Atenea amazónica es un servicio de consulta interactivo que facilita el análisis de datos en Servicio de almacenamiento simple de Amazon (Amazon S3) y fuentes de datos que residen en AWS, en las instalaciones u otros sistemas en la nube mediante SQL o Python. Athena se basa en motores Trino y Presto de código abierto y marcos Apache Spark, sin necesidad de aprovisionamiento ni esfuerzo de configuración. Athena no tiene servidor, por lo que no hay infraestructura que administrar y solo paga por las consultas que ejecuta.
iceberg apache es un formato de tabla abierta para conjuntos de datos analíticos muy grandes. Gestiona grandes colecciones de archivos como tablas y admite operaciones analíticas modernas de lagos de datos, como consultas de inserción, actualización, eliminación y viajes en el tiempo a nivel de registro. Athena admite consultas de lectura, viaje en el tiempo, escritura y DDL para tablas Apache Iceberg que usan el formato Apache Parquet para datos y el Catálogo de datos de AWS Glue para su metastore.
Ingeniería de características es un proceso de identificar y transformar datos sin procesar (imágenes, archivos de texto, videos, etc.), completar los datos faltantes y agregar uno o más elementos de datos significativos para proporcionar contexto para que un modelo de aprendizaje automático (ML) pueda aprender de ellos. El etiquetado de datos es necesario para varios casos de uso, incluidos pronósticos, visión por computadora, procesamiento de lenguaje natural y reconocimiento de voz.
Combinado con las capacidades de Athena, Apache Iceberg ofrece un flujo de trabajo simplificado para que los científicos de datos creen nuevas funciones de datos sin necesidad de copiar o recrear todo el conjunto de datos. Puede crear funciones utilizando SQL estándar en Athena sin usar ningún otro servicio para la ingeniería de funciones. Los científicos de datos pueden reducir el tiempo dedicado a preparar y copiar conjuntos de datos y, en cambio, centrarse en la ingeniería de características de los datos, la experimentación y el análisis de datos a escala.
En esta publicación, revisamos los beneficios de usar Athena con el formato de tabla abierta Apache Iceberg y cómo simplifica las tareas de ingeniería de características comunes para los científicos de datos. Demostramos cómo Athena puede convertir una tabla existente en formato Apache Iceberg, luego agregar columnas, eliminar columnas y modificar los datos en la tabla sin recrear ni copiar el conjunto de datos, y usar estas capacidades para crear nuevas funciones en las tablas de Apache Iceberg.
Resumen de la solución
Los científicos de datos generalmente están acostumbrados a trabajar con grandes conjuntos de datos. Los conjuntos de datos generalmente se almacenan en JSON, CSV, ORC o Parquet Apache formato o formatos similares optimizados para lectura para un rendimiento de lectura rápido. Los científicos de datos a menudo crean nuevas características de datos y las completan con datos agregados y auxiliares. Históricamente, esta tarea se lograba creando una vista en la parte superior de la tabla con los datos subyacentes en formato Apache Parquet, donde dichas columnas y datos se agregaban en tiempo de ejecución o creando una nueva tabla con columnas adicionales. Aunque este flujo de trabajo es adecuado para muchos casos de uso, es ineficiente para conjuntos de datos grandes, porque los datos deberían generarse en tiempo de ejecución o los conjuntos de datos deberían copiarse y transformarse.
Atenea ha presentado Transacción ACID (Atomicidad, Consistencia, Aislamiento, Durabilidad) capacidades que agregan INSERTAR, ACTUALIZAR, ELIMINAR, FUSIONAR y operaciones de viaje en el tiempo basadas en Mesas Apache Iceberg. Estas capacidades permiten a los científicos de datos crear nuevas características de datos y eliminar características de datos existentes en conjuntos de datos existentes sin preocuparse por copiar o transformar el conjunto de datos o abstraerlo con una vista. Los científicos de datos pueden centrarse en el trabajo de ingeniería de características y evitar copiar y transformar los conjuntos de datos.
La operación UPDATE de Athena Iceberg escribe los archivos de eliminación de posición de Apache Iceberg y las filas recién actualizadas como archivos de datos en la misma transacción. Puede realizar correcciones de registros a través de una sola declaración de ACTUALIZACIÓN.
Con el lanzamiento de la versión 3 del motor Athena, las capacidades de las tablas Apache Iceberg se mejoran con soporte para operaciones como CREAR TABLA COMO SELECCIONAR (CTAS) y comandos MERGE que agilizan la gestión del ciclo de vida de sus datos de Iceberg. CTAS hace que sea rápido y eficiente la creación de tablas a partir de otros formatos como Apache Paquet y UNIRSE CON actualizaciones condicionales, elimina o inserta filas en una tabla Iceberg. Una sola instrucción puede combinar acciones de actualización, eliminación e inserción.
Requisitos previos
Configure un grupo de trabajo de Athena con el motor Athena versión 3 para usar comandos CTAS y MERGE con una tabla Apache Iceberg. Para actualizar su motor Athena existente a la versión 3 en su grupo de trabajo de Athena, siga las instrucciones en Actualice a la versión 3 del motor Athena para aumentar el rendimiento de las consultas y acceder a más funciones de análisis o referirse a Cambiar la versión del motor en la consola Athena.
Conjunto de datos
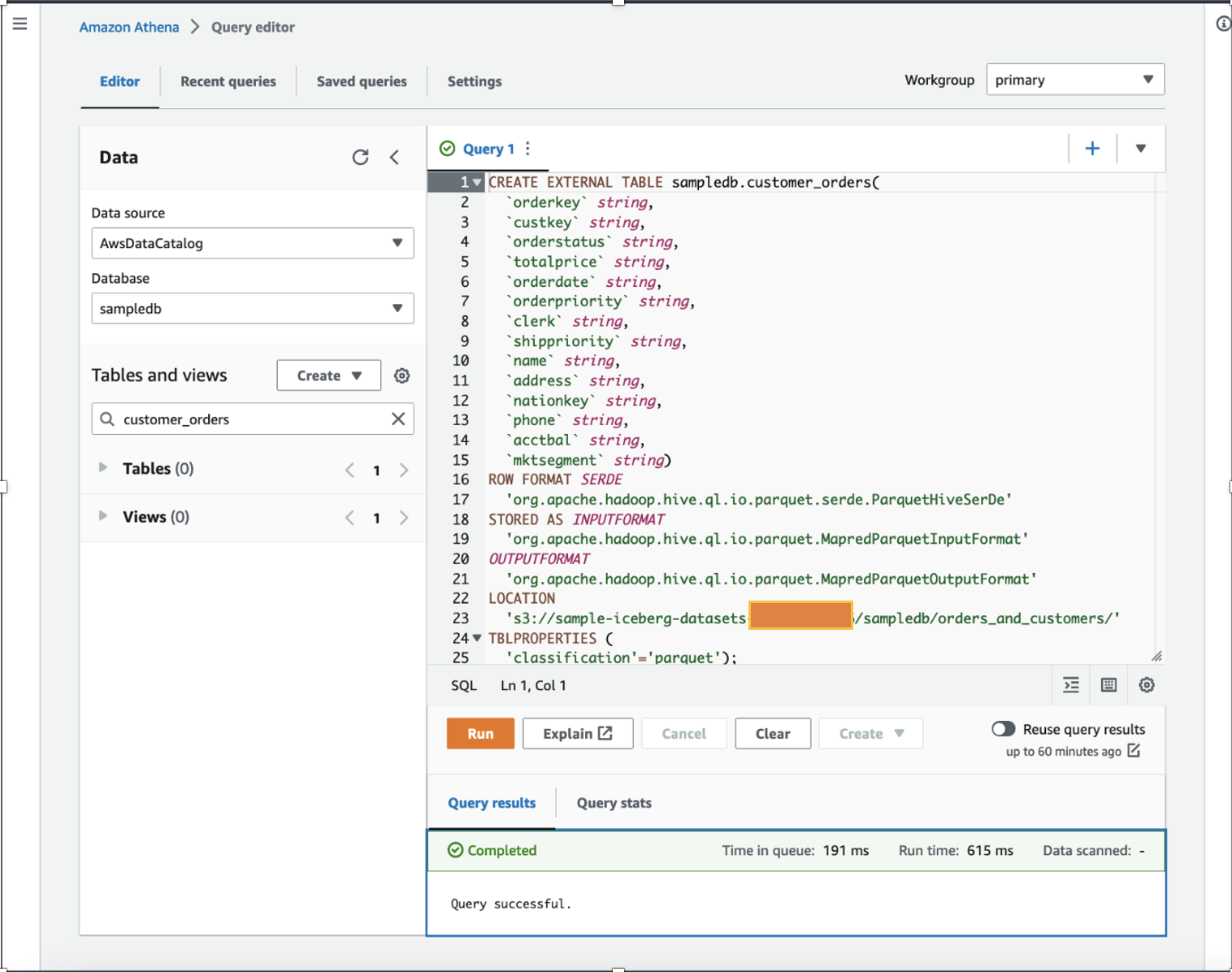
Para la demostración, utilizamos una tabla Apache Parquet que contiene varios millones de registros de datos de ventas ficticios distribuidos aleatoriamente de los últimos años almacenados en un depósito de S3. Descargar el conjunto de datos, descomprímalo en su computadora local y cárguelo en su depósito S3. En esta publicación, subimos nuestro conjunto de datos a s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
La siguiente tabla muestra el diseño de la tabla. customer_orders.
| Nombre de columna | Tipo de datos | Descripción |
| clave de pedido | cadena | Número de pedido para el pedido |
| custodio | cadena | Número de identificación del cliente |
| estado del pedido | cadena | Estado del pedido |
| precio total | cadena | Precio total del pedido |
| fecha de orden | cadena | Fecha del pedido |
| orden de prioridad | cadena | Prioridad del pedido |
| secretario | cadena | Nombre del empleado que procesó el pedido. |
| prioridad de envío | cadena | Prioridad en el envío. |
| nombre | cadena | Nombre del cliente |
| dirección | cadena | Dirección del cliente |
| clave de nación | cadena | Clave de nación del cliente |
| teléfono | cadena | Número de teléfono del cliente |
| cuenta | cadena | Saldo de la cuenta del cliente |
| segmento de mercado | cadena | Segmento de mercado de clientes |
Realizar ingeniería de características
Como científico de datos, queremos realizar ingeniería de características en los datos de pedidos de los clientes sumando las compras totales calculadas de un año y las compras promedio de un año para cada cliente en el conjunto de datos existente. Para fines de demostración, creamos el customer_orders mesa en el sampledb base de datos usando Athena como se muestra en el siguiente comando DDL. (Puede utilizar cualquiera de sus conjuntos de datos existentes y seguir los pasos mencionados en esta publicación). customer_orders El conjunto de datos se generó y almacenó en la ubicación del depósito S3. s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ en formato Parquet. Esta mesa no es una mesa Apache Iceberg.
![]()
Valide los datos de la tabla ejecutando una consulta:
![]()
Queremos agregar nuevas funciones a esta tabla para obtener una comprensión más profunda de las ventas de los clientes, lo que puede resultar en una capacitación del modelo más rápida y conocimientos más valiosos. Para agregar nuevas características al conjunto de datos, convierta el customer_orders Mesa Athena a mesa Apache Iceberg en Athena. Emitir un CTAS declaración de consulta para crear una nueva tabla con formato Apache Iceberg desde el customer_orders mesa. Al hacerlo, se agrega una nueva función para obtener el monto total de la compra del año pasado (año máximo del conjunto de datos) por parte de cada cliente.
En la siguiente consulta CTAS, una nueva columna llamada one_year_sales_aggregate con el valor predeterminado como 0.0 del tipo de datos double se agrega y table_type se establece a ICEBERG:
![]()
Emita la siguiente consulta para verificar los datos en la tabla Apache Iceberg con la nueva columna one_year_sales_aggregate valores como 0.0:
![]()
Queremos completar los valores para la nueva característica. one_year_sales_aggregate en el conjunto de datos para obtener el monto total de la compra de cada cliente en función de sus compras en el último año (año máximo del conjunto de datos). Emita una declaración de consulta MERGE a la tabla Apache Iceberg usando Athena para completar los valores para la one_year_sales_aggregate característica:
![]()
Emita la siguiente consulta para validar el valor actualizado del gasto total de cada cliente en el último año:
![]()
Decidimos agregar otra característica a una tabla Apache Iceberg existente para calcular y almacenar el monto promedio de compra del año pasado por parte de cada cliente. Emitir una declaración de consulta ALTER para agregar una nueva columna a una tabla existente para la característica one_year_sales_average:
![]()
Antes de completar los valores de esta nueva característica, puede establecer el valor predeterminado para la característica one_year_sales_average a 0.0. Usando la misma tabla Apache Iceberg en Athena, emita una instrucción de consulta UPDATE para completar el valor de la nueva característica como 0.0:
![]()
Emita la siguiente consulta para verificar que el valor actualizado del gasto promedio de cada cliente en el último año esté establecido en 0.0:
![]()
Ahora queremos completar los valores para la nueva característica. one_year_sales_average en el conjunto de datos para obtener el monto de compra promedio de cada cliente en función de sus compras en el último año (año máximo del conjunto de datos). Emitir una declaración de consulta MERGE a la tabla Apache Iceberg existente en Athena utilizando el motor de Athena para completar los valores de la característica one_year_sales_average:
![]()
Emita la siguiente consulta para verificar los valores actualizados del gasto promedio de cada cliente:
![]()
Una vez que se han agregado características de datos adicionales al conjunto de datos, los científicos de datos generalmente proceden a entrenar modelos de aprendizaje automático y hacer inferencias utilizando Amazon Sagemaker o un conjunto de herramientas equivalente.
Conclusión
En esta publicación, demostramos cómo realizar la ingeniería de características usando Athena con Apache Iceberg. También demostramos el uso de la consulta CTAS para crear una tabla Apache Iceberg en Athena a partir de un conjunto de datos existente en formato Apache Parquet, agregando nuevas características en una tabla Apache Iceberg existente en Athena usando la consulta ALTER y usando declaraciones de consulta UPDATE y MERGE para actualizar la tabla. valores de características de las columnas existentes.
Le recomendamos que utilice consultas CTAS para crear tablas de forma rápida y eficiente, y que utilice la instrucción de consulta MERGE para sincronizar tablas en un solo paso para simplificar la preparación de datos y las tareas de actualización al transformar las funciones utilizando Athena con Apache Iceberg. Si tiene comentarios o sugerencias, déjelos en la sección de comentarios.
Acerca de los autores
![]() vivek gautam es Arquitecto de Datos con especialización en lagos de datos en AWS Professional Services. Trabaja con clientes empresariales creando productos de datos, plataformas de análisis y soluciones en AWS. Cuando no construye y diseña plataformas de datos modernas, Vivek es un entusiasta de la comida al que también le gusta explorar nuevos destinos de viaje y hacer caminatas.
vivek gautam es Arquitecto de Datos con especialización en lagos de datos en AWS Professional Services. Trabaja con clientes empresariales creando productos de datos, plataformas de análisis y soluciones en AWS. Cuando no construye y diseña plataformas de datos modernas, Vivek es un entusiasta de la comida al que también le gusta explorar nuevos destinos de viaje y hacer caminatas.
![]() Mijaíl Vaynshteyn es un Arquitecto de Soluciones con Amazon Web Services. Mikhail trabaja con clientes de atención médica y ciencias de la vida para crear soluciones que ayuden a mejorar los resultados de los pacientes. Mikhail se especializa en servicios de análisis de datos.
Mijaíl Vaynshteyn es un Arquitecto de Soluciones con Amazon Web Services. Mikhail trabaja con clientes de atención médica y ciencias de la vida para crear soluciones que ayuden a mejorar los resultados de los pacientes. Mikhail se especializa en servicios de análisis de datos.
![]() Naresh Gautam es un líder de análisis de datos e inteligencia artificial/aprendizaje automático en AWS con 20 años de experiencia, que disfruta ayudando a los clientes a diseñar análisis de datos y soluciones de inteligencia artificial/aprendizaje automático altamente disponibles, de alto rendimiento y rentables para empoderar a los clientes con la toma de decisiones basada en datos . En su tiempo libre, disfruta de la meditación y la cocina.
Naresh Gautam es un líder de análisis de datos e inteligencia artificial/aprendizaje automático en AWS con 20 años de experiencia, que disfruta ayudando a los clientes a diseñar análisis de datos y soluciones de inteligencia artificial/aprendizaje automático altamente disponibles, de alto rendimiento y rentables para empoderar a los clientes con la toma de decisiones basada en datos . En su tiempo libre, disfruta de la meditación y la cocina.
![]() Harsha Tadiparti es un Arquitecto de Soluciones Principal especialista, Análisis en AWS. Disfruta resolviendo problemas complejos de clientes en bases de datos y análisis y brindando resultados exitosos. Fuera del trabajo, le encanta pasar tiempo con su familia, ver películas y viajar siempre que sea posible.
Harsha Tadiparti es un Arquitecto de Soluciones Principal especialista, Análisis en AWS. Disfruta resolviendo problemas complejos de clientes en bases de datos y análisis y brindando resultados exitosos. Fuera del trabajo, le encanta pasar tiempo con su familia, ver películas y viajar siempre que sea posible.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- EVM Finanzas. Interfaz unificada para finanzas descentralizadas. Accede Aquí.
- Grupo de medios cuánticos. IR/PR amplificado. Accede Aquí.
- PlatoAiStream. Inteligencia de datos Web3. Conocimiento amplificado. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :posee
- :es
- :no
- :dónde
- $ UP
- 10
- 100
- 12
- 17
- 20
- 20 años
- 23
- 27
- 7
- a
- Nuestra Empresa
- acelerar
- de la máquina
- logrado
- Mi Cuenta
- acciones
- add
- adicional
- la adición de
- Adicionales
- dirección
- AI / ML
- también
- Aunque
- Amazon
- Atenea amazónica
- Amazon SageMaker
- Amazon Web Services
- cantidad
- an
- Analítico
- Pruebas analíticas
- Analytics
- analizar
- el análisis de
- y
- Otra
- cualquier
- APACHE
- Apache Spark
- somos
- AS
- At
- Hoy Disponibles
- promedio
- evitar
- AWS
- Servicios profesionales de AWS
- basado
- BE
- porque
- esto
- beneficios
- build
- Construir la
- construido
- by
- calculado
- PUEDEN
- capacidades
- cases
- clasificación
- Soluciones
- colecciones
- Columna
- Columnas
- combinar
- comentarios
- Algunos
- integraciones
- Calcular
- computadora
- Visión por computador
- Configuración
- contiene
- contexto
- convertir
- cocinar
- proceso de copiar
- correcciones
- rentable
- Para crear
- creado
- Creamos
- cliente
- Clientes
- datos
- Data Analytics
- Lago de datos
- Ciencia de los datos
- científico de datos
- basada en datos
- Base de datos
- bases de datos
- conjuntos de datos
- Fecha
- decidir
- Toma de Decisiones
- más profundo
- Predeterminado
- entregar
- entrega
- demostrar
- demostrado
- diseño
- destinos
- distribuidos
- "Hacer"
- doble
- Soltar
- durabilidad
- cada una
- de forma sencilla
- eficiente
- eficiente.
- esfuerzo
- ya sea
- elementos
- empoderar a
- habilitar
- fomentar
- Motor
- Ingeniería
- motores
- mejorado
- Empresa
- clientes empresariales
- entusiasta
- Todo
- Equivalente a
- Éter (ETH)
- existente
- experience
- explorar
- externo
- false
- familia
- RÁPIDO
- más rápida
- Feature
- Caracteristicas
- realimentación
- archivos
- Focus
- seguir
- siguiendo
- Comida
- formato
- marcos
- Gratis
- Desde
- en general
- generado
- obtener
- Go
- Grupo procesos
- Hadoop
- Tienen
- he
- la salud
- ayuda
- ayudando
- Alto rendimiento
- altamente
- Caminatas
- su
- históricamente
- Colmena
- Cómo
- Como Hacer
- HTML
- HTTPS
- Identificación
- identificar
- if
- imágenes
- mejorar
- in
- Incluye
- aumente
- ineficiente
- EN LA MINA
- Insertos
- Insights
- Instrucciones
- interactivo
- dentro
- Introducido
- solo
- IT
- jpg
- json
- etiquetado
- lago
- idioma
- large
- Apellidos
- Disposición
- líder
- APRENDE:
- aprendizaje
- Abandonar
- Vida
- Ciencias de la vida
- ciclo de vida
- LIMITE LAS
- local
- Ubicación
- ama
- máquina
- máquina de aprendizaje
- para lograr
- HACE
- gestionan
- Management
- gestiona
- muchos
- Mercado
- emparejado
- max
- significativo
- Meditación
- mencionado
- ir
- millones
- que falta
- ML
- modelo
- modelos
- Moderno
- modificar
- más,
- Películas
- nombre
- Llamado
- UR DONATIONS
- Natural
- Lenguaje natural
- Procesamiento natural del lenguaje
- ¿ Necesita ayuda
- necesidad
- Nuevo
- nueva función
- Nuevas características
- recién
- no
- número
- of
- a menudo
- on
- ONE
- , solamente
- habiertos
- de código abierto
- Inteligente
- Operaciones
- or
- en pedidos de venta.
- Otro
- nuestros
- resultados
- afuera
- pasado
- Pagar
- realizar
- actuación
- teléfono
- Plataformas
- Platón
- Inteligencia de datos de Platón
- PlatónDatos
- Por favor
- posición
- posible
- Publicación
- preparación
- precio
- Director de la escuela
- problemas
- procesado
- tratamiento
- Productos
- Profesional
- proporcionar
- comprar
- compras
- fines
- Python
- consultas
- con rapidez
- Crudo
- datos en bruto
- Leer
- reconocimiento
- grabar
- archivos
- reducir
- ,
- Requisitos
- resultado
- una estrategia SEO para aparecer en las búsquedas de Google.
- FILA
- Ejecutar
- correr
- sabio
- ventas
- mismo
- Escala
- Ciencia:
- CIENCIAS
- Científico
- los científicos
- Sección
- Sin servidor
- de coches
- Servicios
- set
- Varios
- mostrado
- Shows
- similares
- sencillos
- simplificado
- simplificar
- soltero
- So
- Soluciones
- Resolver
- Fuentes
- Spark
- especialista
- se especializa
- habla
- Reconocimiento de voz
- pasar
- gastado
- SQL
- estándar
- Posicionamiento
- declaraciones
- paso
- pasos
- STORAGE
- tienda
- almacenados
- aerodinamizar
- Cordón
- exitosos
- tal
- SOPORTE
- soportes
- Todas las funciones a su disposición
- mesa
- Tarea
- tareas
- esa
- La
- La fusión
- su
- Les
- luego
- Ahí.
- Estas
- así
- equipo
- el tiempo de viaje
- a
- parte superior
- Total
- Entrenar
- Formación
- transaccional
- transaccional
- transformado
- transformadora
- viajes
- tipo
- subyacente
- comprensión
- Actualizar
- actualizado
- Actualizaciones
- actualizar
- subido
- utilizan el
- usando
- generalmente
- VALIDAR
- Valioso
- propuesta de
- Valores
- diversos
- verificar
- versión
- muy
- vía
- Videos
- Ver
- visión
- quieres
- fue
- Ver ahora
- we
- web
- servicios web
- tuvieron
- cuando
- cuando
- que
- mientras
- QUIENES
- sin
- Actividades:
- flujo de trabajo
- Forma de interés del Grupo de Trabajo
- trabajando
- funciona
- se
- escribir
- año
- años
- Usted
- tú
- zephyrnet
- Zip