Forfatter: Vitalik Buterin via Vitalik Buterin blog
Særlig tak til Worldcoin- og Modulus Labs-teamene, Xinyuan Sun, Martin Koeppelmann og Illia Polosukhin for feedback og diskussion.
Mange mennesker gennem årene har stillet mig et lignende spørgsmål: hvad er det kryds mellem krypto og AI, som jeg anser for at være den mest frugtbare? Det er et rimeligt spørgsmål: Krypto og AI er de to vigtigste dybe (software) teknologitrends i det sidste årti, og det føles bare som om der skal være en form for forbindelse mellem de to. Det er nemt at komme med synergier på et overfladisk vibeniveau: kryptodecentralisering kan balancere AI-centralisering, AI er uigennemsigtig og krypto bringer gennemsigtighed, AI har brug for data og blockchains er gode til at gemme og spore data. Men gennem årene, hvor folk bad mig om at grave et niveau dybere og tale om specifikke applikationer, har mit svar været skuffende: "ja, der er et par ting, men ikke så meget".
I de sidste tre år, med fremkomsten af meget mere kraftfuld AI i form af moderne LLM'er, og fremkomsten af meget mere kraftfuld krypto i form af ikke kun blockchain-skaleringsløsninger, men også ZKPs, FHE, (to-parti og N-parti) MPC, jeg begynder at se denne ændring. Der er faktisk nogle lovende anvendelser af AI inde i blockchain-økosystemer, eller AI sammen med kryptografi, selvom det er vigtigt at være forsigtig med, hvordan AI'en anvendes. En særlig udfordring er: I kryptografi er open source den eneste måde at gøre noget virkelig sikkert på, men i AI er en model (eller endda dens træningsdata) åben stiger kraftigt dens sårbarhed overfor modstridende maskinlæring angreb. Dette indlæg vil gennemgå en klassificering af forskellige måder, hvorpå krypto + AI kan krydse hinanden, og perspektiverne og udfordringerne for hver kategori.
En oversigt på højt niveau af crypto+AI skæringspunkter fra en uETH blogindlæg. Men hvad skal der til for rent faktisk at realisere nogen af disse synergier i en konkret applikation?
De fire hovedkategorier
AI er et meget bredt begreb: du kan tænke på "AI" som værende det sæt af algoritmer, som du ikke skaber ved at specificere dem eksplicit, men snarere ved at røre en stor beregningssuppe og lægge en form for optimeringstryk, der skubber suppen mod producere algoritmer med de egenskaber, du ønsker. Denne beskrivelse skal bestemt ikke tages afvisende: den omfatter og behandle at oprettet os mennesker i første omgang! Men det betyder, at AI-algoritmer har nogle fælles egenskaber: deres evne til at gøre ting, der er ekstremt kraftfulde, sammen med grænser for vores evne til at vide eller forstå, hvad der foregår under motorhjelmen.
Der er mange måder at kategorisere AI på; i forbindelse med dette indlæg, som taler om interaktioner mellem AI og blockchains (som er blevet beskrevet som en platform for skabe "spil"), vil jeg kategorisere det som følger:
- AI som spiller i et spil [højeste levedygtighed]: AI'er deltager i mekanismer, hvor den ultimative kilde til incitamenterne kommer fra en protokol med menneskelige input.
- AI som en grænseflade til spillet [højt potentiale, men med risici]: AI hjælper brugere med at forstå kryptoverdenen omkring dem og sikre, at deres adfærd (dvs. signerede meddelelser og transaktioner) matcher deres intentioner, og at de ikke bliver snydt eller snydt.
- AI som spillets regler [træd meget forsigtigt]: blockchains, DAO'er og lignende mekanismer, der direkte kalder ind i AI'er. Tænk fx. "AI-dommere"
- AI som formålet med spillet [langsigtet, men spændende]: design af blockchains, DAO'er og lignende mekanismer med det formål at konstruere og vedligeholde en AI, der kunne bruges til andre formål, ved at bruge kryptobits enten til bedre at stimulere træning eller for at forhindre AI i at lække private data eller blive misbrugt.
Lad os gennemgå disse én efter én.
AI som spiller i et spil
Dette er faktisk en kategori, der har eksisteret i næsten et årti, i hvert fald siden on-chain decentraliserede udvekslinger (DEX'er) begyndte at se betydelig brug. Hver gang der er en udveksling, er der mulighed for at tjene penge gennem arbitrage, og bots kan gøre arbitrage meget bedre, end mennesker kan. Denne use case har eksisteret i lang tid, selv med meget simplere AI'er end hvad vi har i dag, men i sidste ende er det et meget ægte AI + krypto-krydsningspunkt. For nylig har vi set MEV arbitrage bots ofte udnytter hinanden. Hver gang du har en blockchain-applikation, der involverer auktioner eller handel, vil du have arbitrage-bots.
Men AI-arbitrage-bots er kun det første eksempel på en meget større kategori, som jeg forventer snart vil begynde at inkludere mange andre applikationer. Mød AIOmen, en demo af et forudsigelsesmarked, hvor AI'er er spillere:
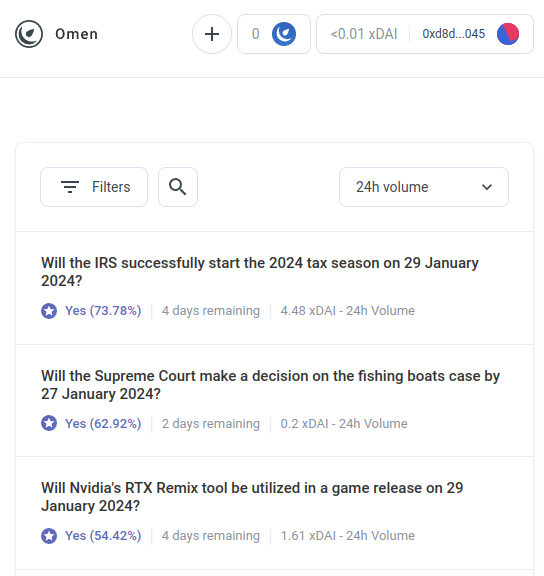
Et svar på dette er at pege på løbende UX-forbedringer i Polymarked eller andre nye forudsigelsesmarkeder, og håber, at de vil lykkes, hvor tidligere iterationer har fejlet. Når alt kommer til alt, lyder historien, er folk villige til at satse titusindvis af milliarder på sport, så hvorfor ville folk ikke smide penge nok med at satse på amerikanske valg eller LK99 at det begynder at give mening, at de seriøse spillere begynder at komme ind? Men dette argument må kæmpe med det faktum, at, ja, tidligere iterationer have formåede ikke at nå dette skalaniveau (i hvert fald sammenlignet med deres fortaleres drømme), og så det ser ud til, at du har brug for noget nyt at få forudsigelsesmarkederne til at lykkes. Og så et andet svar er at pege på et specifikt træk ved forudsigelsesmarkedsøkosystemer, som vi kan forvente at se i 2020'erne, som vi ikke så i 2010'erne: muligheden for allestedsnærværende deltagelse af AI'er.
AI'er er villige til at arbejde for mindre end $1 i timen og har kendskabet til et leksikon – og hvis det ikke er nok, kan de endda integreres med realtids-websøgningsfunktioner. Hvis du laver et marked og giver et likviditetstilskud på $50, vil mennesker være ligeglade nok med at byde, men tusindvis af AI'er vil nemt myldre over hele spørgsmålet og lave det bedste gæt, de kan. Incitamentet til at gøre et godt stykke arbejde med ethvert spørgsmål kan være lille, men incitamentet til at lave en AI, der giver gode forudsigelser generelt kan være i millioner. Bemærk, at potentielt, du behøver ikke engang mennesker til at bedømme de fleste spørgsmål: du kan bruge et multi-round tvistsystem svarende til Augur eller Kleros, hvor AI'er også ville være dem, der deltager i tidligere runder. Mennesker behøver kun at reagere i de få tilfælde, hvor en række eskalationer har fundet sted, og der er begået store beløb fra begge sider.
Dette er en stærk primitiv, for når først et "forudsigelsesmarked" kan fås til at fungere på en sådan mikroskopisk skala, kan du genbruge "forudsigelsesmarkedets" primitiv til mange andre slags spørgsmål:
- Er dette indlæg på sociale medier acceptabelt under [brugsbetingelser]?
- Hvad vil der ske med prisen på aktie X (se f.eks Numerai)
- Er denne konto, der i øjeblikket sender mig beskeder, faktisk Elon Musk?
- Er denne arbejdsindsendelse på en online opgavemarkedsplads acceptabel?
- Er dapp'en på https://examplefinance.network en fidus?
- Is
0x1b54....98c3faktisk adressen på "Casinu Inu" ERC20-tokenet?
Du bemærker måske, at mange af disse ideer går i retning af det, jeg kaldte "info forsvar” i. Bredt defineret er spørgsmålet: hvordan hjælper vi brugere med at skelne sande og falske oplysninger fra hinanden og opdage svindel uden at bemyndige en centraliseret autoritet til at beslutte rigtigt og forkert, hvem der så kan misbruge denne position? På mikroniveau kan svaret være "AI". Men på makroniveau er spørgsmålet: hvem bygger AI'en? AI er en afspejling af den proces, der skabte den, og kan derfor ikke undgå at have skævheder. Derfor er der behov for et spil på højere niveau, som bedømmer, hvor godt de forskellige AI'er klarer sig, hvor AI'er kan deltage som spillere i spillet.
Denne brug af AI, hvor AI'er deltager i en mekanisme, hvor de i sidste ende bliver belønnet eller straffet (sandsynligvis) af en on-chain mekanisme, der samler input fra mennesker (kald det decentraliseret markedsbaseret RLHF?), er noget, som jeg synes er virkelig værd at se nærmere på. Nu er det rigtige tidspunkt at se nærmere på brugssager som dette, fordi blockchain-skalering endelig lykkes, hvilket gør "mikro-" noget endeligt levedygtigt på kæden, når det ofte ikke var før.
En relateret kategori af applikationer går i retning af meget autonome agenter bruge blockchains til bedre at samarbejde, hvad enten det er gennem betalinger eller ved at bruge smarte kontrakter til at give troværdige forpligtelser.
AI som en grænseflade til spillet
En idé, som jeg tog op i min skriverier på er ideen om, at der er en markedsmulighed for at skrive brugervendt software, der beskytter brugernes interesser ved at fortolke og identificere farer i den online verden, som brugeren navigerer efter. Et allerede eksisterende eksempel på dette er Metamasks scam-detektionsfunktion:
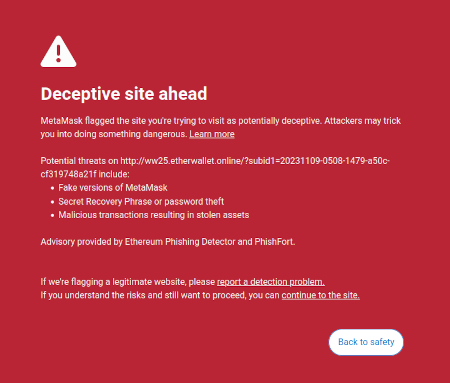
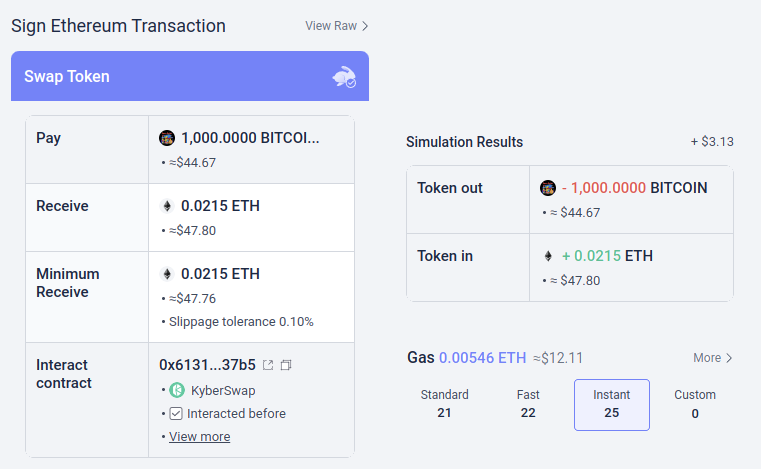
Potentielt kan denne slags værktøjer være superladede med AI. AI kunne give en meget rigere menneskevenlig forklaring på, hvilken slags dapp du deltager i, konsekvenserne af mere komplicerede operationer, som du underskriver, uanset om et bestemt token er ægte eller ej (f. BITCOIN er ikke bare en streng af tegn, det er navnet på en faktisk kryptovaluta, som ikke er et ERC20-token, og som har en pris, der er højere end $0.045, og en moderne LLM ville vide det), og så videre. Der er projekter, der begynder at gå helt ud i denne retning (f.eks LangChain pung, som bruger AI som en primære grænseflade). Min egen mening er, at rene AI-grænseflader nok er for risikable i øjeblikket, da det øger risikoen for andre slags fejl, men AI, der supplerer en mere konventionel grænseflade, bliver meget levedygtig.
Der er én særlig risiko, der er værd at nævne. Jeg vil komme mere ind på dette i afsnittet om "AI som spilleregler" nedenfor, men det generelle problem er modstridende maskinlæring: hvis en bruger har adgang til en AI-assistent inde i en open source-pung, vil de onde også have adgang til den AI-assistent, og så vil de have ubegrænsede muligheder for at optimere deres svindel til ikke at udløse den pungs forsvar. Alle moderne AI'er har fejl et eller andet sted, og det er ikke for svært for en træningsproces, selv en med kun begrænset adgang til modellen, for at finde dem.
Det er her, "AI'er, der deltager i mikromarkeder i kæden" fungerer bedre: hver enkelt AI er sårbar over for de samme risici, men du skaber med vilje et åbent økosystem af snesevis af mennesker, der konstant itererer og forbedrer dem på en løbende basis. Desuden er hver enkelt AI lukket: systemets sikkerhed kommer fra åbenheden i reglerne for spil, ikke den interne funktion af hver enkelt spiller.
Sammendrag: AI kan hjælpe brugere med at forstå, hvad der foregår i almindeligt sprog, det kan tjene som en real-time tutor, det kan beskytte brugere mod fejl, men vær advaret, når du forsøger at bruge det direkte mod ondsindede fejlinformere og svindlere.
AI som spillets regler
Nu kommer vi til den applikation, som mange mennesker er begejstrede for, men som jeg synes er den mest risikable, og hvor vi skal træde mest forsigtigt: Det, jeg kalder AI, er en del af spillets regler. Dette hænger sammen med begejstring blandt mainstream politiske eliter om "AI-dommere" (se f.eks denne artikel på hjemmesiden for "World Government Summit"), og der er analoger til disse ønsker i blockchain-applikationer. Hvis en blockchain-baseret smart kontrakt eller en DAO skal træffe en subjektiv beslutning (f.eks. er et bestemt arbejdsprodukt acceptabelt i en work-for-hire kontrakt? Hvilken er den rigtige fortolkning af en naturligt sproglig forfatning som Optimismen Lov om kæder?), kunne du få en AI til blot at være en del af kontrakten eller DAO for at hjælpe med at håndhæve disse regler?
Det er her modstridende maskinlæring bliver en ekstremt hård udfordring. Det grundlæggende argument i to sætninger hvorfor er som følger:
Hvis en AI-model, der spiller en nøglerolle i en mekanisme, lukkes, kan du ikke verificere dens indre funktion, og den er derfor ikke bedre end en centraliseret applikation. Hvis AI-modellen er åben, så kan en angriber downloade og simulere den lokalt og designe stærkt optimerede angreb for at narre modellen, som de så kan afspille på live-netværket.

Nu kan hyppige læsere af denne blog (eller indbyggere fra cryptoverse) allerede komme mig foran og tænke: men vent! Vi har fancy nul viden beviser og andre virkelig fede former for kryptografi. Vi kan helt sikkert lave noget krypto-magi og skjule modellens indre funktioner, så angribere ikke kan optimere angreb, men samtidig bevise at modellen bliver eksekveret korrekt, og blev konstrueret ved hjælp af en rimelig træningsproces på et rimeligt sæt af underliggende data!
Normalt er dette præcist nok den type tænkning, som jeg går ind for både på denne blog og i mine andre skrifter. Men i tilfælde af AI-relateret beregning er der to store indvendinger:
- Kryptografisk overhead: det er meget mindre effektivt at gøre noget inde i en SNARK (eller MPC eller...), end det er at gøre det "i det klare". I betragtning af at AI allerede er meget beregningsintensivt, er det så overhovedet beregningsmæssigt muligt at lave AI inde i kryptografiske sorte bokse?
- Black-box modstridende maskinlæringsangreb: der er måder at optimere angreb mod AI-modeller på også uden at vide meget om modellens interne virke. Og hvis du gemmer dig for meget, risikerer du at gøre det for nemt for den, der vælger træningsdataene, at korrumpere modellen med forgiftning angreb.
Begge disse er komplicerede kaninhuller, så lad os komme ind på hver af dem på skift.
Kryptografisk overhead
Kryptografiske gadgets, især dem til generelle formål som ZK-SNARK'er og MPC, har en høj overhead. En Ethereum-blok tager et par hundrede millisekunder for en klient at verificere direkte, men at generere en ZK-SNARK for at bevise rigtigheden af en sådan blok kan tage timer. Den typiske overhead for andre kryptografiske gadgets, som MPC, kan være endnu værre. AI-beregning er allerede dyr: de mest kraftfulde LLM'er kan kun udskrive individuelle ord en smule hurtigere, end mennesker kan læse dem, for ikke at nævne de ofte mange millioner dollar beregningsomkostninger ved uddannelse modellerne. Forskellen i kvalitet mellem topmodeller og de modeller, der forsøger at spare meget mere på uddannelsesomkostninger or parameterantal er stor. Ved første øjekast er dette en meget god grund til at være mistænksom over for hele projektet med at forsøge at tilføje garantier til AI ved at pakke det ind i kryptografi.
Heldigvis dog AI er en meget specifik type af beregning, hvilket gør det egnet til alle former for optimeringer som mere "ustrukturerede" typer beregninger som ZK-EVM'er ikke kan drage fordel af. Lad os undersøge den grundlæggende struktur af en AI-model:

y = max(x, 0)). Asymptotisk tager matrixmultiplikationer det meste af arbejdet: at gange to N*N matrixer tager �(�2.8) tid, hvorimod antallet af ikke-lineære operationer er meget mindre. Dette er virkelig praktisk til kryptografi, fordi mange former for kryptografi kan udføre lineære operationer (hvilket matrixmultiplikationer er, i det mindste hvis du krypterer modellen, men ikke input til den) næsten "gratis".
Hvis du er kryptograf, har du sikkert allerede hørt om et lignende fænomen i forbindelse med homomorf kryptering: udfører tilføjelser på krypterede chiffertekster er virkelig nemt, men multiplikationer er utrolig hårde, og vi fandt slet ikke ud af nogen måde at gøre det på med ubegrænset dybde før 2009.
For ZK-SNARKs er det tilsvarende protokoller som denne fra 2013, som viser en mindre end 4x overhead ved at bevise matrixmultiplikationer. Desværre ender overheaden på de ikke-lineære lag stadig med at være betydelig, og de bedste implementeringer i praksis viser overhead på omkring 200x. Men der er håb om, at dette i høj grad kan mindskes gennem yderligere forskning; se denne præsentation fra Ryan Cao for en nylig tilgang baseret på GKR, og min egen forenklet forklaring af, hvordan hovedkomponenten i GKR fungerer.
Men for mange applikationer vil vi det ikke bare bevise at et AI-output blev beregnet korrekt, vil vi også gerne skjul modellen. Der er naive tilgange til dette: du kan opdele modellen, så et andet sæt servere redundant gemmer hvert lag, og håbe på, at nogle af de servere, der lækker nogle af lagene, ikke lækker for meget data. Men der er også overraskende effektive former for specialiseret flerpartsberegning.
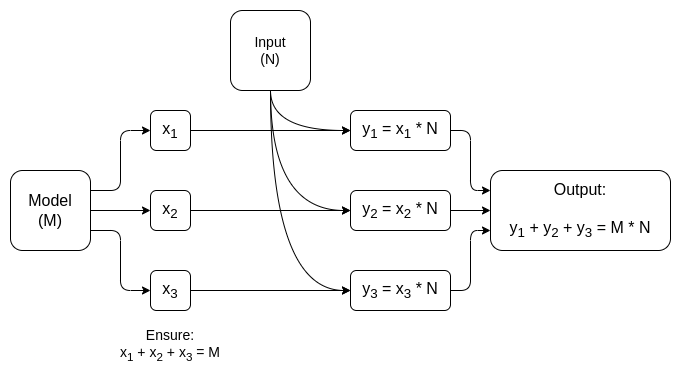
I begge tilfælde er moralen i historien den samme: den største del af en AI-beregning er matrixmultiplikationer, som det er muligt at lave meget effektiv ZK-SNARK'er eller MPC'er (eller endda FHE), og så den samlede overhead ved at placere AI i kryptografiske bokse er overraskende lav. Generelt er det de ikke-lineære lag, der er den største flaskehals på trods af deres mindre størrelse; måske nyere teknikker som opslagsargumenter kan hjælpe.
Black-box modstridende maskinlæring
Lad os nu komme til det andet store problem: den slags angreb, du kan udføre selvom modellens indhold holdes privat, og du har kun "API-adgang" til modellen. Citerer en papir fra 2016:
Mange machine learning-modeller er sårbare over for modstridende eksempler: input, der er specielt udformet til at få en machine learning-model til at producere et forkert output. Modstridende eksempler, der påvirker en model, påvirker ofte en anden model, selvom de to modeller har forskellige arkitekturer eller blev trænet på forskellige træningssæt, så længe begge modeller blev trænet til at udføre den samme opgave. En angriber kan derfor træne deres egen erstatningsmodel, udforme modstridende eksempler mod vikaren og overføre dem til en offermodel med meget få oplysninger om offeret.
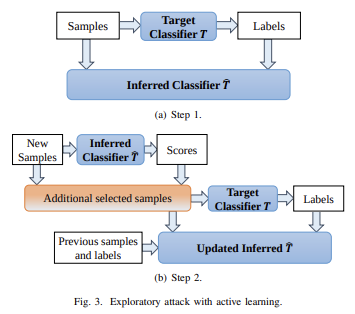
Potentielt kan du endda oprette angreb vel vidende kun træningsdataene, selvom du har meget begrænset eller ingen adgang til den model, du forsøger at angribe. Fra og med 2023 er denne slags angreb fortsat et stort problem.
For effektivt at begrænse denne slags black-box-angreb skal vi gøre to ting:
- Virkelig begrænse, hvem eller hvad der kan forespørge på modellen og hvor meget. Sorte bokse med ubegrænset API-adgang er ikke sikre; sorte bokse med meget begrænset API-adgang kan være.
- Skjul træningsdataene, mens du bevarer selvtilliden at den proces, der bruges til at oprette træningsdataene, ikke er beskadiget.
Det projekt, der har gjort mest på førstnævnte, er måske Worldcoin, hvoraf jeg analyserer en tidligere version (blandt andre protokoller) grundigt link.. Worldcoin bruger AI-modeller i vid udstrækning på protokolniveau til (i) at konvertere iris-scanninger til korte "iris-koder", der er nemme at sammenligne for lighed, og (ii) verificere, at den ting, den scanner, faktisk er et menneske. Det vigtigste forsvar, som Worldcoin er afhængig af, er det faktum, at det lader ikke nogen blot ringe ind i AI-modellen: snarere bruger den pålidelig hardware til at sikre, at modellen kun accepterer input digitalt signeret af kuglens kamera.
Denne tilgang er ikke garanteret at virke: det viser sig, at du kan lave modstridende angreb mod biometrisk AI, der kommer i form af fysiske plastre eller smykker, som du kan sætte på dit ansigt:

Men håbet er, at hvis du kombinere alle forsvarene sammen, skjuler selve AI-modellen, i høj grad begrænser antallet af forespørgsler og kræver, at hver forespørgsel på en eller anden måde skal autentificeres, kan du modstridende angreb, der er vanskelige nok til, at systemet kan være sikkert.
Og dette bringer os til anden del: hvordan kan vi skjule træningsdataene? Det er her "DAO'er til demokratisk styring af AI" kan faktisk give mening: vi kan oprette en on-chain DAO, der styrer processen for, hvem der har tilladelse til at indsende træningsdata (og hvilke attesteringer der kræves på selve dataene), hvem der har lov til at foretage forespørgsler, og hvor mange, og bruge kryptografiske teknikker som MPC at kryptere hele pipelinen med at skabe og køre AI fra hver enkelt brugers træningsinput hele vejen til det endelige output af hver forespørgsel. Denne DAO kunne samtidig opfylde det meget populære mål om at kompensere folk for at indsende data.
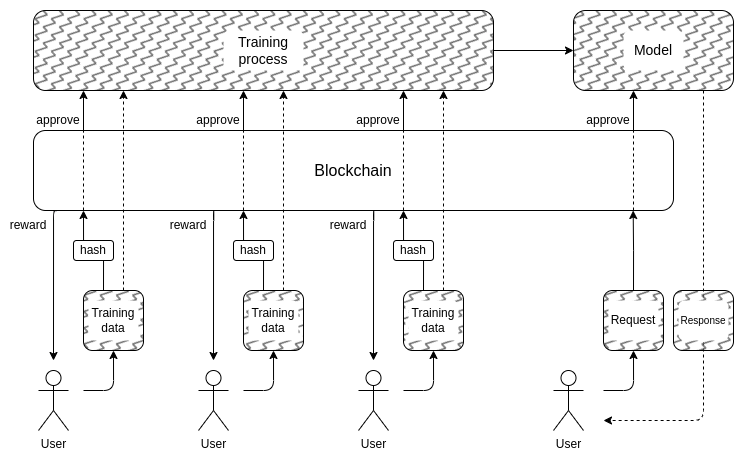
- Kryptografisk overhead kan stadig vise sig at være for højt for at denne form for fuld-black-box-arkitektur kan være konkurrencedygtig med traditionelle lukkede "trust me"-tilgange.
- Det kunne det vise sig der er ikke en god måde at gøre indsendelsesprocessen for træningsdata decentraliseret , beskyttet mod forgiftningsangreb.
- Beregningsgadgets fra flere parter kan gå i stykker deres sikkerhed eller privatlivsgarantier pga deltagere samarbejder: det er trods alt sket med krydskædede kryptovalutabroer igen , igen.
En grund til, at jeg ikke startede denne sektion med flere store røde advarselsetiketter, der siger "DON'T DO AI JUDGES, THAT'S DYSTOPIAN", er, at vores samfund i forvejen er meget afhængig af uansvarlige centraliserede AI-dommere: algoritmerne, der bestemmer, hvilke slags indlæg og politiske meninger bliver boostet og deboostet, eller endda censureret, på sociale medier. Jeg tror, at det udvider denne tendens yderligere på dette stadium er det en ret dårlig idé, men jeg tror ikke, der er en stor chance for det blockchain-samfundet, der eksperimenterer med AI, er mere vil være det, der er med til at gøre det værre.
Faktisk er der nogle ret grundlæggende lavrisiko-måder, hvorpå kryptoteknologi kan gøre selv disse eksisterende centraliserede systemer bedre, som jeg er ret sikker på. En simpel teknik er verificeret AI med forsinket offentliggørelse: Når et socialt medie-websted laver en AI-baseret rangering af indlæg, kan det offentliggøre en ZK-SNARK, der beviser hashen af modellen, der genererede den rangering. Siden kunne forpligte sig til at afsløre sine AI-modeller efter f.eks. et års forsinkelse. Når en model er afsløret, kunne brugerne tjekke hashen for at bekræfte, at den korrekte model blev frigivet, og fællesskabet kunne køre test på modellen for at bekræfte dens retfærdighed. Udgivelsesforsinkelsen ville sikre, at når modellen afsløres, er den allerede forældet.
Så sammenlignet med centraliseret verden, er spørgsmålet ikke if vi kan gøre det bedre, men med hvor meget. For decentraliseret verdenDet er dog vigtigt at være forsigtig: hvis nogen bygger f.eks. et forudsigelsesmarked eller en stablecoin, der bruger et AI-orakel, og det viser sig, at oraklet kan angribes, det er en enorm mængde penge, der kan forsvinde på et øjeblik.
AI som målet med spillet
Hvis ovenstående teknikker til at skabe en skalerbar decentraliseret privat AI, hvis indhold er en sort boks, der ikke er kendt af nogen, faktisk kan fungere, så kan dette også bruges til at skabe AI'er med nytte, der går ud over blockchains. NEAR-protokolholdet gør dette til en hovedformålet med deres igangværende arbejde.
Der er to grunde til at gøre dette:
- Hvis du kan lave "pålidelige black-box AI'er” ved at køre trænings- og inferensprocessen ved hjælp af en kombination af blockchains og MPC, så kan masser af applikationer, hvor brugere er bekymrede over, at systemet er forudindtaget eller snyder dem, drage fordel af det. Mange mennesker har udtrykt ønske om demokratisk styring af systemisk vigtige AI'er som vi vil være afhængige af; kryptografiske og blockchain-baserede teknikker kunne være en vej til at gøre det.
- Fra en AI sikkerhed perspektiv, ville dette være en teknik til at skabe en decentral AI, der også har en naturlig kill-switch, og som kan begrænse forespørgsler, der søger at bruge AI'en til ondsindet adfærd.
Det er også værd at bemærke, at "at bruge kryptoincitamenter til at incitamente til at skabe bedre AI" kan gøres uden også at gå ned i det fulde kaninhul ved at bruge kryptografi til fuldstændigt at kryptere det: tilgange som f.eks. BitTensor falder inden for denne kategori.
konklusioner
Nu hvor både blockchains og AI'er bliver mere magtfulde, er der et stigende antal use cases i skæringspunktet mellem de to områder. Nogle af disse use cases giver dog meget mere mening og er meget mere robuste end andre. Generelt brug tilfælde, hvor den bagvedliggende mekanisme fortsat er designet nogenlunde som før, men individet spillere bliver AI'er, der gør det muligt for mekanismen at fungere effektivt i en meget mere mikroskala, er de mest umiddelbart lovende og de nemmeste at få rigtigt.
Det mest udfordrende at få det rigtige er applikationer, der forsøger at bruge blockchains og kryptografiske teknikker til at skabe en "singleton": en enkelt decentraliseret betroet AI, som nogle applikationer ville stole på til et eller andet formål. Disse applikationer lover, både for funktionalitet og for at forbedre AI-sikkerheden på en måde, der undgår de centraliseringsrisici, der er forbundet med mere almindelige tilgange til dette problem. Men der er også mange måder, hvorpå de underliggende antagelser kan fejle; derfor er det værd at træde varsomt, især når disse applikationer implementeres i højværdi- og højrisikosammenhænge.
Jeg ser frem til at se flere forsøg på konstruktiv brug af kunstig intelligens på alle disse områder, så vi kan se, hvilke af dem der virkelig er levedygtige i skala.
Forfatter: Vitalik Buterin
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- BlockOffsets. Modernisering af miljømæssig offset-ejerskab. Adgang her.
- Kilde: Platon Data Intelligence.