AWS Glue Studio er en grafisk grænseflade, der gør det nemt at oprette, køre og overvåge udtrække, transformere og indlæse (ETL) jobs i AWS Lim. Det giver dig mulighed for visuelt at sammensætte datatransformations-workflows ved hjælp af noder, der repræsenterer forskellige datahåndteringstrin, som senere konverteres automatisk til kode for at køre.
AWS Glue Studio For nylig udgivet 10 flere visuelle transformationer for at give mulighed for at skabe mere avancerede jobs på en visuel måde uden kodefærdigheder. I dette indlæg diskuterer vi potentielle anvendelsessager, der afspejler almindelige ETL-behov.
De nye transformationer, der vil blive demonstreret i dette indlæg, er: Sammenkædning, Split streng, Array til kolonner, Tilføj aktuelt tidsstempel, Pivot rækker til kolonner, Unpivot kolonner til rækker, Opslag, Eksploder matrix eller kortlægning i kolonner, Afledt kolonne og Autobalancebehandling .
Løsningsoversigt
I dette tilfælde har vi nogle JSON-filer med aktieoptionsoperationer. Vi ønsker at lave nogle transformationer, inden vi lagrer dataene for at gøre det nemmere at analysere, og vi ønsker også at lave et separat datasætresumé.
I dette datasæt repræsenterer hver række en handel med optionskontrakter. Optioner er finansielle instrumenter, der giver ret - men ikke pligt - til at købe eller sælge aktieaktier til en fast pris (kaldet strejke pris) før en defineret udløbsdato.
Indtast data
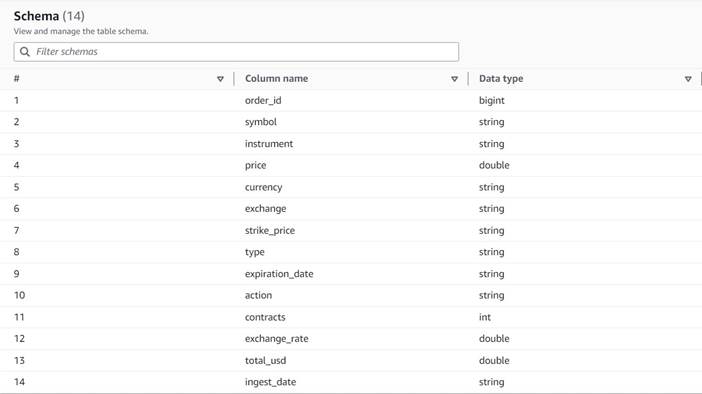
Dataene følger følgende skema:
- Ordre ID – Et unikt ID
- symbol – En kode, der generelt er baseret på nogle få bogstaver for at identificere det selskab, der udsender de underliggende aktieaktier
- instrument – Navnet, der identificerer den specifikke option, der købes eller sælges
- valuta – ISO-valutakoden, som prisen er udtrykt i
- pris – Det beløb, der blev betalt for købet af hver optionskontrakt (på de fleste børser giver én kontrakt dig mulighed for at købe eller sælge 100 aktieaktier)
- udveksling – Koden for det byttecenter eller det sted, hvor optionen blev handlet
- solgt – En liste over antallet af kontrakter, der blev tildelt til at udfylde salgsordren, når dette er en salgshandel
- købte – En liste over antallet af kontrakter, der er tildelt til at udfylde købsordre, når dette er købshandel
Følgende er et eksempel på de syntetiske data, der er genereret til dette indlæg:
ETL krav
Disse data har en række unikke egenskaber, som ofte findes på ældre systemer, der gør dataene sværere at bruge.
Følgende er ETL-kravene:
- Instrumentnavnet har værdifuld information, som er beregnet til at mennesker kan forstå; vi ønsker at normalisere det i separate kolonner for lettere analyse.
- Egenskaberne
bought,soldudelukker hinanden; vi kan konsolidere dem i en enkelt kolonne med kontraktnumrene og have en anden kolonne, der angiver, om kontrakterne er købt eller solgt i denne rækkefølge. - Vi ønsker at beholde oplysningerne om de individuelle kontrakttildelinger, men som individuelle rækker i stedet for at tvinge brugerne til at håndtere en række tal. Vi kunne lægge tallene sammen, men vi ville miste information om, hvordan ordren blev udfyldt (som indikerer markedslikviditet). I stedet vælger vi at denormalisere tabellen, så hver række har et enkelt antal kontrakter, og opdeler ordrer med flere tal i separate rækker. I et komprimeret søjleformat er den ekstra datasætstørrelse af denne gentagelse ofte lille, når komprimering anvendes, så det er acceptabelt at gøre datasættet nemmere at forespørge.
- Vi ønsker at generere en oversigtstabel over volumen for hver optiontype (call and put) for hver aktie. Dette giver en indikation af markedsstemningen for hver aktie og markedet generelt (grådighed vs. frygt).
- For at muliggøre overordnede handelsoversigter ønsker vi for hver operation at angive totalsummen og standardisere valutaen til amerikanske dollars ved hjælp af en omtrentlig konverteringsreference.
- Vi ønsker at tilføje datoen for, hvornår disse transformationer fandt sted. Dette kunne f.eks. være nyttigt for at have en reference til, hvornår valutaomregningen blev foretaget.
Baseret på disse krav vil jobbet producere to output:
- En CSV-fil med en oversigt over antallet af kontrakter for hvert symbol og type
- En katalogtabel til at holde en historik over ordren efter at have udført de angivne transformationer
Forudsætninger
Du skal bruge din egen S3-spand til at følge med i denne brugssag. For at oprette en ny spand, se Oprettelse af en spand.
Generer syntetiske data
For at følge med i dette indlæg (eller eksperimentere med denne slags data på egen hånd), kan du generere dette datasæt syntetisk. Følgende Python-script kan køres i et Python-miljø med Boto3 installeret og adgang til Amazon Simple Storage Service (Amazon S3).
For at generere data skal du udføre følgende trin:
- På AWS Glue Studio skal du oprette et nyt job med muligheden Python shell script editor.
- Giv jobbet et navn og på Joboplysninger fanen, skal du vælge en passende rolle og et navn til Python-scriptet.
- I Joboplysninger sektion, udvide Avancerede egenskaber og rul ned til Jobparametre.
- Indtast en parameter med navnet
--bucketog tildel som værdi navnet på den bøtte, du vil bruge til at gemme prøvedataene. - Indtast følgende script i AWS Glue shell-editoren:
- Kør jobbet, og vent, indtil det viser sig som fuldført på fanen Kørsler (det bør kun tage et par sekunder).
Hver kørsel genererer en JSON-fil med 1,000 rækker under den angivne bucket og præfikset transformsblog/inputdata/. Du kan køre jobbet flere gange, hvis du vil teste med flere inputfiler.
Hver linje i de syntetiske data er en datarække, der repræsenterer et JSON-objekt som følgende:
Opret AWS Glue visuelle job
For at oprette AWS Glue visuelle job skal du udføre følgende trin:
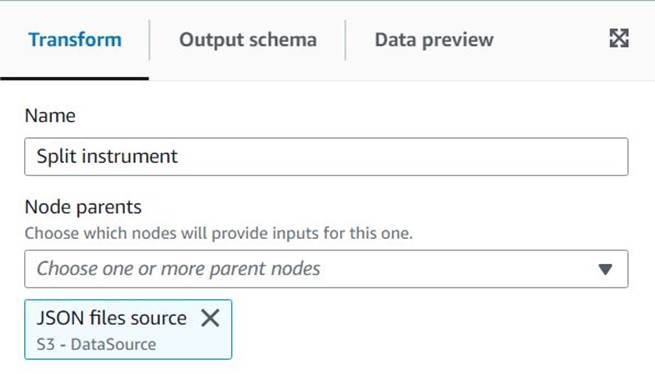
- Gå til AWS Glue Studio og opret et job ved hjælp af muligheden Visuel med et tomt lærred.
- Redigere
Untitled jobat give den et navn og tildele den en rolle, der passer til AWS Glue på den Joboplysninger fane. - Tilføj en S3-datakilde (du kan navngive den
JSON files source) og indtast den S3 URL, som filerne er gemt under (f.eks.s3://<your bucket name>/transformsblog/inputdata/), vælg derefter JSON som dataformat. - Type Udled skema så det indstiller output-skemaet baseret på dataene.
Fra denne kildenode vil du blive ved med at kæde transformationer. Når du tilføjer hver transformation, skal du sørge for, at den valgte node er den sidst tilføjede, så den bliver tildelt som forælder, medmindre andet er angivet i instruktionerne.
Hvis du ikke har valgt den rigtige forælder, kan du altid redigere forælderen ved at vælge den og vælge en anden forælder i konfigurationsruden.
For hver tilføjet node vil du give den et specifikt navn (så formålet med noden fremgår af grafen) og konfiguration på Transform fane.
Hver gang en transformation ændrer skemaet (f.eks. tilføje en ny kolonne), skal outputskemaet opdateres, så det er synligt for nedstrømstransformationerne. Du kan redigere outputskemaet manuelt, men det er mere praktisk og sikrere at gøre det ved at bruge dataeksemplet.
Derudover kan du på den måde bekræfte, at transformationen fungerer så langt som forventet. For at gøre det skal du åbne Eksempel på data fanen med transformationen valgt og start en forhåndsvisningssession. Når du har bekræftet, at de transformerede data ser ud som forventet, skal du gå til Output skema fanebladet og vælg Brug dataeksempelskema for at opdatere skemaet automatisk.
Når du tilføjer nye former for transformationer, viser forhåndsvisningen muligvis en meddelelse om en manglende afhængighed. Når dette sker, skal du vælge Afslut session og start en ny, så forhåndsvisningen opfanger den nye slags node.
Udtræk instrumentoplysninger
Lad os starte med at behandle oplysningerne om instrumentnavnet for at normalisere det til kolonner, der er lettere at få adgang til i den resulterende outputtabel.
- Føj til Split streng node og navngiv den
Split instrument, som vil tokenisere instrumentkolonnen ved hjælp af et blanktegnsregex:s+(et enkelt rum ville gøre det i dette tilfælde, men denne måde er mere fleksibel og visuelt klarere). - Vi ønsker at beholde den originale instrumentinformation, som den er, så indtast et nyt kolonnenavn for det opdelte array:
instrument_arr.
- Tilføj en Array til kolonner node og navngiv den
Instrument columnsat konvertere den array-kolonne, der netop er oprettet, til nye felter, undtagensymbol, som vi allerede har en kolonne til. - Vælg kolonnen
instrument_arr, spring det første token over og bed det om at udtrække outputkolonnernemonth, day, year, strike_price, typeved hjælp af indekser2, 3, 4, 5, 6(mellemrummene efter kommaerne er for læsbarheden, de påvirker ikke konfigurationen).
Det udtrukne år er kun udtrykt med to cifre; lad os sætte en stop for at antage, at det er i dette århundrede, hvis de bare bruger to cifre.
- Føj til Afledt kolonne node og navngiv den
Four digits year. - Indtast
yearsom den afledte kolonne, så den tilsidesætter den, og indtast følgende SQL-udtryk:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
For nemheds skyld bygger vi en expiration_date felt, som en bruger kan have som reference for den sidste dato, optionen kan udnyttes.
- Føj til Sammenkæd kolonner node og navngiv den
Build expiration date. - Navngiv den nye kolonne
expiration_date, vælg kolonnerneyear,monthogday(i nævnte rækkefølge), og en bindestreg som spacer.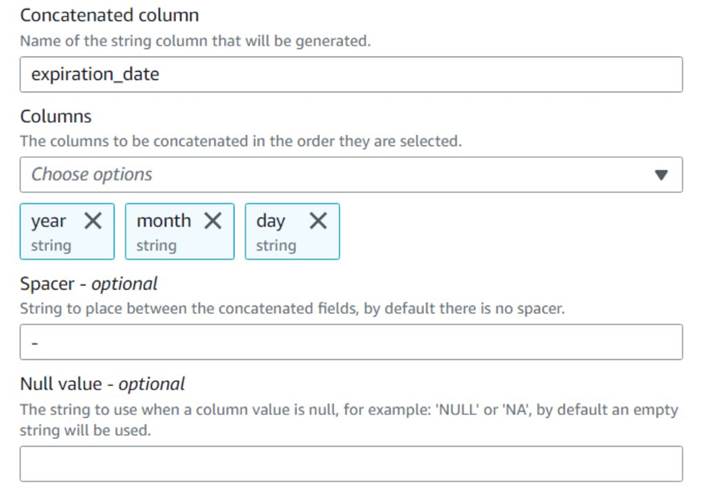
Diagrammet skal indtil videre se ud som det følgende eksempel.
![]()
Dataforhåndsvisningen af de nye kolonner indtil videre skulle se ud som følgende skærmbillede.
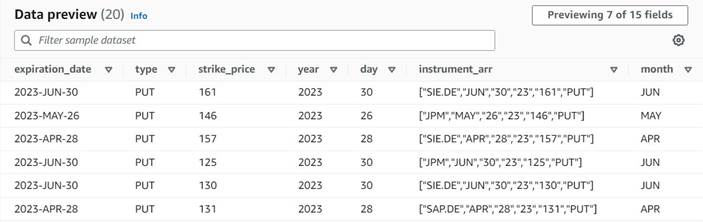
Normaliser antallet af kontrakter
Hver af rækkerne i dataene angiver antallet af kontrakter for hver option, der blev købt eller solgt, og de partier, hvor ordrerne blev udfyldt. Uden at miste informationen om de enkelte batches, ønsker vi at have hvert beløb på en individuel række med en enkelt mængdeværdi, mens resten af informationen replikeres i hver produceret række.
Lad os først flette beløbene i en enkelt kolonne.
- Tilføj en Ophæv pivot kolonner i rækker node og navngiv den
Unpivot actions. - Vælg kolonnerne
bought,soldat deaktivere og gemme navnene og værdierne i navngivne kolonneraction,contracts, henholdsvis.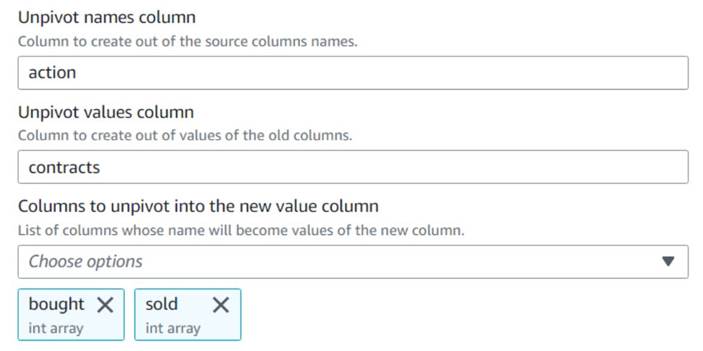
Bemærk i forhåndsvisningen, at den nye kolonnecontractser stadig en række af tal efter denne transformation.
- Tilføj en Eksploder array eller kort i rækker række navngivet
Explode contracts. - Vælg den
contractskolonne og indtastcontractssom den nye kolonne for at tilsidesætte den (vi behøver ikke at beholde det originale array).
Forhåndsvisningen viser nu, at hver række har en enkelt contracts beløb, og resten af felterne er de samme.
Det betyder også det order_id er ikke længere en unik nøgle. Til dine egne brugstilfælde skal du beslutte, hvordan du modellerer dine data, og om du vil denormalisere eller ej.
Følgende skærmbillede er et eksempel på, hvordan de nye kolonner ser ud efter transformationerne indtil videre.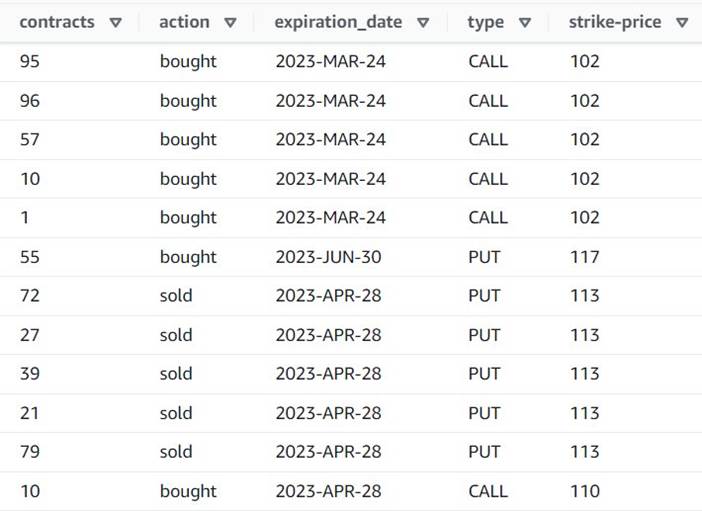
Opret en oversigtstabel
Nu opretter du en oversigtstabel med antallet af handlede kontrakter for hver type og hvert aktiesymbol.
Lad os for illustrationsøjemed antage, at de behandlede filer tilhører en enkelt dag, så denne oversigt giver forretningsbrugerne information om, hvad markedsinteressen og stemningen er den dag.
- Føj til Vælg felter node og vælg følgende kolonner for at beholde til oversigten:
symbol,typeogcontracts.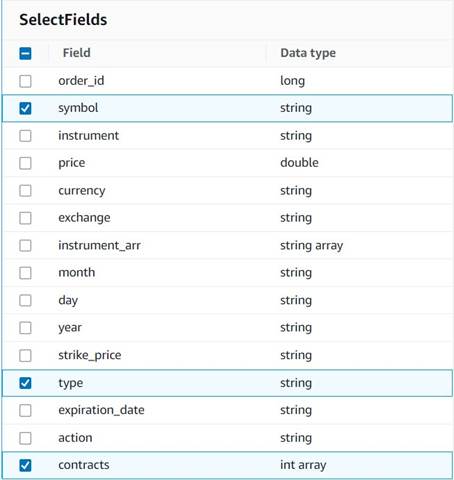
- Føj til Drej rækker til kolonner node og navngiv den
Pivot summary. - Saml på
contractskolonne ved hjælp afsumog vælg at konverteretypekolonne.
Normalt ville du gemme det på en ekstern database eller fil til reference; i dette eksempel gemmer vi den som en CSV-fil på Amazon S3.
- Tilføj en Autobalancebehandling node og navngiv den
Single output file. - Selvom denne transformationstype normalt bruges til at optimere paralleliteten, bruger vi den her til at reducere outputtet til en enkelt fil. Indtast derfor
1i antallet af partitioner konfiguration.
- Tilføj et S3-mål og navngiv det
CSV Contract summary. - Vælg CSV som dataformat, og indtast en S3-sti, hvor jobrollen har tilladelse til at gemme filer.
Den sidste del af jobbet skulle nu se ud som det følgende eksempel.![]()
- Gem og kør jobbet. Brug Kører fanen for at kontrollere, hvornår det er afsluttet.
Du finder en fil under den sti, der er en CSV, på trods af at den ikke har den udvidelse. Du skal sandsynligvis tilføje udvidelsen efter at have downloadet den for at åbne den.
På et værktøj, der kan læse CSV'en, skal resuméet ligne det følgende eksempel.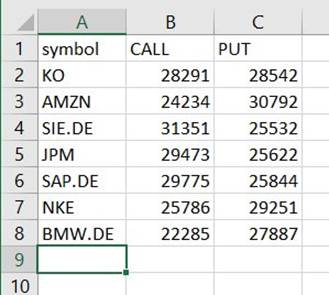
Ryd op i midlertidige kolonner
Som forberedelse til at gemme ordrerne i en historisk tabel til fremtidig analyse, lad os rydde op i nogle midlertidige kolonner, der er oprettet undervejs.
- Føj til Drop felter node med
Explode contractsnode valgt som sin overordnede (vi forgrener datapipelinen for at generere et separat output). - Vælg de felter, der skal slettes:
instrument_arr,month,dayogyear.
Resten ønsker vi at beholde, så de gemmes i den historiske tabel, vi opretter senere.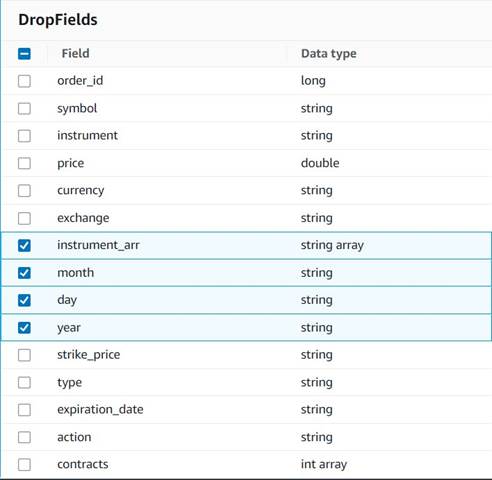
Standardisering af valuta
Disse syntetiske data indeholder fiktive operationer på to valutaer, men i et rigtigt system kan du få valutaer fra markeder over hele verden. Det er nyttigt at standardisere de håndterede valutaer til en enkelt referencevaluta, så de nemt kan sammenlignes og aggregeres til rapportering og analyse.
Vi anvender Amazonas Athena at simulere en tabel med omtrentlige valutaomregninger, der bliver opdateret med jævne mellemrum (her antager vi, at vi behandler ordrerne rettidigt nok til, at omregningen er en rimelig repræsentant til sammenligningsformål).
- Åbn Athena-konsollen i det samme område, hvor du bruger AWS Glue.
- Kør følgende forespørgsel for at oprette tabellen ved at indstille en S3-placering, hvor både dine Athena- og AWS Glue-roller kan læse og skrive. Du vil måske også gerne gemme tabellen i en anden database end
default(hvis du gør det, skal du opdatere det tabelkvalificerede navn i overensstemmelse hermed i de angivne eksempler). - Indtast et par eksempler på konverteringer i tabellen:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - Du skulle nu være i stand til at se tabellen med følgende forespørgsel:
SELECT * FROM default.exchange_rates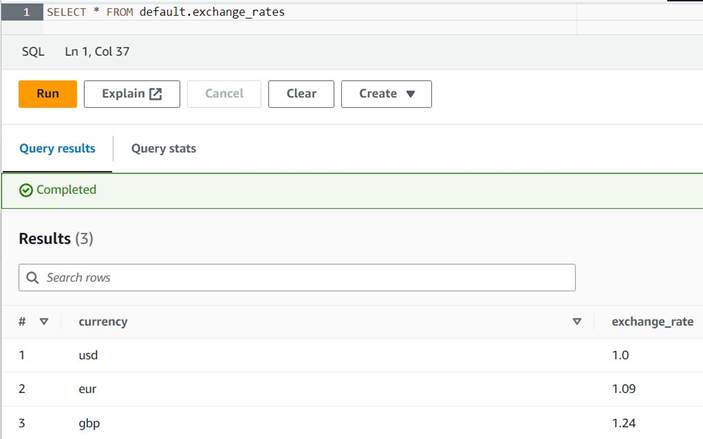
- Tilbage på AWS Glue visuelle job, tilføje en Opslag node (som et barn af
Drop Fields) og navngiv detExchange rate. - Indtast det kvalificerede navn på den tabel, du lige har oprettet, vha
currencysom tasten og vælgexchange_ratefelt at bruge.
Fordi feltet hedder det samme i både data og opslagstabellen, kan vi bare indtaste navnetcurrencyog behøver ikke at definere en kortlægning.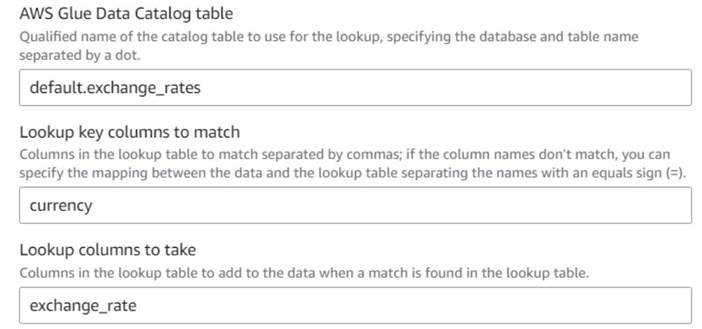
På tidspunktet for skrivningen understøttes Lookup-transformationen ikke i dataeksemplet, og det vil vise en fejl om, at tabellen ikke eksisterer. Dette er kun til forhåndsvisning af data og forhindrer ikke jobbet i at køre korrekt. De få resterende trin i indlægget kræver ikke, at du opdaterer skemaet. Hvis du har brug for at køre et dataeksempel på andre noder, kan du fjerne opslagsknuden midlertidigt og derefter sætte den tilbage. - Føj til Afledt kolonne node og navngiv den
Total in usd. - Navngiv den afledte kolonne
total_usdog brug følgende SQL-udtryk:round(contracts * price * exchange_rate, 2)
- Føj til Tilføj aktuelt tidsstempel node og navngiv kolonnen
ingest_date. - Brug formatet
%Y-%m-%dtil dit tidsstempel (til demonstrationsformål bruger vi blot datoen; du kan gøre det mere præcist, hvis du vil).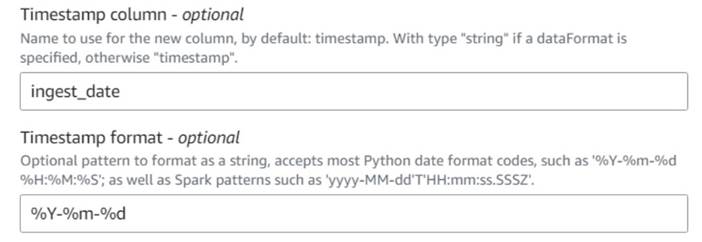
Gem tabellen over historiske ordrer
Udfør følgende trin for at gemme tabellen over historiske ordrer:
- Tilføj en S3-målknude, og navngiv den
Orders table. - Konfigurer Parket-format med hurtig komprimering, og giv en S3-målsti, hvorunder resultaterne kan lagres (adskilt fra oversigten).
- Type Opret en tabel i datakataloget og ved efterfølgende kørsler, opdater skemaet og tilføj nye partitioner.
- Indtast en måldatabase og et navn til den nye tabel, for eksempel:
option_orders.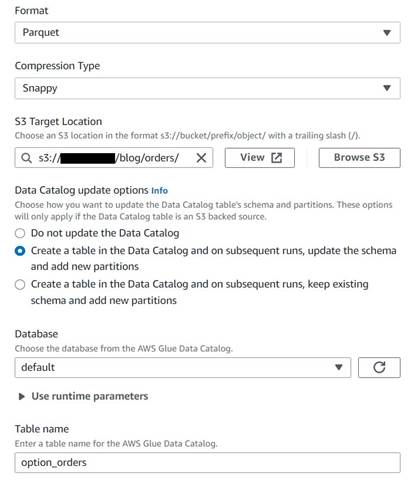
Den sidste del af diagrammet skulle nu ligne følgende, med to forgreninger til de to separate udgange.![]()
Når du har kørt jobbet med succes, kan du bruge et værktøj som Athena til at gennemgå de data, jobbet har produceret, ved at forespørge i den nye tabel. Du kan finde bordet på Athena-listen og vælge Eksempeltabel eller bare kør en SELECT-forespørgsel (ved at opdatere tabelnavnet til det navn og katalog, du brugte):
SELECT * FROM default.option_orders limit 10
Dit tabelindhold skal ligne det følgende skærmbillede.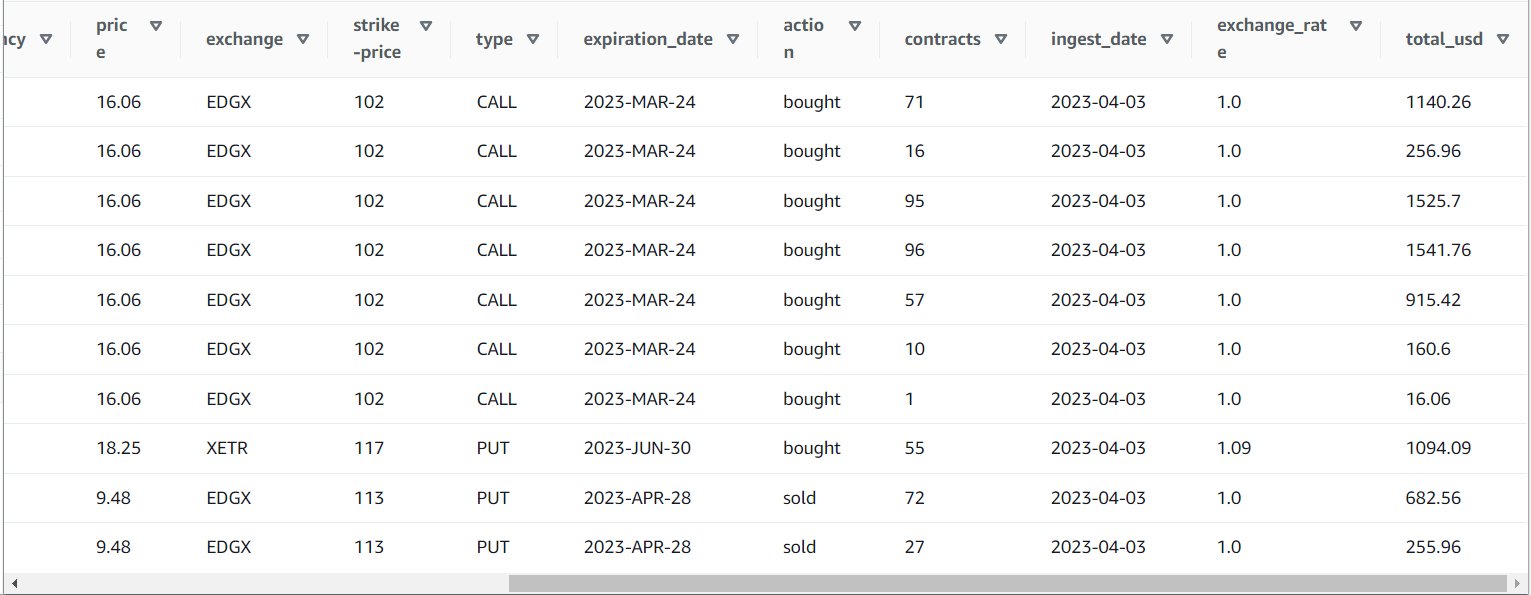
Ryd op
Hvis du ikke vil beholde dette eksempel, skal du slette de to job, du oprettede, de to tabeller i Athena og S3-stierne, hvor input- og outputfilerne blev gemt.
Konklusion
I dette indlæg viste vi, hvordan de nye transformationer i AWS Glue Studio kan hjælpe dig med at lave mere avanceret transformation med minimal konfiguration. Dette betyder, at du kan implementere flere ETL-brugssager uden at skulle skrive og vedligeholde nogen kode. De nye transformationer er allerede tilgængelige på AWS Glue Studio, så du kan bruge de nye transformationer i dag i dine visuelle job.
Om forfatteren
![]() Gonzalo herreros er Senior Big Data Architect på AWS Glue-teamet.
Gonzalo herreros er Senior Big Data Architect på AWS Glue-teamet.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Køb og sælg aktier i PRE-IPO-virksomheder med PREIPO®. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :har
- :er
- :ikke
- :hvor
- $OP
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15 %
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- I stand
- Om
- acceptabel
- adgang
- derfor
- tilføje
- tilføjet
- tilføje
- fremskreden
- Efter
- Alle
- allokeret
- tildelinger
- tillade
- tillader
- sammen
- allerede
- også
- altid
- Amazon
- beløb
- beløb
- an
- analyse
- analysere
- ,
- En anden
- enhver
- anvendt
- omtrentlig
- april
- ER
- argument
- Array
- AS
- tildelt
- At
- attributter
- automatisk
- til rådighed
- AWS
- AWS Lim
- tilbage
- baseret
- BE
- før
- være
- Big
- Big data
- blank
- BMW
- både
- købte
- grene
- bygge
- virksomhed
- men
- købe
- by
- ringe
- CAN
- tilfælde
- tilfælde
- katalog
- center
- Århundrede
- Ændringer
- karakteristika
- kontrollere
- barn
- Vælg
- vælge
- klarere
- kode
- Kodning
- Kolonne
- Kolonner
- Fælles
- sammenlignet
- sammenligning
- fuldføre
- Afsluttet
- Konfiguration
- Konsol
- konsolidere
- indeholder
- indhold
- kontrakt
- kontrakter
- bekvemmelighed
- Konvertering
- konverteringer
- konvertere
- konverteret
- VIRKSOMHED
- kunne
- skabe
- oprettet
- Oprettelse af
- valutaer
- Valuta
- Nuværende
- DAG
- data
- Database
- Dato
- Datoer
- dato tid
- dag
- deal
- beskæftiger
- beslutte
- Standard
- definerede
- demonstreret
- Afhængighed
- Afledt
- Trods
- detaljer
- forskellige
- cifre
- diskutere
- do
- Er ikke
- gør
- dollars
- Dont
- fordoble
- ned
- Drop
- droppet
- hver
- lettere
- nemt
- let
- editor
- muliggøre
- nok
- Indtast
- Miljø
- fejl
- Ether (ETH)
- EUR
- eksempel
- eksempler
- Undtagen
- udveksling
- Udvekslinger
- Eksklusiv
- eksisterer
- Udvid
- forventet
- eksperiment
- udløb
- udtrykt
- udvidelse
- ekstern
- ekstra
- ekstrakt
- langt
- frygt
- få
- fiktive
- felt
- Fields
- File (Felt)
- Filer
- udfylde
- fyldt
- finansielle
- Finansielle instrumenter
- Finde
- Fornavn
- fast
- fleksibel
- følger
- efter
- følger
- Til
- format
- fundet
- fra
- fremtiden
- GBP
- Generelt
- generelt
- generere
- genereret
- få
- Giv
- giver
- Go
- graf
- Grådighed
- Håndtering
- sker
- Have
- have
- hjælpe
- link.
- historisk
- historie
- Hvordan
- How To
- HTML
- http
- HTTPS
- Mennesker
- i
- identificerer
- identificere
- if
- KIMOs Succeshistorier
- gennemføre
- importere
- in
- indekser
- angivet
- angiver
- angiver
- tegn
- individuel
- oplysninger
- indgang
- instans
- i stedet
- anvisninger
- instrument
- instrumenter
- interesse
- grænseflade
- ind
- ISO
- IT
- ITS
- Job
- Karriere
- jpg
- json
- lige
- Holde
- Nøgle
- Venlig
- Efternavn
- senere
- ligesom
- GRÆNSE
- Line (linje)
- Likviditet
- Liste
- belastning
- placering
- længere
- Se
- ligner
- UDSEENDE
- kig op
- taber
- miste
- lavet
- vedligeholde
- lave
- maerker
- manuelt
- kort
- kortlægning
- Marked
- markedstemning
- Markeder
- Kan..
- midler
- Flet
- besked
- måske
- minimum
- mangler
- model
- Overvåg
- mere
- mest
- flere
- gensidigt
- navn
- Som hedder
- navne
- Behov
- behov
- Ny
- ingen
- node
- noder
- Normalt
- nu
- nummer
- numre
- objekt
- of
- tit
- on
- ONE
- kun
- åbent
- drift
- Produktion
- Optimer
- Option
- Indstillinger
- or
- ordrer
- ordrer
- original
- Andet
- Ellers
- output
- i løbet af
- samlet
- overstyring
- egen
- betalt
- brød
- parameter
- del
- sti
- picks
- pipeline
- Pivot
- Place
- plato
- Platon Data Intelligence
- PlatoData
- Indlæg
- potentiale
- Praktisk
- brug
- forhindre
- Eksempel
- pris
- sandsynligvis
- behandle
- forarbejdning
- producere
- produceret
- give
- forudsat
- giver
- køb
- formål
- formål
- sætte
- Python
- kvalificeret
- rejse
- tilfældig
- Læs
- ægte
- rimelige
- reducere
- afspejler
- region
- resterende
- Fjern
- replikeres
- Rapportering
- repræsentere
- repræsentativt
- repræsenterer
- repræsenterer
- kræver
- Krav
- Kræver
- henholdsvis
- REST
- resulterer
- Resultater
- gennemgå
- roller
- roller
- RÆKKE
- Kør
- kører
- sikrere
- samme
- sap
- Gem
- besparelse
- rulle
- sekunder
- valgt
- udvælgelse
- sælger
- senior
- stemningen
- adskille
- Session
- sæt
- indstilling
- Aktier
- Shell
- bør
- Vis
- Shows
- lignende
- Simpelt
- enkelt
- Størrelse
- færdigheder
- lille
- So
- indtil nu
- solgt
- nogle
- noget
- Kilde
- Space
- rum
- specifikke
- specificeret
- delt
- regneark
- SQL
- starte
- Steps
- Stadig
- bestand
- opbevaring
- butik
- opbevaret
- String
- Studio
- efterfølgende
- Succesfuld
- egnede
- RESUMÉ
- Understøttet
- symbol
- syntetisk
- syntetiske data
- syntetisk
- systemet
- Systemer
- bord
- Tag
- mål
- hold
- fortælle
- midlertidig
- ti
- prøve
- end
- at
- Grafen
- oplysninger
- verdenen
- Them
- derefter
- derfor
- Disse
- de
- denne
- dem
- tid
- gange
- tidsstempel
- til
- i dag
- token
- tokenisere
- tog
- værktøj
- I alt
- handle
- handles
- Transform
- Transformation
- transformationer
- omdannet
- to
- typen
- under
- underliggende
- forstå
- enestående
- indtil
- Opdatering
- opdateret
- opdatering
- URL
- us
- US Dollars
- USD
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- ved brug af
- Værdifuld
- Værdifuld information
- værdi
- Værdier
- Venue
- verificeres
- verificere
- Specifikation
- synlig
- bind
- vs
- vente
- ønsker
- var
- Vej..
- we
- var
- Hvad
- hvornår
- som
- mens
- vilje
- med
- uden
- arbejdsgange
- arbejder
- world
- ville
- skriver
- skrivning
- år
- dig
- Din
- zephyrnet











