Ένα νεοδημιουργημένο σύστημα τεχνητής νοημοσύνης (AI) που βασίζεται στη βαθιά ενισχυτική μάθηση (DRL) μπορεί να αντιδράσει σε επιτιθέμενους σε ένα προσομοιωμένο περιβάλλον και να μπλοκάρει το 95% των κυβερνοεπιθέσεων προτού κλιμακωθούν.
Αυτό λένε οι ερευνητές από το Εθνικό Εργαστήριο Βορειοδυτικού Ειρηνικού του Τμήματος Ενέργειας, οι οποίοι δημιούργησαν μια αφηρημένη προσομοίωση της ψηφιακής σύγκρουσης μεταξύ επιτιθέμενων και υπερασπιστών σε ένα δίκτυο και εκπαίδευσαν τέσσερα διαφορετικά νευρωνικά δίκτυα DRL για να μεγιστοποιήσουν τις ανταμοιβές με βάση την πρόληψη συμβιβασμούς και την ελαχιστοποίηση της διακοπής του δικτύου.
Οι προσομοιωμένοι επιτιθέμενοι χρησιμοποίησαν μια σειρά από τακτικές βασισμένες στο MITER ATT & CK την ταξινόμηση του πλαισίου για μετάβαση από την αρχική φάση πρόσβασης και αναγνώρισης σε άλλες φάσεις επίθεσης μέχρι να φτάσουν στον στόχο τους: τη φάση πρόσκρουσης και διήθησης.
Η επιτυχής εκπαίδευση του συστήματος AI στο απλοποιημένο περιβάλλον επίθεσης καταδεικνύει ότι οι αμυντικές απαντήσεις στις επιθέσεις σε πραγματικό χρόνο θα μπορούσαν να αντιμετωπιστούν από ένα μοντέλο τεχνητής νοημοσύνης, λέει ο Samrat Chatterjee, ένας επιστήμονας δεδομένων που παρουσίασε το έργο της ομάδας στην ετήσια συνάντηση της Ένωσης για την Προώθηση της Τεχνητής Νοημοσύνης στην Ουάσιγκτον, DC στις 14 Φεβρουαρίου.
«Δεν θέλετε να προχωρήσετε σε πιο σύνθετες αρχιτεκτονικές εάν δεν μπορείτε καν να δείξετε την υπόσχεση αυτών των τεχνικών», λέει. «Θέλαμε να δείξουμε πρώτα ότι μπορούμε πραγματικά να εκπαιδεύσουμε ένα DRL με επιτυχία και να δείξουμε κάποια καλά αποτελέσματα δοκιμών, πριν προχωρήσουμε».
Η εφαρμογή τεχνικών μηχανικής μάθησης και τεχνητής νοημοσύνης σε διαφορετικά πεδία της κυβερνοασφάλειας έχει γίνει μια καυτή τάση την τελευταία δεκαετία, από την πρώιμη ενσωμάτωση της μηχανικής μάθησης σε πύλες ασφαλείας email στις αρχές της δεκαετίας του 2010 σε πιο πρόσφατες προσπάθειες να χρησιμοποιήστε το ChatGPT για να αναλύσετε τον κώδικα ή διεξαγωγή ιατροδικαστικής ανάλυσης. Τώρα, έχουν τα περισσότερα προϊόντα ασφαλείας — ή ισχυριστείτε ότι έχετε — μερικές δυνατότητες που υποστηρίζονται από αλγόριθμους μηχανικής εκμάθησης που έχουν εκπαιδευτεί σε μεγάλα σύνολα δεδομένων.
Ωστόσο, η δημιουργία ενός συστήματος AI ικανού για προληπτική άμυνα εξακολουθεί να είναι φιλόδοξη, παρά πρακτική. Ενώ παραμένουν διάφορα εμπόδια για τους ερευνητές, η έρευνα PNNL δείχνει ότι ένας υπερασπιστής της τεχνητής νοημοσύνης θα μπορούσε να είναι δυνατός στο μέλλον.
«Η αξιολόγηση πολλαπλών αλγορίθμων DRL που εκπαιδεύονται κάτω από διαφορετικές ρυθμίσεις αντιπάλου είναι ένα σημαντικό βήμα προς πρακτικές αυτόνομες λύσεις άμυνας στον κυβερνοχώρο», η ερευνητική ομάδα PNNL αναφέρουν στο έγγραφό τους. «Τα πειράματά μας υποδηλώνουν ότι οι αλγόριθμοι DRL χωρίς μοντέλα μπορούν να εκπαιδευτούν αποτελεσματικά σε προφίλ επίθεσης πολλαπλών σταδίων με διαφορετικά επίπεδα δεξιοτήτων και επιμονής, αποδίδοντας ευνοϊκά αμυντικά αποτελέσματα σε αμφισβητούμενες ρυθμίσεις».
Πώς το σύστημα χρησιμοποιεί το MITER ATT&CK
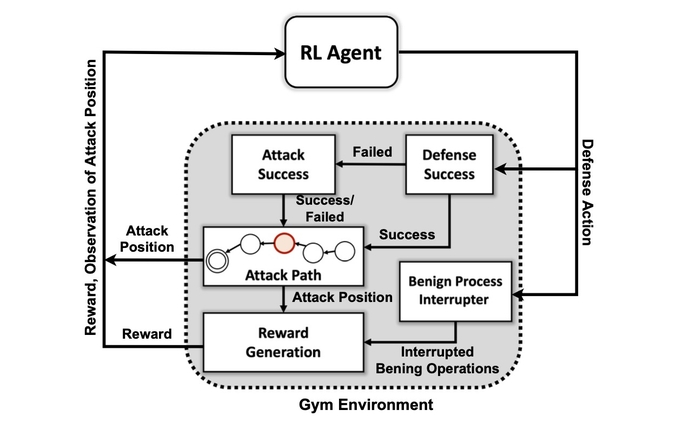
Ο πρώτος στόχος της ερευνητικής ομάδας ήταν να δημιουργήσει ένα προσαρμοσμένο περιβάλλον προσομοίωσης βασισμένο σε ένα κιτ εργαλείων ανοιχτού κώδικα γνωστό ως Ανοίξτε το AI Gym. Χρησιμοποιώντας αυτό το περιβάλλον, οι ερευνητές δημιούργησαν οντότητες επιτιθέμενων διαφορετικών επιπέδων δεξιοτήτων και επιμονής με τη δυνατότητα να χρησιμοποιούν ένα υποσύνολο 7 τακτικών και 15 τεχνικών από το πλαίσιο MITER ATT&CK.
Οι στόχοι των πρακτόρων επιτιθέμενων είναι να περάσουν στα επτά βήματα της αλυσίδας επίθεσης, από την αρχική πρόσβαση στην εκτέλεση, από την επιμονή στη διοίκηση και τον έλεγχο και από τη συλλογή στην πρόσκρουση.
Για τον επιτιθέμενο, η προσαρμογή της τακτικής του στην κατάσταση του περιβάλλοντος και στις τρέχουσες ενέργειες του αμυνόμενου μπορεί να είναι περίπλοκη, λέει ο Chatterjee του PNNL.
«Ο αντίπαλος πρέπει να πλοηγηθεί από την αρχική κατάσταση επανεξέτασης μέχρι κάποια κατάσταση διήθησης ή πρόσκρουσης», λέει. «Δεν προσπαθούμε να δημιουργήσουμε ένα είδος μοντέλου για να σταματήσουμε έναν αντίπαλο προτού εισέλθει στο περιβάλλον – υποθέτουμε ότι το σύστημα είναι ήδη σε κίνδυνο».
Οι ερευνητές χρησιμοποίησαν τέσσερις προσεγγίσεις στα νευρωνικά δίκτυα που βασίζονται στην ενισχυτική μάθηση. Η ενισχυτική μάθηση (RL) είναι μια προσέγγιση μηχανικής μάθησης που μιμείται το σύστημα ανταμοιβής του ανθρώπινου εγκεφάλου. Ένα νευρωνικό δίκτυο μαθαίνει ενισχύοντας ή αποδυναμώνοντας ορισμένες παραμέτρους για μεμονωμένους νευρώνες για να ανταμείψει καλύτερες λύσεις, όπως μετράται με μια βαθμολογία που δείχνει πόσο καλά αποδίδει το σύστημα.
Η ενισχυτική μάθηση επιτρέπει ουσιαστικά στον υπολογιστή να δημιουργήσει μια καλή, αλλά όχι τέλεια, προσέγγιση στο πρόβλημα που αντιμετωπίζει, λέει ο Mahantesh Halappanavar, ερευνητής PNNL και συγγραφέας της εργασίας.
«Χωρίς τη χρήση οποιασδήποτε ενισχυτικής μάθησης, θα μπορούσαμε να το κάνουμε, αλλά θα ήταν ένα πραγματικά μεγάλο πρόβλημα που δεν θα έχει αρκετό χρόνο για να καταλήξει σε κάποιον καλό μηχανισμό», λέει. «Η έρευνά μας… μας δίνει αυτόν τον μηχανισμό όπου η βαθιά ενισχυτική μάθηση μιμείται κάποια από την ίδια την ανθρώπινη συμπεριφορά, σε κάποιο βαθμό, και μπορεί να εξερευνήσει πολύ αποτελεσματικά αυτόν τον πολύ τεράστιο χώρο».
Δεν είναι έτοιμος για την Prime Time
Τα πειράματα διαπίστωσαν ότι μια συγκεκριμένη μέθοδος ενισχυτικής μάθησης, γνωστή ως Deep Q Network, δημιούργησε μια ισχυρή λύση στο αμυντικό πρόβλημα. πιάνοντας το 97% των επιτιθέμενων στο σύνολο δεδομένων δοκιμής. Ωστόσο, η έρευνα είναι μόνο η αρχή. Οι επαγγελματίες ασφάλειας δεν θα πρέπει να αναζητούν έναν σύντροφο τεχνητής νοημοσύνης για να τους βοηθήσει να ανταποκριθούν σε περιστατικά και εγκληματολογικές εξετάσεις σύντομα.
Μεταξύ των πολλών προβλημάτων που απομένουν να επιλυθούν είναι η ενίσχυση της μάθησης και τα βαθιά νευρωνικά δίκτυα για να εξηγήσουν τους παράγοντες που επηρέασαν τις αποφάσεις τους, ένας τομέας έρευνας που ονομάζεται εξηγήσιμη ενισχυτική μάθηση (XRL).
Επιπλέον, η ευρωστία των αλγορίθμων AI και η εύρεση αποτελεσματικών τρόπων εκπαίδευσης των νευρωνικών δικτύων είναι και τα δύο προβλήματα που πρέπει να επιλυθούν, λέει ο Chatterjee του PNNL.
"Η δημιουργία ενός προϊόντος - δεν ήταν αυτό το κύριο κίνητρο για αυτήν την έρευνα", λέει. «Αυτό αφορούσε περισσότερο τον επιστημονικό πειραματισμό και την αλγοριθμική ανακάλυψη».
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- ικανότητα
- ΠΛΗΡΟΦΟΡΙΕΣ
- ΠΕΡΙΛΗΨΗ
- πρόσβαση
- Σύμφωνα με
- ενεργειών
- πραγματικά
- Επιπλέον
- προαγωγή
- αντιφατική
- παράγοντες
- AI
- Τροφοδοτείται από AI
- αλγοριθμικός
- αλγόριθμοι
- Όλα
- επιτρέπει
- ήδη
- ανάλυση
- αναλύσει
- και
- ετήσιος
- Εφαρμογή
- πλησιάζω
- προσεγγίσεις
- ΠΕΡΙΟΧΗ
- τεχνητός
- τεχνητή νοημοσύνη
- Τεχνητή νοημοσύνη (AI)
- Σχέση
- επίθεση
- Επιθέσεις
- συγγραφέας
- αυτονόμος
- βασίζονται
- γίνονται
- πριν
- Καλύτερα
- μεταξύ
- Μεγάλος
- Αποκλεισμός
- Εγκέφαλος
- χτισμένο
- που ονομάζεται
- δεν μπορώ
- ικανός
- ορισμένες
- αλυσίδα
- ChatGPT
- ισχυρισμός
- ταξινόμηση
- συλλογή
- Ελάτε
- συγκρότημα
- Συμβιβασμένος
- υπολογιστή
- Διεξαγωγή
- σύγκρουση
- συνεχίζεται
- έλεγχος
- θα μπορούσε να
- δημιουργία
- δημιουργήθηκε
- δημιουργία
- Ρεύμα
- έθιμο
- στον κυβερνοχώρο
- cyberattacks
- Κυβερνασφάλεια
- ημερομηνία
- επιστήμονας δεδομένων
- σύνολο δεδομένων
- σύνολα δεδομένων
- dc
- δεκαετία
- απόφαση
- αποφάσεις
- βαθύς
- βαθιά νευρωνικά δίκτυα
- Υπερασπιστές
- Άμυνα
- αμυντικός
- αποδεικνύουν
- καταδεικνύει
- Τμήμα
- Υπουργείο Ενέργειας
- διαφορετικές
- ψηφιακό
- ανακάλυψη
- Αναστάτωση
- διάφορα
- DOE
- Νωρίς
- αποτελεσματικά
- αποτελεσματικός
- αποτελεσματικά
- προσπάθειες
- ΗΛΕΚΤΡΟΝΙΚΗ ΔΙΕΥΘΥΝΣΗ
- ασφάλεια ηλεκτρονικού ταχυδρομείου
- ενέργεια
- αρκετά
- οντότητες
- Περιβάλλον
- κατ 'ουσίαν,
- Αιθέρας (ΕΤΗ)
- αξιολογώντας
- Even
- εκτέλεση
- διήθηση
- Εξηγήστε
- διερευνήσει
- παράγοντες
- Χαρακτηριστικά
- λίγοι
- Πεδία
- εύρεση
- Όνομα
- ροή
- Δικανικός
- ιατροδικαστική
- Προς τα εμπρός
- Βρέθηκαν
- Πλαίσιο
- από
- μελλοντικός
- παίρνω
- να πάρει
- δίνει
- γκολ
- Στόχοι
- καλός
- χέρι
- βοήθεια
- ΚΑΥΤΌ
- Πως
- HTTPS
- ανθρώπινος
- Εμπόδια
- Επίπτωση
- σημαντικό
- in
- περιστατικό
- απάντηση περιστατικού
- υποδεικνύοντας
- ατομικές
- επηρεάζονται
- αρχικός
- ολοκλήρωση
- Νοημοσύνη
- IT
- εαυτό
- Είδος
- γνωστός
- εργαστήριο
- large
- μάθηση
- επίπεδα
- ματιά
- μηχανή
- μάθηση μηχανής
- Κυρίως
- πολοί
- max-width
- Αυξάνω στον ανώτατο βαθμό
- μηχανισμός
- συνάντηση
- μέθοδος
- ελαχιστοποιώντας
- μοντέλο
- περισσότερο
- Κινητοποίηση
- μετακινήσετε
- κίνηση
- πολλαπλούς
- εθνικός
- Πλοηγηθείτε
- Ανάγκη
- δίκτυο
- δίκτυα
- Νευρικός
- νευρικό σύστημα
- νευρωνικά δίκτυα
- Νευρώνες
- ανοίξτε
- ανοικτού κώδικα
- ΑΛΛΑ
- Ειρηνικός
- Χαρτί
- παράμετροι
- Το παρελθόν
- τέλειος
- εκτελεί
- επιμονή
- φάση
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- δυνατός
- τροφοδοτείται
- Πρακτικός
- παρουσιάζονται
- πρόληψη
- Ακμή
- Προληπτική
- Πρόβλημα
- προβλήματα
- Προϊόντα
- επαγγελματίες
- προφίλ
- υπόσχεση
- RE
- φθάσει
- Αντίδραση
- Αντιδρά
- έτοιμος
- πραγματικός
- σε πραγματικό χρόνο
- πρόσφατος
- ενίσχυση μάθησης
- παραμένουν
- έρευνα
- ερευνητής
- ερευνητές
- απάντησης
- Ανταμοιβή
- Ανταμοιβές
- ευρωστία
- λέει
- Επιστήμονας
- ασφάλεια
- Σειρές
- σειρά
- ρυθμίσεις
- επτά
- θα πρέπει να
- δείχνουν
- Δείχνει
- απλοποιημένη
- προσομοίωση
- επιδεξιότητα
- λύση
- Λύσεις
- μερικοί
- Σύντομα
- Πηγή
- Χώρος
- συγκεκριμένες
- Εκκίνηση
- Κατάσταση
- Βήμα
- Βήματα
- Ακόμη
- στάση
- ενίσχυση
- ισχυρός
- επιτυχής
- Επιτυχώς
- σύστημα
- τακτική
- τεχνικές
- Δοκιμές
- Η
- Το μέλλον
- Το κράτος
- τους
- Μέσω
- ώρα
- προς την
- εργαλειοθήκη
- προς
- Τρένο
- εκπαιδευμένο
- Εκπαίδευση
- τάση
- υπό
- us
- χρήση
- ποικιλία
- Σταθερή
- ήθελε
- Ουάσιγκτον
- τρόπους
- ενώ
- Ο ΟΠΟΊΟΣ
- θα
- εντός
- χωρίς
- Εργασία
- θα
- αποδίδοντας
- zephyrnet











