Amazon RedShift είναι μια πλήρως διαχειριζόμενη αποθήκη δεδομένων cloud σε κλίμακα petabyte που χρησιμοποιείται από δεκάδες χιλιάδες πελάτες για την επεξεργασία exabyte δεδομένων κάθε μέρα για να τροφοδοτήσει τον φόρτο εργασίας τους στα αναλυτικά στοιχεία. Μπορείτε να δομήσετε τα δεδομένα σας, να μετρήσετε τις επιχειρηματικές διαδικασίες και να λάβετε πολύτιμες πληροφορίες γρήγορα, χρησιμοποιώντας ένα μοντέλο διαστάσεων. Το Amazon Redshift παρέχει ενσωματωμένες λειτουργίες για την επιτάχυνση της διαδικασίας μοντελοποίησης, ενορχήστρωσης και αναφοράς από ένα μοντέλο διαστάσεων.
Σε αυτήν την ανάρτηση, συζητάμε πώς να εφαρμόσουμε ένα μοντέλο διαστάσεων, συγκεκριμένα το Μεθοδολογία Kimball. Συζητάμε την υλοποίηση διαστάσεων και γεγονότων στο Amazon Redshift. Δείχνουμε πώς να εκτελείται η εξαγωγή, ο μετασχηματισμός και η φόρτωση (ELT), μια διαδικασία ολοκλήρωσης που επικεντρώνεται στη μεταφορά των ακατέργαστων δεδομένων από μια λίμνη δεδομένων σε ένα στρώμα σταδιοποίησης για την εκτέλεση της μοντελοποίησης. Συνολικά, η ανάρτηση θα σας δώσει μια σαφή κατανόηση του τρόπου χρήσης της μοντελοποίησης διαστάσεων στο Amazon Redshift.
Επισκόπηση λύσεων
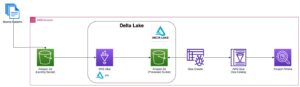
Το παρακάτω διάγραμμα απεικονίζει την αρχιτεκτονική λύσεων.

Στις επόμενες ενότητες, αρχικά συζητάμε και δείχνουμε τις βασικές πτυχές του μοντέλου διαστάσεων. Μετά από αυτό, δημιουργούμε ένα data mart χρησιμοποιώντας το Amazon Redshift με ένα μοντέλο δεδομένων διαστάσεων που περιλαμβάνει πίνακες διαστάσεων και δεδομένων. Τα δεδομένα φορτώνονται και σκηνοθετούνται χρησιμοποιώντας το COPY εντολή, τα δεδομένα στις διαστάσεις φορτώνονται χρησιμοποιώντας το ΣΥΓΧΩΝΕΥΣΗ δήλωση και τα γεγονότα θα ενωθούν με τις διαστάσεις από τις οποίες προέρχονται οι πληροφορίες. Προγραμματίζουμε τη φόρτωση των διαστάσεων και των στοιχείων χρησιμοποιώντας το Amazon Redshift Query Editor V2. Τέλος, χρησιμοποιούμε Amazon QuickSight για να αποκτήσετε πληροφορίες σχετικά με τα μοντελοποιημένα δεδομένα με τη μορφή ενός πίνακα εργαλείων QuickSight.
Για αυτήν τη λύση, χρησιμοποιούμε ένα δείγμα δεδομένων (κανονικοποιημένο) που παρέχεται από το Amazon Redshift για πωλήσεις εισιτηρίων εκδηλώσεων. Για αυτήν την ανάρτηση, περιορίσαμε το σύνολο δεδομένων για λόγους απλότητας και επίδειξης. Οι παρακάτω πίνακες δείχνουν παραδείγματα των δεδομένων για τις πωλήσεις εισιτηρίων και τους χώρους διεξαγωγής.


Σύμφωνα με το Μεθοδολογία μοντελοποίησης διαστάσεων Kimball, υπάρχουν τέσσερα βασικά βήματα για το σχεδιασμό ενός μοντέλου διαστάσεων:
- Προσδιορίστε την επιχειρηματική διαδικασία.
- Δηλώστε την ουσία των δεδομένων σας.
- Προσδιορίστε και εφαρμόστε τις διαστάσεις.
- Προσδιορίστε και εφαρμόστε τα γεγονότα.
Επιπλέον, προσθέτουμε ένα πέμπτο βήμα για σκοπούς επίδειξης, το οποίο είναι η αναφορά και η ανάλυση επιχειρηματικών γεγονότων.
Προϋποθέσεις
Για αυτήν την καθοδήγηση, θα πρέπει να έχετε τις ακόλουθες προϋποθέσεις:
Προσδιορίστε την επιχειρηματική διαδικασία
Με απλά λόγια, ο προσδιορισμός της επιχειρηματικής διαδικασίας είναι ο προσδιορισμός ενός μετρήσιμου γεγονότος που δημιουργεί δεδομένα μέσα σε έναν οργανισμό. Συνήθως, οι εταιρείες διαθέτουν κάποιου είδους λειτουργικό σύστημα πηγής που παράγει τα δεδομένα τους στην ακατέργαστη μορφή τους. Αυτό είναι ένα καλό σημείο εκκίνησης για τον εντοπισμό διαφόρων πηγών για μια επιχειρηματική διαδικασία.
Στη συνέχεια, η επιχειρηματική διαδικασία συνεχίζεται ως α δεδομένα mart με τη μορφή διαστάσεων και γεγονότων. Εξετάζοντας το δείγμα δεδομένων μας που αναφέρθηκε προηγουμένως, μπορούμε να δούμε ξεκάθαρα ότι η επιχειρηματική διαδικασία είναι οι πωλήσεις που πραγματοποιήθηκαν για ένα δεδομένο γεγονός.
Ένα συνηθισμένο λάθος που γίνεται είναι η χρήση τμημάτων μιας εταιρείας ως επιχειρηματική διαδικασία. Τα δεδομένα (επιχειρηματική διαδικασία) πρέπει να ενσωματωθούν σε διάφορα τμήματα, σε αυτήν την περίπτωση, το μάρκετινγκ μπορεί να έχει πρόσβαση στα δεδομένα πωλήσεων. Ο εντοπισμός της σωστής επιχειρηματικής διαδικασίας είναι κρίσιμος—το λάθος αυτού του βήματος μπορεί να επηρεάσει ολόκληρη την αγορά δεδομένων (μπορεί να προκαλέσει διπλότυπο του κόκκου και εσφαλμένες μετρήσεις στις τελικές αναφορές).
Δηλώστε το σύνολο των δεδομένων σας
Η δήλωση του κόκκου είναι η πράξη της μοναδικής αναγνώρισης μιας εγγραφής στην πηγή δεδομένων σας. Ο κόκκος χρησιμοποιείται στον πίνακα γεγονότων για να μετρήσει με ακρίβεια τα δεδομένα και να σας επιτρέψει να κάνετε ρολό περαιτέρω. Στο παράδειγμά μας, αυτό θα μπορούσε να είναι ένα στοιχείο γραμμής στην επιχειρηματική διαδικασία πωλήσεων.
Στην περίπτωση χρήσης μας, μια πώληση μπορεί να προσδιοριστεί μοναδικά εξετάζοντας το χρόνο συναλλαγής που πραγματοποιήθηκε η πώληση. αυτό θα είναι το πιο ατομικό επίπεδο.

Προσδιορίστε και εφαρμόστε τις διαστάσεις
Ο πίνακας διαστάσεων σας περιγράφει τον πίνακα γεγονότων και τα χαρακτηριστικά του. Κατά τον προσδιορισμό του περιγραφικού πλαισίου της επιχειρηματικής σας διαδικασίας, αποθηκεύετε το κείμενο σε ξεχωριστό πίνακα, λαμβάνοντας υπόψη τα στοιχεία του πίνακα. Όταν συνδέετε τον πίνακα διαστάσεων στον πίνακα γεγονότων, θα πρέπει να υπάρχει μόνο μία γραμμή που σχετίζεται με τον πίνακα γεγονότων. Στο παράδειγμά μας, χρησιμοποιούμε τον παρακάτω πίνακα για διαχωρισμό σε πίνακα διαστάσεων. αυτά τα πεδία περιγράφουν τα γεγονότα που θα μετρήσουμε.
Όταν σχεδιάζετε τη δομή του μοντέλου διαστάσεων (το σχήμα), μπορείτε είτε να δημιουργήσετε ένα αστέρι or νιφάδα χιονιού σχήμα. Η δομή πρέπει να ευθυγραμμίζεται στενά με την επιχειρηματική διαδικασία. Επομένως, ένα σχήμα αστεριού ταιριάζει καλύτερα στο παράδειγμά μας. Το παρακάτω σχήμα δείχνει το διάγραμμα σχέσεων οντοτήτων (ERD).

Στις επόμενες ενότητες, περιγράφουμε λεπτομερώς τα βήματα για την υλοποίηση των διαστάσεων.
Σταδιοποιήστε τα δεδομένα πηγής
Για να μπορέσουμε να δημιουργήσουμε και να φορτώσουμε τον πίνακα διαστάσεων, χρειαζόμαστε δεδομένα προέλευσης. Επομένως, τοποθετούμε τα δεδομένα προέλευσης σε έναν πίνακα σταδιοποίησης ή προσωρινού πίνακα. Αυτό αναφέρεται συχνά ως το στρώμα σταδιοποίησης, που είναι το μη επεξεργασμένο αντίγραφο των δεδομένων πηγής. Για να το κάνουμε αυτό στο Amazon Redshift, χρησιμοποιούμε το Εντολή COPY για να φορτώσετε τα δεδομένα από τον δημόσιο κάδο S3 dimensional-modeling-in-amazon-redshift που βρίσκεται στο us-east-1 Περιοχή. Σημειώστε ότι η εντολή COPY χρησιμοποιεί ένα Διαχείριση ταυτότητας και πρόσβασης AWS (IAM) ρόλος με πρόσβαση στο Amazon S3. Ο ρόλος πρέπει να είναι που σχετίζονται με το σύμπλεγμα. Ολοκληρώστε τα παρακάτω βήματα για να αναβαθμίσετε τα δεδομένα προέλευσης:
- Δημιουργήστε το
venueπίνακας πηγής:
- Φορτώστε τα δεδομένα του χώρου:
- Δημιουργήστε το
salesπίνακας πηγής:
- Φορτώστε τα δεδομένα πηγής πωλήσεων:
- Δημιουργήστε το
calendarτραπέζι:
- Φόρτωση δεδομένων ημερολογίου:
Δημιουργήστε τον πίνακα διαστάσεων
Ο σχεδιασμός του πίνακα διαστάσεων μπορεί να εξαρτάται από τις απαιτήσεις της επιχείρησής σας—για παράδειγμα, χρειάζεται να παρακολουθείτε τις αλλαγές στα δεδομένα με την πάροδο του χρόνου; Υπάρχουν επτά διαφορετικοί τύποι διαστάσεων. Για το παράδειγμά μας χρησιμοποιούμε πληκτρολογήστε 1 γιατί δεν χρειάζεται να παρακολουθούμε τις ιστορικές αλλαγές. Για περισσότερα σχετικά με τον τύπο 2, ανατρέξτε στο Απλοποιήστε τη φόρτωση δεδομένων σε διαστάσεις τύπου 2 που αλλάζουν αργά στο Amazon Redshift. Ο πίνακας διαστάσεων θα αποκανονικοποιηθεί με ένα πρωτεύον κλειδί, ένα υποκατάστατο κλειδί και μερικά προστιθέμενα πεδία για να υποδείξουν τις αλλαγές στον πίνακα. Δείτε τον παρακάτω κώδικα:
Μερικές σημειώσεις σχετικά με τη δημιουργία του πίνακα διαστάσεων:
- Τα ονόματα των πεδίων μετατρέπονται σε ονόματα φιλικά προς τις επιχειρήσεις
- Το πρωταρχικό μας κλειδί είναι
VenueID, το οποίο χρησιμοποιούμε για να προσδιορίσουμε μοναδικά έναν τόπο στον οποίο πραγματοποιήθηκε η πώληση - Θα προστεθούν δύο επιπλέον σειρές, που υποδεικνύουν πότε εισήχθη και ενημερώθηκε μια εγγραφή (για παρακολούθηση αλλαγών)
- Χρησιμοποιούμε ένα ΑΥΤΟΜΑΤΟ στυλ διανομής να δώσει στο Amazon Redshift την ευθύνη να επιλέξει και να προσαρμόσει το στυλ διανομής
Ένας άλλος σημαντικός παράγοντας που πρέπει να ληφθεί υπόψη στη μοντελοποίηση διαστάσεων είναι η χρήση του υποκατάστατα κλειδιά. Τα υποκατάστατα κλειδιά είναι τεχνητά κλειδιά που χρησιμοποιούνται στη μοντελοποίηση διαστάσεων για να αναγνωρίζουν μοναδικά κάθε εγγραφή σε έναν πίνακα διαστάσεων. Συνήθως δημιουργούνται ως διαδοχικός ακέραιος και δεν έχουν καμία σημασία στον επιχειρηματικό τομέα. Προσφέρουν πολλά πλεονεκτήματα, όπως η εξασφάλιση μοναδικότητας και η βελτίωση της απόδοσης στις συνδέσεις, επειδή είναι συνήθως μικρότερα από τα φυσικά κλειδιά και ως υποκατάστατα κλειδιά δεν αλλάζουν με την πάροδο του χρόνου. Αυτό μας επιτρέπει να είμαστε συνεπείς και να ενώνουμε πιο εύκολα γεγονότα και διαστάσεις.
Στο Amazon Redshift, τα υποκατάστατα κλειδιά δημιουργούνται συνήθως χρησιμοποιώντας τη λέξη-κλειδί IDENTITY. Για παράδειγμα, η προηγούμενη πρόταση CREATE δημιουργεί έναν πίνακα διαστάσεων με a VenueSkey υποκατάστατο κλειδί. ο VenueSkey Η στήλη συμπληρώνεται αυτόματα με μοναδικές τιμές καθώς προστίθενται νέες σειρές στον πίνακα. Αυτή η στήλη μπορεί στη συνέχεια να χρησιμοποιηθεί για τη σύνδεση του πίνακα χώρων στο FactSaleTransactions πίνακα.
Μερικές συμβουλές για το σχεδιασμό υποκατάστατων κλειδιών:
- Χρησιμοποιήστε έναν τύπο δεδομένων μικρού, σταθερού πλάτους για το υποκατάστατο κλειδί. Αυτό θα βελτιώσει την απόδοση και θα μειώσει τον αποθηκευτικό χώρο.
- Χρησιμοποιήστε τη λέξη-κλειδί IDENTITY ή δημιουργήστε το υποκατάστατο κλειδί χρησιμοποιώντας μια διαδοχική τιμή ή τιμή GUID. Αυτό θα διασφαλίσει ότι το υποκατάστατο κλειδί είναι μοναδικό και δεν μπορεί να αλλάξει.
Φορτώστε τον πίνακα φωτεινότητας χρησιμοποιώντας το MERGE
Υπάρχουν πολλοί τρόποι για να φορτώσετε το αμυδρό τραπέζι σας. Πρέπει να ληφθούν υπόψη ορισμένοι παράγοντες—για παράδειγμα, η απόδοση, ο όγκος δεδομένων και ίσως οι χρόνοι φόρτωσης SLA. Με την ΣΥΓΧΩΝΕΥΣΗ δήλωση, εκτελούμε ένα upsert χωρίς να χρειάζεται να καθορίσουμε πολλαπλές εντολές εισαγωγής και ενημέρωσης. Μπορείτε να ρυθμίσετε το ΣΥΓΧΩΝΕΥΣΗ δήλωση σε α αποθηκευμένη διαδικασία για να συμπληρώσετε τα δεδομένα. Στη συνέχεια, προγραμματίζετε την αποθηκευμένη διαδικασία να εκτελεστεί μέσω προγραμματισμού μέσω του προγράμματος επεξεργασίας ερωτημάτων, το οποίο παρουσιάζουμε αργότερα στην ανάρτηση. Ο παρακάτω κώδικας δημιουργεί μια αποθηκευμένη διαδικασία που ονομάζεται SalesMart.DimVenueLoad:
Μερικές σημειώσεις σχετικά με τη φόρτωση διαστάσεων:
- Όταν μια εγγραφή εισάγεται για πρώτη φορά, θα συμπληρωθεί η ημερομηνία εισαγωγής και η ενημερωμένη ημερομηνία. Όταν αλλάζουν οποιεσδήποτε τιμές, τα δεδομένα ενημερώνονται και η ενημερωμένη ημερομηνία αντικατοπτρίζει την ημερομηνία κατά την οποία άλλαξε. Η ημερομηνία που εισήχθη παραμένει.
- Επειδή τα δεδομένα θα χρησιμοποιηθούν από επαγγελματίες χρήστες, πρέπει να αντικαταστήσουμε τις NULL τιμές, εάν υπάρχουν, με περισσότερες τιμές κατάλληλες για τις επιχειρήσεις.
Προσδιορίστε και εφαρμόστε τα γεγονότα
Τώρα που έχουμε δηλώσει ότι το σιτάρι μας είναι το γεγονός μιας πώλησης που πραγματοποιήθηκε σε μια συγκεκριμένη χρονική στιγμή, ο πίνακας στοιχείων μας θα αποθηκεύει τα αριθμητικά στοιχεία για την επιχειρηματική μας διαδικασία.
Προσδιορίσαμε τα ακόλουθα αριθμητικά γεγονότα για μέτρηση:
- Ποσότητα εισιτηρίων που πωλήθηκαν ανά πώληση
- προμήθεια για την πώληση
Εφαρμογή του Γεγονός
Υπάρχουν τρεις τύποι πινάκων γεγονότων (πίνακας γεγονότων συναλλαγής, περιοδικός πίνακας γεγονότων στιγμιότυπων και πίνακας γεγονότων συγκεντρωτικών στιγμιοτύπων). Το καθένα εξυπηρετεί μια διαφορετική άποψη της επιχειρηματικής διαδικασίας. Για το παράδειγμά μας, χρησιμοποιούμε έναν πίνακα γεγονότων συναλλαγής. Ολοκληρώστε τα παρακάτω βήματα:
- Δημιουργήστε τον πίνακα γεγονότων
Προστίθεται μια ημερομηνία που έχει εισαχθεί με μια προεπιλεγμένη τιμή, η οποία υποδεικνύει εάν και πότε φορτώθηκε μια εγγραφή. Μπορείτε να το χρησιμοποιήσετε κατά τη φόρτωση εκ νέου του πίνακα γεγονότων για να αφαιρέσετε τα ήδη φορτωμένα δεδομένα για να αποφύγετε τα διπλότυπα.
Η φόρτωση του πίνακα γεγονότων αποτελείται από μια απλή δήλωση εισαγωγής που ενώνει τις συσχετισμένες διαστάσεις σας. Συμμετέχουμε από το DimVenue πίνακα που δημιουργήθηκε, ο οποίος περιγράφει τα γεγονότα μας. Είναι η καλύτερη πρακτική, αλλά προαιρετική ημερολογιακή ημερομηνία διαστάσεις, οι οποίες επιτρέπουν στον τελικό χρήστη να περιηγηθεί στον πίνακα γεγονότων. Τα δεδομένα μπορούν είτε να φορτώνονται όταν υπάρχει νέα πώληση είτε καθημερινά. Εδώ είναι χρήσιμη η ημερομηνία που έχει εισαχθεί ή η ημερομηνία φόρτωσης.
Φορτώνουμε τον πίνακα δεδομένων χρησιμοποιώντας μια αποθηκευμένη διαδικασία και χρησιμοποιούμε μια παράμετρο ημερομηνίας.
- Δημιουργήστε την αποθηκευμένη διαδικασία με τον ακόλουθο κώδικα. Για να διατηρήσουμε την ίδια ακεραιότητα δεδομένων που εφαρμόσαμε στο φορτίο ιδιότητας, αντικαθιστούμε τις NULL τιμές, εάν υπάρχουν, με περισσότερες κατάλληλες για την επιχείρηση τιμές:
- Φορτώστε τα δεδομένα καλώντας τη διαδικασία με την ακόλουθη εντολή:
Προγραμματίστε τη φόρτωση δεδομένων
Μπορούμε τώρα να αυτοματοποιήσουμε τη διαδικασία μοντελοποίησης προγραμματίζοντας τις αποθηκευμένες διαδικασίες στο Amazon Redshift Query Editor V2. Ολοκληρώστε τα παρακάτω βήματα:
- Αρχικά καλούμε το φορτίο διάστασης και μετά την επιτυχή εκτέλεση του φορτίου διάστασης, ξεκινά το φόρτωση δεδομένων:
Εάν το φορτίο διάστασης αποτύχει, το φορτίο δεδομένων δεν θα εκτελεστεί. Αυτό εξασφαλίζει συνέπεια στα δεδομένα, επειδή δεν θέλουμε να φορτώσουμε τον πίνακα γεγονότων με ξεπερασμένες διαστάσεις.
- Για να προγραμματίσετε τη φόρτωση, επιλέξτε Πρόγραμμα στο Query Editor V2.

- Προγραμματίζουμε το ερώτημα να εκτελείται καθημερινά στις 5:00 π.μ.
- Προαιρετικά, μπορείτε να προσθέσετε ειδοποιήσεις αποτυχίας ενεργοποιώντας Υπηρεσία απλών ειδοποιήσεων Amazon Ειδοποιήσεις (Amazon SNS).

Αναφέρετε και αναλύστε τα δεδομένα στο Amazon Quicksight
Το QuickSight είναι μια υπηρεσία επιχειρηματικής ευφυΐας που διευκολύνει την παροχή πληροφοριών. Ως πλήρως διαχειριζόμενη υπηρεσία, το QuickSight σάς επιτρέπει να δημιουργείτε και να δημοσιεύετε εύκολα διαδραστικούς πίνακες εργαλείων στους οποίους μπορείτε στη συνέχεια να έχετε πρόσβαση από οποιαδήποτε συσκευή και να ενσωματωθούν στις εφαρμογές, τις πύλες και τους ιστότοπούς σας.
Χρησιμοποιούμε το data mart για να παρουσιάσουμε οπτικά τα γεγονότα με τη μορφή πίνακα ελέγχου. Για να ξεκινήσετε και να ρυθμίσετε το QuickSight, ανατρέξτε στο Δημιουργία ενός συνόλου δεδομένων χρησιμοποιώντας μια βάση δεδομένων που δεν ανακαλύπτεται αυτόματα.
Αφού δημιουργήσετε την πηγή δεδομένων σας στο QuickSight, ενώνουμε τα μοντελοποιημένα δεδομένα (data mart) με βάση το υποκατάστατο κλειδί μας skey. Χρησιμοποιούμε αυτό το σύνολο δεδομένων για να οπτικοποιήσουμε το data mart.

Ο τελικός μας πίνακας εργαλείων θα περιέχει τις πληροφορίες σχετικά με την τεχνολογία δεδομένων και θα απαντά σε κρίσιμα επιχειρηματικά ερωτήματα, όπως η συνολική προμήθεια ανά χώρο και οι ημερομηνίες με τις υψηλότερες πωλήσεις. Το παρακάτω στιγμιότυπο οθόνης δείχνει το τελικό προϊόν του data mart.

εκκαθάριση
Για να αποφύγετε μελλοντικές χρεώσεις, διαγράψτε τυχόν πόρους που δημιουργήσατε ως μέρος αυτής της ανάρτησης.
Συμπέρασμα
Έχουμε πλέον εφαρμόσει με επιτυχία ένα data mart χρησιμοποιώντας το δικό μας DimVenue, DimCalendar, να FactSaleTransactions τραπέζια. Η αποθήκη μας δεν είναι πλήρης. καθώς μπορούμε να επεκτείνουμε την αγορά δεδομένων με περισσότερα στοιχεία και να εφαρμόσουμε περισσότερες μάρκες, και καθώς η επιχειρηματική διαδικασία και οι απαιτήσεις αυξάνονται με την πάροδο του χρόνου, το ίδιο θα αυξάνει και η αποθήκη δεδομένων. Σε αυτήν την ανάρτηση, δώσαμε μια ολοκληρωμένη άποψη για την κατανόηση και την εφαρμογή μοντελοποίησης διαστάσεων στο Amazon Redshift.
Ξεκινήστε με το δικό σας Amazon RedShift διαστάσεων μοντέλο σήμερα.
Σχετικά με τους Συγγραφείς
 Μπέρναρντ Βέρστερ είναι ένας έμπειρος μηχανικός cloud με χρόνια έκθεσης στη δημιουργία επεκτάσιμων και αποτελεσματικών μοντέλων δεδομένων, στον καθορισμό στρατηγικών ενοποίησης δεδομένων και στη διασφάλιση διακυβέρνησης και ασφάλειας δεδομένων. Είναι παθιασμένος με τη χρήση δεδομένων για την ανάπτυξη γνώσεων, ενώ ευθυγραμμίζεται με τις επιχειρηματικές απαιτήσεις και στόχους.
Μπέρναρντ Βέρστερ είναι ένας έμπειρος μηχανικός cloud με χρόνια έκθεσης στη δημιουργία επεκτάσιμων και αποτελεσματικών μοντέλων δεδομένων, στον καθορισμό στρατηγικών ενοποίησης δεδομένων και στη διασφάλιση διακυβέρνησης και ασφάλειας δεδομένων. Είναι παθιασμένος με τη χρήση δεδομένων για την ανάπτυξη γνώσεων, ενώ ευθυγραμμίζεται με τις επιχειρηματικές απαιτήσεις και στόχους.
 Abhishek Pan είναι ειδικός της WWSO SA-Analytics που συνεργάζεται με πελάτες του δημόσιου τομέα της AWS India. Συνεργάζεται με πελάτες για να καθορίσει στρατηγική βάσει δεδομένων, να παρέχει συνεδρίες βαθιάς κατάδυσης σε περιπτώσεις χρήσης αναλυτικών στοιχείων και να σχεδιάζει επεκτάσιμες και αποδοτικές αναλυτικές εφαρμογές. Έχει 12 χρόνια εμπειρία και είναι παθιασμένος με τις βάσεις δεδομένων, τα αναλυτικά στοιχεία και την AI/ML. Είναι μανιώδης ταξιδιώτης και προσπαθεί να απαθανατίσει τον κόσμο μέσα από τον φωτογραφικό του φακό.
Abhishek Pan είναι ειδικός της WWSO SA-Analytics που συνεργάζεται με πελάτες του δημόσιου τομέα της AWS India. Συνεργάζεται με πελάτες για να καθορίσει στρατηγική βάσει δεδομένων, να παρέχει συνεδρίες βαθιάς κατάδυσης σε περιπτώσεις χρήσης αναλυτικών στοιχείων και να σχεδιάζει επεκτάσιμες και αποδοτικές αναλυτικές εφαρμογές. Έχει 12 χρόνια εμπειρία και είναι παθιασμένος με τις βάσεις δεδομένων, τα αναλυτικά στοιχεία και την AI/ML. Είναι μανιώδης ταξιδιώτης και προσπαθεί να απαθανατίσει τον κόσμο μέσα από τον φωτογραφικό του φακό.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Αυτοκίνητο / EVs, Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- BlockOffsets. Εκσυγχρονισμός της περιβαλλοντικής αντιστάθμισης ιδιοκτησίας. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :έχει
- :είναι
- :δεν
- :που
- $UP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Σχετικα
- επιταχύνουν
- πρόσβαση
- πρόσβαση
- με ακρίβεια
- απέναντι
- Πράξη
- προσθέτω
- προστιθέμενη
- Πρόσθετος
- Μετά το
- AI / ML
- ευθυγράμμιση
- ευθυγράμμιση
- επιτρέπουν
- επιτρέπει
- ήδη
- am
- Amazon
- Amazon υπηρεσίες Web
- an
- ανάλυση
- Αναλυτικός
- analytics
- αναλύσει
- και
- απάντηση
- κάθε
- εφαρμογές
- εφαρμοσμένος
- κατάλληλος
- αρχιτεκτονική
- ΕΙΝΑΙ
- τεχνητός
- AS
- πτυχές
- συσχετισμένη
- At
- γνωρίσματα
- αυτόματη
- αυτοματοποίηση
- αυτομάτως
- αποφύγετε
- AWS
- b
- βασίζονται
- BE
- επειδή
- αρχίζουν
- οφέλη
- ΚΑΛΎΤΕΡΟΣ
- ενσωματωμένο
- επιχείρηση
- επιχειρηματικής ευφυΐας
- Επιχειρηματική διαδικασία
- επιχειρηματικών διαδικασιών
- αλλά
- by
- Ημερολογιο
- κλήση
- που ονομάζεται
- κλήση
- φωτογραφική μηχανή
- CAN
- πιάνω
- περίπτωση
- περιπτώσεις
- Αιτία
- ορισμένες
- αλλαγή
- άλλαξε
- Αλλαγές
- αλλαγή
- χαρακτήρας
- φορτία
- Επιλέξτε
- καθαρός
- σαφώς
- στενά
- Backup
- κωδικός
- Στήλη
- έρχεται
- παραπομπής σας
- Κοινός
- Εταιρείες
- εταίρα
- πλήρης
- Εξετάστε
- συνεπής
- αποτελείται
- συμφραζόμενα
- διορθώσει
- θα μπορούσε να
- δημιουργία
- δημιουργήθηκε
- δημιουργεί
- δημιουργία
- δημιουργία
- κρίσιμης
- Πελάτες
- καθημερινά
- ταμπλό
- dashboards
- ημερομηνία
- ολοκλήρωση δεδομένων
- Λίμνη δεδομένων
- αποθήκη δεδομένων
- βασίζονται σε δεδομένα
- Στρατηγική με γνώμονα τα δεδομένα
- βάση δεδομένων
- βάσεις δεδομένων
- Ημερομηνία
- Ημερομηνίες
- ημερομηνία
- ημέρα
- βαθύς
- βαθιά κατάδυση
- Προεπιλογή
- καθορίζοντας
- παραδώσει
- αποδεικνύουν
- τμήματα
- Συμπληρωματικός
- περιγράφουν
- Υπηρεσίες
- σχέδιο
- λεπτομέρεια
- συσκευή
- διαφορετικές
- Διάσταση
- Διαστάσεις
- συζητήσουν
- διακριτή
- διανομή
- do
- τομέα
- γίνεται
- Μην
- κάτω
- αυτοκίνητο
- αντίγραφα
- κάθε
- Νωρίτερα
- εύκολα
- εύκολος
- συντάκτης
- αποτελεσματικός
- είτε
- ενσωματωμένο
- ενεργοποιήσετε
- ενεργοποίηση
- τέλος
- από άκρη σε άκρη
- δεσμεύεται
- μηχανικός
- εξασφαλίζω
- εξασφαλίζει
- εξασφαλίζοντας
- Ολόκληρος
- οντότητα
- Αιθέρας (ΕΤΗ)
- Συμβάν
- εκδηλώσεις
- Κάθε
- κάθε μέρα
- παράδειγμα
- παραδείγματα
- Ανάπτυξη
- εμπειρία
- έμπειρος
- Έκθεση
- εκχύλισμα
- γεγονός
- παράγοντας
- παράγοντες
- γεγονότα
- αποτυγχάνει
- Αποτυχία
- Χαρακτηριστικά
- λίγοι
- πεδίο
- Πεδία
- πέμπτος
- Εικόνα
- φιλτράρισμα
- τελικός
- Όνομα
- πρώτη φορά
- ταιριάζουν
- επικεντρώθηκε
- Εξής
- Για
- μορφή
- μορφή
- τέσσερα
- από
- πλήρως
- περαιτέρω
- μελλοντικός
- Κέρδος
- παράγουν
- παράγεται
- δημιουργεί
- παίρνω
- να πάρει
- Δώστε
- δεδομένου
- καλός
- διακυβέρνησης
- Grow
- κινητός
- Έχω
- he
- υψηλότερο
- του
- ιστορικών
- Αργία
- Πως
- Πώς να
- HTML
- http
- HTTPS
- IAM
- προσδιορίζονται
- προσδιορίσει
- προσδιορισμό
- Ταυτότητα
- if
- απεικονίζει
- Επίπτωση
- εφαρμογή
- εφαρμοστεί
- εκτελεστικών
- σημαντικό
- βελτίωση
- βελτίωση
- in
- Συμπεριλαμβανομένου
- Ινδία
- υποδεικνύω
- υποδεικνύοντας
- πληροφορίες
- ιδέες
- ενσωματωθεί
- ολοκλήρωση
- ακεραιότητα
- Νοημοσύνη
- διαδραστικό
- σε
- IT
- ΤΟΥ
- ενταχθούν
- εντάχθηκαν
- ενώνει
- Ενώνει
- jpg
- Διατήρηση
- τήρηση
- Κλειδί
- πλήκτρα
- λίμνη
- Γλώσσα
- αργότερα
- αργότερο
- στρώμα
- αριστερά
- Φακός
- Αφήνει
- Επίπεδο
- γραμμή
- φορτίο
- φόρτωση
- φορτία
- που βρίσκεται
- κοιτάζοντας
- που
- ΚΑΝΕΙ
- διαχειρίζεται
- Μάρκετινγκ
- συμφωνημένα
- νόημα
- μέτρο
- που αναφέρθηκαν
- πηγαίνω
- Metrics
- νου
- λάθος
- μοντέλο
- μοντελοποίηση
- πρίπλασμα
- μοντέλα
- Μηνας
- περισσότερο
- πλέον
- πολλαπλούς
- ονόματα
- Φυσικό
- Πλοηγηθείτε
- Ανάγκη
- χρειάζονται
- ανάγκες
- Νέα
- Notes
- κοινοποίηση
- κοινοποιήσεις
- τώρα
- πολυάριθμες
- στόχοι
- of
- προσφορά
- συχνά
- on
- αποκλειστικά
- επιχειρήσεων
- or
- επιχειρήσεις
- δικός μας
- επί
- φόρμες
- παράμετρος
- μέρος
- παθιασμένος
- για
- εκτελέσει
- επίδοση
- ίσως
- περιοδικός
- Μέρος
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- Σημείο
- κατοικημένη περιοχή
- Θέση
- δύναμη
- πρακτική
- προαπαιτούμενα
- παρόν
- πρωταρχικός
- διαδικασία
- διαδικασίες
- διαδικασια μας
- Διεργασίες
- Προϊόν
- παρέχουν
- παρέχεται
- παρέχει
- δημόσιο
- δημοσιεύει
- σκοποί
- Ερωτήσεις
- γρήγορα
- αύξηση
- Ακατέργαστος
- ακατέργαστα δεδομένα
- ρεκόρ
- αρχεία
- μείωση
- αναφέρεται
- αντικατοπτρίζει
- περιοχή
- σχέση
- λείψανα
- αφαιρέστε
- αντικαθιστώ
- αναφέρουν
- Αναφορά
- Εκθέσεις
- απαιτήσεις
- Υποστηρικτικό υλικό
- ευθύνη
- Ρόλος
- Ρολό
- ΣΕΙΡΑ
- τρέξιμο
- τρέχει
- πώληση
- εμπορικός
- ίδιο
- Δείγμα δεδομένων
- επεκτάσιμη
- πρόγραμμα
- προγραμματισμός
- τμήματα
- τομέας
- ασφάλεια
- δείτε
- ξεχωριστό
- εξυπηρετεί
- υπηρεσία
- Υπηρεσίες
- συνεδρίες
- σειρά
- διάφοροι
- θα πρέπει να
- δείχνουν
- Δείχνει
- Απλούς
- απλότητα
- ενιαίας
- Αργά
- small
- μικρότερος
- Στιγμιότυπο
- So
- πωλούνται
- λύση
- μερικοί
- Πηγή
- Πηγές
- Χώρος
- ειδικός
- συγκεκριμένες
- ειδικά
- Στάδιο
- σκαλωσιά
- Αστέρι
- ξεκίνησε
- Ξεκινήστε
- Δήλωση
- Βήμα
- Βήματα
- χώρος στο δίσκο
- κατάστημα
- αποθηκεύονται
- στρατηγικές
- Στρατηγική
- δομή
- επιτυχής
- Επιτυχώς
- τέτοιος
- σύστημα
- τραπέζι
- προσωρινή
- δεκάδες
- όροι
- από
- ότι
- Η
- Η Πηγη
- ο κόσμος
- τους
- τότε
- Εκεί.
- επομένως
- Αυτοί
- αυτοί
- αυτό
- χιλιάδες
- Μέσω
- εισιτήριο
- πωλήσεις εισιτηρίων
- εισιτήρια
- ώρα
- φορές
- timestamp
- συμβουλές
- προς την
- σήμερα
- μαζι
- πήρε
- Σύνολο
- τροχιά
- συναλλαγή
- Μεταμορφώστε
- μετασχηματίζεται
- ταξιδιώτης
- τύπος
- τύποι
- συνήθως
- κατανόηση
- μοναδικός
- μοναδικώς
- μοναδικότητα
- άγνωστος
- Ενημέρωση
- ενημερώθηκε
- us
- Χρήση
- χρήση
- περίπτωση χρήσης
- μεταχειρισμένος
- Χρήστες
- χρησιμοποιεί
- χρησιμοποιώντας
- συνήθως
- Πολύτιμος
- αξία
- Αξίες
- διάφορα
- Χώρος δεξίωσης
- χώρους
- μέσω
- Δες
- τόμος
- περιδιάβαση
- θέλω
- Αποθήκη
- ήταν
- τρόπους
- we
- ιστός
- διαδικτυακές υπηρεσίες
- ιστοσελίδες
- εβδομάδα
- πότε
- Ποιό
- ενώ
- θα
- με
- εντός
- χωρίς
- εργαζόμενος
- κόσμος
- Λανθασμένος
- έτος
- χρόνια
- εσείς
- Σας
- zephyrnet