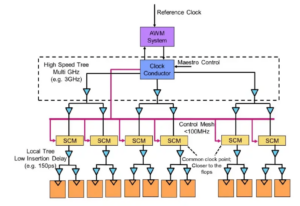
Eksperter ved bordet: Semiconductor Engineering satte sig ned for at tale om vejen frem for hukommelse i stadigt mere heterogene systemer, med Frank Ferro, koncerndirektør, produktledelse på kadence; Steven Woo, kollega og fremtrædende opfinder ved Rambus; Jongsin Yun, hukommelsesteknolog ved Siemens EDA; Randy White, programleder for hukommelsesløsninger hos Nøglesyn; og Frank Schirrmeister, vicepræsident for løsninger og forretningsudvikling på Arteris. Det følgende er uddrag af den samtale. Del et af denne diskussion kan findes link..
![[LR]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; og Frank Schirrmeister, Arteris.](https://platoaistream.com/wp-content/uploads/2024/01/rethinking-memory.png)
[LR]: Frank Ferro, Cadence; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; og Frank Schirrmeister, Arteris
SE: Mens vi kæmper med AI/ML og strømkrav, hvilke konfigurationer skal genovervejes? Vil vi se et skift væk fra Von Neumann-arkitekturen?
Woo: Med hensyn til systemarkitekturer er der en bifurkation i gang i industrien. De traditionelle applikationer, der er de dominerende arbejdsheste, som vi kører i skyen på x86-baserede servere, forsvinder ikke. Der er årtiers software, der er blevet bygget op og udviklet, og som vil stole på, at den arkitektur fungerer godt. Derimod er AI/ML en ny klasse. Folk har gentænket arkitekturerne og bygget meget domænespecifikke processorer. Vi ser, at omkring to tredjedele af energien bruges på at flytte data mellem en processor og en HBM-enhed, mens kun omkring en tredjedel bruges på faktisk at få adgang til bits i DRAM-kernerne. Databevægelsen er nu meget mere udfordrende og dyrere. Vi kommer ikke til at slippe af med hukommelsen. Vi har brug for det, fordi datasættene bliver større. Så spørgsmålet er, 'Hvad er den rigtige vej frem?' Der har været megen diskussion om stabling. Hvis vi skulle tage den hukommelse og sætte den direkte oven på processoren, gør den to ting for dig. For det første er båndbredden i dag begrænset af kysten eller chippens omkreds. Det er der, I/O'erne går. Men hvis du skulle stable den direkte oven på processoren, kan du nu gøre brug af hele området af chippen til distribuerede sammenkoblinger, og du kan få mere af båndbredden i selve hukommelsen, og den kan feeds direkte ned i processoren. Links bliver meget kortere, og strømeffektiviteten stiger sandsynligvis i størrelsesordenen 5X til 6X. For det andet stiger mængden af båndbredde, du kan få på grund af den større array-forbindelse til hukommelsen, også med flere heltalsfaktorer. At gøre disse to ting sammen kan give mere båndbredde og gøre det mere strømeffektivt. Industrien udvikler sig til, hvad end behovene er, og det er bestemt en måde, hvorpå vi vil se hukommelsessystemer begynde at udvikle sig i fremtiden for at blive mere strømeffektive og give mere båndbredde.
Jern: Da jeg først begyndte at arbejde på HBM tilbage omkring 2016, spurgte nogle af de mere avancerede kunder, om det kunne stables. De har kigget på, hvordan man kan stable DRAM'en ovenpå i et stykke tid, fordi der er klare fordele. Fra det fysiske lag bliver PHY'en stort set ubetydelig, hvilket sparer en masse strøm og effektivitet. Men nu har du en processor på flere 100W, der har en hukommelse ovenpå. Hukommelsen kan ikke tåle varmen. Det er nok det svageste led i varmekæden, hvilket skaber endnu en udfordring. Der er fordele, men de skal stadig finde ud af, hvordan de skal håndtere termikken. Der er mere incitament nu til at flytte den type arkitektur fremad, fordi det virkelig sparer dig generelt med hensyn til ydeevne og kraft, og det vil forbedre din computereffektivitet. Men der er nogle fysiske designudfordringer, der skal håndteres. Som Steve sagde, ser vi alle slags arkitekturer, der kommer ud. Jeg er helt enig i, at GPU/CPU-arkitekturerne ikke kommer nogen vegne, de vil stadig være dominerende. Samtidig forsøger alle virksomheder på planeten at finde på en bedre musefælde til at udføre deres AI. Vi ser on-chip SRAM og kombinationer af hukommelse med høj båndbredde. LPDDR har løftet hovedet en del i disse dage med hensyn til, hvordan man kan udnytte LPDDR i datacentret på grund af strømmen. Vi har endda set GDDR blive brugt i nogle AI-inferensapplikationer, såvel som alle de gamle hukommelsessystemer. De forsøger nu at presse så mange DDR5'er på et fodaftryk som muligt. Jeg har set enhver arkitektur, du kan komme i tanke om, uanset om det er DDR, HBM, GDDR eller andre. Det afhænger af din processorkerne i forhold til, hvad din samlede værditilvækst er, og så hvordan du kan bryde igennem netop din arkitektur. Hukommelsessystemet, der følger med, så du kan skulpturere din CPU og din hukommelsesarkitektur, alt efter hvad der er tilgængeligt.
Og en: Et andet problem er ikke-volatiliteten. Hvis AI'en skal forholde sig til strømintervallet mellem at køre en IoT-baseret AI, for eksempel, så skal vi have en masse strøm slukket og tændt, og al denne information til AI-træningen skal rotere igen og igen. Hvis vi har en form for løsninger, hvor vi kan gemme de vægte ind i chippen, så vi ikke altid skal bevæge os frem og tilbage for den samme vægt, så vil det være en masse strømbesparelser, især for IoT-baseret AI. Der vil være en anden løsning til at hjælpe med disse strømbehov.
Schirrmeister: Det, jeg finder fascinerende, set fra et NoC-perspektiv, er, hvor du skal optimere disse stier fra en processor, der går gennem en NoC, for at få adgang til en hukommelsesgrænseflade med en controller, der potentielt går gennem UCIe for at sende en chiplet til en anden chiplet, som så har hukommelse i det. Det er ikke, at Von Neumann-arkitekturer er døde. Men der er så mange variationer nu, afhængigt af den arbejdsbyrde, du ønsker at beregne. De skal betragtes i sammenhæng med hukommelsen, og hukommelsen er kun ét aspekt. Hvor du får data fra datalokaliteten, hvordan er det arrangeret i denne DRAM? Vi arbejder gennem alle disse ting, såsom performance-analyse af minder og derefter optimere systemarkitekturen på det. Det ansporer en masse innovation til nye arkitekturer, som jeg aldrig tænkte på, da jeg var på universitetet og lærte om Von Neumann. I den yderste anden ende har du ting som masker. Der er en hel del flere arkitekturer nu imellem, der skal tages i betragtning, og det er drevet af hukommelsesbåndbredden, beregningsmuligheder og så videre, der ikke vokser i samme hastighed.
Hvid: Der er en tendens, der involverer disaggregeret databehandling eller distribueret databehandling, hvilket betyder, at arkitekten skal have flere værktøjer til deres rådighed. Hukommelseshierarkiet er blevet udvidet. Der er semantik inkluderet, samt CXL og forskellige hybridhukommelser, der er tilgængelige til flash og i DRAM. En parallel applikation til datacentret er bilindustrien. Automotive havde altid denne sensor beregnet med ECU'er (elektroniske styreenheder). Jeg er fascineret af, hvordan det har udviklet sig til datacentret. Spol frem, og i dag har vi distribueret compute noder, kaldet domænecontrollere. Det er det samme. Det forsøger at adressere, at magt måske ikke er så stor en aftale, fordi omfanget af computere ikke er så stort, men latency er bestemt en stor sag med bilindustrien. ADAS har brug for superhøj båndbredde, og du har forskellige afvejninger. Og så har du flere mekaniske sensorer, men lignende begrænsninger i et datacenter. Du har koldt lager, der ikke behøver at have lav latency, og så har du andre applikationer med høj båndbredde. Det er fascinerende at se, hvor meget værktøjerne og mulighederne for arkitekten har udviklet sig. Branchen har gjort et rigtig godt stykke arbejde med at reagere, og vi leverer alle sammen forskellige løsninger, der kommer ind på markedet.
SE: Hvordan har værktøjer til hukommelsesdesign udviklet sig?
Schirrmeister: Da jeg startede med mine første par chips i 90'erne, var det mest brugte systemværktøj Excel. Siden da har jeg altid håbet, at det kunne gå i stykker på et tidspunkt for de ting, vi gør på systemniveau, hukommelse, båndbreddeanalyse og så videre. Dette påvirkede mine hold en del. På det tidspunkt var det meget avancerede ting. Men til Randys pointe, nu skal visse komplekse ting simuleres på et niveau af troskab, som tidligere ikke var muligt uden beregningen. For at give et eksempel kan antagelse af en vis latenstid for en DRAM-adgang føre til dårlige arkitekturbeslutninger og potentielt forkert design af datatransportarkitekturer på chip. Bagsiden er også sand. Hvis du altid antager worst case, vil du overdesigne arkitekturen. At have værktøjer til at udføre DRAM og ydeevneanalyse og have de rigtige modeller til rådighed for controllerne gør det muligt for en arkitekt at simulere det hele, det er et fascinerende miljø at være i. Mit håb fra 90'erne om, at Excel på et tidspunkt kan bryde som en Værktøj på systemniveau kan faktisk blive til virkelighed, fordi visse af de dynamiske påvirkninger, du ikke længere kan gøre i Excel, fordi du skal simulere dem ud - især når du indsætter en die-to-die-grænseflade med PHY-karakteristika og derefter forbinder lag egenskaber som al kontrol af om alt var korrekt og potentielt gensende data. Hvis disse simuleringer ikke bliver udført, vil det resultere i suboptimal arkitektur.
Jern: Det første trin i de fleste evalueringer, vi laver, er at give dem hukommelsestestbordet til at begynde at se på DRAM-effektiviteten. Det er et stort skridt, selv at gøre ting så simple som at køre lokale værktøjer til at lave DRAM-simulering, men så gå ind i fuld-blæste simuleringer. Vi ser flere kunder, der efterspørger den type simulering. At sikre, at din DRAM-effektivitet er oppe i de høje 90'ere er et meget vigtigt første skridt i enhver evaluering.
Woo: En del af grunden til, at du ser fremkomsten af komplette systemsimuleringsværktøjer er, at DRAM'er er blevet meget mere komplicerede. Det er meget svært nu at være lige i baren for nogle af disse komplekse arbejdsbelastninger ved at bruge simple værktøjer som Excel. Hvis du ser på dataarket for DRAM i 90'erne, var disse datablade som 40 sider. Nu er de hundredvis af sider. Det taler bare om enhedens kompleksitet for at få de høje båndbredder ud. Du kobler det sammen med det faktum, at hukommelsen er sådan en driver i systemomkostninger, såvel som båndbredde og latens relateret til processorens ydeevne. Det er også en stor driver i kraft, så du skal simulere på et meget mere detaljeret niveau nu. Med hensyn til værktøjsflow forstår systemarkitekter, at hukommelse er en stor drivkraft. Så værktøjerne skal være mere sofistikerede, og de skal interface til andre værktøjer meget godt, så systemarkitekten får det bedste globale overblik over, hvad der foregår - især med hvordan hukommelsen påvirker systemet.
Og en: Når vi bevæger os til AI-æraen, bliver der brugt mange multi-core-systemer, men vi ved ikke, hvilke data der går hvorhen. Det går også mere parallelt med chippen. Størrelsen på hukommelsen er meget større. Hvis vi bruger ChatGPT-typen af AI, så kræver datahåndteringen for modellerne omkring 350 MB data, hvilket er en enorm mængde data kun for en vægt, og det faktiske input/output er meget større. Denne stigning i mængden af data, der kræves, betyder, at der er mange sandsynlige effekter, vi ikke har set før. Det er en ekstremt udfordrende test at se alle de fejl, der er relateret til denne store mængde hukommelse. Og ECC bruges overalt, også i SRAM, som ikke traditionelt brugte ECC, men nu er det meget almindeligt for de største systemer. Test for alt dette er meget udfordrende og skal understøttes af EDA-løsninger for at teste alle disse forskellige forhold.
SE: Hvilke udfordringer står ingeniørteams over for i det daglige?
Hvid: På en given dag vil du finde mig i laboratoriet. Jeg smøger ærmerne op, og jeg har fået mine hænder snavsede, stikke ledninger, lodde, og hvad der ellers. Jeg tænker meget på post-silicium validering. Vi talte om tidlig simulering og on-die-værktøjer - BiST og den slags. I slutningen af dagen, inden vi sender, ønsker vi at lave en form for systemvalidering eller test på enhedsniveau. Vi talte om, hvordan man overvinder hukommelsesvæggen. Vi samlokaliserer hukommelse, HBM, sådan noget. Hvis vi ser på emballageteknologiens udvikling, startede vi med blyholdige pakker. De var ikke særlig gode til signalintegritet. Årtier senere gik vi over til optimeret signalintegritet, som ball grid arrays (BGA'er). Vi kunne ikke få adgang til det, hvilket betød, at du ikke kunne teste det. Så vi fandt på dette koncept kaldet en enhedsinterposer - en BGA interposer - og det gjorde det muligt for os at sandwiche en speciel armatur, der dirigerede signaler ud. Så kunne vi koble den til testudstyret. Spol frem til i dag, og nu har vi HBM og chiplets. Hvordan lægger jeg mit armatur ind imellem på siliciummellemlægget? Det kan vi ikke, og det er kampen. Det er en udfordring, der holder mig vågen om natten. Hvordan udfører vi fejlanalyse i marken med en OEM- eller systemkunde, hvor de ikke får de 90 % effektivitet. Der er flere fejl i linket, de kan ikke initialiseres korrekt, og træningen virker ikke. Er det et systemintegritetsproblem?
Schirrmeister: Vil du ikke hellere gøre dette hjemmefra med en virtuel grænseflade end at gå til laboratoriet? Er svaret ikke mere analyse, du bygger ind i chippen? Med chiplets integrerer vi alt endnu mere. At få dit loddekolbe derind er ikke rigtig en mulighed, så der skal være en måde for on-chip-analyser. Vi har det samme problem for NoC. Folk kigger på NoC, og du sender dataene, og så er det væk. Vi har brug for analyserne til at lægge der, så folk kan foretage fejlretning, og det strækker sig til produktionsniveauet, så du endelig kan arbejde hjemmefra og gøre det hele baseret på chipanalyse.
Jern: Især med hukommelse med høj båndbredde kan du ikke fysisk komme derind. Når vi licenserer PHY, har vi også et produkt, der passer til det, så du kan sætte øjnene på hver eneste af de 1,024 bits. Du kan begynde at læse og skrive DRAM fra værktøjet, så du ikke fysisk behøver at komme derind. Jeg kan godt lide interposer-idéen. Vi tager nogle stifter ud af interposeren under test, hvilket du ikke kan gøre i systemet. Det er virkelig en udfordring at komme ind i disse 3D-systemer. Selv fra et designværktøjsflowsynspunkt ser det ud til, at de fleste virksomheder laver deres eget individuelle flow på mange af disse 2.5D-værktøjer. Vi er begyndt at sammensætte en mere standardiseret måde at bygge et 2.5D-system på, fra signalintegritet, kraft, hele flowet.
Hvid: Mens tingene går videre, håber jeg, at vi stadig kan bevare det samme niveau af nøjagtighed. Jeg er med i UCIe form factor compliance-gruppen. Jeg ser på, hvordan man karakteriserer en kendt god terning, en gylden terning. Til sidst vil dette tage meget mere tid, men vi vil finde et lykkeligt medium mellem ydeevnen og nøjagtigheden af den test, vi har brug for, og den fleksibilitet, der er indbygget.
Schirrmeister: Hvis jeg ser nærmere på chiplets og deres indførelse i et mere åbent produktionsmiljø, er test en af de større udfordringer i måden at få det til at fungere rigtigt. Hvis jeg er en stor virksomhed, og jeg kontrollerer alle sider af det, så kan jeg begrænse tingene passende, så test og så videre bliver gennemførligt. Hvis jeg vil gå til UCIe-sloganet om, at UCI kun er ét bogstav væk fra PCI, og jeg forestiller mig en fremtid, hvor UCIe-samling fra et produktionsperspektiv bliver som PCI-slots i en pc i dag, så er testaspekterne for det virkelig. udfordrende. Vi skal finde en løsning. Der er masser af arbejde at gøre.
Relaterede artikler
Hukommelsens fremtid (Del 1 af ovenstående afrundes)
Fra forsøg på at løse termiske og strømmæssige problemer til rollerne som CXL og UCIe rummer fremtiden en række muligheder for hukommelse.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://semiengineering.com/rethinking-memory/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 2016
- 3d
- 40
- a
- Om
- over
- adgang
- Adgang
- nøjagtighed
- faktiske
- faktisk
- ADA'er
- tilføje
- adresse
- Vedtagelse
- fremskreden
- Fordel
- fordele
- igen
- AI
- AI -træning
- AI / ML
- Alle
- tilladt
- tillader
- også
- altid
- beløb
- an
- analyse
- analytics
- ,
- En anden
- besvare
- enhver
- længere
- overalt
- Anvendelse
- applikationer
- passende
- arkitekter
- arkitektur
- ER
- OMRÅDE
- omkring
- anbragt
- Array
- AS
- spørge
- udseende
- aspekter
- Assembly
- antage
- At
- Forsøg på
- automotive
- til rådighed
- væk
- tilbage
- Bad
- bold
- båndbredde
- Bar
- baseret
- I bund og grund
- grundlag
- BE
- fordi
- bliver
- bliver
- været
- før
- være
- fordele
- BEDSTE
- Bedre
- mellem
- Big
- større
- Bit
- Pause
- bringe
- bygge
- bygget
- virksomhed
- forretningsudvikling
- men
- by
- kadence
- kaldet
- kom
- CAN
- Kan få
- kapaciteter
- tilfælde
- center
- vis
- sikkert
- kæde
- udfordre
- udfordringer
- udfordrende
- karakteristika
- karakterisere
- kontrol
- chip
- Chips
- klasse
- klar
- Cloud
- forkølelse
- Kølig opbevaring
- kombinationer
- Kom
- kommer
- Fælles
- Virksomheder
- selskab
- komplekse
- kompleksitet
- Compliance
- kompliceret
- Compute
- computere
- computing
- Konceptet
- betingelser
- Tilslut
- betragtes
- begrænsninger
- sammenhæng
- kontrast
- kontrol
- controller
- Samtale
- Core
- korrigere
- Koste
- kunne
- Par
- CPU
- skaber
- kunde
- Kunder
- data
- Data Center
- datasæt
- dag
- dag til dag
- Dage
- døde
- deal
- årtier
- afgørelser
- definitivt
- krav
- Afhængigt
- afhænger
- Design
- designe
- detaljeret
- Udvikling
- enhed
- Die
- forskellige
- svært
- direkte
- Direktør
- diskussion
- bortskaffelse
- Distinguished
- distribueret
- distribueret computing
- do
- gør
- Er ikke
- gør
- domæne
- dominerende
- færdig
- Dont
- ned
- drevet
- driver
- i løbet af
- dynamisk
- Tidligt
- effekter
- effektivitet
- effektiv
- elektronisk
- ende
- energi
- Engineering
- Hele
- Miljø
- udstyr
- Era
- fejl
- især
- Ether (ETH)
- evaluering
- evalueringer
- Endog
- til sidst
- Hver
- at alt
- overalt
- evolution
- udvikle sig
- udviklet sig
- udvikler
- eksempel
- Excel
- udvidet
- dyrt
- udvider
- ekstrem
- ekstremt
- Øjne
- Ansigtet
- Faktisk
- faktor
- Manglende
- fascinerende
- FAST
- gennemførlig
- fyr
- troskab
- felt
- Figur
- Endelig
- Finde
- Fornavn
- Blink
- Fleksibilitet
- Flip
- flow
- følger
- Fodspor
- Til
- formular
- frem
- Videresend
- fundet
- frank
- fra
- fuld
- yderligere
- fremtiden
- få
- få
- Giv
- given
- Global
- Go
- Goes
- gå
- Golden
- gået
- godt
- godt arbejde
- fik
- Grid
- gruppe
- Dyrkning
- havde
- Håndtering
- hænder
- Gem
- Have
- have
- hoved
- hjælpe
- hierarki
- Høj
- besidder
- Home
- håber
- Hvordan
- How To
- HTML
- HTTPS
- kæmpe
- Hundreder
- Hybrid
- i
- idé
- if
- billede
- påvirket
- påvirker
- vigtigt
- Forbedre
- in
- Tilskyndelse
- medtaget
- forkert
- Forøg
- stigende
- individuel
- industrien
- oplysninger
- Innovation
- indvendig
- integrere
- integritet
- sammenkobler
- grænseflade
- ind
- involverer
- spørgsmål
- spørgsmål
- IT
- ITS
- selv
- Job
- lige
- Kend
- kendt
- lab
- stor
- større
- største
- Latency
- senere
- lag
- føre
- læring
- brev
- Niveau
- Licens
- ligesom
- Limited
- LINK
- links
- lokale
- Se
- leder
- Lot
- masser
- Lav
- vedligeholde
- lave
- Making
- ledelse
- leder
- Produktion
- mange
- Marked
- max-bredde
- kan være
- me
- midler
- betød
- mekanisk
- medium
- Memories
- Hukommelse
- måske
- modeller
- mere
- mest
- bevæge sig
- flyttet
- bevægelse
- flytning
- meget
- my
- Behov
- behov
- aldrig
- Ny
- nat
- noder
- nu
- nummer
- of
- off
- Gammel
- on
- ONE
- kun
- åbent
- Muligheder
- Optimer
- optimeret
- optimering
- Option
- Indstillinger
- or
- ordrer
- Andet
- Andre
- ud
- samlet
- Overvind
- egen
- pakker
- emballage
- sider
- Parallel
- del
- særlig
- passerer
- sti
- stier
- PC
- Mennesker
- udføre
- ydeevne
- perspektiv
- fysisk
- Fysisk
- fyr
- planet
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- mulig
- potentielt
- magt
- præsident
- tidligere
- sandsynligvis
- Problem
- Processor
- processorer
- Produkt
- produktstyring
- produktion
- Program
- passende
- korrekt
- give
- sætte
- spørgsmål
- helt
- hæve
- Sats
- hellere
- Læsning
- virkelig
- relaterede
- stole
- påkrævet
- Kræver
- løse
- reagere
- resultere
- Rid
- højre
- Rise
- roller
- Roll
- Kør
- kører
- samme
- Gem
- Besparelser
- siger
- Scale
- Anden
- se
- se
- synes
- set
- semantik
- halvleder
- send
- sensor
- sensorer
- servere
- flere
- ark
- skifte
- skib
- side
- sider
- Siemens
- Signal
- signaler
- Silicon
- lignende
- Simpelt
- simulation
- simuleringer
- siden
- enkelt
- Størrelse
- spillemaskiner
- So
- Software
- løsninger
- Løsninger
- nogle
- sofistikeret
- Taler
- særligt
- brugt
- Presse
- stable
- stablet
- stabling
- standardiseret
- standpunkt
- starte
- påbegyndt
- Starter
- Trin
- Steve
- steven
- Stadig
- opbevaring
- butik
- Kamp
- sådan
- Understøttet
- sikker
- systemet
- Systemer
- bord
- Tag
- Tal
- hold
- teknolog
- Teknologier
- vilkår
- prøve
- Test
- tests
- end
- at
- Fremtiden
- deres
- Them
- derefter
- Der.
- termisk
- Disse
- de
- ting
- ting
- tror
- Tredje
- denne
- dem
- tænkte
- Gennem
- tid
- til
- i dag
- sammen
- værktøj
- værktøjer
- top
- HELT
- kompromiser
- traditionelle
- traditionelt
- Kurser
- transportere
- Trend
- sand
- forsøger
- to
- to tredjedele
- typen
- forstå
- enheder
- universitet
- us
- brug
- anvendte
- ved brug af
- validering
- værdi
- variationer
- forskellige
- meget
- vice
- Vice President
- Specifikation
- Virtual
- af
- gå
- Væglampe
- ønsker
- var
- Vej..
- we
- vægt
- GODT
- var
- Hvad
- uanset
- hvornår
- hvorvidt
- som
- mens
- hvid
- Hele
- hvorfor
- vilje
- med
- uden
- Woo
- Arbejde
- arbejde hjemmefra
- arbejder
- Værst
- skrivning
- dig
- Din
- zephyrnet