Εύρεση παρόμοιων στηλών σε α λίμνη δεδομένων έχει σημαντικές εφαρμογές στον καθαρισμό και τον σχολιασμό δεδομένων, την αντιστοίχιση σχημάτων, την ανακάλυψη δεδομένων και την ανάλυση σε πολλαπλές πηγές δεδομένων. Η αδυναμία ακριβούς εύρεσης και ανάλυσης δεδομένων από διαφορετικές πηγές αντιπροσωπεύει έναν πιθανό δολοφόνο αποτελεσματικότητας για όλους, από επιστήμονες δεδομένων, ιατρικούς ερευνητές, ακαδημαϊκούς έως οικονομικούς και κυβερνητικούς αναλυτές.
Οι συμβατικές λύσεις περιλαμβάνουν αναζήτηση λεξιλογικών λέξεων-κλειδιών ή αντιστοίχιση κανονικών εκφράσεων, οι οποίες είναι ευαίσθητες σε ζητήματα ποιότητας δεδομένων, όπως απουσία ονομάτων στηλών ή διαφορετικές συμβάσεις ονομασίας στηλών σε διάφορα σύνολα δεδομένων (για παράδειγμα, zip_code, zcode, postalcode).
Σε αυτήν την ανάρτηση, παρουσιάζουμε μια λύση για την αναζήτηση παρόμοιων στηλών με βάση το όνομα της στήλης, το περιεχόμενο στήλης ή και τα δύο. Η λύση χρησιμοποιεί κατά προσέγγιση αλγόριθμοι πλησιέστερων γειτόνων διαθέσιμο σε Amazon OpenSearch Service για να αναζητήσετε σημασιολογικά παρόμοιες στήλες. Για να διευκολυνθεί η αναζήτηση, δημιουργούμε αναπαραστάσεις χαρακτηριστικών (ενσωματώσεις) για μεμονωμένες στήλες στη λίμνη δεδομένων χρησιμοποιώντας προεκπαιδευμένα μοντέλα Transformer από το βιβλιοθήκη μετασχηματιστών προτάσεων in Amazon Sage Maker. Τέλος, για να αλληλεπιδράσουμε και να οπτικοποιήσουμε τα αποτελέσματα από τη λύση μας, χτίζουμε μια διαδραστική Ροή εφαρμογή web που εκτελείται AWS Fargate.
Περιλαμβάνουμε α σεμινάριο κώδικα για να αναπτύξετε τους πόρους για την εκτέλεση της λύσης σε δείγματα δεδομένων ή στα δικά σας δεδομένα.
Επισκόπηση λύσεων
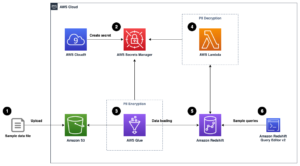
Το παρακάτω διάγραμμα αρχιτεκτονικής απεικονίζει τη ροή εργασίας δύο σταδίων για την εύρεση σημασιολογικά παρόμοιων στηλών. Το πρώτο στάδιο εκτελείται ένα Λειτουργίες βημάτων AWS ροή εργασίας που δημιουργεί ενσωματώσεις από στήλες σε πίνακα και δημιουργεί το ευρετήριο αναζήτησης της υπηρεσίας OpenSearch. Το δεύτερο στάδιο, ή το διαδικτυακό στάδιο συμπερασμάτων, εκτελεί μια εφαρμογή Streamlit μέσω του Fargate. Η εφαρμογή Ιστού συλλέγει ερωτήματα αναζήτησης εισόδου και ανακτά από το ευρετήριο OpenSearch Service τις κατά προσέγγιση k-πιο παρόμοιες στήλες με το ερώτημα.

Εικόνα 1. Αρχιτεκτονική λύσης
Η αυτοματοποιημένη ροή εργασιών προχωρά στα ακόλουθα βήματα:
- Ο χρήστης ανεβάζει σύνολα δεδομένων σε πίνακα σε ένα Απλή υπηρεσία αποθήκευσης Amazon (Amazon S3) κάδος, ο οποίος καλεί ένα AWS Lambda συνάρτηση που εκκινεί τη ροή εργασίας Step Functions.
- Η ροή εργασίας ξεκινά με ένα Κόλλα AWS εργασία που μετατρέπει τα αρχεία CSV σε Παρκέ Apache μορφή δεδομένων.
- Μια εργασία επεξεργασίας SageMaker δημιουργεί ενσωματώσεις για κάθε στήλη χρησιμοποιώντας προεκπαιδευμένα μοντέλα ή προσαρμοσμένα μοντέλα ενσωμάτωσης στηλών. Η εργασία SageMaker Processing αποθηκεύει τις ενσωματώσεις στηλών για κάθε πίνακα στο Amazon S3.
- Μια συνάρτηση Lambda δημιουργεί τον τομέα και το σύμπλεγμα OpenSearch Service για την ευρετηρίαση των ενσωματώσεων στηλών που παράγονται στο προηγούμενο βήμα.
- Τέλος, μια διαδραστική εφαρμογή web Streamlit αναπτύσσεται με το Fargate. Η εφαρμογή Ιστού παρέχει μια διεπαφή για τον χρήστη για να εισάγει ερωτήματα για αναζήτηση στον τομέα της Υπηρεσίας OpenSearch για παρόμοιες στήλες.
Μπορείτε να κατεβάσετε το σεμινάριο κώδικα από GitHub για να δοκιμάσετε αυτήν τη λύση σε δείγματα δεδομένων ή στα δικά σας δεδομένα. Οδηγίες σχετικά με τον τρόπο ανάπτυξης των απαιτούμενων πόρων για αυτό το σεμινάριο είναι διαθέσιμες στο Github.
Προαπαιτούμενα
Για να εφαρμόσετε αυτήν τη λύση, χρειάζεστε τα εξής:
- An Λογαριασμός AWS.
- Βασική εξοικείωση με υπηρεσίες AWS όπως η Κιτ ανάπτυξης AWS Cloud (AWS CDK), Lambda, OpenSearch Service και SageMaker Processing.
- Ένα σύνολο δεδομένων πίνακα για τη δημιουργία του ευρετηρίου αναζήτησης. Μπορείτε να φέρετε τα δικά σας δεδομένα σε πίνακα ή να κάνετε λήψη των δειγμάτων συνόλων δεδομένων GitHub.
Δημιουργήστε ένα ευρετήριο αναζήτησης
Το πρώτο στάδιο δημιουργεί το ευρετήριο της μηχανής αναζήτησης στήλης. Το παρακάτω σχήμα απεικονίζει τη ροή εργασίας Step Functions που εκτελεί αυτό το στάδιο.

Εικόνα 2 – Ροή εργασιών συναρτήσεων βήματος – μοντέλα πολλαπλών ενσωματώσεων
Δεδομένα
Σε αυτήν την ανάρτηση, δημιουργούμε ένα ευρετήριο αναζήτησης που περιλαμβάνει περισσότερες από 400 στήλες από περισσότερα από 25 σύνολα δεδομένων σε πίνακα. Τα σύνολα δεδομένων προέρχονται από τις ακόλουθες δημόσιες πηγές:
Για την πλήρη λίστα των πινάκων που περιλαμβάνονται στο ευρετήριο, ανατρέξτε στον οδηγό κώδικα GitHub.
Μπορείτε να φέρετε το δικό σας πίνακα δεδομένων για να αυξήσετε τα δείγματα δεδομένων ή να δημιουργήσετε το δικό σας ευρετήριο αναζήτησης. Περιλαμβάνουμε δύο συναρτήσεις Lambda που εκκινούν τη ροή εργασίας Step Functions για τη δημιουργία του ευρετηρίου αναζήτησης για μεμονωμένα αρχεία CSV ή μια παρτίδα αρχείων CSV, αντίστοιχα.
Μετατρέψτε το CSV σε Παρκέ
Τα ακατέργαστα αρχεία CSV μετατρέπονται σε μορφή δεδομένων Parquet με AWS Glue. Το Parquet είναι μια μορφή αρχείου προσανατολισμένη στη στήλη που προτιμάται στα αναλυτικά δεδομένα μεγάλων δεδομένων που παρέχει αποτελεσματική συμπίεση και κωδικοποίηση. Στα πειράματά μας, η μορφή δεδομένων Parquet προσέφερε σημαντική μείωση στο μέγεθος αποθήκευσης σε σύγκριση με τα ακατέργαστα αρχεία CSV. Χρησιμοποιήσαμε επίσης το Parquet ως κοινή μορφή δεδομένων για τη μετατροπή άλλων μορφών δεδομένων (για παράδειγμα JSON και NDJSON), επειδή υποστηρίζει προηγμένες ένθετες δομές δεδομένων.
Δημιουργήστε ενσωματώσεις στηλών σε πίνακα
Για να εξαγάγουμε ενσωματώσεις για μεμονωμένες στήλες πίνακα στα δείγματα συνόλων δεδομένων πίνακα σε αυτήν την ανάρτηση, χρησιμοποιούμε τα ακόλουθα προεκπαιδευμένα μοντέλα από το sentence-transformers βιβλιοθήκη. Για πρόσθετα μοντέλα, βλ Προεκπαιδευμένα μοντέλα.
Εκτελείται η εργασία επεξεργασίας SageMaker create_embeddings.py(κωδικός) για ένα μόνο μοντέλο. Για την εξαγωγή ενσωματώσεων από πολλά μοντέλα, η ροή εργασιών εκτελεί παράλληλες εργασίες επεξεργασίας του SageMaker, όπως φαίνεται στη ροή εργασίας Step Functions. Χρησιμοποιούμε το μοντέλο για να δημιουργήσουμε δύο σετ ενσωματώσεων:
- στήλη_όνομα_ενσωματώσεις – Ενσωματώσεις ονομάτων στηλών (κεφαλίδες)
- στήλη_περιεχόμενο_ενσωματώσεις – Μέση ενσωμάτωση όλων των γραμμών στη στήλη
Για περισσότερες πληροφορίες σχετικά με τη διαδικασία ενσωμάτωσης στηλών, ανατρέξτε στον οδηγό κώδικα στο GitHub.
Μια εναλλακτική λύση στο βήμα Επεξεργασίας SageMaker είναι να δημιουργήσετε έναν μετασχηματισμό παρτίδας του SageMaker για να λάβετε ενσωματώσεις στηλών σε μεγάλα σύνολα δεδομένων. Αυτό θα απαιτούσε την ανάπτυξη του μοντέλου σε ένα τελικό σημείο του SageMaker. Για περισσότερες πληροφορίες, βλ Χρησιμοποιήστε το Batch Transform.
Ενσωματώσεις ευρετηρίου με την υπηρεσία OpenSearch
Στο τελευταίο βήμα αυτού του σταδίου, μια συνάρτηση Lambda προσθέτει τις ενσωματώσεις στηλών σε μια Υπηρεσία OpenSearch κατά προσέγγιση k-Nearest-Neighbor (kNN) ευρετήριο αναζήτησης. Σε κάθε μοντέλο εκχωρείται το δικό του ευρετήριο αναζήτησης. Για περισσότερες πληροφορίες σχετικά με τις κατά προσέγγιση παραμέτρους ευρετηρίου αναζήτησης kNN, βλ κ-ΝΝ.
Online συμπεράσματα και σημασιολογική αναζήτηση με μια εφαρμογή Ιστού
Το δεύτερο στάδιο της ροής εργασίας εκτελείται α Ροή web εφαρμογή όπου μπορείτε να παρέχετε εισόδους και να αναζητήσετε σημασιολογικά παρόμοιες στήλες που έχουν ευρετηριαστεί στην Υπηρεσία OpenSearch. Το επίπεδο εφαρμογής χρησιμοποιεί ένα Ισορροπία φόρτωσης εφαρμογής, Fargate και Lambda. Η υποδομή της εφαρμογής αναπτύσσεται αυτόματα ως μέρος της λύσης.
Η εφαρμογή σάς επιτρέπει να παρέχετε μια εισαγωγή και να αναζητάτε σημασιολογικά παρόμοια ονόματα στηλών, περιεχόμενο στηλών ή και τα δύο. Επιπλέον, μπορείτε να επιλέξετε το μοντέλο ενσωμάτωσης και τον αριθμό των πλησιέστερων γειτόνων που θα επιστρέψετε από την αναζήτηση. Η εφαρμογή λαμβάνει εισόδους, ενσωματώνει την είσοδο με το καθορισμένο μοντέλο και χρησιμοποιεί Αναζήτηση kNN στην υπηρεσία OpenSearch για να αναζητήσετε ενσωματώσεις στηλών με ευρετήριο και να βρείτε τις πιο παρόμοιες στήλες με τη δεδομένη είσοδο. Τα αποτελέσματα αναζήτησης που εμφανίζονται περιλαμβάνουν τα ονόματα των πινάκων, τα ονόματα στηλών και τις βαθμολογίες ομοιότητας για τις στήλες που προσδιορίστηκαν, καθώς και τις θέσεις των δεδομένων στο Amazon S3 για περαιτέρω εξερεύνηση.
Το παρακάτω σχήμα δείχνει ένα παράδειγμα της διαδικτυακής εφαρμογής. Σε αυτό το παράδειγμα, αναζητήσαμε στήλες στη λίμνη δεδομένων μας που έχουν παρόμοια Column Names (τύπος ωφέλιμου φορτίου) Προς district (ωφέλιμο φορτίο). Η εφαρμογή που χρησιμοποιείται all-MiniLM-L6-v2 καθώς η μοντέλο ενσωμάτωσης και επέστρεψε 10 (k) οι πλησιέστεροι γείτονες από το ευρετήριο της Υπηρεσίας OpenSearch.
Η αίτηση επέστρεψε transit_district, city, borough, να location ως οι τέσσερις πιο παρόμοιες στήλες με βάση τα δεδομένα που ευρετηριάζονται στην Υπηρεσία OpenSearch. Αυτό το παράδειγμα δείχνει την ικανότητα της προσέγγισης αναζήτησης να προσδιορίζει σημασιολογικά παρόμοιες στήλες σε σύνολα δεδομένων.

Εικόνα 3: Διεπαφή χρήστη εφαρμογής Ιστού
εκκαθάριση
Για να διαγράψετε τους πόρους που δημιουργήθηκαν από το AWS CDK σε αυτό το σεμινάριο, εκτελέστε την ακόλουθη εντολή:
cdk destroy --allΣυμπέρασμα
Σε αυτήν την ανάρτηση, παρουσιάσαμε μια ροή εργασίας από άκρο σε άκρο για τη δημιουργία μιας μηχανής σημασιολογικής αναζήτησης για στήλες με πίνακα.
Ξεκινήστε σήμερα με τα δικά σας δεδομένα με το σεμινάριο κώδικα που είναι διαθέσιμο στο GitHub. Εάν θέλετε βοήθεια για την επιτάχυνση της χρήσης του ML στα προϊόντα και τις διαδικασίες σας, επικοινωνήστε με το Εργαστήριο Amazon Machine Learning Solutions.
Σχετικά με τους Συγγραφείς
![]() Kachi Odoemene είναι Εφαρμοσμένος Επιστήμονας στο AWS AI. Κατασκευάζει λύσεις AI/ML για την επίλυση επιχειρηματικών προβλημάτων για πελάτες AWS.
Kachi Odoemene είναι Εφαρμοσμένος Επιστήμονας στο AWS AI. Κατασκευάζει λύσεις AI/ML για την επίλυση επιχειρηματικών προβλημάτων για πελάτες AWS.
![]() Taylor McNally είναι αρχιτέκτονας Deep Learning στο Amazon Machine Learning Solutions Lab. Βοηθά πελάτες από διάφορες βιομηχανίες να δημιουργήσουν λύσεις αξιοποιώντας το AI/ML στο AWS. Απολαμβάνει ένα καλό φλιτζάνι καφέ, την ύπαιθρο και χρόνο με την οικογένειά του και τον ενεργητικό σκύλο του.
Taylor McNally είναι αρχιτέκτονας Deep Learning στο Amazon Machine Learning Solutions Lab. Βοηθά πελάτες από διάφορες βιομηχανίες να δημιουργήσουν λύσεις αξιοποιώντας το AI/ML στο AWS. Απολαμβάνει ένα καλό φλιτζάνι καφέ, την ύπαιθρο και χρόνο με την οικογένειά του και τον ενεργητικό σκύλο του.
![]() Austin Welch είναι Επιστήμονας Δεδομένων στο Amazon ML Solutions Lab. Αναπτύσσει προσαρμοσμένα μοντέλα βαθιάς εκμάθησης για να βοηθήσει τους πελάτες του δημόσιου τομέα του AWS να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud. Στον ελεύθερο χρόνο του, του αρέσει το διάβασμα, τα ταξίδια και το jiu-jitsu.
Austin Welch είναι Επιστήμονας Δεδομένων στο Amazon ML Solutions Lab. Αναπτύσσει προσαρμοσμένα μοντέλα βαθιάς εκμάθησης για να βοηθήσει τους πελάτες του δημόσιου τομέα του AWS να επιταχύνουν την υιοθέτηση της τεχνητής νοημοσύνης και του cloud. Στον ελεύθερο χρόνο του, του αρέσει το διάβασμα, τα ταξίδια και το jiu-jitsu.
- SEO Powered Content & PR Distribution. Ενισχύστε σήμερα.
- Platoblockchain. Web3 Metaverse Intelligence. Ενισχύθηκε η γνώση. Πρόσβαση εδώ.
- πηγή: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- ικανότητα
- Σχετικα
- απών
- επιταχύνουν
- επιταχύνοντας
- με ακρίβεια
- απέναντι
- Πρόσθετος
- Επιπλέον
- Προσθέτει
- Υιοθεσία
- προηγμένες
- AI
- AI / ML
- Όλα
- επιτρέπει
- εναλλακτική λύση
- Amazon
- Εκμάθηση μηχανών του Αμαζονίου
- Εργαστήριο Amazon ML Solutions
- Αναλυτές
- analytics
- αναλύσει
- και
- Apache
- Εφαρμογή
- εφαρμογές
- εφαρμοσμένος
- πλησιάζω
- αρχιτεκτονική
- ανατεθεί
- Αυτοματοποιημένη
- αυτομάτως
- διαθέσιμος
- μέσος
- AWS
- Κόλλα AWS
- βασίζονται
- επειδή
- Μεγάλος
- Big Data
- φέρω
- χτίζω
- Κτίριο
- Χτίζει
- επιχείρηση
- Καθάρισμα
- Backup
- υιοθέτηση νέφους
- συστάδα
- κωδικός
- Καφές
- συλλέγει
- Στήλη
- Στήλες
- Κοινός
- σύγκριση
- επικοινωνήστε μαζί μας
- περιεχόμενο
- συμβάσεις
- μετατρέψετε
- μετατρέπονται
- δημιουργία
- δημιουργήθηκε
- δημιουργεί
- Φλιτζάνι
- έθιμο
- Πελάτες
- ημερομηνία
- Δεδομένα Analytics
- Λίμνη δεδομένων
- την ποιότητα των δεδομένων
- επιστήμονας δεδομένων
- σύνολα δεδομένων
- βαθύς
- βαθιά μάθηση
- αποδεικνύουν
- καταδεικνύει
- παρατάσσω
- αναπτυχθεί
- ανάπτυξη
- καταστρέψει
- Ανάπτυξη
- αναπτύσσεται
- διαφορετικές
- ανακάλυψη
- τρέλα
- διάφορα
- Σκύλος
- τομέα
- κατεβάσετε
- κάθε
- αποδοτικότητα
- αποτελεσματικός
- από άκρη σε άκρη
- Τελικό σημείο
- Κινητήρας
- Αιθέρας (ΕΤΗ)
- όλοι
- παράδειγμα
- εξερεύνηση
- εκχύλισμα
- διευκολύνω
- Εξοικείωση
- οικογένεια
- Χαρακτηριστικά
- Εικόνα
- Αρχεία
- Αρχεία
- τελικός
- Τελικά
- οικονομικός
- Εύρεση
- εύρεση
- Όνομα
- Εξής
- μορφή
- από
- πλήρη
- λειτουργία
- λειτουργίες
- περαιτέρω
- παίρνω
- δεδομένου
- καλός
- Κυβέρνηση
- κεφαλίδες
- βοήθεια
- βοηθά
- Πως
- Πώς να
- HTML
- HTTPS
- προσδιορίζονται
- προσδιορίσει
- εφαρμογή
- σημαντικό
- in
- αδυναμία
- περιλαμβάνουν
- περιλαμβάνονται
- ευρετήριο
- ατομικές
- βιομηχανίες
- πληροφορίες
- Υποδομή
- κινήσει
- Αρχίζει
- εισαγωγή
- οδηγίες
- αλληλεπιδρούν
- διαδραστικό
- περιβάλλον λειτουργίας
- επικαλείται
- εμπλέκω
- θέματα
- IT
- Δουλειά
- Θέσεις εργασίας
- json
- εργαστήριο
- λίμνη
- large
- στρώμα
- μάθηση
- μόχλευσης
- Βιβλιοθήκη
- Λιστα
- φορτίο
- θέσεις
- μηχανή
- μάθηση μηχανής
- ταιριάζουν
- ιατρικών
- ML
- μοντέλο
- μοντέλα
- περισσότερο
- πλέον
- πολλαπλούς
- όνομα
- ονόματα
- ονοματοδοσία
- Ανάγκη
- γείτονες
- αριθμός
- προσφέρονται
- διαδικτυακά (online)
- ΑΛΛΑ
- ύπαιθρο
- δική
- Παράλληλο
- παράμετροι
- μέρος
- Πλάτων
- Πληροφορία δεδομένων Plato
- Πλάτωνα δεδομένα
- σας παρακαλούμε
- Θέση
- δυναμικού
- προτιμάται
- παρουσιάζονται
- προηγούμενος
- προβλήματα
- πρόσοδοι
- διαδικασια μας
- Διεργασίες
- μεταποίηση
- Παράγεται
- Προϊόντα
- παρέχουν
- παρέχει
- δημόσιο
- ποιότητα
- Ακατέργαστος
- Ανάγνωση
- λαμβάνει
- τακτικός
- αντιπροσωπεύει
- απαιτούν
- απαιτείται
- ερευνητές
- Υποστηρικτικό υλικό
- αντίστοιχα
- Αποτελέσματα
- απόδοση
- τρέξιμο
- τρέξιμο
- σοφός
- Επιστήμονας
- επιστήμονες
- Αναζήτηση
- μηχανή αναζήτησης
- αναζήτηση
- Δεύτερος
- τομέας
- υπηρεσία
- Υπηρεσίες
- Σέτς
- παρουσιάζεται
- Δείχνει
- σημαντικός
- παρόμοιες
- Απλούς
- ενιαίας
- Μέγεθος
- λύση
- Λύσεις
- SOLVE
- Πηγές
- καθορίζεται
- Στάδιο
- ξεκίνησε
- Βήμα
- Βήματα
- χώρος στο δίσκο
- τέτοιος
- Υποστηρίζει
- ευαίσθητος
- τραπέζι
- Η
- τους
- Μέσω
- ώρα
- προς την
- σήμερα
- Μεταμορφώστε
- μετασχηματιστές
- Ταξίδια
- φροντιστήριο
- χρήση
- Χρήστες
- Διεπαφής χρήστη
- διάφορα
- ιστός
- Εφαρμογή Web
- Ποιό
- ροής εργασίας
- θα
- Σας
- zephyrnet