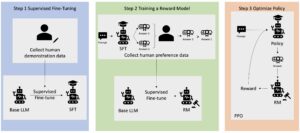
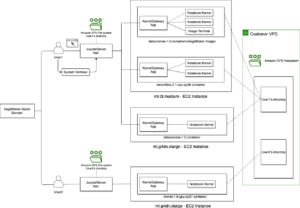
Αυτή είναι μια κοινή ανάρτηση που συντάχθηκε από τους AWS και Voxel51. Η Voxel51 είναι η εταιρεία πίσω από το FiftyOne, το κιτ εργαλείων ανοιχτού κώδικα για τη δημιουργία συνόλων δεδομένων υψηλής ποιότητας και μοντέλων υπολογιστικής όρασης.
Μια εταιρεία λιανικής κατασκευάζει μια εφαρμογή για κινητά για να βοηθήσει τους πελάτες να αγοράσουν ρούχα. Για να δημιουργήσουν αυτήν την εφαρμογή, χρειάζονται ένα σύνολο δεδομένων υψηλής ποιότητας που περιέχει εικόνες ρούχων, με ετικέτα διαφορετικές κατηγορίες. Σε αυτήν την ανάρτηση, δείχνουμε πώς να επαναπροσδιορίσετε ένα υπάρχον σύνολο δεδομένων μέσω καθαρισμού δεδομένων, προεπεξεργασίας και προεπισήμανσης με ένα μοντέλο ταξινόμησης μηδενικής λήψης σε Πενήντα ένακαι προσαρμόζοντας αυτές τις ετικέτες με Amazon SageMaker Ground Αλήθεια.
Μπορείτε να χρησιμοποιήσετε το Ground Truth και το FiftyOne για να επιταχύνετε το έργο επισήμανσης δεδομένων. Δείχνουμε πώς να χρησιμοποιείτε απρόσκοπτα τις δύο εφαρμογές μαζί για τη δημιουργία συνόλων δεδομένων υψηλής ποιότητας με ετικέτα. Για το παράδειγμά μας, εργαζόμαστε με το Δεδομένα Fashion200K, κυκλοφόρησε στο ICCV 2017.
Επισκόπηση λύσεων
Το Ground Truth είναι μια πλήρως αυτοεξυπηρετούμενη και διαχειριζόμενη υπηρεσία επισήμανσης δεδομένων που εξουσιοδοτεί επιστήμονες δεδομένων, μηχανικούς μηχανικής μάθησης (ML) και ερευνητές να δημιουργήσουν σύνολα δεδομένων υψηλής ποιότητας. Πενήντα ένα by voxel51 είναι μια εργαλειοθήκη ανοιχτού κώδικα για την επιμέλεια, την οπτικοποίηση και την αξιολόγηση συνόλων δεδομένων υπολογιστικής όρασης, ώστε να μπορείτε να εκπαιδεύσετε και να αναλύσετε καλύτερα μοντέλα επιταχύνοντας τις περιπτώσεις χρήσης σας.
Στις παρακάτω ενότητες, δείχνουμε πώς να κάνετε τα εξής:
- Οπτικοποιήστε το σύνολο δεδομένων στο FiftyOne
- Καθαρίστε το σύνολο δεδομένων με φιλτράρισμα και απεγγραφή εικόνας στο FiftyOne
- Προτιμήστε τα καθαρισμένα δεδομένα με ταξινόμηση zero-shot στο FiftyOne
- Επισημάνετε το μικρότερο επιμελημένο σύνολο δεδομένων με Ground Truth
- Εισάγετε τα αποτελέσματα με ετικέτα από το Ground Truth στο FiftyOne και ελέγξτε τα αποτελέσματα με ετικέτα στο FiftyOne
Χρησιμοποιήστε επισκόπηση περίπτωσης
Ας υποθέσουμε ότι είστε ιδιοκτήτης μιας εταιρείας λιανικής και θέλετε να δημιουργήσετε μια εφαρμογή για κινητά για να δίνετε εξατομικευμένες προτάσεις για να βοηθήσετε τους χρήστες να αποφασίσουν τι θα φορέσουν. Οι υποψήφιοι χρήστες σας αναζητούν μια εφαρμογή που τους λέει ποια ρούχα στην ντουλάπα τους συνεργάζονται καλά μεταξύ τους. Βλέπετε μια ευκαιρία εδώ: εάν μπορείτε να εντοπίσετε καλά ρούχα, μπορείτε να το χρησιμοποιήσετε για να προτείνετε νέα είδη ένδυσης που συμπληρώνουν τα ρούχα που έχει ήδη ένας πελάτης.
Θέλετε να κάνετε τα πράγματα όσο το δυνατόν πιο εύκολα για τον τελικό χρήστη. Στην ιδανική περίπτωση, κάποιος που χρησιμοποιεί την εφαρμογή σας χρειάζεται μόνο να τραβήξει φωτογραφίες των ρούχων στην γκαρνταρόμπα του και τα μοντέλα ML σας κάνουν τη μαγεία τους στα παρασκήνια. Μπορείτε να εκπαιδεύσετε ένα μοντέλο γενικής χρήσης ή να προσαρμόσετε ένα μοντέλο στο μοναδικό στυλ κάθε χρήστη με κάποια μορφή σχολίων.
Πρώτα, ωστόσο, πρέπει να προσδιορίσετε τον τύπο ρούχων που συλλαμβάνει ο χρήστης. Είναι πουκάμισο; Ένα παντελόνι; Ή κάτι άλλο? Εξάλλου, μάλλον δεν θέλετε να προτείνετε ένα ρούχο που έχει πολλά φορέματα ή πολλά καπέλα.
Για να αντιμετωπίσετε αυτήν την αρχική πρόκληση, θέλετε να δημιουργήσετε ένα σύνολο δεδομένων εκπαίδευσης που να αποτελείται από εικόνες διαφόρων ειδών ένδυσης με διάφορα μοτίβα και στυλ. Για να δημιουργήσετε πρωτότυπο με περιορισμένο προϋπολογισμό, θέλετε να κάνετε bootstrap χρησιμοποιώντας ένα υπάρχον σύνολο δεδομένων.
Για να σας δείξουμε και να σας καθοδηγήσουμε στη διαδικασία σε αυτήν την ανάρτηση, χρησιμοποιούμε το σύνολο δεδομένων Fashion200K που κυκλοφόρησε στο ICCV 2017. Είναι ένα καθιερωμένο και καλά αναφερόμενο σύνολο δεδομένων, αλλά δεν είναι άμεσα κατάλληλο για την περίπτωση χρήσης σας.
Παρόλο που τα είδη ένδυσης επισημαίνονται με κατηγορίες (και υποκατηγορίες) και περιέχουν μια ποικιλία από χρήσιμες ετικέτες που εξάγονται από τις αρχικές περιγραφές προϊόντων, τα δεδομένα δεν επισημαίνονται συστηματικά με πληροφορίες μοτίβων ή στυλ. Ο στόχος σας είναι να μετατρέψετε αυτό το υπάρχον σύνολο δεδομένων σε ένα ισχυρό σύνολο δεδομένων εκπαίδευσης για τα μοντέλα ταξινόμησης ρούχων σας. Πρέπει να καθαρίσετε τα δεδομένα, αυξάνοντας το σχήμα ετικετών με ετικέτες στυλ. Και θέλετε να το κάνετε γρήγορα και με όσο το δυνατόν λιγότερα έξοδα.
Λήψη των δεδομένων τοπικά
Αρχικά, πραγματοποιήστε λήψη του αρχείου zip women.tar και του φακέλου labels (με όλους τους υποφακέλους του) ακολουθώντας τις οδηγίες που παρέχονται στο Αποθετήριο δεδομένων Fashion200K GitHub. Αφού τα αποσυμπιέσετε και τα δύο, δημιουργήστε έναν γονικό κατάλογο fashion200k και μετακινήστε τις ετικέτες και τους φακέλους γυναικών σε αυτόν. Ευτυχώς, αυτές οι εικόνες έχουν ήδη περικοπεί στα πλαίσια οριοθέτησης ανίχνευσης αντικειμένων, επομένως μπορούμε να επικεντρωθούμε στην ταξινόμηση, αντί να ανησυχούμε για τον εντοπισμό αντικειμένων.
Παρά το «200K» στο παρατσούκλι του, ο κατάλογος γυναικών που εξάγαμε περιέχει 338,339 εικόνες. Για να δημιουργήσουν το επίσημο σύνολο δεδομένων Fashion200K, οι συντάκτες του συνόλου δεδομένων ανίχνευσαν περισσότερα από 300,000 προϊόντα στο Διαδίκτυο και μόνο προϊόντα με περιγραφές που περιέχουν περισσότερες από τέσσερις λέξεις έκαναν την περικοπή. Για τους σκοπούς μας, όπου η περιγραφή του προϊόντος δεν είναι απαραίτητη, μπορούμε να χρησιμοποιήσουμε όλες τις ανιχνευμένες εικόνες.
Ας δούμε πώς είναι οργανωμένα αυτά τα δεδομένα: εντός του φακέλου γυναικών, οι εικόνες ταξινομούνται ανά τύπο άρθρου κορυφαίου επιπέδου (φούστες, μπλούζες, παντελόνια, σακάκια και φορέματα) και υποκατηγορία τύπου άρθρου (μπλούζες, μπλουζάκια, μακρυμάνικα άριστος).
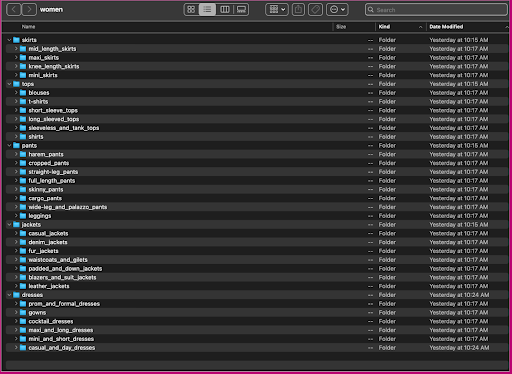
Μέσα στους καταλόγους υποκατηγοριών, υπάρχει ένας υποκατάλογος για κάθε καταχώριση προϊόντων. Κάθε ένα από αυτά περιέχει έναν μεταβλητό αριθμό εικόνων. Η υποκατηγορία cropped_pants, για παράδειγμα, περιέχει τις ακόλουθες λίστες προϊόντων και σχετικές εικόνες.
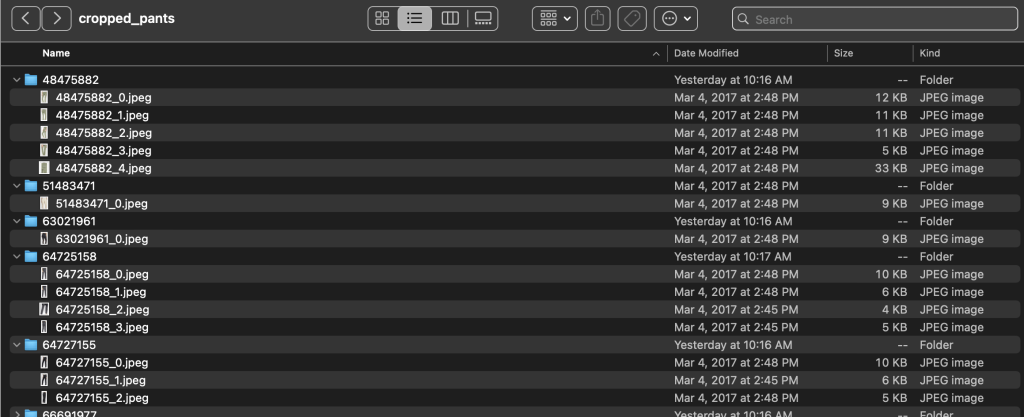
Ο φάκελος ετικετών περιέχει ένα αρχείο κειμένου για κάθε τύπο άρθρου ανώτατου επιπέδου, τόσο για διαχωρισμό αμαξοστοιχίας όσο και για δοκιμαστική διαίρεση. Μέσα σε καθένα από αυτά τα αρχεία κειμένου υπάρχει μια ξεχωριστή γραμμή για κάθε εικόνα, που καθορίζει τη σχετική διαδρομή αρχείου, μια βαθμολογία και ετικέτες από την περιγραφή του προϊόντος.
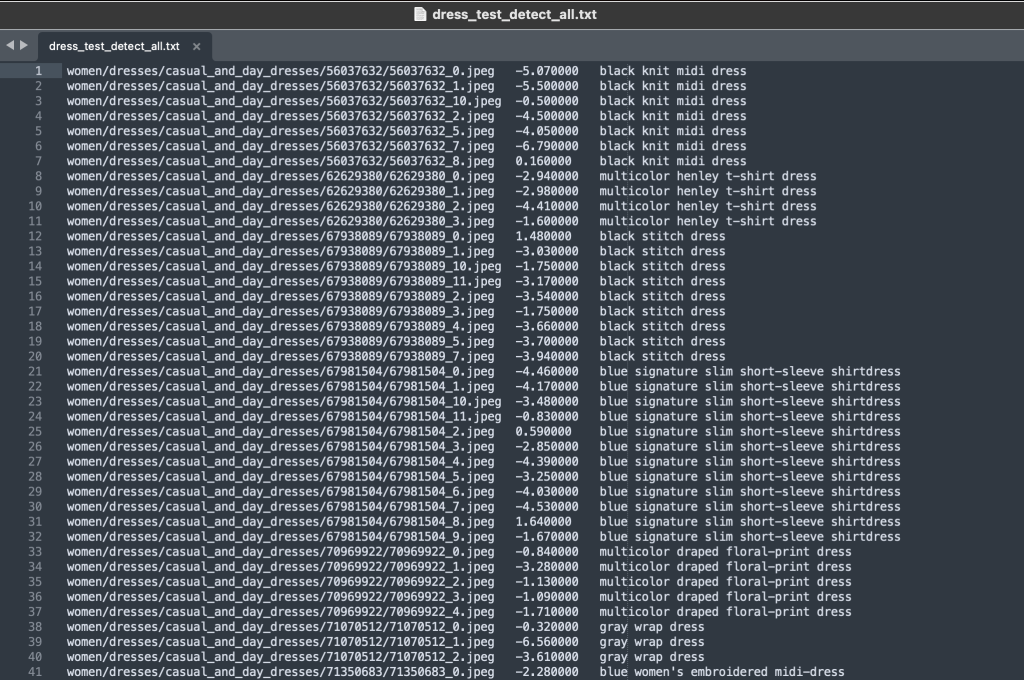
Επειδή επανατοποθετούμε το σύνολο δεδομένων, συνδυάζουμε όλες τις εικόνες τρένου και δοκιμής. Τα χρησιμοποιούμε για να δημιουργήσουμε ένα υψηλής ποιότητας σύνολο δεδομένων για συγκεκριμένες εφαρμογές. Αφού ολοκληρώσουμε αυτή τη διαδικασία, μπορούμε τυχαία να χωρίσουμε το σύνολο δεδομένων που προκύπτει σε νέα τμήματα αμαξοστοιχίας και δοκιμής.
Εισαγωγή, προβολή και επεξεργασία ενός συνόλου δεδομένων στο FiftyOne
Εάν δεν το έχετε κάνει ήδη, εγκαταστήστε το FiftyOne ανοιχτού κώδικα χρησιμοποιώντας το pip:
Μια καλύτερη πρακτική είναι να το κάνετε σε ένα νέο εικονικό περιβάλλον (venv ή conda). Στη συνέχεια, εισάγετε τις σχετικές ενότητες. Εισαγάγετε τη βασική βιβλιοθήκη, το fiftyone, το FiftyOne Brain, το οποίο έχει ενσωματωμένες μεθόδους ML, το FiftyOne Zoo, από το οποίο θα φορτώσουμε ένα μοντέλο που θα δημιουργήσει ετικέτες zero-shot για εμάς και το ViewField, το οποίο μας επιτρέπει να φιλτράρουμε αποτελεσματικά το δεδομένα στο σύνολο δεδομένων μας:
Θέλετε επίσης να εισαγάγετε τις λειτουργικές μονάδες glob και os Python, οι οποίες θα μας βοηθήσουν να εργαστούμε με μονοπάτια και αντιστοίχιση μοτίβων σε περιεχόμενα καταλόγου:
Τώρα είμαστε έτοιμοι να φορτώσουμε το σύνολο δεδομένων στο FiftyOne. Αρχικά, δημιουργούμε ένα σύνολο δεδομένων με το όνομα fashion200k και το κάνουμε επίμονο, το οποίο μας επιτρέπει να αποθηκεύουμε τα αποτελέσματα υπολογιστικά εντατικών λειτουργιών, επομένως χρειάζεται να υπολογίσουμε τις εν λόγω ποσότητες μόνο μία φορά.
Μπορούμε τώρα να επαναλάβουμε όλους τους καταλόγους υποκατηγοριών, προσθέτοντας όλες τις εικόνες στους καταλόγους προϊόντων. Προσθέτουμε μια ετικέτα ταξινόμησης FiftyOne σε κάθε δείγμα με το όνομα πεδίου article_type, που συμπληρώνεται από την κατηγορία άρθρου ανώτατου επιπέδου της εικόνας. Προσθέτουμε επίσης πληροφορίες κατηγορίας και υποκατηγορίας ως ετικέτες:
Σε αυτό το σημείο, μπορούμε να οπτικοποιήσουμε το σύνολο δεδομένων μας στην εφαρμογή FiftyOne ξεκινώντας μια περίοδο λειτουργίας:
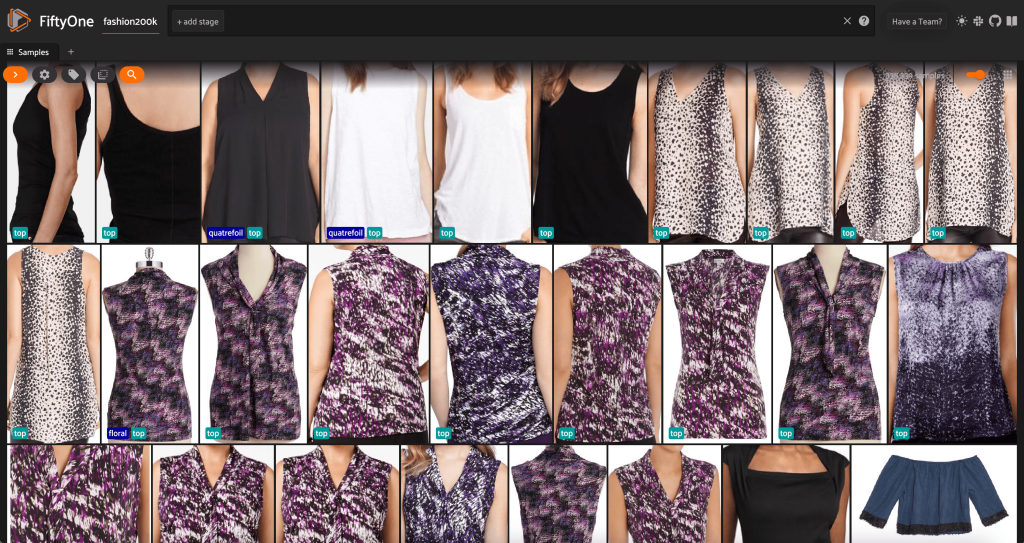
Μπορούμε επίσης να εκτυπώσουμε μια περίληψη του συνόλου δεδομένων στην Python εκτελώντας print(dataset):
Μπορούμε επίσης να προσθέσουμε τις ετικέτες από το labels κατάλογο στα δείγματα στο σύνολο δεδομένων μας:
Βλέποντας τα δεδομένα, μερικά πράγματα γίνονται ξεκάθαρα:
- Μερικές από τις εικόνες είναι αρκετά κοκκώδεις, με χαμηλή ανάλυση. Αυτό είναι πιθανό επειδή αυτές οι εικόνες δημιουργήθηκαν με την περικοπή αρχικών εικόνων σε πλαίσια οριοθέτησης ανίχνευσης αντικειμένων.
- Κάποια ρούχα φοριούνται από ένα άτομο και μερικά φωτογραφίζονται μόνα τους. Αυτές οι λεπτομέρειες περικλείονται από το
viewpointιδιοκτησία. - Πολλές από τις εικόνες του ίδιου προϊόντος είναι πολύ παρόμοιες, επομένως, τουλάχιστον αρχικά, η συμπερίληψη περισσότερων από μία εικόνων ανά προϊόν ενδέχεται να μην προσθέτει μεγάλη προγνωστική ισχύ. Ως επί το πλείστον, η πρώτη εικόνα κάθε προϊόντος (λήγει σε
_0.jpeg) είναι το πιο καθαρό.
Αρχικά, μπορεί να θέλουμε να εκπαιδεύσουμε το μοντέλο ταξινόμησης στυλ ρούχων σε ένα ελεγχόμενο υποσύνολο αυτών των εικόνων. Για το σκοπό αυτό, χρησιμοποιούμε εικόνες υψηλής ανάλυσης των προϊόντων μας και περιορίζουμε την προβολή μας σε ένα αντιπροσωπευτικό δείγμα ανά προϊόν.
Αρχικά, φιλτράρουμε τις εικόνες χαμηλής ανάλυσης. Χρησιμοποιούμε το compute_metadata() μέθοδος υπολογισμού και αποθήκευσης πλάτους και ύψους εικόνας, σε pixel, για κάθε εικόνα στο σύνολο δεδομένων. Στη συνέχεια, χρησιμοποιούμε το FiftyOne ViewField για να φιλτράρετε εικόνες με βάση τις ελάχιστες επιτρεπόμενες τιμές πλάτους και ύψους. Δείτε τον παρακάτω κώδικα:
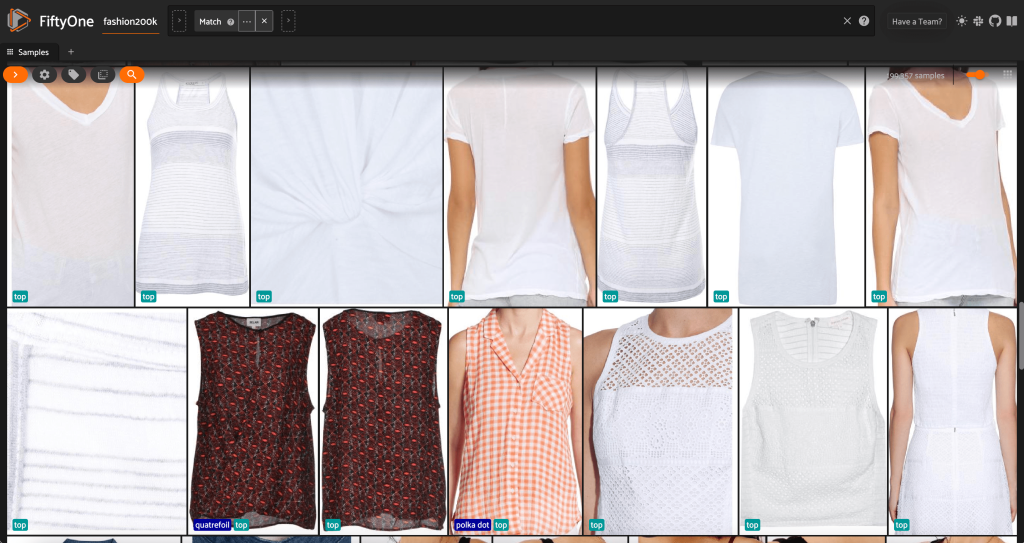
Αυτό το υποσύνολο υψηλής ανάλυσης έχει λιγότερο από 200,000 δείγματα.
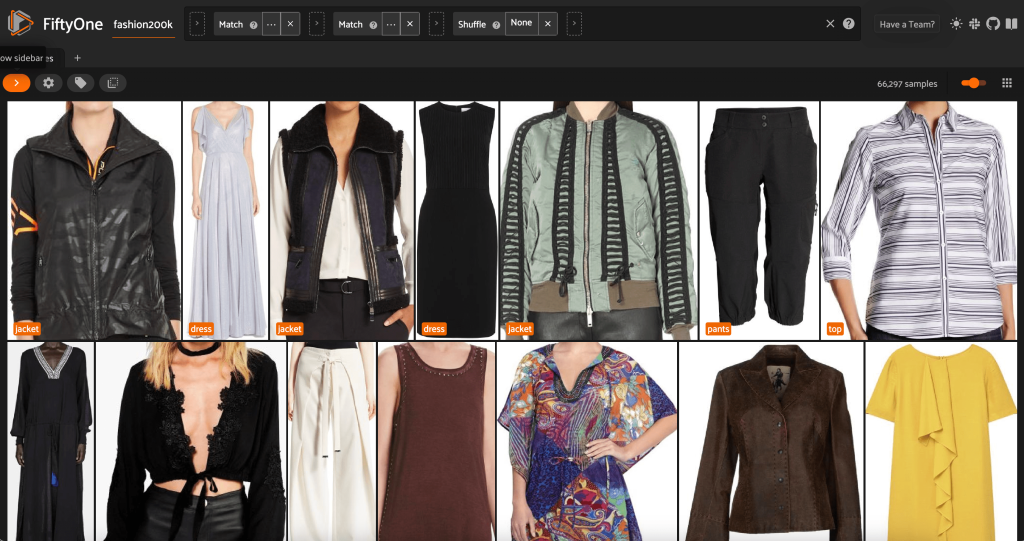
Από αυτήν την προβολή, μπορούμε να δημιουργήσουμε μια νέα προβολή στο σύνολο δεδομένων μας που περιέχει μόνο ένα αντιπροσωπευτικό δείγμα (το πολύ) για κάθε προϊόν. Χρησιμοποιούμε το ViewField για άλλη μια φορά, αντιστοίχιση μοτίβων για διαδρομές αρχείων που τελειώνουν με _0.jpeg:
Ας δούμε μια τυχαία τυχαία σειρά εικόνων σε αυτό το υποσύνολο:
Καταργήστε τις περιττές εικόνες στο σύνολο δεδομένων
Αυτή η προβολή περιέχει 66,297 εικόνες ή λίγο περισσότερο από το 19% του αρχικού συνόλου δεδομένων. Όταν κοιτάμε τη θέα, όμως, βλέπουμε ότι υπάρχουν πολλά παρόμοια προϊόντα. Η διατήρηση όλων αυτών των αντιγράφων πιθανότατα θα προσθέσει μόνο κόστος στην εκπαίδευση ετικετών και μοντέλων, χωρίς να βελτιώσει αισθητά την απόδοση. Αντ 'αυτού, ας απαλλαγούμε από τα σχεδόν διπλότυπα για να δημιουργήσουμε ένα μικρότερο σύνολο δεδομένων που εξακολουθεί να έχει την ίδια γροθιά.
Επειδή αυτές οι εικόνες δεν είναι ακριβώς διπλότυπες, δεν μπορούμε να ελέγξουμε για ισότητα εικονοστοιχείων. Ευτυχώς, μπορούμε να χρησιμοποιήσουμε το FiftyOne Brain για να μας βοηθήσει να καθαρίσουμε το σύνολο δεδομένων μας. Συγκεκριμένα, θα υπολογίσουμε μια ενσωμάτωση για κάθε εικόνα - ένα διάνυσμα χαμηλότερης διάστασης που αντιπροσωπεύει την εικόνα - και στη συνέχεια θα αναζητήσουμε εικόνες των οποίων τα διανύσματα ενσωμάτωσης είναι κοντά το ένα στο άλλο. Όσο πιο κοντά είναι τα διανύσματα, τόσο πιο όμοιες είναι οι εικόνες.
Χρησιμοποιούμε ένα μοντέλο CLIP για να δημιουργήσουμε ένα διάνυσμα ενσωμάτωσης 512 διαστάσεων για κάθε εικόνα και να αποθηκεύσουμε αυτές τις ενσωματώσεις στις ενσωματώσεις πεδίου στα δείγματα στο σύνολο δεδομένων μας:
Στη συνέχεια υπολογίζουμε την εγγύτητα μεταξύ των ενσωματώσεων, χρησιμοποιώντας ομοιότητα συνημίτονοκαι βεβαιωθείτε ότι οποιαδήποτε δύο διανύσματα των οποίων η ομοιότητα είναι μεγαλύτερη από κάποιο όριο είναι πιθανό να είναι σχεδόν διπλά. Οι βαθμολογίες ομοιότητας συνημιτονίου βρίσκονται στο εύρος [0, 1] και κοιτάζοντας τα δεδομένα, μια βαθμολογία κατωφλίου thresh=0.5 φαίνεται να είναι περίπου σωστή. Και πάλι, αυτό δεν χρειάζεται να είναι τέλειο. Λίγες σχεδόν διπλότυπες εικόνες δεν είναι πιθανό να καταστρέψουν την προγνωστική μας δύναμη και η απόρριψη μερικών μη διπλότυπων εικόνων δεν επηρεάζει ουσιαστικά την απόδοση του μοντέλου.
Μπορούμε να προβάλουμε τα υποτιθέμενα διπλότυπα για να επαληθεύσουμε ότι είναι πράγματι περιττά:
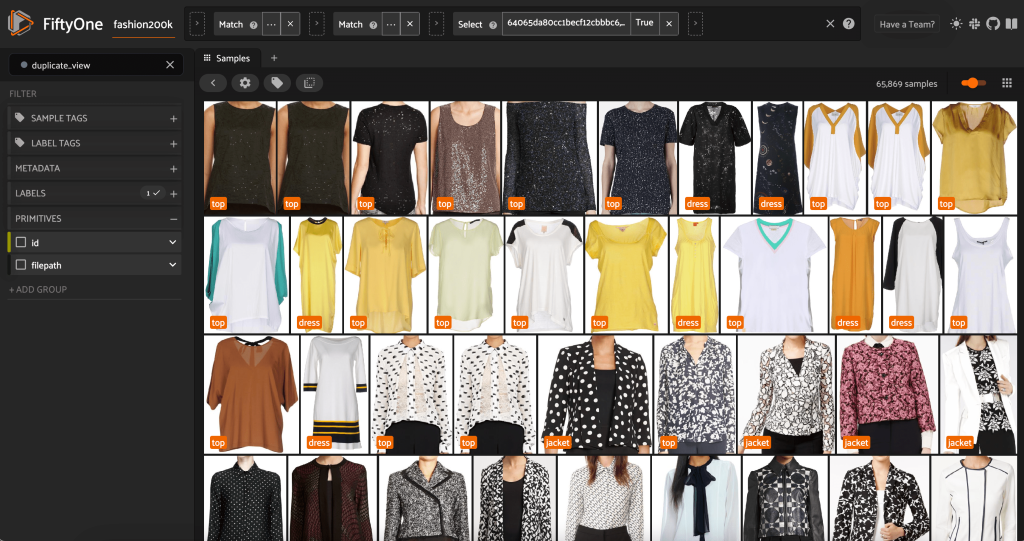
Όταν είμαστε ευχαριστημένοι με το αποτέλεσμα και πιστεύουμε ότι αυτές οι εικόνες είναι όντως διπλότυπες, μπορούμε να διαλέξουμε ένα δείγμα από κάθε σύνολο παρόμοιων δειγμάτων για να κρατήσουμε και να αγνοήσουμε τα άλλα:
Τώρα αυτή η προβολή έχει 3,729 εικόνες. Καθαρίζοντας τα δεδομένα και προσδιορίζοντας ένα υποσύνολο υψηλής ποιότητας του συνόλου δεδομένων Fashion200K, το FiftyOne μάς επιτρέπει να περιορίσουμε την εστίασή μας από περισσότερες από 300,000 εικόνες σε κάτι λιγότερο από 4,000, που αντιπροσωπεύει μείωση κατά 98%. Μόνο η χρήση ενσωματώσεων για την αφαίρεση σχεδόν διπλότυπων εικόνων μείωσε τον συνολικό αριθμό των υπό εξέταση εικόνων κατά περισσότερο από 90%, με ελάχιστη έως καθόλου επίδραση σε μοντέλα που θα εκπαιδευτούν σε αυτά τα δεδομένα.
Πριν από την προεπισήμανση αυτού του υποσυνόλου, μπορούμε να κατανοήσουμε καλύτερα τα δεδομένα οπτικοποιώντας τις ενσωματώσεις που έχουμε ήδη υπολογίσει. Μπορούμε να χρησιμοποιήσουμε το ενσωματωμένο FiftyOne Brain compute_visualization() μέθοδος, η οποία χρησιμοποιεί την τεχνική ομοιόμορφης πολλαπλής προσέγγισης (UMAP) για την προβολή των διανυσμάτων ενσωμάτωσης 512 διαστάσεων σε δισδιάστατο χώρο, ώστε να μπορούμε να τα οπτικοποιήσουμε:
Ανοίγουμε ένα νέο Πίνακας ενσωματώσεων στην εφαρμογή FiftyOne και χρωματισμός ανά τύπο άρθρου, και μπορούμε να δούμε ότι αυτές οι ενσωματώσεις κωδικοποιούν χονδρικά μια έννοια του τύπου άρθρου (μεταξύ άλλων!).
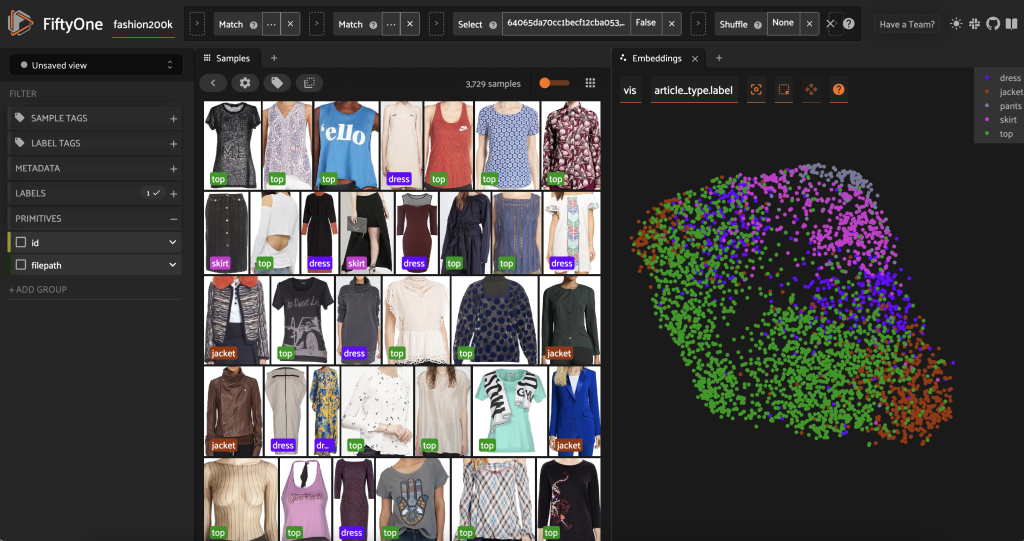
Τώρα είμαστε έτοιμοι να προεπισημάνουμε αυτά τα δεδομένα.
Επιθεωρώντας αυτές τις εξαιρετικά μοναδικές εικόνες υψηλής ανάλυσης, μπορούμε να δημιουργήσουμε μια αξιοπρεπή αρχική λίστα στυλ για χρήση ως κλάσεις στην ταξινόμηση μηδενικής λήψης πριν από την επισήμανση. Ο στόχος μας στην προεπισήμανση αυτών των εικόνων δεν είναι απαραίτητα να φέρουμε σωστά κάθε εικόνα. Αντίθετα, στόχος μας είναι να παρέχουμε ένα καλό σημείο εκκίνησης για τους ανθρώπινους σχολιαστές, ώστε να μπορούμε να μειώσουμε τον χρόνο και το κόστος της επισήμανσης.
Μπορούμε στη συνέχεια να δημιουργήσουμε ένα μοντέλο ταξινόμησης μηδενικής βολής για αυτήν την εφαρμογή. Χρησιμοποιούμε ένα μοντέλο CLIP, το οποίο είναι ένα μοντέλο γενικής χρήσης εκπαιδευμένο τόσο σε εικόνες όσο και σε φυσική γλώσσα. Δημιουργούμε ένα μοντέλο CLIP με την προτροπή κειμένου "Ρούχα στο στυλ", έτσι ώστε με μια εικόνα, το μοντέλο να βγάζει την κατηγορία για την οποία ταιριάζει καλύτερα το "Ρούχα στο στυλ [τάξη]". Το CLIP δεν είναι εκπαιδευμένο σε δεδομένα λιανικής ή ειδικά για τη μόδα, επομένως αυτό δεν θα είναι τέλειο, αλλά μπορεί να σας εξοικονομήσει κόστος ετικετών και σχολιασμού.
Στη συνέχεια εφαρμόζουμε αυτό το μοντέλο στο μειωμένο υποσύνολο μας και αποθηκεύουμε τα αποτελέσματα σε ένα article_style πεδίο:
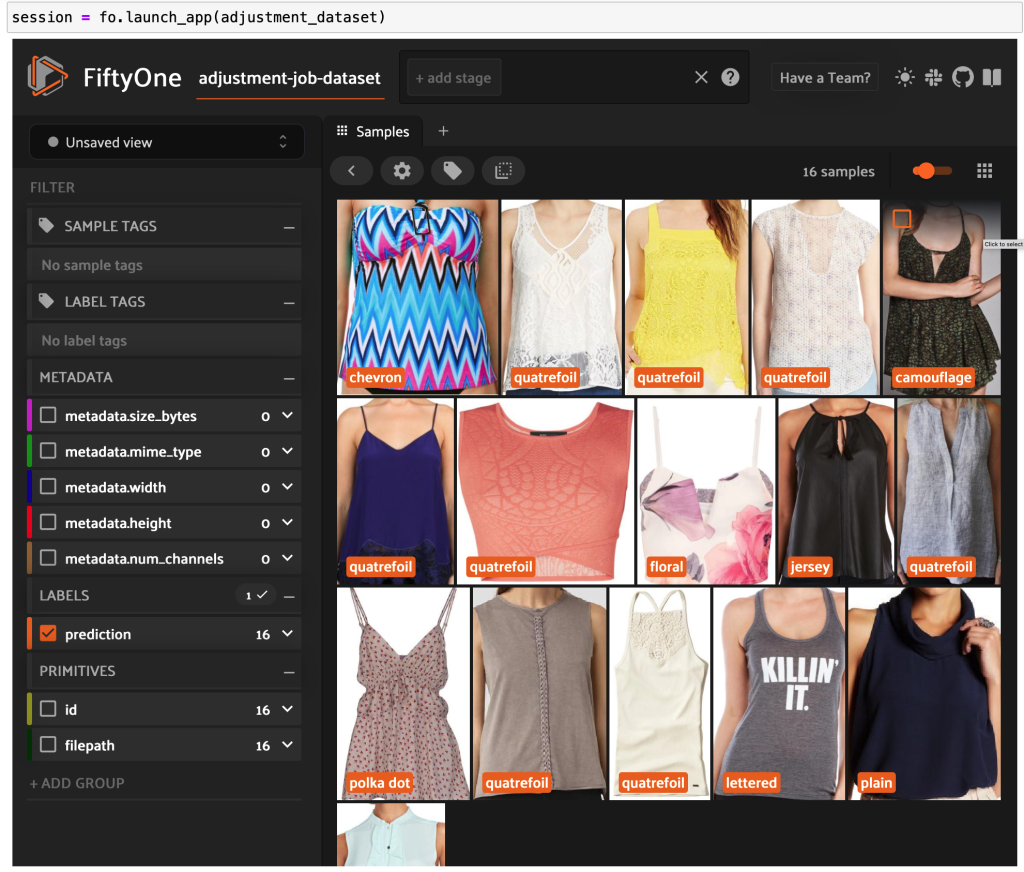
Ξεκινώντας ξανά την εφαρμογή FiftyOne, μπορούμε να οπτικοποιήσουμε τις εικόνες με αυτές τις προβλεπόμενες ετικέτες στυλ. Ταξινομούμε με βάση την εμπιστοσύνη πρόβλεψης, ώστε να βλέπουμε πρώτα τις πιο σίγουρες προβλέψεις στυλ:
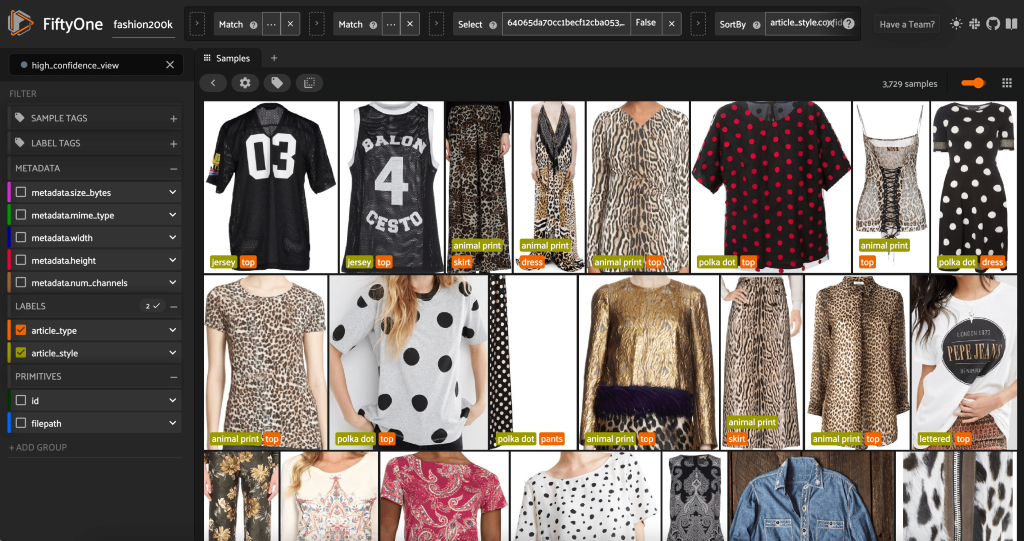
Μπορούμε να δούμε ότι οι προβλέψεις με την υψηλότερη εμπιστοσύνη φαίνεται να αφορούν τα στυλ «ζέρσεϊ», «ζωοτυπία», «πουά» και «γράμματα». Αυτό είναι λογικό, γιατί αυτά τα στυλ είναι σχετικά διαφορετικά. Φαίνεται επίσης ότι, ως επί το πλείστον, οι προβλεπόμενες ετικέτες στυλ είναι ακριβείς.
Μπορούμε επίσης να δούμε τις προβλέψεις στυλ χαμηλότερης εμπιστοσύνης:
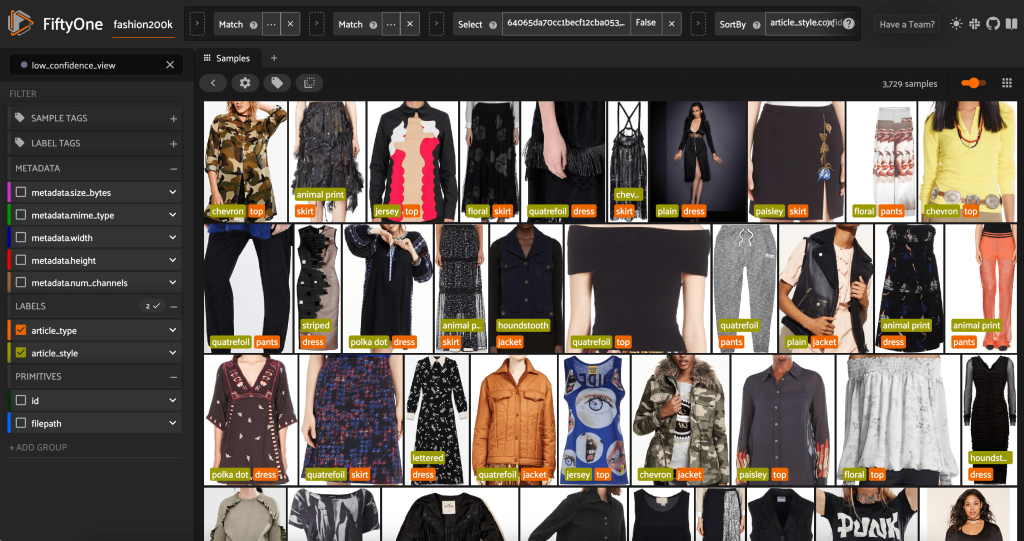
Για ορισμένες από αυτές τις εικόνες, η κατάλληλη κατηγορία στυλ βρίσκεται στη λίστα που παρέχεται και το ρούχο έχει εσφαλμένη ετικέτα. Η πρώτη εικόνα στο πλέγμα, για παράδειγμα, θα πρέπει να είναι ξεκάθαρα «καμουφλάζ» και όχι «σεβρόν». Σε άλλες περιπτώσεις, ωστόσο, τα προϊόντα δεν ταιριάζουν καλά στις κατηγορίες στυλ. Το φόρεμα στη δεύτερη εικόνα της δεύτερης σειράς, για παράδειγμα, δεν είναι ακριβώς «ριγέ», αλλά δεδομένων των ίδιων επιλογών σήμανσης, ένας ανθρώπινος σχολιαστής μπορεί επίσης να έχει αντιπαρατεθεί. Καθώς δημιουργούμε το σύνολο δεδομένων μας, πρέπει να αποφασίσουμε εάν θα αφαιρέσουμε περιπτώσεις ακμών όπως αυτές, θα προσθέσουμε νέες κατηγορίες στυλ ή θα αυξήσουμε το σύνολο δεδομένων.
Εξαγάγετε το τελικό σύνολο δεδομένων από το FiftyOne
Εξάγετε το τελικό σύνολο δεδομένων με τον ακόλουθο κώδικα:
Μπορούμε να εξάγουμε ένα μικρότερο σύνολο δεδομένων, για παράδειγμα, 16 εικόνες, στον φάκελο 200kFashionDatasetExportResult-16Images. Δημιουργούμε μια εργασία προσαρμογής Ground Truth χρησιμοποιώντας την:
Ανεβάστε το αναθεωρημένο σύνολο δεδομένων, μετατρέψτε τη μορφή ετικέτας σε Ground Truth, μεταφορτώστε στο Amazon S3 και δημιουργήστε ένα αρχείο δήλωσης για την εργασία προσαρμογής
Μπορούμε να μετατρέψουμε τις ετικέτες στο σύνολο δεδομένων ώστε να ταιριάζουν με τις σχήμα δήλωσης εξόδου μιας εργασίας πλαισίου οριοθέτησης της αλήθειας και μεταφορτώστε τις εικόνες σε ένα Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) κάδος για εκτόξευση α Εργασία προσαρμογής Ground Truth:
Ανεβάστε το αρχείο δήλωσης στο Amazon S3 με τον ακόλουθο κώδικα:
Δημιουργήστε διορθωμένες ετικέτες στυλ με το Ground Truth
Για να σχολιάσετε τα δεδομένα σας με ετικέτες στυλ χρησιμοποιώντας το Ground Truth, ολοκληρώστε τα απαραίτητα βήματα για να ξεκινήσετε μια εργασία επισήμανσης πλαισίου οριοθέτησης ακολουθώντας τη διαδικασία που περιγράφεται στο Ξεκινώντας με τη βασική αλήθεια οδηγός με το σύνολο δεδομένων στον ίδιο κάδο S3.
- Στην κονσόλα SageMaker, δημιουργήστε μια εργασία ετικετών Ground Truth.
- Ρυθμίστε το Εισαγωγή του συνόλου δεδομένων να είναι το μανιφέστο που δημιουργήσαμε στα προηγούμενα βήματα.
- Καθορίστε μια διαδρομή S3 για Θέση δεδομένων εξόδου.
- Για Ρόλος IAM, επιλέξτε Εισαγάγετε έναν προσαρμοσμένο ρόλο IAM RNA, μετά εισάγετε τον ρόλο ARN.
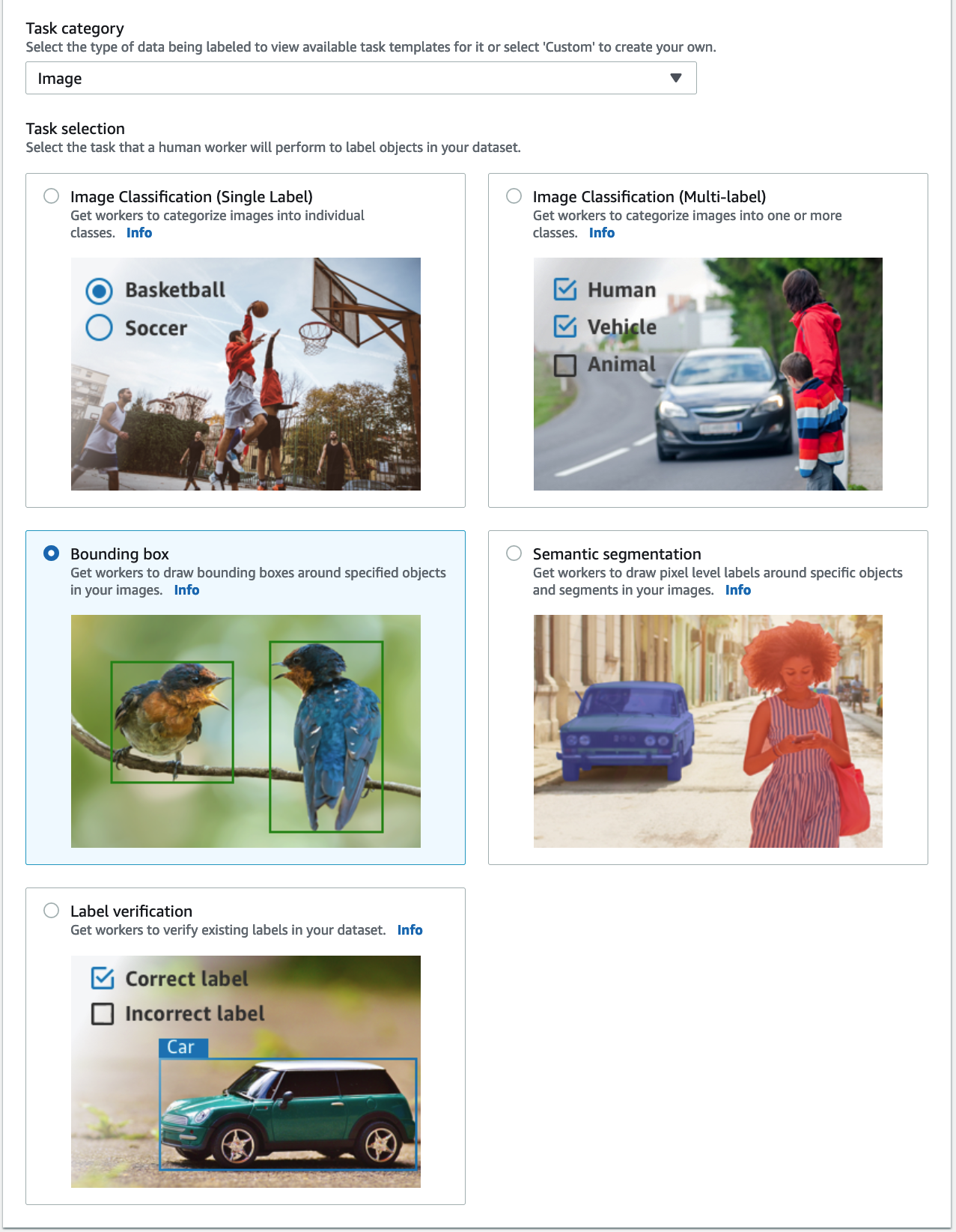
- Για Κατηγορία εργασιών, επιλέξτε Εικόνα και επιλέξτε Οριοθέτηση.
- Επιλέξτε Επόμενο.
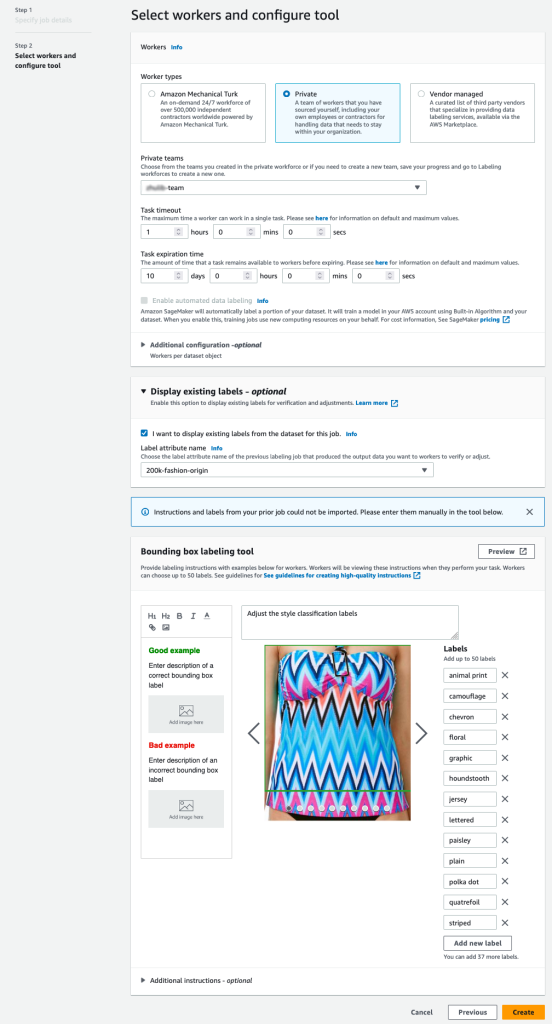
- Στο Οι εργαζόμενοι ενότητα, επιλέξτε τον τύπο εργατικού δυναμικού που θέλετε να χρησιμοποιήσετε.
Μπορείτε να επιλέξετε ένα εργατικό δυναμικό μέσω Αμαζόν Μηχανολόγος Τούρκος, τρίτους προμηθευτές ή το δικό σας ιδιωτικό εργατικό δυναμικό. Για περισσότερες λεπτομέρειες σχετικά με τις επιλογές εργατικού δυναμικού σας, βλ Δημιουργία και διαχείριση εργατικού δυναμικού. - Ανάπτυξη Επιλογές εμφάνισης υπαρχουσών ετικετών και επιλέξτε Θέλω να εμφανίσω υπάρχουσες ετικέτες από το σύνολο δεδομένων για αυτήν την εργασία.
- Για Χαρακτηριστικό ετικέτας όνομα, επιλέξτε το όνομα από το μανιφέστο σας που αντιστοιχεί στις ετικέτες που θέλετε να εμφανίζονται για προσαρμογή.
Θα δείτε μόνο ονόματα χαρακτηριστικών ετικετών για ετικέτες που ταιριάζουν με τον τύπο εργασίας που επιλέξατε στα προηγούμενα βήματα. - Εισαγάγετε χειροκίνητα τις ετικέτες για Εργαλείο επισήμανσης κουτιού οριοθέτησης.
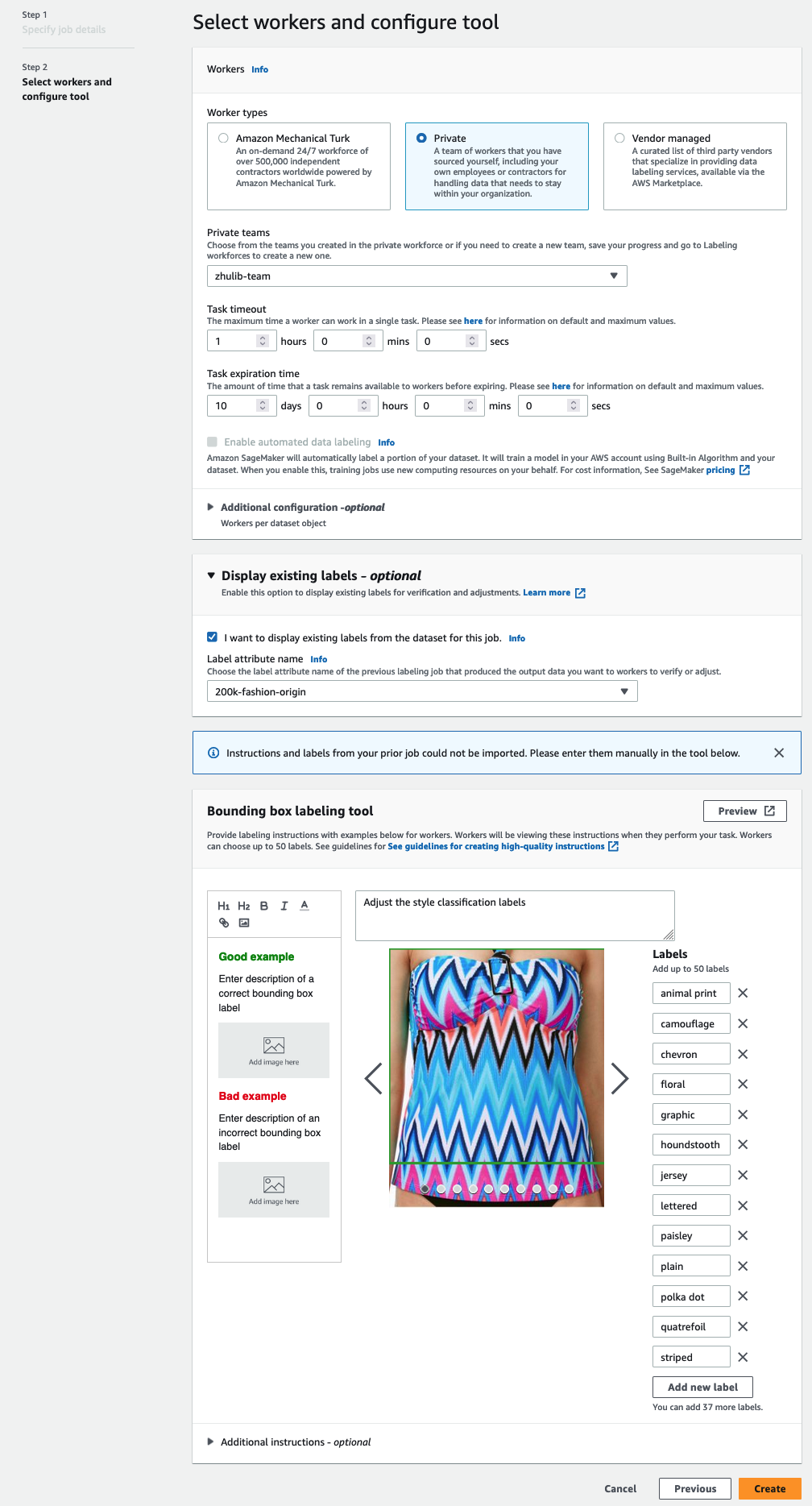 Οι ετικέτες πρέπει να περιέχουν τις ίδιες ετικέτες που χρησιμοποιούνται στο δημόσιο σύνολο δεδομένων. Μπορείτε να προσθέσετε νέες ετικέτες. Το παρακάτω στιγμιότυπο οθόνης δείχνει πώς μπορείτε να επιλέξετε τους εργάτες και να διαμορφώσετε το εργαλείο για την εργασία επισήμανσης.
Οι ετικέτες πρέπει να περιέχουν τις ίδιες ετικέτες που χρησιμοποιούνται στο δημόσιο σύνολο δεδομένων. Μπορείτε να προσθέσετε νέες ετικέτες. Το παρακάτω στιγμιότυπο οθόνης δείχνει πώς μπορείτε να επιλέξετε τους εργάτες και να διαμορφώσετε το εργαλείο για την εργασία επισήμανσης.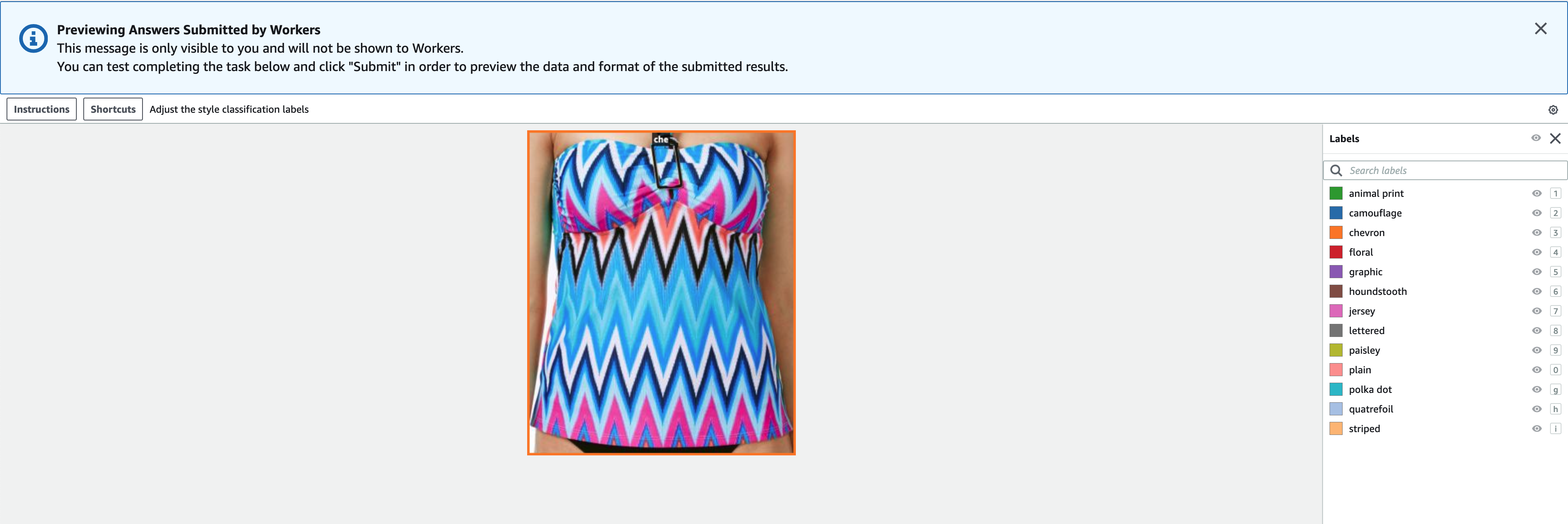
- Επιλέξτε Προβολή για προεπισκόπηση της εικόνας και των αρχικών σχολιασμών.
Τώρα έχουμε δημιουργήσει μια εργασία επισήμανσης στο Ground Truth. Αφού ολοκληρωθεί η εργασία μας, μπορούμε να φορτώσουμε τα πρόσφατα δημιουργημένα δεδομένα με ετικέτα στο FiftyOne. Το Ground Truth παράγει δεδομένα εξόδου σε μια δήλωση εξόδου Ground Truth. Για περισσότερες λεπτομέρειες σχετικά με το αρχείο δήλωσης εξόδου, βλ Έξοδος εργασίας Bounding Box. Ο παρακάτω κώδικας δείχνει ένα παράδειγμα αυτής της μορφής δήλωσης εξόδου:
Ελέγξτε τα αποτελέσματα με ετικέτα από το Ground Truth στο FiftyOne
Αφού ολοκληρωθεί η εργασία, πραγματοποιήστε λήψη του μανιφέστου εξόδου της εργασίας επισήμανσης από το Amazon S3.
Διαβάστε το αρχείο δήλωσης εξόδου:
Δημιουργήστε ένα σύνολο δεδομένων FiftyOne και μετατρέψτε τις γραμμές δήλωσης σε δείγματα στο σύνολο δεδομένων:
Τώρα μπορείτε να δείτε δεδομένα με ετικέτα υψηλής ποιότητας από το Ground Truth στο FiftyOne.
Συμπέρασμα
Σε αυτήν την ανάρτηση, δείξαμε πώς να δημιουργήσετε σύνολα δεδομένων υψηλής ποιότητας συνδυάζοντας τη δύναμη του Πενήντα ένα by voxel51, μια εργαλειοθήκη ανοιχτού κώδικα που σας επιτρέπει να διαχειρίζεστε, να παρακολουθείτε, να οπτικοποιείτε και να επιμελείτε το σύνολο δεδομένων σας και το Ground Truth, μια υπηρεσία ετικετοποίησης δεδομένων που σας επιτρέπει να επισημαίνετε αποτελεσματικά και με ακρίβεια τα σύνολα δεδομένων που απαιτούνται για την εκπαίδευση συστημάτων ML παρέχοντας πρόσβαση σε πολλαπλά ενσωματωμένα -πρότυπα εργασιών και πρόσβαση σε ποικίλο εργατικό δυναμικό μέσω της Mechanical Turk, τρίτων προμηθευτών ή του δικού σας ιδιωτικού εργατικού δυναμικού.
Σας συνιστούμε να δοκιμάσετε αυτή τη νέα λειτουργία εγκαθιστώντας μια παρουσία FiftyOne και χρησιμοποιώντας την κονσόλα Ground Truth για να ξεκινήσετε. Για να μάθετε περισσότερα για το Ground Truth, ανατρέξτε στο Δεδομένα ετικέτας, Συχνές ερωτήσεις για την επισήμανση δεδομένων του Amazon SageMaker, και το Ιστολόγιο μηχανικής εκμάθησης AWS.
Συνδεθείτε με το Κοινότητα Machine Learning & AI αν έχετε οποιεσδήποτε ερωτήσεις ή σχόλια!
Γίνετε μέλος της κοινότητας FiftyOne!
Γίνετε μέλος των χιλιάδων μηχανικών και επιστημόνων δεδομένων που χρησιμοποιούν ήδη το FiftyOne για να λύσετε μερικά από τα πιο προκλητικά προβλήματα στην όραση υπολογιστών σήμερα!
Σχετικά με τους Συγγραφείς
Shalendra Chhabra είναι επί του παρόντος Επικεφαλής Διεύθυνσης Προϊόντων για τις Υπηρεσίες Amazon SageMaker Human-in-the-Loop (HIL). Προηγουμένως, η Shalendra επώασε και ηγήθηκε της Γλώσσας και της Συνομιλητικής Ευφυΐας για τις Συναντήσεις Ομάδων της Microsoft, ήταν EIR στο Amazon Alexa Techstars Startup Accelerator, Αντιπρόεδρος Προϊόντος και Μάρκετινγκ στο Discuss.io, Επικεφαλής Προϊόντος και Μάρκετινγκ στο Clipboard (εξαγοράστηκε από τη Salesforce) και Επικεφαλής Διευθυντής Προϊόντων στη Swype (εξαγοράστηκε από τη Nuance). Συνολικά, η Shalendra έχει βοηθήσει στην κατασκευή, αποστολή και εμπορία προϊόντων που έχουν αγγίξει περισσότερες από ένα δισεκατομμύριο ζωές.
Jacob Marks είναι Μηχανικός Μηχανικής Μάθησης και Προγραμματιστής Ευαγγελιστής στο Voxel51, όπου συμβάλλει στη διαφάνεια και τη σαφήνεια στα δεδομένα του κόσμου. Πριν γίνει μέλος του Voxel51, ο Jacob ίδρυσε μια startup για να βοηθήσει τους ανερχόμενους μουσικούς να συνδεθούν και να μοιραστούν δημιουργικό περιεχόμενο με τους θαυμαστές. Πριν από αυτό, εργάστηκε στο Google X, τη Samsung Research και τη Wolfram Research. Σε μια προηγούμενη ζωή, ο Jacob ήταν θεωρητικός φυσικός, ολοκλήρωσε το διδακτορικό του στο Στάνφορντ, όπου ερεύνησε κβαντικές φάσεις της ύλης. Στον ελεύθερο χρόνο του, ο Τζέικομπ του αρέσει να σκαρφαλώνει, να τρέχει και να διαβάζει μυθιστορήματα επιστημονικής φαντασίας.
Τζέισον Κόρσο είναι συνιδρυτής και Διευθύνων Σύμβουλος της Voxel51, όπου κατευθύνει τη στρατηγική για να συμβάλει στη διαφάνεια και τη σαφήνεια στα δεδομένα του κόσμου μέσω ευέλικτου λογισμικού τελευταίας τεχνολογίας. Είναι επίσης Καθηγητής Ρομποτικής, Ηλεκτρολόγων Μηχανικών και Επιστήμης Υπολογιστών στο Πανεπιστήμιο του Μίσιγκαν, όπου εστιάζει σε προβλήματα αιχμής στη διασταύρωση της όρασης υπολογιστών, της φυσικής γλώσσας και των φυσικών πλατφορμών. Στον ελεύθερο χρόνο του, ο Τζέισον απολαμβάνει να περνά χρόνο με την οικογένειά του, να διαβάζει, να βρίσκεται στη φύση, να παίζει επιτραπέζια παιχνίδια και κάθε είδους δημιουργικές δραστηριότητες.
Μπράιαν Μουρ είναι συνιδρυτής και CTO της Voxel51, όπου ηγείται της τεχνικής στρατηγικής και του οράματος. Είναι κάτοχος διδακτορικού διπλώματος Ηλεκτρολόγου Μηχανικού από το Πανεπιστήμιο του Μίσιγκαν, όπου η έρευνά του επικεντρώθηκε σε αποτελεσματικούς αλγόριθμους για προβλήματα μηχανικής μάθησης μεγάλης κλίμακας, με ιδιαίτερη έμφαση στις εφαρμογές όρασης υπολογιστών. Στον ελεύθερο χρόνο του, απολαμβάνει το μπάντμιντον, το γκολφ, την πεζοπορία και το παιχνίδι με τα δίδυμα τεριέ του Γιορκσάιρ.
Ζουλίνγκ Μπάι είναι Μηχανικός Ανάπτυξης Λογισμικού στην Amazon Web Services. Εργάζεται στην ανάπτυξη κατανεμημένων συστημάτων μεγάλης κλίμακας για την επίλυση προβλημάτων μηχανικής μάθησης.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoAiStream. Web3 Data Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- Minting the Future με την Adryenn Ashley. Πρόσβαση εδώ.
- Αγορά και πώληση μετοχών σε εταιρείες PRE-IPO με το PREIPO®. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :έχει
- :είναι
- :δεν
- :που
- $UP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Σχετικά
- επιταχύνουν
- επιταχύνοντας
- επιταχυντής
- πρόσβαση
- ακριβής
- με ακρίβεια
- αποκτήθηκαν
- δραστηριοτήτων
- προσθέτω
- προσθήκη
- διεύθυνση
- ρυθμίζεται
- Προσαρμογή
- Μετά το
- πάλι
- AI
- Alexa
- αλγόριθμοι
- Όλα
- επιτρέπει
- alone
- ήδη
- Επίσης
- Amazon
- amazon alexa
- Amazon Sage Maker
- Amazon SageMaker Ground Αλήθεια
- Amazon υπηρεσίες Web
- μεταξύ των
- an
- αναλύσει
- και
- ζώο
- κάθε
- app
- Εφαρμογή
- εφαρμογές
- Εφαρμογή
- κατάλληλος
- ΕΙΝΑΙ
- διατεταγμένα
- άρθρο
- εμπορεύματα
- AS
- συσχετισμένη
- At
- συγγραφείς
- μακριά
- AWS
- βάση
- βασίζονται
- BE
- επειδή
- γίνονται
- ήταν
- πριν
- πίσω
- στα παρασκήνια
- είναι
- Πιστεύω
- ΚΑΛΎΤΕΡΟΣ
- Καλύτερα
- μεταξύ
- Δισεκατομμύριο
- επιτροπή
- Επιτραπέζια παιχνίδια
- ΟΣΤΟ
- Bootstrap
- και οι δύο
- Κουτί
- κουτιά
- Εγκέφαλος
- Διακοπή
- φέρω
- Έφερε
- προϋπολογισμός
- χτίζω
- Κτίριο
- ενσωματωμένο
- αλλά
- αγορά
- by
- CAN
- Καταγραφή
- περίπτωση
- περιπτώσεις
- κατηγορίες
- κατηγορία
- Διευθύνων Σύμβουλος
- πρόκληση
- πρόκληση
- έλεγχος
- Επιλέξτε
- σαφήνεια
- τάξη
- τάξεις
- ταξινόμηση
- Καθάρισμα
- καθαρός
- σαφώς
- πελάτης
- Ορειβασία
- Κλεισιμο
- πιο κοντά
- ρούχα
- ΡΟΥΧΑ
- Συνιδρυτής
- κωδικός
- συνδυασμός
- συνδυάζοντας
- εταίρα
- Συμπλήρωμα
- πλήρης
- ολοκληρώνοντας
- Υπολογίστε
- υπολογιστή
- Πληροφορική
- Computer Vision
- Εφαρμογές Computer Vision
- εμπιστοσύνη
- βέβαιος
- Connect
- εξέταση
- Αποτελείται από
- πρόξενος
- Περιέχει
- περιεχόμενο
- περιεχόμενα
- ελέγχεται
- ομιλητικός
- μετατρέψετε
- αντίγραφα
- πυρήνας
- Διορθώθηκε
- αντιστοιχεί
- Κόστος
- Δικαστικά έξοδα
- δημιουργία
- δημιουργήθηκε
- Δημιουργικός
- Διαπιστεύσεις
- ΚΟΤ
- επιμέλεια
- υπεφημέριος
- Τη στιγμή
- έθιμο
- πελάτης
- Πελάτες
- Τομή
- αιχμής
- ημερομηνία
- σύνολα δεδομένων
- αποφασίζει
- αποδεικνύουν
- Τζιν
- βάθος
- περιγραφή
- καθέκαστα
- Ανίχνευση
- Εργολάβος
- ανάπτυξη
- Ανάπτυξη
- διαφορετικές
- κατευθείαν
- Κατάλογοι
- Display
- διακριτή
- διανέμονται
- κατανεμημένα συστήματα
- διάφορα
- do
- Όχι
- Σκύλος
- πράξη
- γίνεται
- Μην
- DOT
- κάτω
- κατεβάσετε
- αντίγραφα
- e
- κάθε
- εύκολος
- άκρη
- αποτέλεσμα
- αποτελεσματικός
- αποτελεσματικά
- Ηλεκτρολόγων Μηχανικών
- ενσωμάτωση
- σμυριδόπετρα
- έμφαση
- απασχολεί
- εξουσιοδοτεί
- έγκλειστα
- ενθαρρύνει
- τέλος
- μηχανικός
- Μηχανική
- Μηχανικοί
- εισάγετε
- Περιβάλλον
- ισότητα
- ουσιώδης
- εγκατεστημένος
- Αιθέρας (ΕΤΗ)
- αξιολογώντας
- Ευαγγελιστής
- ακριβώς
- παράδειγμα
- υφιστάμενα
- εξαγωγή
- αρκετά
- οικογένεια
- ανεμιστήρες
- ανατροφοδότηση
- λίγοι
- Μυθιστόρημα
- πεδίο
- Πεδία
- Αρχεία
- Αρχεία
- φιλτράρισμα
- φιλτράρισμα
- τελικός
- Όνομα
- ταιριάζουν
- εύκαμπτος
- Συγκέντρωση
- επικεντρώθηκε
- εστιάζει
- Εξής
- Για
- μορφή
- μορφή
- Ευτυχώς
- Ίδρυση
- τέσσερα
- Δωρεάν
- από
- πλήρως
- λειτουργικότητα
- Games
- γενικού σκοπού
- παράγουν
- παράγεται
- παίρνω
- GitHub
- Δώστε
- δεδομένου
- γκολ
- γκολφ
- καλός
- μεγαλύτερη
- Πλέγμα
- Έδαφος
- Group
- καθοδηγήσει
- ευτυχισμένος
- Έχω
- he
- κεφάλι
- ύψος
- βοήθεια
- βοήθησε
- χρήσιμο
- βοηθά
- εδώ
- υψηλής ποιότητας
- υψηλής ανάλυσης
- υψηλότερο
- υψηλά
- πεζοπορία
- του
- κατέχει
- Πως
- Πώς να
- Ωστόσο
- HTML
- http
- HTTPS
- ανθρώπινος
- i
- IAM
- ID
- προσδιορίσει
- προσδιορισμό
- ids
- if
- εικόνα
- εικόνες
- Επίπτωση
- εισαγωγή
- βελτίωση
- in
- Σε άλλες
- Συμπεριλαμβανομένου
- εσφαλμένα
- επωάζονται
- πληροφορίες
- αρχικός
- αρχικά
- εγκαθιστώ
- εγκατάσταση
- παράδειγμα
- αντί
- οδηγίες
- Νοημοσύνη
- διασταύρωση
- σε
- IT
- ΤΟΥ
- Φανέλα
- Δουλειά
- ενώνει
- άρθρωση
- json
- μόλις
- Διατήρηση
- τήρηση
- επιγραφή
- τιτλοφόρηση
- Ετικέτες
- Γλώσσα
- μεγάλης κλίμακας
- ξεκινήσει
- δρομολόγηση
- οδηγήσει
- Οδηγεί
- ΜΑΘΑΊΝΩ
- μάθηση
- ελάχιστα
- Led
- αριστερά
- Αφήνει
- Βιβλιοθήκη
- ζωή
- Μου αρέσει
- Πιθανός
- LIMIT
- Περιωρισμένος
- γραμμή
- γραμμές
- Λίστα
- λίστα
- Ακίνητα
- λίγο
- ζωές
- φορτίο
- ματιά
- κοιτάζοντας
- Παρτίδα
- Χαμηλός
- μηχανή
- μάθηση μηχανής
- που
- μαγεία
- κάνω
- ΚΑΝΕΙ
- διαχείριση
- διαχειρίζεται
- διαχείριση
- διευθυντής
- πολοί
- χάρτη
- αγορά
- Μάρκετινγκ
- Ταίριασμα
- ταιριάζουν
- υλικά
- ύλη
- Ενδέχεται..
- μηχανικός
- Εικόνες / Βίντεο
- συναντήσεις
- Meta
- Μεταδεδομένα
- μέθοδος
- μέθοδοι
- Μίσιγκαν
- Microsoft
- μικροσκοπικές ομάδες
- ενδέχεται να
- ελάχιστο
- ML
- Κινητό
- εφαρμογή για κινητά
- μοντέλο
- μοντέλα
- ενότητες
- περισσότερο
- πλέον
- μετακινήσετε
- πολύ
- πολλαπλούς
- μουσικούς
- πρέπει
- όνομα
- Ονομάστηκε
- ονόματα
- Φυσικό
- Φυσική γλώσσα
- Φύση
- Κοντά
- αναγκαίως
- απαραίτητος
- Ανάγκη
- ανάγκες
- Νέα
- αισθητώς
- Εννοια
- τώρα
- Απόχρωση
- αριθμός
- αντικείμενο
- Ανίχνευση αντικειμένων
- αντικειμένων
- of
- επίσημος ανώτερος υπάλληλος
- on
- μια φορά
- ONE
- διαδικτυακά (online)
- αποκλειστικά
- ανοίξτε
- ανοικτού κώδικα
- λειτουργίες
- Ευκαιρία
- Επιλογές
- or
- Οργανωμένος
- πρωτότυπο
- OS
- ΑΛΛΑ
- Άλλα
- δικός μας
- έξω
- σκιαγραφείται
- παραγωγή
- επί
- δική
- ανήκει
- πακέτα
- ζεύγη
- μέρος
- Ειδικότερα
- Το παρελθόν
- μονοπάτι
- πρότυπο
- πρότυπα
- τέλειος
- επίδοση
- person
- Εξατομικευμένη
- Φάσεις της Ύλης
- φυσικός
- επιλέξτε
- Εικόνες
- ΚΑΡΟ ΥΦΑΣΜΑ
- Σκέτη
- Πλατφόρμες
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- παιχνίδι
- Σημείο
- κατοικημένη περιοχή
- δυνατός
- Θέση
- δύναμη
- πρακτική
- προβλεπόμενη
- πρόβλεψη
- Προβλέψεις
- Προβολή
- προηγούμενος
- προηγουμένως
- Πριν
- ιδιωτικός
- πιθανώς
- προβλήματα
- διαδικασια μας
- Προϊόν
- διαχείριση προϊόντων
- υπεύθυνος προϊόντων
- Προϊόντα
- Δάσκαλος
- σχέδιο
- περιουσία
- υποψήφιος
- πρωτότυπο
- παρέχουν
- παρέχεται
- χορήγηση
- δημόσιο
- γροθιά
- σκοποί
- Python
- Quantum
- Ερωτήσεις
- γρήγορα
- σειρά
- μάλλον
- Ανάγνωση
- έτοιμος
- συνιστώ
- συστάσεις
- μείωση
- Μειωμένος
- μείωση
- σχετικά
- κυκλοφόρησε
- αφαιρέστε
- εκπρόσωπος
- εκπροσωπούν
- απαιτείται
- έρευνα
- ερευνητές
- Ανάλυση
- περιορίζω
- αποτέλεσμα
- με αποτέλεσμα
- Αποτελέσματα
- λιανική πώληση
- απόδοση
- ανασκόπηση
- Απαλλάσσω
- ρομποτική
- εύρωστος
- Ρόλος
- περίπου
- ΣΕΙΡΑ
- καταστροφή
- τρέξιμο
- σοφός
- Είπε
- salesforce
- ίδιο
- Samsung
- Αποθήκευση
- Σκηνές
- Επιστήμη
- Επιστημονική φαντασία
- επιστήμονες
- σκορ
- άψογα
- Δεύτερος
- Τμήμα
- τμήματα
- δείτε
- φαίνομαι
- φαίνεται
- επιλέγονται
- αίσθηση
- ξεχωριστό
- υπηρεσία
- Υπηρεσίες
- Συνεδρίαση
- σειρά
- Κοινοποίηση
- αυτή
- θα πρέπει να
- δείχνουν
- Δείχνει
- ΝΑΙ
- παρόμοιες
- Απλούς
- μικρότερος
- So
- λογισμικό
- ανάπτυξη λογισμικού
- SOLVE
- μερικοί
- Κάποιος
- κάτι
- Χώρος
- δαπανήσει
- Δαπάνες
- διαίρεση
- Διαχωρίστε
- stanford
- Εκκίνηση
- ξεκίνησε
- Ξεκινήστε
- εκκίνηση
- επιταχυντή εκκίνησης
- state-of-the-art
- Βήματα
- Ακόμη
- χώρος στο δίσκο
- κατάστημα
- Στρατηγική
- στυλ
- στυλ
- ΠΕΡΙΛΗΨΗ
- υποστηριζόνται!
- συστήματα
- Πάρτε
- Έργο
- ομάδες
- Τεχνικός
- techstars
- λέει
- πρότυπα
- δοκιμή
- από
- ότι
- Η
- τους
- Τους
- τότε
- θεωρητικός
- Εκεί.
- Αυτοί
- αυτοί
- πράγματα
- νομίζω
- τρίτους
- αυτό
- χιλιάδες
- κατώφλι
- Μέσω
- Ρίψη
- ώρα
- προς την
- μαζι
- εργαλείο
- εργαλειοθήκη
- κορυφή
- κορυφαίο επίπεδο
- Tops
- Σύνολο
- τρελλός λίγο
- τροχιά
- Τρένο
- εκπαιδευμένο
- Εκπαίδευση
- Μεταμορφώστε
- Διαφάνεια
- αληθής
- Αλήθεια
- ΣΤΡΟΦΗ
- δύο
- τύπος
- τύποι
- υπό
- καταλαβαίνω
- μοναδικός
- πανεπιστήμιο
- Πανεπιστήμιο του Michigan
- Ενημέρωση
- us
- χρήση
- περίπτωση χρήσης
- μεταχειρισμένος
- Χρήστες
- Χρήστες
- χρησιμοποιώντας
- Αξίες
- ποικιλία
- διάφορα
- πωλητές
- επαληθεύει
- πολύ
- μέσω
- Δες
- Πραγματικός
- όραμα
- θέλω
- ήταν
- we
- ιστός
- διαδικτυακές υπηρεσίες
- ΛΟΙΠΌΝ
- ήταν
- Τι
- πότε
- αν
- Ποιό
- Wikipedia
- θα
- με
- εντός
- χωρίς
- Γυναίκες
- λόγια
- Εργασία
- εργάστηκαν
- εργαζομένων
- Εργατικό δυναμικό
- λειτουργεί
- του κόσμου
- ανησυχία
- θα
- γράφω
- X
- εσείς
- Σας
- zephyrnet
- Zip
- ΖΩΟΛΟΓΙΚΟΣ ΚΗΠΟΣ