
Billede lavet med DALL-E3
Kunstig intelligens har været en komplet revolution i den teknologiske verden.
Dens evne til at efterligne menneskelig intelligens og udføre opgaver, der engang blev betragtet som udelukkende menneskelige domæner, forbløffer stadig de fleste af os.
Men uanset hvor gode disse sene AI-spring fremad har været, er der altid plads til forbedringer.
Og det er netop her, hurtig ingeniørarbejde starter!
Indtast dette felt, der kan forbedre produktiviteten af AI-modeller markant.
Lad os opdage det hele sammen!
Prompt engineering er et hurtigt voksende domæne inden for AI, der fokuserer på at forbedre effektiviteten og effektiviteten af sprogmodeller. Det handler om at lave perfekte prompter til at guide AI-modeller til at producere vores ønskede output.
Tænk på det som at lære at give bedre instruktioner til nogen for at sikre, at de forstår og udfører en opgave korrekt.
Hvorfor prompt ingeniørarbejde betyder noget
- Forbedret produktivitet: Ved at bruge prompter af høj kvalitet kan AI-modeller generere mere nøjagtige og relevante svar. Dette betyder mindre tid brugt på rettelser og mere tid på at udnytte AI's muligheder.
- Omkostningseffektivitet: Træning af AI-modeller er ressourcekrævende. Hurtig konstruktion kan reducere behovet for omskoling ved at optimere modellens ydeevne gennem bedre prompter.
- Alsidighed: En veludformet prompt kan gøre AI-modeller mere alsidige, så de kan tackle en bredere række af opgaver og udfordringer.
Før vi dykker ned i de mest avancerede teknikker, lad os huske to af de mest nyttige (og grundlæggende) hurtige ingeniørteknikker.
Sekventiel tænkning med "Lad os tænke trin for trin"
I dag er det velkendt, at LLM-modellers nøjagtighed er væsentligt forbedret, når man tilføjer ordsekvensen "Lad os tænke trin for trin".
Hvorfor… spørger du måske?
Nå, det skyldes, at vi tvinger modellen til at opdele enhver opgave i flere trin, og dermed sikre, at modellen har nok tid til at behandle hver af dem.
For eksempel kunne jeg udfordre GPT3.5 med følgende prompt:
Hvis John har 5 pærer, så spiser 2, køber 5 mere og giver så 3 til sin ven, hvor mange pærer har han?
Modellen vil give mig et svar med det samme. Men hvis jeg tilføjer det sidste "Lad os tænke trin for trin", tvinger jeg modellen til at generere en tankeproces med flere trin.
Få skud tilskyndet
Mens Zero-shot prompten refererer til at bede modellen om at udføre en opgave uden at give nogen kontekst eller forudgående viden, indebærer få-shot promptteknikken, at vi præsenterer LLM med et par eksempler på vores ønskede output sammen med et specifikt spørgsmål.
For eksempel, hvis vi ønsker at komme med en model, der definerer ethvert udtryk ved hjælp af en poetisk tone, kan det være ret svært at forklare. Højre?
Vi kunne dog bruge følgende få-shot prompts til at styre modellen i den retning, vi ønsker.
Din opgave er at svare i en konsistent stil tilpasset følgende stil.
: Lær mig om robusthed.
: Modstandsdygtighed er som et træ, der bøjer sig med vinden, men aldrig knækker.
Det er evnen til at komme tilbage fra modgang og blive ved med at bevæge sig fremad.
: Dit input her.
Hvis du ikke har prøvet det endnu, kan du udfordre GPT.
Men da jeg er ret sikker på, at de fleste af jer allerede kender disse grundlæggende teknikker, vil jeg prøve at udfordre jer med nogle avancerede teknikker.
1. Chain of Thought (CoT)-anmodning
Indført af Google i 2022, involverer denne metode at instruere modellen i at gennemgå flere ræsonnementfaser, før den leverer det ultimative svar.
Lyder bekendt ikke? Hvis ja, har du fuldstændig ret.
Det er som at fusionere både Sequential Thinking og Few-Shot Prompting.
Hvordan?
I det væsentlige dirigerer CoT-anmodning LLM til at behandle information sekventielt. Det betyder, at vi eksemplificerer, hvordan man løser et første problem med flere trins-ræsonnementer og derefter sender vores egentlige opgave til modellen, idet vi forventer, at den efterligner en sammenlignelig tankekæde, når vi svarer på den faktiske forespørgsel, vi ønsker, at den skal løse.
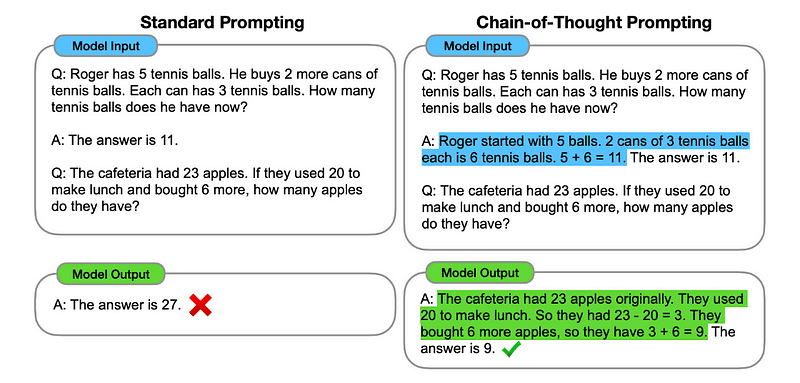
Billede taget fra papir.
Så efter det allerførste eksempel kunne vi give en prompt med det første problem og en sekventiel forklaring på, hvordan det løses. Så kan vi sende vores input og se, hvordan magien sker!
Hvis John har 5 pærer, så spiser 2, køber 5 mere og giver så 3 til sin ven, hvor mange pærer har han? Lad os tænke trin for trin.
Lad os gå skridt for skridt. John starter med 5 pærer. Han spiser 2 pærer, så han har 5–2 = 3 pærer tilbage. Så køber han 5 pærer mere. Så han har nu 3 + 5 = 8 pærer. Til sidst giver han 3 pærer til sin ven. Derfor har han 8–3 = 5 pærer tilbage. Så efter alle disse trin har John 5 pærer.
Dit input her.
De fleste af jer må dog tænke... Skal jeg tænke på en sekventiel måde at løse et problem på, hver gang jeg vil spørge om noget på ChatGPT?
Nå... du er ikke den første! Og det fører os til...
2. Automatisk Chain-of-Thought (Auto-CoT)
I 2022, blev Zhang og kolleger introducerede en metode til at undgå denne manuelle proces. Der er to hovedårsager til at undgå enhver manuel opgave:
- Det kan være kedeligt.
- Det kan give dårlige resultater – for eksempel når vores mentale proces er forkert.
De foreslog at bruge LLM'er kombineret med "Lad os tænke trin for trin"-prompten for sekventielt at producere begrundelseskæder for hver demonstration.
Det betyder, at man spørger ChatGPT, hvordan man løser ethvert problem sekventielt og derefter bruger det samme eksempel til at træne det, hvordan man løser ethvert andet problem.
3. Selvkonsistens
Selvkonsistens er en anden interessant tilskyndelsesteknik, der har til formål at forbedre tankekæden, der tilskynder til mere komplekse ræsonnementproblemer.
Så ... hvad er den største forskel?
Hovedideen under Self-Consistency er at være opmærksom på, at vi kan træne modellen med et forkert eksempel. Forestil dig, at jeg løser det forrige problem med en forkert mental proces:
Hvis John har 5 pærer, så spiser 2, køber 5 mere og giver så 3 til sin ven, hvor mange pærer har han? Lad os tænke trin for trin.
Start med 5 pærer. John spiser 2 pærer. Derefter giver han 3 pærer til sin ven. Disse handlinger kan kombineres: 2 (spist) + 3 (givet) = 5 pærer i alt påvirket. Træk nu det samlede antal påvirkede pærer fra de første 5 pærer: 5 (indledende) – 5 (påvirkede) = 0 pærer tilbage.
Så vil enhver anden opgave, jeg sender til modellen, være forkert.
Dette er grunden til, at Self-Consistency involverer stikprøver fra forskellige ræsonnementer, hver af dem indeholder en tankekæde, og derefter lade LLM vælge den bedste og mest konsekvente vej til at løse problemet.
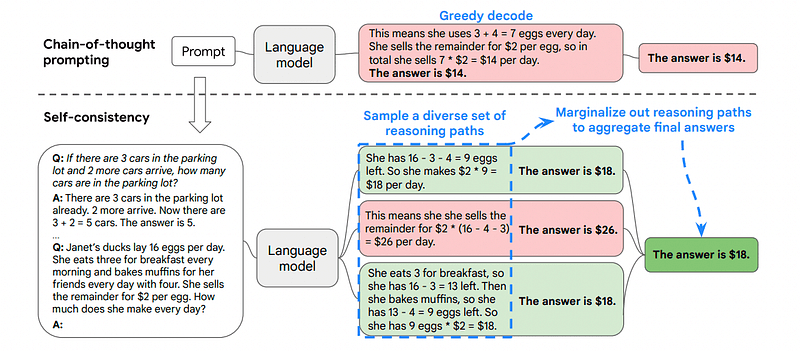
Billede taget fra papir
I dette tilfælde, og efter det allerførste eksempel igen, kan vi vise modellen forskellige måder at løse problemet på.
Hvis John har 5 pærer, så spiser 2, køber 5 mere og giver så 3 til sin ven, hvor mange pærer har han?
Start med 5 pærer. John spiser 2 pærer og efterlader ham med 5-2 = 3 pærer. Han køber 5 pærer mere, hvilket bringer totalen op på 3 + 5 = 8 pærer. Til sidst giver han 3 pærer til sin ven, så han har 8–3 = 5 pærer tilbage.
Hvis John har 5 pærer, så spiser 2, køber 5 mere og giver så 3 til sin ven, hvor mange pærer har han?
Start med 5 pærer. Så køber han 5 pærer mere. John spiser 2 pærer nu. Disse handlinger kan kombineres: 2 (spist) + 5 (købt) = 7 pærer i alt. Træk den pære, Jon har spist, fra den samlede mængde pærer 7 (samlet mængde) – 2 (spist) = 5 pærer tilbage.
Dit input her.
Og her kommer den sidste teknik.
4. Generel vidensspørgsmål
En almindelig praksis for prompt engineering er at udvide en forespørgsel med yderligere viden, før du sender det endelige API-kald til GPT-3 eller GPT-4.
Ifølge Jiacheng Liu og Co, vi kan altid tilføje noget viden til enhver anmodning, så LLM ved bedre om spørgsmålet.
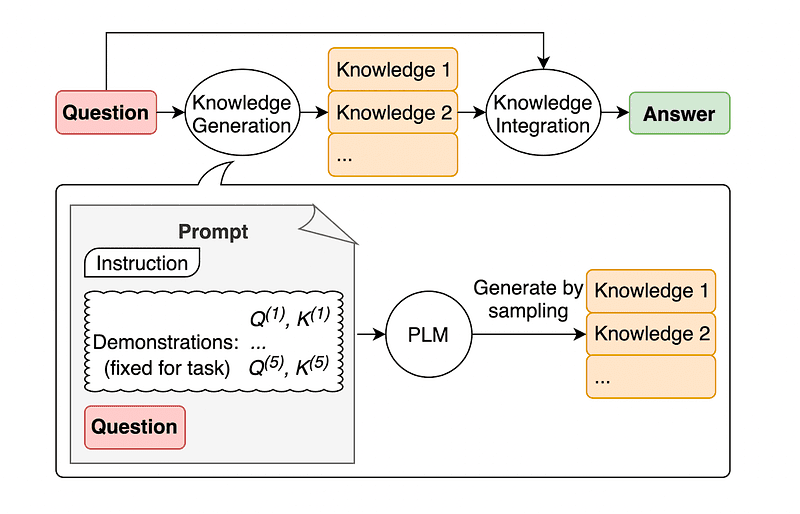
Billede taget fra papir.
Så når du for eksempel spørger ChatGPT, om en del af golf forsøger at få et højere pointtotal end andre, vil det validere os. Men hovedmålet med golf er det modsatte. Dette er grunden til, at vi kan tilføje noget tidligere viden og fortælle det "Spilleren med den laveste score vinder".

Så .. hvad er det sjove, hvis vi fortæller modellen præcis svaret?
I dette tilfælde bruges denne teknik til at forbedre måden, LLM interagerer med os på.
Så i stedet for at trække supplerende kontekst fra en ekstern database, anbefaler papirets forfattere, at LLM producerer sin egen viden. Denne selvgenererede viden integreres derefter i prompten for at styrke sund fornuft og give bedre resultater.
Så det er sådan LLM'er kan forbedres uden at øge dets træningsdatasæt!
Hurtig ingeniørarbejde er dukket op som en afgørende teknik til at forbedre LLM's muligheder. Ved at gentage og forbedre prompter kan vi kommunikere på en mere direkte måde til AI-modeller og dermed opnå mere præcise og kontekstuelt relevante output, hvilket sparer både tid og ressourcer.
For både teknologientusiaster, dataforskere og indholdsskabere kan forståelse og beherskelse af prompt engineering være et værdifuldt aktiv i at udnytte det fulde potentiale af AI.
Ved at kombinere omhyggeligt designede input-prompter med disse mere avancerede teknikker vil det uden tvivl give dig et forspring i de kommende år, hvis du har færdigheder inden for hurtig ingeniørarbejde.
Josep Ferrer er en analyseingeniør fra Barcelona. Han er uddannet i fysikingeniør og arbejder i øjeblikket inden for datavidenskab, der anvendes på menneskelig mobilitet. Han er en deltidsindholdsskaber med fokus på datavidenskab og teknologi. Du kan kontakte ham på LinkedIn, Twitter or Medium.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :har
- :er
- :ikke
- :hvor
- $OP
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- evne
- Om
- nøjagtighed
- præcis
- aktioner
- faktiske
- tilføje
- tilføje
- Yderligere
- fremskreden
- Efter
- igen
- AI
- AI modeller
- målsætninger
- justeret
- ens
- Alle
- tillade
- sammen
- allerede
- altid
- am
- beløb
- an
- analytics
- ,
- En anden
- besvare
- enhver
- api
- anvendt
- ER
- AS
- spørg
- spørge
- aktiv
- forfattere
- Automatisk Ur
- undgå
- opmærksom på
- væk
- tilbage
- Bad
- Barcelona
- grundlæggende
- BE
- fordi
- været
- før
- være
- BEDSTE
- Bedre
- styrke
- boost
- Boring
- både
- købte
- Bounce
- Pause
- pauser
- Bringer
- bredere
- men
- Buys
- by
- ringe
- CAN
- kapaciteter
- omhyggeligt
- tilfælde
- kæde
- kæder
- udfordre
- udfordringer
- ChatGPT
- Vælg
- kolleger
- kombineret
- kombinerer
- Kom
- kommer
- kommer
- Fælles
- kommunikere
- sammenlignelig
- fuldføre
- komplekse
- betragtes
- konsekvent
- kontakt
- indhold
- indhold skabere
- sammenhæng
- Rettelser
- korrekt
- kunne
- oprettet
- skaberen
- skabere
- For øjeblikket
- data
- datalogi
- Database
- definerer
- leverer
- konstrueret
- ønskes
- forskel
- forskellige
- direkte
- retning
- opdage
- dykning
- do
- gør
- domæne
- Domæner
- ned
- hver
- Edge
- effektivitet
- effektivitet
- opstået
- ingeniør
- Engineering
- forbedre
- styrke
- nok
- sikre
- entusiaster
- præcist nok
- eksempel
- eksempler
- udføre
- forventer
- Forklar
- forklaring
- bekendt
- få
- felt
- endelige
- Endelig
- Fornavn
- fokuserede
- fokuserer
- efter
- Til
- tvinger
- Videresend
- ven
- fra
- fuld
- sjovt
- Generelt
- generere
- få
- Giv
- given
- giver
- Go
- mål
- golf
- godt
- vejlede
- Hård Ost
- udnyttelse
- Have
- have
- he
- link.
- høj kvalitet
- højere
- ham
- hans
- Hvordan
- How To
- Men
- HTTPS
- menneskelig
- menneskelig intelligens
- i
- idé
- if
- billede
- Forbedre
- forbedret
- forbedring
- in
- stigende
- oplysninger
- initial
- indgang
- instans
- anvisninger
- integreret
- Intelligens
- interagerer
- interessant
- ind
- introduceret
- involverer
- IT
- ITS
- John
- jon
- lige
- KDnuggets
- Holde
- sparke
- Kicks
- Kend
- viden
- kender
- Sprog
- Efternavn
- Sent
- Leads
- Leap
- læring
- forlader
- til venstre
- mindre
- lad
- udlejning
- løftestang
- ligesom
- lavere
- Magic
- Main
- lave
- Making
- måde
- manuel
- mange
- mastering
- Matter
- me
- midler
- mentale
- sammenlægning
- metode
- måske
- mobilitet
- model
- modeller
- mere
- mest
- flytning
- flere
- skal
- Behov
- aldrig
- ingen
- nu
- opnå
- of
- on
- engang
- modsat
- optimering
- or
- Andet
- Andre
- vores
- ud
- output
- udgange
- uden for
- egen
- Papir
- del
- sti
- perfekt
- udføre
- ydeevne
- Fysik
- afgørende
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Punkt
- potentiale
- praksis
- præcist
- præsentere
- smuk
- tidligere
- Problem
- problemer
- behandle
- producere
- produktivitet
- give
- leverer
- trækker
- spørgsmål
- helt
- rækkevidde
- hellere
- ægte
- årsager
- anbefaler
- reducere
- refererer
- relevant
- anmode
- modstandskraft
- ressourceintensive
- Ressourcer
- reagere
- svar
- reaktioner
- Resultater
- omskoling
- revolution
- højre
- Værelse
- s
- samme
- besparelse
- Videnskab
- Videnskab og Teknologi
- forskere
- score
- se
- send
- afsendelse
- Sequence
- sæt
- flere
- Vis
- betydeligt
- dygtighed
- So
- Alene
- SOLVE
- Løsning
- nogle
- Nogen
- noget
- specifikke
- brugt
- etaper
- starte
- starter
- styre
- Trin
- Steps
- Stadig
- stil
- sikker
- tackle
- taget
- Opgaver
- opgaver
- tech
- teknik
- teknikker
- Teknologier
- fortæller
- semester
- end
- at
- Them
- derefter
- Der.
- derfor
- Disse
- de
- tror
- Tænker
- denne
- tænkte
- Gennem
- Dermed
- tid
- til
- TONE
- I alt
- HELT
- Tog
- Kurser
- træ
- forsøgte
- prøv
- forsøger
- to
- ultimativ
- under
- gennemgå
- forstå
- forståelse
- utvivlsomt
- us
- brug
- anvendte
- ved brug af
- VALIDATE
- Værdifuld
- forskellige
- alsidige
- meget
- ønsker
- Vej..
- måder
- we
- Kendt
- var
- hvornår
- som
- hvorfor
- vilje
- blæst
- med
- inden for
- uden
- ord
- arbejder
- world
- Forkert
- år
- endnu
- Udbytte
- dig
- Din
- zephyrnet







