15 fragmentos de Python para optimizar su canal de ciencia de datos
Soluciones rápidas de Python para ayudar a su ciclo de ciencia de datos.
By Lucas Soares, Ingeniero de aprendizaje automático en K1 Digital

Foto por Carlos muza on Unsplash
Por qué los fragmentos son importantes para la ciencia de datos
En mi rutina diaria tengo que lidiar con muchas de las mismas situaciones, desde cargar archivos csv hasta visualizar datos. Entonces, para ayudar a agilizar mi proceso, creé el hábito de almacenar fragmentos de código que son útiles en diferentes situaciones, desde cargar archivos csv hasta visualizar datos.
En esta publicación, compartiré 15 fragmentos de código para ayudar con diferentes aspectos de su canalización de análisis de datos.
1. Carga de varios archivos con comprensión global y de lista
import glob
import pandas as pd
csv_files = glob.glob("path/to/folder/with/csvs/*.csv")
dfs = [pd.read_csv(filename) for filename in csv_files]2. Obtener valores únicos de una tabla de columnas
import pandas as pd
df = pd.read_csv("path/to/csv/file.csv")
df["Item_Identifier"].unique()array(['FDA15', 'DRC01', 'FDN15', ..., 'NCF55', 'NCW30', 'NCW05'], dtype=object)3. Mostrar marcos de datos de pandas uno al lado del otro
from IPython.display import display_html
from itertools import chain,cycledef display_side_by_side(*args,titles=cycle([''])): # source: https://stackoverflow.com/questions/38783027/jupyter-notebook-display-two-pandas-tables-side-by-side html_str='' for df,title in zip(args, chain(titles,cycle(['</br>'])) ): html_str+='<th style="text-align:center"><td style="vertical-align:top">' html_str+="<br>" html_str+=f'<h2>{title}</h2>' html_str+=df.to_html().replace('table','table style="display:inline"') html_str+='</td></th>' display_html(html_str,raw=True)
df1 = pd.read_csv("file.csv")
df2 = pd.read_csv("file2")
display_side_by_side(df1.head(),df2.head(), titles=['Sales','Advertising'])
### Output
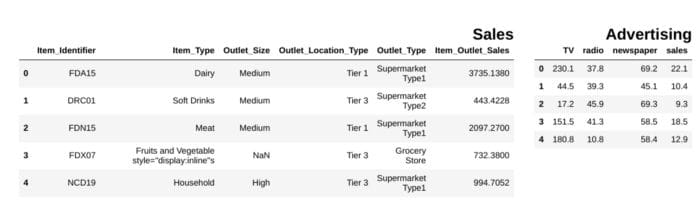
imagen del autor
4. Elimina todos los NaN en el marco de datos de pandas
df = pd.DataFrame(dict(a=[1,2,3,None]))
df
df.dropna(inplace=True)
df

5. Muestre el número de entradas de NaN en las columnas de DataFrame
def findNaNCols(df): for col in df: print(f"Column: {col}") num_NaNs = df[col].isnull().sum() print(f"Number of NaNs: {num_NaNs}")
df = pd.DataFrame(dict(a=[1,2,3,None],b=[None,None,5,6]))
findNaNCols(df)# OutputColumn: a
Number of NaNs: 1
Column: b
Number of NaNs: 26. Transformar columnas con .apply y funciones lambda
df = pd.DataFrame(dict(a=[10,20,30,40,50]))
square = lambda x: x**2
df["a"]=df["a"].apply(square)
df

7. Transformar 2 columnas de DataFrame en un diccionario
df = pd.DataFrame(dict(a=["a","b","c"],b=[1,2,3]))
df_dictionary = dict(zip(df["a"],df["b"]))
df_dictionary{'a': 1, 'b': 2, 'c': 3}8. Trazado de cuadrícula de distribuciones con condicionales en columnas.
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd df = pd.DataFrame(dict(a=np.random.randint(0,100,100),b=np.arange(0,100,1)))
plt.figure(figsize=(15,7))
plt.subplot(1,2,1)
df["b"][df["a"]>50].hist(color="green",label="bigger than 50")
plt.legend()
plt.subplot(1,2,2)
df["b"][df["a"]<50].hist(color="orange",label="smaller than 50")
plt.legend()
plt.show()
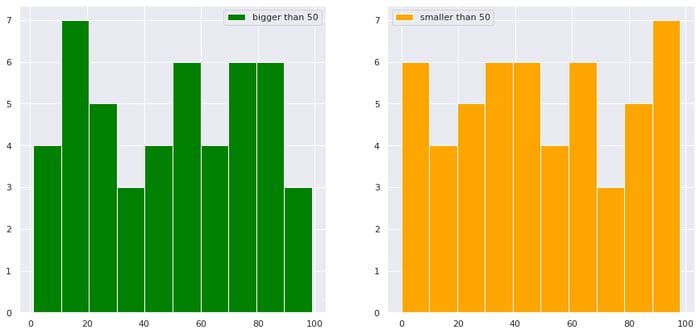
imagen del autor
9. Ejecución de pruebas t para valores de diferentes columnas en pandas
from scipy.stats import ttest_rel data = np.arange(0,1000,1)
data_plus_noise = np.arange(0,1000,1) + np.random.normal(0,1,1000)
df = pd.DataFrame(dict(data=data, data_plus_noise=data_plus_noise))
print(ttest_rel(df["data"],df["data_plus_noise"]))# Output
Ttest_relResult(statistic=-1.2717454718006775, pvalue=0.20375954602300195)10. Fusionar marcos de datos en una columna determinada
df1 = pd.DataFrame(dict(a=[1,2,3],b=[10,20,30],col_to_merge=["a","b","c"]))
df2 = pd.DataFrame(dict(d=[10,20,100],col_to_merge=["a","b","c"]))
df_merged = df1.merge(df2, on='col_to_merge')
df_merged

11. Normalizar valores en una columna de pandas con sklearn
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scores = scaler.fit_transform(df["a"].values.reshape(-1,1))12. Colocar NaN en una columna específica en pandas
df.dropna(subset=["col_to_remove_NaNs_from"],inplace=True)13. Seleccionar un subconjunto de un marco de datos con condicionales y or ambiental
df = pd.DataFrame(dict(result=["Pass","Fail","Pass","Fail","Distinction","Distinction"]))
pass_index = (df["result"]=="Pass") | (df["result"]=="Distinction")
df_pass = df[pass_index]
df_pass

14. Gráfico circular básico
import matplotlib.pyplot as plt df = pd.DataFrame(dict(a=[10,20,50,10,10],b=["A","B","C","D","E"]))
labels = df["b"]
sizes = df["a"]
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()

15. Cambiar una cadena de porcentaje a un valor numérico usando .apply()
def change_to_numerical(x): try: x = int(x.strip("%")[:2]) except: x = int(x.strip("%")[:1]) return x df = pd.DataFrame(dict(a=["A","B","C"],col_with_percentage=["10%","70%","20%"]))
df["col_with_percentage"] = df["col_with_percentage"].apply(change_to_numerical)
df

Conclusión
Creo que los fragmentos de código son muy valiosos, reescribir el código puede ser una verdadera pérdida de tiempo, por lo que tener un conjunto de herramientas completo con todas las soluciones simples que necesita para optimizar su proceso de análisis de datos puede ser de gran ayuda.
Si te gustó esta publicación conéctate conmigo en Twitter, Etiqueta LinkedIn y sígueme Medio. ¡Gracias y hasta la próxima! 🙂
Más contenido en simpleenglish.io
Bio: Lucas Soares es un ingeniero de inteligencia artificial que trabaja en aplicaciones de aprendizaje profundo para una amplia gama de problemas.
Original. Publicado de nuevo con permiso.
Relacionado:
Fuente: https://www.kdnuggets.com/2021/08/15-python-snippets-optimize-data-science-pipeline.html
- '
- "
- &
- 100
- 7
- Publicidad
- AI
- Todos
- análisis
- Aplicación
- aplicaciones
- auto
- AWS
- código
- Columna
- Algunos
- contenido
- datos
- análisis de los datos
- Ciencia de los datos
- acuerdo
- deep learning
- Director
- ingeniero
- Caracteristicas
- Nombre
- seguir
- GPU
- maravillosa
- Verde
- Cuadrícula
- Cómo
- Como Hacer
- HTTPS
- Entrevista
- Etiquetas
- APRENDE:
- aprendizaje
- Etiqueta LinkedIn
- Lista
- máquina de aprendizaje
- mediano
- ML
- Neural
- habiertos
- de código abierto
- Python
- distancia
- razones
- regresión
- correr
- ventas
- Ciencia:
- los científicos
- Compartir
- sencillos
- So
- Soluciones
- cuadrado
- estadísticas
- Historias
- TD
- Pruebas
- equipo
- parte superior
- transformadora
- propuesta de
- X