Amazon EMR runtime for Apache Spark er en ydeevneoptimeret runtime for Apache Spark, der er 100 % API-kompatibel med open source Apache Spark. Med Amazon EMR udgivelse 6.9.0, EMR-runtime for Apache Spark understøtter tilsvarende Spark-version 3.3.0.
Med Amazon EMR 6.9.0 kan du nu køre dine Apache Spark 3.x-applikationer hurtigere og til lavere omkostninger uden at kræve ændringer i dine applikationer. I vores præstationsbenchmark-test, afledt af TPC-DS-ydelsestest på 3 TB skala, fandt vi ud af, at EMR-kørselstiden for Apache Spark 3.3.0 giver en ydeevneforbedring på 3.5 gange (ved brug af total runtime) i gennemsnit i forhold til open source Apache Spark 3.3.0. XNUMX.
I dette indlæg analyserer vi resultaterne fra vores benchmark-test, der kører en TPC-DS-applikation på open source Apache Spark og så på Amazon EMR 6.9, som kommer med en optimeret Spark-runtime, der er kompatibel med open source Spark. Vi gennemgår en detaljeret omkostningsanalyse og giver til sidst trin-for-trin instruktioner til at køre benchmark.
Resultater observeret
For at evaluere ydeevneforbedringerne brugte vi et open source Spark-ydelsestestværktøj, der er afledt af TPC-DS-ydelsestestværktøjssættet. Vi kørte testene på en syv-node (seks kerneknuder og en primær node) c5d.9xlarge EMR-klynge med EMR-runtime for Apache Spark, og en anden syv-node selvadministreret klynge på Amazon Elastic Compute Cloud (Amazon EC2) med den tilsvarende open source-version af Spark. Vi kørte begge tests med data i Amazon Simple Storage Service (Amazon S3).
Dynamic Resource Allocation (DRA) er en fantastisk funktion til at bruge til varierende arbejdsbelastninger. Men til en benchmarking-øvelse, hvor vi sammenligner to platforme udelukkende på ydeevne, og testdatamængderne ikke ændres (3 TB i vores tilfælde), mener vi, at det er bedst at undgå variabilitet for at køre en æble-til-æbler-sammenligning. I vores test i både open source Spark og Amazon EMR deaktiverede vi DRA, mens vi kørte benchmarking-applikationen.
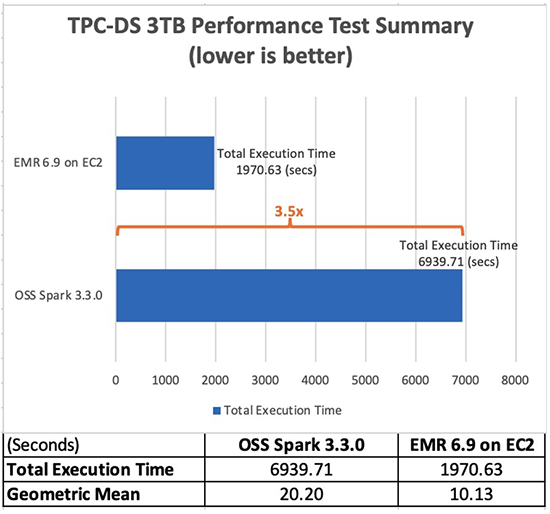
Følgende tabel viser den samlede jobkørselstid for alle forespørgsler (i sekunder) i 3 TB forespørgselsdatasættet mellem Amazon EMR version 6.9.0 og open source Spark version 3.3.0. Vi observerede, at vores TPC-DS-test havde en samlet jobkørselstid på Amazon EMR på Amazon EC2, der var 3.5 gange hurtigere end ved brug af en open source Spark-klynge med samme konfiguration.
Fremskyndelsen pr. forespørgsel på Amazon EMR 6.9 med og uden EMR-runtime for Apache Spark er illustreret i følgende diagram. Den vandrette akse viser hver forespørgsel i 3 TB benchmark. Den lodrette akse viser hastigheden af hver forespørgsel på grund af EMR-kørselstiden. Bemærkelsesværdige præstationsforbedringer er over 10 gange hurtigere for TPC-DS-forespørgsler 24b, 72, 95 og 96.

Omkostningsanalyse
Ydeevneforbedringerne af EMR runtime til Apache Spark oversættes direkte til lavere omkostninger. Vi var i stand til at realisere en omkostningsbesparelse på 67 % ved at køre benchmark-applikationen på Amazon EMR sammenlignet med omkostningerne ved at køre den samme applikation på open source Spark på Amazon EC2 med samme klyngestørrelse på grund af reducerede timer med Amazon EMR og Amazon EC2 brug. Amazon EMR-priser er for EMR-applikationer, der kører på EMR-klynger med EC2-instanser. Amazon EMR-prisen lægges til de underliggende beregnings- og lagerpriser, såsom EC2-forekomstpris og Amazon Elastic Block Store (Amazon EBS) omkostninger (hvis der vedhæftes EBS-volumener). Samlet set er de estimerede benchmark-omkostninger i den amerikanske østlige (N. Virginia)-region $27.01 pr. kørsel for open source Spark på Amazon EC2 og $8.82 pr. kørsel for Amazon EMR.
| Benchmark job | Kørselstid (time) | Anslåede omkostninger | Samlet EC2-instans | Samlet vCPU | Samlet hukommelse (GiB) | Rodenhed (Amazon EBS) |
|
Open source Spark på Amazon EC2 (1 primær og 6 kernenoder) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EMR på Amazon EC2 (1 primær og 6 kernenoder) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Omkostningsfordeling
Følgende er omkostningsfordelingen for open source Spark på Amazon EC2-jobbet ($27.01):
- Samlede Amazon EC2-omkostninger – (7 * $1.728 * 2.23) = (antal forekomster * c5d.9xlarge timepris * jobkørselstid i time) = $26.97
- Amazon EBS omkostninger – ($0.1/730 * 20 * 7 * 2.23) = (Amazon EBS pr. GB-timepris * root EBS-størrelse * antal forekomster * jobkørselstid i time) = $0.042
Følgende er omkostningsfordelingen for Amazon EMR på Amazon EC2-job ($8.82):
- Samlede Amazon EMR-omkostninger – (7 * $0.27 * 0.63) = ((antal kernenoder + antal primære noder)* c5d.9xlarge Amazon EMR-pris * jobkørselstid i time) = $1.19
- Samlede Amazon EC2-omkostninger – (7 * $1.728 * 0.63) = ((antal kernenoder + antal primære noder)* c5d.9xlarge instanspris * jobkørselstid i time) = $7.62
- Amazon EBS omkostninger – ($0.1/730 * 20 GiB * 7 * 0.63) = (Amazon EBS pr. GB-timepris * EBS-størrelse * antal forekomster * jobkørselstid i time) = $0.012
Konfigurer OSS Spark-benchmarking
I de følgende afsnit giver vi en kort oversigt over de trin, der er involveret i opsætningen af benchmarkingen. For detaljerede instruktioner med eksempler henvises til GitHub repo.
Til vores OSS Spark-benchmarking bruger vi open source-værktøjet Flintrock at lancere vores Amazon EC2-baserede Apache Spark klynge. Flintrock giver en hurtig måde at starte en Apache Spark-klynge på Amazon EC2 ved hjælp af kommandolinjen.
Forudsætninger
Udfør følgende forudsætningstrin:
- Har Python 3.7.x eller nyere.
- Har Pip3 22.2.2 eller nyere.
- Tilføj Python bin-mappen til din miljøsti. Flintrock binær vil blive installeret i denne sti.
- Kør
aws configureat konfigurere din AWS kommandolinjegrænseflade (AWS CLI) shell for at pege på benchmarking-kontoen. Henvise til Hurtig konfiguration med aws configure for at få vejledning. - Have en nøglepar med restriktive filtilladelser til at få adgang til OSS Spark primære node.
- Opret en ny S3-bøtte på din testkonto, hvis det er nødvendigt.
- Kopier TPC-DS-kildedataene som input til din S3-bøtte.
- Byg benchmark-applikationen ved at følge de trin, der er angivet i Trin til at bygge gnist-benchmark-assembly-applikation. Alternativt kan du downloade en præ-bygget gnist-benchmark-samling-3.3.0.jar hvis du ønsker en Spark 3.3.0-baseret applikation.
Implementer Spark-klyngen, og kør benchmark-jobbet
Udfør følgende trin:
- Installer Flintrock-værktøjet via pip som vist i Trin til opsætning af OSS Spark Benchmarking.
- Kør kommandoen flintrock configure, som dukker en standardkonfigurationsfil op.
- Rediger standard
config.yamlfil baseret på dine behov. Alternativt kan du kopiere og indsætte config.yaml filen indholdet til standardkonfigurationsfilen. Gem derefter filen, hvor den var. - Start endelig 7-node Spark-klyngen på Amazon EC2 via Flintrock.
Dette skulle skabe en Spark-klynge med én primær knude og seks arbejdsknudepunkter. Hvis du ser nogen fejlmeddelelser, skal du dobbelttjekke konfigurationsfilens værdier, især Spark- og Hadoop-versionerne og attributterne for download-source og AMI.
OSS Spark-klyngen leveres ikke med YARN-ressourcemanager. For at aktivere det skal vi konfigurere klyngen.
- Download yarn-site.xml , enable-yarn.sh filer fra GitHub-repoen.
- Erstatte med IP-adressen på den primære node i din Flintrock-klynge.
Du kan hente IP-adressen fra Amazon EC2-konsollen.
- Upload filerne til alle noderne i Spark-klyngen.
- Kør enable-yarn scriptet.
- Aktiver Snappy-understøttelse i Hadoop (benchmark-jobbet læser Snappy-komprimerede data).
- Download JAR-filen til benchmark-hjælpeprogrammet gnist-benchmark-samling-3.3.0.jar til din lokale maskine.
- Kopier denne fil til klyngen.
- Log ind på den primære node og start YARN.
- Indsend benchmark-jobbet på open source Spark-klyngen som vist i Indsend benchmarkjobbet.
Opsummer resultaterne
Download testresultatfilen fra output S3-bøtten s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Erstatte $YOUR_S3_BUCKET med dit S3-spandnavn.) Du kan bruge Amazon S3-konsollen og navigere til S3-output-placeringen eller bruge AWS CLI.
Spark benchmark-applikationen opretter en tidsstempelmappe og skriver en oversigtsfil i et summary.csv-præfiks. Dit tidsstempel og filnavn vil være anderledes end det, der er vist i det foregående eksempel.
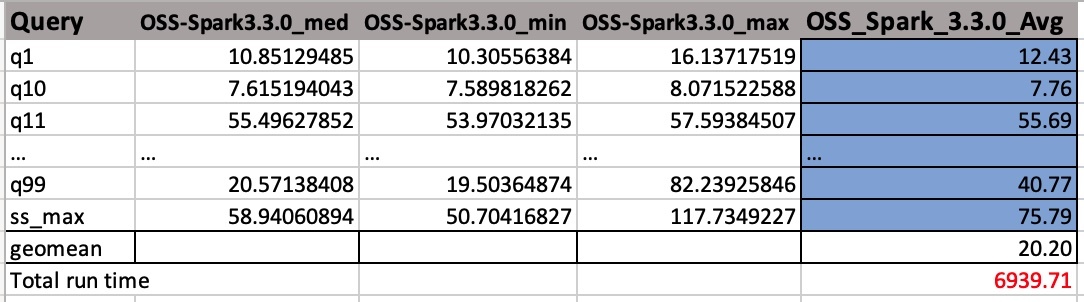
CSV-outputfilerne har fire kolonner uden overskriftsnavne. De er:
- Forespørgselsnavn
- Mediantid
- Minimum tid
- Maksimal tid
Følgende skærmbillede viser et eksempel på output. Vi har manuelt tilføjet kolonnenavne. Den måde, vi beregner geometrien og den samlede jobkørselstid på, er baseret på aritmetiske gennemsnit. Vi tager først middelværdien af med-, min- og maksværdierne ved hjælp af formlen AVERAGE(B2:D2). Derefter tager vi et geometrisk gennemsnit af kolonnen Avg ved at bruge formlen GEOMEAN(E2:E105).
Konfigurer Amazon EMR-benchmarking
For detaljerede instruktioner, se Trin til opsætning af EMR-benchmarking.
Forudsætninger
Udfør følgende forudsætningstrin:
- Kør
aws configurefor at konfigurere din AWS CLI-skal til at pege på benchmarking-kontoen. Henvise til Hurtig konfiguration med aws configure for at få vejledning. - Upload benchmark-applikationen til Amazon S3.
Implementer EMR-klyngen og kør benchmark-jobbet
Udfør følgende trin:
- Drej Amazon EMR op i din AWS CLI-shell ved hjælp af kommandolinjen som vist i Implementer EMR Cluster og kør benchmarkjob.
- Konfigurer Amazon EMR med én primær (c5d.9xlarge) og seks kerne (c5d.9xlarge) noder. Henvise til skabe-klynge for en detaljeret beskrivelse af AWS CLI-muligheder.
- Gem klynge-id'et fra svaret. Du har brug for dette i næste trin.
- Indsend benchmark-jobbet i Amazon EMR ved hjælp af tilføjelsestrin i AWS CLI.
Opsummer resultaterne
Opsummer resultaterne fra output-bøtten s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT på samme måde som vi gjorde for OSS-resultaterne og sammenligne.
Ryd op
For at undgå fremtidige gebyrer skal du slette de ressourcer, du har oprettet ved hjælp af instruktionerne i Oprydningssektion af GitHub-repoen.
- Stop EMR- og OSS Spark-klyngerne. Du kan også slette dem, hvis du ikke ønsker at beholde indholdet. Du kan slette disse ressourcer ved at køre scriptet cleanup-benchmark-env.sh fra en terminal i dit benchmark-miljø.
- Hvis du brugte AWS Cloud9 som din IDE til at bygge benchmark-applikationen JAR-fil ved hjælp af Trin til at bygge gnist-benchmark-assembly-applikation, vil du måske også slette miljøet.
Konklusion
Du kan køre dine Apache Spark-arbejdsbelastninger 3.5 gange (baseret på samlet runtime) hurtigere og til lavere omkostninger uden at foretage ændringer i dine applikationer ved at bruge Amazon EMR 6.9.0.
For at holde dig opdateret, abonner på Big Data-bloggen RSS-feed for at lære mere om EMR-runtime for Apache Spark, bedste praksis for konfiguration og råd om tuning.
For tidligere benchmarktest, se Kør Apache Spark 3.0 arbejdsbelastninger 1.7 gange hurtigere med Amazon EMR runtime til Apache Spark. Bemærk, at det tidligere benchmarkresultat på 1.7 gange præstation var baseret på geometrisk gennemsnit. Baseret på geometrisk gennemsnit var ydeevnen i Amazon EMR 6.9 to gange hurtigere.
Om forfatterne
 Sekar Srinivasan er Sr. Specialist Solutions Architect hos AWS med fokus på Big Data og Analytics. Sekar har over 20 års erfaring med at arbejde med data. Han brænder for at hjælpe kunder med at bygge skalerbare løsninger, der moderniserer deres arkitektur og genererer indsigt fra deres data. I sin fritid kan han godt lide at arbejde på non-profit projekter, især dem, der fokuserer på underprivilegerede børns uddannelse.
Sekar Srinivasan er Sr. Specialist Solutions Architect hos AWS med fokus på Big Data og Analytics. Sekar har over 20 års erfaring med at arbejde med data. Han brænder for at hjælpe kunder med at bygge skalerbare løsninger, der moderniserer deres arkitektur og genererer indsigt fra deres data. I sin fritid kan han godt lide at arbejde på non-profit projekter, især dem, der fokuserer på underprivilegerede børns uddannelse.
 Prabu Ravichandran er en Senior Data Architect med Amazon Web Services, med fokus på Analytics, data Lake-arkitektur og implementering. Han hjælper kunder med at arkitekte og bygge skalerbare og robuste løsninger ved hjælp af AWS-tjenester. I sin fritid nyder Prabu at rejse og tilbringe tid med familien.
Prabu Ravichandran er en Senior Data Architect med Amazon Web Services, med fokus på Analytics, data Lake-arkitektur og implementering. Han hjælper kunder med at arkitekte og bygge skalerbare og robuste løsninger ved hjælp af AWS-tjenester. I sin fritid nyder Prabu at rejse og tilbringe tid med familien.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 år
- 7
- 9
- a
- I stand
- Om
- over
- adgang
- Konto
- tilføjet
- adresse
- rådgivning
- Alle
- allokering
- Amazon
- Amazon EC2
- Amazon EMR
- Amazon Web Services
- analyse
- analytics
- analysere
- ,
- Apache
- Apache Spark
- api
- Anvendelse
- applikationer
- arkitektur
- attributter
- gennemsnit
- AVG
- AWS
- Axis
- baseret
- Tro
- benchmark
- BEDSTE
- bedste praksis
- mellem
- Big
- Big data
- Bloker
- Fordeling
- bygge
- Bygning
- tilfælde
- lave om
- Ændringer
- afgifter
- Chart
- Cluster
- Kolonne
- Kolonner
- Kom
- sammenligne
- sammenligning
- kompatibel
- Compute
- Konfiguration
- Konsol
- indhold
- Core
- Koste
- omkostningsbesparelser
- Omkostninger
- skabe
- oprettet
- skaber
- Kunder
- data
- Data Lake
- Dato
- Standard
- Afledt
- beskrivelse
- detaljeret
- enhed
- DID
- forskellige
- direkte
- deaktiveret
- Er ikke
- Dont
- downloade
- hver
- Øst
- EBS
- Uddannelse
- muliggøre
- Miljø
- Ækvivalent
- fejl
- især
- anslået
- Ether (ETH)
- evaluere
- eksempel
- eksempler
- Dyrke motion
- erfaring
- familie
- hurtigere
- Feature
- File (Felt)
- Filer
- Endelig
- Fornavn
- fokuserede
- fokuseret
- efter
- Formula
- fundet
- Gratis
- fra
- fremtiden
- gevinster
- generere
- GitHub
- stor
- Hadoop
- hjælpe
- hjælper
- Vandret
- HOURS
- Men
- HTML
- HTTPS
- implementering
- forbedringer
- in
- indgang
- indsigt
- instans
- anvisninger
- involverede
- IP
- IP-adresse
- IT
- Job
- Holde
- sø
- lancere
- LÆR
- Line (linje)
- lokale
- placering
- maskine
- Making
- leder
- måde
- manuelt
- max
- midler
- Hukommelse
- beskeder
- mere
- navn
- navne
- Naviger
- Behov
- behov
- behov
- Ny
- næste
- node
- noder
- non-profit
- bemærkelsesværdig
- nummer
- ONE
- open source
- optimeret
- Indstillinger
- ordrer
- Os
- skitse
- samlet
- lidenskabelige
- forbi
- sti
- ydeevne
- Tilladelser
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- Pops
- Indlæg
- praksis
- pris
- Priser
- prissætning
- primære
- private
- projekter
- give
- forudsat
- giver
- rent
- Python
- Hurtig
- Sats
- indse
- Reduceret
- region
- frigive
- erstatte
- ressource
- Ressourcer
- svar
- restriktiv
- resultere
- Resultater
- robust
- rod
- Kør
- kører
- samme
- Gem
- Besparelser
- skalerbar
- Scale
- Anden
- sekunder
- Sektion
- sektioner
- senior
- Tjenester
- indstilling
- setup
- Shell
- bør
- vist
- Shows
- Simpelt
- SIX
- Størrelse
- Løsninger
- Kilde
- Spark
- specialist
- udgifterne
- starte
- Trin
- Steps
- opbevaring
- Hold mig opdateret
- sådan
- RESUMÉ
- support
- Understøtter
- bord
- Tag
- terminal
- prøve
- tests
- deres
- Gennem
- tid
- gange
- tidsstempel
- til
- værktøj
- toolkit
- I alt
- Oversætte
- Traveling
- underliggende
- underprivilegerede
- us
- Brug
- brug
- nytte
- Værdier
- udgave
- via
- Virginia
- mængder
- web
- webservices
- som
- mens
- vilje
- uden
- Arbejde
- arbejdstager
- arbejder
- X
- XML
- yaml
- år
- Din
- zephyrnet