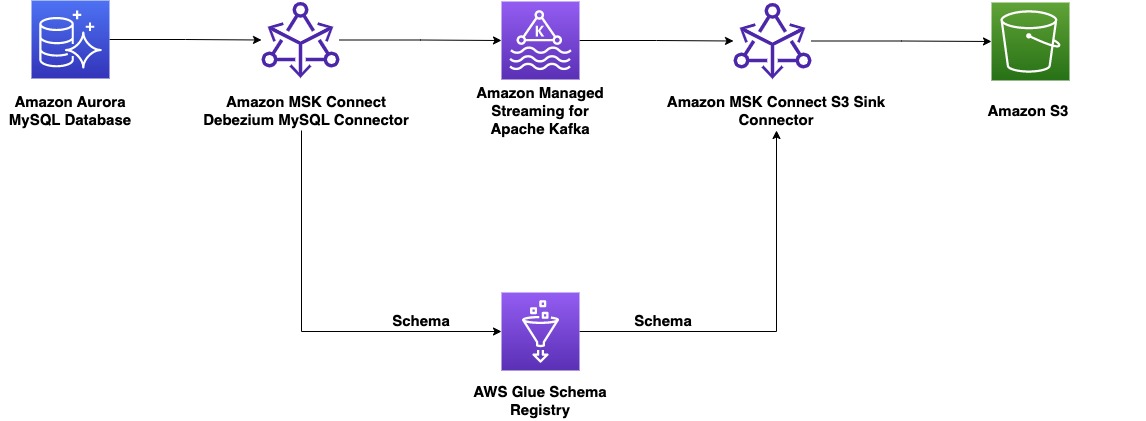
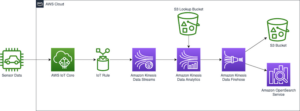
Del lado del productor, para este ejemplo elegimos un servidor compatible con MySQL Aurora amazónica base de datos como la fuente de datos, y tenemos un debecio Conector MySQL para realizar CDC. El conector Debezium monitorea continuamente las bases de datos y envía cambios a nivel de fila a un tema de Kafka. El conector obtiene el esquema de la base de datos para serializar los registros en forma binaria. Si el esquema aún no existe en el registro, se registrará el esquema. Si el esquema existe pero el serializador está usando una nueva versión, el registro del esquema verifica la el modo de compatibilidad del esquema antes de actualizar el esquema. En esta solución, usamos modo de compatibilidad con versiones anteriores. El registro del esquema devuelve un error si una nueva versión del esquema no es compatible con versiones anteriores, y podemos configurar Kafka Connect para enviar mensajes incompatibles a la cola de mensajes fallidos.
En el lado del consumidor, usamos un Servicio de almacenamiento simple de Amazon (Amazon S3) conector receptor para deserializar el registro y almacenar cambios en Amazon S3. Creamos e implementamos el conector Debezium y el sumidero de Amazon S3 mediante MSK Connect.
Esquema de ejemplo
Para esta publicación, usamos el siguiente esquema como la primera versión de la tabla:
Requisitos previos
Antes de configurar los conectores de productor y consumidor de MSK, primero debemos configurar una fuente de datos, un clúster de MSK y un nuevo registro de esquema. Proporcionamos un Formación en la nube de AWS plantilla para generar los recursos de apoyo necesarios para la solución:
- Una base de datos Aurora compatible con MySQL como fuente de datos. Para realizar CDC, activamos el registro binario en el Grupo de parámetros de clúster de base de datos.
- Un clúster de MSK. Para simplificar la conexión de red, usamos la misma VPC para la base de datos de Aurora y el clúster de MSK.
- Dos registros de esquema para manejar esquemas para clave de mensaje y valor de mensaje.
- Un depósito S3 como sumidero de datos.
- Se necesitan complementos de MSK Connect y configuración de trabajadores para esta demostración.
- Un Nube informática elástica de Amazon (Amazon EC2) instancia para ejecutar comandos de base de datos.
Para configurar recursos en su cuenta de AWS, complete los siguientes pasos en una región de AWS que admita Amazon MSK, MSK Connect y AWS Glue Schema Registry:
- Elige Pila de lanzamiento:
- Elige Siguiente.
- Nombre de pila, introduzca un nombre adecuado.
- Contraseña de la base de datos, ingrese la contraseña que desea para el usuario de la base de datos.
- Mantenga otros valores como predeterminados.
- Elige Siguiente.
- En la página siguiente, elija Siguiente.
- Revise los detalles en la página final y seleccione Reconozco que AWS CloudFormation podría crear recursos de IAM.
- Elige Crear pila.
Complemento personalizado para el conector de origen y destino
Un complemento personalizado es un conjunto de archivos JAR que contienen la implementación de uno o más conectores, transformaciones o convertidores. Amazon MSK instalará el complemento en los trabajadores del clúster de MSK Connect donde se ejecuta el conector. Como parte de esta demostración, para el conector de código fuente usamos código abierto Debezium MySQL conector JAR, y para el conector de destino usamos la comunidad con licencia de Confluent JAR del conector receptor de Amazon S3. Ambos complementos también se agregan con bibliotecas para Serializadores y deserializadores Avro del registro de esquemas de AWS Glue. Estos complementos personalizados ya se crearon como parte de la plantilla de CloudFormation implementada en el paso anterior.
Utilice el registro de esquemas de AWS Glue con el conector Debezium en MSK Connect como productor de MSK
Primero implementamos el conector de origen usando el complemento Debezium MySQL para transmitir datos desde un Edición compatible con MySQL de Amazon Aurora base de datos a Amazon MSK. Complete los siguientes pasos:
- En la consola de Amazon MSK, en el panel de navegación, en Conexión MSK, escoger Conectores.
- Elige Crear conector.
- Elige Usar complemento personalizado existente y luego elija el complemento personalizado con el nombre que comienza
msk-blog-debezium-source-plugin. - Elige Siguiente.
- Introduzca un nombre adecuado como
debezium-mysql-connectory una descripción opcional. - Clúster de Apache Kafka, escoger Clúster MSK y elija el clúster creado por la plantilla de CloudFormation.
- In Configuración del conector, elimine los valores predeterminados y use los siguientes pares clave-valor de configuración y con los valores apropiados:
- nombre – El nombre utilizado para el conector.
- base de datos.hostsname – La salida de CloudFormation para Punto final de la base de datos.
- base de datos.usuario y base de datos.contraseña – Los parámetros pasados en la plantilla de CloudFormation.
- base de datos.historia.kafka.bootstrap.servidores – La salida de CloudFormation para Bootstrap de Kafka.
- key.converter.region y value.converter.region – Su Región.
Algunas de estas configuraciones son genéricas y deben especificarse para cualquier conector. Por ejemplo:
- conector.clase es la clase Java del conector
- tareas.max es el número máximo de tareas que deben crearse para este conector
Algunas configuraciones (database.*, transforms.*) son específicos del conector Debezium MySQL. Referirse a Propiedades de configuración del conector de origen MySQL de Debezium para obtener más información.
Algunas configuraciones (key.converter.* y value.converter.*) son específicos del registro de esquemas. usamos el AWSKafkaAvroConverter del desplegable Biblioteca de registro de esquemas de AWS Glue como convertidor de formato. Para configurar AWSKafkaAvroConverter, usamos el valor de las propiedades constantes de cadena en el AWSSchemaRegistryConstants clase:
key.converteryvalue.convertercontrole el formato de los datos que se escribirán en Kafka para los conectores de origen o que se leerán de Kafka para los conectores de receptor. UsamosAWSKafkaAvroConverterpara formato Avro.key.converter.registry.nameyvalue.converter.registry.namedefinir qué registro de esquema usar.key.converter.compatibilityyvalue.converter.compatibilitydefinir el modelo de compatibilidad.
Consulte Uso de Kafka Connect con el registro de esquemas de AWS Glue para obtener más información.
- A continuación, configuramos Capacidad del conector. Podemos elegir Aprovisionado y dejar otras propiedades por defecto
- Configuración del trabajador, elija la configuración del trabajador personalizado con el nombre que comienza
msk-gsr-blogcreado como parte de la plantilla de CloudFormation. - Permisos de acceso, utilizar el Gestión de identidades y accesos de AWS (IAM) rol generado por la plantilla de CloudFormation
MSKConnectRole. - Elige Siguiente.
- Seguridad, elija los valores predeterminados.
- Elige Siguiente.
- Entrega de registro, seleccione Entregar a Amazon CloudWatch Logs y busque el grupo de registro creado por la plantilla de CloudFormation (
msk-connector-logs). - Elige Siguiente.
- Revise la configuración y elija Crear conector.
Después de unos minutos, el conector cambia al estado de ejecución.
Utilice el registro de esquemas de AWS Glue con el conector receptor de Confluent S3 ejecutándose en MSK Connect como consumidor de MSK
Implementamos el conector de sumidero mediante el complemento de sumidero Confluent S3 para transmitir datos de Amazon MSK a Amazon S3. Complete los siguientes pasos:
-
- En la consola de Amazon MSK, en el panel de navegación, en Conexión MSK, escoger Conectores.
- Elige Crear conector.
- Elige Usar complemento personalizado existente y elija el complemento personalizado con el nombre que comienza
msk-blog-S3sink-plugin. - Elige Siguiente.
- Introduzca un nombre adecuado como
s3-sink-connectory una descripción opcional. - Clúster de Apache Kafka, escoger Clúster MSK y seleccione el clúster creado por la plantilla de CloudFormation.
- In Configuración del conector, elimine los valores predeterminados proporcionados y use los siguientes pares clave-valor de configuración con los valores adecuados:
-
- nombre – El mismo nombre utilizado para el conector.
- s3.depósito.nombre – La salida de CloudFormation para Nombre del cubo.
- s3.region, key.converter.region y value.converter.region – Su Región.
-
- A continuación, configuramos Capacidad del conector. Podemos elegir Aprovisionado y dejar otras propiedades por defecto
- Configuración del trabajador, elija la configuración del trabajador personalizado con el nombre que comienza
msk-gsr-blogcreado como parte de la plantilla de CloudFormation. - Permisos de acceso, use el rol de IAM generado por la plantilla de CloudFormation
MSKConnectRole. - Elige Siguiente.
- Seguridad, elija los valores predeterminados.
- Elige Siguiente.
- Entrega de registro, seleccione Entregar a Amazon CloudWatch Logs y busque el grupo de registro creado por la plantilla de CloudFormation
msk-connector-logs. - Elige Siguiente.
- Revise la configuración y elija Crear conector.
Después de unos minutos, el conector se está ejecutando.
Probar el flujo de registro de CDC de extremo a extremo
Ahora que tanto el conector receptor Debezium como el S3 están en funcionamiento, complete los siguientes pasos para probar el CDC de extremo a extremo:
- En la consola de Amazon EC2, vaya a la Grupos de seguridad .
- Seleccione el grupo de seguridad
ClientInstanceSecurityGroupy elige Editar reglas de entrada. - Agregue una regla de entrada que permita la conexión SSH desde su red local.
- En Instancias página, seleccione la instancia
ClientInstancey elige Contacto. - En Conexión de instancia EC2 pestaña, elegir Contacto.
- Asegúrese de que su directorio de trabajo actual sea
/home/ec2-usery tiene los archivoscreate_table.sql,alter_table.sql,initial_insert.sqlyinsert_data_with_new_column.sql. - Cree una tabla en su base de datos MySQL ejecutando el siguiente comando (proporcione el nombre de host de la base de datos de los resultados de la plantilla de CloudFormation):
- Cuando se le solicite una contraseña, ingrese la contraseña de los parámetros de la plantilla de CloudFormation.
- Inserte algunos datos de muestra en la tabla con el siguiente comando:
- Cuando se le solicite una contraseña, ingrese la contraseña de los parámetros de la plantilla de CloudFormation.
- En la consola de AWS Glue, elija Registros de esquema en el panel de navegación, luego elija Esquemas.
- Navegue hasta
db1.sampledatabase.moviesversión 1 para verificar el nuevo esquema creado para la tabla de películas:
Se crea una carpeta de S3 independiente para cada partición del tema de Kafka y los datos del tema se escriben en esa carpeta.
- En la consola de Amazon S3, busque datos escritos en formato Parquet en la carpeta de su tema de Kafka.
Evolución del esquema
Después de definir el esquema inicial, es posible que las aplicaciones deban evolucionarlo con el tiempo. Cuando esto sucede, es fundamental que los consumidores intermedios puedan manejar los datos codificados con el esquema antiguo y el nuevo sin problemas. Los modos de compatibilidad le permiten controlar cómo los esquemas pueden o no evolucionar con el tiempo. Estos modos forman el contrato entre las aplicaciones que producen y consumen datos. Para obtener información detallada sobre los diferentes modos de compatibilidad disponibles en AWS Glue Schema Registry, consulte Registro de esquemas de AWS Glue. En nuestro ejemplo, utilizamos la combinación hacia atrás para garantizar que los consumidores puedan leer tanto la versión actual como la anterior del esquema. Complete los siguientes pasos:
- Agregue una nueva columna a la tabla ejecutando el siguiente comando:
- Inserte nuevos datos en la tabla ejecutando el siguiente comando:
- En la consola de AWS Glue, elija Registros de esquema en el panel de navegación, luego elija Esquemas.
- Navegar al esquema
db1.sampledatabase.moviesversión 2 para verificar la nueva versión del esquema creado para las películas de la tabla de películas, incluida la columna de país que agregó:
- En la consola de Amazon S3, busque datos escritos en formato Parquet en la carpeta del tema de Kafka.
Limpiar
Para ayudar a evitar cargos no deseados en su cuenta de AWS, elimine los recursos de AWS que utilizó en esta publicación:
- En la consola de Amazon S3, navegue hasta el depósito de S3 creado por la plantilla de CloudFormation.
- Seleccione todos los archivos y carpetas y elija Borrar.
- Ingrese eliminar permanentemente como se indica y elija Eliminar objetos.
- En la consola de AWS CloudFormation, elimine la pila que creó.
- Espere a que el estado de la pila cambie a BORRAR_COMPLETO.
Conclusión
Esta publicación demostró cómo usar Amazon MSK, MSK Connect y AWS Glue Schema Registry para crear un flujo de registro de CDC y desarrollar esquemas para flujos de datos a medida que cambian las necesidades comerciales. Puede aplicar este patrón de arquitectura a otras fuentes de datos con diferentes conectores Kafka. Para obtener más información, consulte el Ejemplos de MSK Connect.
Sobre la autora
 Kalyan Janaki es especialista sénior en Big Data y análisis de Amazon Web Services. Ayuda a los clientes a diseñar y crear soluciones basadas en la nube altamente escalables, seguras y de alto rendimiento en AWS.
Kalyan Janaki es especialista sénior en Big Data y análisis de Amazon Web Services. Ayuda a los clientes a diseñar y crear soluciones basadas en la nube altamente escalables, seguras y de alto rendimiento en AWS.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :es
- $ UP
- 1
- 10
- 11
- 7
- 8
- a
- Poder
- Nuestra Empresa
- de la máquina
- Mi Cuenta
- preciso
- reconocer
- adicional
- adición
- Todos
- Permitir
- permite
- ya haya utilizado
- Amazon
- Amazon EC2
- Amazon Web Services
- Analytics
- y
- APACHE
- Apache Kafka
- aplicaciones
- Aplicá
- adecuado
- arquitectura
- somos
- AS
- Aurora
- automáticamente
- Hoy Disponibles
- AWS
- Formación en la nube de AWS
- Pegamento AWS
- BE
- antes
- beneficios
- entre
- Big
- Big Data
- Bootstrap
- build
- by
- PUEDEN
- capacidades
- capturar
- Capturando
- cases
- catalogar
- CDC
- centralizado
- el cambio
- Cambios
- cargos
- comprobar
- Cheques
- Elige
- clase
- Médico
- Columna
- vibrante e inclusiva
- compatibilidad
- compatible
- completar
- componente
- Calcular
- Configuración
- ConFluent™
- Contacto
- conexión
- Consola
- constante
- consumir
- consumidor
- Clientes
- continuamente
- contrato
- control
- país
- Para crear
- creado
- crítico
- Current
- personalizado
- Clientes
- datos
- integración de datos
- basada en datos
- Base de datos
- bases de datos
- Días
- decisiones
- Predeterminado
- por defecto
- se define
- entregar
- De demostración
- demostrado
- demuestra
- desplegar
- desplegado
- descripción
- destino
- detallado
- detalles
- una experiencia diferente
- descrubrir
- No
- Soltar
- cada una
- elimina
- permitiendo
- de extremo a extremo
- garantizar
- asegura
- Participar
- Entorno
- error
- especialmente
- Éter (ETH)
- Cada
- evoluciona
- ejemplo
- existente
- existe
- pocos
- Terrenos
- Archive
- archivos
- final
- Nombre
- siguiendo
- formulario
- formato
- en
- generar
- generado
- Grupo procesos
- Grupo
- encargarse de
- Manejo
- que sucede
- Tienen
- ayuda
- ayuda
- altamente
- historia
- fortaleza
- HORAS
- Cómo
- Como Hacer
- HTML
- http
- HTTPS
- Bujes
- AMI
- identificar
- Identidad
- implementación
- importante
- in
- Incluye
- índices
- información
- inicial
- instalar
- ejemplo
- integrar
- integración
- interno
- IT
- Java
- jpg
- json
- kafka
- Clave
- Saber
- Abandonar
- bibliotecas
- Con licencia
- como
- carga
- carga
- local
- Largo
- hecho
- HACE
- Realizar
- gestionado
- dominar
- max
- máximas
- mecanismo
- mensaje
- la vida
- podría
- minutos
- modelo
- los modos
- monitores
- más,
- Películas
- emocionante
- múltiples
- MySQL
- nombre
- Navegar
- Navegación
- ¿ Necesita ayuda
- del sistema,
- Nuevo
- Next
- número
- of
- Viejo
- on
- ONE
- de código abierto
- Otro
- salida
- página
- pares
- cristal
- parámetro
- parámetros
- parte
- pasado
- Contraseña
- Patrón de Costura
- realizar
- permanentemente
- recoger
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- plugin
- plugins
- Publicación
- evitar
- anterior
- tratamiento
- producir
- productor
- propiedades
- proporcionar
- previsto
- proporciona un
- Leer
- real
- en tiempo real
- recepción
- grabar
- archivos
- se refiere
- región
- registrarte
- registrado
- registro
- repositorio
- representado
- Recursos
- devoluciones
- Función
- Regla
- Ejecutar
- correr
- mismo
- escalable
- sin problemas
- Buscar
- segundos
- seguro
- EN LINEA
- mayor
- sensible
- separado
- de coches
- Servicios
- set
- ajustes
- tienes
- sencillos
- simplificar
- a medida
- Soluciones
- algo
- Fuente
- Fuentes
- especialista
- soluciones y
- especificado
- montón
- Comience a
- Estado
- paso
- pasos
- STORAGE
- tienda
- tiendas
- stream
- en streaming
- corrientes
- estructura
- adecuado
- Apoyar
- soportes
- sincronizar
- te
- Todas las funciones a su disposición
- mesa
- Target
- tareas
- plantilla
- test
- esa
- El
- La Fuente
- Les
- Estas
- equipo
- tiempo sensible
- Título
- a
- tema
- Transacciones
- GIRO
- tipos
- bajo
- no deseado
- actualización
- utilizan el
- Usuario
- propuesta de
- Valores
- versión
- web
- servicios web
- que
- seguirá
- ventanas
- obrero
- los trabajadores.
- trabajando
- funciona
- escrito
- tú
- zephyrnet