Multi-model endpoints (MME'er) er et stærkt træk ved Amazon SageMaker designet til at forenkle implementeringen og driften af maskinlæringsmodeller (ML). Med MME'er kan du hoste flere modeller på en enkelt serveringscontainer og hoste alle modellerne bag et enkelt slutpunkt. SageMaker-platformen styrer automatisk lastning og losning af modeller og skalerer ressourcer baseret på trafikmønstre, hvilket reducerer den operationelle byrde ved at administrere en stor mængde modeller. Denne funktion er især gavnlig for deep learning og generative AI-modeller, der kræver accelereret beregning. Omkostningsbesparelserne opnået gennem ressourcedeling og forenklet modelstyring gør SageMaker MME'er til et glimrende valg for dig til at hoste modeller i stor skala på AWS.
For nylig har generative AI-applikationer fanget udbredt opmærksomhed og fantasi. Kunder ønsker at implementere generative AI-modeller på GPU'er, men er samtidig bevidste om omkostningerne. SageMaker MME'er understøtter GPU-instanser og er en fantastisk mulighed for disse typer applikationer. I dag er vi glade for at kunne annoncere TorchServe-support til SageMaker MME'er. Denne nye modelserverunderstøttelse giver dig fordelen ved alle fordelene ved MME'er, mens du stadig bruger serveringsstakken, som TorchServe-kunder er mest bekendt med. I dette indlæg demonstrerer vi, hvordan man hoster generative AI-modeller, såsom Stable Diffusion og Segment Anything Model, på SageMaker MME'er ved hjælp af TorchServe og bygger en sprogstyret redigeringsløsning, der kan hjælpe kunstnere og indholdsskabere med at udvikle og iterere deres kunstværker hurtigere.
Løsningsoversigt
Sprogstyret redigering er en almindelig generativ AI-brug på tværs af brancher. Det kan hjælpe kunstnere og indholdsskabere med at arbejde mere effektivt for at imødekomme efterspørgsel efter indhold ved at automatisere gentagne opgaver, optimere kampagner og give slutkunden en hyperpersonlig oplevelse. Virksomheder kan drage fordel af øget indholdsoutput, omkostningsbesparelser, forbedret personalisering og forbedret kundeoplevelse. I dette indlæg demonstrerer vi, hvordan du kan bygge sprogassisterede redigeringsfunktioner ved hjælp af MME TorchServe, der giver dig mulighed for at slette ethvert uønsket objekt fra et billede og ændre eller erstatte ethvert objekt i et billede ved at levere en tekstinstruktion.
Brugeroplevelsesflowet for hver use case er som følger:
- For at fjerne et uønsket objekt skal du vælge objektet fra billedet for at fremhæve det. Denne handling sender pixelkoordinaterne og det originale billede til en generativ AI-model, som genererer en segmenteringsmaske for objektet. Når du har bekræftet det korrekte objektvalg, kan du sende original- og maskebillederne til en anden model til fjernelse. Den detaljerede illustration af dette brugerflow er vist nedenfor.
 |
 |
 |
|
Trin 1: Vælg et objekt ("hund") fra billedet |
Trin 2: Bekræft, at det korrekte objekt er fremhævet |
Trin 3: Slet objektet fra billedet |
- For at ændre eller erstatte et objekt skal du vælge og markere det ønskede objekt ved at følge samme proces som beskrevet ovenfor. Når du har bekræftet det korrekte objektvalg, kan du ændre objektet ved at levere det originale billede, masken og en tekstprompt. Modellen vil derefter ændre det fremhævede objekt baseret på de medfølgende instruktioner. En detaljeret illustration af dette andet brugerflow er som følger.
 |
 |
 |
|
Trin 1: Vælg et objekt ("vase") fra billedet |
Trin 2: Bekræft, at det korrekte objekt er fremhævet |
Trin 3: Giv en tekstprompt ("futuristisk vase") for at ændre objektet |
Til at drive denne løsning bruger vi tre generative AI-modeller: Segment Anything Model (SAM), Large Mask Inpainting Model (LaMa) og Stable Diffusion Inpaint (SD). Her er, hvordan disse modeller er blevet brugt i workflowet for brugeroplevelse:
| For at fjerne et uønsket objekt | For at ændre eller erstatte et objekt |
 |
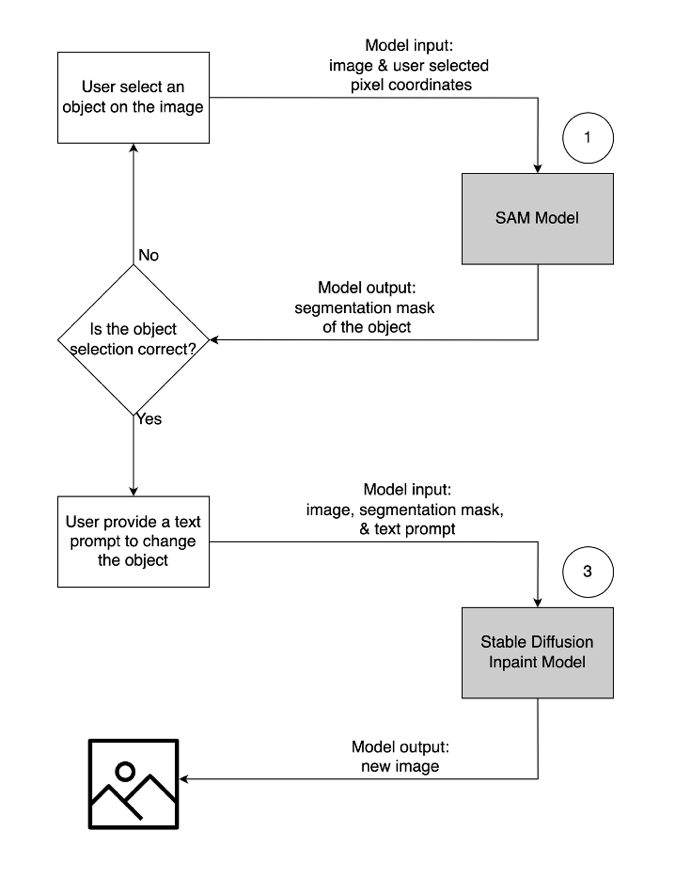 |
- Segment Anything Model (SAM) bruges til at generere en segmentmaske for objektet af interesse. SAM er udviklet af Meta Research og er en open source-model, der kan segmentere ethvert objekt i et billede. Denne model er blevet trænet på et massivt datasæt kendt som SA-1B, som omfatter over 11 millioner billeder og 1.1 milliarder segmenteringsmasker. For mere information om SAM, se deres hjemmeside , forskningsartikel.
- LaMa bruges til at fjerne eventuelle uønskede objekter fra et billede. LaMa er en Generative Adversarial Network (GAN) model, der er specialiseret i at udfylde manglende dele af billeder ved hjælp af uregelmæssige masker. Modelarkitekturen inkorporerer billeddækkende global kontekst og en enkelttrinsarkitektur, der bruger Fourier-foldninger, hvilket gør det muligt at opnå avancerede resultater med en hurtigere hastighed. For flere detaljer om LaMa, besøg deres hjemmeside , forskningsartikel.
- SD 2 inpaint model fra Stability AI bruges til at ændre eller erstatte objekter i et billede. Denne model giver os mulighed for at redigere objektet i maskeområdet ved at give en tekstprompt. Inpaint-modellen er baseret på tekst-til-billede SD-modellen, som kan skabe billeder i høj kvalitet med en simpel tekstprompt. Det giver yderligere argumenter såsom originale og maskebilleder, hvilket giver mulighed for hurtig ændring og gendannelse af eksisterende indhold. For at lære mere om stabile diffusionsmodeller på AWS, se Skab billeder i høj kvalitet med stabile diffusionsmodeller, og implementer dem omkostningseffektivt med Amazon SageMaker.
Alle tre modeller er hostet på SageMaker MME'er, hvilket reducerer den operationelle byrde fra at administrere flere endpoints. Derudover eliminerer brugen af MME bekymringer om, at visse modeller bliver underudnyttet, fordi ressourcerne deles. Du kan se fordelene ved forbedret instansmætning, som i sidste ende fører til omkostningsbesparelser. Det følgende arkitekturdiagram illustrerer, hvordan alle tre modeller betjenes ved hjælp af SageMaker MME'er med TorchServe.
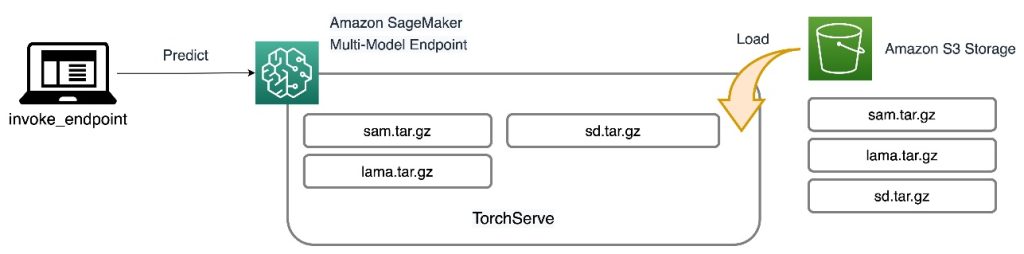
Vi har udgivet koden til at implementere denne løsningsarkitektur i vores GitHub repository. For at følge med i resten af indlægget, brug notesbogsfilen. Det anbefales at køre dette eksempel på en SageMaker notebook-instans ved hjælp af conda_python3 (Python 3.10.10) kerne.
Forlæng TorchServe-beholderen
Det første trin er at forberede modellens hostingcontainer. SageMaker leverer en administreret PyTorch Deep Learning Container (DLC), som du kan hente ved hjælp af følgende kodestykke:
Fordi modellerne kræver ressourcer og yderligere pakker, der ikke er på basis PyTorch DLC, skal du bygge et Docker-image. Dette billede uploades derefter til Amazon Elastic Container Registry (Amazon ECR), så vi kan få adgang direkte fra SageMaker. De brugerdefinerede installerede biblioteker er angivet i Docker-filen:
Kør shell-kommandofilen for at bygge det brugerdefinerede billede lokalt og skub det til Amazon ECR:
Forbered modellens artefakter
Den største forskel for de nye MME'er med TorchServe-understøttelse er, hvordan du forbereder dine modelartefakter. Kode-repoen giver en skeletmappe for hver model (modelmappe) til at rumme de nødvendige filer til TorchServe. Vi følger den samme fire-trins proces for at forberede hver model .tar fil. Følgende kode er et eksempel på skeletmappen til SD-modellen:
Det første trin er at downloade de forudtrænede modelkontrolpunkter i modelmappen:
Det næste trin er at definere en custom_handler.py fil. Dette er nødvendigt for at definere modellens adfærd, når den modtager en anmodning, såsom indlæsning af modellen, forbehandling af input og efterbehandling af output. Det handle metoden er hovedindgangspunktet for anmodninger, og den accepterer et anmodningsobjekt og returnerer et svarobjekt. Den indlæser de forudtrænede modelkontrolpunkter og anvender preprocess , postprocess metoder til input og output data. Følgende kodestykke illustrerer en simpel struktur af custom_handler.py fil. For flere detaljer henvises til TorchServe handler API.
Den sidste nødvendige fil til TorchServe er model-config.yaml. Filen definerer konfigurationen af modelserveren, såsom antal arbejdere og batchstørrelse. Konfigurationen er på et niveau pr. model, og et eksempel på en konfigurationsfil er vist i følgende kode. For en komplet liste over parametre henvises til GitHub repo.
Det sidste trin er at pakke alle modelartefakter i en enkelt .tar.gz-fil ved hjælp af torch-model-archiver modul:
Opret multi-model slutpunktet
Trinene til at oprette en SageMaker MME er de samme som før. I dette særlige eksempel opretter du et slutpunkt ved hjælp af SageMaker SDK. Start med at definere en Amazon Simple Storage Service (Amazon S3) placering og hostingcontaineren. Denne S3-placering er, hvor SageMaker dynamisk indlæser modellerne baseret på invokationsmønstre. Hostingcontaineren er den brugerdefinerede container, du byggede og skubbede til Amazon ECR i det tidligere trin. Se følgende kode:
Så vil du definere en MulitDataModel der fanger alle attributter som modelplacering, hostingbeholder og tilladelsesadgang:
deploy() funktion opretter en slutpunktskonfiguration og hoster slutpunktet:
I eksemplet, vi gav, viser vi også, hvordan du kan liste modeller og dynamisk tilføje nye modeller ved hjælp af SDK. Det add_model() funktion kopierer din lokale model .tar filer til MME S3-placeringen:
Påkald modellerne
Nu hvor vi har alle tre modeller hostet på en MME, kan vi påberåbe hver model i rækkefølge for at bygge vores sprogassisterede redigeringsfunktioner. For at kalde hver model skal du angive en target_model parameter i predictor.predict() fungere. Modelnavnet er blot navnet på modellen .tar fil, vi har uploadet. Følgende er et eksempel på et kodestykke til SAM-modellen, der tager en pixelkoordinat, en punktetiket og dilateret kernestørrelse ind og genererer en segmenteringsmaske af objektet på pixelplaceringen:
For at fjerne et uønsket objekt fra et billede, tag segmenteringsmasken, der er genereret fra SAM, og indfør den i LaMa-modellen med det originale billede. De følgende billeder viser et eksempel.
 |
 |
|
|
Prøve billede |
Segmenteringsmaske fra SAM |
Slet hunden ved hjælp af LaMa |
For at ændre eller erstatte ethvert objekt i et billede med en tekstprompt, tag segmenteringsmasken fra SAM og indfør den i SD-modellen med det originale billede og tekstprompt, som vist i følgende eksempel.
|
|
 |
|
Prøve billede |
Segmenteringsmaske fra SAM |
Udskift ved brug af SD-model med tekstprompt "en hamster på en bænk" |
Omkostningsbesparelser
Fordelene ved SageMaker MME'er øges baseret på omfanget af modelkonsolidering. Følgende tabel viser GPU-hukommelsesbrugen for de tre modeller i dette indlæg. De er indsat på én g5.2xlarge instans ved at bruge én SageMaker MME.
| Model | GPU-hukommelse (MiB) |
| Segmentér hvad som helst model | 3,362 |
| Stabil diffusion i maling | 3,910 |
| Lama | 852 |
Du kan se omkostningsbesparelser, når du hoster de tre modeller med ét slutpunkt, og for brugssager med hundredvis eller tusindvis af modeller er besparelserne meget større.
Overvej for eksempel 100 stabile diffusionsmodeller. Hver af modellerne kunne for sig selv betjenes af en ml.g5.2xlarge endepunkt (4 GiB hukommelse), koster 1.52 USD pr. instanstime i den østlige region i USA (N. Virginia). At levere alle 100 modeller ved hjælp af deres eget endepunkt ville koste $218,880 om måneden. Med en SageMaker MME, et enkelt slutpunkt ved hjælp af ml.g5.2xlarge instanser kan være vært for fire modeller samtidigt. Dette reducerer produktionsomkostningerne med 75 % til kun $54,720 pr. måned. Følgende tabel opsummerer forskellene mellem enkelt-model- og multi-model-endepunkter for dette eksempel. Givet en slutpunktskonfiguration med tilstrækkelig hukommelse til dine målmodeller, vil steady state invocation latens, efter at alle modeller er blevet indlæst, svare til den for et enkelt-model slutpunkt.
| . | Enkeltmodel slutpunkt | Multi-model slutpunkt |
| Samlet slutpunktspris pr. måned | $218,880 | $54,720 |
| Endpoint-forekomsttype | ml.g5.2xlarge | ml.g5.2xlarge |
| CPU-hukommelseskapacitet (GiB) | 32 | 32 |
| GPU-hukommelseskapacitet (GiB) | 24 | 24 |
| Slutpunktspris pr. time | $1.52 | $1.52 |
| Antal forekomster pr. slutpunkt | 2 | 2 |
| Endpoints nødvendige for 100 modeller | 100 | 25 |
Ryd op
Når du er færdig, skal du følge instruktionerne i oprydningssektionen af notesbogen for at slette de ressourcer, der er tilvejebragt i dette indlæg for at undgå unødvendige gebyrer. Henvise til Amazon SageMaker-priser for detaljer om omkostningerne ved slutningstilfældene.
Konklusion
Dette indlæg demonstrerer de sprogassisterede redigeringsmuligheder, der er muliggjort gennem brugen af generative AI-modeller hostet på SageMaker MME'er med TorchServe. Eksemplet, vi delte, illustrerer, hvordan vi kan bruge ressourcedeling og forenklet modelstyring med SageMaker MME'er, mens vi stadig bruger TorchServe som vores modelserveringstak. Vi brugte tre grundlæggende modeller for dyb læring: SAM, SD 2 Inpainting og LaMa. Disse modeller gør det muligt for os at opbygge kraftfulde funktioner, såsom at slette ethvert uønsket objekt fra et billede og ændre eller erstatte ethvert objekt i et billede ved at levere en tekstinstruktion. Disse funktioner kan hjælpe kunstnere og indholdsskabere med at arbejde mere effektivt og opfylde deres indholdskrav ved at automatisere gentagne opgaver, optimere kampagner og give en hyperpersonlig oplevelse. Vi inviterer dig til at udforske eksemplet i dette indlæg og opbygge din egen UI-oplevelse ved at bruge TorchServe på en SageMaker MME.
For at komme i gang, se Understøttede algoritmer, rammer og instanser til multi-model slutpunkter ved hjælp af GPU-understøttede instanser.
Om forfatterne
 James Wu er Senior AI/ML Specialist Solution Architect hos AWS. hjælpe kunder med at designe og bygge AI/ML-løsninger. James' arbejde dækker en bred vifte af ML use cases med en primær interesse i computervision, deep learning og skalering af ML på tværs af virksomheden. Inden han kom til AWS, var James arkitekt, udvikler og teknologileder i over 10 år, herunder 6 år inden for ingeniørvidenskab og 4 år i marketing- og reklamebranchen.
James Wu er Senior AI/ML Specialist Solution Architect hos AWS. hjælpe kunder med at designe og bygge AI/ML-løsninger. James' arbejde dækker en bred vifte af ML use cases med en primær interesse i computervision, deep learning og skalering af ML på tværs af virksomheden. Inden han kom til AWS, var James arkitekt, udvikler og teknologileder i over 10 år, herunder 6 år inden for ingeniørvidenskab og 4 år i marketing- og reklamebranchen.
 Li Ning er senior softwareingeniør hos AWS med speciale i at bygge store AI-løsninger. Som tech lead for TorchServe, et projekt udviklet i fællesskab af AWS og Meta, ligger hendes passion i at udnytte PyTorch og AWS SageMaker til at hjælpe kunder med at omfavne AI til det bedste. Ud over sine professionelle bestræbelser nyder Li at svømme, rejse, følge de seneste fremskridt inden for teknologi og tilbringe kvalitetstid med sin familie.
Li Ning er senior softwareingeniør hos AWS med speciale i at bygge store AI-løsninger. Som tech lead for TorchServe, et projekt udviklet i fællesskab af AWS og Meta, ligger hendes passion i at udnytte PyTorch og AWS SageMaker til at hjælpe kunder med at omfavne AI til det bedste. Ud over sine professionelle bestræbelser nyder Li at svømme, rejse, følge de seneste fremskridt inden for teknologi og tilbringe kvalitetstid med sin familie.
 Ankith Gunapal er AI Partner Engineer hos Meta (PyTorch). Han brænder for modeloptimering og modelservering, med erfaring lige fra RTL-verifikation, indlejret software, computervision til PyTorch. Han har en Master i Data Science og en Master i Telekommunikation. Uden for arbejdet er Ankith også producer af elektronisk dansemusik.
Ankith Gunapal er AI Partner Engineer hos Meta (PyTorch). Han brænder for modeloptimering og modelservering, med erfaring lige fra RTL-verifikation, indlejret software, computervision til PyTorch. Han har en Master i Data Science og en Master i Telekommunikation. Uden for arbejdet er Ankith også producer af elektronisk dansemusik.
 Saurabh Trikande er Senior Product Manager for Amazon SageMaker Inference. Han brænder for at arbejde med kunder og er motiveret af målet om at demokratisere machine learning. Han fokuserer på kerneudfordringer relateret til implementering af komplekse ML-applikationer, multi-tenant ML-modeller, omkostningsoptimeringer og at gøre implementering af deep learning-modeller mere tilgængelig. I sin fritid nyder Saurabh at vandre, lære om innovative teknologier, følge TechCrunch og tilbringe tid med sin familie.
Saurabh Trikande er Senior Product Manager for Amazon SageMaker Inference. Han brænder for at arbejde med kunder og er motiveret af målet om at demokratisere machine learning. Han fokuserer på kerneudfordringer relateret til implementering af komplekse ML-applikationer, multi-tenant ML-modeller, omkostningsoptimeringer og at gøre implementering af deep learning-modeller mere tilgængelig. I sin fritid nyder Saurabh at vandre, lære om innovative teknologier, følge TechCrunch og tilbringe tid med sin familie.
 Subhash Talluri er en Lead AI/ML-løsningsarkitekt for Telecom Industrys forretningsenhed hos Amazon Web Services. Han har ledet udviklingen af innovative AI/ML-løsninger til Telecom-kunder og partnere verden over. Han bringer tværfaglig ekspertise inden for teknik og datalogi til at hjælpe med at bygge skalerbare, sikre og kompatible AI/ML-løsninger via cloud-optimerede arkitekturer på AWS.
Subhash Talluri er en Lead AI/ML-løsningsarkitekt for Telecom Industrys forretningsenhed hos Amazon Web Services. Han har ledet udviklingen af innovative AI/ML-løsninger til Telecom-kunder og partnere verden over. Han bringer tværfaglig ekspertise inden for teknik og datalogi til at hjælpe med at bygge skalerbare, sikre og kompatible AI/ML-løsninger via cloud-optimerede arkitekturer på AWS.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Automotive/elbiler, Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- ChartPrime. Løft dit handelsspil med ChartPrime. Adgang her.
- BlockOffsets. Modernisering af miljømæssig offset-ejerskab. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/run-multiple-generative-ai-models-on-gpu-using-amazon-sagemaker-multi-model-endpoints-with-torchserve-and-save-up-to-75-in-inference-costs/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 100
- 11
- 12
- 14
- 15 %
- 19
- 200
- 28
- 300
- 500
- 52
- 7
- 8
- 9
- a
- Om
- over
- fremskynde
- accelereret
- accepterer
- adgang
- tilgængelig
- opnå
- opnået
- tværs
- Handling
- tilføje
- Desuden
- Yderligere
- fremskridt
- Fordel
- kontradiktorisk
- Reklame
- Efter
- AI
- AI modeller
- AI / ML
- algoritmer
- Alle
- tillade
- tillade
- tillader
- sammen
- også
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- ,
- Annoncere
- enhver
- noget
- api
- applikationer
- arkitektur
- ER
- OMRÅDE
- argumenter
- Artister
- kunstværk
- AS
- At
- opmærksomhed
- attributter
- automatisk
- Automatisering
- undgå
- AWS
- Backed
- bund
- baseret
- BE
- fordi
- været
- før
- bag
- være
- jf. nedenstående
- gavnlig
- gavner det dig
- fordele
- mellem
- Billion
- Bringer
- bygge
- Bygning
- bygget
- byrde
- virksomhed
- virksomheder
- men
- by
- Kampagner
- CAN
- kapaciteter
- Kapacitet
- fanget
- fanger
- tilfælde
- tilfælde
- vis
- udfordringer
- lave om
- afgifter
- valg
- kode
- Fælles
- fuldføre
- komplekse
- kompatibel
- omfatter
- Compute
- computer
- Datalogi
- Computer Vision
- Bekymringer
- Konfiguration
- Bekræfte
- bevidst
- Overvej
- konsolidering
- Container
- indhold
- indhold skabere
- sammenhæng
- koordinere
- kopier
- Core
- korrigere
- Koste
- omkostningsbesparelser
- Omkostninger
- kunne
- dækker
- skabe
- skaber
- skabere
- skik
- kunde
- Kundeoplevelse
- Kunder
- dans
- data
- datalogi
- dato tid
- dyb
- dyb læring
- definere
- definerer
- definere
- Efterspørgsel
- krav
- demokratisering
- demonstrere
- demonstreret
- demonstrerer
- indsætte
- indsat
- implementering
- implementering
- beskrevet
- Design
- konstrueret
- ønskes
- detail
- detaljeret
- detaljer
- udvikle
- udviklet
- Udvikler
- Udvikling
- forskel
- forskelle
- Broadcasting
- direkte
- Docker
- Dog
- færdig
- downloade
- dynamisk
- hver
- tidligere
- Øst
- redigering
- effektivt
- elektronisk
- eliminerer
- indlejret
- omfavne
- muliggøre
- muliggør
- ende
- bestræbelser
- Endpoint
- endpoints
- ingeniør
- Engineering
- forbedret
- Enterprise
- indrejse
- Ether (ETH)
- eksempel
- fremragende
- ophidset
- eksisterende
- erfaring
- ekspertise
- udforske
- bekendt
- familie
- hurtigere
- Feature
- Funktionalitet
- File (Felt)
- Filer
- udfylde
- endelige
- Fornavn
- flow
- fokuserer
- følger
- efter
- følger
- Til
- Foundation
- fire
- rammer
- fra
- funktion
- generere
- genereret
- genererer
- generative
- Generativ AI
- få
- GitHub
- given
- giver
- Global
- global kontekst
- mål
- godt
- GPU
- GPU'er
- stor
- større
- Hamster
- Have
- he
- hjælpe
- hjælpe
- hende
- link.
- høj kvalitet
- Fremhæv
- Fremhævet
- hiking
- hans
- besidder
- host
- hostede
- Hosting
- værter
- time
- hus
- Hvordan
- How To
- http
- HTTPS
- Hundreder
- illustrerer
- billede
- billeder
- fantasi
- gennemføre
- importere
- forbedret
- in
- Herunder
- inkorporerer
- Forøg
- øget
- industrier
- industrien
- oplysninger
- innovativ
- innovative teknologier
- indgang
- installere
- instans
- anvisninger
- interesse
- ind
- invitere
- IT
- ITS
- james
- sammenføjning
- jpg
- json
- lige
- kendt
- etiket
- stor
- storstilet
- Efternavn
- Latency
- seneste
- føre
- leder
- førende
- Leads
- LÆR
- læring
- Niveau
- løftestang
- li
- biblioteker
- ligger
- ligesom
- Liste
- Børsnoterede
- belastning
- lastning
- belastninger
- lokale
- lokalt
- placering
- maskine
- machine learning
- lavet
- Main
- maerker
- Making
- lykkedes
- ledelse
- leder
- administrerer
- styring
- Marketing
- Marketing & Annoncering
- maske
- Masker
- massive
- herres
- matplotlib
- Mød
- Hukommelse
- Meta
- meta forskning
- metode
- metoder
- million
- mangler
- ML
- model
- modeller
- ændre
- modul
- Måned
- mere
- mest
- motiveret
- meget
- flere
- Musik
- navn
- Behov
- behov
- netværk
- Ny
- næste
- Ingen
- notesbog
- nummer
- objekt
- objekter
- observere
- of
- on
- engang
- ONE
- kun
- open source
- drift
- operationelle
- optimering
- optimering
- Option
- or
- original
- vores
- output
- uden for
- i løbet af
- egen
- pakke
- pakker
- parameter
- parametre
- særlig
- især
- partner
- partnere
- dele
- lidenskab
- lidenskabelige
- mønstre
- per
- tilladelse
- Personalisering
- pipeline
- pixel
- perron
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- Punkt
- mulig
- Indlæg
- magt
- vigtigste
- Predictor
- Forbered
- pris
- primære
- Forud
- behandle
- producent
- Produkt
- produktchef
- produktion
- professionel
- projekt
- give
- forudsat
- giver
- leverer
- offentliggjort
- Skub ud
- skubbet
- Python
- pytorch
- kvalitet
- mængde
- Hurtig
- rækkevidde
- spænder
- Læs
- modtager
- anbefales
- reducerer
- reducere
- region
- relaterede
- fjernelse
- Fjern
- repetitiv
- erstatte
- anmode
- anmodninger
- kræver
- påkrævet
- forskning
- ressource
- Ressourcer
- svar
- reaktioner
- REST
- restaurering
- Resultater
- afkast
- afkast
- RGB
- Kør
- sagemaker
- SageMaker Inference
- Sam
- samme
- Gem
- Besparelser
- skalerbar
- Scale
- skalaer
- skalering
- Videnskab
- SD
- SDK
- Anden
- Sektion
- sikker
- se
- segment
- segmentering
- valg
- SELV
- send
- sender
- senior
- Sequence
- Tjenester
- servering
- delt
- deling
- Shell
- Vis
- vist
- Shows
- lignende
- Simpelt
- forenklet
- forenkle
- samtidigt
- enkelt
- Størrelse
- uddrag
- So
- Software
- Software Engineer
- løsninger
- Løsninger
- specialist
- specialiseret
- hastighed
- udgifterne
- Spin
- Stabilitet
- stabil
- stable
- starte
- påbegyndt
- Tilstand
- state-of-the-art
- steady
- Trin
- Steps
- Stadig
- opbevaring
- struktur
- sådan
- tilstrækkeligt
- leverer
- support
- svømning
- bord
- Tag
- tager
- mål
- opgaver
- tech
- TechCrunch
- Teknologier
- Teknologier
- telecom
- telekommunikation
- tensorflow
- tekst
- at
- deres
- Them
- derefter
- Disse
- de
- denne
- tusinder
- tre
- Gennem
- tid
- til
- i dag
- fakkel
- Trafik
- uddannet
- transformers
- Traveling
- typer
- ui
- Ultimativt
- enhed
- uønsket
- uploadet
- us
- Brug
- brug
- brug tilfælde
- anvendte
- Bruger
- Brugererfaring
- bruger
- ved brug af
- udnyttet
- Ved hjælp af
- Verifikation
- via
- Virginia
- vision
- Besøg
- ønsker
- var
- we
- web
- webservices
- hvornår
- som
- mens
- bred
- Bred rækkevidde
- udbredt
- vilje
- med
- Arbejde
- arbejdere
- workflow
- arbejder
- verdensplan
- ville
- år
- dig
- Din
- zephyrnet