In 2021 , 2020, fortalte vi dig om de nye funktioner i Amazon rødforskydning der gør det nemmere, hurtigere og mere omkostningseffektivt at analysere alle dine data og finde rig og kraftfuld indsigt. I 2022 er vi glade for at kunne rapportere, at Amazon Redshift-teamet var hårdt på arbejde. Vi arbejdede baglæns i forhold til kundernes krav og annoncerede flere nye funktioner for at gøre det nemmere, hurtigere og mere omkostningseffektivt at analysere alle dine data. Dette indlæg dækker nogle af disse nye funktioner.
Hos AWS, for data og analyse, er vores strategi at give dig en moderne dataarkitektur der hjælper dig med at bryde fri fra datasiloer; have specialbyggede data, analyser, maskinlæring (ML) og kunstig intelligens-tjenester for at bruge det rigtige værktøj til det rigtige job; og har åbne, styret, sikre og fuldt administrerede tjenester for at gøre analyser tilgængelige for alle. Inden for AWS' moderne dataarkitektur forbliver Amazon Redshift som cloud-datavarehuset en nøglekomponent, der gør det muligt for dig at køre komplekse SQL-analyser i skala og ydeevne på terabyte til petabyte af strukturerede og ustrukturerede data og gøre indsigten bredt tilgængelig gennem populær business intelligence ( BI) og analyseværktøjer. Vi fortsætter med at arbejde baglæns i forhold til kundernes krav og lancerede i 2022 over 40 funktioner i Amazon Redshift for at hjælpe kunder med deres bedste data warehousing use cases, herunder:
- Selvbetjeningsanalyse
- Nem dataindtagelse
- Datadeling og samarbejde
- Datavidenskab og maskinlæring
- Sikker og pålidelig analyse
- Bedste prispræstationsanalyse
Lad os dykke dybere og diskutere de nye Amazon Redshift-funktioner i disse områder.
Selvbetjeningsanalyse
Kunder fortsætter med at fortælle os, at data og analyser bliver allestedsnærværende, og alle i deres organisation har brug for analyser. Vi annoncerede Amazon Redshift Serverløs (i preview) i 2021 for at gøre det nemt at køre og skalere analyser på få sekunder uden at skulle klargøre og administrere datavarehusinfrastruktur. I juli 2022 annoncerede vi generel tilgængelighed af Redshift Serverless, og siden da har tusindvis af kunder, inklusive Peloton, Broadridge Financials og NextGen Healthcare, brugt det til hurtigt og nemt at analysere deres data. Amazon Redshift Serverless klargør og skalerer automatisk datavarehuskapaciteten for at levere høj ydeevne for alle dine analyser, og du betaler kun for den computer, der bruges i løbet af arbejdsbelastningerne, pr. sekund. Siden GA har vi tilføjet funktioner som ressourcemærkning, forenklet overvågning og tilgængelighed i yderligere AWS-regioner for yderligere at forenkle fakturering og udvide rækkevidden på tværs af flere regioner verden over.
I 2021 lancerede vi Amazon Redshift Query Editor V2, som er et gratis webbaseret værktøj til dataanalytikere, dataforskere og udviklere til at udforske, analysere og samarbejde om data i Amazon Redshift-datavarehuse og datasøer. I 2022 fik Query Editor V2 yderligere forbedringer som f.eks notebook support for forbedret samarbejde om at skrive, organisere og kommentere forespørgsler; brugeradgang igennem identitetsudbyder (IdP) legitimationsoplysninger til single sign-on; og evnen til at køre flere forespørgsler samtidigt for at forbedre udviklerproduktiviteten.
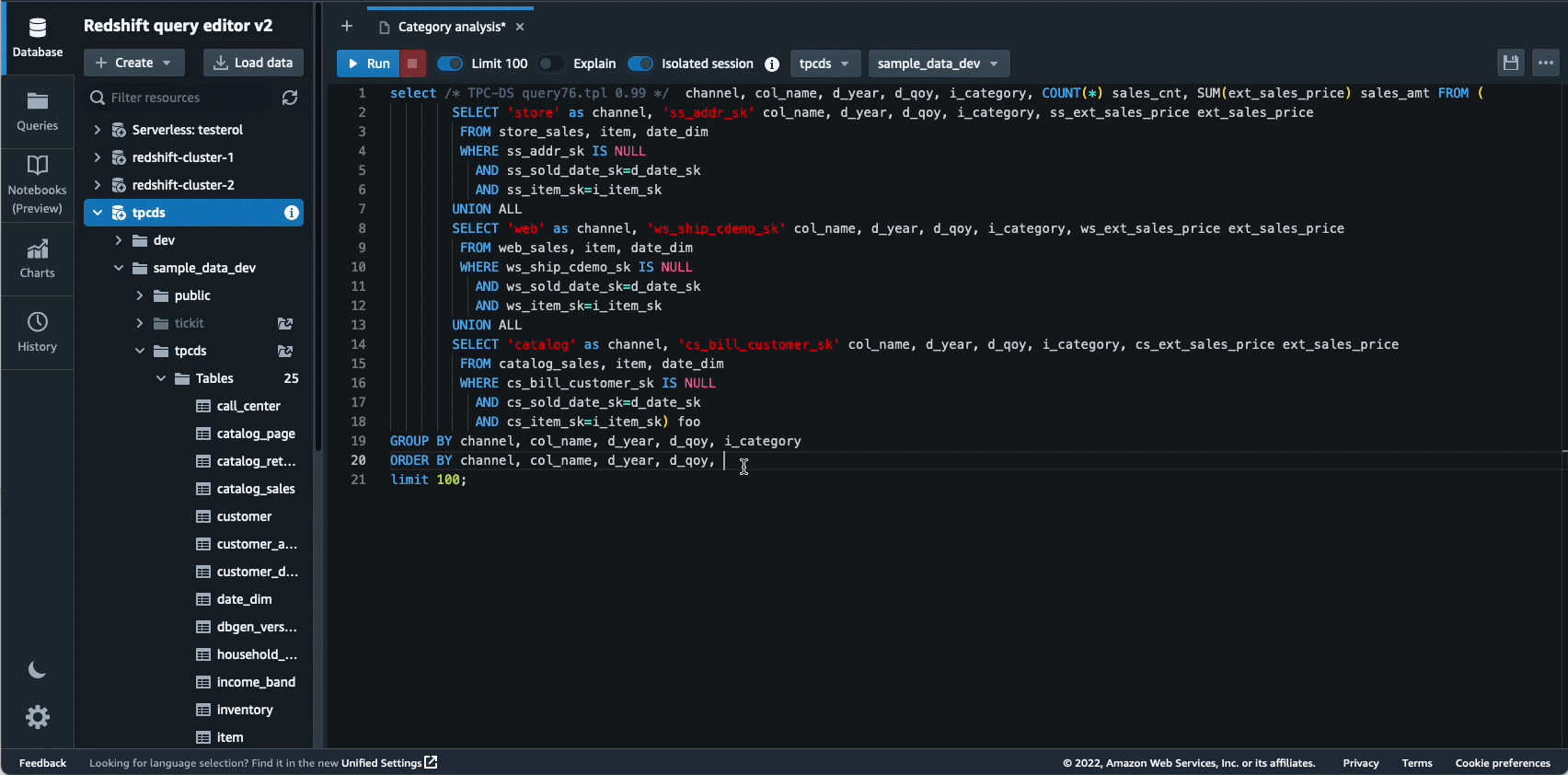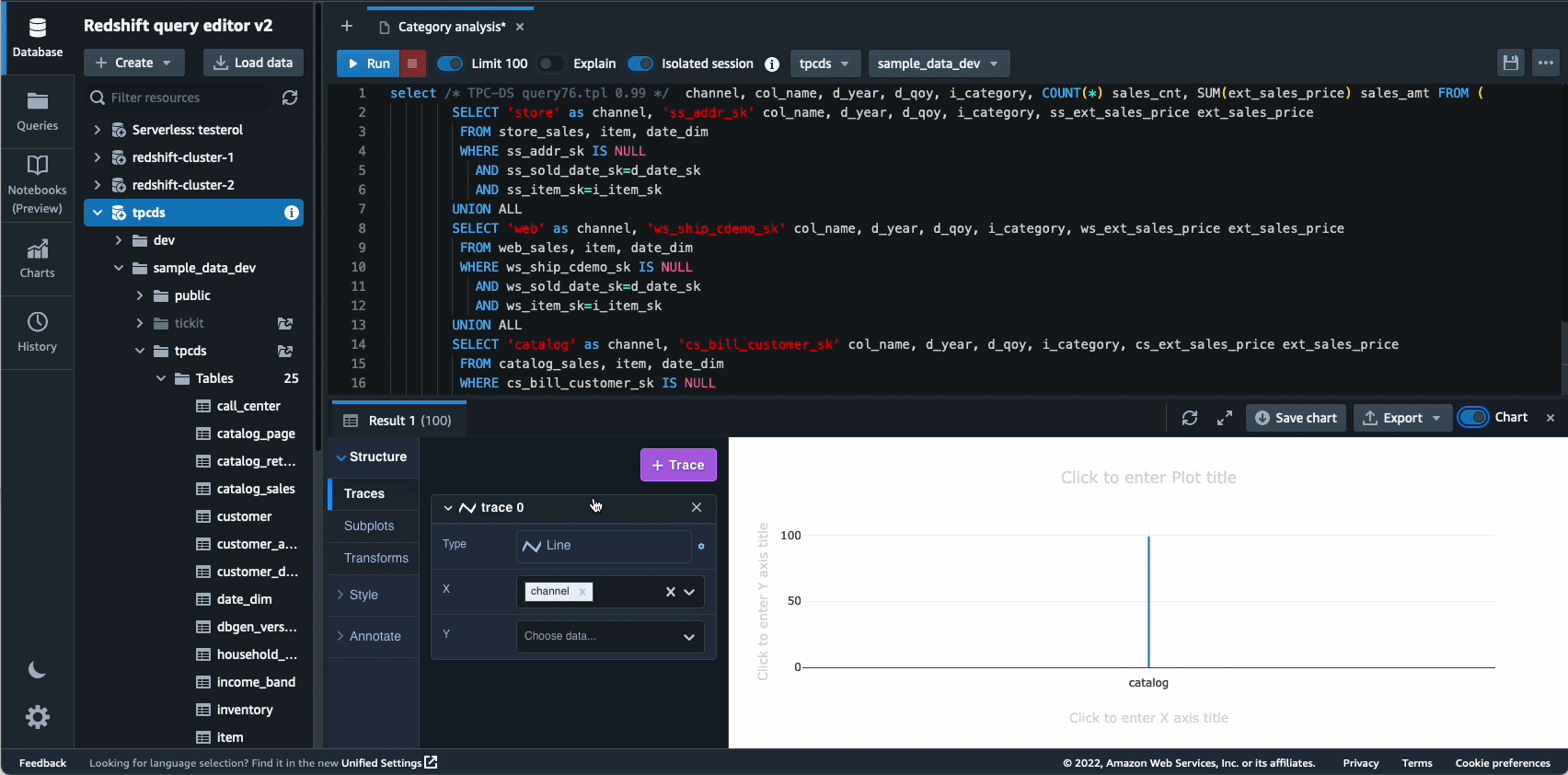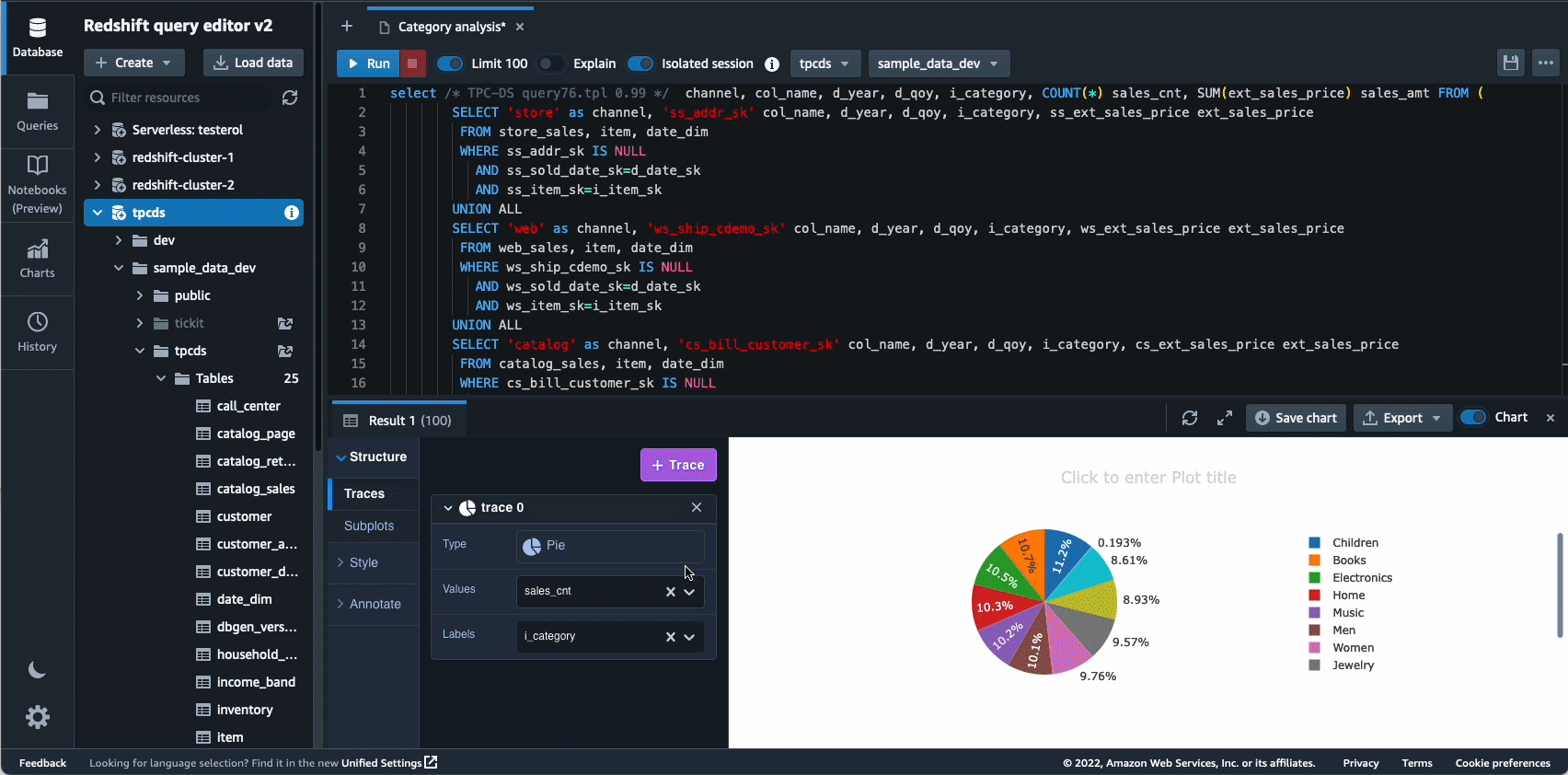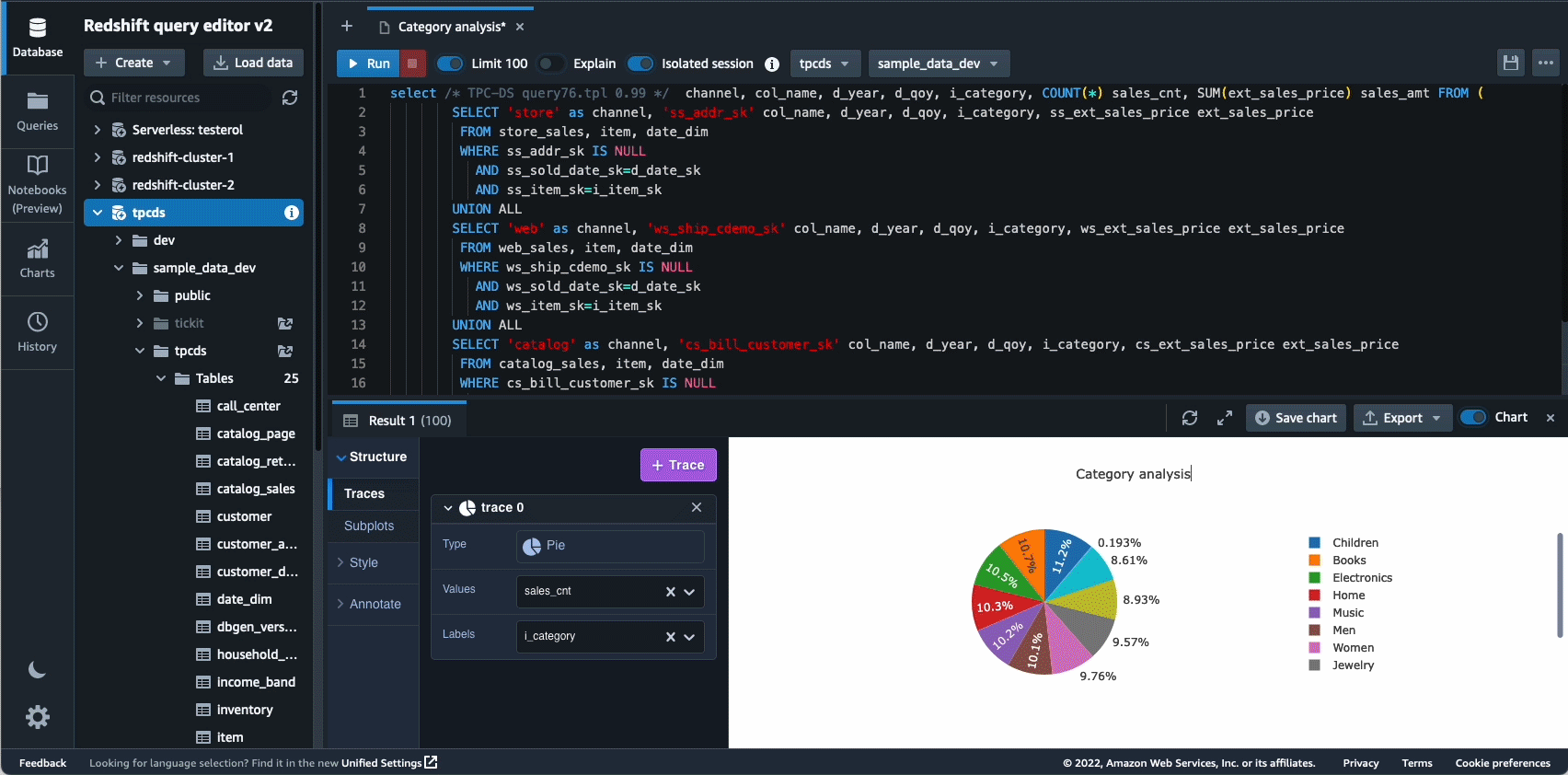
Autonomics er et andet område, hvor vi aktivt arbejder på at bruge ML-baserede optimeringer og give kunderne et selvlærende og selvoptimerende datavarehus. I 2022 annoncerede vi den generelle tilgængelighed af Automatiserede materialiserede visninger (AutoMV'er) for at forbedre ydelsen af forespørgsler (reducere den samlede kørselstid) uden brugerindsats ved automatisk at oprette og vedligeholde materialiserede visninger. AutoMV'er, kombineret med automatisk opdatering, trinvis opdatering og automatisk forespørgselsomskrivning for materialiserede visninger, gjorde materialiserede visninger vedligeholdelsesfrie, hvilket giver dig hurtigere ydeevne automatisk. Hertil kommer automatisk tabeloptimering (ATO) mulighed for skemaoptimering og automatisk arbejdsbelastningsstyring (auto WLM) kapacitet til arbejdsbelastningsoptimering fik yderligere forbedringer for bedre forespørgselsydeevne.
Nem dataindtagelse
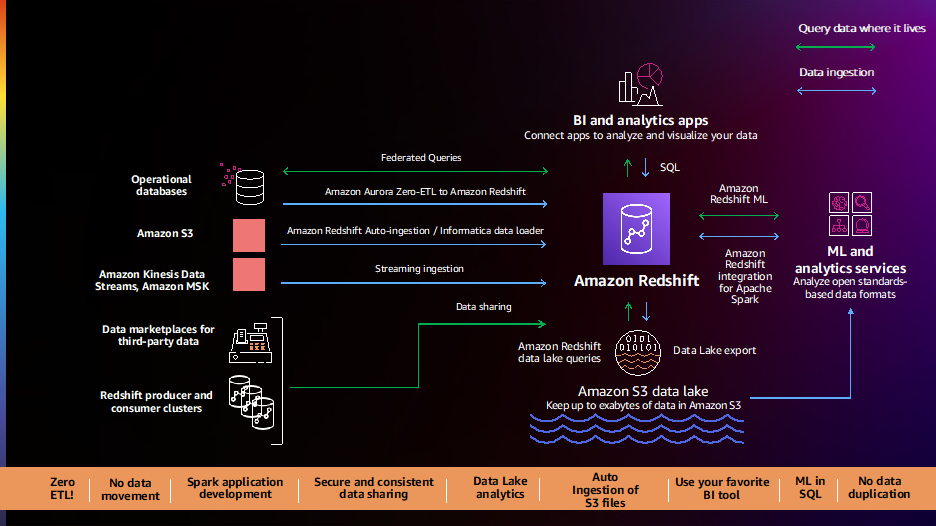
Kunder fortæller os, at de har deres data fordelt over flere datakilder som transaktionsdatabaser, datavarehuse, datasøer og big data-systemer. De ønsker fleksibiliteten til at integrere disse data med no-code/low-code, nul-ETL datapipelines eller analysere disse data på plads uden at flytte dem. Kunder fortæller os, at deres nuværende datapipelines er komplekse, manuelle, stive og langsomme, hvilket resulterer i ufuldstændige, inkonsistente og forældede visninger af data, hvilket begrænser indsigten. Kunder har bedt os om en bedre vej frem, og vi er glade for at kunne annoncere en række nye muligheder til at forenkle og automatisere datapipelines.
Amazon Aurora nul-ETL-integration med Amazon Redshift (forhåndsvisning) giver dig mulighed for at køre næsten-realtidsanalyse og ML på petabytes af transaktionsdata. Det tilbyder en kodefri løsning til at lave transaktionsdata fra flere Amazon Aurora databaser tilgængelige i Amazon Redshift-datavarehuse inden for få sekunder efter at være blevet skrevet til Aurora, hvilket eliminerer behovet for at bygge og vedligeholde komplekse datapipelines. Med denne funktion kan Aurora-kunder også få adgang til Amazon Redshift-funktioner såsom komplekse SQL-analyser, indbygget ML, datadeling og fødereret adgang til flere datalagre og datasøer. Denne funktion er nu tilgængelig i forhåndsvisning for Amazon Aurora MySQL-kompatibel udgave version 3 (med MySQL 8.0-kompatibilitet), og du kan anmode om adgang til forhåndsvisningen.
Amazon Redshift understøtter nu auto-kopi fra Amazon S3 (preview) for at forenkle dataindlæsning fra Amazon Simple Storage Service (Amazon S3) til Amazon Redshift. Du kan nu opsætte regler for kontinuerlig filindtagelse (kopijob) for at spore dine Amazon S3-stier og automatisk indlæse nye filer uden behov for yderligere værktøjer eller tilpassede løsninger. Kopijob kan overvåges gennem systemtabeller, og de holder automatisk styr på tidligere indlæste filer og udelukker dem fra indlæsningsprocessen for at forhindre dataduplikering. Denne funktion er nu tilgængelig i preview; du kan prøve denne funktion ved at oprette en ny klynge ved hjælp af forhåndsvisningssporet.
Kunder fortsætter med at fortælle os, at de har brug for øjeblikkelige analyser i realtid, og vi er glade for at kunne annoncere generel tilgængelighed af support til streaming i Amazon Redshift for Amazon Kinesis datastrømme , Amazon administrerede streaming til Apache Kafka (Amazon MSK). Denne funktion eliminerer behovet for at iscenesætte streamingdata i Amazon S3, før de indlæses i Amazon Redshift, hvilket gør det muligt for dig at opnå lav latenstid, målt i sekunder, mens du indtager hundredvis af megabyte streamingdata pr. sekund i dine datavarehuse. Du kan bruge SQL i Amazon Redshift til at oprette forbindelse til og direkte indlæse data fra flere Kinesis-datastrømme eller MSK-emner, oprette auto-forfriskende streamingmaterialiserede visninger med transformationer oven på streams direkte for at få adgang til streamingdata og kombinere realtidsdata med historiske data for bedre indsigt. For eksempel har Adobe integreret Amazon Redshift-streamingindtagelse som en del af deres Adobe Experience Platform til at indtage og analysere, i realtid, internettet og applikationernes klikstrøm og sessionsdata til forskellige applikationer som CRM og kundesupportapplikationer.
Kunder har fortalt os, at de ønsker enkel, out-of-the-box integration mellem Amazon Redshift, BI og ETL (ekstrahere, transformere og indlæse) værktøjer og forretningsapplikationer som Salesforce og Marketo. Vi er glade for at kunne meddele den generelle tilgængelighed af Informatica Data Loader til Amazon Redshift, som giver dig mulighed for gratis at bruge Informatica Data Loader til højhastigheds- og højvolumen dataindlæsning til Amazon Redshift. Du kan blot vælge indstillingen Informatica Data Loader på Amazon Redshift-konsollen. Når du først er i Informatica Data Loader, kan du oprette forbindelse til kilder som Salesforce eller Marketo, vælge Amazon Redshift som mål og begynde at indlæse dine data.
Datadeling og samarbejde
Kunder fortsætter med at fortælle os, at de ønsker at analysere alle deres førsteparts- og tredjepartsdata og gøre den omfattende datadrevne indsigt tilgængelig for deres kunder, partnere og leverandører. Vi lancerede nye funktioner i 2021, som f.eks Datadeling , AWS Data Exchange integration, for at gøre det nemmere for dig at analysere alle dine data og dele dem inden for og uden for dine organisationer.
Et godt eksempel på en kunde, der bruger datadeling, er Orion. Orion leverer real-time data as a service-løsninger (DaaS) til kunder i den finansielle serviceindustri, såsom formueforvaltning, asset management og udbydere af investeringsforvaltning. De har over 2,500 datakilder, der primært er SQL Server-databaser, der sidder både på stedet og i AWS. Data streames ved hjælp af Kafka-forbindelser til Amazon Redshift. De har en producentklynge, der modtager alle disse data og derefter bruger datadeling til at dele data i realtid til samarbejde. Dette er en multi-tenant-arkitektur, der betjener flere klienter. I betragtning af deres datas følsomhed er datadeling en måde at give arbejdsbelastningsisolering mellem klynger og også sikkert dele disse data til slutbrugere.
I 2022 fortsatte vi med at investere i dette område for at forbedre ydeevnen, styringen og udviklerproduktiviteten med nye funktioner for at gøre det nemmere, enklere og hurtigere at dele og samarbejde om data.
Da kunder bygger store datadelingskonfigurationer, har de bedt om forenklet styring og sikkerhed for delte data, og vi tilføjer centraliseret adgangskontrol med AWS Lake Formation til Amazon Redshift-datadelinger for at muliggøre deling af live-data på tværs af flere Amazon Redshift-datavarehuse. Med denne funktion understøtter Amazon Redshift nu forenklet styring af Amazon Redshift-datadelinger ved at bruge AWS søformation som en enkelt rude til centralt at administrere data eller tilladelser på datashares. Du kan se, ændre og revidere tilladelser, inklusive sikkerhed på række- og kolonneniveau på tabellerne og visningerne i Amazon Redshift-datadelingerne ved hjælp af Lake Formation API'er og AWS Management Console, og tillade Amazon Redshift-datashares at blive opdaget og forbrugt af andre Amazon Redshift-datavarehuse.
Datavidenskab og maskinlæring
Kunder fortsætter med at fortælle os, at de ønsker, at deres data- og analysesystemer hjælper dem med at besvare en lang række spørgsmål, fra hvad der sker i deres virksomhed (deskriptiv analyse) til hvorfor sker det (diagnostisk analyse), og hvad der vil ske i fremtiden (prædiktiv analyse). Amazon Redshift leverer funktioner som kompleks SQL-analyse, datasøanalyse og Amazon Redshift ML for kunder at analysere deres data og opdage kraftfuld indsigt. Rødforskydning ML integrerer Amazon Redshift med Amazon SageMaker, en fuldt administreret ML-tjeneste, der giver dig mulighed for at oprette, træne og implementere ML-modeller ved hjælp af velkendte SQL-kommandoer.
Kunder har også bedt os om bedre integration mellem Amazon Redshift og Apache Spark, så vi er glade for at kunne annoncere Amazon Redshift-integration til Apache Spark at gøre datavarehuse let tilgængelige for Spark-baserede applikationer. Nu bruger udviklere AWS-analyse og ML-tjenester som f.eks Amazon EMR, AWS Lim, og SageMaker kan ubesværet bygge Apache Spark-applikationer, der læser fra og skriver til deres Amazon Redshift-datavarehuse. Amazon EMR og AWS Glue pakker Redshift-Spark-stikket, så du nemt kan oprette forbindelse til dit datavarehus fra dine Spark-baserede applikationer. Du kan bruge flere pushdown-funktioner til operationer såsom sorterings-, aggregerings-, limit-, join- og skalarfunktioner, så kun de relevante data flyttes fra dit Amazon Redshift-datavarehus til den forbrugende Spark-applikation. Du kan også gøre dine applikationer mere sikre ved at bruge AWS identitets- og adgangsstyring (IAM) legitimationsoplysninger for at oprette forbindelse til Amazon Redshift.
Sikker og pålidelig analyse
Kunder fortsætter med at fortælle os, at deres datavarehuse er missionskritiske systemer, der har brug for høj tilgængelighed, pålidelighed og sikkerhed. Vi lancerede en række nye funktioner i 2022 på dette område.
Amazon Redshift understøtter nu Multi-AZ-implementeringer (i preview) for RA3-instansbaserede klynger, som gør det muligt at køre dit datavarehus i flere AWS-tilgængelighedszoner samtidigt og kontinuerlig drift i uforudsete Tilgængelighedszone-omfattende fejlscenarier. Multi-AZ-understøttelse er allerede tilgængelig for Redshift Serverless. En Amazon Redshift Multi-AZ-implementering giver dig mulighed for at gendanne i tilfælde af Availability Zone-fejl uden nogen brugerindblanding. Et Amazon Redshift Multi-AZ-datavarehus tilgås som et enkelt datavarehus med ét slutpunkt og hjælper dig med at maksimere ydeevnen ved automatisk at distribuere arbejdsbelastningsbehandling på tværs af flere tilgængelighedszoner. Ingen applikationsændringer er nødvendige for at opretholde forretningskontinuitet under uforudsete udfald.
I 2022 lancerede vi funktioner som rollebaseret adgangskontrol, sikkerhed på rækkeniveau og datamaskering (i forhåndsvisning) for at gøre det nemmere for dig at administrere adgang og beslutte, hvem der har adgang til hvilke data, herunder sløring af personlig identificerbar information (PII ) som kreditkortnumre.
Du kan bruge rollebaseret adgangskontrol (RBAC) at kontrollere slutbrugeres adgang til data på et bredt eller granulært niveau baseret på en slutbrugers jobrolle og tilladelser. Med RBAC kan du oprette en rolle ved hjælp af SQL, give en samling granulære tilladelser til rollen og derefter tildele denne rolle til slutbrugere. Roller kan tildeles tilladelser på objektniveau, kolonneniveau og systemniveau. Derudover introducerer RBAC out-of-box systemroller for DBA'er, operatører, sikkerhedsadministratorer eller tilpassede roller.
Sikkerhed på rækkeniveau (RLS) forenkler design og implementering af finmasket adgang til rækkerne i tabeller. Med RLS kan du begrænse adgangen til et undersæt af rækker i en tabel baseret på brugernes jobrolle eller tilladelser med SQL.
Amazon Redshift-understøttelse til dynamisk datamaskering (DDM), som nu er tilgængelig i forhåndsvisning, giver dig mulighed for at forenkle beskyttelsen af PII såsom CPR-numre, kreditkortnumre og telefonnumre i dit Amazon Redshift-datavarehus. Med dynamisk datamaskering styrer du adgangen til dine data gennem simple SQL-baserede maskeringspolitikker, der bestemmer, hvordan Amazon Redshift returnerer følsomme data til brugeren på forespørgselstidspunktet. Du kan oprette maskeringspolitikker for at definere konsistente, formatbevarende og irreversible maskerede dataværdier. Du kan anvende en maskeringspolitik på en bestemt kolonne eller liste over kolonner i en tabel. Du har også fleksibiliteten til at vælge, hvordan du vil vise de maskerede data. For eksempel kan du helt skjule dataene, erstatte delvise reelle værdier med jokertegn eller definere din egen måde at maskere dataene på ved hjælp af SQL-udtryk, Python eller AWS Lambda brugerdefinerede funktioner. Derudover kan du anvende en betinget maskeringspolitik baseret på andre kolonner, som selektivt beskytter kolonnedataene i en tabel baseret på værdierne i en eller flere forskellige kolonner.
Vi annoncerede også forbedringer til revisionslogning, indfødt integration med Microsoft Azure Active Directory, og støtte til standard IAM-roller i yderligere regioner for yderligere at forenkle sikkerhedsstyringen.
Bedste prispræstationsanalyse
Kunder fortsætter med at fortælle os, at de har brug for hurtige og omkostningseffektive datavarehuse, der leverer høj ydeevne i enhver skala, samtidig med at omkostningerne holdes lave. Fra dag 1 siden Amazon Redshifts lancering i 2012, har vi taget en datadrevet tilgang og brugt flådetelemetri til at bygge en cloud-datavarehus-tjeneste, der giver dig den bedste prisydelse i enhver skala. Gennem årene har vi udviklet os Amazon Redshifts arkitektur og lancerede funktioner som f.eks Redshift Managed Storage (RMS) til adskillelse af lager og computer, Amazon Redshift Spectrum for data sø-forespørgsler, automatisk tabeloptimering til fysisk skemaoptimering, automatisk arbejdsbelastningsstyring at prioritere arbejdsbelastninger og allokere den rigtige computer og hukommelse, klynge ændre størrelse at skalere beregning og lagring lodret, og samtidighedsskalering til dynamisk at skalere beregne ud eller ind. Vores præstationsbenchmarks fortsætte med at demonstrere Amazon Redshifts lederskab i prispræstationer.
I 2022 tilføjede vi nye funktioner såsom den generelle tilgængelighed af samtidighedsskalering til skriveoperationer som COPY, INSERT, UPDATE og DELETE for at understøtte stort set ubegrænset samtidige brugere og forespørgsler. Vi introducerede også ydeevneforbedringer for strengbaseret databehandling gennem vektoriserede scanninger over lette, CPU-effektive, ordbogskodede strengkolonner, som gør det muligt for databasemotoren at fungere direkte over komprimerede data.
Vi tilføjede også understøttelse af SQL-operatører som f.eks FUSIONERE (enkelt operatør for indsættelser eller opdateringer); CONNECY_BY (til hierarkiske forespørgsler); GRUPPERINGSSÆT, ROLLUP og TERNING (til multidimensionel rapportering); og øgede størrelsen af SUPER-datatypen til 16 MB for at gøre det nemmere for dig at migrere fra ældre datavarehuse til Amazon Redshift.
Konklusion
Vores kunder fortsætter med at fortælle os, at data og analyser forbliver en topprioritet for dem, og behovet for omkostningseffektivt at udtrække mere forretningsværdi fra deres data i disse tider er mere udtalt end nogen anden tid i fortiden. Amazon Redshift som dit cloud-datavarehus giver dig mulighed for at køre komplekse SQL-analyser med skala og ydeevne på terabyte til petabyte af strukturerede og ustrukturerede data og gøre indsigten bredt tilgængelig gennem populære BI- og analyseværktøjer.
Selvom vi lancerede over 40 funktioner i 2022, og innovationstempoet fortsætter med at accelerere, er det stadig dag 1, og vi ser frem til at høre fra dig om, hvordan disse funktioner hjælper dig med at frigøre mere værdi for dine organisationer. Vi inviterer dig til at prøve disse nye funktioner og komme i kontakt med os gennem dit AWS-kontoteam, hvis du har yderligere kommentarer.
Om forfatteren
 Manan Goel er Product Go-To-Market Leader for AWS Analytics Services, herunder Amazon Redshift hos AWS. Han har mere end 25 års erfaring og er velbevandret med databaser, data warehousing, business intelligence og analytics. Manan har en MBA fra Duke University og en BS i Electronics & Communications engineering.
Manan Goel er Product Go-To-Market Leader for AWS Analytics Services, herunder Amazon Redshift hos AWS. Han har mere end 25 års erfaring og er velbevandret med databaser, data warehousing, business intelligence og analytics. Manan har en MBA fra Duke University og en BS i Electronics & Communications engineering.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/whats-new-in-amazon-redshift-2022-a-year-in-review/
- 1
- 100
- 2021
- 2022
- a
- evne
- Om
- fremskynde
- adgang
- Adgang til data
- af udleverede
- tilgængelig
- Konto
- opnå
- tværs
- aktiv
- aktivt
- tilføjet
- Desuden
- Yderligere
- Derudover
- Adobe
- Alle
- tillader
- allerede
- Amazon
- Amazon EMR
- Analytikere
- analytics
- analysere
- analysere
- ,
- Annoncere
- annoncerede
- En anden
- besvare
- Apache
- Apache Spark
- API'er
- Anvendelse
- applikationer
- Indløs
- tilgang
- arkitektur
- OMRÅDE
- områder
- kunstig
- kunstig intelligens
- aktiv
- formueforvaltning
- revision
- Aurora
- forfatter
- auto
- automatisere
- Automatisk Ur
- automatisk
- tilgængelighed
- til rådighed
- AWS
- AWS Lim
- Azure
- baseret
- grundlag
- blive
- før
- være
- BEDSTE
- Bedre
- mellem
- Big
- Big data
- fakturerings- og
- Pause
- bred
- Broadridge
- bygge
- Bygning
- indbygget
- virksomhed
- Business Applications
- business kontinuitet
- business intelligence
- kapaciteter
- Kapacitet
- kort
- tilfælde
- tilfælde
- Ændringer
- tegn
- Vælg
- vælge
- kunder
- Cloud
- Cluster
- samarbejde
- samarbejde
- samling
- Kolonne
- Kolonner
- kombinerer
- kombineret
- kommentarer
- Kommunikation
- kompatibilitet
- fuldstændig
- komplekse
- komponent
- Compute
- konkurrent
- Tilslut
- konsekvent
- Konsol
- forbruges
- fortsæt
- fortsatte
- fortsætter
- kontinuerlig
- kontrol
- omkostningseffektiv
- Omkostninger
- dækker
- skabe
- Oprettelse af
- Legitimationsoplysninger
- kredit
- kreditkort
- Medvirkende
- CRM
- Nuværende
- skik
- kunde
- Kunde support
- Kunder
- tilpassede
- data
- Dataudveksling
- Data Lake
- databehandling
- datadeling
- datalager
- datavarehuse
- datastyret
- Database
- databaser
- dag
- dybere
- levere
- demonstrere
- indsætte
- implementering
- Design
- Bestem
- Udvikler
- udviklere
- forskellige
- direkte
- opdage
- opdaget
- diskutere
- distribueret
- distribution
- Duke
- hertug universitet
- i løbet af
- dynamisk
- lettere
- nemt
- editor
- indsats
- Elektronik
- eliminerer
- eliminere
- muliggøre
- muliggør
- muliggør
- Endpoint
- Engine (Motor)
- Engineering
- Ether (ETH)
- alle
- udviklet sig
- eksempel
- udveksling
- ophidset
- Udvid
- erfaring
- udforske
- udtryk
- ekstrakt
- Manglende
- bekendt
- FAST
- hurtigere
- Feature
- Funktionalitet
- File (Felt)
- Filer
- finansielle
- finansielle tjenesteydelser
- finansielle poster
- Finde
- FLÅDE
- Fleksibilitet
- formation
- Videresend
- Gratis
- fra
- fuldt ud
- funktioner
- yderligere
- fremtiden
- Generelt
- få
- gif
- Giv
- given
- giver
- Give
- glas
- Gå-på-marked
- regeringsførelse
- indrømme
- bevilget
- stor
- ske
- Gem
- Hård Ost
- have
- sundhedspleje
- høre
- hjælpe
- hjælper
- Skjule
- Høj
- historisk
- besidder
- Hvordan
- How To
- HTML
- HTTPS
- Hundreder
- IAM
- Identity
- implementering
- Forbedre
- forbedret
- forbedringer
- in
- Herunder
- øget
- industrien
- oplysninger
- Infrastruktur
- Innovation
- Indsætter
- indsigt
- integrere
- integreret
- Integrerer
- integration
- Intelligens
- indgriben
- introduceret
- Introducerer
- Invest
- investering
- invitere
- isolation
- IT
- Job
- Karriere
- deltage
- juli
- Kafka
- Holde
- holde
- Nøgle
- Kinesis datastrømme
- sø
- storstilet
- Latency
- lancere
- lanceret
- leder
- Leadership" (virkelig menneskelig ledelse)
- læring
- Legacy
- Niveau
- letvægt
- GRÆNSE
- Liste
- leve
- live data
- belastning
- loader
- lastning
- Se
- Lav
- maskine
- machine learning
- lavet
- vedligeholde
- vedligeholdelse
- lave
- Making
- administrere
- lykkedes
- ledelse
- manuel
- Marketo
- maske
- Maksimer
- Hukommelse
- migrere
- ML
- modeller
- Moderne
- ændre
- overvåges
- overvågning
- mere
- flytning
- flere
- MySQL
- indfødte
- Behov
- behov
- behov
- Ny
- Nye funktioner
- nummer
- numre
- Tilbud
- ONE
- åbent
- betjene
- drift
- Produktion
- operatør
- Operatører
- optimering
- Option
- organisation
- organisationer
- Andet
- udfald
- uden for
- egen
- Tempo
- pakke
- brød
- del
- partnere
- forbi
- Betal
- feltet
- ydeevne
- Tilladelser
- Personligt
- telefon
- fysisk
- PIO
- Place
- perron
- plato
- Platon Data Intelligence
- PlatoData
- tilfreds
- politikker
- politik
- Populær
- Indlæg
- vigtigste
- Prediktiv Analytics
- forhindre
- Eksempel
- tidligere
- pris
- primært
- Prioriter
- prioritet
- behandle
- forarbejdning
- producent
- Produkt
- produktivitet
- beskyttelse
- give
- udbyder
- udbydere
- giver
- bestemmelse
- Python
- Spørgsmål
- hurtigt
- rækkevidde
- nå
- Læs
- ægte
- realtid
- data i realtid
- modtager
- Recover
- reducere
- regioner
- relevant
- pålidelighed
- pålidelig
- resterne
- erstatte
- indberette
- Rapportering
- Krav
- begrænse
- resulterer
- afkast
- gennemgå
- omskrivning
- Rich
- stiv
- roller
- roller
- Rul op
- regler
- Kør
- kører
- sagemaker
- salgsstyrke
- Scale
- skalaer
- skalering
- scenarier
- Videnskab
- forskere
- Anden
- sekunder
- sikker
- sikkert
- sikkerhed
- følsom
- Følsomhed
- Serverless
- tjener
- tjeneste
- Tjenester
- Session
- sæt
- sæt
- flere
- Del
- delt
- deling
- Vis
- Simpelt
- forenklet
- forenkle
- ganske enkelt
- samtidigt
- siden
- enkelt
- Siddende
- Størrelse
- langsom
- So
- Social
- løsninger
- Løsninger
- nogle
- Kilder
- Spark
- specifikke
- SQL
- Stage
- opbevaring
- forhandler
- Strategi
- streamet
- streaming
- vandløb
- struktureret
- strukturerede og ustrukturerede data
- sådan
- Super
- leverandører
- support
- Understøtter
- systemet
- Systemer
- bord
- mål
- hold
- Fremtiden
- deres
- tredjepart
- tusinder
- Gennem
- tid
- gange
- til
- værktøj
- værktøjer
- top
- Emner
- I alt
- spor
- Tog
- transaktionsbeslutning
- Transform
- transformationer
- allestedsnærværende
- uforudset
- universitet
- ubegrænset
- låse
- Opdatering
- opdateringer
- us
- brug
- Bruger
- brugere
- Ved hjælp af
- værdi
- Værdier
- forskellige
- udgave
- Specifikation
- visninger
- næsten
- Warehouse
- Warehousing
- Rigdom
- formueforvaltning
- web
- web-baseret
- Hvad
- Hvad er
- som
- mens
- WHO
- bred
- Bred rækkevidde
- bredt
- vilje
- inden for
- uden
- Arbejde
- arbejdede
- arbejder
- verdensplan
- skriver
- skriftlig
- år
- år
- Din
- zephyrnet
- zoner