Kilde: rawpixel.com
Conversational AI er en applikation af LLM'er, der har udløst en masse buzz og opmærksomhed på grund af dens skalerbarhed på tværs af mange industrier og use cases. Mens samtalesystemer har eksisteret i årtier, har LLM'er bragt det kvalitetsfremstød, der var nødvendigt for deres implementering i stor skala. I denne artikel vil vi bruge den mentale model vist i figur 1 til at dissekere samtale-AI-applikationer (jf. Opbygning af AI-produkter med en holistisk mental model for en introduktion til den mentale model). Efter at have overvejet markedsmulighederne og forretningsværdien af konversations-AI-systemer, vil vi forklare det yderligere "maskineri" i form af data, LLM-finjustering og samtaledesign, der skal konfigureres for at gøre samtaler ikke kun mulige, men også nyttige og fornøjelig.
1. Mulighed, værdi og begrænsninger
Traditionelt UX-design er bygget op omkring et væld af kunstige UX-elementer, swipes, tryk og klik, hvilket kræver en indlæringskurve for hver ny app. Ved at bruge konversations-AI kan vi gøre op med denne travlhed og erstatte den med den elegante oplevelse af en naturligt flydende samtale, hvor vi kan glemme overgangene mellem forskellige apps, vinduer og enheder. Vi bruger sproget, vores universelle og velkendte protokol til kommunikation, til at interagere med forskellige virtuelle assistenter (VA'er) og udføre vores opgaver.
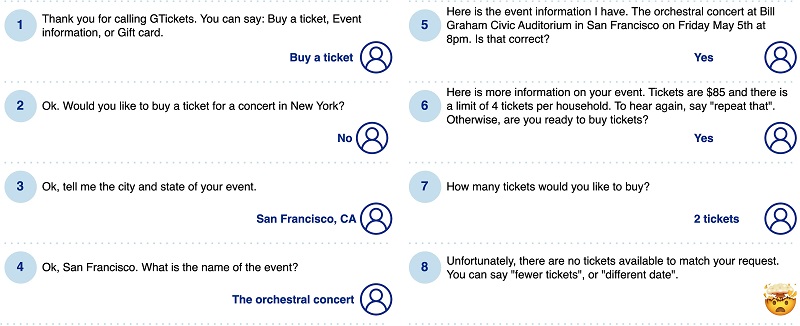
Conversational UI'er er ikke ligefrem det nye hot stuff. Interaktive stemmesvarssystemer (IVR'er) og chatbots har eksisteret siden 1990'erne, og store fremskridt inden for NLP er blevet fulgt tæt af bølger af håb og udvikling for stemme- og chatgrænseflader. Men før LLM'ernes tid blev de fleste af systemerne implementeret i det symbolske paradigme, baseret på regler, nøgleord og samtalemønstre. De var også begrænset til et specifikt, foruddefineret domæne af "kompetence", og brugere, der vovede sig uden for disse, ville snart ramme en blindgyde. Alt i alt blev disse systemer udvundet med potentielle fejlpunkter, og efter et par frustrerende forsøg kom mange brugere aldrig tilbage til dem. Følgende figur illustrerer et eksempel på en dialog. En bruger, der ønsker at bestille billetter til en bestemt koncert, gennemgår tålmodigt et detaljeret forhørsforløb, for til sidst at finde ud af, at koncerten er udsolgt.
Som en muliggørende teknologi kan LLM'er bringe samtalegrænseflader til nye niveauer af kvalitet og brugertilfredshed. Samtalesystemer kan nu vise meget bredere verdensviden, sproglig kompetence og samtaleevne. Ved at udnytte fortrænede modeller kan de også udvikles i meget kortere tidsrum, da det kedelige arbejde med at kompilere regler, nøgleord og dialogstrømme nu er erstattet af den statistiske viden om LLM. Lad os se på to fremtrædende applikationer, hvor samtale-AI kan give værdi i skala:
- Kundesupport og mere generelt applikationer, der bruges af et stort antal brugere, som ofte fremsætter lignende anmodninger. Her har virksomheden, der yder kundesupporten, en klar informationsfordel i forhold til brugeren og kan udnytte dette til at skabe en mere intuitiv og behagelig brugeroplevelse. Overvej tilfældet med ombooking af et fly. For mig selv, en ret hyppig flyver, er dette noget, der sker 1-2 gange om året. Ind i mellem har jeg en tendens til at glemme detaljerne i processen, for ikke at tale om brugergrænsefladen for et specifikt flyselskab. I modsætning hertil har flyselskabets kundesupport anmodninger om ombooking foran og i midten af deres operationer. I stedet for at afsløre ombookingsprocessen via en kompleks grafisk grænseflade, kan dens logik "skjules" for kunder, der kontakter supporten, og de kan bruge sproget som en naturlig kanal til at foretage deres ombooking. Selvfølgelig vil der stadig være en "lang hale" af mindre velkendte anmodninger. Forestil dig for eksempel et spontant humørsving, der presser en virksomhedskunde til at tilføje sin elskede hund som overskydende bagage til en booket flyrejse. Disse mere individuelle anmodninger kan videregives til menneskelige agenter eller dækkes via et internt videnstyringssystem, der er forbundet med den virtuelle assistent.
- Videnstyring som er baseret på en stor mængde data. For mange moderne virksomheder er den interne viden, de akkumulerer i løbet af år med drift, iteration og læring, et kerneaktiv og en differentieringsfaktor - hvis den lagres, administreres og tilgås på en effektiv måde. Når de sidder på et væld af data, der er skjult i samarbejdsværktøjer, interne wiki'er, vidensbaser osv., formår de ofte ikke at omdanne det til brugbar viden. Når medarbejderne forlader, bliver nye medarbejdere ombord, og du aldrig kommer til at færdiggøre den dokumentationsside, du startede for tre måneder siden, bliver værdifuld viden offer for entropi. Det bliver mere og mere vanskeligt at finde en vej gennem den interne datalabyrint og få fingrene i de informationsstykker, der kræves i en specifik forretningssituation. Dette fører til enorme effektivitetstab for vidensarbejdere. For at løse dette problem kan vi udvide LLM'er med semantisk søgning på interne datakilder. LLM'er tillader at bruge spørgsmål på naturligt sprog i stedet for komplekse formelle forespørgsler til at stille spørgsmål mod denne database. Brugere kan således fokusere på deres informationsbehov frem for på strukturen af videnbasen eller syntaksen i et forespørgselssprog som SQL. Da disse systemer er tekstbaserede, arbejder de med data i et rigt semantisk rum og skaber meningsfulde forbindelser "under hætten".
Ud over disse store applikationsområder er der talrige andre applikationer, såsom telehealth, mentale sundhedsassistenter og pædagogiske chatbots, der kan strømline UX og bringe værdi til deres brugere på en hurtigere og mere effektiv måde.
Hvis dette dybdegående undervisningsindhold er nyttigt for dig, kan du abonner på vores AI-forskningsmailingliste for at blive advaret, når vi udgiver nyt materiale.
2. Data
LLM'er er oprindeligt ikke uddannet til at deltage i flydende smalltalk eller mere omfattende samtaler. I stedet lærer de at generere følgende token ved hvert inferenstrin, hvilket til sidst resulterer i en sammenhængende tekst. Denne målsætning på lavt niveau er forskellig fra udfordringen med menneskelig samtale. Samtale er utroligt intuitivt for mennesker, men det bliver utroligt komplekst og nuanceret, når du vil lære en maskine at gøre det. Lad os for eksempel se på det grundlæggende begreb om hensigter. Når vi bruger sprog, gør vi det til et bestemt formål, som er vores kommunikative hensigt - det kan være at formidle information, socialisere eller bede nogen om at gøre noget. Mens de to første er ret ligetil for en LLM (så længe den har set de nødvendige oplysninger i dataene), er sidstnævnte allerede mere udfordrende. LLM skal ikke kun kombinere og strukturere den relaterede information på en sammenhængende måde, men den skal også sætte den rigtige følelsesmæssige tone i form af bløde kriterier såsom formalitet, kreativitet, humor osv. Dette er en udfordring for samtaledesign. (jf. afsnit 5), som hænger tæt sammen med opgaven med at skabe finjusterende data.
At lave overgangen fra klassisk sproggenerering til at genkende og reagere på specifikke kommunikative hensigter er et vigtigt skridt mod bedre brugervenlighed og accept af samtalesystemer. Som for alle finjusteringsbestræbelser starter dette med kompileringen af et passende datasæt.
Finjusteringsdataene bør komme så tæt som muligt på den (fremtidige) datadistribution i den virkelige verden. For det første skal det være samtaledata (dialog). For det andet, hvis din virtuelle assistent vil være specialiseret i et specifikt domæne, bør du prøve at samle finjusteringsdata, der afspejler den nødvendige domæneviden. For det tredje, hvis der er typiske flows og forespørgsler, der vil være tilbagevendende ofte i din ansøgning, som i tilfældet med kundesupport, så prøv at inkorporere forskellige eksempler på disse i dine træningsdata. Følgende tabel viser et eksempel på samtale finjusteringsdata fra 3K-samtaledatasæt til ChatBot, som er gratis tilgængelig på Kaggle:
Manuel oprettelse af samtaledata kan blive en dyr virksomhed - crowdsourcing og brug af LLM'er til at hjælpe dig med at generere data er to måder at skalere op på. Når dialogdataene er indsamlet, skal samtalerne vurderes og kommenteres. Dette giver dig mulighed for at vise både positive og negative eksempler til din model og skubbe den til at opfange karakteristikaene ved de "rigtige" samtaler. Vurderingen kan ske enten med absolutte score eller en rangordning af forskellige muligheder mellem hinanden. Sidstnævnte tilgang fører til mere nøjagtige finjusteringsdata, fordi mennesker normalt er bedre til at rangere flere muligheder end at vurdere dem isoleret.
Med dine data på plads er du klar til at finjustere din model og berige den med yderligere muligheder. I det næste afsnit vil vi se på finjustering, integration af yderligere information fra hukommelse og semantisk søgning og tilslutning af agenter til dit samtalesystem for at sætte det i stand til at udføre specifikke opgaver.
3. Samling af samtalesystemet
Et typisk samtalesystem er bygget med en samtaleagent, der orkestrerer og koordinerer systemets komponenter og muligheder, såsom LLM, hukommelsen og eksterne datakilder. Udviklingen af samtale-AI-systemer er en meget eksperimenterende og empirisk opgave, og dine udviklere vil være i en konstant frem og tilbage mellem at optimere dine data, forbedre finjusteringsstrategien, lege med yderligere komponenter og forbedringer og teste resultaterne . Ikke-tekniske teammedlemmer, herunder produktchefer og UX-designere, vil også løbende teste produktet. Baseret på deres kundeopdagelsesaktiviteter er de i en god position til at forudse fremtidige brugeres samtalestil og indhold og bør aktivt bidrage med denne viden.
3.1 Undervisning af samtalefærdigheder til din LLM
Til finjustering har du brug for dine finjusteringsdata (jf. afsnit 2) og en foruddannet LLM. LLM'er ved allerede meget om sproget og verden, og vores udfordring er at lære dem principperne for samtale. Ved finjustering er måludgangene tekster, og modellen vil blive optimeret til at generere tekster, der ligner målene så meget som muligt. Til overvåget finjustering skal du først klart definere den samtale-AI-opgave, du ønsker, at modellen skal udføre, indsamle data og køre og gentage finjusteringsprocessen.
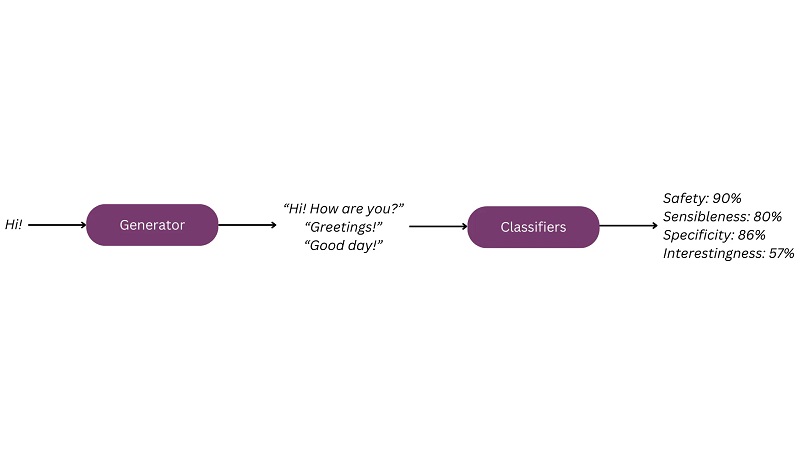
Med hypen omkring LLM'er er der opstået en række finjusteringsmetoder. For et ret traditionelt eksempel på finjustering til samtale, kan du henvise til beskrivelsen af LaMDA-modellen.[1] LaMDA blev finjusteret i to trin. Først bruges dialogdata til at lære modellen samtalefærdigheder (“generativ” finjustering). Derefter bruges etiketterne produceret af annotatorer under vurderingen af dataene til at træne klassifikatorer, der kan vurdere modellens output ud fra ønskede egenskaber, som omfatter fornuftighed, specificitet, interessanthed og sikkerhed (“diskriminerende” finjustering). Disse klassifikatorer bruges derefter til at styre modellens adfærd mod disse attributter.
Derudover er faktuel begrundelse - evnen til at basere deres output i troværdig ekstern information - en vigtig egenskab ved LLM'er. For at sikre faktuel begrundelse og minimere hallucinationer blev LaMDA finjusteret med et datasæt, der involverer opkald til et eksternt informationssøgningssystem, når der kræves ekstern viden. Således lærte modellen først at hente faktuelle oplysninger, hver gang brugeren lavede en forespørgsel, der krævede ny viden.
En anden populær finjusteringsteknik er Reinforcement Learning from Human Feedback (RLHF)[2]. RLHF "omdirigerer" læreprocessen i LLM fra den ligefremme, men kunstige næste-token forudsigelsesopgave til at lære menneskelige præferencer i en given kommunikativ situation. Disse menneskelige præferencer er direkte indkodet i træningsdataene. Under annoteringsprocessen bliver mennesker præsenteret for prompter og enten skriver det ønskede svar eller rangordner en række eksisterende svar. LLM'ens adfærd optimeres derefter til at afspejle den menneskelige præference.
3.2 Tilføjelse af eksterne data og semantisk søgning
Ud over at kompilere samtaler for at finjustere modellen, vil du måske forbedre dit system med specialiserede data, der kan udnyttes under samtalen. For eksempel kan dit system have brug for adgang til eksterne data, såsom patenter eller videnskabelige artikler, eller interne data, såsom kundeprofiler eller din tekniske dokumentation. Dette gøres normalt via semantisk søgning (også kendt som retrieval-augmented generation eller RAG)[3]. De yderligere data gemmes i en database i form af semantiske indlejringer (jf. denne artikel for en forklaring af indlejringer og yderligere referencer). Når brugeranmodningen kommer ind, er den forbehandlet og transformeret til en semantisk indlejring. Den semantiske søgning identificerer derefter de dokumenter, der er mest relevante for anmodningen, og bruger dem som kontekst for prompten. Ved at integrere yderligere data med semantisk søgning kan du reducere hallucinationer og give mere nyttige, faktuelt funderede svar. Ved løbende at opdatere indlejringsdatabasen kan du også holde viden og svar fra dit system opdateret uden konstant at køre din finjusteringsproces igen.
3.3 Hukommelse og kontekstbevidsthed
Forestil dig at gå til en fest og møde Peter, en advokat. Du bliver begejstret og begynder at pitche den juridiske chatbot, du i øjeblikket planlægger at bygge. Peter ser interesseret ud, læner sig mod dig, uhm og nikker. På et tidspunkt vil du gerne have hans mening om, hvorvidt han kunne tænke sig at bruge din app. I stedet for en informativ udtalelse, der ville kompensere for din veltalenhed, hører du: "Uhm... hvad lavede denne app igen?"
Den uskrevne kontrakt om kommunikation mellem mennesker forudsætter, at vi lytter til vores samtalepartnere og bygger vores egne talehandlinger på den kontekst, vi er med til at skabe under interaktionen. I sociale sammenhænge kendetegner fremkomsten af denne fælles forståelse en frugtbar, berigende samtale. I mere hverdagsagtige omgivelser som at reservere et restaurantbord eller købe en togbillet, er det en absolut nødvendighed for at udføre opgaven og give brugeren den forventede værdi. Dette kræver, at din assistent kender historikken for den aktuelle samtale, men også af tidligere samtaler - for eksempel bør den ikke bede om navnet og andre personlige oplysninger om en bruger igen og igen, hver gang de starter en samtale.
En af udfordringerne ved at opretholde kontekstbevidsthed er coreference resolution, dvs. at forstå hvilke objekter der refereres til med pronominer. Mennesker bruger intuitivt mange kontekstuelle signaler, når de fortolker sprog - for eksempel kan du spørge et lille barn: "Få venligst den grønne bold ud af den røde boks og bring den til mig," og barnet vil vide, at du mener bolden , ikke kassen. For virtuelle assistenter kan denne opgave være ret udfordrende, som illustreret af følgende dialog:
Assistent: Tak, jeg vil nu bestille dit fly. Vil du også bestille et måltid til din flyrejse?
Bruger: Uhm... kan jeg beslutte senere, om jeg vil have det?
Assistent: Beklager, denne flyvning kan ikke ændres eller aflyses senere.
Her kan assistenten ikke genkende, at pronomenet it fra brugeren refererer ikke til flyveturen, men til måltidet, hvilket kræver endnu en iteration for at rette op på denne misforståelse.
3.4 Ekstra autoværn
Nu og da vil selv den bedste LLM opføre sig dårligt og hallucinere. I mange tilfælde er hallucinationer almindelige nøjagtighedsproblemer - og godt, du skal acceptere, at ingen AI er 100 % nøjagtig. Sammenlignet med andre AI-systemer er "afstanden" mellem brugeren og AI'en ret lille mellem brugeren og AI'en. Et almindeligt nøjagtighedsproblem kan hurtigt blive til noget, der opfattes som giftigt, diskriminerende eller generelt skadeligt. Derudover, da LLM'er ikke har en iboende forståelse af privatlivets fred, kan de også afsløre følsomme data såsom personligt identificerbare oplysninger (PII). Du kan modarbejde denne adfærd ved at bruge ekstra autoværn. Værktøjer såsom Guardrails AI, Rebuff, NeMo Guardrails og Microsoft Guidance giver dig mulighed for at fjerne risikoen for dit system ved at formulere yderligere krav til LLM-output og blokere uønskede output.
Flere arkitekturer er mulige i konversations-AI. Følgende skema viser et simpelt eksempel på, hvordan den finjusterede LLM, eksterne data og hukommelse kan integreres af en samtaleagent, som også er ansvarlig for den hurtige konstruktion og autoværnet.

4. Brugeroplevelse og samtaledesign
Charmen ved samtalegrænseflader ligger i deres enkelhed og ensartethed på tværs af forskellige applikationer. Hvis fremtiden for brugergrænseflader er, at alle apps ser mere eller mindre ens ud, er UX-designerens job da dømt? Absolut ikke - samtale er en kunst, der skal læres til din LLM, så den kan føre samtaler, der er nyttige, naturlige og behagelige for dine brugere. Godt samtaledesign opstår, når vi kombinerer vores viden om menneskelig psykologi, lingvistik og UX-design. I det følgende vil vi først overveje to grundlæggende valg, når du bygger et samtalesystem, nemlig om du vil bruge stemme og/eller chat, samt den større kontekst af dit system. Derefter vil vi se på selve samtalerne og se, hvordan du kan designe din assistents personlighed, mens du lærer den at deltage i nyttige og samarbejdssamtaler.
4.1 Stemme versus chat
Samtalegrænseflader kan implementeres ved hjælp af chat eller stemme. I en nøddeskal er stemmen hurtigere, mens chat giver brugerne mulighed for at forblive private og drage fordel af den berigede brugergrænseflade-funktionalitet. Lad os dykke lidt dybere ned i de to muligheder, da dette er en af de første og vigtigste beslutninger, du vil møde, når du bygger en samtale-app.
For at vælge mellem de to alternativer, start med at overveje de fysiske rammer, hvor din app skal bruges. For eksempel, hvorfor er næsten alle samtalesystemer i biler, som dem, der tilbydes af Nuance Communications, baseret på stemme? Fordi chaufførens hænder allerede har travlt, og de kan ikke konstant skifte mellem rattet og et tastatur. Dette gælder også for andre aktiviteter som madlavning, hvor brugere ønsker at forblive i flowet af deres aktivitet, mens de bruger din app. Biler og køkkener er for det meste private indstillinger, så brugere kan opleve glæden ved stemmeinteraktion uden at bekymre sig om privatlivets fred eller om at genere andre. Hvis din app derimod skal bruges i offentlige omgivelser som kontoret, et bibliotek eller en togstation, er stemme muligvis ikke dit førstevalg.
Når du har forstået de fysiske rammer, skal du overveje den følelsesmæssige side. Stemme kan bruges med vilje til at overføre tone, stemning og personlighed - tilføjer dette værdi i din kontekst? Hvis du bygger din app til fritid, kan stemme øge den sjove faktor, mens en assistent til mental sundhed kunne rumme mere empati og give en potentielt urolig bruger en større udtryksform. Hvis din app derimod hjælper brugere i et professionelt miljø som handel eller kundeservice, kan en mere anonym, tekstbaseret interaktion bidrage til mere objektive beslutninger og spare dig for besværet med at designe en alt for følelsesladet oplevelse.
Som et næste skridt skal du tænke på funktionaliteten. Den tekstbaserede grænseflade giver dig mulighed for at berige samtalerne med andre medier som billeder og grafiske UI-elementer såsom knapper. For eksempel i en e-handelsassistent vil en app, der foreslår produkter ved at poste deres billeder og strukturerede beskrivelser, være langt mere brugervenlig end en, der beskriver produkter via stemmen og potentielt giver deres identifikatorer.
Lad os endelig tale om de yderligere design- og udviklingsudfordringer ved at bygge en stemme-brugergrænseflade:
- Der er et ekstra trin med talegenkendelse, der sker, før brugerinput kan behandles med LLM'er og Natural Language Processing (NLP).
- Stemme er et mere personligt og følelsesmæssigt kommunikationsmiddel - derfor er kravene til at designe en konsistent, passende og behagelig persona bag din virtuelle assistent højere, og du bliver nødt til at tage højde for yderligere faktorer af "stemmedesign" såsom klang , stress, tone og talehastighed.
- Brugere forventer, at din stemmesamtale fortsætter med samme hastighed som en menneskelig samtale. For at tilbyde en naturlig interaktion via stemmen har du brug for en meget kortere latenstid end for chat. I menneskelige samtaler er det typiske mellemrum mellem drejningerne 200 millisekunder — Denne hurtige reaktion er mulig, fordi vi begynder at konstruere vores drejninger, mens vi lytter til vores partners tale. Din stemmeassistent skal matche denne grad af flydende interaktion. For chatbots konkurrerer du derimod med tidsrum på sekunder, og nogle udviklere introducerer endda en ekstra forsinkelse for at få samtalen til at føles som en maskinskrevet chat mellem mennesker.
- Kommunikation via stemme er en lineær, enkeltstående virksomhed - hvis din bruger ikke fik, hvad du sagde, er du i en kedelig, fejltilbøjelig afklaringsløkke. Dine ture skal derfor være så kortfattede, klare og informative som muligt.
Hvis du går efter stemmeløsningen, skal du sørge for, at du ikke kun tydeligt forstår fordelene sammenlignet med chat, men også har kompetencerne og ressourcerne til at løse disse yderligere udfordringer.
4.2 Hvor vil din samtale-AI bo?
Lad os nu overveje den større kontekst, hvor du kan integrere samtale-AI. Vi kender alle chatbots på virksomhedens hjemmesider - de widgets til højre på din skærm, der dukker op, når vi åbner en virksomheds hjemmeside. Personligt, oftere end ikke, er min intuitive reaktion at lede efter Luk-knappen. Hvorfor det? Gennem indledende forsøg på at "konversere" med disse bots, har jeg lært, at de ikke kan opfylde mere specifikke informationskrav, og i sidste ende mangler jeg stadig at finde rundt på hjemmesiden. Moralen i historien? Byg ikke en chatbot, fordi den er cool og trendy – byg den snarere, fordi du er sikker på, at den kan skabe yderligere værdi for dine brugere.
Ud over den kontroversielle widget på en virksomheds hjemmeside er der flere spændende sammenhænge til at integrere de mere generelle chatbots, der er blevet mulige med LLM'er:
- Copiloter: Disse assistenter guider og rådgiver dig gennem specifikke processer og opgaver, såsom GitHub CoPilot til programmering. Normalt er copiloter "bundet" til en specifik applikation (eller en lille pakke af relaterede applikationer).
- Syntetiske mennesker (også digitale mennesker): Disse skabninger "emulerer" rigtige mennesker i den digitale verden. De ser ud, handler og taler som mennesker og har dermed også brug for rige samtaleevner. Syntetiske mennesker bruges ofte i fordybende applikationer som gaming og augmented og virtual reality.
- Digitale tvillinger: Digitale tvillinger er digitale "kopier" af processer og objekter i den virkelige verden, såsom fabrikker, biler eller motorer. De bruges til at simulere, analysere og optimere designet og adfærden af det virkelige objekt. Naturlige sproginteraktioner med digitale tvillinger giver mulighed for jævnere og mere alsidig adgang til data og modeller.
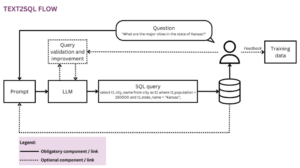
- Databaser: I dag er data tilgængelige om ethvert emne, det være sig investeringsanbefalinger, kodestykker eller undervisningsmateriale. Det, der ofte er svært, er at finde de helt specifikke data, som brugerne har brug for i en bestemt situation. Grafiske grænseflader til databaser er enten for grovkornede eller dækket af endeløse søge- og filterwidgets. Alsidige forespørgselssprog som SQL og GraphQL er kun tilgængelige for brugere med de tilsvarende færdigheder. Samtaleløsninger giver brugerne mulighed for at forespørge dataene i naturligt sprog, mens LLM, der behandler anmodningerne automatisk konverterer dem til det tilsvarende forespørgselssprog (jf. denne artikel for en forklaring af Text2SQL).
4.3 At præge en personlighed på din assistent
Som mennesker er vi tvunget til at antropomorfisere, dvs. at påføre yderligere menneskelige træk, når vi ser noget, der vagt ligner et menneske. Sproget er en af menneskehedens mest unikke og fascinerende evner, og samtaleprodukter vil automatisk blive forbundet med mennesker. Folk vil forestille sig en person bag deres skærm eller enhed - og det er god praksis ikke at overlade denne specifikke person til chancen for dine brugeres fantasi, men snarere give den en konsistent personlighed, der er tilpasset dit produkt og brand. Denne proces kaldes "persona design".
Det første trin i persona-design er at forstå de karaktertræk, du gerne vil have din persona skal vise. Ideelt set gøres dette allerede på niveau med træningsdata - for eksempel, når du bruger RLHF, kan du bede dine annotatorer om at rangere dataene efter egenskaber som hjælpsomhed, høflighed, sjov osv., for at bias modellen mod de ønskede egenskaber. Disse egenskaber kan matches med dine brand-attributter for at skabe et ensartet image, der løbende promoverer dit branding via produktoplevelsen.
Ud over generelle karakteristika bør du også tænke på, hvordan din virtuelle assistent vil håndtere specifikke situationer ud over den "lykkelige vej". Hvordan vil den f.eks. reagere på brugeranmodninger, der ligger uden for dens omfang, besvare spørgsmål om sig selv og håndtere krænkende eller vulgært sprog?
Det er vigtigt at udvikle eksplicitte interne retningslinjer for din persona, som kan bruges af dataannotatorer og samtaledesignere. Dette vil give dig mulighed for at designe din persona på en målrettet måde og holde den konsistent på tværs af dit team og over tid, da din applikation gennemgår flere iterationer og justeringer.
4.4 Gøre samtaler nyttige med "samarbejdsprincippet"
Har du nogensinde haft indtryk af at tale til en murstensvæg, mens du rent faktisk talte med et menneske? Nogle gange oplever vi, at vores samtalepartnere bare ikke er interesserede i at føre samtalen til succes. Heldigvis går tingene i de fleste tilfælde glattere, og mennesker vil intuitivt følge "samarbejdets princip", som blev introduceret af sprogfilosoffen Paul Grice. Ifølge dette princip følger mennesker, der med succes kommunikerer med hinanden, fire maksimer, nemlig kvantitet, kvalitet, relevans og måde.
Maksimum af mængde
Maksimen for kvantitet beder taleren om at være informativ og give sit bidrag så informativt som nødvendigt. På den virtuelle assistents side betyder det også, at man aktivt flytter samtalen fremad. Overvej f.eks. dette uddrag fra en e-handelsmodeapp:
Assistent: Hvilken slags beklædningsgenstand leder du efter?
Bruger: Jeg leder efter en kjole i orange.
Assistent: Lad være med: Beklager, vi har ikke orange kjoler i øjeblikket.
Gør: Beklager, vi har ikke kjoler i orange, men vi har denne flotte og meget behagelige kjole i gul: …
Brugeren håber at forlade din app med et passende element. Hvis du stopper samtalen, fordi du ikke har genstande, der passer til den nøjagtige beskrivelse, dræber du muligheden for succes. Men hvis din app kommer med forslag til alternative elementer, vil den virke mere nyttig og lade muligheden for en vellykket interaktion stå åben.
Især i stemmeinteraktioner er det vigtigt at finde den rette balance mellem at levere al den information, som brugeren kan have brug for for at få succes, mens den ikke overvældes med unødvendig information, som kan forplumre interaktionen.
Maksimal kvalitet
Kvalitetsmaksimen beder talere om at være sandfærdige og ikke sige ting, de mener er falske, eller som de mangler tilstrækkelige beviser for. Der er en masse subjektivitet og personlig tro involveret her - derfor kan denne maksime ikke projiceres direkte på LLM'er. Som vi har set, har LLM'er en tendens til at hallucinere, og denne risiko er især høj, når samtalen driver ud i mindre velkendte territorier. Yderligere autoværn kan bruges for at undgå vildledende udsagn og bringe samtalen tilbage på sporet.
Maksimal relevans
Maksimen om relevans beder os om at være – ja, relevante. Som en forudsætning er den virtuelle assistent nødt til at forstå brugerens sande hensigt. Her er et eksempel på en flyselskabsassistent, der overtræder denne regel:
Bruger: Jeg skal bruge et fly fra Berlin til Zürich i morgen tidlig.
Assistent: OK, jeg fandt følgende fly fra Berlin til Zürich til i morgen tidlig. Fly BZ36294 forlader Berlin kl. 6.30 og ankommer til Zürich kl. 8. Fly BZ96294 forlader Berlin kl. 8 og ankommer kl. 9.30. Fly BZ96294 forlader Berlin kl. 8 og ankommer til Zürich kl. 9.30. Fly BZ95614 forlader Berlin kl. 11 og ankommer til Zürich kl. 12.30. Der er også mulighed for et tilslutningsfly, i hvilket tilfælde du forlader Berlin kl. 11.45 og ankommer til Zürich kl. 3.
Bruger: Undskyld... kunne du gentage dette igen?
Assistenten overvælder brugeren med detaljerede oplysninger, som måske ikke er relevante. Ved at bryde dette op og guide brugeren til at begrænse deres søgeplads, bliver dialogen meget lettere at fordøje:
Bruger: Jeg skal bruge et fly fra Berlin til Zürich i morgen tidlig.
Assistent: Ok, jeg fandt flyafgange kl. 6.30, 8. og 11. Hvilket tidspunkt vil du gerne afsted?
Bruger: Jeg skal være i Zürich før kl.
Assistent: OK, så du kan tage flyet BZ36294. Den går kl. 6.30 og ankommer kl. 8. Skal jeg købe billetten til dig?
Bruger: Ja tak.
Maksimal måde
Endelig siger mådens maksime, at vores talehandlinger skal være klare, kortfattede og velordnede og undgå tvetydighed og uklarhed i udtryk. Din virtuelle assistent bør undgå teknisk eller intern jargon og foretrække enkle, universelt forståelige formuleringer.
Mens Grices principper er gyldige for alle samtaler uafhængigt af et specifikt domæne, kan LLM'er, der ikke er uddannet specifikt til samtale, ofte ikke opfylde dem. Når du kompilerer dine træningsdata, er det derfor vigtigt at have nok dialogeksempler, der gør det muligt for din model at lære disse principper.
Domænet for konversationsdesign udvikler sig ret hurtigt. Uanset om du allerede bygger AI-produkter eller tænker på din karriere inden for AI, opfordrer jeg dig til at grave dybere ned i dette emne (jf. de fremragende introduktioner i [5] og [6]). I takt med at AI bliver til en vare, vil godt design sammen med en forsvarlig datastrategi blive to vigtige differentiatorer for AI-produkter.
Resumé
Lad os opsummere de vigtigste ting fra artiklen. Derudover tilbyder figur 5 et "snydeark" med hovedpunkterne, som du kan downloade som reference.
- LLM'er forbedrer konversations-AI: Store sprogmodeller (LLM'er) har væsentligt forbedret kvaliteten og skalerbarheden af konversations-AI-applikationer på tværs af forskellige brancher og anvendelsesmuligheder.
- Conversational AI kan tilføje en masse værdi til applikationer med mange lignende brugeranmodninger (f.eks. kundeservice), eller som har behov for at få adgang til en stor mængde ustrukturerede data (f.eks. vidensstyring).
- Data: Finjustering af LLM'er til samtaleopgaver kræver samtaledata af høj kvalitet, der nøje afspejler interaktioner i den virkelige verden. Crowdsourcing og LLM-genererede data kan være værdifulde ressourcer til at skalere dataindsamling.
- At sætte systemet sammen: Udvikling af konversations-AI-systemer er en iterativ og eksperimentel proces, der involverer konstant optimering af data, finjustering af strategier og komponentintegration.
- Undervisning af samtalefærdigheder til LLM'er: Finjustering af LLM'er involverer træning af dem til at genkende og reagere på specifikke kommunikative hensigter og situationer.
- Tilføjelse af eksterne data med semantisk søgning: Integrering af eksterne og interne datakilder ved hjælp af semantisk søgning forbedrer AI's svar ved at give mere kontekstuelt relevant information.
- Hukommelse og kontekstbevidsthed: Effektive samtalesystemer skal opretholde kontekstbevidsthed, herunder sporing af historien om den aktuelle samtale og tidligere interaktioner, for at give meningsfulde og sammenhængende svar.
- Indstilling af autoværn: For at sikre ansvarlig adfærd bør AI-systemer til samtale anvende autoværn for at forhindre unøjagtigheder, hallucinationer og brud på privatlivets fred.
- Personadesign: At designe en konsistent persona til din samtaleassistent er afgørende for at skabe en sammenhængende og brandet brugeroplevelse. Personaegenskaber bør stemme overens med dine produkt- og brandattributter.
- Stemme vs. chat: Valget mellem stemme- og chatgrænseflader afhænger af faktorer som de fysiske rammer, følelsesmæssig kontekst, funktionalitet og designudfordringer. Overvej disse faktorer, når du beslutter dig for grænsefladen til din samtale-AI.
- Integration i forskellige sammenhænge: Conversational AI kan integreres i forskellige sammenhænge, herunder copiloter, syntetiske mennesker, digitale tvillinger og databaser, hver med specifikke use cases og krav.
- Overholdelse af samarbejdsprincippet: At følge principperne om kvantitet, kvalitet, relevans og måde i samtaler kan gøre interaktioner med samtale-AI mere nyttig og brugervenlig.

Referencer
[1] Heng-Tze Chen et al. 2022. LaMDA: Mod sikre, jordede og højkvalitetsdialogmodeller til alt.
[2] OpenAI. 2022. ChatGPT: Optimering af sprogmodeller til dialog. Hentet den 13. januar 2022.
[3] Patrick Lewis et al. 2020. Retrieval-Augmented Generation til viden-intensive NLP-opgaver.
[4] Paul Grice. 1989. Studier i ordenes vej.
[5] Cathy Pearl. 2016. Design af stemmebrugergrænseflader.
[6] Michael Cohen et al. 2004. Stemmebrugergrænsefladedesign.
Bemærk: Alle billeder er af forfatteren, medmindre andet er angivet.
Denne artikel blev oprindeligt offentliggjort den Mod datalogi og genudgivet til TOPBOTS med tilladelse fra forfatteren.
Nyder du denne artikel? Tilmeld dig flere AI-forskningsopdateringer.
Vi giver dig besked, når vi udgiver flere oversigtsartikler som denne.
Relaterede
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.topbots.com/redefining-conversational-ai-with-large-language-models/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 11
- 110
- 12
- 125
- 13
- 14
- 17
- 200
- 2016
- 2020
- 2022
- 30
- 32
- 35 %
- 41
- 65
- 7
- 70
- 8
- 9
- a
- evner
- evne
- Om
- absolutte
- Acceptere
- accept
- adgang
- af udleverede
- tilgængelig
- imødekomme
- udrette
- Ifølge
- Konto
- Ophobe
- nøjagtighed
- præcis
- tværs
- Lov
- aktivt
- aktiviteter
- aktivitet
- handlinger
- faktisk
- tilføje
- tilføje
- Yderligere
- yderligere information
- Derudover
- adresse
- Vedtagelse
- fremskridt
- Fordel
- fordele
- rådgive
- Efter
- igen
- mod
- Agent
- midler
- siden
- AI
- ai forskning
- AI-systemer
- flyselskab
- AL
- tilpasse
- justeret
- Alle
- tillade
- tillader
- næsten
- sammen
- allerede
- også
- alternativ
- alternativer
- am
- tvetydigheden
- blandt
- an
- analysere
- ,
- anonym
- En anden
- foregribe
- enhver
- app
- vises
- Anvendelse
- applikationer
- gælder
- tilgang
- passende
- apps
- ER
- områder
- omkring
- Ankommer
- Kunst
- artikel
- artikler
- kunstig
- AS
- spørg
- spørge
- vurdere
- vurderes
- vurdering
- aktiv
- hjælpe
- Assistant
- assistenter
- forbundet
- At
- Forsøg på
- opmærksomhed
- attributter
- forøge
- augmented
- forfatter
- automatisk
- til rådighed
- undgå
- undgå
- bevidsthed
- væk
- tilbage
- tilbage på sporet
- Balance
- bold
- bund
- baseret
- grundlæggende
- BE
- fordi
- bliver
- bliver
- været
- før
- bag
- være
- tro
- Tro
- elskede
- gavner det dig
- berlin
- BEDSTE
- bedste praksis
- Bedre
- mellem
- Beyond
- skævhed
- Bit
- blokering
- bog
- både
- bots
- Boks
- brand
- mærkevarer
- branding
- brud
- Breaking
- bringe
- bredere
- bragte
- bygge
- Byg en chatbot
- Bygning
- bygget
- virksomhed
- travlt
- men
- .
- knapper
- købe
- Købe
- by
- kaldet
- Opkald
- kom
- CAN
- aflyst
- kan ikke
- kapaciteter
- Karriere
- biler
- tilfælde
- tilfælde
- cathy
- center
- udfordre
- udfordringer
- udfordrende
- chance
- ændret
- Kanal
- karakter
- karakteristika
- karakteriserer
- chatbot
- chatbots
- ChatGPT
- chen
- barn
- valg
- valg
- vælge
- klar
- tydeligt
- Luk
- nøje
- Tøj
- Cloud
- kode
- cohen
- SAMMENHÆNGENDE
- sammenhængende
- samarbejde
- samling
- kombinerer
- Kom
- kommer
- behagelig
- råvare
- kommunikere
- Kommunikation
- Kommunikation
- Virksomheder
- selskab
- sammenlignet
- konkurrere
- komplekse
- komponent
- komponenter
- koncert
- kortfattet
- Adfærd
- tilsluttet
- Tilslutning
- Tilslutninger
- Overvej
- Overvejer
- konsekvent
- konstant
- konstant
- konstruere
- opbygge
- kontakt
- indhold
- sammenhæng
- sammenhænge
- kontekstuelle
- kontinuerligt
- kontrakt
- kontrast
- bidrage
- bidrager
- bidrag
- kontroversielle
- Samtale
- konversation
- samtale AI
- Samtalegrænseflader
- samtaler
- madlavning
- Cool
- samarbejde
- kooperativ
- Core
- Tilsvarende
- kunne
- Par
- kursus
- dækket
- skabe
- Oprettelse af
- kreativitet
- skabninger
- troværdig
- kriterier
- crowdsourcing
- Nuværende
- For øjeblikket
- skøger
- kunde
- Kundeservice
- Kunde support
- Kunder
- data
- datastrategi
- Database
- databaser
- døde
- deal
- årtier
- beslutte
- Beslutter
- afgørelser
- dybere
- definere
- definitivt
- Degree
- forsinkelse
- afhænger
- beskrivelse
- Design
- Designer
- designere
- designe
- ønskes
- detaljeret
- detaljer
- udvikle
- udviklet
- udviklere
- udvikling
- Udvikling
- enhed
- Enheder
- dialog
- Dialog
- forskellige
- differentiator
- svært
- DIG
- Fordøje
- digital
- Digitale tvillinger
- digital verden
- direkte
- opdagelse
- Skærm
- fordeling
- dyk
- do
- dokumentation
- dokumenter
- gør
- Dog
- gør
- domæne
- færdig
- Dont
- Doomed
- downloade
- driver
- grund
- i løbet af
- e
- e-handel
- E&T
- hver
- lettere
- uddannelsesmæssige
- Effektiv
- effektivitet
- effektiv
- enten
- elementer
- indlejring
- opstået
- fremkomsten
- fremgår
- Empati
- medarbejdere
- bemyndige
- muliggør
- tilskynde
- ende
- bestræbelser
- Endless
- engagere
- Motorer
- forbedre
- forbedringer
- Forbedrer
- fornøjelig
- nok
- berige
- beriget
- berigende
- sikre
- Enterprise
- især
- væsentlig
- etc.
- evaluere
- Endog
- til sidst
- NOGENSINDE
- bevismateriale
- præcist nok
- eksempel
- eksempler
- fremragende
- Undtagen
- overskydende
- ophidset
- spændende
- udføre
- eksisterende
- forvente
- forventet
- dyrt
- erfaring
- eksperimenterende
- Forklar
- forklaring
- udtryk
- ekstern
- Ansigtet
- faktor
- fabrikker
- faktorer
- Faktuel
- FAIL
- mislykkes
- Manglende
- Falls
- falsk
- bekendt
- fascinerende
- Mode
- hurtigere
- tilbagemeldinger
- føler sig
- Figur
- filtrere
- færdiggøre
- Finde
- Fornavn
- passer
- Fix
- fly
- Fly
- flow
- Flowing
- strømme
- Fokus
- følger
- efterfulgt
- efter
- Til
- formular
- formel
- formulering
- Heldigvis
- Videresend
- fundet
- fire
- hyppig
- hyppigt
- fra
- forsiden
- frustrerende
- Opfylde
- sjovt
- funktionalitet
- fundamental
- yderligere
- fremtiden
- spil
- kløft
- samle
- Generelt
- generelt
- generere
- generation
- få
- GitHub
- given
- Go
- Goes
- gå
- godt
- grafql
- stor
- Grøn
- Ground
- vejledning
- vejlede
- retningslinjer
- havde
- hænder
- ske
- sker
- Hård Ost
- skadelig
- Have
- he
- Helse
- høre
- hjælpe
- hjælpsom
- hende
- link.
- Skjult
- Høj
- høj kvalitet
- højere
- stærkt
- hans
- historie
- Hit
- holistisk
- håber
- håber
- HOT
- Hvordan
- Men
- HTML
- http
- HTTPS
- kæmpe
- menneskelig
- Mennesker
- Humor
- Hype
- i
- ideelt
- identifikatorer
- identificerer
- if
- illustrerer
- billede
- billeder
- fantasi
- billede
- fordybende
- implementeret
- vigtigt
- forbedret
- forbedring
- in
- dybdegående
- omfatter
- Herunder
- indarbejde
- Forøg
- utroligt
- uafhængigt
- individuel
- industrier
- Påfør
- oplysninger
- informative
- iboende
- initial
- indlede
- indgange
- i stedet
- integrere
- integreret
- Integration
- integration
- hensigt
- med vilje
- interagere
- interaktion
- interaktioner
- interaktiv
- Interaktive stemmesvarssystemer
- interesseret
- grænseflade
- grænseflader
- interne
- sammenflettede
- ind
- indføre
- introduceret
- Introduktion
- introduktioner
- intuitiv
- investering
- investeringsanbefalinger
- involverede
- involverer
- involverer
- isolation
- spørgsmål
- spørgsmål
- IT
- Varer
- iteration
- iterationer
- ITS
- selv
- IVR'er
- januar
- jargon
- Job
- fælles
- jpg
- lige
- Holde
- Nøgle
- søgeord
- Kills
- Venlig
- Kend
- viden
- Knowledge Management
- kendt
- Etiketter
- labyrint
- Mangel
- Sprog
- Sprog
- stor
- storstilet
- større
- Latency
- senere
- advokat
- førende
- Leads
- LÆR
- lærte
- læring
- Forlade
- forlader
- Legacy
- Politikker
- LÅNE
- mindre
- lad
- Niveau
- niveauer
- Leverage
- gearede
- løftestang
- Lewis
- Bibliotek
- ligger
- ligesom
- GRÆNSE
- Limited
- lingvistik
- Lytte
- leve
- logik
- Lang
- Se
- leder
- UDSEENDE
- tab
- Lot
- masser
- maskine
- lavet
- mailing
- Main
- vedligeholde
- opretholdelse
- større
- lave
- maerker
- Making
- lykkedes
- ledelse
- styringssystem
- Ledere
- måde
- mange
- Marked
- markedsmuligheder
- Match
- matchede
- materiale
- materialer
- max-bredde
- Maxim
- me
- betyde
- meningsfuld
- midler
- Medier
- medium
- møde
- Medlemmer
- Hukommelse
- mentale
- Mental sundhed
- metoder
- Michael
- microsoft
- måske
- millisekunder
- minerede
- misvisende
- misforståelse
- model
- modeller
- Moderne
- øjeblik
- måned
- humør
- moralsk
- mere
- mere effektiv
- morgen
- mest
- for det meste
- flytning
- meget
- flere
- mangfoldighed
- skal
- my
- mig selv
- navn
- nemlig
- Natural
- Naturligt sprog
- Natural Language Processing
- nødvendig
- nødvendighed
- Behov
- behov
- behov
- negativ
- aldrig
- Ny
- ny app
- næste
- NLP
- ingen
- ikke-teknisk
- Ingen
- Normalt
- bemærkede
- Begreb
- nu
- Nuance
- nummer
- talrige
- Nøddeskal
- objekt
- objektiv
- objekter
- of
- off
- tilbyde
- tilbydes
- Tilbud
- Office
- tit
- on
- engang
- ONE
- kun
- åbent
- OpenAI
- drift
- Produktion
- Udtalelse
- Muligheder
- Opportunity
- optimering
- Optimer
- optimeret
- optimering
- Option
- Indstillinger
- or
- Orange
- ordrer
- oprindeligt
- Andet
- Andre
- Ellers
- vores
- ud
- udgange
- uden for
- i løbet af
- overdrevent
- overvældende
- egen
- side
- papirer
- paradigme
- partnere
- part
- Bestået
- forbi
- Patenter
- sti
- tålmodigt
- patrick
- mønstre
- paul
- Mennesker
- per
- opfattet
- udføre
- tilladelse
- person,
- personale
- Personlighed
- Personligt
- Peter
- fysisk
- pick
- Billeder
- PIO
- pitching
- Place
- Almindeligt
- planlægning
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Punkt
- punkter
- fattige
- pop
- Populær
- position
- positiv
- Muligheden
- mulig
- potentiale
- potentielt
- praksis
- praksis
- forudsigelse
- præferencer
- forelagt
- forhindre
- princippet
- principper
- Beskyttelse af personlige oplysninger
- private
- Fortsæt
- behandle
- bearbejdet
- Processer
- forarbejdning
- produceret
- Produkt
- Produkter
- professionel
- Profiler
- Programmering
- fremskrevet
- fremtrædende
- fremmer
- protokol
- give
- giver
- leverer
- Psykologi
- offentlige
- offentliggjort
- formål
- Skub ud
- skubber
- kvalitet
- mængde
- forespørgsler
- Spørgsmål
- hurtigt
- rangerer
- Ranking
- hellere
- reaktion
- klar
- ægte
- virkelige verden
- Reality
- anerkendelse
- genkende
- anerkende
- anbefalinger
- tilbagevendende
- Rød
- Omdefinering
- reducere
- henvise
- henvisningen
- referencer
- benævnt
- refererer
- afspejler
- afspejler
- forstærkning læring
- relaterede
- frigive
- relevans
- relevant
- stole
- forblive
- gentag
- udskiftes
- svar
- anmode
- anmodninger
- påkrævet
- Krav
- Kræver
- forskning
- Ligner
- Løsning
- Ressourcer
- Svar
- reagere
- svar
- reaktioner
- ansvarlige
- Restaurant
- resulterer
- Resultater
- afsløre
- Rich
- højre
- Risiko
- Herske
- regler
- Kør
- sikker
- Sikkerhed
- Said
- samme
- tilfredshed
- gemt
- siger
- Skalerbarhed
- Scale
- skalering
- videnskabelig
- rækkevidde
- scores
- Skærm
- Søg
- Anden
- sekunder
- Sektion
- se
- set
- følsom
- Series
- tjeneste
- sæt
- indstilling
- indstillinger
- flere
- bør
- Vis
- vist
- Shows
- side
- underskrive
- betydeligt
- lignende
- Simpelt
- enkelhed
- siden
- Siddende
- Situationen
- situationer
- færdigheder
- lille
- glattere
- uddrag
- So
- Social
- socialisere
- Soft
- solgt
- løsninger
- Løsninger
- nogle
- Nogen
- noget
- sommetider
- Snart
- Kilder
- Space
- spændvidder
- tale
- Højttaler
- højttalere
- taler
- specialiserede
- specifikke
- specifikt
- specificitet
- tale
- Talegenkendelse
- hastighed
- SQL
- starte
- påbegyndt
- starter
- Statement
- udsagn
- Stater
- station
- statistiske
- forblive
- styre
- styretøj
- rat
- Trin
- Steps
- Stadig
- standsning
- opbevaret
- Story
- ligetil
- strategier
- Strategi
- strømline
- stress
- struktur
- struktureret
- undersøgelser
- stil
- væsentlig
- succes
- vellykket
- Succesfuld
- sådan
- foreslår
- egnede
- suite
- opsummere
- RESUMÉ
- support
- sikker
- Swing
- Kontakt
- symbolske
- syntaks
- syntetisk
- systemet
- Systemer
- bord
- Tag
- Takeaways
- Tal
- taler
- Taps
- mål
- mål
- Opgaver
- opgaver
- undervist
- Undervisning
- hold
- Holdkammerater
- Teknisk
- teknik
- Teknologier
- Telehealth
- vilkår
- territorier
- Test
- tekst
- end
- tak
- at
- Fremtiden
- oplysninger
- verdenen
- deres
- Them
- selv
- derefter
- Der.
- Disse
- de
- ting
- tror
- Tænker
- Tredje
- denne
- dem
- tre
- Gennem
- Dermed
- billet
- billetter
- tid
- gange
- til
- sammen
- token
- i morgen
- TONE
- også
- værktøjer
- TOPBOTS
- emne
- mod
- mod
- spor
- Sporing
- Trading
- traditionelle
- Tog
- uddannet
- Kurser
- Transform
- omdannet
- overgang
- overgange
- transmittere
- udløst
- sand
- prøv
- TUR
- Drejning
- vender
- Twins
- to
- typisk
- ui
- gennemgår
- forstå
- forståelig
- forståelse
- enestående
- Universal
- universelt
- up-to-date
- opdateringer
- opdatering
- us
- usability
- brug
- anvendte
- Bruger
- Brugererfaring
- Brugergrænseflade
- brugergrænsefladesign
- brugervenlig
- brugere
- bruger
- ved brug af
- ux
- UX design
- ux designer
- ux designere
- gyldig
- Værdifuld
- værdi
- række
- forskellige
- alsidige
- versus
- meget
- via
- Victim
- Virtual
- virtuel assistent
- Virtual reality
- Voice
- Voice Assistant
- vs
- Vulgar
- W3
- Væglampe
- ønsker
- ønsker
- var
- bølger
- Vej..
- måder
- we
- Rigdom
- Hjemmeside
- websites
- GODT
- var
- Hvad
- Hvad er
- Hjul
- hvornår
- når
- hvorvidt
- som
- mens
- WHO
- hvorfor
- vilje
- vinduer
- med
- uden
- ord
- Arbejde
- arbejdere
- world
- bekymrende
- ville
- skriver
- år
- år
- gul
- dig
- unge
- Din
- zephyrnet
- Zürich