Αυτή η ανάρτηση έχει συνταχθεί από κοινού με τους Pramod Nayak, LakshmiKanth Mannem και Vivek Aggarwal από την ομάδα Low Latency του LSEG.
Η ανάλυση κόστους συναλλαγών (TCA) χρησιμοποιείται ευρέως από εμπόρους, διαχειριστές χαρτοφυλακίου και μεσίτες για ανάλυση πριν και μετά τη συναλλαγή και τους βοηθά να μετρήσουν και να βελτιστοποιήσουν το κόστος συναλλαγών και την αποτελεσματικότητα των στρατηγικών συναλλαγών τους. Σε αυτήν την ανάρτηση, αναλύουμε τα spreads προσφοράς-ζήτησης επιλογών από το LSEG Tick History – PCAP χρήση συνόλου δεδομένων Amazon Athena για το Apache Spark. Σας δείχνουμε πώς μπορείτε να αποκτήσετε πρόσβαση σε δεδομένα, να ορίσετε προσαρμοσμένες συναρτήσεις για εφαρμογή σε δεδομένα, να κάνετε αναζήτηση και να φιλτράρετε το σύνολο δεδομένων και να οπτικοποιήσετε τα αποτελέσματα της ανάλυσης, όλα αυτά χωρίς να χρειάζεται να ανησυχείτε για τη ρύθμιση της υποδομής ή τη διαμόρφωση του Spark, ακόμη και για μεγάλα σύνολα δεδομένων.
Ιστορικό
Η Αρχή Αναφοράς Τιμών Επιλογών (OPRA) χρησιμεύει ως κρίσιμος υπεύθυνος επεξεργασίας πληροφοριών τίτλων, συλλέγοντας, ενοποιώντας και διανέμοντας αναφορές τελευταίας πώλησης, τιμές και σχετικές πληροφορίες για τις US Options. Με 18 ενεργά χρηματιστήρια δικαιωμάτων προαίρεσης των ΗΠΑ και πάνω από 1.5 εκατομμύριο επιλέξιμες συμβάσεις, η OPRA διαδραματίζει κεντρικό ρόλο στην παροχή ολοκληρωμένων δεδομένων αγοράς.
Στις 5 Φεβρουαρίου 2024, η Securities Industry Automation Corporation (SIAC) πρόκειται να αναβαθμίσει τη ροή OPRA από 48 σε 96 κανάλια πολλαπλής εκπομπής. Αυτή η βελτίωση στοχεύει στη βελτιστοποίηση της διανομής συμβόλων και της χρήσης της χωρητικότητας γραμμής ως απάντηση στην κλιμακούμενη εμπορική δραστηριότητα και την αστάθεια στην αγορά δικαιωμάτων προαίρεσης των ΗΠΑ. Η SIAC συνέστησε στις εταιρείες να προετοιμαστούν για μέγιστες ταχύτητες δεδομένων έως και 37.3 GBit ανά δευτερόλεπτο.
Παρά το γεγονός ότι η αναβάθμιση δεν μεταβάλλει άμεσα τον συνολικό όγκο των δημοσιευμένων δεδομένων, επιτρέπει στην OPRA να διαδίδει δεδομένα με σημαντικά ταχύτερο ρυθμό. Αυτή η μετάβαση είναι ζωτικής σημασίας για την αντιμετώπιση των απαιτήσεων της δυναμικής αγοράς επιλογών.
Η OPRA ξεχωρίζει ως μία από τις πιο ογκώδεις ροές, με κορύφωση 150.4 δισεκατομμυρίων μηνυμάτων σε μία ημέρα το τρίτο τρίμηνο του 3 και απαίτηση χωρητικότητας 2023 δισεκατομμυρίων μηνυμάτων σε μία ημέρα. Η λήψη κάθε μηνύματος είναι κρίσιμης σημασίας για την ανάλυση κόστους συναλλαγών, την παρακολούθηση της ρευστότητας της αγοράς, την αξιολόγηση της στρατηγικής συναλλαγών και την έρευνα αγοράς.
Σχετικά με τα δεδομένα
LSEG Tick History – PCAP είναι ένα αποθετήριο που βασίζεται σε σύννεφο, που υπερβαίνει τα 30 PB, που φιλοξενεί δεδομένα παγκόσμιας αγοράς εξαιρετικά υψηλής ποιότητας. Αυτά τα δεδομένα συλλέγονται σχολαστικά απευθείας στα κέντρα δεδομένων ανταλλαγής, χρησιμοποιώντας πλεονάζουσες διαδικασίες λήψης στρατηγικά τοποθετημένες σε μεγάλα κύρια και εφεδρικά κέντρα δεδομένων ανταλλαγής δεδομένων παγκοσμίως. Η τεχνολογία λήψης της LSEG διασφαλίζει τη λήψη δεδομένων χωρίς απώλειες και χρησιμοποιεί μια πηγή χρόνου GPS για ακρίβεια χρονικής σήμανσης νανοδευτερόλεπτο. Επιπλέον, χρησιμοποιούνται εξελιγμένες τεχνικές arbitrage δεδομένων για την απρόσκοπτη κάλυψη τυχόν κενών δεδομένων. Μετά τη σύλληψη, τα δεδομένα υφίστανται σχολαστική επεξεργασία και διαιτησία και στη συνέχεια κανονικοποιούνται σε μορφή παρκέ χρησιμοποιώντας Το Real Time Ultra Direct της LSEG (RTUD) χειριστές ζωοτροφών.
Η διαδικασία κανονικοποίησης, η οποία αποτελεί αναπόσπαστο κομμάτι της προετοιμασίας των δεδομένων για ανάλυση, δημιουργεί έως και 6 TB συμπιεσμένων αρχείων Parquet την ημέρα. Ο τεράστιος όγκος δεδομένων αποδίδεται στην περιεκτική φύση του OPRA, που εκτείνεται σε πολλαπλές ανταλλαγές και διαθέτει πολυάριθμες συμβάσεις προαίρεσης που χαρακτηρίζονται από διαφορετικά χαρακτηριστικά. Η αυξημένη αστάθεια της αγοράς και η δραστηριότητα δημιουργίας αγορών στα χρηματιστήρια δικαιωμάτων προαίρεσης συμβάλλουν περαιτέρω στον όγκο των δεδομένων που δημοσιεύονται στο OPRA.
Τα χαρακτηριστικά του Tick History – PCAP επιτρέπουν στις εταιρείες να διεξάγουν διάφορες αναλύσεις, συμπεριλαμβανομένων των εξής:
- Ανάλυση πριν από τη συναλλαγή – Αξιολογήστε τον πιθανό αντίκτυπο στο εμπόριο και εξερευνήστε διαφορετικές στρατηγικές εκτέλεσης με βάση ιστορικά δεδομένα
- Αξιολόγηση μετά τη συναλλαγή – Μετρήστε το πραγματικό κόστος εκτέλεσης σε σχέση με δείκτες αναφοράς για την αξιολόγηση της απόδοσης των στρατηγικών εκτέλεσης
- βελτιστοποιημένη εκτέλεση – Βελτιώστε τις στρατηγικές εκτέλεσης που βασίζονται σε ιστορικά πρότυπα αγοράς για να ελαχιστοποιήσετε τον αντίκτυπο στην αγορά και να μειώσετε το συνολικό κόστος συναλλαγών
- Διαχείριση κινδύνου – Προσδιορίστε μοτίβα ολίσθησης, εντοπίστε ακραίες τιμές και διαχειριστείτε προληπτικά τους κινδύνους που σχετίζονται με τις εμπορικές δραστηριότητες
- Αναφορά απόδοσης – Διαχωρίστε τον αντίκτυπο των αποφάσεων συναλλαγών από τις επενδυτικές αποφάσεις κατά την ανάλυση της απόδοσης του χαρτοφυλακίου
Το σύνολο δεδομένων LSEG Tick History – PCAP είναι διαθέσιμο στο Ανταλλαγή δεδομένων AWS και μπορεί να προσπελαστεί στο AWS Marketplace. Με Ανταλλαγή δεδομένων AWS για το Amazon S3, μπορείτε να αποκτήσετε πρόσβαση σε δεδομένα PCAP απευθείας από το LSEG Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) κουβάδες, εξαλείφοντας την ανάγκη για τις εταιρείες να αποθηκεύουν το δικό τους αντίγραφο των δεδομένων. Αυτή η προσέγγιση απλοποιεί τη διαχείριση και την αποθήκευση δεδομένων, παρέχοντας στους πελάτες άμεση πρόσβαση σε υψηλής ποιότητας PCAP ή κανονικοποιημένα δεδομένα με ευκολία στη χρήση, ενσωμάτωση και σημαντική εξοικονόμηση αποθήκευσης δεδομένων.
Athena για το Apache Spark
Για αναλυτικές προσπάθειες, Athena για το Apache Spark προσφέρει μια απλοποιημένη εμπειρία φορητού υπολογιστή, προσβάσιμη μέσω της κονσόλας Athena ή των API της Athena, επιτρέποντάς σας να δημιουργήσετε διαδραστικές εφαρμογές Apache Spark. Με βελτιστοποιημένο χρόνο εκτέλεσης Spark, το Athena βοηθά στην ανάλυση petabyte δεδομένων, κλιμακώνοντας δυναμικά τον αριθμό των κινητήρων Spark που είναι μικρότερος από ένα δευτερόλεπτο. Επιπλέον, κοινές βιβλιοθήκες Python όπως τα panda και το NumPy ενσωματώνονται άψογα, επιτρέποντας τη δημιουργία περίπλοκης λογικής εφαρμογής. Η ευελιξία επεκτείνεται στην εισαγωγή προσαρμοσμένων βιβλιοθηκών για χρήση σε σημειωματάρια. Το Athena for Spark φιλοξενεί τις περισσότερες μορφές ανοιχτών δεδομένων και ενσωματώνεται άψογα με το Κόλλα AWS Κατάλογος Δεδομένων.
Σύνολο δεδομένων
Για αυτήν την ανάλυση, χρησιμοποιήσαμε το σύνολο δεδομένων LSEG Tick History – PCAP OPRA από τις 17 Μαΐου 2023. Αυτό το σύνολο δεδομένων περιλαμβάνει τα ακόλουθα στοιχεία:
- Καλύτερη προσφορά και προσφορά (BBO) – Αναφέρει την υψηλότερη προσφορά και τη χαμηλότερη ζήτηση για τίτλο σε μια δεδομένη ανταλλαγή
- Εθνική καλύτερη προσφορά και προσφορά (NBBO) – Αναφέρει την υψηλότερη προσφορά και τη χαμηλότερη ζήτηση για ασφάλεια σε όλα τα χρηματιστήρια
- συναλλαγές – Καταγράφει ολοκληρωμένες συναλλαγές σε όλα τα χρηματιστήρια
Το σύνολο δεδομένων περιλαμβάνει τους ακόλουθους όγκους δεδομένων:
- συναλλαγές – 160 MB κατανεμημένα σε περίπου 60 συμπιεσμένα αρχεία Parquet
- BBO – 2.4 TB κατανεμημένα σε περίπου 300 συμπιεσμένα αρχεία Parquet
- NBBO – 2.8 TB κατανεμημένα σε περίπου 200 συμπιεσμένα αρχεία Parquet
Επισκόπηση ανάλυσης
Η ανάλυση των δεδομένων OPRA Tick History για την Ανάλυση Κόστους Συναλλαγών (TCA) περιλαμβάνει τον έλεγχο των τιμών αγοράς και των συναλλαγών γύρω από ένα συγκεκριμένο εμπορικό γεγονός. Χρησιμοποιούμε τις ακόλουθες μετρήσεις ως μέρος αυτής της μελέτης:
- Προσφορές (QS) – Υπολογίζεται ως η διαφορά μεταξύ της ζήτησης BBO και της προσφοράς BBO
- Αποτελεσματική εξάπλωση (ES) – Υπολογίζεται ως η διαφορά μεταξύ της τιμής συναλλαγής και του μέσου σημείου του BBO (BBO bid + (BBO ask – BBO bid)/2)
- Αποτελεσματικό/τιμώμενο spread (EQF) – Υπολογίστηκε ως (ES / QS) * 100
Υπολογίζουμε αυτά τα spread πριν από τη συναλλαγή και επιπλέον σε τέσσερα διαστήματα μετά τη συναλλαγή (λίγο μετά, 1 δευτερόλεπτο, 10 δευτερόλεπτα και 60 δευτερόλεπτα μετά τη συναλλαγή).
Ρύθμιση παραμέτρων Athena για Apache Spark
Για να διαμορφώσετε το Athena για Apache Spark, ολοκληρώστε τα παρακάτω βήματα:
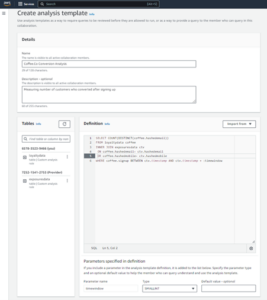
- Στην κονσόλα Athena, κάτω Αγορά, Επιλέξτε Αναλύστε τα δεδομένα σας χρησιμοποιώντας PySpark και Spark SQL.
- Εάν αυτή είναι η πρώτη φορά που χρησιμοποιείτε το Athena Spark, επιλέξτε Δημιουργία ομάδας εργασίας.

- Για Όνομα ομάδας εργασίας¸ πληκτρολογήστε ένα όνομα για την ομάδα εργασίας, όπως π.χ
tca-analysis. - Στο Μηχανή Analytics , επιλέξτε Apache Spark.
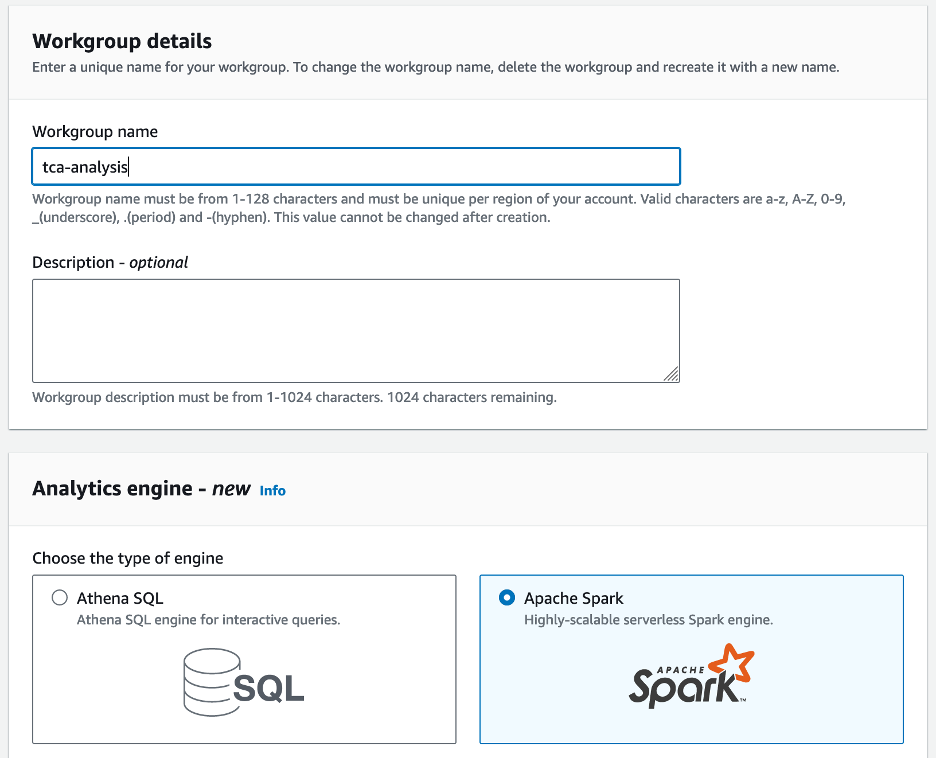
- Στο Πρόσθετες διαμορφώσεις ενότητα, μπορείτε να επιλέξετε Χρησιμοποιήστε προεπιλογές ή παρέχετε ένα έθιμο Διαχείριση ταυτότητας και πρόσβασης AWS ρόλος (IAM) και τοποθεσία Amazon S3 για τα αποτελέσματα υπολογισμού.
- Επιλέξτε Δημιουργία ομάδας εργασίας.
- Αφού δημιουργήσετε την ομάδα εργασίας, μεταβείτε στο Φορητοί υπολογιστές καρτέλα και επιλέξτε Δημιουργήστε σημειωματάριο.
- Εισαγάγετε ένα όνομα για το σημειωματάριό σας, όπως π.χ
tca-analysis-with-tick-history. - Επιλέξτε Δημιουργία για να δημιουργήσετε το σημειωματάριό σας.
Εκκινήστε το σημειωματάριό σας
Εάν έχετε ήδη δημιουργήσει μια ομάδα εργασίας Spark, επιλέξτε Εκκινήστε το πρόγραμμα επεξεργασίας σημειωματάριων υπό Αγορά.
![]()
Αφού δημιουργηθεί το σημειωματάριό σας, θα ανακατευθυνθείτε στο διαδραστικό πρόγραμμα επεξεργασίας σημειωματάριων.
![]()
Τώρα μπορούμε να προσθέσουμε και να εκτελέσουμε τον παρακάτω κώδικα στο σημειωματάριό μας.
Δημιουργήστε μια ανάλυση
Ολοκληρώστε τα παρακάτω βήματα για να δημιουργήσετε μια ανάλυση:
- Εισαγωγή κοινών βιβλιοθηκών:
- Δημιουργήστε τα πλαίσια δεδομένων μας για BBO, NBBO και συναλλαγές:
- Τώρα μπορούμε να προσδιορίσουμε μια συναλλαγή που θα χρησιμοποιηθεί για την ανάλυση κόστους συναλλαγής:
Παίρνουμε την ακόλουθη έξοδο:
Χρησιμοποιούμε τις επισημασμένες πληροφορίες συναλλαγών στο μέλλον για το εμπορικό προϊόν (tp), την τιμή συναλλαγών (tpr) και το χρόνο συναλλαγών (tt).
- Εδώ δημιουργούμε έναν αριθμό βοηθητικών συναρτήσεων για την ανάλυσή μας
- Στην παρακάτω συνάρτηση, δημιουργούμε το σύνολο δεδομένων που περιέχει όλα τα εισαγωγικά πριν και μετά τη συναλλαγή. Το Athena Spark καθορίζει αυτόματα πόσες DPU θα ξεκινήσει για την επεξεργασία των δεδομένων μας.
- Τώρα ας καλέσουμε τη συνάρτηση ανάλυσης TCA με τις πληροφορίες από την επιλεγμένη συναλλαγή μας:
Οραματιστείτε τα αποτελέσματα της ανάλυσης
Τώρα ας δημιουργήσουμε τα πλαίσια δεδομένων που χρησιμοποιούμε για την οπτικοποίησή μας. Κάθε πλαίσιο δεδομένων περιέχει εισαγωγικά για ένα από τα πέντε χρονικά διαστήματα για κάθε ροή δεδομένων (BBO, NBBO):
Στις επόμενες ενότητες, παρέχουμε παράδειγμα κώδικα για τη δημιουργία διαφορετικών απεικονίσεων.
Οικόπεδο QS και NBBO πριν από το εμπόριο
Χρησιμοποιήστε τον ακόλουθο κώδικα για να σχεδιάσετε το εισηγμένο spread και το NBBO πριν από τη συναλλαγή:
![]()
Οικόπεδο QS για κάθε αγορά και NBBO μετά το εμπόριο
Χρησιμοποιήστε τον ακόλουθο κώδικα για να σχεδιάσετε το περιθώριο τιμών για κάθε αγορά και NBBO αμέσως μετά τη συναλλαγή:
![]()
Οικόπεδο QS για κάθε χρονικό διάστημα και κάθε αγορά για BBO
Χρησιμοποιήστε τον ακόλουθο κώδικα για να σχεδιάσετε το προσφερόμενο spread για κάθε χρονικό διάστημα και κάθε αγορά για το BBO:
![]()
Οικόπεδο ES για κάθε χρονικό διάστημα και αγορά για BBO
Χρησιμοποιήστε τον ακόλουθο κώδικα για να σχεδιάσετε το πραγματικό spread για κάθε χρονικό διάστημα και αγορά για το BBO:
Οικόπεδο EQF για κάθε χρονικό διάστημα και αγορά για BBO
Χρησιμοποιήστε τον ακόλουθο κώδικα για να σχεδιάσετε την αποτελεσματική/αναφερόμενη διαφορά για κάθε χρονικό διάστημα και αγορά για το BBO:
Απόδοση υπολογισμού Athena Spark
Όταν εκτελείτε ένα μπλοκ κώδικα, το Athena Spark καθορίζει αυτόματα πόσες DPU χρειάζεται για να ολοκληρώσει τον υπολογισμό. Στο τελευταίο μπλοκ κώδικα, όπου καλούμε το tca_analysis λειτουργία, στην πραγματικότητα δίνουμε εντολή στο Spark να επεξεργαστεί τα δεδομένα και, στη συνέχεια, μετατρέπουμε τα πλαίσια δεδομένων Spark που προκύπτουν σε πλαίσια δεδομένων Pandas. Αυτό αποτελεί το πιο εντατικό μέρος επεξεργασίας της ανάλυσης και όταν το Athena Spark εκτελεί αυτό το μπλοκ, δείχνει τη γραμμή προόδου, τον χρόνο που έχει παρέλθει και πόσες DPU επεξεργάζονται δεδομένα αυτήν τη στιγμή. Για παράδειγμα, στον ακόλουθο υπολογισμό, το Athena Spark χρησιμοποιεί 18 DPU.
![]()
Όταν διαμορφώνετε τον φορητό υπολογιστή Athena Spark, έχετε την επιλογή να ορίσετε τον μέγιστο αριθμό DPU που μπορεί να χρησιμοποιήσει. Η προεπιλογή είναι 20 DPU, αλλά δοκιμάσαμε αυτόν τον υπολογισμό με 10, 20 και 40 DPU για να δείξουμε πώς το Athena Spark κλιμακώνεται αυτόματα για να εκτελέσει την ανάλυσή μας. Παρατηρήσαμε ότι το Athena Spark κλιμακώνεται γραμμικά, χρειαζόταν 15 λεπτά και 21 δευτερόλεπτα όταν ο φορητός υπολογιστής είχε ρυθμιστεί με μέγιστο 10 DPU, 8 λεπτά και 23 δευτερόλεπτα όταν ο φορητός υπολογιστής είχε διαμορφωθεί με 20 DPU και 4 λεπτά και 44 δευτερόλεπτα όταν το notebook ήταν διαμορφωμένο με 40 DPU. Επειδή το Athena Spark χρεώνει με βάση τη χρήση της DPU, με ακρίβεια ανά δευτερόλεπτο, το κόστος αυτών των υπολογισμών είναι παρόμοιο, αλλά αν ορίσετε υψηλότερη μέγιστη τιμή DPU, το Athena Spark μπορεί να επιστρέψει το αποτέλεσμα της ανάλυσης πολύ πιο γρήγορα. Για περισσότερες λεπτομέρειες σχετικά με την τιμολόγηση του Athena Spark, κάντε κλικ εδώ.
Συμπέρασμα
Σε αυτήν την ανάρτηση, δείξαμε πώς μπορείτε να χρησιμοποιήσετε δεδομένα OPRA υψηλής πιστότητας από το Tick History-PCAP της LSEG για την εκτέλεση αναλύσεων κόστους συναλλαγών χρησιμοποιώντας το Athena Spark. Η έγκαιρη διαθεσιμότητα των δεδομένων OPRA, σε συνδυασμό με τις καινοτομίες προσβασιμότητας του AWS Data Exchange για το Amazon S3, μειώνει στρατηγικά τον χρόνο για τα αναλυτικά στοιχεία για εταιρείες που θέλουν να δημιουργήσουν χρήσιμες πληροφορίες για κρίσιμες εμπορικές αποφάσεις. Η OPRA παράγει περίπου 7 TB κανονικοποιημένων δεδομένων Parquet κάθε μέρα και η διαχείριση της υποδομής για την παροχή αναλυτικών στοιχείων με βάση τα δεδομένα OPRA είναι δύσκολη.
Η επεκτασιμότητα του Athena στον χειρισμό μεγάλης κλίμακας επεξεργασίας δεδομένων για το Tick History – PCAP για δεδομένα OPRA το καθιστά μια συναρπαστική επιλογή για οργανισμούς που αναζητούν γρήγορες και επεκτάσιμες λύσεις ανάλυσης στο AWS. Αυτή η ανάρτηση δείχνει την απρόσκοπτη αλληλεπίδραση μεταξύ του οικοσυστήματος AWS και των δεδομένων Tick History-PCAP και πώς τα χρηματοπιστωτικά ιδρύματα μπορούν να επωφεληθούν από αυτήν τη συνέργεια για να οδηγήσουν στη λήψη αποφάσεων βάσει δεδομένων για κρίσιμες στρατηγικές συναλλαγών και επενδύσεων.
Σχετικά με τους Συγγραφείς
![]() Pramod Nayak είναι Διευθυντής Διαχείρισης Προϊόντων της Ομάδας Low Latency στο LSEG. Η Pramod έχει πάνω από 10 χρόνια εμπειρίας στον κλάδο της χρηματοοικονομικής τεχνολογίας, εστιάζοντας στην ανάπτυξη λογισμικού, την ανάλυση και τη διαχείριση δεδομένων. Ο Pramod είναι πρώην μηχανικός λογισμικού και παθιασμένος με τα δεδομένα της αγοράς και τις ποσοτικές συναλλαγές.
Pramod Nayak είναι Διευθυντής Διαχείρισης Προϊόντων της Ομάδας Low Latency στο LSEG. Η Pramod έχει πάνω από 10 χρόνια εμπειρίας στον κλάδο της χρηματοοικονομικής τεχνολογίας, εστιάζοντας στην ανάπτυξη λογισμικού, την ανάλυση και τη διαχείριση δεδομένων. Ο Pramod είναι πρώην μηχανικός λογισμικού και παθιασμένος με τα δεδομένα της αγοράς και τις ποσοτικές συναλλαγές.
![]() LakshmiKanth Mannem είναι Διαχειριστής προϊόντων στην ομάδα χαμηλού λανθάνοντος χρόνου της LSEG. Επικεντρώνεται σε προϊόντα δεδομένων και πλατφόρμας για τη βιομηχανία δεδομένων αγοράς χαμηλής καθυστέρησης. Η LakshmiKanth βοηθά τους πελάτες να δημιουργήσουν τις βέλτιστες λύσεις για τις ανάγκες τους σε δεδομένα αγοράς.
LakshmiKanth Mannem είναι Διαχειριστής προϊόντων στην ομάδα χαμηλού λανθάνοντος χρόνου της LSEG. Επικεντρώνεται σε προϊόντα δεδομένων και πλατφόρμας για τη βιομηχανία δεδομένων αγοράς χαμηλής καθυστέρησης. Η LakshmiKanth βοηθά τους πελάτες να δημιουργήσουν τις βέλτιστες λύσεις για τις ανάγκες τους σε δεδομένα αγοράς.
![]() Vivek Aggarwal είναι Senior Data Engineer στην Ομάδα Low Latency του LSEG. Η Vivek εργάζεται για την ανάπτυξη και τη συντήρηση αγωγών δεδομένων για την επεξεργασία και την παράδοση ροών δεδομένων αγοράς που έχουν συλληφθεί και ροών δεδομένων αναφοράς.
Vivek Aggarwal είναι Senior Data Engineer στην Ομάδα Low Latency του LSEG. Η Vivek εργάζεται για την ανάπτυξη και τη συντήρηση αγωγών δεδομένων για την επεξεργασία και την παράδοση ροών δεδομένων αγοράς που έχουν συλληφθεί και ροών δεδομένων αναφοράς.
![]() Alket Memushaj είναι Κύριος Αρχιτέκτονας στην ομάδα Ανάπτυξης Αγοράς Χρηματοοικονομικών Υπηρεσιών στο AWS. Η Alket είναι υπεύθυνη για την τεχνική στρατηγική, συνεργαζόμενη με συνεργάτες και πελάτες για την ανάπτυξη ακόμη και των πιο απαιτητικών φόρτων εργασίας των κεφαλαιαγορών στο AWS Cloud.
Alket Memushaj είναι Κύριος Αρχιτέκτονας στην ομάδα Ανάπτυξης Αγοράς Χρηματοοικονομικών Υπηρεσιών στο AWS. Η Alket είναι υπεύθυνη για την τεχνική στρατηγική, συνεργαζόμενη με συνεργάτες και πελάτες για την ανάπτυξη ακόμη και των πιο απαιτητικών φόρτων εργασίας των κεφαλαιαγορών στο AWS Cloud.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- PlatoHealth. Ευφυΐα βιοτεχνολογίας και κλινικών δοκιμών. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :έχει
- :είναι
- :δεν
- :που
- $UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- Σχετικά
- πρόσβαση
- πρόσβαση
- προσιτότητα
- προσιτός
- απέναντι
- ενεργός
- δραστηριότητα
- πραγματικός
- πραγματικά
- προσθέτω
- Επιπλέον
- διευθυνσιοδότηση
- Πλεονέκτημα
- Μετά το
- κατά
- Aggarwal
- στόχοι
- Όλα
- Επιτρέποντας
- ήδη
- Amazon
- Αμαζόν Αθηνά
- Amazon υπηρεσίες Web
- an
- αναλύσεις
- ανάλυση
- Αναλυτικός
- analytics
- αναλύσει
- αναλύοντας
- και
- κάθε
- Apache
- Apache Spark
- APIs
- Εφαρμογή
- εφαρμογές
- Εφαρμογή
- πλησιάζω
- περίπου
- διαιτησία
- διαιτησία
- ΕΙΝΑΙ
- γύρω
- AS
- ζητώ
- εκτιμώ
- συσχετισμένη
- At
- γνωρίσματα
- εξουσία
- αυτομάτως
- Αυτοματοποίηση
- διαθεσιμότητα
- διαθέσιμος
- AWS
- εφεδρικός
- μπαρ
- βασίζονται
- BE
- επειδή
- πριν
- αναφοράς
- ΚΑΛΎΤΕΡΟΣ
- μεταξύ
- προσφορά
- Δισεκατομμύριο
- Αποκλεισμός
- μεσίτες
- χτίζω
- αλλά
- by
- υπολογίσει
- υπολογίζεται
- υπολογισμός
- κλήση
- CAN
- Χωρητικότητα
- κεφάλαιο
- Κεφαλαιαγορές
- πιάνω
- συλλαμβάνονται
- Καταγραφή
- κατάλογος
- Κέντρα
- πρόκληση
- κανάλια
- χαρακτηρίζεται
- φορτία
- επιλογή
- Επιλέξτε
- πελάτες
- Backup
- κωδικός
- Συλλέγοντας
- Κοινός
- συναρπαστικό
- πλήρης
- Ολοκληρώθηκε το
- εξαρτήματα
- περιεκτικός
- περιλαμβάνει
- Διεξαγωγή
- έχει ρυθμιστεί
- Διαμόρφωση
- πρόξενος
- ενοποίηση
- Περιέχει
- συμβάσεις
- συμβάλλει
- μετατρέψετε
- ΕΤΑΙΡΕΙΑ
- Κόστος
- Δικαστικά έξοδα
- γραφτό
- δημιουργία
- δημιουργήθηκε
- δημιουργία
- κρίσιμης
- κρίσιμος
- Τη στιγμή
- έθιμο
- Πελάτες
- παύλα
- ημερομηνία
- κέντρα δεδομένων
- μηχανικός δεδομένων
- Ανταλλαγή δεδομένων
- διαχείριση δεδομένων
- επεξεργασία δεδομένων
- αποθήκευση δεδομένων
- βασίζονται σε δεδομένα
- σύνολα δεδομένων
- ημέρα
- Λήψη Αποφάσεων
- αποφάσεις
- Προεπιλογή
- ορίζεται
- διανομή
- απαιτητικές
- απαιτήσεις
- αποδεικνύουν
- κατέδειξε
- παρατάσσω
- καθέκαστα
- καθορίζει
- ανάπτυξη
- Ανάπτυξη
- ομάδα ανάπτυξης
- διαφορά
- διαφορετικές
- κατευθείαν
- Διευθυντής
- διανέμονται
- διανομή
- διάφορα
- διπλασιαστεί
- αυτοκίνητο
- δυναμικός
- δυναμικά
- δυναμική
- κάθε
- ευκολία
- ευκολία στη χρήση
- οικοσύστημα
- συντάκτης
- Αποτελεσματικός
- αποτελεσματικότητα
- επιλέξιμες
- εξάλειψη
- μισθωτών
- απασχολώντας
- ενεργοποιήσετε
- δίνει τη δυνατότητα
- που περιλαμβάνει
- προσπάθειες
- Κινητήρας
- μηχανικός
- Κινητήρες
- Βελτιστοποίηση
- εξασφαλίζει
- εισάγετε
- κλιμακώνοντας
- Αιθέρας (ΕΤΗ)
- αξιολογήσει
- εκτίμηση
- Even
- Συμβάν
- Κάθε
- παράδειγμα
- ανταλλαγή
- Χρηματιστήρια
- εκτέλεση
- εμπειρία
- διερευνήσει
- ρητή
- Επεκτείνεται
- γρηγορότερα
- Χαρακτηρίζοντας
- Φεβρουάριος
- Σύκο
- Αρχεία
- συμπληρώστε
- φιλτράρισμα
- οικονομικός
- Χρηματοπιστωτικά ιδρύματα
- των χρηματοπιστωτικών υπηρεσιών
- χρηματοοικονομική τεχνολογία
- επιχειρήσεις
- Όνομα
- πρώτη φορά
- πέντε
- Ευελιξία
- εστιάζει
- εστιάζοντας
- Εξής
- Για
- μορφή
- Πρώην
- Προς τα εμπρός
- τέσσερα
- ΠΛΑΙΣΙΟ
- από
- λειτουργία
- λειτουργίες
- περαιτέρω
- κενά
- δημιουργεί
- παίρνω
- δεδομένου
- Παγκόσμιο
- παγκόσμια αγορά
- Go
- μετάβαση
- gps
- Group
- Χειρισμός
- Έχω
- που έχει
- he
- το κεφάλι
- βοηθά
- υψηλής ποιότητας
- υψηλότερο
- υψηλότερο
- Τόνισε
- ιστορικών
- ιστορία
- στέγαση
- Πως
- Πώς να
- http
- HTTPS
- IAM
- προσδιορίσει
- Ταυτότητα
- if
- άμεσος
- αμέσως
- Επίπτωση
- εισαγωγή
- in
- Συμπεριλαμβανομένου
- αυξημένη
- βιομηχανία
- πληροφορίες
- Υποδομή
- καινοτομίες
- ιδέες
- ιδρυμάτων
- ολοκλήρωμα
- ενσωματωθεί
- ολοκλήρωση
- αλληλεπίδραση
- διαδραστικό
- σε
- πολύπλοκος
- επένδυση
- περιλαμβάνει
- IT
- jpg
- μόλις
- large
- μεγάλης κλίμακας
- Επίθετο
- Αφάνεια
- ξεκινήσει
- μείον
- βιβλιοθήκες
- γραμμή
- Ρευστότητα
- τοποθεσία
- λογική
- κοιτάζοντας
- Χαμηλός
- χαμηλότερο
- Η διατήρηση
- μεγάλες
- ΚΑΝΕΙ
- Κατασκευή
- διαχείριση
- διαχείριση
- διευθυντής
- Διευθυντές
- διαχείριση
- τρόπος
- πολοί
- αγορά
- Τα δεδομένα της αγοράς
- αντίκτυπο στην αγορά
- έρευνα αγοράς
- Μεταβλητότητα της αγοράς
- αγορά της αγοράς
- αγορές
- μαζική
- mastering
- ανώτατο όριο
- Ενδέχεται..
- μέτρο
- μήνυμα
- μηνύματα
- λεπτολόγος
- σχολαστικά
- Metrics
- εκατομμύριο
- ελαχιστοποίηση
- πρακτικά
- παρακολούθηση
- περισσότερο
- Εξάλλου
- πλέον
- πολύ
- πολλαπλούς
- όνομα
- Φύση
- Πλοηγηθείτε
- Ανάγκη
- ανάγκες
- Κανένας
- σημειωματάριο
- φορητούς υπολογιστές
- αριθμός
- πολυάριθμες
- πολλοί
- παρατηρούμενη
- of
- προσφορά
- προσφορές
- on
- ONE
- βέλτιστη
- Βελτιστοποίηση
- βελτιστοποιημένη
- Επιλογή
- Επιλογές
- or
- οργανώσεις
- δικός μας
- έξω
- παραγωγή
- επί
- φόρμες
- δική
- Πάντα
- μέρος
- Συνεργάτες
- παθιασμένος
- πρότυπα
- Κορυφή
- για
- εκτελέσει
- επίδοση
- πιλοτικές
- πλατφόρμες
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- παίζει
- σας παρακαλούμε
- οικόπεδο
- χαρτοφυλάκιο
- διαχειριστές χαρτοφυλακίου
- τοποθετημένες
- Θέση
- μετά το εμπόριο
- δυναμικού
- Ακρίβεια
- Προετοιμάστε
- προετοιμασία
- τιμή
- τιμολόγηση
- πρωταρχικός
- Κύριος
- διαδικασια μας
- Διεργασίες
- μεταποίηση
- Επεξεργαστής
- Προϊόν
- διαχείριση προϊόντων
- υπεύθυνος προϊόντων
- Προϊόντα
- Πρόοδος
- παρέχουν
- χορήγηση
- δημοσιεύθηκε
- Python
- Q3
- ποσοτικός
- ποσότητα
- απορία
- εισαγωγικά
- Τιμή
- Τιμές
- Διάβασε
- πραγματικός
- σε πραγματικό χρόνο
- συνιστάται
- αρχεία
- Red
- μείωση
- μειώνει
- αναφορά
- ανανεώσω
- Αναφορά
- Εκθέσεις
- Αποθήκη
- απαίτηση
- Απαιτεί
- έρευνα
- απάντησης
- υπεύθυνος
- αποτέλεσμα
- με αποτέλεσμα
- Αποτελέσματα
- απόδοση
- κινδύνους
- Ρόλος
- τρέξιμο
- τρέχει
- πώληση
- Απεριόριστες δυνατότητες
- επεκτάσιμη
- Ζυγός
- απολέπιση
- αδιάλειπτη
- άψογα
- Δεύτερος
- δευτερόλεπτα
- Τμήμα
- τμήματα
- Χρεόγραφα
- ασφάλεια
- αναζήτηση
- επιλέξτε
- επιλέγονται
- αρχαιότερος
- ξεχωριστό
- εξυπηρετεί
- Υπηρεσίες
- σειρά
- τον καθορισμό
- δείχνουν
- Δείχνει
- σημαντικά
- παρόμοιες
- Απλούς
- απλοποιημένη
- ενιαίας
- ολίσθηση
- λογισμικό
- ανάπτυξη λογισμικού
- Μηχανικός Λογισμικού
- Λύσεις
- εξελιγμένα
- ένταση
- Σπινθήρας
- συγκεκριμένες
- διάδοση
- Spreads
- στέκεται
- Βήματα
- χώρος στο δίσκο
- κατάστημα
- Στρατηγικώς
- στρατηγικές
- Στρατηγική
- απλουστεύει
- Μελέτη
- μεταγενέστερος
- τέτοιος
- SWIFT
- σύμβολο
- συνεργία
- Πάρτε
- λήψη
- Τεχνικός
- τεχνικές
- Τεχνολογία
- δοκιμαστεί
- από
- ότι
- Η
- οι πληροφορίες
- τους
- Τους
- τότε
- Αυτοί
- αυτό
- Μέσω
- τσιμπούρι
- ώρα
- έγκαιρος
- timestamp
- Τίτλος
- προς την
- Σύνολο
- tp
- TPR
- εμπόριο
- Οι έμποροι
- συναλλαγές
- Διαπραγμάτευσης
- Στρατηγικές Trading
- εμπορική στρατηγική
- συναλλαγή
- το κόστος των συναλλαγών
- μετασχηματίζοντας
- μετάβαση
- Υπερ
- υπό
- υφίσταται
- αναβάθμισης
- us
- Χρήση
- χρήση
- μεταχειρισμένος
- χρησιμοποιεί
- χρησιμοποιώντας
- αξιοποιώντας
- αξία
- διάφορα
- οραματισμός
- φαντάζομαι
- Μεταβλητότητα
- τόμος
- όγκους
- ήταν
- we
- ιστός
- διαδικτυακές υπηρεσίες
- πότε
- Ποιό
- ευρέως
- θα
- με
- εντός
- χωρίς
- Ομάδα εργασίας
- εργαζόμενος
- λειτουργεί
- παγκόσμιος
- ανησυχία
- X
- χρόνια
- εσείς
- Σας
- zephyrnet