Encontrar columnas similares en un datos tiene aplicaciones importantes en la limpieza y anotación de datos, coincidencia de esquemas, descubrimiento de datos y análisis en múltiples fuentes de datos. La incapacidad de encontrar y analizar con precisión datos de fuentes dispares representa un potencial asesino de eficiencia para todos, desde científicos de datos, investigadores médicos, académicos hasta analistas financieros y gubernamentales.
Las soluciones convencionales implican la búsqueda de palabras clave léxicas o la coincidencia de expresiones regulares, que son susceptibles a problemas de calidad de los datos, como nombres de columnas ausentes o diferentes convenciones de nombres de columnas en diversos conjuntos de datos (por ejemplo, zip_code, zcode, postalcode).
En esta publicación, demostramos una solución para buscar columnas similares según el nombre de la columna, el contenido de la columna o ambos. La solución utiliza algoritmos de vecinos más cercanos aproximados disponible en Servicio Amazon OpenSearch para buscar columnas semánticamente similares. Para facilitar la búsqueda, creamos representaciones de características (incrustaciones) para columnas individuales en el lago de datos usando modelos de Transformer pre-entrenados del biblioteca de transformadores de oraciones in Amazon SageMaker. Finalmente, para interactuar y visualizar los resultados de nuestra solución, construimos un interactivo iluminado aplicación web ejecutándose en AWS Fargate.
Incluimos un tutorial de código para que implemente los recursos para ejecutar la solución en datos de muestra o en sus propios datos.
Resumen de la solución
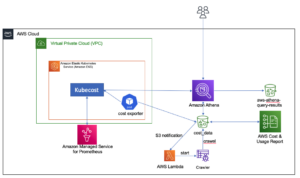
El siguiente diagrama de arquitectura ilustra el flujo de trabajo de dos etapas para encontrar columnas semánticamente similares. La primera etapa ejecuta un Funciones de paso de AWS flujo de trabajo que crea incrustaciones a partir de columnas tabulares y crea el índice de búsqueda de OpenSearch Service. La segunda etapa, o la etapa de inferencia en línea, ejecuta una aplicación Streamlit a través de Fargate. La aplicación web recopila consultas de búsqueda de entrada y recupera del índice del servicio OpenSearch las k columnas más similares aproximadas a la consulta.

Figura 1. Arquitectura de la solución
El flujo de trabajo automatizado procede en los siguientes pasos:
- El usuario carga conjuntos de datos tabulares en un Servicio de almacenamiento simple de Amazon (Amazon S3), que invoca un AWS Lambda que inicia el flujo de trabajo de Step Functions.
- El flujo de trabajo comienza con un Pegamento AWS trabajo que convierte los archivos CSV en Parquet Apache formato de datos.
- Un trabajo de procesamiento de SageMaker crea incrustaciones para cada columna utilizando modelos previamente entrenados o modelos de incrustación de columnas personalizados. El trabajo de procesamiento de SageMaker guarda las incrustaciones de columnas para cada tabla en Amazon S3.
- Una función de Lambda crea el dominio y el clúster de OpenSearch Service para indexar las incrustaciones de columnas producidas en el paso anterior.
- Finalmente, se implementa una aplicación web interactiva Streamlit con Fargate. La aplicación web proporciona una interfaz para que el usuario ingrese consultas para buscar columnas similares en el dominio del servicio OpenSearch.
Puede descargar el tutorial de código de GitHub para probar esta solución con datos de muestra o con sus propios datos. Las instrucciones sobre cómo implementar los recursos necesarios para este tutorial están disponibles en Github.
requisitos previos
Para implementar esta solución, necesita lo siguiente:
- An Cuenta de AWS.
- Familiaridad básica con los servicios de AWS, como el Kit de desarrollo en la nube de AWS (AWS CDK), Lambda, OpenSearch Service y SageMaker Processing.
- Un conjunto de datos tabulares para crear el índice de búsqueda. Puede traer sus propios datos tabulares o descargar los conjuntos de datos de muestra en GitHub.
Crear un índice de búsqueda
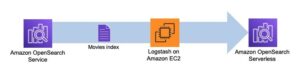
La primera etapa construye la columna del índice del motor de búsqueda. La siguiente figura ilustra el flujo de trabajo de Step Functions que ejecuta esta etapa.

Figura 2: flujo de trabajo de funciones de pasos: múltiples modelos de incrustación
Conjuntos de datos
En esta publicación, creamos un índice de búsqueda para incluir más de 400 columnas de más de 25 conjuntos de datos tabulares. Los conjuntos de datos proceden de las siguientes fuentes públicas:
Para obtener la lista completa de las tablas incluidas en el índice, consulte el tutorial de código en GitHub.
Puede traer su propio conjunto de datos tabulares para aumentar los datos de muestra o crear su propio índice de búsqueda. Incluimos dos funciones Lambda que inician el flujo de trabajo de Step Functions para crear el índice de búsqueda para archivos CSV individuales o un lote de archivos CSV, respectivamente.
Transformar CSV a Parquet
Los archivos CSV sin procesar se convierten al formato de datos Parquet con AWS Glue. Parquet es un formato de archivo de formato orientado a columnas preferido en el análisis de big data que proporciona compresión y codificación eficientes. En nuestros experimentos, el formato de datos Parquet ofreció una reducción significativa en el tamaño de almacenamiento en comparación con los archivos CSV sin procesar. También usamos Parquet como un formato de datos común para convertir otros formatos de datos (por ejemplo, JSON y NDJSON) porque admite estructuras de datos anidadas avanzadas.
Crear incrustaciones de columnas tabulares
Para extraer incorporaciones para columnas de tablas individuales en los conjuntos de datos tabulares de muestra en esta publicación, usamos los siguientes modelos previamente entrenados de la sentence-transformers biblioteca. Para modelos adicionales, consulte Modelos preentrenados.
El trabajo de procesamiento de SageMaker se ejecuta create_embeddings.py(código) para un solo modelo. Para extraer incrustaciones de varios modelos, el flujo de trabajo ejecuta trabajos de procesamiento de SageMaker en paralelo, como se muestra en el flujo de trabajo de Step Functions. Usamos el modelo para crear dos conjuntos de incrustaciones:
- nombre_columna_incrustaciones – Incrustaciones de nombres de columnas (encabezados)
- column_content_embeddings – Incrustación promedio de todas las filas en la columna
Para obtener más información sobre el proceso de incrustación de columnas, consulte el tutorial de código en GitHub.
Una alternativa al paso de procesamiento de SageMaker es crear una transformación por lotes de SageMaker para obtener incrustaciones de columnas en grandes conjuntos de datos. Esto requeriría implementar el modelo en un punto final de SageMaker. Para más información, ver Usar transformación por lotes.
Indexar incrustaciones con OpenSearch Service
En el paso final de esta etapa, una función Lambda agrega las incrustaciones de columnas a un k-vecino más cercano aproximado de OpenSearch Service (kNN) índice de búsqueda. A cada modelo se le asigna su propio índice de búsqueda. Para obtener más información sobre los parámetros de índice de búsqueda kNN aproximados, consulte k-NN.
Inferencia en línea y búsqueda semántica con una aplicación web
La segunda etapa del flujo de trabajo ejecuta un iluminado aplicación web donde puede proporcionar entradas y buscar columnas semánticamente similares indexadas en OpenSearch Service. La capa de aplicación utiliza un Balanceador de carga de aplicaciones, Fargate y Lambda. La infraestructura de la aplicación se implementa automáticamente como parte de la solución.
La aplicación le permite proporcionar una entrada y buscar nombres de columna semánticamente similares, contenido de columna o ambos. Además, puede seleccionar el modelo de incrustación y la cantidad de vecinos más cercanos para regresar de la búsqueda. La aplicación recibe entradas, incrusta la entrada con el modelo especificado y usa Búsqueda de kNN en el servicio OpenSearch para buscar incrustaciones de columnas indexadas y encontrar las columnas más similares a la entrada dada. Los resultados de la búsqueda que se muestran incluyen los nombres de las tablas, los nombres de las columnas y las puntuaciones de similitud de las columnas identificadas, así como las ubicaciones de los datos en Amazon S3 para una mayor exploración.
La siguiente figura muestra un ejemplo de la aplicación web. En este ejemplo, buscamos columnas en nuestro lago de datos que tengan Column Names (tipo de carga útil) A district (carga útil). La aplicación utilizada all-MiniLM-L6-v2 como el modelo de incrustación y volvió 10 (k) vecinos más cercanos de nuestro índice de OpenSearch Service.
La aplicación devolvió transit_district, city, boroughy location como las cuatro columnas más similares según los datos indexados en OpenSearch Service. Este ejemplo demuestra la capacidad del enfoque de búsqueda para identificar columnas semánticamente similares en conjuntos de datos.

Figura 3: interfaz de usuario de la aplicación web
Limpiar
Para eliminar los recursos creados por AWS CDK en este tutorial, ejecute el siguiente comando:
cdk destroy --allConclusión
En esta publicación, presentamos un flujo de trabajo integral para crear un motor de búsqueda semántica para columnas tabulares.
Comience hoy con sus propios datos con nuestro tutorial de código disponible en GitHub. Si desea ayuda para acelerar el uso de ML en sus productos y procesos, comuníquese con el Laboratorio de soluciones de aprendizaje automático de Amazon.
Acerca de los autores
![]() Kachi Odoemene es científico aplicado en AWS AI. Crea soluciones de IA/ML para resolver problemas comerciales para los clientes de AWS.
Kachi Odoemene es científico aplicado en AWS AI. Crea soluciones de IA/ML para resolver problemas comerciales para los clientes de AWS.
![]() taylor mcnally es arquitecto de aprendizaje profundo en Amazon Machine Learning Solutions Lab. Ayuda a los clientes de diversas industrias a crear soluciones que aprovechan AI/ML en AWS. Disfruta de una buena taza de café, el aire libre y el tiempo con su familia y su perro enérgico.
taylor mcnally es arquitecto de aprendizaje profundo en Amazon Machine Learning Solutions Lab. Ayuda a los clientes de diversas industrias a crear soluciones que aprovechan AI/ML en AWS. Disfruta de una buena taza de café, el aire libre y el tiempo con su familia y su perro enérgico.
![]() austin gallego es científico de datos en Amazon ML Solutions Lab. Desarrolla modelos personalizados de aprendizaje profundo para ayudar a los clientes del sector público de AWS a acelerar su adopción de la inteligencia artificial y la nube. En su tiempo libre, le gusta leer, viajar y practicar jiu-jitsu.
austin gallego es científico de datos en Amazon ML Solutions Lab. Desarrolla modelos personalizados de aprendizaje profundo para ayudar a los clientes del sector público de AWS a acelerar su adopción de la inteligencia artificial y la nube. En su tiempo libre, le gusta leer, viajar y practicar jiu-jitsu.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- Platoblockchain. Inteligencia del Metaverso Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- capacidad
- Nuestra Empresa
- ausente
- acelerar
- acelerador
- precisamente
- a través de
- Adicionales
- Adicionalmente
- Añade
- Adopción
- avanzado
- AI
- AI / ML
- Todos
- permite
- alternativa
- Amazon
- Aprendizaje automático de Amazon
- Laboratorio de soluciones de Amazon ML
- Analistas
- Analytics
- analizar
- y
- APACHE
- Aplicación
- aplicaciones
- aplicada
- enfoque
- arquitectura
- asigna
- Confirmación de Viaje
- automáticamente
- Hoy Disponibles
- promedio
- AWS
- Pegamento AWS
- basado
- porque
- Big
- Big Data
- llevar
- build
- Construir la
- construye
- Limpieza
- Soluciones
- adopción en la nube
- Médico
- código
- CAFÉ
- colecciona
- Columna
- Columnas
- Algunos
- en comparación con
- contacte
- contenido
- Convenciones
- convertir
- convertido
- Para crear
- creado
- crea
- Vaso
- personalizado
- Clientes
- datos
- Data Analytics
- Lago de datos
- calidad de los datos
- científico de datos
- conjuntos de datos
- profundo
- deep learning
- demostrar
- demuestra
- desplegar
- desplegado
- Desplegando
- destruir
- Desarrollo
- desarrolla el
- una experiencia diferente
- descubrimiento
- dispar
- diverso
- Perro
- dominio
- descargar
- cada una
- eficiencia
- eficiente
- de extremo a extremo
- Punto final
- Motor
- Éter (ETH)
- todos
- ejemplo
- exploración
- extraerlos
- facilitar
- Familiaridad
- familia
- Caracteristicas
- Figura
- Archive
- archivos
- final
- Finalmente
- financiero
- Encuentre
- la búsqueda de
- Nombre
- siguiendo
- formato
- Desde
- ser completados
- función
- funciones
- promover
- obtener
- dado
- candidato
- Gobierno
- cabeceras
- ayuda
- ayuda
- Cómo
- Como Hacer
- HTML
- HTTPS
- no haber aun identificado una solucion para el problema
- Identifique
- implementar
- importante
- in
- incapacidad
- incluir
- incluido
- índice
- INSTRUMENTO individual
- industrias
- información
- EN LA MINA
- iniciar
- Iniciados
- Las opciones de entrada
- Instrucciones
- interactuar
- interactivo
- Interfaz
- invoca
- involucrar
- cuestiones
- IT
- Trabajos
- Empleo
- json
- el lab
- lago
- large
- .
- aprendizaje
- aprovechando
- Biblioteca
- Lista
- carga
- Ubicaciones
- máquina
- máquina de aprendizaje
- pareo
- servicios
- ML
- modelo
- modelos
- más,
- MEJOR DE TU
- múltiples
- nombre
- nombres
- nombrando
- ¿ Necesita ayuda
- vecinos
- número
- Ofrecido
- en línea
- Otro
- al exterior
- EL DESARROLLADOR
- Paralelo
- parámetros
- parte
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Por favor
- Publicación
- posible
- preferido
- presentó
- anterior
- problemas
- producto
- en costes
- tratamiento
- producido
- Productos
- proporcionar
- proporciona un
- público
- calidad
- Crudo
- Reading
- recibe
- regular
- representa
- exigir
- Requisitos
- investigadores
- Recursos
- respectivamente
- Resultados
- volvemos
- Ejecutar
- correr
- sabio
- Científico
- los científicos
- Buscar
- motor de búsqueda
- búsqueda
- Segundo
- sector
- de coches
- Servicios
- Sets
- mostrado
- Shows
- importante
- similares
- sencillos
- soltero
- Tamaño
- a medida
- Soluciones
- RESOLVER
- Fuentes
- especificado
- Etapa
- fundó
- paso
- pasos
- STORAGE
- tal
- soportes
- susceptible
- mesa
- La
- su
- A través de esta formación, el personal docente y administrativo de escuelas y universidades estará preparado para manejar los recursos disponibles que derivan de la diversidad cultural de sus estudiantes. Además, un mejor y mayor entendimiento sobre estas diferencias y similitudes culturales permitirá alcanzar los objetivos de inclusión previstos.
- equipo
- a
- hoy
- Transformar
- transformers
- Viajar
- tutoriales
- utilizan el
- Usuario
- Interfaz de usuario
- diversos
- web
- Aplicación web
- que
- flujo de trabajo
- se
- tú
- zephyrnet