By David Wendt , Gregory Kimball
Effektiv behandling af strengdata er afgørende for mange datavidenskabelige applikationer. For at udtrække værdifuld information fra strengdata, RAPIDS libcudf giver kraftfulde værktøjer til at accelerere strengdatatransformationer. libcudf er et C++ GPU DataFrame-bibliotek, der bruges til at indlæse, forbinde, aggregere og filtrere data.
Inden for datavidenskab repræsenterer strengdata tale, tekst, genetiske sekvenser, logning og mange andre typer information. Når der arbejdes med strengdata til maskinlæring og feature engineering, skal dataene ofte normaliseres og transformeres, før de kan anvendes til specifikke use cases. libcudf leverer både generelle API'er såvel som hjælpeprogrammer på enhedssiden for at muliggøre en bred vifte af brugerdefinerede strengoperationer.
Dette indlæg demonstrerer, hvordan man dygtigt transformerer strengekolonner med libcudf's generelle API. Du får ny viden om, hvordan du låser op for maksimal ydeevne ved hjælp af brugerdefinerede kerner og libcudf-værktøjer på enhedssiden. Dette indlæg leder dig også gennem eksempler på, hvordan du bedst administrerer GPU-hukommelse og effektivt konstruerer libcudf-kolonner for at fremskynde dine strengtransformationer.
libcudf gemmer strengdata i enhedens hukommelse ved hjælp af Pil format, som repræsenterer strengkolonner som to underordnede kolonner: chars and offsets (Figur 1).
chars kolonnen indeholder strengdataene som UTF-8-kodede tegnbytes, der er lagret sammenhængende i hukommelsen.
offsets kolonne indeholder en stigende sekvens af heltal, som er byte-positioner, der identificerer starten af hver enkelt streng i chars-dataarrayet. Det endelige offset-element er det samlede antal bytes i tegnkolonnen. Dette betyder størrelsen af en individuel streng i rækken i er defineret som (offsets[i+1]-offsets[i]).
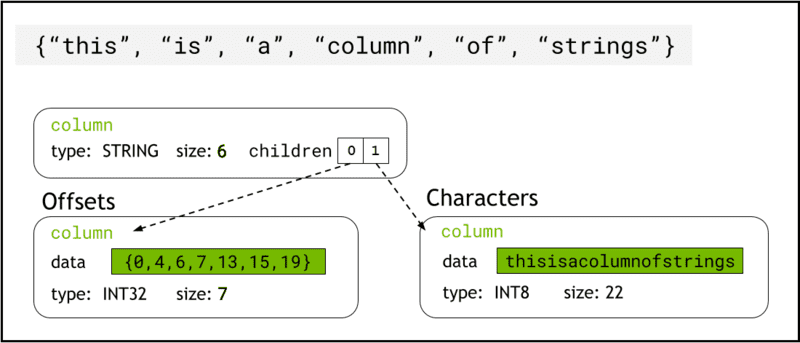 Figur 1. Skematisk, der viser, hvordan pilformat repræsenterer strenge kolonner med
Figur 1. Skematisk, der viser, hvordan pilformat repræsenterer strenge kolonner med chars , offsets underordnede kolonner
For at illustrere et eksempel på strengtransformation skal du overveje en funktion, der modtager to inputstrengkolonner og producerer én redigeret outputstrengskolonne.
Indtastningsdataene har følgende form: en "navne"-kolonne, der indeholder for- og efternavne adskilt af et mellemrum, og en "synlighed"-kolonne, der indeholder statussen "offentlig" eller "privat".
Vi foreslår "redact"-funktionen, der opererer på inputdataene for at producere outputdata, der består af den første initial af efternavnet efterfulgt af et mellemrum og hele fornavnet. Men hvis den tilsvarende synlighedskolonne er "privat", skal outputstrengen være fuldstændigt redigeret som "X X."
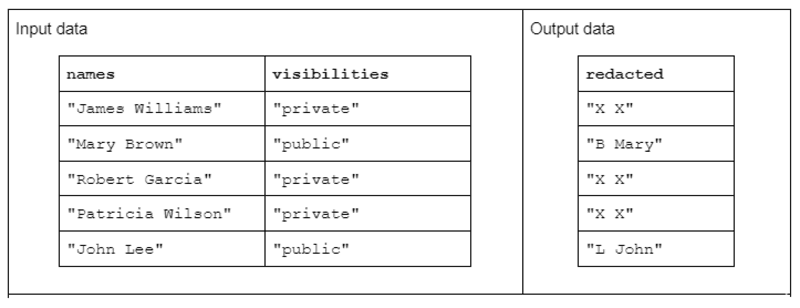 Tabel 1. Eksempel på en "redact"-strengtransformation, der modtager navne- og synlighedsstrengkolonner som input og delvist eller fuldstændigt redigerede data som output
Tabel 1. Eksempel på en "redact"-strengtransformation, der modtager navne- og synlighedsstrengkolonner som input og delvist eller fuldstændigt redigerede data som output
For det første kan strengtransformation udføres ved hjælp af libcudf strenge API. Den generelle API er et glimrende udgangspunkt og en god baseline for sammenligning af ydeevne.
API-funktionerne fungerer på en hel strengkolonne, starter mindst én kerne pr. funktion og tildeler én tråd pr. streng. Hver tråd håndterer en enkelt række data parallelt på tværs af GPU'en og udsender en enkelt række som en del af en ny outputkolonne.
Følg disse trin for at fuldføre redigeringseksempelfunktionen ved hjælp af den generelle API:
- Konverter kolonnen "synligheder" strenge til en boolsk kolonne ved hjælp af
contains - Opret en ny strengkolonne fra navnekolonnen ved at kopiere "XX", når den tilsvarende rækkeindtastning i den boolske kolonne er "falsk"
- Opdel den "redigerede" kolonne i kolonnerne for fornavn og efternavn
- Skær det første tegn i efternavnene som initialer til efternavnet
- Byg outputkolonnen ved at sammenkæde den sidste initialkolonne og kolonnen for fornavne med mellemrum (" ") separator.
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Denne tilgang tager omkring 3.5 ms på en A6000 med 600 rækker af data. Dette eksempel bruger contains, copy_if_else, split, slice_strings , concatenate for at udføre en tilpasset strengtransformation. En profileringsanalyse med Nsight systemer viser, at split funktion tager længst tid, efterfulgt af slice_strings , concatenate.
Figur 2 viser profileringsdata fra Nsight Systems i redact-eksemplet, der viser ende-til-ende strengbehandling med op til ~600 millioner elementer pr. sekund. Regionerne svarer til NVTX-intervaller, der er knyttet til hver funktion. Lyseblå områder svarer til perioder, hvor CUDA-kerner kører.
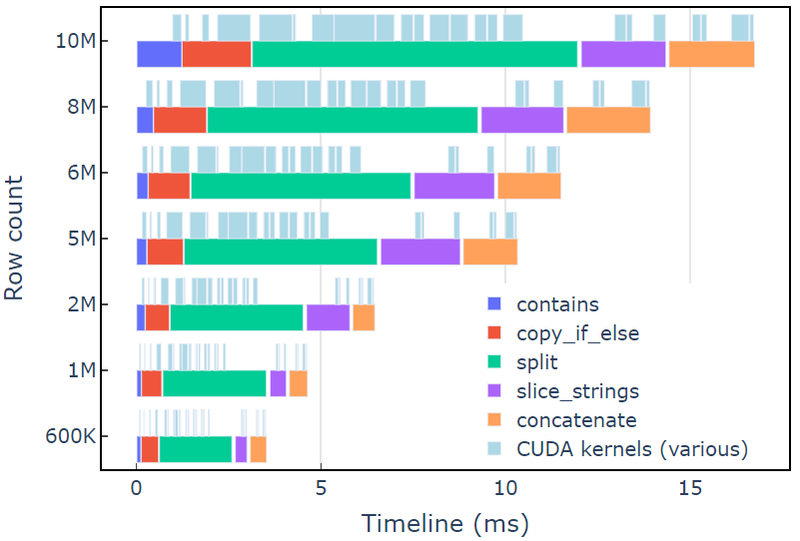 Figur 2. Profileringsdata fra Nsight Systems i redakteksemplet
Figur 2. Profileringsdata fra Nsight Systems i redakteksemplet
Libcudf strings API er et hurtigt og effektivt værktøjssæt til at transformere strenge, men nogle gange skal ydeevnekritiske funktioner køre endnu hurtigere. En vigtig kilde til ekstra arbejde i libcudf strings API er oprettelsen af mindst én ny streng kolonne i global enhedshukommelse for hvert API-kald, hvilket åbner muligheden for at kombinere flere API-kald til en tilpasset kerne.
Ydeevnebegrænsninger i kerne malloc-kald
Først bygger vi en brugerdefineret kerne for at implementere redigeringseksemplets transformation. Når vi designer denne kerne, skal vi huske på, at libcudf-strengkolonner er uforanderlige.
Stringskolonner kan ikke ændres på plads, fordi tegnbytes gemmes sammenhængende, og enhver ændring af længden af en streng vil ugyldiggøre forskydningsdataene. Derfor redact_kernel brugerdefineret kerne genererer en ny streng kolonne ved at bruge en libcudf kolonne fabrik til at bygge begge offsets , chars underordnede kolonner.
I denne første tilgang oprettes outputstrengen for hver række i dynamisk enhedshukommelse ved hjælp af et malloc-kald inde i kernen. Det brugerdefinerede kerneoutput er en vektor af enhedsmarkører til hver rækkeoutput, og denne vektor tjener som input til en strengkolonnefabrik.
Den brugerdefinerede kerne accepterer en cudf::column_device_view for at få adgang til strenge kolonnedata og bruger element metode til at returnere en cudf::string_view repræsenterer strengdataene ved det angivne rækkeindeks. Kerneoutputtet er en vektor af typen cudf::string_view der holder pointere til enhedshukommelsen, der indeholder outputstrengen og størrelsen af denne streng i bytes.
cudf::string_view klasse ligner std::string_view-klassen, men er implementeret specifikt til libcudf og indpakker en fast længde af tegndata i enhedshukommelsen kodet som UTF-8. Det har mange af de samme funktioner (find , substr funktioner, for eksempel) og begrænsninger (ingen null-terminator) som std modpart. EN cudf::string_view repræsenterer en tegnsekvens gemt i enhedens hukommelse, så vi kan bruge den her til at optage malloc'd-hukommelsen for en outputvektor.
Malloc kerne
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Dette kan virke som en rimelig tilgang, indtil kerneydelsen er målt. Denne tilgang tager omkring 108 ms på en A6000 med 600 rækker af data - mere end 30 gange langsommere end løsningen, der er leveret ovenfor, ved brug af libcudf strings API.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Den vigtigste flaskehals er malloc/free kalder inde i de to kerner her. CUDA dynamisk enhedshukommelse kræver malloc/free kalder en kerne ind for at blive synkroniseret, hvilket får parallel eksekvering til at degenerere til sekventiel udførelse.
Forudallokering af arbejdshukommelse for at eliminere flaskehalse
Fjern malloc/free flaskehals ved at erstatte malloc/free kalder kernen ind med forudtildelt arbejdshukommelse, før kernen startes.
For redact-eksemplet bør outputstørrelsen af hver streng i dette eksempel ikke være større end selve inputstrengen, da logikken kun fjerner tegn. Derfor kan en enkelt enhedshukommelsesbuffer bruges med samme størrelse som inputbufferen. Brug inputforskydningerne til at lokalisere hver rækkeposition.
Adgang til strengsøjlens forskydninger involverer indpakning af cudf::column_view med en cudf::strings_column_view og kalder det offsets_begin metode. Størrelsen af chars underordnet kolonne kan også tilgås ved hjælp af chars_size metode. Derefter a rmm::device_uvector er præ-allokeret, før du kalder kernen for at gemme tegnoutputdataene.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Forudallokeret kerne
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Kernen udsender en vektor på cudf::string_view genstande, som sendes til cudf::make_strings_column fabriksfunktion. Den anden parameter til denne funktion bruges til at identificere nul-indtastninger i outputkolonnen. Eksemplerne i dette indlæg har ikke null-indgange, så en nullptr-pladsholder cudf::string_view{nullptr,0} anvendes.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Denne tilgang tager omkring 1.1 ms på en A6000 med 600 rækker af data og slår derfor basislinjen med mere end 2x. Den omtrentlige opdeling er vist nedenfor:
redact_kernel 66us make_strings_column 400us
Den resterende tid bruges i cudaMalloc, cudaFree, cudaMemcpy, hvilket er typisk for overhead til håndtering af midlertidige tilfælde af rmm::device_uvector. Denne metode fungerer godt, hvis alle output-strenge garanteres at have samme størrelse eller mindre som input-strengene.
Samlet set er skift til en bulk-arbejdshukommelsesallokering med RAPIDS RMM en væsentlig forbedring og en god løsning til en brugerdefineret strengfunktion.
Optimering af kolonneoprettelse for hurtigere beregningstider
Er der en måde at forbedre dette yderligere på? Flaskehalsen er nu cudf::make_strings_column fabriksfunktion, som bygger de to strenge kolonnekomponenter, offsets , chars, fra vektoren af cudf::string_view objekter.
I libcudf er mange fabriksfunktioner inkluderet til at bygge strengsøjler. Fabriksfunktionen brugt i de foregående eksempler tager en cudf::device_span of cudf::string_view objekter og konstruerer derefter kolonnen ved at udføre en gather på de underliggende tegndata for at bygge forskydninger og underordnede tegnkolonner. EN rmm::device_uvector er automatisk konverterbar til en cudf::device_span uden at kopiere nogen data.
Men hvis vektoren af tegn og vektoren af forskydninger er bygget direkte, så kan en anden fabriksfunktion bruges, som simpelthen opretter strengsøjlen uden at kræve en samling for at kopiere dataene.
sizes_kernel laver en første passage over inputdataene for at beregne den nøjagtige outputstørrelse for hver outputrække:
Optimeret kerne: Del 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Outputstørrelserne konverteres derefter til offsets ved at udføre en in-place exclusive_scan. Bemærk, at offsets vektor blev skabt med names.size()+1 elementer. Den sidste post vil være det samlede antal bytes (alle størrelser lagt sammen), mens den første post vil være 0. Disse håndteres begge af exclusive_scan opkald. Størrelsen af chars kolonne hentes fra den sidste indtastning af offsets kolonne for at bygge tegnvektoren.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
redact_kernel logikken er stadig meget den samme, bortset fra at den accepterer outputtet d_offsets vektor for at bestemme hver rækkes outputplacering:
Optimeret kerne: Del 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
Størrelsen af output d_chars kolonne hentes fra den sidste indtastning af d_offsets kolonne for at tildele tegnvektoren. Kernen starter med den forudberegnede forskydningsvektor og returnerer den udfyldte tegnvektor. Endelig opretter kolonnefabrikken libcudf-strenge output-strengkolonnerne.
Denne cudf::make_strings_column fabriksfunktionen opbygger strenge-kolonnen uden at lave en kopi af dataene. Det offsets data og chars data er allerede i det korrekte, forventede format, og denne fabrik flytter simpelthen dataene fra hver vektor og skaber kolonnestrukturen omkring den. Når den er afsluttet rmm::device_uvectors forum offsets , chars er tomme, deres data er blevet flyttet til outputkolonnen.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Denne tilgang tager omkring 300 us (0.3 ms) på en A6000 med 600 rækker af data og forbedrer i forhold til den tidligere tilgang med mere end 2x. Det kan du måske bemærke sizes_kernel , redact_kernel deler meget af den samme logik: én gang for at måle størrelsen af output og derefter igen for at udfylde output.
Fra et kodekvalitetsperspektiv er det fordelagtigt at omstrukturere transformationen som en enhedsfunktion, der kaldes af både størrelserne og redigere kernerne. Fra et præstationsperspektiv kan du blive overrasket over at se, at de beregningsmæssige omkostninger ved transformationen bliver betalt to gange.
Fordelene ved hukommelsesstyring og mere effektiv kolonneoprettelse opvejer ofte beregningsomkostningerne ved at udføre transformationen to gange.
Tabel 2 viser beregningstiden, kerneantal og bytes behandlet for de fire løsninger, der er diskuteret i dette indlæg. "Total kernel launches" afspejler det samlede antal lancerede kerner, inklusive både computer- og hjælpekerner. "Total bytes behandlet" er den kumulative DRAM læse-plus skrive-gennemstrømning, og "minimum behandlede bytes" er et gennemsnit på 37.9 bytes pr. række for vores test-input og -output. Den ideelle "hukommelsesbåndbredde begrænset" sag antager 768 GB/s båndbredde, den teoretiske maksimale gennemstrømning af A6000.
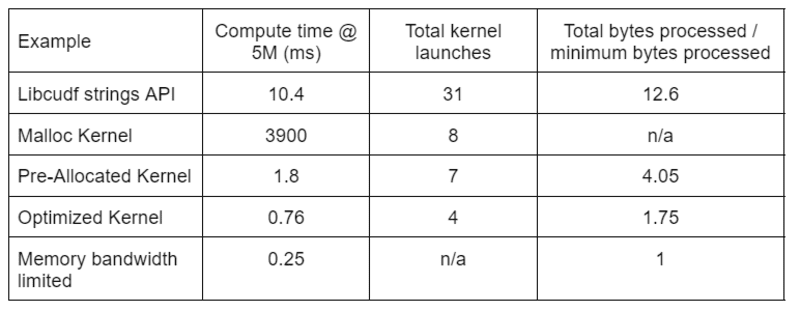 Tabel 2. Beregningstid, kerneantal og bytes behandlet for de fire løsninger, der er diskuteret i dette indlæg
Tabel 2. Beregningstid, kerneantal og bytes behandlet for de fire løsninger, der er diskuteret i dette indlæg
"Optimeret kerne" giver den højeste gennemstrømning på grund af det reducerede antal kernelanceringer og de færre samlede bytes, der behandles. Med effektive brugerdefinerede kerner falder de samlede kernelanceringer fra 31 til 4, og de samlede bytes behandlet fra 12.6x til 1.75x af input plus outputstørrelse.
Som et resultat opnår den tilpassede kerne >10 gange højere gennemløb end den generelle streng-API til redigeringstransformationen.
Poolens hukommelsesressource i RAPIDS Memory Manager (RMM) er et andet værktøj, du kan bruge til at øge ydeevnen. Eksemplerne ovenfor bruger standard "CUDA-hukommelsesressource" til at allokere og frigøre global enhedshukommelse. Den tid, der er nødvendig for at allokere arbejdshukommelse, tilføjer imidlertid betydelig latenstid mellem trinene i strengtransformationerne. "Pool-hukommelsesressourcen" i RMM reducerer latens ved at allokere en stor pulje af hukommelse på forhånd og tildele underallokeringer efter behov under behandlingen.
Med CUDA-hukommelsesressourcen viser "Optimized Kernel" en 10x-15x speedup, der begynder at falde ved højere rækkeantal på grund af den stigende allokeringsstørrelse (figur 3). Brug af puljehukommelsesressourcen afbøder denne effekt og opretholder 15x-25x speedups i forhold til libcudf strings API-tilgangen.
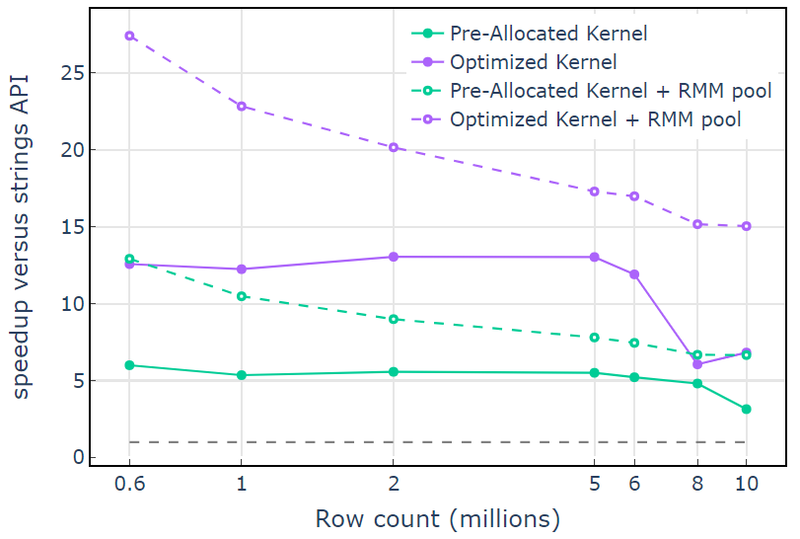 Figur 3. Fremskyndelse fra de brugerdefinerede kerner "Pre-Allocated Kernel" og "Optimized Kernel" med standard CUDA hukommelsesressourcen (fast) og pool hukommelsesressourcen (stiplet), i forhold til libcudf streng API, der bruger standard CUDA hukommelses ressourcen
Figur 3. Fremskyndelse fra de brugerdefinerede kerner "Pre-Allocated Kernel" og "Optimized Kernel" med standard CUDA hukommelsesressourcen (fast) og pool hukommelsesressourcen (stiplet), i forhold til libcudf streng API, der bruger standard CUDA hukommelses ressourcen
Med poolhukommelsesressourcen demonstreres en ende-til-ende hukommelsesgennemstrømning, der nærmer sig den teoretiske grænse for en to-pass algoritme. "Optimeret kerne" når 320-340 GB/s gennemløb, målt ved hjælp af størrelsen af input plus størrelsen af output og beregningstiden (Figur 4).
To-pass tilgangen måler først størrelsen af output-elementerne, allokerer hukommelse og indstiller derefter hukommelsen med output. Givet en to-pass behandlingsalgoritme, udfører implementeringen i "Optimized Kernel" tæt på hukommelsesbåndbreddegrænsen. "End-to-end memory throughput" er defineret som input plus output størrelse i GB divideret med beregningstiden. *RTX A6000 hukommelsesbåndbredde (768 GB/s).
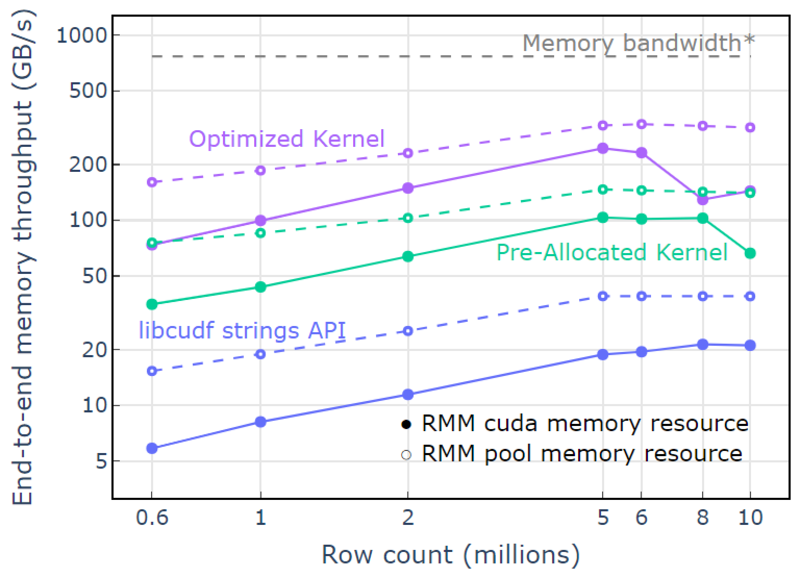 Figur 4. Hukommelsesgennemløb for "Optimized Kernel", "Pre-Allocated Kernel" og "libcudf strings API" som en funktion af input/output rækkeantal
Figur 4. Hukommelsesgennemløb for "Optimized Kernel", "Pre-Allocated Kernel" og "libcudf strings API" som en funktion af input/output rækkeantal
Dette indlæg demonstrerer to tilgange til at skrive effektive strengdatatransformationer i libcudf. libcudf generelle formål API er hurtig og ligetil for udviklere og leverer god ydeevne. libcudf leverer også hjælpeprogrammer på enhedssiden, der er designet til brug med brugerdefinerede kerner, og i dette eksempel låser op for >10x hurtigere ydeevne.
Anvend din viden
For at komme i gang med RAPIDS cuDF, besøg rapidsai/cudf GitHub repo. Hvis du endnu ikke har prøvet cuDF og libcudf til dine strengbehandlingsarbejdsbelastninger, opfordrer vi dig til at teste den seneste udgivelse. Docker containere leveres til udgivelser såvel som natlige builds. Conda pakker er også tilgængelige for at gøre test og implementering nemmere. Hvis du allerede bruger cuDF, opfordrer vi dig til at køre det nye eksempel på strengtransformation ved at besøge rapidsai/cudf/tree/HEAD/cpp/eksempler/strenge på GitHub.
David Wendt er en senior systemsoftwareingeniør hos NVIDIA, der udvikler C++/CUDA-kode til RAPIDS. David har en mastergrad i elektroteknik fra Johns Hopkins University.
Gregory Kimball er en softwareingeniørchef hos NVIDIA, der arbejder på RAPIDS-teamet. Gregory leder udviklingen af libcudf, CUDA/C++-biblioteket til søjleformet databehandling, der driver RAPIDS cuDF. Gregory har en PhD i anvendt fysik fra California Institute of Technology.
Original. Genopslået med tilladelse.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- Om
- over
- accelererende
- accepterer
- adgang
- af udleverede
- gennemført
- tværs
- tilføjet
- Tilføjer
- algoritme
- Alle
- allokerer
- allokering
- allerede
- beløb
- analyse
- ,
- En anden
- Apache
- api
- API'er
- applikationer
- anvendt
- tilgang
- tilgange
- nærmer sig
- omkring
- Array
- forbundet
- auto
- automatisk
- til rådighed
- gennemsnit
- båndbredde
- Baseline
- fordi
- før
- være
- jf. nedenstående
- gavnlig
- fordele
- BEDSTE
- mellem
- Blå
- Fordeling
- buffer
- bygge
- Bygning
- bygger
- bygget
- C + +
- california
- ringe
- kaldet
- ringer
- Opkald
- kan ikke
- tilfælde
- tilfælde
- forårsager
- Ændringer
- karakter
- tegn
- barn
- klasse
- Luk
- kode
- Kolonne
- Kolonner
- kombinerer
- sammenligne
- fuldføre
- Afsluttet
- komponenter
- beregning
- Compute
- Overvej
- Bestående
- konstruere
- indeholder
- konvertere
- konverteret
- kopiering
- Tilsvarende
- Koste
- skabe
- oprettet
- skaber
- skabelse
- skik
- data
- databehandling
- datalogi
- David
- Standard
- Degree
- leverer
- demonstreret
- implementering
- konstrueret
- designe
- udviklere
- udvikling
- Udvikling
- enhed
- forskellige
- direkte
- drøftet
- Divided
- Docker
- Drop
- i løbet af
- dynamisk
- hver
- lettere
- effekt
- effektiv
- effektivt
- Elektroteknik
- elementer
- eliminere
- muliggøre
- tilskynde
- ende til ende
- ingeniør
- Engineering
- Hele
- indrejse
- Ether (ETH)
- Endog
- at alt
- eksempel
- eksempler
- fremragende
- Undtagen
- udførelse
- forventet
- ekstern
- ekstra
- ekstrakt
- fabrik
- FAST
- hurtigere
- Feature
- Funktionalitet
- Figur
- filtrering
- endelige
- Endelig
- Fornavn
- fast
- følger
- efterfulgt
- efter
- formular
- format
- Gratis
- hyppigt
- fra
- forsiden
- fuldt ud
- funktion
- funktioner
- yderligere
- Gevinst
- Generelt
- genererer
- få
- GitHub
- given
- Global
- godt
- GPU
- garanteret
- Håndterer
- have
- link.
- højere
- højeste
- besidder
- Hvordan
- How To
- Men
- HTML
- HTTPS
- ideal
- identificere
- uforanderlige
- gennemføre
- implementering
- implementeret
- Forbedre
- forbedrer
- in
- medtaget
- Herunder
- Forøg
- stigende
- indeks
- individuel
- oplysninger
- initial
- indgang
- Institut
- interne
- IT
- selv
- Johns Hopkins
- Johns Hopkins University
- sammenføjning
- KDnuggets
- Holde
- Nøgle
- viden
- etiket
- stor
- større
- Efternavn
- Latency
- seneste
- seneste udgivelse
- lanceret
- lanceringer
- lancering
- Leads
- læring
- Længde
- Bibliotek
- lys
- GRÆNSE
- begrænsninger
- lastning
- placering
- maskine
- machine learning
- Main
- fastholder
- lave
- maerker
- Making
- administrere
- ledelse
- leder
- styring
- mange
- Master
- mastering
- Match
- midler
- måle
- foranstaltninger
- Hukommelse
- metode
- måske
- million
- tankerne
- mere
- mere effektiv
- bevæger sig
- MS
- flere
- navn
- navne
- Behov
- behov
- Ny
- nummer
- Nvidia
- objekter
- offset
- ONE
- åbning
- betjene
- opererer
- Produktion
- Opportunity
- Andet
- betalt
- Parallel
- parameter
- del
- Bestået
- Peak
- ydeevne
- udfører
- udfører
- perioder
- tilladelse
- perspektiv
- Fysik
- Place
- plato
- Platon Data Intelligence
- PlatoData
- plus
- Punkt
- pool
- befolkede
- position
- positioner
- Indlæg
- vigtigste
- beføjelser
- tidligere
- forarbejdning
- producere
- profilering
- foreslå
- forudsat
- giver
- offentlige
- formål
- kvalitet
- rækkevidde
- når
- Læs
- rimelige
- modtager
- optage
- Reduceret
- reducerer
- Refaktor
- afspejler
- regioner
- frigive
- Udgivelser
- resterende
- repræsenterer
- repræsenterer
- ressource
- resultere
- afkast
- afkast
- RÆKKE
- Kør
- kører
- samme
- Videnskab
- Anden
- senior
- Sequence
- tjener
- sæt
- Del
- bør
- vist
- Shows
- signifikant
- lignende
- ganske enkelt
- siden
- enkelt
- Størrelse
- størrelser
- mindre
- So
- Software
- Software Engineer
- software Engineering
- solid
- løsninger
- Løsninger
- Kilde
- Space
- specifikke
- specifikt
- specificeret
- tale
- hastighed
- brugt
- delt
- starte
- påbegyndt
- Starter
- Status
- Steps
- Stadig
- butik
- opbevaret
- forhandler
- ligetil
- strøm
- struktur
- overrasket
- Systemer
- tager
- hold
- Teknologier
- midlertidig
- prøve
- Test
- deres
- teoretisk
- derfor
- Gennem
- kapacitet
- tid
- til
- sammen
- værktøj
- toolkit
- værktøjer
- I alt
- Transform
- Transformation
- transformationer
- omdannet
- omdanne
- tv
- typer
- typisk
- underliggende
- universitet
- låse
- oplåsning
- us
- brug
- forsyningsselskaber
- Værdifuld
- Værdifuld information
- versus
- synlighed
- synlig
- afgørende
- som
- mens
- bred
- Bred rækkevidde
- vilje
- inden for
- uden
- Arbejde
- arbejder
- virker
- ville
- skriver
- skrivning
- X
- Din
- zephyrnet










