Billede af jcomp on Freepik
Tidsserier er et unikt datasæt inden for datavidenskabsområdet. Dataene registreres på tids-frekvens (f.eks. dagligt, ugentligt, månedligt osv.), og hver observation er relateret til den anden. Tidsseriedataene er værdifulde, når du vil analysere, hvad der sker med dine data over tid og skabe fremtidige forudsigelser.
Tidsserieprognoser er en metode til at skabe fremtidige forudsigelser baseret på historiske tidsseriedata. Der findes mange statistiske metoder til tidsserieprognoser, som f.eks ARIMA or Eksponentiel udjævning.
Tidsserieprognoser støder man ofte på i virksomheden, så det er en fordel for dataforskeren at vide, hvordan man udvikler en tidsseriemodel. I denne artikel vil vi lære, hvordan man forudsiger tidsserier ved hjælp af to populære prognoser Python-pakker; statsmodeller og profet. Lad os komme ind i det.
statsmodeller Python-pakken er en open source-pakke, der tilbyder forskellige statistiske modeller, herunder tidsserieprognosemodellen. Lad os prøve pakken med et eksempeldatasæt. Denne artikel vil bruge Digital valuta tidsserie data fra Kaggle (CC0: Public Domain).
Lad os rydde op i dataene og tage et kig på det datasæt, vi har.
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
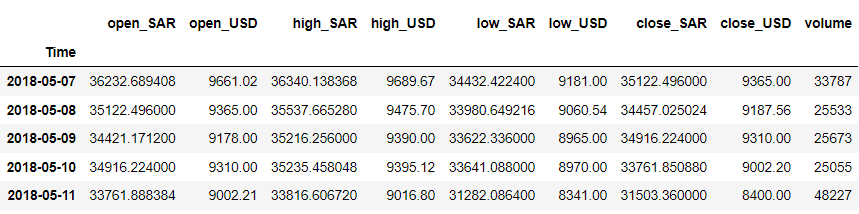
df = df.iloc[::-1].set_index('Time') df.head()
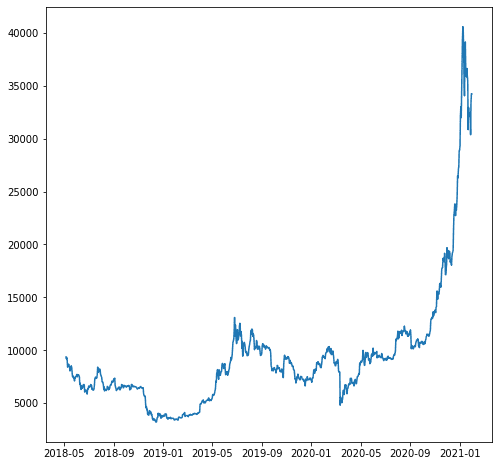
For vores eksempel, lad os sige, at vi ønsker at forudsige variablen 'close_USD'. Lad os se, hvordan datamønstret over tid.
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
Lad os bygge prognosemodellen baseret på vores ovenstående data. Før modellering, lad os opdele dataene i tog- og testdata.
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
Vi deler ikke dataene tilfældigt, fordi det er tidsseriedata, og vi skal bevare rækkefølgen. I stedet forsøger vi at have togdataene fra tidligere og testdataene fra de seneste data.
Lad os bruge statsmodeller til at skabe en prognosemodel. Det statsmodel giver mange tidsseriemodel-API'er, men vi ville bruge ARIMA-modellen som vores eksempel.
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
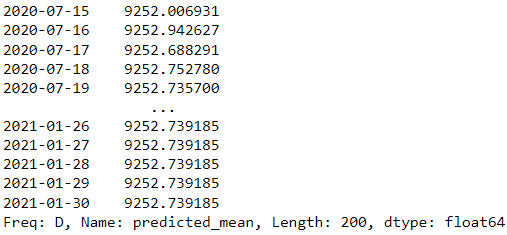
I vores eksempel ovenfor bruger vi ARIMA-modellen fra statsmodeller som prognosemodel og forsøger at forudsige de næste 200 dage.
Er modelresultatet godt? Lad os prøve at evaluere dem. Evalueringen af tidsseriemodeller bruger normalt en visualiseringsgraf til at sammenligne den faktiske og forudsigelse med regressionsmålinger såsom Mean Absolute Error (MAE), Root Mean Square Error (RMSE) og MAPE (Mean Absolute Percentage Error).
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
Ovenstående score ser fint ud, men lad os se, hvordan det er, når vi visualiserer dem.
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
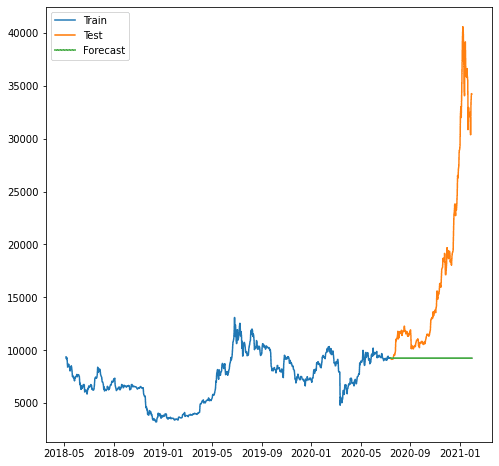
Som vi kan se, var prognosen værre, da vores model ikke kan forudsige den stigende tendens. Modellen ARIMA, som vi bruger, virker for simpel til at forudsige.
Måske er det bedre, hvis vi prøver at bruge en anden model uden for statsmodeller. Lad os prøve den berømte profetpakke fra Facebook.
Profeten er en modelpakke til tidsserieprognoser, der fungerer bedst på data med sæsonbestemte effekter. Prophet blev også betragtet som en robust prognosemodel, fordi den kunne håndtere manglende data og outliers.
Lad os prøve profetpakken. Først skal vi installere pakken.
pip install prophet
Derefter skal vi forberede vores datasæt til prognosemodeltræningen. Profeten har et specifikt krav: tidskolonnen skal navngives som 'ds' og værdien som 'y'.
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
Med vores data klar, lad os prøve at skabe forudsigelse baseret på dataene.
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
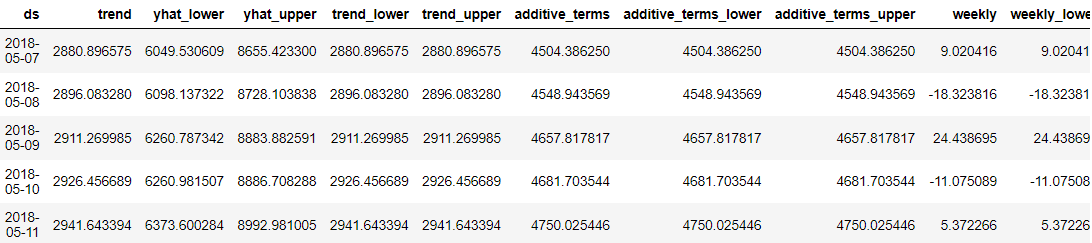
Det, der var fantastisk ved profeten, var, at hvert prognosedatapunkt var detaljeret for os brugere at forstå. Det er dog svært at forstå resultatet kun ud fra dataene. Så vi kunne prøve at visualisere dem ved hjælp af profeten.
model.plot(predictions)
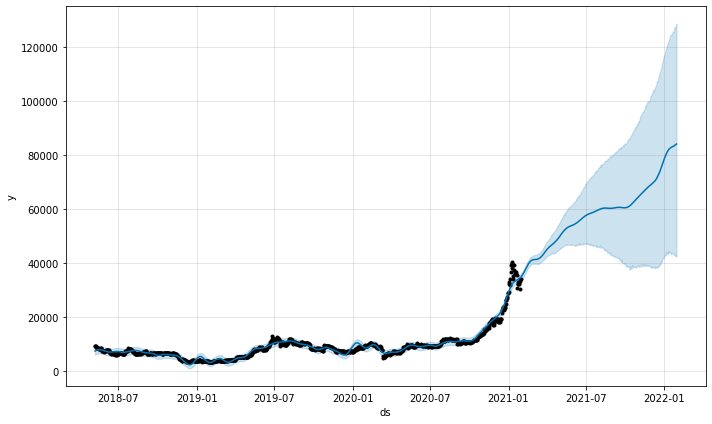
Forudsigelsesplotfunktionen fra modellen ville give os, hvor sikre forudsigelserne var. Fra ovenstående plot kan vi se, at forudsigelsen har en opadgående tendens, men med øget usikkerhed jo længere forudsigelserne er.
Det er også muligt at undersøge prognosekomponenterne med følgende funktion.
model.plot_components(predictions)
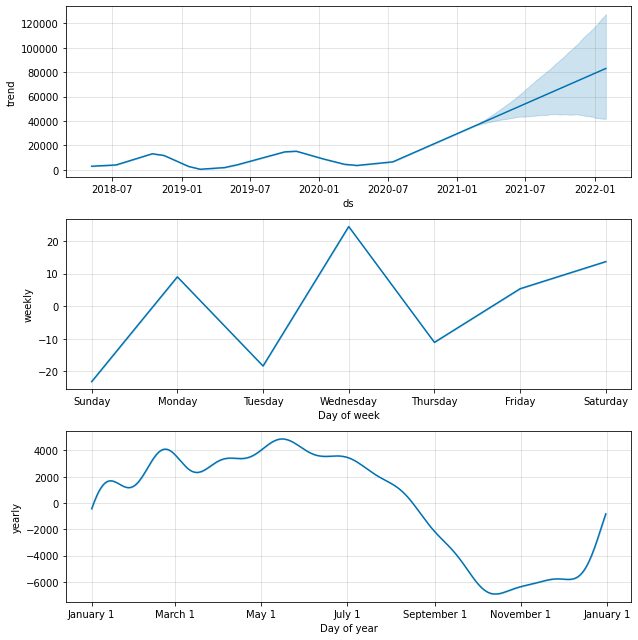
Som standard ville vi få datatendensen med årlige og ugentlige sæsonvariationer. Det er en god måde at forklare, hvad der sker med vores data.
Ville det også være muligt at evaluere profetmodellen? Absolut. Profeten inkluderer en diagnostisk måling, som vi kan bruge: krydsvalidering af tidsserier. Metoden bruger en del af de historiske data og tilpasser modellen hver gang ved hjælp af data op til cutoff-punktet. Så ville profeten sammenligne forudsigelserne med de faktiske. Lad os prøve at bruge koden.
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
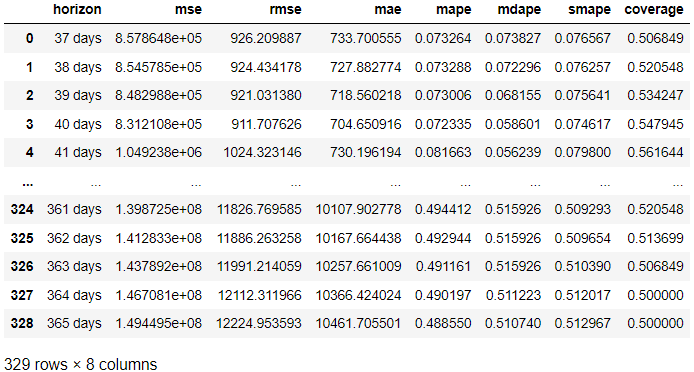
I resultatet ovenfor har vi opnået evalueringsresultatet fra det faktiske resultat sammenlignet med prognosen på hver prognosedag. Det er også muligt at visualisere resultatet med følgende kode.
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
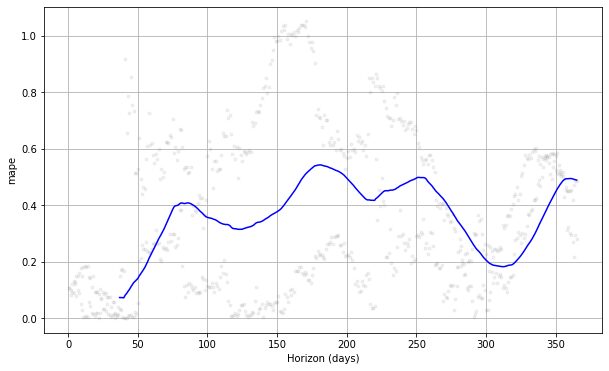
Hvis vi ser plottet ovenfor, kan vi se, at forudsigelsesfejlen varierede efter dagene, og den kunne opnå 50 % fejl på nogle punkter. På denne måde ønsker vi måske at finjustere modellen yderligere for at rette fejlen. Du kan tjekke dokumentation til yderligere udforskning.
Forecasting er et af de almindelige tilfælde, der opstår i virksomheden. En nem måde at udvikle en prognosemodel på er at bruge statsforecast- og Prophet Python-pakkerne. I denne artikel lærer vi, hvordan man opretter en prognosemodel og evaluerer dem med statsforecast og Prophet.
Cornellius Yudha Wijaya er en data science assisterende leder og dataskribent. Mens han arbejder på fuld tid hos Allianz Indonesia, elsker han at dele Python- og Data-tips via sociale medier og skrivemedier.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- :er
- $OP
- 1
- 11
- 7
- 8
- 9
- a
- Om
- over
- absolutte
- absolut
- opnå
- erhvervede
- Allianz
- analysere
- ,
- En anden
- API'er
- ER
- artikel
- AS
- Assistant
- At
- baseret
- BE
- fordi
- før
- gavnlig
- BEDSTE
- Bedre
- mellem
- bygge
- virksomhed
- by
- beregne
- CAN
- tilfælde
- CC0
- kontrollere
- kode
- Kolonne
- Kolonner
- Fælles
- sammenligne
- sammenlignet
- komponenter
- sikker
- betragtes
- kunne
- dækning
- skabe
- Valuta
- dagligt
- data
- datalogi
- dataforsker
- Dato
- dag
- Dage
- dc
- Standard
- detaljeret
- udvikle
- domæne
- Dont
- e
- hver
- tidligere
- effekter
- fejl
- etc.
- evaluere
- evaluering
- Hver
- eksempel
- Forklar
- udforskning
- berømt
- felt
- ende
- Fornavn
- passer
- Fix
- efter
- Til
- Forecast
- fra
- funktion
- yderligere
- fremtiden
- få
- GitHub
- godt
- graf
- stor
- håndtere
- sker
- Hård Ost
- Have
- historisk
- horisont
- Hvordan
- How To
- Men
- HTML
- HTTPS
- importere
- in
- omfatter
- Herunder
- øget
- stigende
- indeks
- Indonesien
- initial
- installere
- i stedet
- IT
- jpg
- KDnuggets
- Kend
- seneste
- LÆR
- længere
- Se
- UDSEENDE
- lave
- leder
- mange
- matplotlib
- Medier
- metode
- metoder
- Metrics
- måske
- mangler
- model
- modellering
- modeller
- månedligt
- Som hedder
- Behov
- behov
- næste
- bedøvet
- opnå
- of
- tilbyde
- on
- ONE
- open source
- ordrer
- Andet
- uden for
- pakke
- pakker
- pandaer
- parametre
- del
- Mønster
- procentdel
- udføre
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- punkter
- Populær
- mulig
- forudsige
- forudsigelse
- Forudsigelser
- Forbered
- give
- giver
- offentlige
- Python
- klar
- registreres
- regression
- relaterede
- krav
- resultere
- Resultater
- robust
- rod
- Videnskab
- Videnskabsmand
- synes
- Series
- sæt
- Del
- Simpelt
- So
- Social
- sociale medier
- nogle
- specifikke
- delt
- firkant
- statistiske
- sådan
- Tag
- prøve
- at
- Them
- tid
- Tidsserier
- tips
- til
- også
- Tog
- Kurser
- Trend
- Usikkerhed
- forstå
- enestående
- UNAVNT
- opad
- us
- brug
- brugere
- sædvanligvis
- Værdifuld
- værdi
- forskellige
- via
- visualisering
- Vej..
- ugentlig
- GODT
- Hvad
- mens
- Wikipedia
- vilje
- med
- inden for
- arbejder
- virker
- ville
- forfatter
- skrivning
- Din
- zephyrnet