Billede af forfatter
Når du arbejder med data og forskellige variabler, er det nemt at tildele en variabel eller værdi til at være større end den anden. Vi kan antage, at en specifik variabel eller datapunkt havde mere indflydelse på outputtet, men hvor sikre er vi på, at de andre variable har en lige så stor indvirkning?
I statistik kan basissatsen ses som sandsynligheder for klasser, der er ubetingede på "featural evidens". Du kan se basisrenten som din tidligere sandsynlighedsantagelse.
Basissatser er vigtige værktøjer i forskning. Hvis vi for eksempel er en medicinalvirksomhed og er i gang med at udvikle og udsende en ny vaccination, ønsker vi at undersøge, om behandlingen er succesfuld. Hvis vi har 4000 mennesker, der er villige til at tage denne vaccination, og vores basissats er 1/25.
Det betyder, at kun 160 mennesker vil blive helbredt med succes af behandlingen ud af 4000 mennesker. I den farmaceutiske verden er dette en meget lav succesrate. Sådan kan basissatser bruges til at forbedre forskning og nøjagtighed og sikre, at produktet vil fungere godt.
Hvis vi deler ordene op, vil det give os en bedre forståelse. Fejlslutning betyder en fejlagtig tro eller fejlagtig begrundelse. Hvis vi nu kombinerer det med vores definition af basisrenten ovenfor.
Grundsatsfejlen, også kendt som basisrentebias og basisrenteforsømmelse, er sandsynligheden for at bedømme en specifik situation uden at tage alle relevante data i betragtning.
Grundsatsfejlen har information om basissatsen samt anden relevant information. Dette kan skyldes forskellige årsager, såsom ikke grundigt at undersøge og analysere dataene ordentligt eller uvidenhed om at favorisere en bestemt del af dataene.
Grundsatsfejlen beskriver tendensen hos nogen til at se bort fra den eksisterende basissatsinformation, til at skubbe og gå ind for den nye information. Dette er i modstrid med de grundlæggende regler for evidensbaseret ræsonnement.
Du vil typisk høre om dette, der sker i den finansielle branche. For eksempel vil investorer basere deres købs- eller deletaktikker på irrationel information, hvilket fører til udsving i markedet – på trods af at de har basisrenten til deres viden.
Så nu har vi en bedre forståelse af grundsatsen og grundsatsfejlen. Hvad er dets relevans og virkning i Data Science?
Vi har talt om 'sandsynligheder for klasser' og 'at tage alle relevante data i betragtning'. Hvis du er dataforsker eller maskinlæringsingeniør eller får foden inden for døren – vil du vide, hvor vigtige sandsynligheder og relevante data er for at producere nøjagtige output, læreprocessen for din maskinlæringsmodel og producere højtydende modeller.
For at analysere og lave forudsigelser om data eller for at din maskinlæringsmodel kan producere nøjagtige output - skal du tage alle data i betragtning. Når du scanner dine data første gang, du ser dem, vil du måske overveje, at nogle dele er relevante og andre som irrelevante. Dette er dog din vurdering og er endnu ikke faktuel, før en ordentlig analyse har fundet sted.
Som nævnt ovenfor hjælper den indledende basisrate dig med at sikre nøjagtighed og producere højtydende modeller. Så hvordan kan vi gøre dette i Data Science?
Forvirringsmatrix
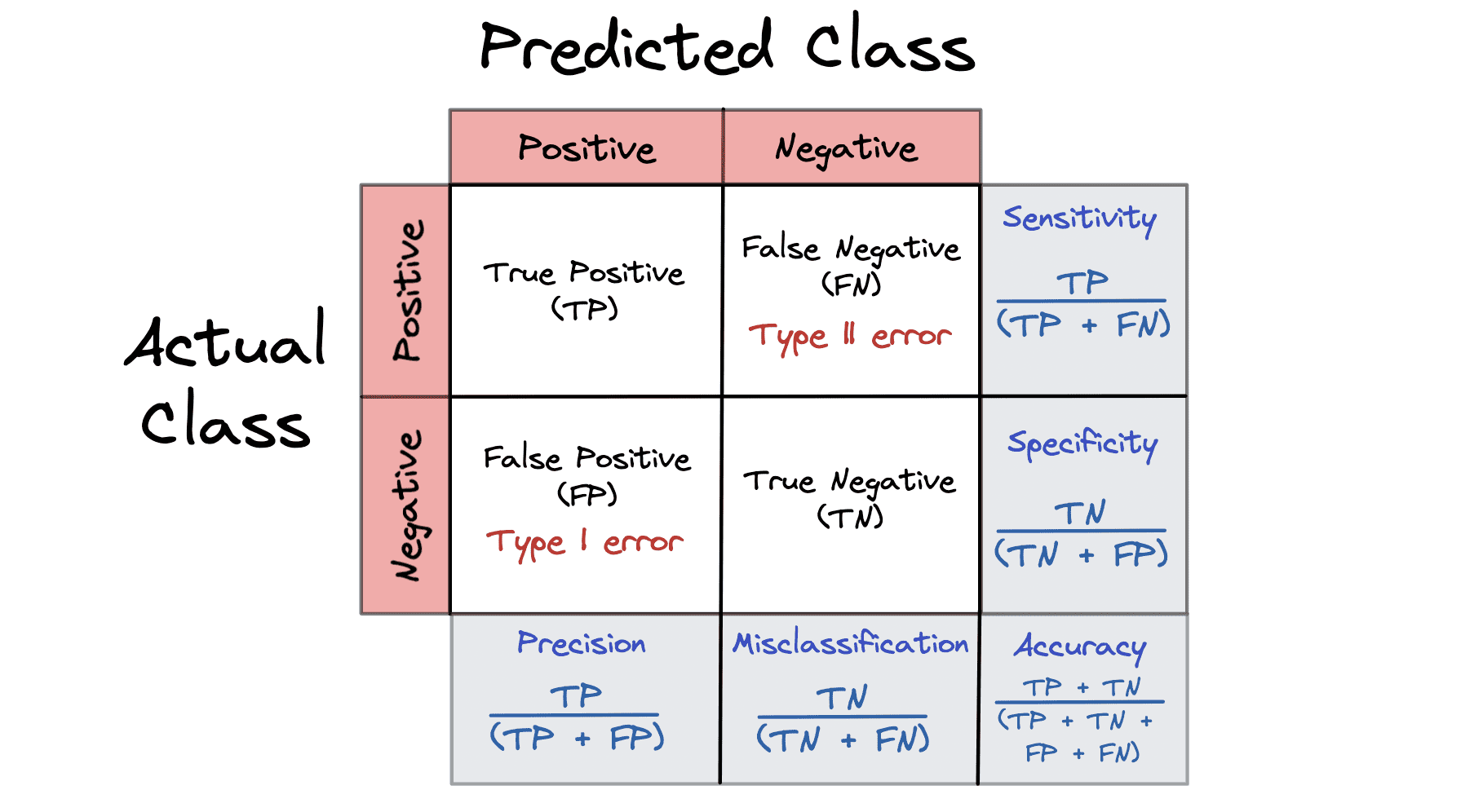
En forvirringsmatrix er en præstationsmåling, der giver en oversigt over forudsigelsesresultater på et klassifikationsproblem. Forvirringsmatricerne er alle baseret på resultatet: Sandt, Falskt, Positivt og Negativt.
Forvirringsmatricen repræsenterer vores models forudsigelser under testfasen. De falsk-negative og falsk-positive i forvirringsmatricen er eksempler på grundrate-fejlslutning.
- Sand positiv (TP) – din model forudsagde positiv, og den er positiv
- True Negative (TN) – din model forudsagde negativ, og den er negativ
- Falsk positiv (FP) – din model forudsagde positiv, og den er negativ
- Falsk negativ (FN) – din model forudsagde negativ, og den er positiv
En forvirringsmatrix kan beregne 5 forskellige metrics for at hjælpe os med at måle gyldigheden af vores model:
- Fejlklassificering = FP + FN / TP + TN + FP + FN
- Præcision = TP / TP + FP
- Nøjagtighed = TP + TN / TP + TN + FP + FN
- Specificitet = TN / TN + FP
- Følsomhed aka Recall = TP / TP + FN
For bedre at forstå en forvirringsmatrix er det bedre at se på en visualisering:
Billede af forfatter
Mens du gennemgår denne artikel, kan du sikkert komme i tanke om en række forskellige årsager til fejl i grundsatsen, såsom ikke at tage alle relevante data i betragtning, menneskelige fejl eller mangel på præcision.
Selvom disse alle er sande og tilføjer årsagen til grundsatsfejlen. De relaterer alle til det største problem med at ignorere basisrenteoplysningerne i første omgang. Oplysninger om basispris ignoreres ofte, da de anses for irrelevante, men oplysningerne om basispris kan spare folk for en masse tid og penge. Ved at bruge de tilgængelige basisrenteoplysninger kan du være mere præcis i at lave sandsynligheder for, om en given hændelse vil finde sted.
Brug af basisrenteoplysningerne hjælper dig med at undgå fejl i basissatsen.
At være opmærksom på fejlslutninger såsom meninger, automatiske processer osv. – vil give dig mulighed for at bekæmpe spørgsmålet om grundsatsfejl og reducere potentielle fejl. Når du måler sandsynligheden for, at en bestemt hændelse indtræffer, kan Bayesianske metoder hjælpe med dette for at reducere grundsatsfejlen.
Grundsatsen er vigtig inden for datavidenskab, da den udstyrer dig med en grundlæggende forståelse af, hvordan du vurderer dit studie eller projekt og finjusterer din model – hvilket giver en samlet stigning i nøjagtighed og ydeevne.
Hvis du gerne vil se en video om grundsatsfejl inden for det medicinske område, så tjek denne video: Medicinsk test paradoks
Nisha Arya er dataforsker, freelance teknisk skribent og Community Manager hos KDnuggets. Hun er særligt interesseret i at give Data Science karriererådgivning eller tutorials og teoribaseret viden omkring Data Science. Hun ønsker også at udforske de forskellige måder, kunstig intelligens er/kan gavne menneskets levetid. En ivrig lærende, der søger at udvide sin tekniske viden og skrivefærdigheder, samtidig med at hun hjælper med at vejlede andre.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/04/base-rate-fallacy-impact-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-base-rate-fallacy-and-its-impact-on-data-science
- :har
- :er
- :ikke
- $OP
- a
- Om
- over
- nøjagtighed
- præcis
- rådgivning
- mod
- Alle
- tillader
- også
- an
- analysere
- analyse
- analysere
- ,
- ER
- omkring
- artikel
- kunstig
- kunstig intelligens
- AS
- antagelse
- At
- Automatisk Ur
- til rådighed
- bund
- baseret
- Bayesiansk
- BE
- tro
- gavner det dig
- Bedre
- skævhed
- Største
- Bit
- udvide
- Købe
- by
- beregne
- CAN
- Karriere
- Årsag
- årsager
- vis
- kontrollere
- klasser
- klassificering
- bekæmpe
- kombinerer
- samfund
- selskab
- forvirring
- Overvej
- overvejelse
- betragtes
- data
- datalogi
- dataforsker
- Trods
- udvikling
- forskellige
- Ved
- i løbet af
- ingeniør
- sikre
- fejl
- fejl
- etc.
- begivenhed
- Hver
- bevismateriale
- Undersøgelse
- eksempel
- eksempler
- eksisterende
- udforske
- Faktuel
- defekt
- felt
- finansielle
- Fornavn
- første gang
- fluktuation
- Fod
- Til
- freelance
- fundamental
- få
- Giv
- given
- Goes
- gå
- større
- vejlede
- Happening
- Have
- have
- høre
- hjælpe
- hjælpe
- hjælper
- Høj ydeevne
- Hvordan
- How To
- Men
- HTTPS
- menneskelig
- Uvidenhed
- KIMOs Succeshistorier
- vigtigt
- Forbedre
- in
- Forøg
- industrien
- oplysninger
- initial
- Intelligens
- interesseret
- ind
- Investorer
- spørgsmål
- IT
- ITS
- KDnuggets
- Keen
- Kend
- viden
- kendt
- Mangel
- Leads
- elev
- læring
- Livet
- ligesom
- levetid
- Se
- Lot
- Lav
- maskine
- machine learning
- lave
- Making
- leder
- Marked
- Matrix
- Kan..
- midler
- måle
- måling
- medicinsk
- nævnte
- metoder
- Metrics
- måske
- model
- modeller
- penge
- mere
- Behov
- negativ
- Ny
- nu
- of
- on
- ONE
- kun
- Udtalelser
- or
- Andet
- Andre
- vores
- Resultat
- output
- samlet
- del
- især
- dele
- Mennesker
- udføre
- ydeevne
- Pharmaceutical
- fase
- Place
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- positiv
- potentiale
- brug
- Precision
- forudsagde
- forudsigelse
- Forudsigelser
- Forud
- sandsynlighed
- sandsynligvis
- Problem
- behandle
- Processer
- producere
- Produkt
- projekt
- passende
- korrekt
- giver
- leverer
- Skub ud
- Sats
- priser
- årsager
- reducere
- relevans
- relevant
- repræsenterer
- forskning
- Resultater
- regler
- s
- Gem
- scanning
- Videnskab
- Videnskabsmand
- søger
- deling
- Situationen
- færdigheder
- So
- nogle
- Nogen
- specifikke
- delt
- statistik
- Studere
- succes
- Succesfuld
- sådan
- RESUMÉ
- taktik
- Tag
- tager
- tech
- Teknisk
- prøve
- Test
- end
- at
- deres
- Disse
- denne
- grundigt
- Gennem
- tid
- til
- værktøjer
- behandling
- sand
- tutorials
- typisk
- ubetinget
- forstå
- forståelse
- us
- anvendte
- værdi
- række
- forskellige
- video
- Ur
- måder
- we
- GODT
- Hvad
- Hvad er
- hvorvidt
- som
- Mens
- WHO
- vilje
- villig
- ønsker
- med
- ord
- arbejder
- world
- ville
- forfatter
- skrivning
- dig
- Din
- zephyrnet