I de sidste par år er store sprogmodeller (LLM'er) blevet fremtrædende som fremragende værktøjer, der er i stand til at forstå, generere og manipulere tekst med hidtil uset dygtighed. Deres potentielle applikationer spænder fra samtaleagenter til indholdsgenerering og informationssøgning, hvilket holder løftet om at revolutionere alle industrier. Men at udnytte dette potentiale og samtidig sikre ansvarlig og effektiv brug af disse modeller afhænger af den kritiske proces med LLM-evaluering. En evaluering er en opgave, der bruges til at måle kvaliteten og ansvaret for output fra en LLM eller generativ AI-tjeneste. Evaluering af LLM'er er ikke kun motiveret af ønsket om at forstå en models ydeevne, men også af behovet for at implementere ansvarlig AI og af behovet for at mindske risikoen for at levere misinformation eller partisk indhold og for at minimere genereringen af skadelige, usikre, ondsindede og uetiske indhold. Desuden kan evaluering af LLM'er også hjælpe med at mindske sikkerhedsrisici, især i forbindelse med hurtig datamanipulation. For LLM-baserede applikationer er det afgørende at identificere sårbarheder og implementere sikkerhedsforanstaltninger, der beskytter mod potentielle brud og uautoriseret manipulation af data.
Ved at levere vigtige værktøjer til evaluering af LLM'er med en ligetil konfiguration og et-klik tilgang, Amazon SageMaker Clarify LLM-evalueringsfunktioner giver kunder adgang til de fleste af de førnævnte fordele. Med disse værktøjer i hånden er den næste udfordring at integrere LLM-evaluering i Machine Learning and Operation (MLOps) livscyklus for at opnå automatisering og skalerbarhed i processen. I dette indlæg viser vi dig, hvordan du integrerer Amazon SageMaker Clarify LLM-evaluering med Amazon SageMaker Pipelines for at muliggøre LLM-evaluering i stor skala. Derudover giver vi kodeeksempel i dette GitHub repository for at gøre det muligt for brugerne at udføre parallel multimodel-evaluering i stor skala ved hjælp af eksempler som Llama2-7b-f, Falcon-7b og finjusterede Llama2-7b-modeller.
Hvem skal udføre LLM-evaluering?
Enhver, der træner, finjusterer eller blot bruger en forudtrænet LLM, skal evaluere den nøjagtigt for at vurdere adfærden af den applikation, der drives af den pågældende LLM. Baseret på dette princip kan vi klassificere generative AI-brugere, der har brug for LLM-evalueringskapaciteter, i 3 grupper som vist i følgende figur: modeludbydere, finjustere og forbrugere.
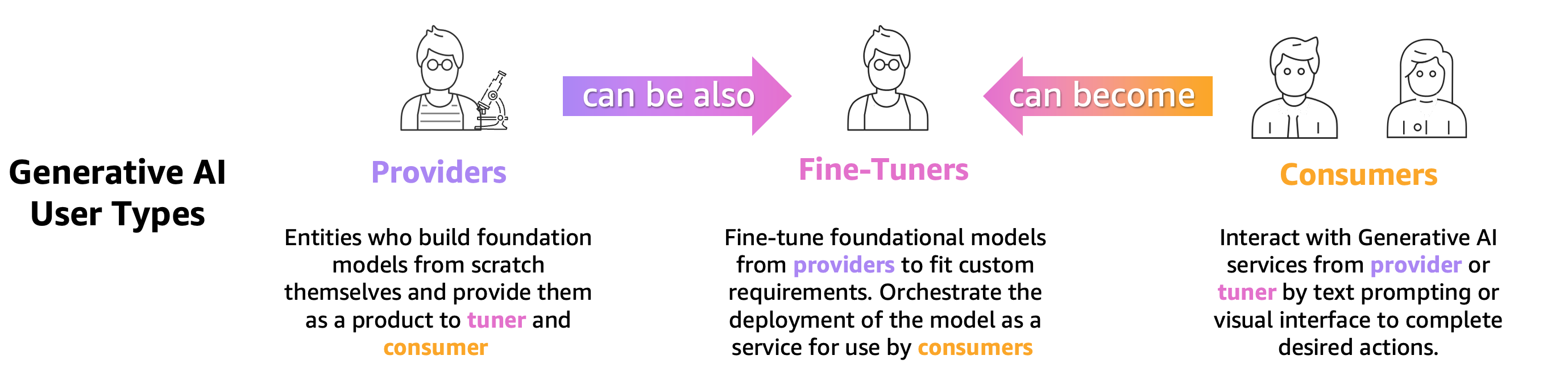
- Udbydere af grundlæggende model (FM). togmodeller, der er til generelle formål. Disse modeller kan bruges til mange downstream-opgaver, såsom udtræk af funktioner eller til at generere indhold. Hver trænet model skal benchmarkes mod mange opgaver, ikke kun for at vurdere dens præstationer, men også for at sammenligne den med andre eksisterende modeller, for at identificere områder, der skal forbedres og endelig for at holde styr på fremskridt på området. Modeludbydere skal også kontrollere tilstedeværelsen af eventuelle skævheder for at sikre kvaliteten af startdatasættet og den korrekte adfærd af deres model. Indsamling af evalueringsdata er afgørende for modeludbydere. Desuden skal disse data og målinger indsamles for at overholde kommende regler. ISO 42001, Biden Administration Bekendtgørelseog EU's AI-lov udvikle standarder, værktøjer og tests for at hjælpe med at sikre, at AI-systemer er sikre, sikre og troværdige. For eksempel har EU AI Act til opgave at give oplysninger om, hvilke datasæt der bruges til træning, hvilken computerkraft der kræves for at køre modellen, rapportere modelresultater mod offentlige/industristandard benchmarks og dele resultater af interne og eksterne tests.
- Model finjustere ønsker at løse specifikke opgaver (f.eks. sentimentklassificering, opsummering, besvarelse af spørgsmål) samt præ-trænede modeller til at tage domænespecifikke opgaver. De har brug for evalueringsmålinger genereret af modeludbydere for at vælge den rigtige foruddannede model som udgangspunkt.
De skal evaluere deres finjusterede modeller i forhold til deres ønskede use-case med opgavespecifikke eller domænespecifikke datasæt. Ofte skal de kurere og skabe deres private datasæt, da offentligt tilgængelige datasæt, selv dem, der er designet til en specifik opgave, muligvis ikke i tilstrækkelig grad fanger de nuancer, der kræves til deres særlige brugssituation.
Finjustering er hurtigere og billigere end en fuld træning og kræver hurtigere operativ iteration til implementering og test, fordi mange kandidatmodeller normalt genereres. Evaluering af disse modeller muliggør kontinuerlig modelforbedring, kalibrering og fejlretning. Bemærk, at finjustere kan blive forbrugere af deres egne modeller, når de udvikler applikationer fra den virkelige verden. - Model forbrugerne eller modeludviklere betjener og overvåger generelle formål eller finjusterede modeller i produktionen, med det formål at forbedre deres applikationer eller tjenester gennem vedtagelsen af LLM'er. Den første udfordring, de har, er at sikre, at den valgte LLM stemmer overens med deres specifikke behov, omkostninger og forventninger til ydeevne. Fortolkning og forståelse af modellens output er en vedvarende bekymring, især når privatliv og datasikkerhed er involveret (f.eks. til revision af risici og overholdelse i regulerede industrier, såsom finanssektoren). Kontinuerlig modelevaluering er afgørende for at forhindre udbredelse af skævhed eller skadeligt indhold. Ved at implementere en robust overvågnings- og evalueringsramme kan modelforbrugere proaktivt identificere og adressere regression i LLM'er, hvilket sikrer, at disse modeller bevarer deres effektivitet og pålidelighed over tid.
Sådan udføres LLM-evaluering
Effektiv modelevaluering involverer tre grundlæggende komponenter: en eller flere FM'er eller finjusterede modeller til at evaluere inputdatasættene (prompter, samtaler eller regelmæssige input) og evalueringslogikken.
For at udvælge modellerne til evaluering skal forskellige faktorer overvejes, herunder datakarakteristika, problemkompleksitet, tilgængelige beregningsressourcer og det ønskede resultat. Inputdatalageret giver de nødvendige data til træning, finjustering og test af den valgte model. Det er afgørende, at dette datalager er velstruktureret, repræsentativt og af høj kvalitet, da modellens ydeevne i høj grad afhænger af de data, den lærer af. Til sidst definerer evalueringslogikker de kriterier og målinger, der bruges til at vurdere modellens ydeevne.
Tilsammen danner disse tre komponenter en sammenhængende ramme, der sikrer en streng og systematisk vurdering af maskinlæringsmodeller, hvilket i sidste ende fører til informerede beslutninger og forbedringer i modeleffektiviteten.
Modelevalueringsteknikker er stadig et aktivt forskningsfelt. Mange offentlige benchmarks og rammer er skabt af forskerfællesskabet i de sidste par år for at dække en lang række opgaver og scenarier som f.eks. lIM, Super lim, ROR, MMLU , BIG-bænk. Disse benchmarks har leaderboards, der kan bruges til at sammenligne og sammenligne evaluerede modeller. Benchmarks, som HELM, har også til formål at vurdere målinger ud over nøjagtighedsmål, såsom præcision eller F1-score. HELM-benchmarket inkluderer målinger for retfærdighed, bias og toksicitet, som har en lige så stor betydning i den overordnede modelevalueringsscore.
Alle disse benchmarks inkluderer et sæt målinger, der måler, hvordan modellen klarer sig på en bestemt opgave. De mest berømte og mest almindelige målinger er RED (Recall-Oriented Understudy for Gisting Evaluation), BLUE (BiLingual Evaluation Understudy), eller METEOR (Metrik for evaluering af oversættelse med eksplicit bestilling). Disse målinger tjener som et nyttigt værktøj til automatiseret evaluering, der giver kvantitative mål for leksikalsk lighed mellem genereret tekst og referencetekst. De fanger dog ikke hele bredden af menneskelignende sproggenerering, som omfatter semantisk forståelse, kontekst eller stilistiske nuancer. For eksempel giver HELM ikke evalueringsdetaljer, der er relevante for specifikke use cases, løsninger til test af brugerdefinerede prompter og letfortolkede resultater, der bruges af ikke-eksperter, fordi processen kan være dyr, ikke let at skalere og kun til specifikke opgaver.
Desuden kræver opnåelse af menneskelignende sproggenerering ofte inkorporering af menneske-i-løkken for at bringe kvalitative vurderinger og menneskelig dømmekraft til at supplere de automatiserede nøjagtighedsmålinger. Menneskelig evaluering er en værdifuld metode til at vurdere LLM-output, men den kan også være subjektiv og tilbøjelig til bias, fordi forskellige menneskelige evaluatorer kan have forskellige meninger og fortolkninger af tekstkvalitet. Desuden kan menneskelig evaluering være ressourcekrævende og omkostningskrævende, og det kan kræve betydelig tid og kræfter.
Lad os dykke dybt ned i, hvordan Amazon SageMaker Clarify problemfrit forbinder prikkerne og hjælper kunderne med at udføre grundig modelevaluering og -udvælgelse.
LLM-evaluering med Amazon SageMaker Clarify
Amazon SageMaker Clarify hjælper kunder med at automatisere metrikken, herunder men ikke begrænset til nøjagtighed, robusthed, toksicitet, stereotyper og faktuel viden til automatiseret samt stil, sammenhæng, relevans for menneskebaseret evaluering og evalueringsmetoder ved at levere en ramme til evaluering af LLM'er og LLM-baserede tjenester såsom Amazon Bedrock. Som en fuldt administreret tjeneste forenkler SageMaker Clarify brugen af open source-evalueringsrammer i Amazon SageMaker. Kunder kan vælge relevante evalueringsdatasæt og -metrikker til deres scenarier og udvide dem med deres egne promptdatasæt og evalueringsalgoritmer. SageMaker Clarify leverer evalueringsresultater i flere formater for at understøtte forskellige roller i LLM-workflowet. Dataforskere kan analysere detaljerede resultater med SageMaker Clarify-visualiseringer i Notebooks, SageMaker Model Cards og PDF-rapporter. I mellemtiden kan driftsteams bruge Amazon SageMaker GroundTruth til at gennemgå og kommentere højrisiko-elementer, som SageMaker Clarify identificerer. For eksempel ved stereotyping, toksicitet, undslippet PII eller lav nøjagtighed.
Annoteringer og forstærkende læring anvendes efterfølgende til at mindske potentielle risici. Menneskevenlige forklaringer af de identificerede risici fremskynder den manuelle gennemgang og reducerer derved omkostningerne. Sammenfattende rapporter tilbyder forretningsinteressenter sammenlignende benchmarks mellem forskellige modeller og versioner, hvilket letter informeret beslutningstagning.
Følgende figur viser rammerne for evaluering af LLM'er og LLM-baserede tjenester:

Amazon SageMaker Clarify LLM evaluation er et open source Foundation Model Evaluation (FMEval) bibliotek udviklet af AWS for at hjælpe kunder med nemt at evaluere LLM'er. Alle funktionaliteterne er også blevet indarbejdet i Amazon SageMaker Studio for at muliggøre LLM-evaluering for sine brugere. I de følgende afsnit introducerer vi integrationen af Amazon SageMaker Clarify LLM-evalueringsfunktioner med SageMaker Pipelines for at muliggøre LLM-evaluering i stor skala ved at bruge MLOps-principper.
Amazon SageMaker MLOps livscyklus
Som indlægget "MLOps fundament køreplan for virksomheder med Amazon SageMaker” beskriver, MLOps er kombinationen af processer, mennesker og teknologi til at producere ML use cases effektivt.
Følgende figur viser ende-til-ende MLOps livscyklus:

En typisk rejse starter med, at en dataforsker laver en proof-of-concept (PoC) notesbog for at bevise, at ML kan løse et forretningsproblem. Under hele Proof of Concept (PoC)-udviklingen påhviler det dataforskeren at konvertere virksomhedens Key Performance Indicators (KPI'er) til maskinlæringsmodelmetrikker, såsom præcision eller falsk-positiv rate, og bruge et begrænset testdatasæt til at evaluere disse målinger. Dataforskere samarbejder med ML-ingeniører for at overføre kode fra notebooks til repositories, ved at skabe ML-pipelines ved hjælp af Amazon SageMaker Pipelines, som forbinder forskellige behandlingstrin og opgaver, herunder forbehandling, træning, evaluering og efterbehandling, alt imens de løbende inkorporerer ny produktion data. Implementering af Amazon SageMaker Pipelines er afhængig af repository-interaktioner og CI/CD-pipelineaktivering. ML-pipelinen vedligeholder toppræsterende modeller, containerbilleder, evalueringsresultater og statusoplysninger i et modelregister, hvor modelinteressenter vurderer ydeevne og beslutter progression til produktion baseret på ydeevneresultater og benchmarks, efterfulgt af aktivering af en anden CI/CD-pipeline til iscenesættelse og produktionsimplementering. Når de først er i produktion, bruger ML-forbrugere modellen via applikationsudløst inferens gennem direkte påkald eller API-kald, med feedback-loops til modelejere til løbende evaluering af ydeevnen.
Amazon SageMaker Clarify og MLOps integration
Efter MLOps livscyklus fremstiller finjustere eller brugere af open source-modeller finjusterede modeller eller FM ved hjælp af Amazon SageMaker Jumpstart og MLOps-tjenester, som beskrevet i Implementering af MLOps-praksis med Amazon SageMaker JumpStart-foruddannede modeller. Dette førte til et nyt domæne for basismodeloperationer (FMOps) og LLM Operations (LLMOps) FMOps/LLMOps: Operationaliser generativ AI og forskelle med MLOps.
Følgende figur viser ende-til-ende LLMOPS-livscyklus:
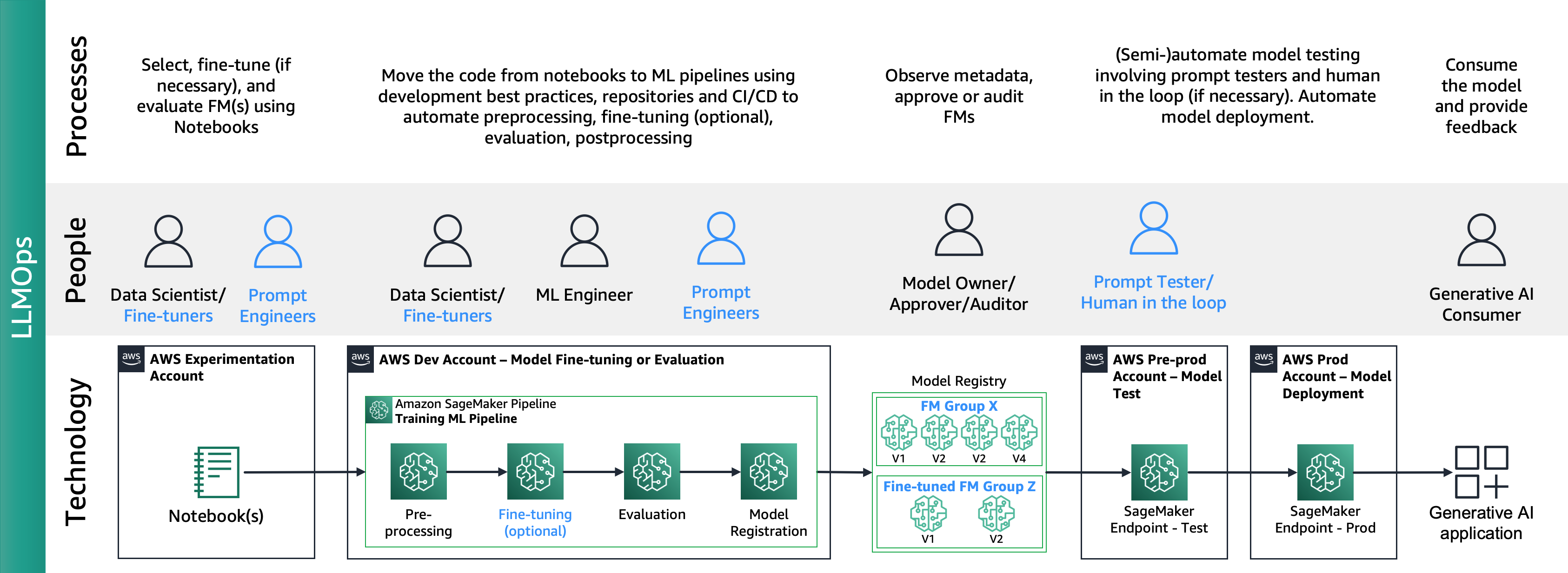
I LLMOps er de største forskelle sammenlignet med MLOps modelvalg og modelevaluering, der involverer forskellige processer og metrikker. I den indledende eksperimenteringsfase vælger dataforskerne (eller finjustere) den FM, der vil blive brugt til en specifik generativ AI-brugssag.
Dette resulterer ofte i test og finjustering af flere FM'er, hvoraf nogle kan give sammenlignelige resultater. Efter udvælgelsen af modellen/modellerne er prompteingeniører ansvarlige for at forberede de nødvendige inputdata og forventede output til evaluering (f.eks. inputprompter, der omfatter inputdata og forespørgsel) og definere metrikker som lighed og toksicitet. Ud over disse målinger skal dataforskere eller finjustere validere resultaterne og vælge den passende FM ikke kun på præcisionsmålinger, men på andre muligheder som latens og omkostninger. Derefter kan de implementere en model til et SageMaker-slutpunkt og teste dens ydeevne i lille skala. Mens eksperimenteringsfasen kan involvere en ligetil proces, kræver overgang til produktion, at kunderne automatiserer processen og forbedrer løsningens robusthed. Derfor er vi nødt til at dykke dybt i, hvordan man automatiserer evaluering, hvilket gør det muligt for testere at udføre effektiv evaluering i skala og implementere realtidsovervågning af modelinput og -output.
Automatiser FM-evaluering
Amazon SageMaker Pipelines automatiserer alle faser af forbehandling, FM-finjustering (valgfrit) og evaluering i skala. I betragtning af de udvalgte modeller under eksperimenter, skal prompte ingeniører dække et større sæt af sager ved at forberede mange prompter og gemme dem i et udpeget lagerlager kaldet promptkatalog. For mere information, se FMOps/LLMOps: Operationaliser generativ AI og forskelle med MLOps. Derefter kan Amazon SageMaker Pipelines struktureres som følger:
Scenarie 1 – Evaluer flere FM'er: I dette scenarie kan FM'erne dække business use casen uden finjustering. Amazon SageMaker Pipeline består af følgende trin: dataforbehandling, parallel evaluering af flere FM'er, sammenligning af modeller og udvælgelse baseret på nøjagtighed og andre egenskaber som omkostninger eller latens, registrering af udvalgte modelartefakter og metadata.
Følgende diagram illustrerer denne arkitektur.

Scenarie 2 – Finjuster og evaluer flere FM'er: I dette scenarie er Amazon SageMaker Pipeline struktureret meget ligesom Scenario 1, men den kører parallelt med både finjusterings- og evalueringstrin for hver FM. Den bedst finjusterede model vil blive registreret i modelregistret.
Følgende diagram illustrerer denne arkitektur.
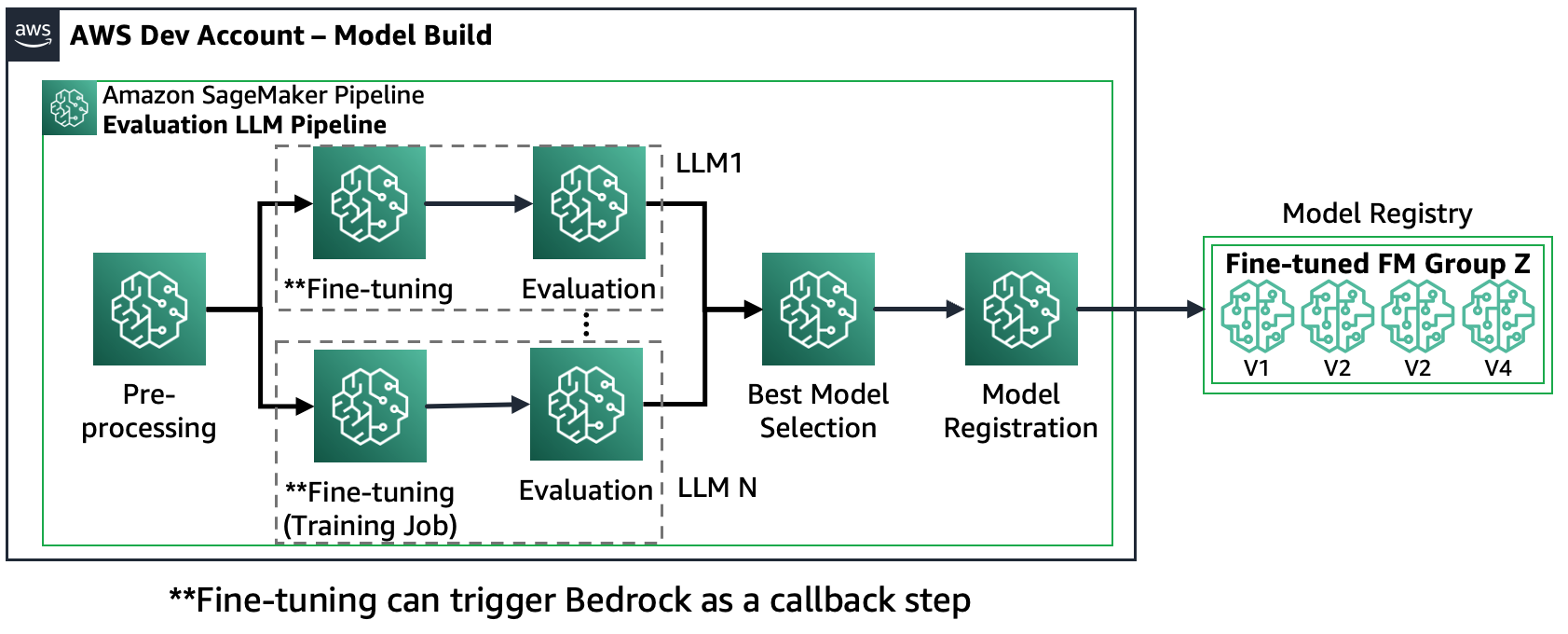
Scenarie 3 – Evaluer flere FM'er og finjusterede FM'er: Dette scenarie er en kombination af evaluering af FM'er til generelle formål og finjusterede FM'er. I dette tilfælde ønsker kunderne at tjekke, om en finjusteret model kan yde bedre end en almindelig FM.
Følgende figur viser de resulterende SageMaker Pipeline-trin.
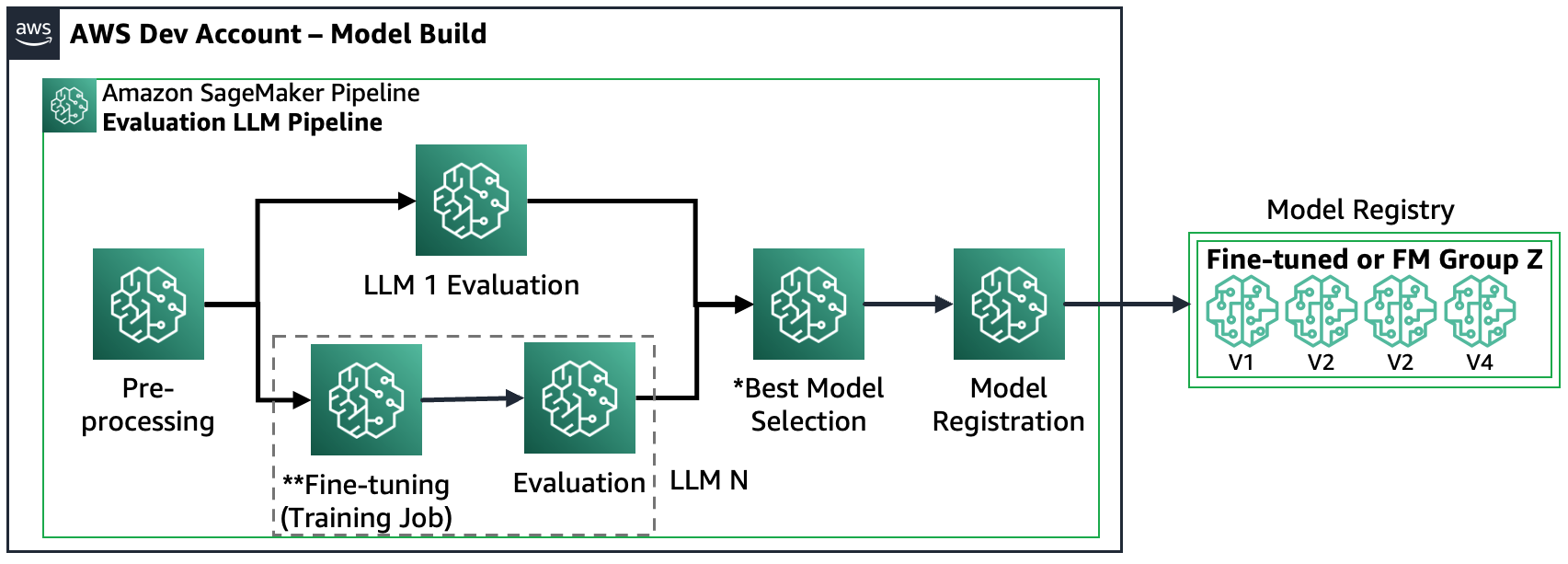
Bemærk, at modelregistrering følger to mønstre: (a) gemme en open source-model og artefakter eller (b) gemme en reference til en proprietær FM. For mere information, se FMOps/LLMOps: Operationaliser generativ AI og forskelle med MLOps.
Løsningsoversigt
For at accelerere din rejse til LLM-evaluering i stor skala, har vi skabt en løsning, der implementerer scenarierne ved hjælp af både Amazon SageMaker Clarify og den nye Amazon SageMaker Pipelines SDK. Kodeeksemplet, inklusive datasæt, kildenotesbøger og SageMaker Pipelines (trin og ML pipeline), er tilgængelig på GitHub. For at udvikle denne eksempelløsning har vi brugt to FM'er: Llama2 og Falcon-7B. I dette indlæg er vores primære fokus på nøgleelementerne i SageMaker Pipeline-løsningen, der vedrører evalueringsprocessen.
Evalueringskonfiguration: Med det formål at standardisere evalueringsproceduren har vi oprettet en YAML-konfigurationsfil, (evaluation_config.yaml), som indeholder de nødvendige detaljer for evalueringsprocessen, herunder datasættet, modellen/modellerne og de algoritmer, der skal køres under evalueringstrin af SageMaker Pipeline. Følgende eksempel illustrerer konfigurationsfilen:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"Evalueringstrin: Den nye SageMaker Pipeline SDK giver brugerne fleksibilitet til at definere tilpassede trin i ML-arbejdsgangen ved hjælp af '@step' Python-dekorator. Derfor skal brugerne oprette et grundlæggende Python-script, der udfører evalueringen, som følger:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultSageMaker Pipeline: Efter at have oprettet de nødvendige trin, såsom dataforbehandling, modelimplementering og modelevaluering, skal brugeren forbinde trinene sammen ved at bruge SageMaker Pipeline SDK. Den nye SDK genererer automatisk arbejdsgangen ved at fortolke afhængighederne mellem forskellige trin, når en SageMaker Pipeline-oprettelses-API påkaldes som vist i følgende eksempel:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
pipeline.start()Eksemplet implementerer evalueringen af en enkelt FM ved at forbehandle det indledende datasæt, implementere modellen og køre evalueringen. Den genererede pipeline-rettede acykliske graf (DAG) er vist i den følgende figur.
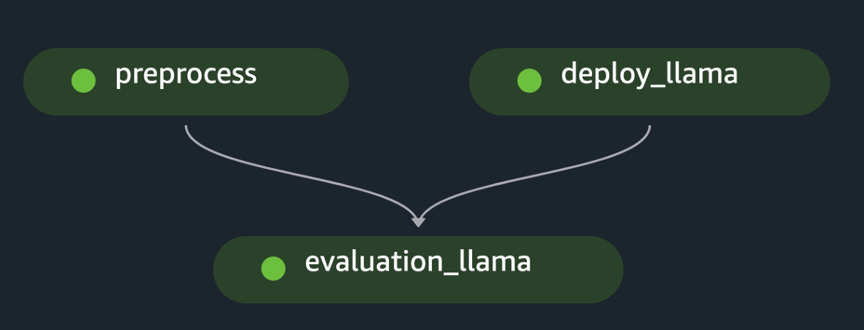
Efter en lignende tilgang og ved at bruge og skræddersy eksemplet ind Finjuster LLaMA 2-modeller på SageMaker JumpStart, skabte vi pipelinen for at evaluere en finjusteret model, som vist i den følgende figur.

Ved at bruge de tidligere SageMaker Pipeline-trin som "Lego"-klodser udviklede vi løsningen til Scenario 1 og Scenario 3, som vist i de følgende figurer. Specifikt GitHub repository gør det muligt for brugeren at evaluere flere FM'er parallelt eller at udføre mere kompleks evaluering, der kombinerer evaluering af både fundament og finjusterede modeller.

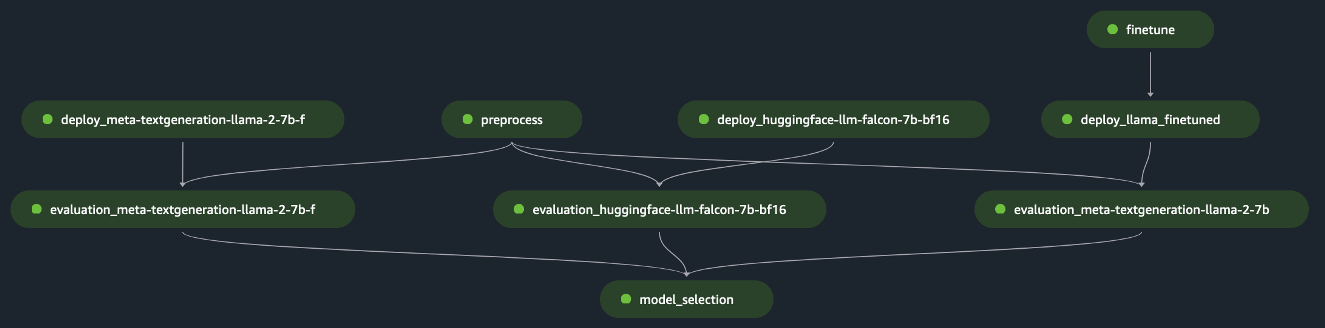
Yderligere funktioner, der er tilgængelige i depotet, omfatter følgende:
- Generering af dynamisk evalueringstrin: Vores løsning genererer alle de nødvendige evalueringstrin dynamisk baseret på konfigurationsfilen for at give brugerne mulighed for at evaluere et vilkårligt antal modeller. Vi har udvidet løsningen til at understøtte en nem integration af nye typer modeller, såsom Hugging Face eller Amazon Bedrock.
- Forhindre omfordeling af slutpunkter: Hvis et slutpunkt allerede er på plads, springer vi implementeringsprocessen over. Dette giver brugeren mulighed for at genbruge endepunkter med FM'er til evaluering, hvilket resulterer i omkostningsbesparelser og reduceret implementeringstid.
- Slutpunktsoprydning: Efter afslutningen af evalueringen dekommissionerer SageMaker Pipeline de implementerede endepunkter. Denne funktionalitet kan udvides for at holde det bedste modelslutpunkt i live.
- Trin til valg af model: Vi har tilføjet en modeludvælgelsestrin-pladsholder, der kræver forretningslogikken i det endelige modelvalg, herunder kriterier såsom pris eller latens.
- Modelregistreringstrin: Den bedste model kan registreres i Amazon SageMaker Model Registry som en ny version af en specifik modelgruppe.
- Varm pool: SageMaker-administrerede varme pools giver dig mulighed for at bevare og genbruge klargjort infrastruktur efter afslutningen af et job for at reducere latens for gentagne arbejdsbelastninger
Følgende figur illustrerer disse muligheder og et multi-model evalueringseksempel, som brugerne nemt og dynamisk kan skabe ved hjælp af vores løsning i denne GitHub repository.

Vi holdt med vilje dataforberedelsen uden for rækkevidde, da den vil blive beskrevet i et andet indlæg i dybden, herunder prompt katalogdesign, promptskabeloner, prompt optimering. For mere information og relaterede komponentdefinitioner henvises til FMOps/LLMOps: Operationaliser generativ AI og forskelle med MLOps.
Konklusion
I dette indlæg fokuserede vi på, hvordan man automatiserer og operationaliserer LLMs evaluering i stor skala ved hjælp af Amazon SageMaker Clarify LLM-evalueringskapacitet og Amazon SageMaker Pipelines. Udover teoretiske arkitekturdesigns har vi eksempelkode i dette GitHub repository (med Llama2 og Falcon-7B FM'er) for at sætte kunder i stand til at udvikle deres egne skalerbare evalueringsmekanismer.
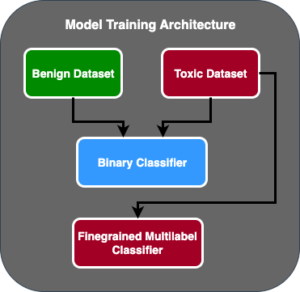
Følgende illustration viser modelevalueringsarkitektur.
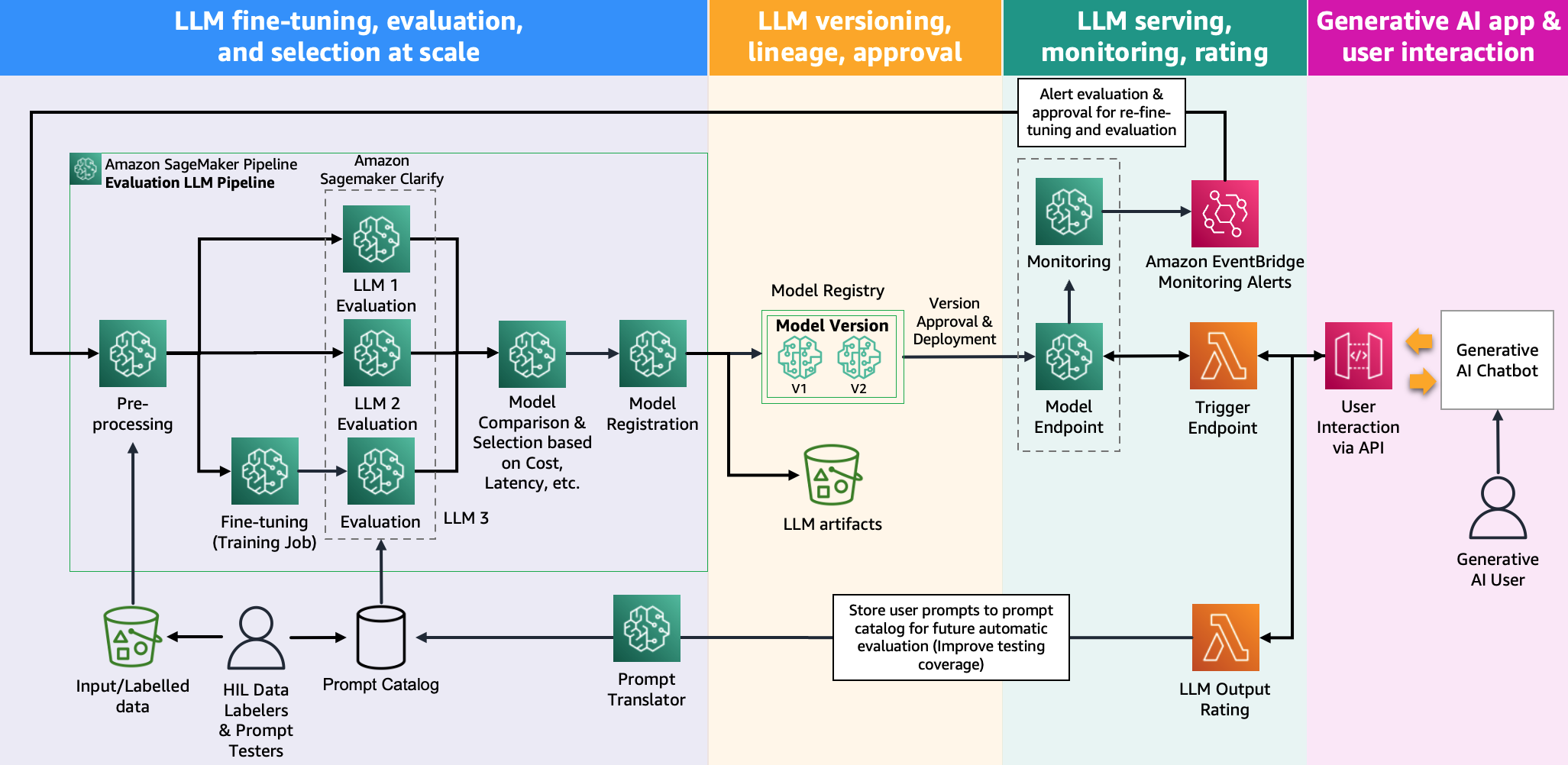
I dette indlæg fokuserede vi på at operationalisere LLM-evalueringen i skala som vist på venstre side af illustrationen. I fremtiden vil vi fokusere på at udvikle eksempler, der opfylder ende-til-ende livscyklus for FM'er til produktion ved at følge retningslinjen beskrevet i FMOps/LLMOps: Operationaliser generativ AI og forskelle med MLOps. Dette inkluderer LLM-servering, overvågning, lagring af output-rating, der i sidste ende vil udløse automatisk re-evaluering og finjustering og endelig brug af mennesker-i-løkken til at arbejde på mærkede data eller promptkatalog.
Om forfatterne
 Dr. Sokratis Kartakis er en Principal Machine Learning and Operations Specialist Solutions Architect for Amazon Web Services. Sokratis fokuserer på at gøre det muligt for virksomhedskunder at industrialisere deres Machine Learning (ML) og generative AI-løsninger ved at udnytte AWS-tjenester og forme deres driftsmodel, dvs. MLOps/FMOps/LLMOps-fundamenter, og transformations-køreplan, der udnytter bedste udviklingspraksis. Han har brugt mere end 15 år på at opfinde, designe, lede og implementere innovative end-to-end produktionsniveau ML- og AI-løsninger inden for områderne energi, detailhandel, sundhed, finans, motorsport osv.
Dr. Sokratis Kartakis er en Principal Machine Learning and Operations Specialist Solutions Architect for Amazon Web Services. Sokratis fokuserer på at gøre det muligt for virksomhedskunder at industrialisere deres Machine Learning (ML) og generative AI-løsninger ved at udnytte AWS-tjenester og forme deres driftsmodel, dvs. MLOps/FMOps/LLMOps-fundamenter, og transformations-køreplan, der udnytter bedste udviklingspraksis. Han har brugt mere end 15 år på at opfinde, designe, lede og implementere innovative end-to-end produktionsniveau ML- og AI-løsninger inden for områderne energi, detailhandel, sundhed, finans, motorsport osv.
 Jagdeep Singh Soni er Senior Partner Solutions Architect hos AWS med base i Holland. Han bruger sin passion for DevOps, GenAI og byggeværktøjer til at hjælpe både systemintegratorer og teknologipartnere. Jagdeep anvender sin applikationsudvikling og arkitekturbaggrund til at drive innovation i sit team og fremme nye teknologier.
Jagdeep Singh Soni er Senior Partner Solutions Architect hos AWS med base i Holland. Han bruger sin passion for DevOps, GenAI og byggeværktøjer til at hjælpe både systemintegratorer og teknologipartnere. Jagdeep anvender sin applikationsudvikling og arkitekturbaggrund til at drive innovation i sit team og fremme nye teknologier.
 Dr. Riccardo Gatti er en Senior Startup Solution Architect baseret i Italien. Han er en teknisk rådgiver for kunder, der hjælper dem med at vokse deres forretning ved at vælge de rigtige værktøjer og teknologier til at innovere, skalere hurtigt og blive global på få minutter. Han har altid været passioneret omkring maskinlæring og generativ kunstig intelligens, efter at have studeret og anvendt disse teknologier på tværs af forskellige domæner gennem hele sin arbejdskarriere. Han er vært og redaktør for AWS italienske podcast "Casa Startup", dedikeret til historier om startup-stiftere og nye teknologiske trends.
Dr. Riccardo Gatti er en Senior Startup Solution Architect baseret i Italien. Han er en teknisk rådgiver for kunder, der hjælper dem med at vokse deres forretning ved at vælge de rigtige værktøjer og teknologier til at innovere, skalere hurtigt og blive global på få minutter. Han har altid været passioneret omkring maskinlæring og generativ kunstig intelligens, efter at have studeret og anvendt disse teknologier på tværs af forskellige domæner gennem hele sin arbejdskarriere. Han er vært og redaktør for AWS italienske podcast "Casa Startup", dedikeret til historier om startup-stiftere og nye teknologiske trends.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 100
- 9
- a
- Om
- fremskynde
- adgang
- nøjagtighed
- præcist
- opnå
- opnå
- tværs
- Lov
- Aktivering
- aktiv
- acykliske
- tilføjet
- Desuden
- Derudover
- adresse
- tilstrækkeligt
- administration
- Vedtagelsen
- Vedtagelse
- fremskridt
- rådgiver
- Efter
- mod
- midler
- AI
- AI-loven
- AI-systemer
- sigte
- sigter
- algoritme
- algoritmer
- Justerer
- live
- Alle
- tillader
- allerede
- også
- altid
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon SageMaker Pipelines
- Amazon SageMaker Studio
- Amazon Web Services
- an
- analysere
- ,
- En anden
- besvare
- enhver
- api
- Anvendelse
- Application Development
- applikationer
- anvendt
- gælder
- tilgang
- passende
- arkitektur
- ER
- områder
- argument
- AS
- vurdere
- Vurdering
- vurdering
- vurderinger
- At
- revision
- automatisere
- Automatiseret
- Automatisk Ur
- automatisk
- Automation
- til rådighed
- AWS
- b
- baggrund
- baseret
- grundlæggende
- BE
- fordi
- bliver
- været
- adfærd
- benchmark
- benchmarkes
- Benchmarks
- fordele
- BEDSTE
- Bedre
- mellem
- Beyond
- skævhed
- forudindtaget
- fordomme
- Blocks
- både
- brud
- bredde
- bringe
- bygge
- Builder
- virksomhed
- men
- by
- kaldet
- Opkald
- CAN
- kandidat
- kapaciteter
- stand
- fange
- Kort
- Karriere
- tilfælde
- tilfælde
- katalog
- vis
- udfordre
- karakteristika
- billigere
- kontrollere
- Vælg
- valgt
- klassificering
- Klassificere
- ren
- kode
- sammenhængende
- samarbejde
- kombination
- kombinerer
- Fælles
- samfund
- sammenlignelig
- sammenligne
- sammenlignet
- sammenligning
- komplement
- færdiggørelse
- komplekse
- kompleksitet
- Compliance
- overholde
- komponent
- komponenter
- omfattende
- beregningsmæssige
- Compute
- Konceptet
- Bekymring
- Adfærd
- udførelse
- adfærd
- Konfiguration
- Tilslut
- forbinder
- betragtes
- består
- konstruere
- Forbrugere
- Container
- indeholder
- indhold
- sammenhæng
- løbende
- kontinuerlig
- kontrast
- konversation
- samtaler
- konvertere
- korrigere
- Koste
- omkostningsbesparelser
- kostbar
- Omkostninger
- dæksel
- skabe
- oprettet
- Oprettelse af
- skabelse
- kriterier
- kritisk
- afgørende
- skik
- Kunder
- DAG
- data
- Dataforberedelse
- dataforsker
- datasikkerhed
- datasæt
- manipulation af data
- datasæt
- dato tid
- beslutte
- Beslutningstagning
- afgørelser
- dedikeret
- dyb
- dyb dykke
- Standard
- definere
- definitioner
- leverer
- Efterspørgsel
- afhængigheder
- afhænger
- indsætte
- indsat
- implementering
- implementering
- dybde
- beskrevet
- udpeget
- konstrueret
- designe
- designs
- ønske
- ønskes
- detaljeret
- detaljer
- udvikle
- udviklet
- udvikling
- Udvikling
- DevOps
- forskelle
- forskellige
- direkte
- rettet
- dyk
- forskelligartede
- do
- Er ikke
- domæne
- Domæner
- køre
- i løbet af
- dynamisk
- e
- hver
- nemt
- let
- editor
- Effektiv
- effektivitet
- effektiv
- effektivt
- indsats
- enten
- elementer
- andet
- selvstændige
- muliggøre
- muliggør
- muliggør
- ende til ende
- Endpoint
- endpoints
- energi
- Ingeniører
- forbedre
- sikre
- sikrer
- sikring
- Enterprise
- virksomhedskunder
- virksomheder
- epoke
- lige
- især
- væsentlig
- etc.
- Ether (ETH)
- EU
- evaluere
- evalueret
- evaluere
- evaluering
- Endog
- til sidst
- eksempel
- eksempler
- udøvende
- eksisterende
- forventninger
- forventet
- fremskynde
- udvide
- udvidet
- ekstern
- udvinding
- f1
- Ansigtet
- faciliterende
- faktorer
- Faktuel
- fairness
- Falls
- falsk
- berømt
- FAST
- hurtigere
- Feature
- Med
- tilbagemeldinger
- få
- felt
- Figur
- tal
- File (Felt)
- endelige
- Endelig
- finansiere
- finansielle
- Finansiel sektor
- Fornavn
- Fleksibilitet
- Fokus
- fokuserede
- fokuserer
- efterfulgt
- efter
- følger
- Til
- formular
- Foundation
- Fonde
- stiftere
- Framework
- rammer
- hyppigt
- fra
- opfyldelse
- fuld
- funktionaliteter
- funktionalitet
- fundamental
- Endvidere
- fremtiden
- indsamling
- Generelt
- generelle formål
- generere
- genereret
- genererer
- generere
- generation
- generative
- Generativ AI
- få
- given
- Global
- Go
- indrømme
- graf
- gruppe
- Gruppens
- Dyrkning
- hånd
- skadelig
- udnyttelse
- Have
- have
- he
- Helse
- stærkt
- hjælpe
- hjælpe
- hjælper
- Høj
- høj risiko
- hængsler
- hans
- bedrift
- host
- Hvordan
- How To
- Men
- HTML
- HTTPS
- menneskelig
- i
- IAM
- identificeret
- identificerer
- identificere
- if
- illustrerer
- billeder
- gennemføre
- gennemføre
- redskaber
- importere
- betydning
- forbedringer
- in
- omfatter
- omfatter
- Herunder
- Incorporated
- inkorporering
- Indikatorer
- industrier
- oplysninger
- informeret
- Infrastruktur
- initial
- innovere
- Innovation
- innovativ
- indgang
- indgange
- integrere
- integration
- med vilje
- interaktioner
- interne
- ind
- indføre
- påberåbes
- involvere
- involverede
- involverer
- involverer
- ISO
- IT
- Italiensk
- Italiensk vin
- Varer
- iteration
- ITS
- Job
- rejse
- jpg
- Holde
- holdt
- Nøgle
- viden
- Sprog
- stor
- større
- Efternavn
- endelig
- Latency
- føre
- leaderboards
- førende
- læring
- til venstre
- lad
- løftestang
- Bibliotek
- livscyklus
- ligesom
- Limited
- LINK
- Llama
- placering
- logik
- Lav
- maskine
- machine learning
- Main
- vedligeholde
- fastholder
- lykkedes
- manipulere
- manipulationer
- manuel
- mange
- Kan..
- I mellemtiden
- måle
- foranstaltninger
- mekanismer
- Metadata
- metode
- metoder
- metrisk
- Metrics
- minimere
- minutter
- misinformation
- afbøde
- formildende
- ML
- MLOps
- model
- modeller
- modul
- Overvåg
- overvågning
- mere
- mest
- motiveret
- Motorsport
- meget
- flere
- skal
- navn
- nødvendig
- Behov
- behov
- Holland
- Ny
- Nye teknologier
- næste
- ikke-eksperter
- Bemærk
- notesbog
- notesbøger
- nuancer
- nummer
- of
- tilbyde
- tit
- on
- engang
- ONE
- igangværende
- kun
- open source
- drift
- drift
- Produktion
- Udtalelser
- optimering
- or
- OS
- Andet
- vores
- ud
- Resultat
- udfald
- output
- udgange
- udestående
- i løbet af
- samlet
- egen
- ejere
- Parallel
- parametre
- særlig
- især
- partner
- partnere
- lidenskab
- lidenskabelige
- sti
- mønstre
- Mennesker
- udføre
- ydeevne
- forestillinger
- udfører
- fase
- PIO
- pipeline
- Place
- pladsholder
- plato
- Platon Data Intelligence
- PlatoData
- PoC
- podcast
- Punkt
- pool
- Pools
- Indlæg
- efterbehandling
- potentiale
- magt
- strøm
- praksis
- Precision
- forberedelse
- forberede
- tilstedeværelse
- forhindre
- tidligere
- primære
- Main
- principper
- Beskyttelse af personlige oplysninger
- private
- Problem
- procedure
- behandle
- Processer
- forarbejdning
- produktion
- progression
- fremtrædende
- løfte
- fremme
- prompter
- bevis
- Bevis for koncept
- formering
- egenskaber
- proprietære
- beskytte
- Bevise
- give
- udbydere
- giver
- leverer
- offentlige
- offentligt
- formål
- Python
- kvalitative
- kvalitet
- kvantitativ
- spørgsmål
- rækkevidde
- Sats
- bedømmelse
- ægte
- virkelige verden
- realtid
- reducere
- Reduceret
- reducere
- henvise
- henvisningen
- registreret
- Registrering
- register
- regression
- fast
- reguleret
- regulerede brancher
- regler
- forstærkning læring
- relaterede
- relevans
- relevant
- pålidelighed
- repetitiv
- indberette
- Rapportering
- Rapporter
- Repository
- repræsentativt
- påkrævet
- Kræver
- forskning
- forskere
- ressourceintensive
- Ressourcer
- ansvar
- ansvarlige
- resulterer
- Resultater
- detail
- tilbageholde
- afkast
- genbruge
- gennemgå
- Revolutionerende
- højre
- stringent
- Risen
- Risiko
- risici
- køreplan
- robust
- robusthed
- roller
- roller
- Kør
- kører
- løber
- s
- sikker
- sikkerhedsforanstaltninger
- sagemaker
- SageMaker Pipelines
- Besparelser
- Skalerbarhed
- skalerbar
- Scale
- scenarie
- scenarier
- Videnskabsmand
- forskere
- rækkevidde
- score
- script
- SDK
- problemfrit
- sektioner
- sektor
- sikker
- sikkerhed
- sikkerhedsrisici
- Vælg
- valgt
- udvælgelse
- valg
- senior
- stemningen
- tjener
- tjeneste
- Tjenester
- servering
- Session
- sæt
- forme
- Del
- Vis
- vist
- Shows
- side
- signifikant
- lignende
- forenkler
- ganske enkelt
- siden
- enkelt
- lille
- løsninger
- Løsninger
- SOLVE
- nogle
- Kilde
- span
- specialist
- specifikke
- specifikt
- brugt
- iscenesættelse
- interessenter
- standardisering
- standarder
- Stanford
- Starter
- starter
- opstart
- Status
- Trin
- Steps
- Stadig
- opbevaring
- butik
- Historier
- ligetil
- struktureret
- studeret
- Studio
- stil
- Efterfølgende
- sådan
- RESUMÉ
- support
- systemet
- Systemer
- skræddersy
- Opgaver
- opgaver
- hold
- hold
- Teknisk
- teknikker
- teknologisk
- Teknologier
- Teknologier
- skabeloner
- prøve
- testere
- Test
- tests
- tekst
- end
- at
- Fremtiden
- deres
- Them
- derefter
- teoretisk
- derved
- derfor
- Disse
- de
- denne
- dem
- tre
- Gennem
- hele
- tid
- til
- sammen
- værktøj
- værktøjer
- spor
- Tog
- uddannet
- Kurser
- tog
- Transformation
- overgang
- overgang
- Oversættelse
- Tendenser
- udløse
- sand
- troværdig
- to
- typer
- typisk
- Ultimativt
- uberettiget
- forstå
- forståelse
- uden fortilfælde
- kommende
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- bruger
- ved brug af
- sædvanligvis
- udnytte
- VALIDATE
- Værdifuld
- forskellige
- udgave
- via
- afgørende
- Sårbarheder
- ønsker
- varm
- we
- web
- webservices
- GODT
- var
- Hvad
- hvornår
- som
- mens
- WHO
- bred
- Bred rækkevidde
- Wikipedia
- vilje
- med
- inden for
- uden
- Arbejde
- workflow
- arbejder
- world
- yaml
- år
- Udbytte
- dig
- Din
- zephyrnet