Geospatiale data er data om bestemte steder på jordens overflade. Det kan repræsentere et geografisk område som helhed, eller det kan repræsentere en begivenhed forbundet med et geografisk område. Analyse af geospatiale data er eftertragtet i nogle få brancher. Det involverer at forstå, hvor data findes fra et rumligt perspektiv, og hvorfor det eksisterer der.
Der er to typer geospatiale data: vektordata og rasterdata. Rasterdata er en matrix af celler repræsenteret som et gitter, der for det meste repræsenterer fotografier og satellitbilleder. I dette indlæg fokuserer vi på vektordata, som er repræsenteret som geografiske koordinater for bredde- og længdegrad samt linjer og polygoner (områder), der forbinder eller omslutter dem. Vektordata har et væld af use cases til at udlede mobilitetsindsigt. Brugermobildata er en sådan komponent af det, og det er for det meste afledt af den geografiske position af mobile enheder, der bruger GPS eller app-udgivere, der bruger SDK'er eller lignende integrationer. I forbindelse med dette indlæg henviser vi til disse data som mobilitetsdata.
Dette er en serie i to dele. I dette første indlæg introducerer vi mobilitetsdata, dets kilder og et typisk skema over disse data. Vi diskuterer derefter de forskellige use cases og undersøger, hvordan du kan bruge AWS-tjenester til at rense dataene, hvordan maskinlæring (ML) kan hjælpe med denne indsats, og hvordan du kan gøre etisk brug af dataene til at generere visuals og indsigt. Det andet indlæg vil være af mere teknisk karakter og dække disse trin i detaljer sammen med prøvekoden. Dette indlæg har ikke et eksempeldatasæt eller en prøvekode, det dækker snarere, hvordan man bruger dataene, efter at de er købt fra en dataaggregator.
Du kan bruge Amazon SageMaker geospatiale muligheder at overlejre mobilitetsdata på et basiskort og give lagvis visualisering for at gøre samarbejde lettere. Den GPU-drevne interaktive visualizer og Python-notebooks giver en problemfri måde at udforske millioner af datapunkter i et enkelt vindue og dele indsigt og resultater.
Kilder og skema
Der er få kilder til mobilitetsdata. Bortset fra GPS-pings og app-udgivere bruges andre kilder til at udvide datasættet, såsom Wi-Fi-adgangspunkter, budstreamdata opnået via visning af annoncer på mobilenheder og specifikke hardwaresendere placeret af virksomheder (f.eks. i fysiske butikker ). Det er ofte svært for virksomheder selv at indsamle disse data, så de kan købe dem fra dataaggregatorer. Dataaggregatorer indsamler mobilitetsdata fra forskellige kilder, renser dem, tilføjer støj og gør dataene tilgængelige på daglig basis for specifikke geografiske regioner. På grund af selve dataenes natur og fordi de er svære at få fat i, kan nøjagtigheden og kvaliteten af disse data variere betydeligt, og det er op til virksomhederne at vurdere og verificere dette ved at bruge målinger såsom daglige aktive brugere, samlede daglige pings, og gennemsnitlige daglige ping pr. enhed. Følgende tabel viser, hvordan et typisk skema for et dagligt datafeed sendt af dataaggregatorer kan se ud.
| Attribut | Beskrivelse |
| ID eller MAID | Mobile Advertising ID (MAID) for enheden (hashed) |
| lat | Enhedens breddegrad |
| lng | Enhedens længdegrad |
| geohash | Geohash placering af enheden |
| enhedstype | Enhedens operativsystem = IDFA eller GAID |
| horisontal_nøjagtighed | Nøjagtighed af vandrette GPS-koordinater (i meter) |
| tidsstempel | Begivenhedens tidsstempel |
| ip | IP-adresse |
| alt | Enhedens højde (i meter) |
| hastighed | Enhedens hastighed (i meter/sekund) |
| land | ISO tocifret kode for oprindelseslandet |
| tilstand | Koder, der repræsenterer stat |
| by | Koder, der repræsenterer by |
| postnummer | Postnummer for, hvor enheds-id'et ses |
| luftfartsselskab | Enhedens bærer |
| device_manufacturer | Producent af enheden |
Brug sager
Mobilitetsdata har udbredte anvendelser i forskellige brancher. Følgende er nogle af de mest almindelige brugstilfælde:
- Tæthedsmålinger – Fodtrafikanalyse kan kombineres med befolkningstæthed for at observere aktiviteter og besøg på interessepunkter (POI'er). Disse målinger præsenterer et billede af, hvor mange enheder eller brugere, der aktivt stopper og engagerer sig i en virksomhed, som yderligere kan bruges til valg af websted eller endda analysere bevægelsesmønstre omkring en begivenhed (f.eks. folk, der rejser til en spilledag). For at opnå sådan indsigt gennemgår de indgående rådata en udtræks-, transformations- og indlæsningsproces (ETL) for at identificere aktiviteter eller engagementer fra den kontinuerlige strøm af enhedsplaceringspings. Vi kan analysere aktiviteter ved at identificere stop foretaget af brugeren eller mobilenheden ved at gruppere ping ved hjælp af ML-modeller i Amazon SageMaker.
- Ture og baner – En enheds daglige placeringsfeed kan udtrykkes som en samling af aktiviteter (stop) og ture (bevægelse). Et par aktiviteter kan repræsentere en tur mellem dem, og sporing af turen med den bevægelige enhed i geografisk rum kan føre til kortlægning af den faktiske bane. Banemønstre for brugerbevægelser kan føre til interessant indsigt såsom trafikmønstre, brændstofforbrug, byplanlægning og mere. Det kan også levere data til at analysere ruten taget fra reklamesteder, såsom et reklametavle, identificere de mest effektive leveringsruter for at optimere forsyningskædedriften eller analysere evakueringsruter i naturkatastrofer (f.eks. orkanevakuering).
- Oplandsanalyse - A afvandingsområde henviser til steder, hvorfra et givet område trækker sine besøgende, som kan være kunder eller potentielle kunder. Detailvirksomheder kan bruge disse oplysninger til at bestemme det optimale sted at åbne en ny butik, eller afgøre, om to butikssteder er for tæt på hinanden med overlappende opland og hæmmer hinandens forretning. De kan også finde ud af, hvor de faktiske kunder kommer fra, identificere potentielle kunder, der kommer forbi området på vej til arbejde eller hjem, analysere lignende besøgsmål for konkurrenter og mere. Marketing Tech (MarTech) og Advertisement Tech (AdTech) virksomheder kan også bruge denne analyse til at optimere marketingkampagner ved at identificere målgruppen tæt på et brands butik eller til at rangere butikker efter ydeevne for out-of-home annoncering.
Der er adskillige andre brugssager, herunder generering af placeringsintelligens til kommerciel ejendom, udvidelse af satellitbilleddata med tilløbstal, identificering af leveringsknudepunkter for restauranter, bestemmelse af sandsynligheden for evakuering af nabolag, opdagelse af folks bevægelsesmønstre under en pandemi og mere.
Udfordringer og etisk brug
Etisk brug af mobilitetsdata kan føre til mange interessante indsigter, der kan hjælpe organisationer med at forbedre deres drift, udføre effektiv markedsføring eller endda opnå en konkurrencefordel. For at bruge disse data etisk, skal flere trin følges.
Det starter med selve indsamlingen af data. Selvom de fleste mobilitetsdata forbliver fri for personligt identificerbare oplysninger (PII) såsom navn og adresse, skal dataindsamlere og aggregatorer have brugerens samtykke til at indsamle, bruge, gemme og dele deres data. Databeskyttelseslove såsom GDPR og CCPA skal overholdes, fordi de giver brugerne mulighed for at bestemme, hvordan virksomheder kan bruge deres data. Dette første skridt er et væsentligt skridt hen imod etisk og ansvarlig brug af mobilitetsdata, men mere kan gøres.
Hver enhed tildeles et hashed mobilannoncerings-id (MAID), som bruges til at forankre de enkelte pings. Dette kan sløres yderligere ved at bruge Amazon Macie, Amazon S3 Object Lambda, Amazon Comprehend, eller endda AWS Glue Studio Registrer PII-transformation. For mere information, se Almindelige teknikker til at detektere PHI- og PII-data ved hjælp af AWS Services.
Ud over PII bør der tages hensyn til at maskere brugerens hjemsted såvel som andre følsomme steder som militærbaser eller tilbedelsessteder.
Det sidste trin til etisk brug er kun at udlede og eksportere aggregerede metrics fra Amazon SageMaker. Dette betyder at få målinger såsom gennemsnitligt antal eller samlede antal besøgende i modsætning til individuelle rejsemønstre; få daglige, ugentlige, månedlige eller årlige tendenser; eller indeksering af mobilitetsmønstre over offentligt tilgængelige data såsom folketællingsdata.
Løsningsoversigt
Som tidligere nævnt er AWS-tjenesterne, som du kan bruge til analyse af mobilitetsdata, Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend og Amazon SageMaker geospatiale muligheder. Amazon SageMakers geospatiale muligheder gør det nemt for dataforskere og ML-ingeniører at bygge, træne og implementere modeller ved hjælp af geospatiale data. Du kan effektivt transformere eller berige store geospatiale datasæt, accelerere modelopbygning med forudtrænede ML-modeller og udforske modelforudsigelser og geospatiale data på et interaktivt kort ved hjælp af 3D-accelereret grafik og indbyggede visualiseringsværktøjer.
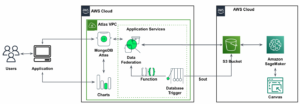
Følgende referencearkitektur viser en arbejdsgang, der bruger ML med geospatiale data.
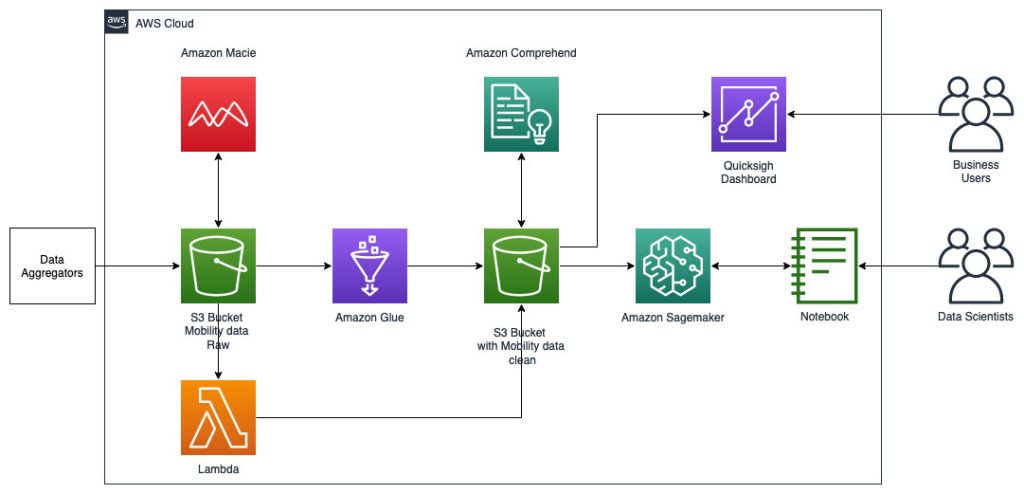
I denne arbejdsgang samles rådata fra forskellige datakilder og lagres i en Amazon Simple Storage Service (S3) spand. Amazon Macie bruges på denne S3-bøtte til at identificere og redigere og PII. AWS Glue bruges derefter til at rense og transformere rådataene til det krævede format, hvorefter de ændrede og rensede data gemmes i en separat S3-spand. Til de datatransformationer, der ikke er mulige via AWS Glue, bruger du AWS Lambda at ændre og rense rådataene. Når dataene er renset, kan du bruge Amazon SageMaker til at bygge, træne og implementere ML-modeller på de forberedte geospatiale data. Du kan også bruge geospatiale behandlingsjob egenskab af Amazon SageMakers geospatiale muligheder til at forbehandle dataene - for eksempel ved at bruge en Python-funktion og SQL-sætninger til at identificere aktiviteter fra de rå mobilitetsdata. Dataforskere kan udføre denne proces ved at oprette forbindelse gennem Amazon SageMaker-notebooks. Du kan også bruge Amazon QuickSight at visualisere forretningsresultater og andre vigtige målinger fra dataene.
Amazon SageMaker geospatiale muligheder og geospatiale behandlingsjob
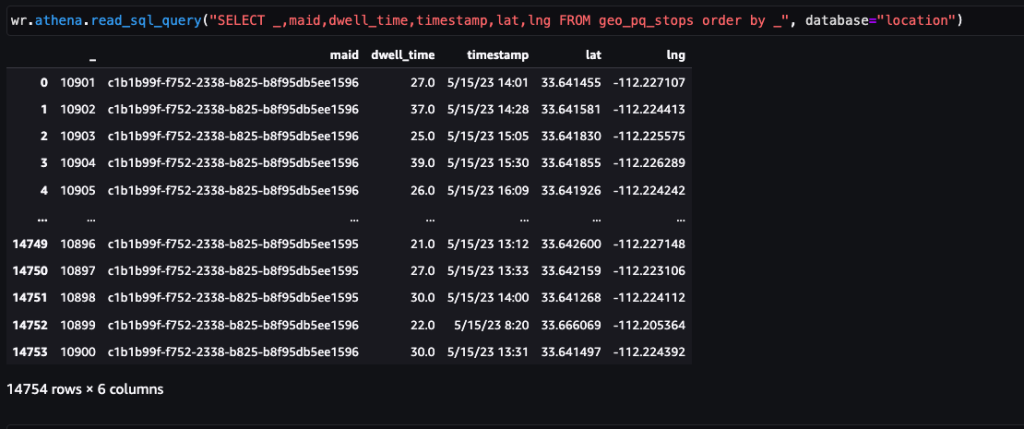
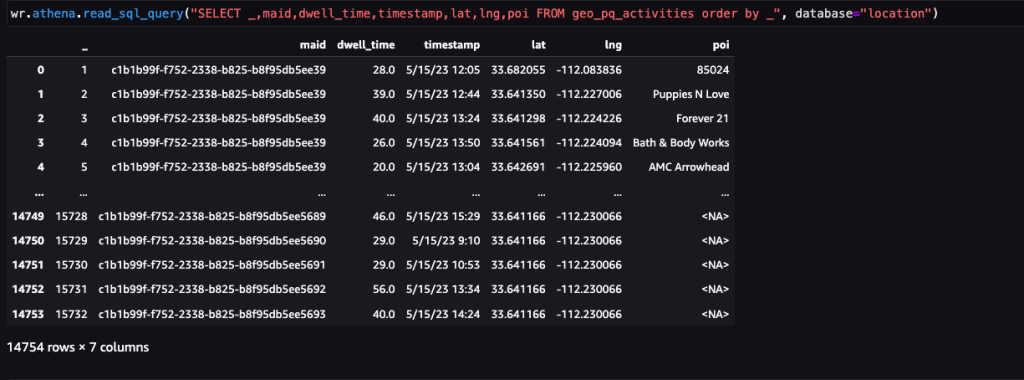
Efter at dataene er opnået og indført i Amazon S3 med et dagligt feed og renset for følsomme data, kan de importeres til Amazon SageMaker ved hjælp af en Amazon SageMaker Studio notesbog med et geospatialt billede. Følgende skærmbillede viser et eksempel på daglige enhedspings, der er uploadet til Amazon S3 som en CSV-fil og derefter indlæst i en panda-dataramme. Amazon SageMaker Studio-notebooken med geospatialt billede leveres forudindlæst med geospatiale biblioteker såsom GDAL, GeoPandas, Fiona og Shapely og gør det nemt at behandle og analysere disse data.
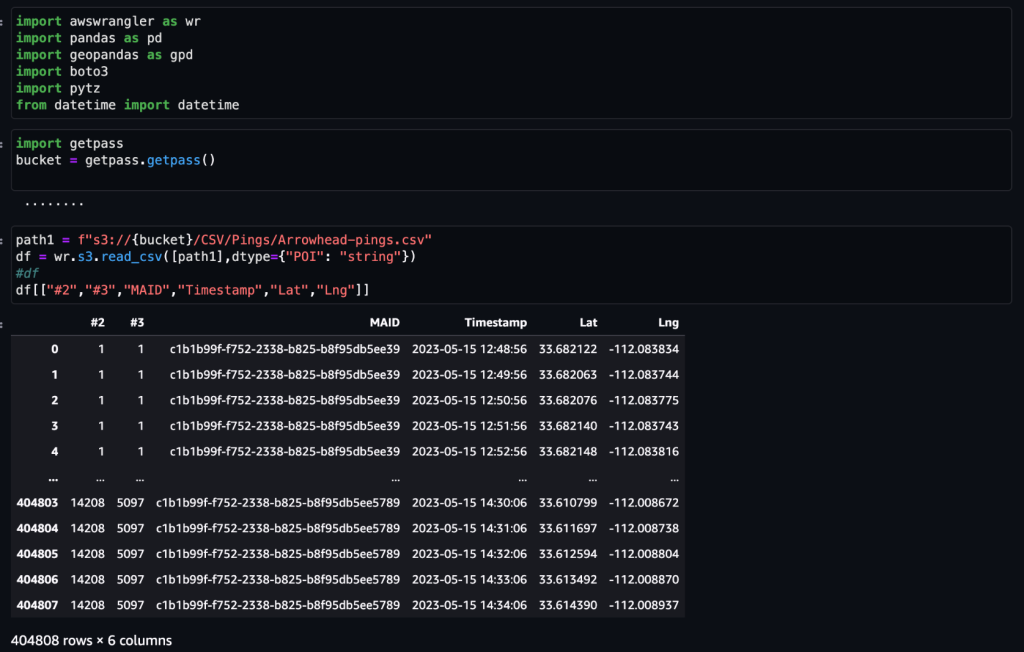
Dette eksempeldatasæt indeholder cirka 400,000 daglige enhedspings fra 5,000 enheder fra 14,000 unikke steder optaget fra brugere, der besøgte Arrowhead Mall, et populært indkøbscenterkompleks i Phoenix, Arizona, den 15. maj 2023. Det foregående skærmbillede viser en undergruppe af kolonner i data skema. Det MAID kolonne repræsenterer enheds-id'et, og hver MAID genererer ping hvert minut, der videresender enhedens bredde- og længdegrad, registreret i eksempelfilen som Lat , Lng kolonner.
Følgende er skærmbilleder fra værktøjet til kortvisualisering af Amazon SageMakers geospatiale kapaciteter drevet af Foursquare Studio, der viser layoutet af ping fra enheder, der besøger indkøbscentret mellem 7:00 AM og 6:00 PM.
Følgende skærmbillede viser ping fra indkøbscenteret og de omkringliggende områder.

Det følgende viser ping fra forskellige butikker i indkøbscentret.
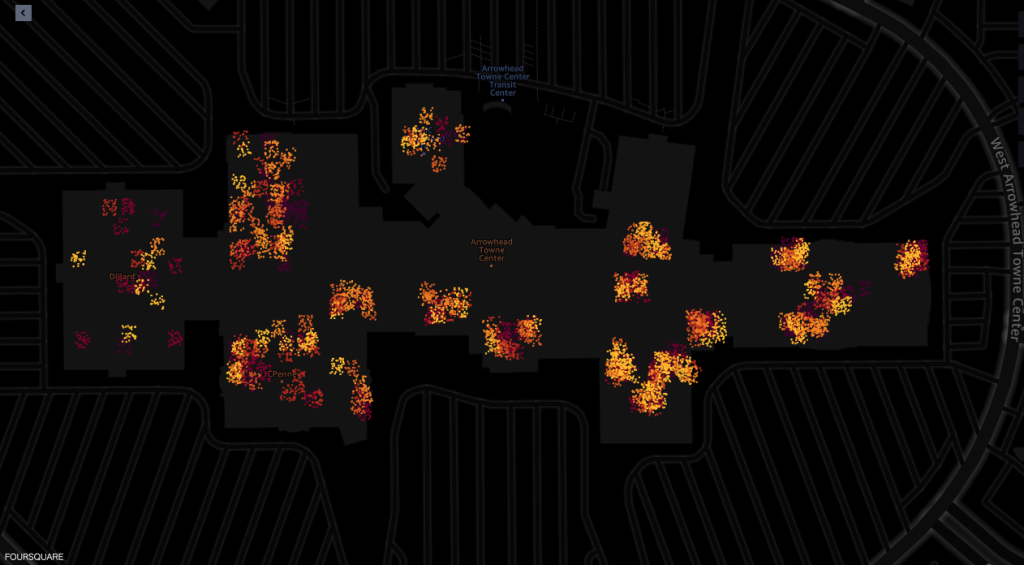
Hver prik i skærmbillederne viser et ping fra en given enhed på et givet tidspunkt. En klynge af ping repræsenterer populære steder, hvor enheder er samlet eller stoppet, såsom butikker eller restauranter.
Som en del af den indledende ETL kan disse rådata indlæses på tabeller ved hjælp af AWS Glue. Du kan oprette en AWS Glue-crawler for at identificere data- og formulartabellernes skema ved at pege på den rå dataplacering i Amazon S3 som datakilden.

Som nævnt ovenfor vil de rå data (de daglige enhedspings), selv efter indledende ETL, repræsentere en kontinuerlig strøm af GPS-pings, der angiver enhedsplaceringer. For at udtrække handlingsorienteret indsigt fra disse data er vi nødt til at identificere stop og ture (baner). Dette kan opnås ved hjælp af geospatiale behandlingsjob funktion af SageMaker geospatiale muligheder. Amazon SageMaker-behandling bruger en forenklet, administreret oplevelse på SageMaker til at køre databehandlingsarbejdsbelastninger med den specialbyggede geospatiale container. Den underliggende infrastruktur for et SageMaker Processing-job administreres fuldt ud af SageMaker. Denne funktion gør det muligt for brugerdefineret kode at køre på geospatiale data gemt på Amazon S3 ved at køre en geospatial ML-container på et SageMaker Processing-job. Du kan køre brugerdefinerede operationer på åbne eller private geospatiale data ved at skrive tilpasset kode med open source-biblioteker og køre operationen i skala ved hjælp af SageMaker Processing-job. Den containerbaserede tilgang løser behov omkring standardisering af udviklingsmiljø med almindeligt anvendte open source-biblioteker.
For at køre sådanne store arbejdsbelastninger har du brug for en fleksibel computerklynge, der kan skaleres fra titusvis af forekomster til at behandle en byblok til tusindvis af forekomster til behandling i planetarisk skala. Manuel styring af en gør-det-selv computerklynge er langsom og dyr. Denne funktion er især nyttig, når mobilitetsdatasættet involverer mere end et par byer til flere stater eller endda lande og kan bruges til at køre en to-trins ML-tilgang.
Det første trin er at bruge tæthedsbaseret rumlig clustering af applikationer med støj (DBSCAN) algoritme til at klynge stop fra ping. Det næste trin er at bruge støttevektormaskiner (SVM'er) metoden til yderligere at forbedre nøjagtigheden af de identificerede stop og også at skelne mellem stop med engagementer med et POI og stop uden et (såsom hjemme eller arbejde). Du kan også bruge SageMaker Processing-job til at generere ture og baner fra de daglige enhedspings ved at identificere på hinanden følgende stop og kortlægge stien mellem kilde- og destinationsstop.
Efter at have behandlet rådataene (daglige enhedspings) i skala med geospatiale behandlingsjob, skulle det nye datasæt kaldet stop have følgende skema.
| Attribut | Beskrivelse |
| ID eller MAID | Mobilannoncerings-id for enheden (hashed) |
| lat | Breddegrad for tyngdepunktet for stopklyngen |
| lng | Længdegrad af tyngdepunktet for stopklyngen |
| geohash | Geohash placering af POI |
| enhedstype | Enhedens operativsystem (IDFA eller GAID) |
| tidsstempel | Starttidspunkt for stop |
| Dvæletid | Dvæletid for stop (i sekunder) |
| ip | IP-adresse |
| alt | Enhedens højde (i meter) |
| land | ISO tocifret kode for oprindelseslandet |
| tilstand | Koder, der repræsenterer stat |
| by | Koder, der repræsenterer by |
| postnummer | Postnummer for, hvor enheds-id ses |
| luftfartsselskab | Enhedens bærer |
| device_manufacturer | Producent af enheden |
Stop konsolideres ved at gruppere pingene pr. enhed. Tæthedsbaseret clustering kombineres med parametre som at stoptærsklen er 300 sekunder og minimumsafstanden mellem stop er 50 meter. Disse parametre kan justeres i henhold til din brugssituation.
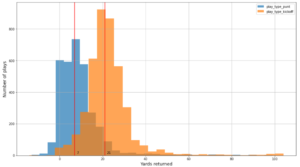
Følgende skærmbillede viser cirka 15,000 stop identificeret ud fra 400,000 ping. En delmængde af det foregående skema er også til stede, hvor kolonnen Dwell Time repræsenterer stopvarigheden, og Lat , Lng kolonner repræsenterer bredde- og længdegraden af tyngdepunkterne i stopklyngen pr. enhed pr. lokation.
Post-ETL lagres data i Parquet filformat, som er et søjleformet lagringsformat, der gør det nemmere at behandle store mængder data.
Følgende skærmbillede viser stoppestederne konsolideret fra pings pr. enhed inde i indkøbscentret og de omkringliggende områder.

Efter at have identificeret stop, kan dette datasæt sættes sammen med offentligt tilgængelige POI-data eller brugerdefinerede POI-data, der er specifikke for brugssagen, for at identificere aktiviteter, såsom engagement med brands.
Følgende skærmbillede viser stoppestederne ved større POI'er (butikker og mærker) inde i Arrowhead Mall.
Hjemmepostnumre er blevet brugt til at maskere hver besøgendes hjemsted for at bevare privatlivets fred, hvis det er en del af deres rejse i datasættet. Bredde- og længdegraden i sådanne tilfælde er de respektive koordinater for postnummerets tyngdepunkt.
Følgende skærmbillede er en visuel repræsentation af sådanne aktiviteter. Det venstre billede kortlægger stoppestederne til butikkerne, og det højre billede giver en idé om indretningen af selve indkøbscentret.

Dette resulterende datasæt kan visualiseres på en række måder, som vi diskuterer i de følgende afsnit.
Tæthedsmålinger
Vi kan beregne og visualisere tætheden af aktiviteter og besøg.
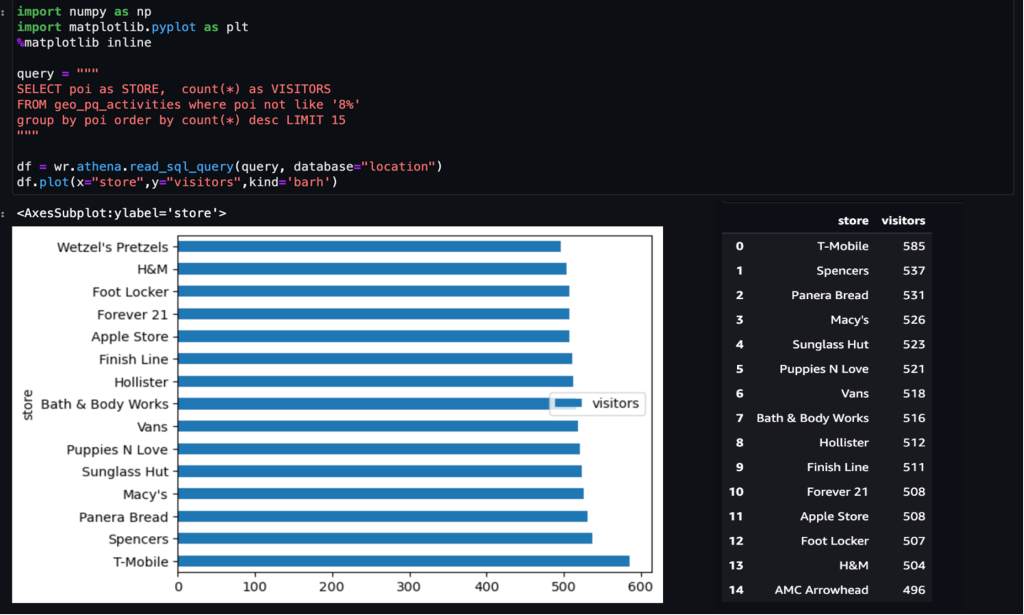
Eksempel 1 – Følgende skærmbillede viser top 15 besøgte butikker i indkøbscenteret.
Eksempel 2 – Følgende skærmbillede viser antallet af besøg i Apple Store pr. time.

Ture og baner
Som nævnt tidligere repræsenterer et par på hinanden følgende aktiviteter en tur. Vi kan bruge følgende tilgang til at udlede ture fra aktivitetsdataene. Her bruges vinduesfunktioner med SQL til at generere trips tabel, som vist på skærmbilledet.

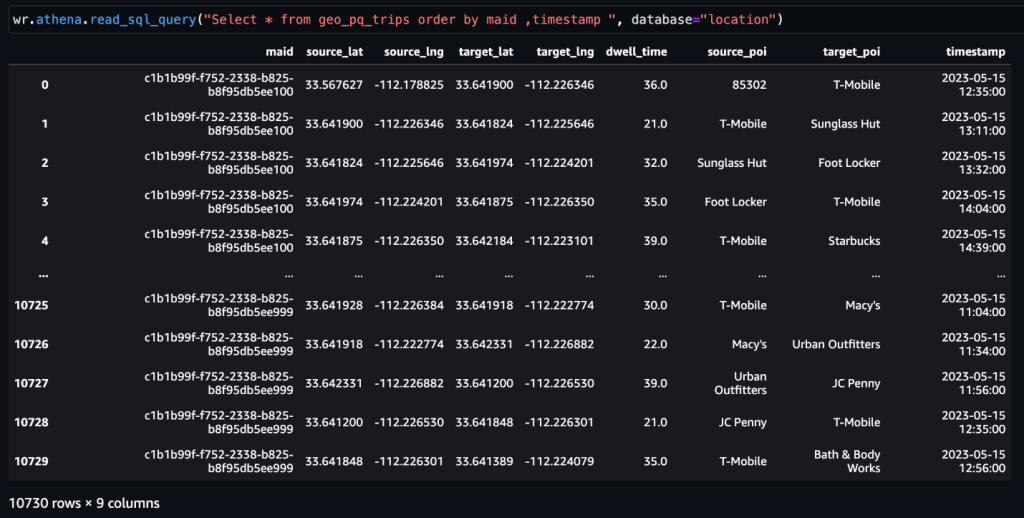
Efter trips tabel genereres, kan ture til et POI bestemmes.
Eksempel 1 – Følgende skærmbillede viser de 10 bedste butikker, der leder gangtrafikken mod Apple Store.

Eksempel 2 – Følgende skærmbillede viser alle turene til Arrowhead Mall.

Eksempel 3 – Den følgende video viser bevægelsesmønstrene inde i indkøbscentret.

Eksempel 4 – Den følgende video viser bevægelsesmønstrene uden for indkøbscentret.
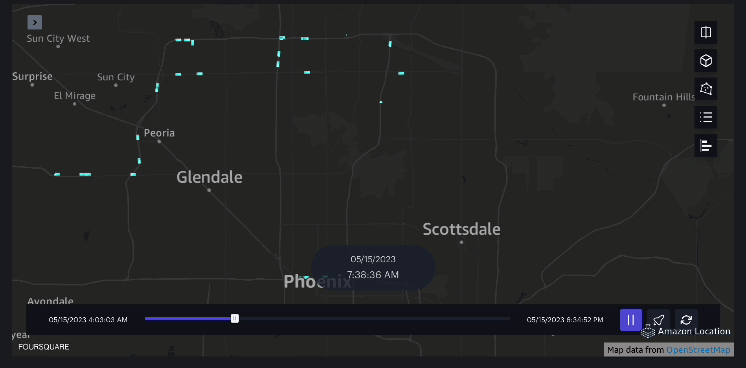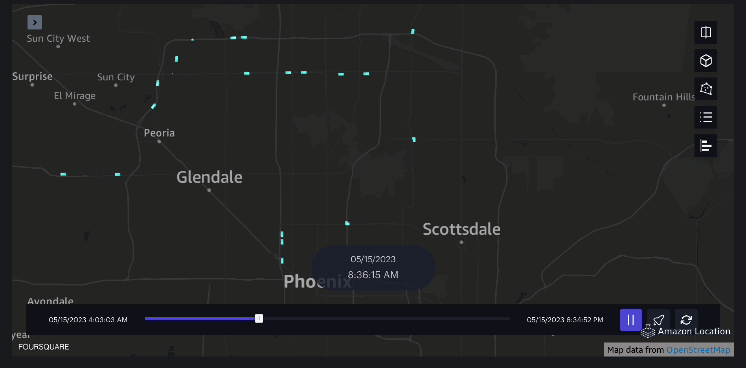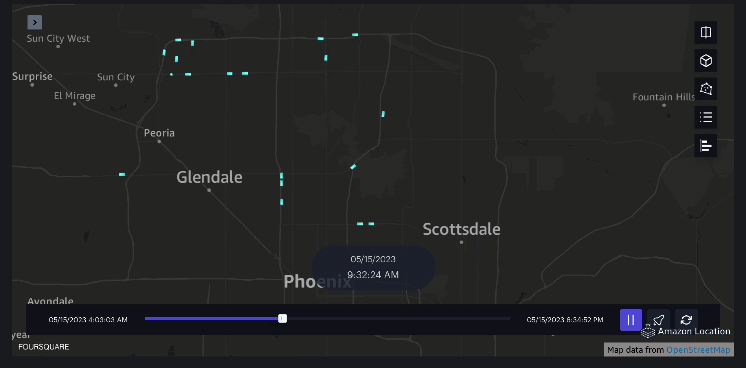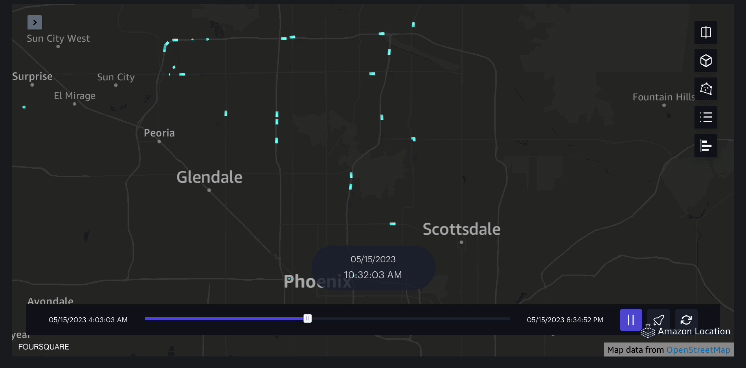
Oplandsanalyse
Vi kan analysere alle besøg på et POI og bestemme oplandet.
Eksempel 1 – Følgende skærmbillede viser alle besøg i Macy's-butikken.

Eksempel 2 – Følgende skærmbillede viser de 10 bedste postnumre i hjemmeområdet (grænser fremhævet), hvorfra besøgene fandt sted.

Kontrol af datakvalitet
Vi kan tjekke det daglige indgående datafeed for kvalitet og opdage uregelmæssigheder ved hjælp af QuickSight-dashboards og dataanalyser. Følgende skærmbillede viser et eksempel på et dashboard.

Konklusion
Mobilitetsdata og deres analyse for at opnå kundeindsigt og opnå konkurrencefordele forbliver et nicheområde, fordi det er svært at opnå et konsistent og præcist datasæt. Disse data kan dog hjælpe organisationer med at tilføje kontekst til eksisterende analyser og endda producere ny indsigt omkring kundebevægelsesmønstre. Amazon SageMaker geospatiale muligheder og geospatiale behandlingsjob kan hjælpe med at implementere disse use cases og udlede indsigt på en intuitiv og tilgængelig måde.
I dette indlæg demonstrerede vi, hvordan man bruger AWS-tjenester til at rense mobilitetsdataene og derefter bruger Amazon SageMaker geospatiale kapaciteter til at generere afledte datasæt såsom stop, aktiviteter og ture ved hjælp af ML-modeller. Derefter brugte vi de afledte datasæt til at visualisere bevægelsesmønstre og generere indsigt.
Du kan komme i gang med Amazon SageMaker geospatiale muligheder på to måder:
Hvis du vil vide mere, kan du besøge Amazon SageMaker geospatiale muligheder , Kom godt i gang med Amazon SageMaker geospatial. Besøg også vores GitHub repo, som har flere eksempler på notesbøger om Amazon SageMaker geospatiale muligheder.
Om forfatterne
 Jimy Matthews er en AWS Solutions Architect, med ekspertise inden for AI/ML-teknologi. Jimy er baseret i Boston og arbejder med virksomhedskunder, mens de transformerer deres forretning ved at adoptere skyen og hjælper dem med at bygge effektive og bæredygtige løsninger. Han brænder for sin familie, biler og Mixed martial arts.
Jimy Matthews er en AWS Solutions Architect, med ekspertise inden for AI/ML-teknologi. Jimy er baseret i Boston og arbejder med virksomhedskunder, mens de transformerer deres forretning ved at adoptere skyen og hjælper dem med at bygge effektive og bæredygtige løsninger. Han brænder for sin familie, biler og Mixed martial arts.
 Girish Keshav er Solutions Architect hos AWS, der hjælper kunder i deres cloud-migreringsrejse med at modernisere og køre arbejdsbelastninger sikkert og effektivt. Han arbejder med ledere af teknologiteams for at vejlede dem om applikationssikkerhed, maskinlæring, omkostningsoptimering og bæredygtighed. Han er baseret i San Francisco og elsker at rejse, vandre, se sport og udforske håndværksbryggerier.
Girish Keshav er Solutions Architect hos AWS, der hjælper kunder i deres cloud-migreringsrejse med at modernisere og køre arbejdsbelastninger sikkert og effektivt. Han arbejder med ledere af teknologiteams for at vejlede dem om applikationssikkerhed, maskinlæring, omkostningsoptimering og bæredygtighed. Han er baseret i San Francisco og elsker at rejse, vandre, se sport og udforske håndværksbryggerier.
 Ramesh Jetty er en senior leder af Solutions Architecture med fokus på at hjælpe AWS enterprise-kunder med at tjene penge på deres dataaktiver. Han rådgiver ledere og ingeniører til at designe og bygge meget skalerbare, pålidelige og omkostningseffektive cloud-løsninger, især med fokus på maskinlæring, data og analyser. I sin fritid nyder han friluftslivet, cykling og vandreture med sin familie.
Ramesh Jetty er en senior leder af Solutions Architecture med fokus på at hjælpe AWS enterprise-kunder med at tjene penge på deres dataaktiver. Han rådgiver ledere og ingeniører til at designe og bygge meget skalerbare, pålidelige og omkostningseffektive cloud-løsninger, især med fokus på maskinlæring, data og analyser. I sin fritid nyder han friluftslivet, cykling og vandreture med sin familie.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/
- :har
- :er
- :ikke
- :hvor
- $OP
- 000
- 1
- 10
- 100
- 14
- 15 %
- 2023
- 300
- 361
- 3d
- 400
- 50
- 7
- 9
- a
- Om
- over
- fremskynde
- accelereret
- adgang
- tilgængelig
- udrette
- nøjagtighed
- præcis
- opnået
- aktiv
- aktivt
- aktiviteter
- faktiske
- tilføje
- adresse
- overholdt
- Justeret
- Vedtagelsen
- annoncer
- Fordel
- reklame
- Reklame
- Efter
- aggregator
- nyhedslæsere
- AI / ML
- Støtte
- algoritme
- Alle
- langs med
- også
- Skønt
- am
- Amazon
- Amazon Comprehend
- Amazon SageMaker
- Amazon SageMaker geospatial
- Amazon SageMaker Studio
- Amazon Web Services
- beløb
- an
- analyser
- analyse
- analytics
- analysere
- analysere
- Anchor
- ,
- enhver
- fra hinanden
- app
- Apple
- Anvendelse
- applikationssikkerhed
- applikationer
- tilgang
- cirka
- arkitektur
- ER
- OMRÅDE
- områder
- arizona
- omkring
- Arts
- AS
- Aktiver
- tildelt
- forbundet
- At
- nå
- publikum
- forøge
- til rådighed
- gennemsnit
- AWS
- AWS Lim
- bund
- baseret
- grundlag
- BE
- fordi
- været
- være
- mellem
- bud
- Bloker
- boston
- grænser
- brands
- bygge
- Bygning
- indbygget
- virksomhed
- virksomheder
- men
- by
- beregne
- kaldet
- Kampagner
- CAN
- Kan få
- kapaciteter
- biler
- tilfælde
- tilfælde
- CCPA
- Celler
- Folketælling
- folketællingsdata
- kæde
- kontrollere
- byer
- By
- ren
- Luk
- Cloud
- Cluster
- klyngedannelse
- kode
- koder
- samarbejde
- indsamler
- samling
- samlere
- Kolonne
- Kolonner
- kombineret
- kommer
- kommer
- kommerciel
- erhvervsejendomme
- Fælles
- almindeligt
- Virksomheder
- konkurrencedygtig
- konkurrenter
- komplekse
- komponent
- forstå
- Compute
- Tilslutning
- træk
- samtykke
- overvejelser
- konsekvent
- forbrug
- Container
- indeholder
- sammenhæng
- kontinuerlig
- Koste
- lande
- land
- dæksel
- dækker
- håndværk
- crawler
- skabe
- skik
- kunde
- Kunder
- dagligt
- instrumentbræt
- dashboards
- data
- datapunkter
- databeskyttelse
- databehandling
- datasæt
- dag
- levering
- demonstreret
- tæthed
- forestillende
- indsætte
- afledte
- udlede
- Afledt
- Design
- destinationer
- detail
- opdage
- Bestem
- bestemmes
- bestemmelse
- Udvikling
- enhed
- Enheder
- svært
- direkte
- katastrofer
- opdage
- diskutere
- afstand
- skelne
- Gør det selv
- gør
- færdig
- DOT
- trækker
- grund
- varighed
- i løbet af
- hver
- tidligere
- lettere
- let
- Effektiv
- effektiv
- effektivt
- indsats
- bemyndige
- muliggør
- omfatter
- engagement
- engagementer
- engagerende
- Ingeniører
- berige
- Enterprise
- virksomhedskunder
- Miljø
- især
- ejendom
- Ether (ETH)
- etisk
- Endog
- begivenhed
- Hver
- eksempel
- ledere
- eksisterende
- eksisterer
- dyrt
- erfaring
- ekspertise
- udforske
- Udforskning
- eksport
- udtrykt
- ekstrakt
- familie
- Feature
- Fed
- få
- File (Felt)
- endelige
- Finde
- fiona
- Fornavn
- fleksibel
- Fokus
- fokuserede
- efterfulgt
- efter
- Fod
- Til
- formular
- format
- Foursquare
- FRAME
- Francisco
- Gratis
- fra
- Brændstof
- fuldt ud
- funktion
- funktioner
- yderligere
- vinder
- spil
- indsamlede
- GDPR
- generere
- genereret
- genererer
- generere
- geografiske
- geografisk
- Geospatial ML
- få
- få
- gif
- given
- giver
- Goes
- gps
- grafik
- stor
- Fantastisk udendørs
- Grid
- vejlede
- Hardware
- hash'et
- Have
- he
- hjælpe
- hjælpsom
- hjælpe
- hjælper
- link.
- Fremhævet
- stærkt
- hiking
- hans
- Home
- Vandret
- time
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- Hubs
- orkan
- ID
- idé
- identificeret
- identificere
- identificere
- IDFA
- if
- billede
- gennemføre
- vigtigt
- Forbedre
- in
- Herunder
- Indgående
- angiver
- individuel
- industrier
- oplysninger
- Infrastruktur
- initial
- indvendig
- indsigt
- forekomster
- integrationer
- Intelligens
- interaktiv
- interesse
- interessant
- ind
- indføre
- intuitiv
- involverer
- IT
- ITS
- selv
- Job
- Karriere
- sluttede
- rejse
- jpg
- stor
- storstilet
- breddegrad
- Love
- lagdelt
- Layout
- føre
- leder
- ledere
- LÆR
- læring
- til venstre
- biblioteker
- ligesom
- sandsynlighed
- linjer
- belastning
- placering
- placeringer
- Se
- ligner
- elsker
- maskine
- machine learning
- Maskiner
- lavet
- vedligeholde
- større
- lave
- maerker
- lykkedes
- styring
- manuelt
- mange
- kort
- kortlægning
- Maps
- Marketing
- Marketingkampagner
- marketingteknologi
- MarTech
- martial
- maske
- Matrix
- Kan..
- midler
- nævnte
- metode
- Metrics
- migration
- Militær
- millioner
- minimum
- minut
- blandet
- ML
- Mobil
- mobil enhed
- mobilenheder
- mobilitet
- model
- modeller
- modernisere
- modificeret
- ændre
- tjene penge
- månedligt
- mere
- mest
- for det meste
- bevæge sig
- bevægelse
- bevægelser
- flytning
- flere
- mangfoldighed
- skal
- navn
- Natural
- Natur
- Behov
- behov
- Ny
- næste
- niche
- Støj
- notesbog
- notesbøger
- nummer
- numre
- objekt
- observere
- opnå
- opnået
- opnå
- forekom
- of
- tit
- on
- ONE
- kun
- åbent
- open source
- drift
- Produktion
- modsætning
- optimal
- optimering
- Optimer
- or
- organisationer
- Andet
- vores
- ud
- udfald
- udendørs
- uden for
- i løbet af
- par
- pandaer
- pandemi
- parametre
- del
- især
- passerer
- lidenskabelige
- sti
- mønstre
- Mennesker
- per
- udføre
- ydeevne
- Personligt
- perspektiv
- phoenix
- fotografier
- fysisk
- billede
- PIO
- ping
- placeret
- Steder
- planlægning
- plato
- Platon Data Intelligence
- PlatoData
- pm
- Punkt
- punkter
- Populær
- befolkning
- position
- mulig
- Indlæg
- potentiale
- potentielle kunder
- strøm
- forud
- Forudsigelser
- præsentere
- Beskyttelse af personlige oplysninger
- lovgivning om beskyttelse af personlige oplysninger
- private
- behandle
- forarbejdning
- producere
- give
- offentligt
- udgivere
- køb
- købt
- formål
- Python
- kvalitet
- rangerer
- hellere
- Raw
- rådata
- ægte
- fast ejendom
- registreres
- henvise
- henvisningen
- refererer
- regioner
- pålidelig
- resterne
- repræsentere
- repræsentation
- repræsenteret
- repræsenterer
- repræsenterer
- påkrævet
- dem
- ansvarlige
- Restauranter
- resulterer
- Resultater
- detail
- højre
- R
- veje
- Kør
- kører
- sagemaker
- Eksempeldatasæt
- San
- San Francisco
- satellit
- satellitbilleder
- skalerbar
- Scale
- forskere
- screenshots
- sdks
- sømløs
- Anden
- sekunder
- sektioner
- sikkert
- sikkerhed
- valg
- senior
- følsom
- sendt
- adskille
- Series
- Tjenester
- servering
- flere
- Del
- Shopping
- bør
- vist
- Shows
- lignende
- Simpelt
- forenklet
- enkelt
- websted
- langsom
- So
- Løsninger
- Løser
- nogle
- søgte
- Kilde
- Kilder
- Space
- rumlige
- specifikke
- Sport
- pletter
- SQL
- standardisering
- påbegyndt
- starter
- udsagn
- Stater
- Trin
- Steps
- Stands
- stoppet
- standsning
- stopper
- opbevaring
- butik
- opbevaret
- forhandler
- ligetil
- strøm
- Studio
- væsentlig
- sådan
- forsyne
- forsyningskæde
- support
- overflade
- Omkringliggende
- Bæredygtighed
- bæredygtig
- systemet
- bord
- taget
- hold
- tech
- Teknisk
- teknikker
- Teknologier
- tiere
- end
- at
- Området
- The Source
- deres
- Them
- selv
- derefter
- Der.
- Disse
- de
- denne
- dem
- tusinder
- tærskel
- Gennem
- tid
- til
- også
- værktøj
- værktøjer
- top
- Top 10
- I alt
- mod
- Sporing
- Trafik
- Tog
- bane
- Transform
- transformationer
- sendere
- rejse
- Traveling
- Tendenser
- tur
- to
- typer
- typisk
- underliggende
- forståelse
- enestående
- uploadet
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- bruger
- ved brug af
- udnytte
- forskellige
- verificere
- via
- video
- Besøg
- besøgte
- besøgende
- Besøg
- visuel
- visualisering
- Visualiser
- visuals
- vs
- ser
- Vej..
- måder
- we
- web
- webservices
- ugentlig
- GODT
- Hvad
- hvornår
- som
- WHO
- Hele
- hvorfor
- Wi-fi
- udbredt
- vilje
- vindue
- med
- uden
- Arbejde
- workflow
- virker
- skrivning
- årligt
- dig
- Din
- zephyrnet
- Zip