By Ντέιβιντ Γουέντ και Γκρέγκορι Κίμπολ
Η αποτελεσματική επεξεργασία δεδομένων συμβολοσειρών είναι ζωτικής σημασίας για πολλές εφαρμογές επιστήμης δεδομένων. Για να εξαγάγετε πολύτιμες πληροφορίες από δεδομένα συμβολοσειράς, RAPIDS libcudf παρέχει ισχυρά εργαλεία για την επιτάχυνση των μετασχηματισμών δεδομένων συμβολοσειρών. Το libcudf είναι μια βιβλιοθήκη C++ GPU DataFrame που χρησιμοποιείται για τη φόρτωση, τη σύνδεση, τη συγκέντρωση και το φιλτράρισμα δεδομένων.
Στην επιστήμη δεδομένων, τα δεδομένα συμβολοσειρών αντιπροσωπεύουν ομιλία, κείμενο, γενετικές ακολουθίες, καταγραφή και πολλούς άλλους τύπους πληροφοριών. Όταν εργάζεστε με δεδομένα συμβολοσειρών για μηχανική εκμάθηση και μηχανική χαρακτηριστικών, τα δεδομένα πρέπει συχνά να κανονικοποιούνται και να μετασχηματίζονται πριν να εφαρμοστούν σε συγκεκριμένες περιπτώσεις χρήσης. Το libcudf παρέχει τόσο API γενικού σκοπού όσο και βοηθητικά προγράμματα στην πλευρά της συσκευής για την ενεργοποίηση ενός ευρέος φάσματος λειτουργιών προσαρμοσμένων συμβολοσειρών.
Αυτή η ανάρτηση δείχνει πώς να μετασχηματίσετε επιδέξια στήλες συμβολοσειρών με το API γενικού σκοπού libcudf. Θα αποκτήσετε νέες γνώσεις για το πώς να ξεκλειδώσετε την κορυφαία απόδοση χρησιμοποιώντας προσαρμοσμένους πυρήνες και βοηθητικά προγράμματα libcudf στην πλευρά της συσκευής. Αυτή η ανάρτηση σας καθοδηγεί επίσης σε παραδείγματα για το πώς μπορείτε να διαχειριστείτε καλύτερα τη μνήμη GPU και να δημιουργήσετε αποτελεσματικά στήλες libcudf για να επιταχύνετε τους μετασχηματισμούς συμβολοσειρών σας.
Το libcudf αποθηκεύει δεδομένα συμβολοσειράς στη μνήμη της συσκευής χρησιμοποιώντας Μορφή βέλους, το οποίο αντιπροσωπεύει τις στήλες συμβολοσειρών ως δύο θυγατρικές στήλες: chars and offsets (Σχήμα 1).
Η chars Η στήλη διατηρεί τα δεδομένα συμβολοσειράς ως byte χαρακτήρων με κωδικοποίηση UTF-8 που αποθηκεύονται συνεχόμενα στη μνήμη.
Η offsets Η στήλη περιέχει μια αυξανόμενη ακολουθία ακεραίων που είναι θέσεις byte που προσδιορίζουν την αρχή κάθε μεμονωμένης συμβολοσειράς μέσα στον πίνακα δεδομένων χαρακτήρων. Το τελικό στοιχείο μετατόπισης είναι ο συνολικός αριθμός των byte στη στήλη χαρακτήρες. Αυτό σημαίνει το μέγεθος μιας μεμονωμένης συμβολοσειράς στη σειρά i ορίζεται ως (offsets[i+1]-offsets[i]).
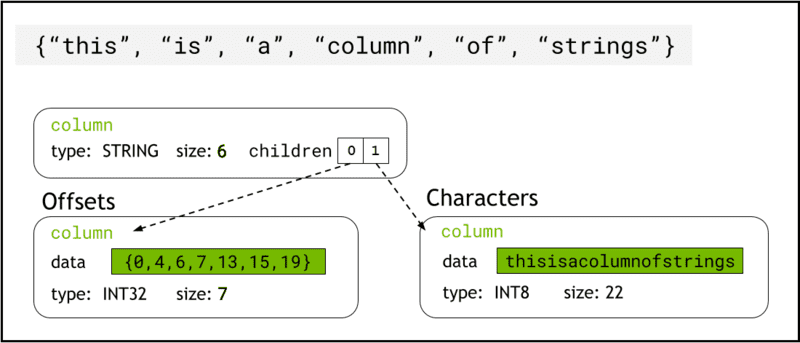 Εικόνα 1. Σχηματικό που δείχνει πώς η μορφή Arrow αντιπροσωπεύει τις στήλες συμβολοσειρών με
Εικόνα 1. Σχηματικό που δείχνει πώς η μορφή Arrow αντιπροσωπεύει τις στήλες συμβολοσειρών με chars και offsets παιδικές στήλες
Για να επεξηγήσετε ένα παράδειγμα μετασχηματισμού συμβολοσειράς, θεωρήστε μια συνάρτηση που λαμβάνει δύο στήλες συμβολοσειρών εισόδου και παράγει μια στήλη συμβολοσειρών εξόδου που έχει ανανεωθεί.
Τα δεδομένα εισαγωγής έχουν την ακόλουθη μορφή: μια στήλη "ονόματα" που περιέχει ονόματα και επώνυμα διαχωρισμένα με κενό και μια στήλη "ορατότητες" που περιέχει την κατάσταση "δημόσιο" ή "ιδιωτικό".
Προτείνουμε τη συνάρτηση "redact" που λειτουργεί στα δεδομένα εισόδου για την παραγωγή δεδομένων εξόδου που αποτελούνται από το πρώτο αρχικό του επωνύμου ακολουθούμενο από ένα κενό και ολόκληρο το όνομα. Ωστόσο, εάν η αντίστοιχη στήλη ορατότητας είναι "ιδιωτική", τότε η συμβολοσειρά εξόδου θα πρέπει να διορθωθεί πλήρως ως "X X".
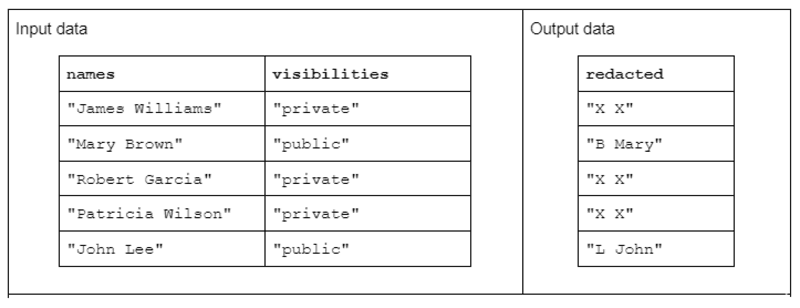 Πίνακας 1. Παράδειγμα μετασχηματισμού συμβολοσειράς "redact" που λαμβάνει ονόματα και ορατές στήλες συμβολοσειρών ως είσοδο και μερικώς ή πλήρως αναθεωρημένα δεδομένα ως έξοδο
Πίνακας 1. Παράδειγμα μετασχηματισμού συμβολοσειράς "redact" που λαμβάνει ονόματα και ορατές στήλες συμβολοσειρών ως είσοδο και μερικώς ή πλήρως αναθεωρημένα δεδομένα ως έξοδο
Πρώτον, ο μετασχηματισμός συμβολοσειράς μπορεί να επιτευχθεί χρησιμοποιώντας το libcudf strings API. Το API γενικού σκοπού είναι ένα εξαιρετικό σημείο εκκίνησης και μια καλή βάση για τη σύγκριση της απόδοσης.
Οι συναρτήσεις API λειτουργούν σε μια ολόκληρη στήλη συμβολοσειρών, εκκινώντας τουλάχιστον έναν πυρήνα ανά συνάρτηση και εκχωρώντας ένα νήμα ανά συμβολοσειρά. Κάθε νήμα χειρίζεται μια μεμονωμένη σειρά δεδομένων παράλληλα κατά μήκος της GPU και εξάγει μια μόνο γραμμή ως μέρος μιας νέας στήλης εξόδου.
Για να ολοκληρώσετε τη συνάρτηση παραδείγματος διόρθωσης χρησιμοποιώντας το API γενικής χρήσης, ακολουθήστε τα εξής βήματα:
- Μετατρέψτε τη στήλη συμβολοσειρών "ορατότητες" σε στήλη Boolean χρησιμοποιώντας
contains - Δημιουργήστε μια νέα στήλη συμβολοσειρών από τη στήλη ονομάτων αντιγράφοντας το "XX" όποτε η αντίστοιχη καταχώρηση γραμμής στη στήλη boolean είναι "false"
- Διαχωρίστε τη στήλη "readacted" σε στήλες ονόματος και επωνύμου
- Κόψτε τον πρώτο χαρακτήρα των επωνύμων ως αρχικά των επωνύμων
- Δημιουργήστε τη στήλη εξόδου συνενώνοντας τη στήλη των τελευταίων αρχικών και τη στήλη των ονομάτων με διαχωριστικό κενό (” “).
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Αυτή η προσέγγιση διαρκεί περίπου 3.5 ms σε ένα A6000 με 600K σειρές δεδομένων. Αυτό το παράδειγμα χρησιμοποιεί contains, copy_if_else, split, slice_strings και concatenate για να ολοκληρώσετε έναν προσαρμοσμένο μετασχηματισμό συμβολοσειράς. Μια ανάλυση προφίλ με Συστήματα Nsight δείχνει ότι η split η λειτουργία διαρκεί το μεγαλύτερο χρονικό διάστημα, ακολουθούμενη από slice_strings και concatenate.
Το Σχήμα 2 δείχνει δεδομένα δημιουργίας προφίλ από τα συστήματα Nsight του παραδείγματος redact, που δείχνει την επεξεργασία συμβολοσειρών από άκρο σε άκρο με έως και ~600 εκατομμύρια στοιχεία ανά δευτερόλεπτο. Οι περιοχές αντιστοιχούν σε περιοχές NVTX που σχετίζονται με κάθε λειτουργία. Οι περιοχές ανοιχτό μπλε αντιστοιχούν σε περιόδους όπου εκτελούνται οι πυρήνες CUDA.
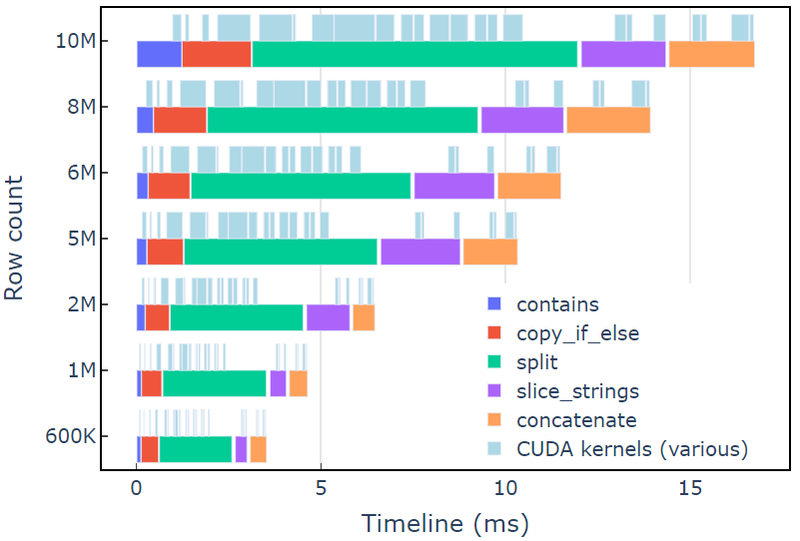 Εικόνα 2. Προφίλ δεδομένων από τα συστήματα Nsight του παραδείγματος redact
Εικόνα 2. Προφίλ δεδομένων από τα συστήματα Nsight του παραδείγματος redact
Το API συμβολοσειρών libcudf είναι μια γρήγορη και αποτελεσματική εργαλειοθήκη για μετασχηματισμό συμβολοσειρών, αλλά μερικές φορές οι κρίσιμες για την απόδοση συναρτήσεις πρέπει να εκτελούνται ακόμη πιο γρήγορα. Μια βασική πηγή πρόσθετης εργασίας στο API συμβολοσειρών libcudf είναι η δημιουργία τουλάχιστον μιας νέας στήλης συμβολοσειρών στην καθολική μνήμη συσκευής για κάθε κλήση API, ανοίγοντας την ευκαιρία να συνδυαστούν πολλές κλήσεις API σε έναν προσαρμοσμένο πυρήνα.
Περιορισμοί απόδοσης σε κλήσεις πυρήνα malloc
Αρχικά, θα δημιουργήσουμε έναν προσαρμοσμένο πυρήνα για να εφαρμόσουμε τον μετασχηματισμό του παραδείγματος redact. Όταν σχεδιάζουμε αυτόν τον πυρήνα, πρέπει να έχουμε κατά νου ότι οι στήλες συμβολοσειρών libcudf είναι αμετάβλητες.
Οι στήλες συμβολοσειρών δεν μπορούν να αλλάξουν στη θέση τους, επειδή τα byte χαρακτήρων αποθηκεύονται συνεχόμενα και τυχόν αλλαγές στο μήκος μιας συμβολοσειράς θα ακύρωναν τα δεδομένα μετατόπισης. Επομένως, ο redact_kernel Ο προσαρμοσμένος πυρήνας δημιουργεί μια νέα στήλη συμβολοσειρών χρησιμοποιώντας ένα εργοστάσιο στηλών libcudf για τη δημιουργία και των δύο offsets και chars παιδικές στήλες.
Σε αυτήν την πρώτη προσέγγιση, δημιουργείται η συμβολοσειρά εξόδου για κάθε σειρά δυναμική μνήμη συσκευής χρησιμοποιώντας μια κλήση malloc μέσα στον πυρήνα. Η προσαρμοσμένη έξοδος πυρήνα είναι ένα διάνυσμα δεικτών συσκευής σε κάθε έξοδο γραμμής και αυτό το διάνυσμα χρησιμεύει ως είσοδος σε ένα εργοστάσιο στηλών συμβολοσειρών.
Ο προσαρμοσμένος πυρήνας δέχεται α cudf::column_device_view για πρόσβαση στα δεδομένα της στήλης συμβολοσειρών και χρησιμοποιεί το element μέθοδος επιστροφής α cudf::string_view που αντιπροσωπεύει τα δεδομένα συμβολοσειράς στο καθορισμένο ευρετήριο σειράς. Η έξοδος του πυρήνα είναι ένα διάνυσμα τύπου cudf::string_view που κρατά δείκτες στη μνήμη της συσκευής που περιέχει τη συμβολοσειρά εξόδου και το μέγεθος αυτής της συμβολοσειράς σε byte.
Η cudf::string_view Η κλάση είναι παρόμοια με την κλάση std::string_view, αλλά υλοποιείται ειδικά για το libcudf και αναδιπλώνει ένα σταθερό μήκος δεδομένων χαρακτήρων στη μνήμη της συσκευής που κωδικοποιείται ως UTF-8. Έχει πολλά από τα ίδια χαρακτηριστικά (find και substr λειτουργίες, για παράδειγμα) και περιορισμούς (χωρίς μηδενικό τερματιστή) όπως το std αντίστοιχος. ΕΝΑ cudf::string_view αντιπροσωπεύει μια ακολουθία χαρακτήρων που είναι αποθηκευμένη στη μνήμη της συσκευής και έτσι μπορούμε να τη χρησιμοποιήσουμε εδώ για να καταγράψουμε τη μνήμη malloc'd για ένα διάνυσμα εξόδου.
Πυρήνας Malloc
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Αυτό μπορεί να φαίνεται σαν μια λογική προσέγγιση, μέχρι να μετρηθεί η απόδοση του πυρήνα. Αυτή η προσέγγιση διαρκεί περίπου 108 ms σε ένα A6000 με 600K σειρές δεδομένων—περισσότερο από 30 φορές πιο αργά από τη λύση που παρέχεται παραπάνω χρησιμοποιώντας το API συμβολοσειρών libcudf.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Το κύριο σημείο συμφόρησης είναι το malloc/free κλήσεις μέσα στους δύο πυρήνες εδώ. Απαιτείται η δυναμική μνήμη συσκευής CUDA malloc/free καλεί έναν πυρήνα να συγχρονιστεί, με αποτέλεσμα η παράλληλη εκτέλεση να εκφυλιστεί σε διαδοχική εκτέλεση.
Προκατανομή μνήμης εργασίας για την εξάλειψη των σημείων συμφόρησης
Εξαλείψτε το malloc/free συμφόρηση αντικαθιστώντας το malloc/free καλεί στον πυρήνα με εκ των προτέρων εκχωρημένη μνήμη εργασίας πριν από την εκκίνηση του πυρήνα.
Για το παράδειγμα redact, το μέγεθος εξόδου κάθε συμβολοσειράς σε αυτό το παράδειγμα δεν πρέπει να είναι μεγαλύτερο από την ίδια τη συμβολοσειρά εισόδου, καθώς η λογική αφαιρεί μόνο χαρακτήρες. Επομένως, μπορεί να χρησιμοποιηθεί ένα buffer μνήμης μιας συσκευής με το ίδιο μέγεθος με το buffer εισόδου. Χρησιμοποιήστε τις μετατοπίσεις εισόδου για να εντοπίσετε τη θέση κάθε σειράς.
Η πρόσβαση στις μετατοπίσεις της στήλης συμβολοσειρών περιλαμβάνει το τύλιγμα του cudf::column_view με cudf::strings_column_view και καλώντας του offsets_begin μέθοδος. Το μέγεθος του chars Η θυγατρική στήλη μπορεί επίσης να προσπελαστεί χρησιμοποιώντας το chars_size μέθοδος. Μετά ένα rmm::device_uvector εκχωρείται εκ των προτέρων πριν καλέσετε τον πυρήνα για να αποθηκεύσετε τα δεδομένα εξόδου χαρακτήρων.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Προκατανεμημένος πυρήνας
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Ο πυρήνας βγάζει ένα διάνυσμα του cudf::string_view αντικείμενα τα οποία περνούν στο cudf::make_strings_column εργοστασιακή λειτουργία. Η δεύτερη παράμετρος αυτής της συνάρτησης χρησιμοποιείται για τον εντοπισμό μηδενικών καταχωρήσεων στη στήλη εξόδου. Τα παραδείγματα σε αυτήν την ανάρτηση δεν έχουν μηδενικές καταχωρήσεις, επομένως ένα σύμβολο κράτησης θέσης nullptr cudf::string_view{nullptr,0} χρησιμοποιείται.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Αυτή η προσέγγιση διαρκεί περίπου 1.1 ms σε ένα A6000 με 600K σειρές δεδομένων και επομένως ξεπερνά τη γραμμή βάσης κατά περισσότερο από 2 φορές. Η κατά προσέγγιση ανάλυση φαίνεται παρακάτω:
redact_kernel 66us make_strings_column 400us
Ο χρόνος που απομένει ξοδεύεται σε cudaMalloc, cudaFree, cudaMemcpy, που είναι τυπικό των γενικών εξόδων για τη διαχείριση προσωρινών περιπτώσεων rmm::device_uvector. Αυτή η μέθοδος λειτουργεί καλά εάν όλες οι συμβολοσειρές εξόδου είναι εγγυημένο ότι έχουν το ίδιο μέγεθος ή μικρότερο με τις συμβολοσειρές εισόδου.
Συνολικά, η μετάβαση σε μαζική κατανομή μνήμης εργασίας με το RAPIDS RMM είναι μια σημαντική βελτίωση και μια καλή λύση για μια προσαρμοσμένη λειτουργία συμβολοσειρών.
Βελτιστοποίηση δημιουργίας στηλών για ταχύτερους χρόνους υπολογισμού
Υπάρχει τρόπος να βελτιωθεί αυτό ακόμη περισσότερο; Το σημείο συμφόρησης είναι πλέον το cudf::make_strings_column εργοστασιακή συνάρτηση που δημιουργεί τα δύο στοιχεία στήλης χορδών, offsets και chars, από το διάνυσμα του cudf::string_view αντικείμενα.
Στο libcudf, περιλαμβάνονται πολλές εργοστασιακές συναρτήσεις για την κατασκευή στηλών συμβολοσειρών. Η εργοστασιακή συνάρτηση που χρησιμοποιήθηκε στα προηγούμενα παραδείγματα παίρνει α cudf::device_span of cudf::string_view αντικείμενα και στη συνέχεια κατασκευάζει τη στήλη εκτελώντας α gather στα υποκείμενα δεδομένα χαρακτήρων για τη δημιουργία των στηλών μετατόπισης και θυγατρικών χαρακτήρων. ΕΝΑ rmm::device_uvector μετατρέπεται αυτόματα σε α cudf::device_span χωρίς αντιγραφή δεδομένων.
Ωστόσο, εάν το διάνυσμα των χαρακτήρων και το διάνυσμα των μετατοπίσεων δημιουργηθούν απευθείας, τότε μπορεί να χρησιμοποιηθεί μια διαφορετική εργοστασιακή συνάρτηση, η οποία απλώς δημιουργεί τη στήλη συμβολοσειρών χωρίς να απαιτείται συλλογή για την αντιγραφή των δεδομένων.
Η sizes_kernel κάνει ένα πρώτο πέρασμα πάνω από τα δεδομένα εισόδου για να υπολογίσει το ακριβές μέγεθος εξόδου κάθε σειράς εξόδου:
Βελτιστοποιημένος πυρήνας: Μέρος 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Τα μεγέθη εξόδου μετατρέπονται στη συνέχεια σε μετατοπίσεις εκτελώντας μια επιτόπια exclusive_scan. Σημειώστε ότι το offsets διάνυσμα δημιουργήθηκε με names.size()+1 στοιχεία. Η τελευταία καταχώρηση θα είναι ο συνολικός αριθμός των byte (όλα τα μεγέθη αθροισμένα μαζί) ενώ η πρώτη καταχώρηση θα είναι 0. Και τα δύο χειρίζονται από το exclusive_scan κλήση. Το μέγεθος του chars η στήλη ανακτάται από την τελευταία καταχώρηση του offsets στήλη για τη δημιουργία του διανύσματος χαρακτήρων.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
Η redact_kernel Η λογική εξακολουθεί να είναι πολύ ίδια εκτός από το ότι δέχεται την έξοδο d_offsets διάνυσμα για την επίλυση της θέσης εξόδου κάθε σειράς:
Βελτιστοποιημένος πυρήνας: Μέρος 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
Το μέγεθος της εξόδου d_chars η στήλη ανακτάται από την τελευταία καταχώρηση του d_offsets στήλη για να εκχωρήσετε το διάνυσμα χαρακτήρων. Ο πυρήνας ξεκινά με το προ-υπολογισμένο διάνυσμα μετατόπισης και επιστρέφει το διάνυσμα συμπληρωμένων χαρακτήρων. Τέλος, το εργοστάσιο στηλών συμβολοσειρών libcudf δημιουργεί τις στήλες συμβολοσειρών εξόδου.
Αυτός ο διαλογισμός στα cudf::make_strings_column Η εργοστασιακή συνάρτηση δημιουργεί τη στήλη συμβολοσειρών χωρίς να δημιουργεί αντίγραφο των δεδομένων. ο offsets δεδομένα και chars Τα δεδομένα είναι ήδη στη σωστή, αναμενόμενη μορφή και αυτό το εργοστάσιο απλώς μετακινεί τα δεδομένα από κάθε διάνυσμα και δημιουργεί τη δομή στήλης γύρω από αυτό. Μόλις ολοκληρωθεί, το rmm::device_uvectors for offsets και chars είναι κενά, τα δεδομένα τους έχουν μετακινηθεί στη στήλη εξόδου.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Αυτή η προσέγγιση απαιτεί περίπου 300 us (0.3 ms) σε ένα A6000 με 600K σειρές δεδομένων και βελτιώνεται σε σχέση με την προηγούμενη προσέγγιση κατά περισσότερο από 2 φορές. Μπορεί να το παρατηρήσετε sizes_kernel και redact_kernel μοιράζονται πολλά από την ίδια λογική: μια φορά για να μετρήσετε το μέγεθος της εξόδου και μετά ξανά για να συμπληρώσετε την έξοδο.
Από την άποψη της ποιότητας του κώδικα, είναι ωφέλιμο να αναπαραχθεί ο μετασχηματισμός ως συνάρτηση συσκευής που καλείται τόσο από τα μεγέθη όσο και από τους πυρήνες. Από την άποψη της απόδοσης, μπορεί να εκπλαγείτε βλέποντας το υπολογιστικό κόστος του μετασχηματισμού να πληρώνεται δύο φορές.
Τα οφέλη για τη διαχείριση της μνήμης και την αποτελεσματικότερη δημιουργία στηλών συχνά υπερτερούν του υπολογιστικού κόστους της διπλής εκτέλεσης του μετασχηματισμού.
Ο Πίνακας 2 δείχνει τον υπολογιστικό χρόνο, τον αριθμό πυρήνων και τα byte που υποβλήθηκαν σε επεξεργασία για τις τέσσερις λύσεις που συζητούνται σε αυτήν την ανάρτηση. Το "Σύνολο εκκινήσεων πυρήνα" αντικατοπτρίζει τον συνολικό αριθμό των πυρήνων που εκτοξεύτηκαν, συμπεριλαμβανομένων των πυρήνων υπολογισμού και βοηθητικού πυρήνα. Το "Σύνολο επεξεργασμένων byte" είναι η αθροιστική απόδοση ανάγνωσης και εγγραφής DRAM και η "ελάχιστη επεξεργασία byte" είναι κατά μέσο όρο 37.9 byte ανά σειρά για τις δοκιμαστικές εισόδους και εξόδους μας. Η ιδανική περίπτωση «περιορισμένου εύρους ζώνης μνήμης» προϋποθέτει εύρος ζώνης 768 GB/s, τη θεωρητική μέγιστη απόδοση του A6000.
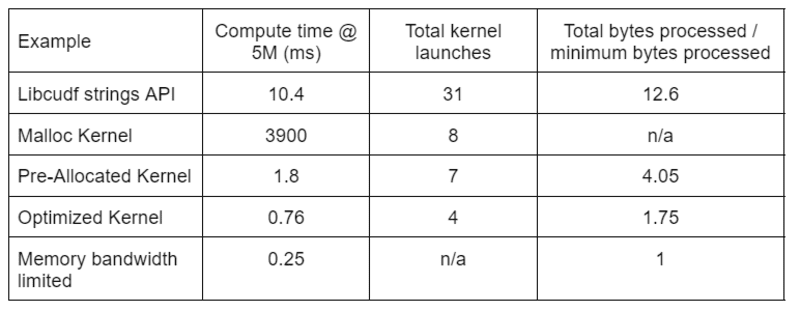 Πίνακας 2. Υπολογίστε τον χρόνο, τον αριθμό πυρήνων και τα byte που υποβλήθηκαν σε επεξεργασία για τις τέσσερις λύσεις που συζητούνται σε αυτήν την ανάρτηση
Πίνακας 2. Υπολογίστε τον χρόνο, τον αριθμό πυρήνων και τα byte που υποβλήθηκαν σε επεξεργασία για τις τέσσερις λύσεις που συζητούνται σε αυτήν την ανάρτηση
Ο "Βελτιστοποιημένος πυρήνας" παρέχει την υψηλότερη απόδοση λόγω του μειωμένου αριθμού εκκινήσεων του πυρήνα και των λιγότερων συνολικών byte που υποβάλλονται σε επεξεργασία. Με αποτελεσματικούς προσαρμοσμένους πυρήνες, οι συνολικές εκκινήσεις του πυρήνα πέφτουν από 31 σε 4 και τα συνολικά byte που υποβάλλονται σε επεξεργασία από 12.6x σε 1.75x του μεγέθους εισόδου συν εξόδου.
Ως αποτέλεσμα, ο προσαρμοσμένος πυρήνας επιτυγχάνει >10x υψηλότερη απόδοση από το API συμβολοσειρών γενικού σκοπού για τον μετασχηματισμό redact.
Ο πόρος μνήμης πισίνας σε Διαχείριση μνήμης RAPIDS (RMM) είναι ένα άλλο εργαλείο που μπορείτε να χρησιμοποιήσετε για να αυξήσετε την απόδοση. Τα παραπάνω παραδείγματα χρησιμοποιούν τον προεπιλεγμένο "πόρο μνήμης CUDA" για την κατανομή και την απελευθέρωση της παγκόσμιας μνήμης της συσκευής. Ωστόσο, ο χρόνος που απαιτείται για την κατανομή της μνήμης εργασίας προσθέτει σημαντική καθυστέρηση μεταξύ των βημάτων των μετασχηματισμών συμβολοσειράς. Ο "πόρος μνήμης συγκέντρωσης" στο RMM μειώνει τον λανθάνοντα χρόνο εκχωρώντας ένα μεγάλο απόθεμα μνήμης εκ των προτέρων και εκχωρώντας δευτερεύουσες εκχωρήσεις όπως απαιτείται κατά την επεξεργασία.
Με τον πόρο μνήμης CUDA, ο "Βελτιστοποιημένος πυρήνας" εμφανίζει μια επιτάχυνση 10x-15x που αρχίζει να μειώνεται σε υψηλότερες μετρήσεις σειρών λόγω του αυξανόμενου μεγέθους κατανομής (Εικόνα 3). Η χρήση του πόρου μνήμης πισίνας μετριάζει αυτό το αποτέλεσμα και διατηρεί επιταχύνσεις 15x-25x στην προσέγγιση API συμβολοσειρών libcudf.
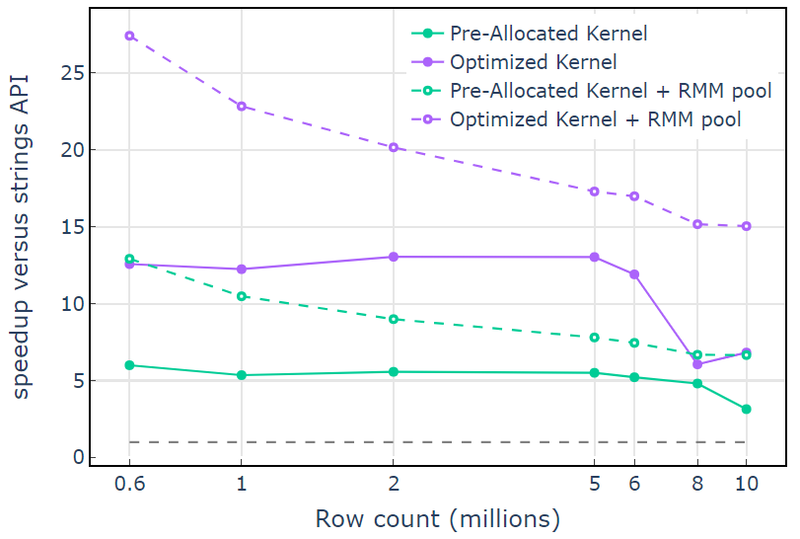 Εικόνα 3. Επιτάχυνση από τους προσαρμοσμένους πυρήνες "Προκατανεμημένος πυρήνας" και "Βελτιστοποιημένος πυρήνας" με τον προεπιλεγμένο πόρο μνήμης CUDA (συμπαγής) και τον πόρο μνήμης ομάδας (διακεκομμένη), έναντι του API συμβολοσειράς libcudf που χρησιμοποιεί τον προεπιλεγμένο πόρο μνήμης CUDA
Εικόνα 3. Επιτάχυνση από τους προσαρμοσμένους πυρήνες "Προκατανεμημένος πυρήνας" και "Βελτιστοποιημένος πυρήνας" με τον προεπιλεγμένο πόρο μνήμης CUDA (συμπαγής) και τον πόρο μνήμης ομάδας (διακεκομμένη), έναντι του API συμβολοσειράς libcudf που χρησιμοποιεί τον προεπιλεγμένο πόρο μνήμης CUDA
Με τον πόρο μνήμης δεξαμενής, αποδεικνύεται μια διεκπεραίωση μνήμης από άκρο σε άκρο που πλησιάζει το θεωρητικό όριο για έναν αλγόριθμο δύο περασμάτων. Ο «Βελτιστοποιημένος πυρήνας» φτάνει τα 320-340 GB/s, μετρούμενη χρησιμοποιώντας το μέγεθος των εισόδων συν το μέγεθος των εξόδων και τον υπολογιστικό χρόνο (Εικόνα 4).
Η προσέγγιση δύο περασμάτων μετρά πρώτα τα μεγέθη των στοιχείων εξόδου, εκχωρεί μνήμη και στη συνέχεια ορίζει τη μνήμη με τις εξόδους. Με δεδομένο έναν αλγόριθμο επεξεργασίας δύο περασμάτων, η υλοποίηση στον "Βελτιστοποιημένο πυρήνα" αποδίδει κοντά στο όριο εύρους ζώνης μνήμης. Η "Διακίνηση μνήμης από άκρο σε άκρο" ορίζεται ως το μέγεθος εισόδου συν εξόδου σε GB διαιρεμένο με τον υπολογιστικό χρόνο. *Εύρος ζώνης μνήμης RTX A6000 (768 GB/s).
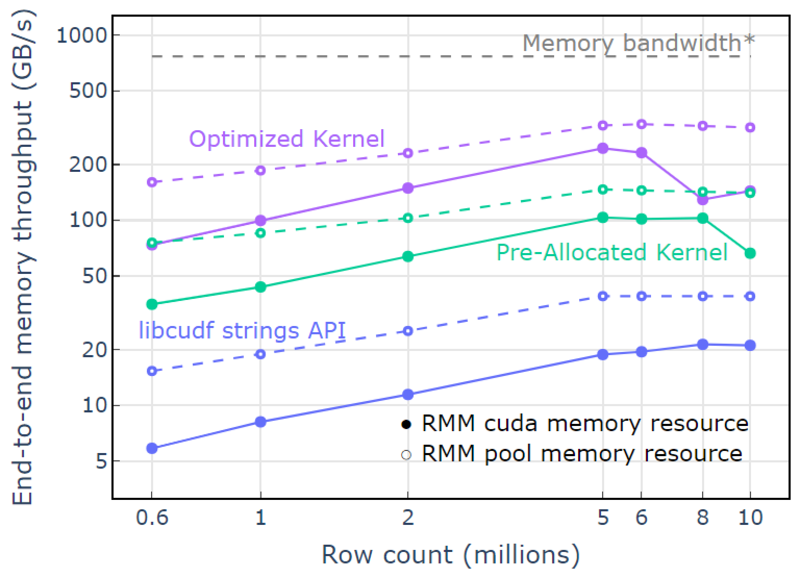 Εικόνα 4. Διακίνηση μνήμης για "Βελτιστοποιημένος πυρήνας", "Προκατανεμημένος πυρήνας" και "ΑΡΙ συμβολοσειρών libcudf" ως συνάρτηση του αριθμού σειρών εισόδου/εξόδου
Εικόνα 4. Διακίνηση μνήμης για "Βελτιστοποιημένος πυρήνας", "Προκατανεμημένος πυρήνας" και "ΑΡΙ συμβολοσειρών libcudf" ως συνάρτηση του αριθμού σειρών εισόδου/εξόδου
Αυτή η ανάρτηση παρουσιάζει δύο προσεγγίσεις για τη σύνταξη αποτελεσματικών μετασχηματισμών δεδομένων συμβολοσειρών στο libcudf. Το API γενικού σκοπού libcudf είναι γρήγορο και απλό για προγραμματιστές και προσφέρει καλή απόδοση. Το libcudf παρέχει επίσης βοηθητικά προγράμματα στην πλευρά της συσκευής που έχουν σχεδιαστεί για χρήση με προσαρμοσμένους πυρήνες, σε αυτό το παράδειγμα ξεκλειδώνοντας >10 φορές ταχύτερη απόδοση.
Εφαρμόστε τις γνώσεις σας
Για να ξεκινήσετε με το RAPIDS cuDF, επισκεφτείτε το rapidsai/cudf Αποθετήριο GitHub. Εάν δεν έχετε δοκιμάσει ακόμη τα cuDF και libcudf για τους φόρτους εργασίας επεξεργασίας συμβολοσειρών, σας συνιστούμε να δοκιμάσετε την πιο πρόσφατη έκδοση. Δοχεία υποδοχής παρέχονται για εκδόσεις καθώς και για νυχτερινές κατασκευές. Πακέτα Conda είναι επίσης διαθέσιμα για να διευκολύνουν τη δοκιμή και την ανάπτυξη. Εάν χρησιμοποιείτε ήδη cuDF, σας συνιστούμε να εκτελέσετε το νέο παράδειγμα μετασχηματισμού συμβολοσειρών μεταβαίνοντας στο rapidsai/cudf/tree/HEAD/cpp/παραδείγματα/χορδές στο GitHub.
Ντέιβιντ Γουέντ είναι ανώτερος μηχανικός λογισμικού συστημάτων στην NVIDIA που αναπτύσσει κώδικα C++/CUDA για το RAPIDS. Ο Ντέιβιντ είναι κάτοχος μεταπτυχιακού τίτλου στον ηλεκτρολόγο μηχανικό από το Πανεπιστήμιο Johns Hopkins.
Γκρέγκορι Κίμπολ είναι διευθυντής μηχανικής λογισμικού στην NVIDIA που εργάζεται στην ομάδα RAPIDS. Ο Gregory ηγείται της ανάπτυξης για το libcudf, τη βιβλιοθήκη CUDA/C++ για επεξεργασία στηλών δεδομένων που τροφοδοτεί το RAPIDS cuDF. Ο Γρηγόρης είναι κάτοχος διδακτορικού στην εφαρμοσμένη φυσική από το Ινστιτούτο Τεχνολογίας της Καλιφόρνια.
Πρωτότυπο. Αναδημοσιεύτηκε με άδεια.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- Σχετικά
- πάνω από
- επιταχύνοντας
- Αποδέχεται
- πρόσβαση
- πρόσβαση
- επιτυγχάνεται
- απέναντι
- προστιθέμενη
- Προσθέτει
- αλγόριθμος
- Όλα
- κατανέμει
- κατανομή
- ήδη
- ποσό
- ανάλυση
- και
- Άλλος
- Apache
- api
- APIs
- εφαρμογές
- εφαρμοσμένος
- πλησιάζω
- προσεγγίσεις
- προσεγγίζοντας
- γύρω
- Παράταξη
- συσχετισμένη
- αυτόματη
- αυτομάτως
- διαθέσιμος
- μέσος
- εύρος ζώνης
- Baseline
- επειδή
- πριν
- είναι
- παρακάτω
- ευεργετική
- οφέλη
- ΚΑΛΎΤΕΡΟΣ
- μεταξύ
- Μπλε
- Ανάλυση
- ρυθμιστικό
- χτίζω
- Κτίριο
- Χτίζει
- χτισμένο
- C + +
- Καλιφόρνια
- κλήση
- που ονομάζεται
- κλήση
- κλήσεις
- δεν μπορώ
- περίπτωση
- περιπτώσεις
- προκαλώντας
- Αλλαγές
- χαρακτήρας
- χαρακτήρες
- παιδί
- τάξη
- Κλεισιμο
- κωδικός
- Στήλη
- Στήλες
- συνδυασμός
- συγκρίνοντας
- πλήρης
- Ολοκληρώθηκε το
- εξαρτήματα
- υπολογισμός
- Υπολογίστε
- Εξετάστε
- Αποτελείται από
- κατασκευάσει
- Περιέχει
- μετατρέψετε
- μετατρέπονται
- αντιγραφή
- Αντίστοιχος
- Κόστος
- δημιουργία
- δημιουργήθηκε
- δημιουργεί
- δημιουργία
- έθιμο
- ημερομηνία
- επεξεργασία δεδομένων
- επιστημονικά δεδομένα
- Δαβίδ
- Προεπιλογή
- Πτυχίο
- παραδίδει
- κατέδειξε
- ανάπτυξη
- σχεδιασμένα
- σχέδιο
- προγραμματιστές
- ανάπτυξη
- Ανάπτυξη
- συσκευή
- διαφορετικές
- κατευθείαν
- συζήτηση
- διαιρούμενο
- Λιμενεργάτης
- Πτώση
- κατά την διάρκεια
- δυναμικός
- κάθε
- ευκολότερη
- αποτέλεσμα
- αποτελεσματικός
- αποτελεσματικά
- Ηλεκτρολόγων Μηχανικών
- στοιχεία
- την εξάλειψη
- ενεργοποιήσετε
- ενθαρρύνει
- από άκρη σε άκρη
- μηχανικός
- Μηχανική
- Ολόκληρος
- καταχώριση
- Αιθέρας (ΕΤΗ)
- Even
- πάντα
- παράδειγμα
- παραδείγματα
- έξοχος
- Εκτός
- εκτέλεση
- αναμένεται
- εξωτερικός
- επιπλέον
- εκχύλισμα
- εργοστάσιο
- FAST
- γρηγορότερα
- Χαρακτηριστικό
- Χαρακτηριστικά
- Εικόνα
- φιλτράρισμα
- τελικός
- Τελικά
- Όνομα
- καθορίζεται
- ακολουθήστε
- ακολουθείται
- Εξής
- μορφή
- μορφή
- Δωρεάν
- συχνά
- από
- εμπρός
- πλήρως
- λειτουργία
- λειτουργίες
- περαιτέρω
- Κέρδος
- General
- δημιουργεί
- παίρνω
- GitHub
- δεδομένου
- Παγκόσμιο
- καλός
- GPU
- εγγυημένη
- Handles
- που έχει
- εδώ
- υψηλότερο
- υψηλότερο
- κατέχει
- Πως
- Πώς να
- Ωστόσο
- HTML
- HTTPS
- ιδανικό
- προσδιορισμό
- αμετάβλητος
- εφαρμογή
- εκτέλεση
- εφαρμοστεί
- βελτίωση
- βελτίωση
- βελτιώνει
- in
- περιλαμβάνονται
- Συμπεριλαμβανομένου
- Αυξάνουν
- αύξηση
- ευρετήριο
- ατομικές
- πληροφορίες
- αρχικός
- εισαγωγή
- Ινστιτούτο
- εσωτερικός
- IT
- εαυτό
- Johns Hopkins
- Πανεπιστήμιο Johns Hopkins
- ενώνει
- KDnuggets
- Διατήρηση
- Κλειδί
- γνώση
- επιγραφή
- large
- μεγαλύτερος
- Επίθετο
- Αφάνεια
- αργότερο
- τελευταία έκδοση
- ξεκίνησε
- ξεκινάει
- δρομολόγηση
- Οδηγεί
- μάθηση
- Μήκος
- Βιβλιοθήκη
- φως
- LIMIT
- περιορισμούς
- φόρτωση
- τοποθεσία
- μηχανή
- μάθηση μηχανής
- Κυρίως
- διατηρεί
- κάνω
- ΚΑΝΕΙ
- Κατασκευή
- διαχείριση
- διαχείριση
- διευθυντής
- διαχείριση
- πολοί
- κύριος
- mastering
- Ταίριασμα
- μέσα
- μέτρο
- μέτρα
- Μνήμη
- μέθοδος
- ενδέχεται να
- εκατομμύριο
- νου
- περισσότερο
- πιο αποτελεσματικό
- κινήσεις
- MS
- πολλαπλούς
- όνομα
- ονόματα
- Ανάγκη
- που απαιτούνται
- Νέα
- αριθμός
- Nvidia
- αντικειμένων
- όφσετ
- ONE
- άνοιγμα
- λειτουργούν
- λειτουργεί
- λειτουργίες
- Ευκαιρία
- ΑΛΛΑ
- καταβλήθηκε
- Παράλληλο
- παράμετρος
- μέρος
- πέρασε
- Κορυφή
- επίδοση
- εκτέλεση
- εκτελεί
- έμμηνα
- άδεια
- προοπτική
- Φυσική
- Μέρος
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- συν
- Σημείο
- πισίνα
- κατοικημένη περιοχή
- θέση
- θέσεις
- Θέση
- ισχυρός
- αρμοδιότητες
- προηγούμενος
- μεταποίηση
- παράγει
- προφίλ
- προτείνω
- παρέχεται
- παρέχει
- δημόσιο
- σκοπός
- ποιότητα
- σειρά
- Φτάνει
- Διάβασε
- λογικός
- λαμβάνει
- ρεκόρ
- Μειωμένος
- μειώνει
- Refactor
- αντικατοπτρίζει
- περιοχές
- απελευθερώνουν
- Δελτία
- υπόλοιπα
- εκπροσωπούν
- αντιπροσωπεύει
- πόρος
- αποτέλεσμα
- απόδοση
- Επιστροφές
- ΣΕΙΡΑ
- τρέξιμο
- τρέξιμο
- ίδιο
- Επιστήμη
- Δεύτερος
- αρχαιότερος
- Ακολουθία
- εξυπηρετεί
- Σέτς
- Κοινοποίηση
- θα πρέπει να
- παρουσιάζεται
- Δείχνει
- σημαντικός
- παρόμοιες
- απλά
- αφού
- ενιαίας
- Μέγεθος
- μεγέθη
- μικρότερος
- So
- λογισμικό
- Μηχανικός Λογισμικού
- τεχνολογία λογισμικού
- στέρεο
- λύση
- Λύσεις
- Πηγή
- Χώρος
- συγκεκριμένες
- ειδικά
- καθορίζεται
- ομιλία
- ταχύτητα
- πέρασε
- διαίρεση
- Εκκίνηση
- ξεκίνησε
- Ξεκινήστε
- Κατάσταση
- Βήματα
- Ακόμη
- κατάστημα
- αποθηκεύονται
- καταστήματα
- ειλικρινής
- μετάδοση
- δομή
- έκπληκτος
- συστήματα
- παίρνει
- Τεχνολογία
- προσωρινή
- δοκιμή
- Δοκιμές
- Η
- τους
- θεωρητικός
- επομένως
- Μέσω
- διακίνηση
- ώρα
- προς την
- μαζι
- εργαλείο
- εργαλειοθήκη
- εργαλεία
- Σύνολο
- Μεταμορφώστε
- Μεταμόρφωση
- μετασχηματισμούς
- μετασχηματίζεται
- μετασχηματίζοντας
- tv
- τύποι
- τυπικός
- υποκείμενες
- πανεπιστήμιο
- ξεκλειδώσετε
- ξεκλειδώματος
- us
- χρήση
- επιχειρήσεις κοινής ωφέλειας
- Πολύτιμος
- Πολύτιμες πληροφορίες
- Εναντίον
- ορατότητα
- ορατός
- ζωτικής σημασίας
- Ποιό
- ενώ
- ευρύς
- Ευρύ φάσμα
- θα
- εντός
- χωρίς
- Εργασία
- εργαζόμενος
- λειτουργεί
- θα
- γράφω
- γραφή
- X
- Σας
- zephyrnet










