
Εικόνα από συγγραφέα
Κατά την ανάλυση των δεδομένων, το θέμα στο μυαλό μας είναι να βρούμε κρυμμένα μοτίβα και να εξάγουμε σημαντικές γνώσεις. Ας μπούμε στη νέα κατηγορία της μάθησης που βασίζεται σε ML, δηλαδή στην μάθηση χωρίς επίβλεψη, στην οποία ένας από τους ισχυρούς αλγόριθμους για την επίλυση των εργασιών ομαδοποίησης είναι ο αλγόριθμος ομαδοποίησης K-Means που φέρνει επανάσταση στην κατανόηση δεδομένων.
K-Means has become a useful algorithm in machine learning and data mining applications. In this article, we will deep dive into the workings of K-Means, its implementation using Python, and exploring its principles, applications, etc. So, let’s start the journey to unlock the secret patterns and harness the potential of the K-Means clustering algorithm.
Ο αλγόριθμος K-Means χρησιμοποιείται για την επίλυση προβλημάτων ομαδοποίησης που ανήκουν στην τάξη Unsupervised Learning. Με τη βοήθεια αυτού του αλγορίθμου, μπορούμε να ομαδοποιήσουμε τον αριθμό των παρατηρήσεων σε ομάδες K.
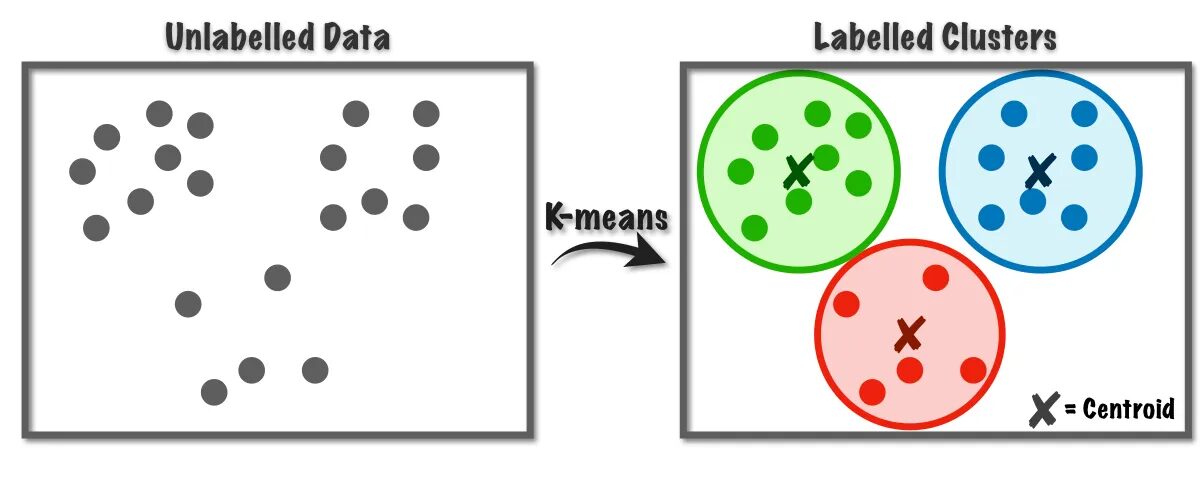
Εικ.1 Αλγόριθμος K-Means Working | Εικόνα από Προς την επιστήμη των δεδομένων
Αυτός ο αλγόριθμος εσωτερικά χρησιμοποιεί διανυσματική κβαντοποίηση, μέσω του οποίου μπορούμε να αντιστοιχίσουμε κάθε παρατήρηση στο σύνολο δεδομένων στο σύμπλεγμα με την ελάχιστη απόσταση, που είναι το πρωτότυπο του αλγορίθμου ομαδοποίησης. Αυτός ο αλγόριθμος ομαδοποίησης χρησιμοποιείται συνήθως στην εξόρυξη δεδομένων και τη μηχανική μάθηση για την κατανομή δεδομένων σε συμπλέγματα K βάσει μετρήσεων ομοιότητας. Επομένως, σε αυτόν τον αλγόριθμο, πρέπει να ελαχιστοποιήσουμε το άθροισμα των τετραγώνων της απόστασης μεταξύ των παρατηρήσεων και των αντίστοιχων κεντροειδών τους, κάτι που τελικά καταλήγει σε διακριτές και ομοιογενείς συστάδες.
Εφαρμογές K-means Clustering
Εδώ είναι μερικές από τις τυπικές εφαρμογές αυτού του αλγορίθμου. Ο αλγόριθμος K-means είναι μια τεχνική που χρησιμοποιείται συνήθως σε περιπτώσεις βιομηχανικής χρήσης για την επίλυση προβλημάτων που σχετίζονται με την ομαδοποίηση.
- Τμηματοποίηση πελατών: Η ομαδοποίηση K-means μπορεί να τμηματοποιήσει διαφορετικούς πελάτες με βάση τα ενδιαφέροντά τους. Μπορεί να εφαρμοστεί σε τραπεζικές εργασίες, τηλεπικοινωνίες, ηλεκτρονικό εμπόριο, αθλητισμό, διαφήμιση, πωλήσεις κ.λπ.
- Ομαδοποίηση εγγράφων: Σε αυτήν την τεχνική, συλλέγουμε παρόμοια έγγραφα από ένα σύνολο εγγράφων, με αποτέλεσμα παρόμοια έγγραφα στα ίδια συμπλέγματα.
- Σύσταση κινητήρων: Μερικές φορές, η ομαδοποίηση K-means μπορεί να χρησιμοποιηθεί για τη δημιουργία συστημάτων συστάσεων. Για παράδειγμα, θέλετε να προτείνετε τραγούδια στους φίλους σας. Μπορείτε να δείτε τα τραγούδια που αρέσουν σε αυτό το άτομο και στη συνέχεια να χρησιμοποιήσετε τη ομαδοποίηση για να βρείτε παρόμοια τραγούδια και να προτείνετε τα πιο παρόμοια.
Υπάρχουν πολλές ακόμη εφαρμογές που είμαι βέβαιος ότι έχετε ήδη σκεφτεί, τις οποίες πιθανότατα μοιραστείτε στην ενότητα σχολίων κάτω από αυτό το άρθρο.
Σε αυτήν την ενότητα, θα αρχίσουμε να εφαρμόζουμε τον αλγόριθμο K-Means σε ένα από τα σύνολα δεδομένων χρησιμοποιώντας Python, που χρησιμοποιείται κυρίως σε έργα Επιστήμης Δεδομένων.
1. Εισαγάγετε τις απαραίτητες Βιβλιοθήκες και Εξαρτήματα
Αρχικά, ας εισάγουμε τις βιβλιοθήκες python που χρησιμοποιούμε για την υλοποίηση του αλγόριθμου K-means, συμπεριλαμβανομένων των NumPy, Pandas, Seaborn, Marplotlib κ.λπ.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sb2. Φορτώστε και αναλύστε το σύνολο δεδομένων
Σε αυτό το βήμα, θα φορτώσουμε το σύνολο δεδομένων μαθητή αποθηκεύοντάς το στο πλαίσιο δεδομένων Pandas. Για να κατεβάσετε το σύνολο δεδομένων, μπορείτε να ανατρέξετε στον σύνδεσμο εδώ.
Ο πλήρης αγωγός του προβλήματος φαίνεται παρακάτω:

Εικ. 2 Αγωγός Έργου | Εικόνα από τον συγγραφέα
df = pd.read_csv('student_clustering.csv')
print("The shape of data is",df.shape)
df.head()3. Σχέδιο διασποράς του συνόλου δεδομένων
Τώρα έρχεται το βήμα της μοντελοποίησης είναι η οπτικοποίηση των δεδομένων, επομένως χρησιμοποιούμε το matplotlib για να σχεδιάσουμε το διάγραμμα διασποράς για να ελέγξουμε πώς λειτουργεί ο αλγόριθμος ομαδοποίησης και να δημιουργήσουμε διαφορετικά συμπλέγματα.
# Scatter plot of the dataset
import matplotlib.pyplot as plt
plt.scatter(df['cgpa'],df['iq'])
Παραγωγή:
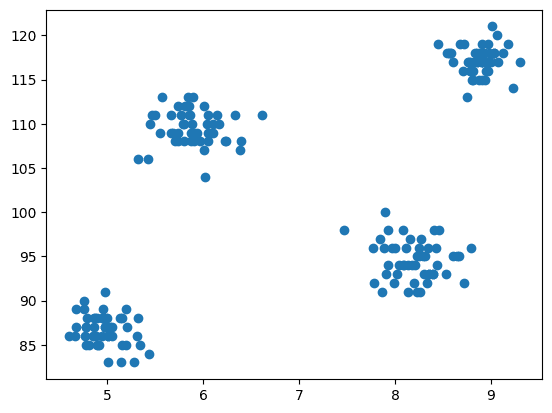
Εικ.3 Οικόπεδο Scatter | Εικόνα από συγγραφέα
4. Εισαγάγετε το K-Means από την κλάση Cluster του Scikit-learn
Τώρα, καθώς πρέπει να εφαρμόσουμε την ομαδοποίηση K-Means, εισάγουμε πρώτα την κλάση συμπλέγματος και μετά έχουμε το KMeans ως ενότητα αυτής της κλάσης.
from sklearn.cluster import KMeans5. Εύρεση της βέλτιστης τιμής του K χρησιμοποιώντας τη μέθοδο Elbow
Σε αυτό το βήμα, θα βρούμε τη βέλτιστη τιμή του K, μιας από τις υπερπαραμέτρους, κατά την υλοποίηση του αλγόριθμου. Η τιμή K υποδηλώνει πόσα συμπλέγματα πρέπει να δημιουργήσουμε για το σύνολο δεδομένων μας. Η εύρεση αυτής της τιμής διαισθητικά δεν είναι δυνατή, επομένως για να βρούμε τη βέλτιστη τιμή, θα δημιουργήσουμε μια γραφική παράσταση μεταξύ WCSS (εντός συστάδας-άθροισμα-τετράγωνων) και διαφορετικών τιμών K, και πρέπει να επιλέξουμε αυτό το K, το οποίο μας δίνει την ελάχιστη τιμή του WCSS.
# create an empty list for store residuals
wcss = [] for i in range(1,11): # create an object of K-Means class km = KMeans(n_clusters=i) # pass the dataframe to fit the algorithm km.fit_predict(df) # append inertia value to wcss list wcss.append(km.inertia_)
Τώρα, ας σχεδιάσουμε το διάγραμμα του αγκώνα για να βρούμε τη βέλτιστη τιμή του K.
# Plot of WCSS vs. K to check the optimal value of K
plt.plot(range(1,11),wcss)
Παραγωγή:
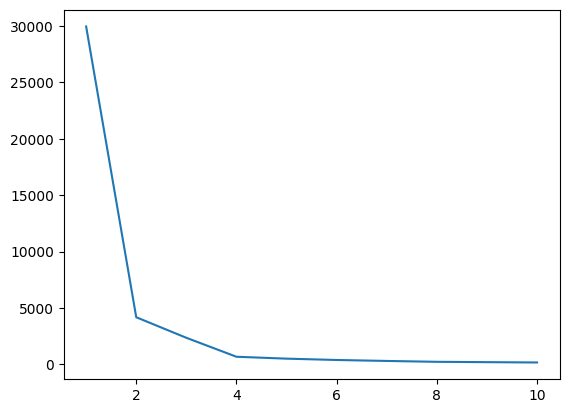
Εικ.4 Οικόπεδο με αγκώνα | Εικόνα από συγγραφέα
Από το παραπάνω οικόπεδο του αγκώνα, μπορούμε να δούμε στο K=4. υπάρχει μια πτώση στην τιμή του WCSS, που σημαίνει ότι αν χρησιμοποιήσουμε τη βέλτιστη τιμή ως 4, σε αυτήν την περίπτωση, η ομαδοποίηση θα σας δώσει καλή απόδοση.
6. Προσαρμόστε τον αλγόριθμο K-Means με τη Βέλτιστη τιμή του K
Τελειώσαμε με την εύρεση της βέλτιστης τιμής του K. Τώρα, ας κάνουμε τη μοντελοποίηση όπου θα δημιουργήσουμε έναν πίνακα X που αποθηκεύει το πλήρες σύνολο δεδομένων έχοντας όλα τα χαρακτηριστικά. Δεν χρειάζεται να διαχωρίσετε το διάνυσμα στόχου και χαρακτηριστικού εδώ, καθώς πρόκειται για ένα πρόβλημα χωρίς επίβλεψη. Μετά από αυτό, θα δημιουργήσουμε ένα αντικείμενο της κλάσης KMeans με μια επιλεγμένη τιμή K και στη συνέχεια θα το προσαρμόσουμε στο παρεχόμενο σύνολο δεδομένων. Τέλος, εκτυπώνουμε το y_means, το οποίο υποδεικνύει τους μέσους όρους των διαφορετικών συστάδων που σχηματίστηκαν.
X = df.iloc[:,:].values # complete data is used for model building
km = KMeans(n_clusters=4)
y_means = km.fit_predict(X)
y_means7. Ελέγξτε την Ανάθεση Cluster για κάθε Κατηγορία
Ας ελέγξουμε ποια σημεία του συνόλου δεδομένων ανήκουν σε ποιο σύμπλεγμα.
X[y_means == 3,1]
Μέχρι τώρα, για την προετοιμασία του κέντρου, χρησιμοποιούσαμε τη στρατηγική K-Means++, τώρα, ας αρχικοποιήσουμε τα τυχαία κεντροειδή αντί για το K-Means++ και ας συγκρίνουμε τα αποτελέσματα ακολουθώντας την ίδια διαδικασία.
km_new = KMeans(n_clusters=4, init='random')
y_means_new = km_new.fit_predict(X)
y_means_new
Ελέγξτε πόσες τιμές ταιριάζουν.
sum(y_means == y_means_new)8. Οπτικοποίηση των συμπλεγμάτων
Για να οπτικοποιήσουμε κάθε συστάδα, τα σχεδιάζουμε στους άξονες και αντιστοιχίζουμε διαφορετικά χρώματα μέσα από τα οποία μπορούμε εύκολα να δούμε να σχηματίζονται 4 συστάδες.
plt.scatter(X[y_means == 0,0],X[y_means == 0,1],color='blue')
plt.scatter(X[y_means == 1,0],X[y_means == 1,1],color='red') plt.scatter(X[y_means == 2,0],X[y_means == 2,1],color='green') plt.scatter(X[y_means == 3,0],X[y_means == 3,1],color='yellow')
Παραγωγή:
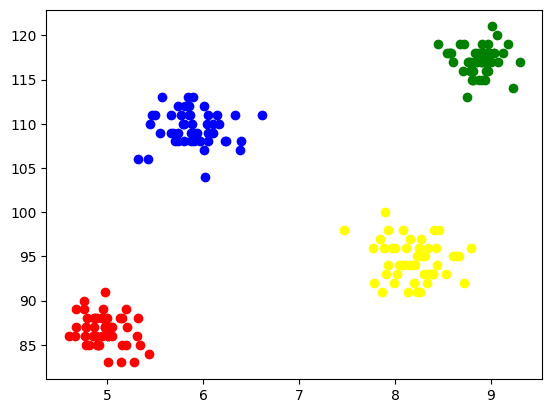
Εικ. 5 Οπτικοποίηση συστάδων που σχηματίστηκαν | Εικόνα από τον συγγραφέα
9. K-Means σε 3D-Data
Καθώς το προηγούμενο σύνολο δεδομένων έχει 2 στήλες, έχουμε ένα πρόβλημα 2-Δ. Τώρα, θα χρησιμοποιήσουμε το ίδιο σύνολο βημάτων για ένα τρισδιάστατο πρόβλημα και θα προσπαθήσουμε να αναλύσουμε την αναπαραγωγιμότητα του κώδικα για δεδομένα n-διαστάσεων.
# Create a synthetic dataset from sklearn
from sklearn.datasets import make_blobs # make synthetic dataset
centroids = [(-5,-5,5),(5,5,-5),(3.5,-2.5,4),(-2.5,2.5,-4)]
cluster_std = [1,1,1,1]
X,y = make_blobs(n_samples=200,cluster_std=cluster_std,centers=centroids,n_features=3,random_state=1)
# Scatter plot of the dataset
import plotly.express as px
fig = px.scatter_3d(x=X[:,0], y=X[:,1], z=X[:,2])
fig.show()
Παραγωγή:
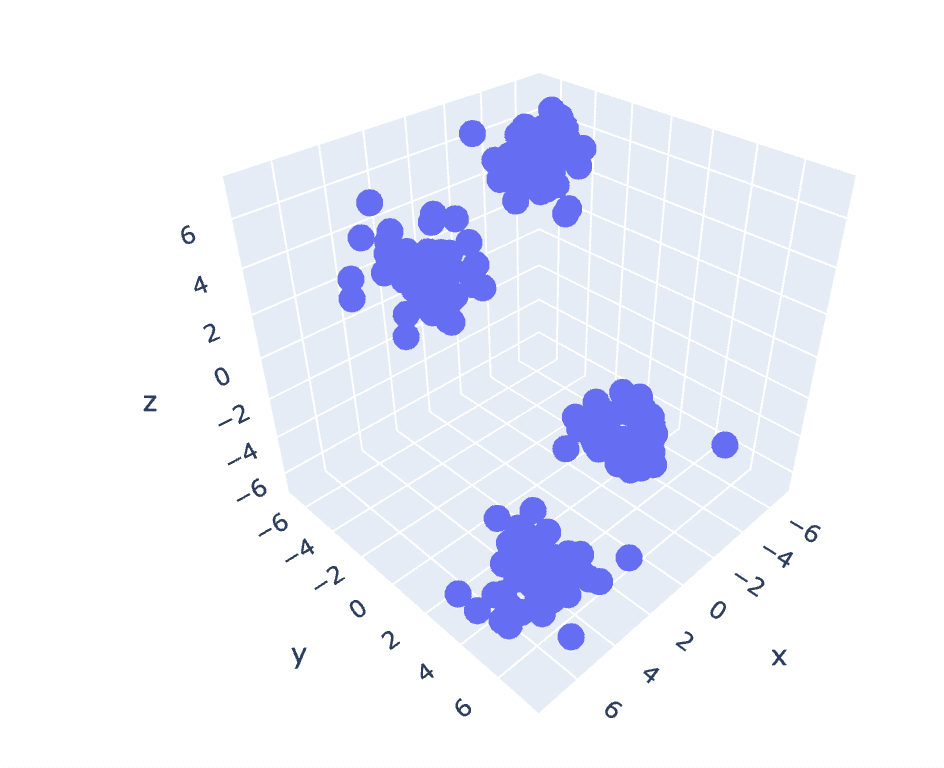
Εικ. 6 Σχέδιο διασποράς τρισδιάστατου συνόλου δεδομένων | Εικόνα από τον συγγραφέα
wcss = []
for i in range(1,21): km = KMeans(n_clusters=i) km.fit_predict(X) wcss.append(km.inertia_) plt.plot(range(1,21),wcss)
Παραγωγή:

Εικ.7 Οικόπεδο με αγκώνα | Εικόνα από συγγραφέα
# Fit the K-Means algorithm with the optimal value of K
km = KMeans(n_clusters=4)
y_pred = km.fit_predict(X)
# Analyse the different clusters formed
df = pd.DataFrame()
df['col1'] = X[:,0]
df['col2'] = X[:,1]
df['col3'] = X[:,2]
df['label'] = y_pred fig = px.scatter_3d(df,x='col1', y='col2', z='col3',color='label')
fig.show()
Παραγωγή:
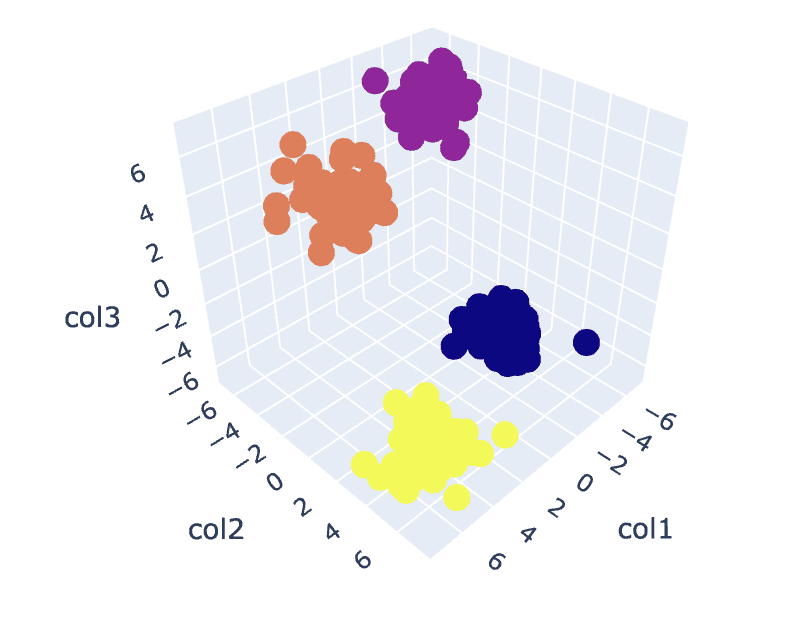
Εικ.8. Οπτικοποίηση συμπλεγμάτων | Εικόνα από συγγραφέα
You can find the complete code here – Σημειωματάριο Colab
Αυτό ολοκληρώνει τη συζήτησή μας. Έχουμε συζητήσει την εργασία, την εφαρμογή και τις εφαρμογές του K-Means. Συμπερασματικά, η υλοποίηση των εργασιών ομαδοποίησης είναι ένας ευρέως χρησιμοποιούμενος αλγόριθμος από την τάξη της μη εποπτευόμενης μάθησης που παρέχει μια απλή και διαισθητική προσέγγιση για την ομαδοποίηση των παρατηρήσεων ενός συνόλου δεδομένων. Η κύρια δύναμη αυτού του αλγορίθμου είναι να χωρίζει τις παρατηρήσεις σε πολλαπλά σύνολα με βάση τις επιλεγμένες μετρήσεις ομοιότητας με τη βοήθεια του χρήστη που εφαρμόζει τον αλγόριθμο.
Ωστόσο, με βάση την επιλογή των κεντροειδών στο πρώτο βήμα, ο αλγόριθμός μας συμπεριφέρεται διαφορετικά και συγκλίνει σε τοπικό ή παγκόσμιο βέλτιστο. Επομένως, η επιλογή του αριθμού των συστάδων για την υλοποίηση του αλγόριθμου, η προεπεξεργασία των δεδομένων, ο χειρισμός των ακραίων τιμών κ.λπ., είναι ζωτικής σημασίας για την επίτευξη καλών αποτελεσμάτων. Αλλά αν παρατηρήσουμε την άλλη πλευρά αυτού του αλγορίθμου πίσω από τους περιορισμούς, το K-Means είναι μια χρήσιμη τεχνική για διερευνητική ανάλυση δεδομένων και αναγνώριση προτύπων σε διάφορους τομείς.
Άριαν Γκαργκ είναι B.Tech. Φοιτητής Ηλεκτρολόγος Μηχανικός, στο τελευταίο έτος του προπτυχιακού του. Το ενδιαφέρον του βρίσκεται στον τομέα της Ανάπτυξης Ιστού και της Μηχανικής Μάθησης. Έχει επιδιώξει αυτό το ενδιαφέρον και είναι πρόθυμος να εργαστεί περισσότερο προς αυτές τις κατευθύνσεις.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- PlatoData.Network Vertical Generative Ai. Ενδυναμώστε τον εαυτό σας. Πρόσβαση εδώ.
- PlatoAiStream. Web3 Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- PlatoESG. Αυτοκίνητο / EVs, Ανθρακας, Cleantech, Ενέργεια, Περιβάλλον, Ηλιακός, Διαχείριση των αποβλήτων. Πρόσβαση εδώ.
- BlockOffsets. Εκσυγχρονισμός της περιβαλλοντικής αντιστάθμισης ιδιοκτησίας. Πρόσβαση εδώ.
- πηγή: https://www.kdnuggets.com/2023/07/clustering-unleashed-understanding-kmeans-clustering.html?utm_source=rss&utm_medium=rss&utm_campaign=clustering-unleashed-understanding-k-means-clustering
- :έχει
- :είναι
- :δεν
- :που
- 1
- 10
- 11
- 13
- 16
- 25
- 28
- 7
- 8
- 9
- a
- πάνω από
- Διαφήμιση
- Μετά το
- αλγόριθμος
- αλγόριθμοι
- Όλα
- ήδη
- am
- an
- αναλύσει
- ανάλυση
- αναλύσει
- αναλύοντας
- και
- εφαρμογές
- εφαρμοσμένος
- πλησιάζω
- ΕΙΝΑΙ
- Παράταξη
- άρθρο
- AS
- At
- ΑΞΟΝΕΣ
- b
- Τράπεζες
- βασίζονται
- BE
- γίνονται
- πίσω
- παρακάτω
- μεταξύ
- Μπλε
- Κτίριο
- αλλά
- by
- CAN
- περίπτωση
- περιπτώσεις
- κατηγορία
- έλεγχος
- Επιλέξτε
- τάξη
- λέσχη
- συστάδα
- ομαδοποίηση
- κωδικός
- Στήλες
- έρχεται
- σχόλια
- συνήθως
- συγκρίνουν
- πλήρης
- Ολοκληρώνει
- συμπέρασμα
- Αντίστοιχος
- δημιουργία
- κρίσιμος
- Τη στιγμή
- πελάτης
- Πελάτες
- ημερομηνία
- ανάλυση δεδομένων
- εξόρυξη δεδομένων
- επιστημονικά δεδομένα
- σύνολα δεδομένων
- βαθύς
- βαθιά κατάδυση
- Ανάπτυξη
- διαφορετικές
- Βουτήξτε
- κατευθύνσεις
- συζήτηση
- συζήτηση
- απόσταση
- διακριτή
- do
- έγγραφο
- έγγραφα
- γίνεται
- κατεβάσετε
- σχεδιάζω
- e
- e-commerce
- κάθε
- πρόθυμος
- εύκολα
- Ηλεκτρολόγων Μηχανικών
- Μηχανική
- Κινητήρες
- εισάγετε
- κ.λπ.
- τελικά
- παράδειγμα
- Διερευνητική Ανάλυση Δεδομένων
- Εξερευνώντας
- ρητή
- εκχύλισμα
- Χαρακτηριστικό
- Χαρακτηριστικά
- πεδίο
- Πεδία
- Σύκο
- τελικός
- Τελικά
- Εύρεση
- εύρεση
- Όνομα
- ταιριάζουν
- Εξής
- Για
- σχηματίζεται
- φίλους
- από
- Δώστε
- δίνει
- Παγκόσμιο
- μετάβαση
- καλός
- Πράσινο
- Group
- Χειρισμός
- ιπποσκευή
- Έχω
- που έχει
- he
- βοήθεια
- χρήσιμο
- εδώ
- κρυμμένο
- του
- Πως
- HTTPS
- i
- if
- εικόνα
- εφαρμογή
- εκτέλεση
- εκτελεστικών
- εισαγωγή
- in
- Συμπεριλαμβανομένου
- υποδηλώνει
- βιομηχανικές
- αδράνεια
- ιδέες
- αντί
- τόκος
- συμφέροντα
- εσωτερικώς
- σε
- διαισθητική
- IT
- ΤΟΥ
- ταξίδι
- jpg
- KDnuggets
- επιγραφή
- μάθηση
- βιβλιοθήκες
- βρίσκεται
- περιορισμούς
- LINK
- Λιστα
- φορτίο
- τοπικός
- ματιά
- μηχανή
- μάθηση μηχανής
- Κυρίως
- κυρίως
- κάνω
- πολοί
- Ταίριασμα
- matplotlib
- νόημα
- μέσα
- Metrics
- νου
- ελάχιστο
- Εξόρυξη
- μοντέλο
- μοντελοποίηση
- ενότητα
- περισσότερο
- πλέον
- πολλαπλούς
- πρέπει
- απαραίτητος
- Ανάγκη
- Νέα
- Όχι.
- τώρα
- αριθμός
- πολλοί
- αντικείμενο
- παρατηρούμε
- αποκτήσει
- of
- on
- ONE
- αυτά
- βέλτιστη
- or
- ΑΛΛΑ
- δικός μας
- Πάντα
- passieren
- πρότυπο
- πρότυπα
- επίδοση
- person
- αγωγού
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- σημεία
- δυνατός
- δυναμικού
- ισχυρός
- προηγούμενος
- αρχές
- πιθανώς
- Πρόβλημα
- προβλήματα
- διαδικασια μας
- σχέδιο
- έργα
- πρωτότυπο
- παρέχεται
- παρέχει
- Python
- τυχαίος
- αναγνώριση
- συνιστώ
- Σύσταση
- Red
- έρευνα
- με αποτέλεσμα
- Αποτελέσματα
- επαναστατεί
- s
- εμπορικός
- ίδιο
- Επιστήμη
- θαλασσοπόρος
- Μυστικό
- Τμήμα
- δείτε
- τμήμα
- κατάτμηση
- επιλέγονται
- επιλογή
- επιλογή
- ξεχωριστό
- σειρά
- Σέτς
- Shape
- Κοινοποίηση
- παρουσιάζεται
- πλευρά
- σημαίνει
- παρόμοιες
- Απλούς
- So
- SOLVE
- Επίλυση
- μερικοί
- Αθλητισμός
- πλατείες
- πρότυπο
- Εκκίνηση
- Βήμα
- Βήματα
- κατάστημα
- καταστήματα
- Στρατηγική
- δύναμη
- Φοιτητής
- βέβαιος
- συνθετικός
- συστήματα
- στόχος
- εργασίες
- tech
- τηλεπικοινωνιών
- ότι
- Η
- τους
- Τους
- τότε
- Εκεί.
- επομένως
- Αυτοί
- πράγμα
- αυτό
- σκέψη
- Μέσω
- προς την
- προσπαθώ
- κατανόηση
- απελευθερωμένος
- ξεκλειδώσετε
- μη εποπτευόμενη μάθηση
- us
- χρήση
- μεταχειρισμένος
- Χρήστες
- χρησιμοποιεί
- χρησιμοποιώντας
- χρησιμοποιώ
- αξία
- Αξίες
- διάφορα
- οραματισμός
- vs
- θέλω
- we
- ιστός
- Web ανάπτυξη
- Ποιό
- ενώ
- Ο ΟΠΟΊΟΣ
- ευρέως
- θα
- με
- Εργασία
- εργαζόμενος
- εργασίες
- λειτουργεί
- X
- έτος
- κίτρινος
- εσείς
- Σας
- zephyrnet








