15 αποσπάσματα Python για τη βελτιστοποίηση του αγωγού επιστήμης δεδομένων σας
Γρήγορες λύσεις Python που βοηθούν τον κύκλο της επιστήμης των δεδομένων σας.
By Λούκας Σοάρες, Μηχανικός Μηχανικής Μάθησης στην K1 Digital

Φωτογραφία Κάρλος Μούζα on Unsplash
Γιατί τα αποσπάσματα έχουν σημασία για την επιστήμη των δεδομένων
Στην καθημερινή μου ρουτίνα πρέπει να αντιμετωπίζω πολλές ίδιες καταστάσεις, από τη φόρτωση αρχείων csv έως την οπτικοποίηση δεδομένων. Έτσι, για να βοηθήσω στον εξορθολογισμό της διαδικασίας μου, δημιούργησα τη συνήθεια να αποθηκεύω αποσπάσματα κώδικα που είναι χρήσιμα σε διαφορετικές καταστάσεις, από τη φόρτωση αρχείων csv έως την οπτικοποίηση δεδομένων.
Σε αυτήν την ανάρτηση θα μοιραστώ 15 αποσπάσματα κώδικα για να σας βοηθήσω με διάφορες πτυχές του αγωγού ανάλυσης δεδομένων σας
1. Φόρτωση πολλών αρχείων με κατανόηση σφαιρών και λίστας
import glob
import pandas as pd
csv_files = glob.glob("path/to/folder/with/csvs/*.csv")
dfs = [pd.read_csv(filename) for filename in csv_files]2. Λήψη μοναδικών τιμών από έναν πίνακα στηλών
import pandas as pd
df = pd.read_csv("path/to/csv/file.csv")
df["Item_Identifier"].unique()array(['FDA15', 'DRC01', 'FDN15', ..., 'NCF55', 'NCW30', 'NCW05'], dtype=object)3. Εμφανίστε τα πλαίσια δεδομένων pandas δίπλα-δίπλα
from IPython.display import display_html
from itertools import chain,cycledef display_side_by_side(*args,titles=cycle([''])): # source: https://stackoverflow.com/questions/38783027/jupyter-notebook-display-two-pandas-tables-side-by-side html_str='' for df,title in zip(args, chain(titles,cycle(['</br>'])) ): html_str+='<th style="text-align:center"><td style="vertical-align:top">' html_str+="<br>" html_str+=f'<h2>{title}</h2>' html_str+=df.to_html().replace('table','table style="display:inline"') html_str+='</td></th>' display_html(html_str,raw=True)
df1 = pd.read_csv("file.csv")
df2 = pd.read_csv("file2")
display_side_by_side(df1.head(),df2.head(), titles=['Sales','Advertising'])
### Output
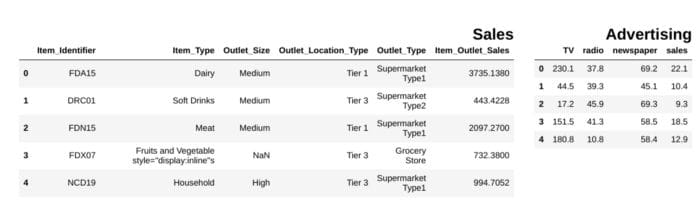
εικόνα από τον συγγραφέα
4. Αφαιρέστε όλα τα NaN στο πλαίσιο δεδομένων pandas
df = pd.DataFrame(dict(a=[1,2,3,None]))
df
df.dropna(inplace=True)
df

5. Εμφάνιση αριθμού καταχωρήσεων NaN στις στήλες DataFrame
def findNaNCols(df): for col in df: print(f"Column: {col}") num_NaNs = df[col].isnull().sum() print(f"Number of NaNs: {num_NaNs}")
df = pd.DataFrame(dict(a=[1,2,3,None],b=[None,None,5,6]))
findNaNCols(df)# OutputColumn: a
Number of NaNs: 1
Column: b
Number of NaNs: 26. Μετασχηματισμός στηλών με .apply και συναρτήσεις λάμδα
df = pd.DataFrame(dict(a=[10,20,30,40,50]))
square = lambda x: x**2
df["a"]=df["a"].apply(square)
df

7. Μετατροπή 2 στηλών DataFrame σε λεξικό
df = pd.DataFrame(dict(a=["a","b","c"],b=[1,2,3]))
df_dictionary = dict(zip(df["a"],df["b"]))
df_dictionary{'a': 1, 'b': 2, 'c': 3}8. Πλέγμα γραφικής παράστασης κατανομών με προϋποθέσεις σε στήλες
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd df = pd.DataFrame(dict(a=np.random.randint(0,100,100),b=np.arange(0,100,1)))
plt.figure(figsize=(15,7))
plt.subplot(1,2,1)
df["b"][df["a"]>50].hist(color="green",label="bigger than 50")
plt.legend()
plt.subplot(1,2,2)
df["b"][df["a"]<50].hist(color="orange",label="smaller than 50")
plt.legend()
plt.show()
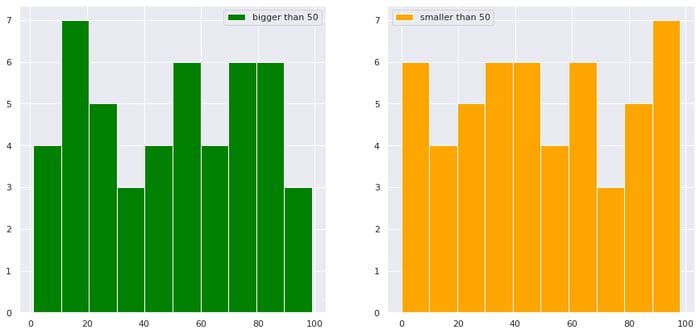
εικόνα από τον συγγραφέα
9. Εκτέλεση t-tests για τιμές διαφορετικών στηλών σε panda
from scipy.stats import ttest_rel data = np.arange(0,1000,1)
data_plus_noise = np.arange(0,1000,1) + np.random.normal(0,1,1000)
df = pd.DataFrame(dict(data=data, data_plus_noise=data_plus_noise))
print(ttest_rel(df["data"],df["data_plus_noise"]))# Output
Ttest_relResult(statistic=-1.2717454718006775, pvalue=0.20375954602300195)10. Συγχώνευση πλαισίων δεδομένων σε μια δεδομένη στήλη
df1 = pd.DataFrame(dict(a=[1,2,3],b=[10,20,30],col_to_merge=["a","b","c"]))
df2 = pd.DataFrame(dict(d=[10,20,100],col_to_merge=["a","b","c"]))
df_merged = df1.merge(df2, on='col_to_merge')
df_merged

11. Κανονικοποίηση τιμών σε στήλη pandas με sklearn
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scores = scaler.fit_transform(df["a"].values.reshape(-1,1))12. Ρίχνοντας NaNs σε μια συγκεκριμένη στήλη στα πάντα
df.dropna(subset=["col_to_remove_NaNs_from"],inplace=True)13. Επιλογή υποσυνόλου ενός πλαισίου δεδομένων με προϋποθέσεις και or δήλωση
df = pd.DataFrame(dict(result=["Pass","Fail","Pass","Fail","Distinction","Distinction"]))
pass_index = (df["result"]=="Pass") | (df["result"]=="Distinction")
df_pass = df[pass_index]
df_pass

14. Βασικό διάγραμμα πίτας
import matplotlib.pyplot as plt df = pd.DataFrame(dict(a=[10,20,50,10,10],b=["A","B","C","D","E"]))
labels = df["b"]
sizes = df["a"]
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()

15. Αλλαγή συμβολοσειράς ποσοστού σε αριθμητική τιμή χρησιμοποιώντας .apply()
def change_to_numerical(x): try: x = int(x.strip("%")[:2]) except: x = int(x.strip("%")[:1]) return x df = pd.DataFrame(dict(a=["A","B","C"],col_with_percentage=["10%","70%","20%"]))
df["col_with_percentage"] = df["col_with_percentage"].apply(change_to_numerical)
df

Συμπέρασμα
Νομίζω ότι τα αποσπάσματα κώδικα είναι εξαιρετικά πολύτιμα, η επανεγγραφή κώδικα μπορεί να είναι πραγματικό χάσιμο χρόνου, επομένως η ύπαρξη μιας ολοκληρωμένης εργαλειοθήκης με όλες τις απλές λύσεις που χρειάζεστε για να βελτιστοποιήσετε τη διαδικασία ανάλυσης δεδομένων σας μπορεί να σας βοηθήσει πολύ.
Αν σας άρεσε αυτή η ανάρτηση επικοινωνήστε μαζί μου Twitter, LinkedIn και ακολούθησέ με Μέτριας Δυσκολίας. Ευχαριστώ και τα λέμε την επόμενη φορά! 🙂
Περισσότερο περιεχόμενο στο plainenglish.io
Bio: Λούκας Σοάρες είναι ένας μηχανικός AI που εργάζεται σε εφαρμογές βαθιάς μάθησης σε ένα ευρύ φάσμα προβλημάτων.
Πρωτότυπο. Αναδημοσιεύτηκε με άδεια.
Συγγενεύων:
Πηγή: https://www.kdnuggets.com/2021/08/15-python-snippets-optimize-data-science-pipeline.html
- '
- "
- &
- 100
- 7
- Διαφήμιση
- AI
- Όλα
- ανάλυση
- Εφαρμογή
- εφαρμογές
- αυτόματη
- AWS
- κωδικός
- Στήλη
- Κοινός
- περιεχόμενο
- ημερομηνία
- ανάλυση δεδομένων
- επιστημονικά δεδομένα
- συμφωνία
- βαθιά μάθηση
- Διευθυντής
- μηχανικός
- Χαρακτηριστικά
- Όνομα
- ακολουθήστε
- GPU
- εξαιρετική
- Πράσινο
- Πλέγμα
- Πως
- Πώς να
- HTTPS
- συνέντευξη
- Ετικέτες
- ΜΑΘΑΊΝΩ
- μάθηση
- Λιστα
- μάθηση μηχανής
- medium
- ML
- Νευρικός
- ανοίξτε
- ανοικτού κώδικα
- Python
- σειρά
- λόγους
- οπισθοδρόμηση
- τρέξιμο
- εμπορικός
- Επιστήμη
- επιστήμονες
- Κοινοποίηση
- Απλούς
- So
- Λύσεις
- πλατεία
- stats
- ιστορίες
- TD
- Δοκιμές
- ώρα
- κορυφή
- μετασχηματίζοντας
- αξία
- X