I dag er vi glade for at kunne meddele, at Lamavagten model er nu tilgængelig for kunder, der bruger Amazon SageMaker JumpStart. Llama Guard giver input- og output-sikkerhedsforanstaltninger i implementering af store sprogmodeller (LLM). Det er en af komponenterne under Purple Llama, Metas initiativ, der byder på åbne tillids- og sikkerhedsværktøjer og evalueringer, der hjælper udviklere med at bygge ansvarligt med AI-modeller. Purple Llama samler værktøjer og evalueringer for at hjælpe samfundet med at bygge ansvarligt med generative AI-modeller. Den første udgivelse inkluderer fokus på cybersikkerhed og LLM-input og -output-sikkerhedsforanstaltninger. Komponenter inden for Purple Llama-projektet, herunder Llama Guard-modellen, er licenseret efter tilladelse, hvilket muliggør både forskning og kommerciel brug.
Nu kan du bruge Llama Guard-modellen i SageMaker JumpStart. SageMaker JumpStart er maskinlærings (ML) hub for Amazon SageMaker der giver adgang til fundamentmodeller ud over indbyggede algoritmer og end-to-end løsningsskabeloner for at hjælpe dig hurtigt i gang med ML.
I dette indlæg gennemgår vi, hvordan man implementerer Llama Guard-modellen og bygger ansvarlige generative AI-løsninger.
Lama Guard model
Llama Guard er en ny model fra Meta, der giver input og output autoværn til LLM-implementeringer. Llama Guard er en åbent tilgængelig model, der præsterer konkurrencedygtigt på almindelige åbne benchmarks og giver udviklere en foruddannet model til at hjælpe med at forsvare sig mod at generere potentielt risikable output. Denne model er blevet trænet i en blanding af offentligt tilgængelige datasæt for at muliggøre detektering af almindelige typer af potentielt risikabelt eller krænkende indhold, der kan være relevant for en række udviklerbrugssager. I sidste ende er modellens vision at gøre det muligt for udviklere at tilpasse denne model til at understøtte relevante use cases og gøre det nemt at vedtage bedste praksis og forbedre det åbne økosystem.
Llama Guard kan bruges som et supplerende værktøj for udviklere til at integrere i deres egne afbødningsstrategier, såsom chatbots, indholdsmoderering, kundeservice, overvågning af sociale medier og uddannelse. Ved at sende brugergenereret indhold gennem Llama Guard, før de udgiver eller reagerer på det, kan udviklere markere usikkert eller upassende sprog og tage skridt til at opretholde et sikkert og respektfuldt miljø.
Lad os undersøge, hvordan vi kan bruge Llama Guard-modellen i SageMaker JumpStart.
Fundamentmodeller i SageMaker
SageMaker JumpStart giver adgang til en række modeller fra populære modelhubs, herunder Hugging Face, PyTorch Hub og TensorFlow Hub, som du kan bruge i din ML-udviklingsworkflow i SageMaker. De seneste fremskridt inden for ML har givet anledning til en ny klasse af modeller kendt som fundament modeller, som typisk trænes på milliarder af parametre og kan tilpasses til en bred kategori af use cases, såsom tekstresumé, digital kunstgenerering og sprogoversættelse. Fordi disse modeller er dyre at træne, ønsker kunder at bruge eksisterende præ-trænede foundation-modeller og finjustere dem efter behov, i stedet for at træne disse modeller selv. SageMaker giver en udvalgt liste over modeller, som du kan vælge imellem på SageMaker-konsollen.
Du kan nu finde fundamentmodeller fra forskellige modeludbydere i SageMaker JumpStart, så du hurtigt kan komme i gang med fundamentmodeller. Du kan finde fundamentmodeller baseret på forskellige opgaver eller modeludbydere og nemt gennemgå modellens egenskaber og brugsbegreber. Du kan også prøve disse modeller ved hjælp af en test-UI-widget. Når du vil bruge en fundamentmodel i stor skala, kan du nemt gøre det uden at forlade SageMaker ved at bruge forudbyggede notesbøger fra modeludbydere. Fordi modellerne er hostet og implementeret på AWS, kan du være sikker på, at dine data, uanset om de bruges til at evaluere eller bruge modellen i stor skala, aldrig deles med tredjeparter.
Lad os undersøge, hvordan vi kan bruge Llama Guard-modellen i SageMaker JumpStart.
Oplev Llama Guard-modellen i SageMaker JumpStart
Du kan få adgang til Code Llama-fundamentmodeller gennem SageMaker JumpStart i SageMaker Studio UI og SageMaker Python SDK. I dette afsnit gennemgår vi, hvordan du opdager modellerne i Amazon SageMaker Studio.
SageMaker Studio er et integreret udviklingsmiljø (IDE), der giver en enkelt webbaseret visuel grænseflade, hvor du kan få adgang til specialbyggede værktøjer til at udføre alle ML-udviklingstrin, fra forberedelse af data til opbygning, træning og implementering af dine ML-modeller. For flere detaljer om, hvordan du kommer i gang og opsætter SageMaker Studio, se Amazon SageMaker Studio.
I SageMaker Studio kan du få adgang til SageMaker JumpStart, som indeholder fortrænede modeller, notebooks og præbyggede løsninger, under Præbyggede og automatiserede løsninger.
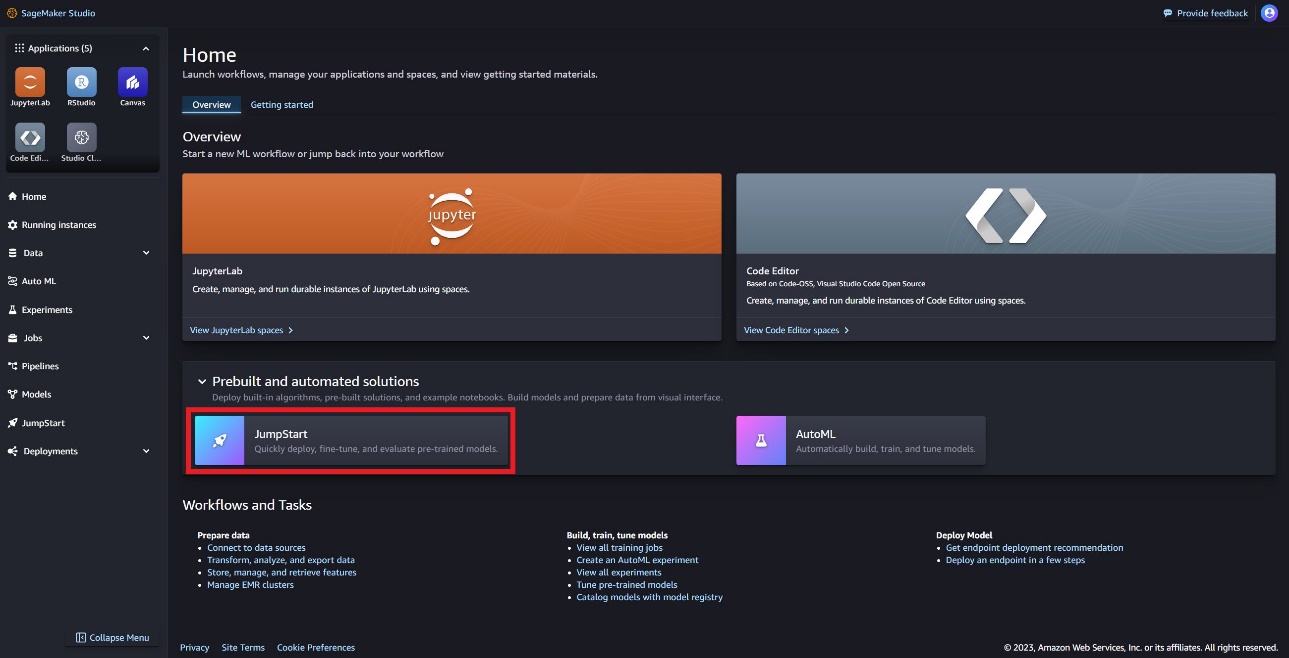
På SageMaker JumpStart-landingssiden kan du finde Llama Guard-modellen ved at vælge Meta-hubben eller søge efter Llama Guard.

Du kan vælge mellem en række forskellige Llama-modelvarianter, herunder Llama Guard, Llama-2 og Code Llama.

Du kan vælge modelkortet for at se detaljer om modellen, såsom licens, data, der bruges til at træne, og hvordan du bruger den. Du finder også en Implementer mulighed, som fører dig til en landingsside, hvor du kan teste slutninger med et eksempel på nyttelast.

Implementer modellen med SageMaker Python SDK
Du kan finde koden, der viser implementeringen af Llama Guard på Amazon JumpStart og et eksempel på, hvordan du bruger den installerede model i denne GitHub notesbog.
I den følgende kode specificerer vi SageMaker model hub model ID og model version, der skal bruges ved implementering af Llama Guard:
Du kan nu implementere modellen ved hjælp af SageMaker JumpStart. Følgende kode bruger standardforekomsten ml.g5.2xlarge til inferensendepunktet. Du kan implementere modellen på andre instanstyper ved at bestå instance_type i JumpStartModel klasse. Implementeringen kan tage et par minutter. For en vellykket implementering skal du manuelt ændre accept_eula argument i modellens implementeringsmetode til True.
Denne model er implementeret ved hjælp af Text Generation Inference (TGI) deep learning container. Inferensanmodninger understøtter mange parametre, herunder følgende:
- max_længde – Modellen genererer tekst, indtil outputlængden (som inkluderer inputkontekstlængden) når
max_length. Hvis det er angivet, skal det være et positivt heltal. - max_new_tokens – Modellen genererer tekst, indtil outputlængden (eksklusive inputkontekstlængden) når
max_new_tokens. Hvis det er angivet, skal det være et positivt heltal. - antal_bjælker – Dette angiver antallet af stråler brugt i den grådige søgning. Hvis det er angivet, skal det være et heltal større end eller lig med
num_return_sequences. - no_repeat_ngram_size – Modellen sikrer, at en række af ord af
no_repeat_ngram_sizegentages ikke i outputsekvensen. Hvis det er angivet, skal det være et positivt heltal større end 1. - temperatur – Denne parameter styrer tilfældigheden i outputtet. En højere
temperatureresulterer i en outputsekvens med ord med lav sandsynlighed og en laveretemperatureresulterer i en outputsekvens med ord med høj sandsynlighed. Hvistemperatureer 0, resulterer det i grådig afkodning. Hvis det er angivet, skal det være en positiv flyder. - tidligt_stop - Hvis
True, er tekstgenerering afsluttet, når alle strålehypoteser når slutningen af sætningstokenet. Hvis det er angivet, skal det være boolesk. - do_sample - Hvis
True, modellen prøver det næste ord efter sandsynligheden. Hvis det er angivet, skal det være boolesk. - top_k – I hvert trin af tekstgenerering prøver modellen kun fra
top_khøjst sandsynlige ord. Hvis det er angivet, skal det være et positivt heltal. - top_s – I hvert trin af tekstgenerering prøver modellen fra det mindst mulige sæt af ord med kumulativ sandsynlighed
top_p. Hvis det er angivet, skal det være en flyder mellem 0-1. - return_full_text - Hvis
True, vil inputteksten være en del af den outputgenererede tekst. Hvis det er angivet, skal det være boolesk. Standardværdien erFalse. - stoppe – Hvis det er angivet, skal det være en liste over strenge. Tekstgenerering stopper, hvis en af de angivne strenge genereres.
Kald et SageMaker-slutpunkt
Du kan programmæssigt hente eksempler på nyttelast fra JumpStartModel objekt. Dette vil hjælpe dig med hurtigt at komme i gang ved at observere forudformaterede instruktionsprompter, som Llama Guard kan indtage. Se følgende kode:
Når du har kørt det foregående eksempel, kan du se, hvordan dit input og output ville blive formateret af Llama Guard:
I lighed med Llama-2 bruger Llama Guard specielle tokens til at angive sikkerhedsinstruktioner til modellen. Generelt skal nyttelasten følge nedenstående format:
Brugerprompt vist som {user_prompt} ovenfor, kan yderligere inkludere sektioner til indholdskategoridefinitioner og samtaler, som ser ud som følgende:
I det næste afsnit diskuterer vi de anbefalede standardværdier for opgave-, indholdskategori- og instruktionsdefinitioner. Samtalen skal veksle mellem User , Agent tekst som følger:
Moderer en samtale med Llama-2 Chat
Du kan nu implementere et Llama-2 7B Chat-slutpunkt til samtalechat og derefter bruge Llama Guard til at moderere input og output tekst, der kommer fra Llama-2 7B Chat.
Vi viser dig eksemplet med Llama-2 7B chatmodellens input og output modereret gennem Llama Guard, men du kan bruge Llama Guard til moderering med enhver LLM efter eget valg.
Implementer modellen med følgende kode:
Du kan nu definere Lama Guard-opgaveskabelonen. De usikre indholdskategorier kan justeres efter ønske til din specifikke brug. Du kan i almindelig tekst definere betydningen af hver indholdskategori, herunder hvilket indhold der skal markeres som usikkert, og hvilket indhold der skal tillades som sikkert. Se følgende kode:
Dernæst definerer vi hjælpefunktioner format_chat_messages , format_guard_messages for at formatere prompten til chatmodellen og for Llama Guard-modellen, der krævede specielle tokens:
Du kan derefter bruge disse hjælpefunktioner på et eksempel på meddelelsesinputprompt til at køre eksempelinputtet gennem Llama Guard for at afgøre, om meddelelsens indhold er sikkert:
Følgende output indikerer, at meddelelsen er sikker. Du bemærker måske, at prompten indeholder ord, der kan være forbundet med vold, men i dette tilfælde er Llama Guard i stand til at forstå konteksten med hensyn til instruktionerne og definitioner af usikre kategorier, som vi gav tidligere, og afgøre, at det er en sikker prompt og ikke relateret til vold.
Nu hvor du har bekræftet, at inputteksten er bestemt til at være sikker med hensyn til dine Llama Guard-indholdskategorier, kan du overføre denne nyttelast til den installerede Llama-2 7B-model for at generere tekst:
Følgende er svaret fra modellen:
Til sidst vil du måske bekræfte, at svarteksten fra modellen er bestemt til at indeholde sikkert indhold. Her udvider du LLM-outputsvaret til inputmeddelelserne og kører hele denne samtale gennem Llama Guard for at sikre, at samtalen er sikker for din applikation:
Du kan muligvis se følgende output, der indikerer, at svaret fra chatmodellen er sikkert:
Ryd op
Når du har testet endepunkterne, skal du sørge for at slette SageMaker-slutningsendepunkterne og modellen for at undgå at pådrage dig gebyrer.
Konklusion
I dette indlæg viste vi dig, hvordan du kan moderere input og output ved hjælp af Llama Guard og sætte autoværn til input og output fra LLM'er i SageMaker JumpStart.
Efterhånden som AI fortsætter med at udvikle sig, er det afgørende at prioritere ansvarlig udvikling og implementering. Værktøjer som Purple Llama's CyberSecEval og Llama Guard er medvirkende til at fremme sikker innovation og tilbyder tidlig risikoidentifikation og begrænsningsvejledning til sprogmodeller. Disse bør være forankret i AI-designprocessen for at udnytte dets fulde potentiale af LLM'er etisk fra dag 1.
Prøv Llama Guard og andre foundation-modeller i SageMaker JumpStart i dag, og fortæl os din feedback!
Denne vejledning er kun til informationsformål. Du bør stadig udføre din egen uafhængige vurdering og træffe foranstaltninger for at sikre, at du overholder dine egne specifikke kvalitetskontrolpraksisser og standarder og de lokale regler, love, regler, licenser og brugsbetingelser, der gælder for dig, dit indhold, og den tredjepartsmodel, der henvises til i denne vejledning. AWS har ingen kontrol eller autoritet over den tredjepartsmodel, der henvises til i denne vejledning, og giver ingen erklæringer eller garantier for, at tredjepartsmodellen er sikker, virusfri, operationel eller kompatibel med dit produktionsmiljø og dine standarder. AWS giver ingen erklæringer, garantier eller garantier for, at nogen information i denne vejledning vil resultere i et bestemt resultat eller resultat.
Om forfatterne
 Dr. Kyle Ulrich er en anvendt videnskabsmand med Amazon SageMaker indbyggede algoritmer hold. Hans forskningsinteresser omfatter skalerbare maskinlæringsalgoritmer, computervision, tidsserier, Bayesianske ikke-parametriske og Gaussiske processer. Hans ph.d. er fra Duke University, og han har udgivet artikler i NeurIPS, Cell og Neuron.
Dr. Kyle Ulrich er en anvendt videnskabsmand med Amazon SageMaker indbyggede algoritmer hold. Hans forskningsinteresser omfatter skalerbare maskinlæringsalgoritmer, computervision, tidsserier, Bayesianske ikke-parametriske og Gaussiske processer. Hans ph.d. er fra Duke University, og han har udgivet artikler i NeurIPS, Cell og Neuron.
 Evan Kravitz er softwareingeniør hos Amazon Web Services, der arbejder på SageMaker JumpStart. Han er interesseret i sammenløbet mellem maskinlæring og cloud computing. Evan modtog sin bachelorgrad fra Cornell University og mastergrad fra University of California, Berkeley. I 2021 præsenterede han et papir om adversarielle neurale netværk på ICLR-konferencen. I sin fritid nyder Evan at lave mad, rejse og løbe i New York City.
Evan Kravitz er softwareingeniør hos Amazon Web Services, der arbejder på SageMaker JumpStart. Han er interesseret i sammenløbet mellem maskinlæring og cloud computing. Evan modtog sin bachelorgrad fra Cornell University og mastergrad fra University of California, Berkeley. I 2021 præsenterede han et papir om adversarielle neurale netværk på ICLR-konferencen. I sin fritid nyder Evan at lave mad, rejse og løbe i New York City.
 Rachna Chadha er Principal Solution Architect AI/ML i Strategic Accounts hos AWS. Rachna er en optimist, der mener, at etisk og ansvarlig brug af kunstig intelligens kan forbedre samfundet i fremtiden og bringe økonomisk og social velstand. I sin fritid kan Rachna godt lide at bruge tid med sin familie, vandreture og lytte til musik.
Rachna Chadha er Principal Solution Architect AI/ML i Strategic Accounts hos AWS. Rachna er en optimist, der mener, at etisk og ansvarlig brug af kunstig intelligens kan forbedre samfundet i fremtiden og bringe økonomisk og social velstand. I sin fritid kan Rachna godt lide at bruge tid med sin familie, vandreture og lytte til musik.
 Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker indbyggede algoritmer og hjælper med at udvikle machine learning algoritmer. Han fik sin ph.d. fra University of Illinois Urbana-Champaign. Han er en aktiv forsker i maskinlæring og statistisk inferens og har publiceret mange artikler i NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP konferencer.
Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker indbyggede algoritmer og hjælper med at udvikle machine learning algoritmer. Han fik sin ph.d. fra University of Illinois Urbana-Champaign. Han er en aktiv forsker i maskinlæring og statistisk inferens og har publiceret mange artikler i NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP konferencer.
 Karl Albertsen fører produkt, teknik og videnskab for Amazon SageMaker Algorithms og JumpStart, SageMakers maskinlæringshub. Han brænder for at anvende maskinlæring til at frigøre forretningsværdi.
Karl Albertsen fører produkt, teknik og videnskab for Amazon SageMaker Algorithms og JumpStart, SageMakers maskinlæringshub. Han brænder for at anvende maskinlæring til at frigøre forretningsværdi.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/llama-guard-is-now-available-in-amazon-sagemaker-jumpstart/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 10
- 100
- 11
- 12
- 13
- 2021
- 39
- 7
- 8
- 9
- a
- I stand
- Om
- over
- Acceptere
- adgang
- Ifølge
- Konti
- Lov
- Handling
- aktioner
- aktiv
- aktiviteter
- faktiske
- Desuden
- Justeret
- vedtage
- fremme
- fremskridt
- kontradiktorisk
- rådgivning
- mod
- Agent
- AI
- AI modeller
- AI / ML
- Procenter
- algoritmer
- Alle
- også
- Amazon
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- an
- ,
- Annoncere
- besvare
- enhver
- Anvendelse
- anvendt
- Indløs
- Anvendelse
- passende
- ER
- argument
- argumenter
- Kunst
- AS
- vurdering
- hjælpe
- Assistant
- forbundet
- sikker
- At
- myndighed
- Automatiseret
- til rådighed
- undgå
- AWS
- baseret
- grundlæggende
- Bayesiansk
- BE
- Beam
- fordi
- været
- før
- begynde
- adfærd
- mener
- jf. nedenstående
- Benchmarks
- Berkeley
- BEDSTE
- bedste praksis
- mellem
- milliarder
- krop
- både
- bringe
- Bringer
- bygge
- Bygning
- indbygget
- virksomhed
- men
- by
- california
- CAN
- cannabis
- kort
- tilfælde
- tilfælde
- kategorier
- Boligtype
- celle
- udfordringer
- chance
- lave om
- karakteristika
- afgifter
- chatte
- chatbots
- kontrollere
- kemikalie
- valg
- Vælg
- vælge
- By
- klasse
- ren
- Cloud
- cloud computing
- kode
- farve
- kommer
- kommerciel
- engageret
- Fælles
- samfund
- kompatibel
- overholde
- komponenter
- sammensætning
- computer
- Computer Vision
- computing
- Konference
- konferencer
- Bekræfte
- BEKRÆFTET
- sammenløbet
- Konsol
- forbrug
- indeholder
- Container
- indeholder
- indhold
- indhold moderering
- sammenhæng
- fortsætter
- kontrol
- kontrolleret
- kontrol
- Samtale
- konversation
- samtaler
- madlavning
- Cornell
- kunne
- skabe
- skabelse
- forbrydelser
- Criminal
- kritisk
- kurateret
- kunde
- Kundeservice
- Kunder
- tilpasse
- Cyber
- cybersikkerhed
- cyklus
- data
- datasæt
- dag
- Dekodning
- dyb
- dyb læring
- Standard
- definere
- definitioner
- Degree
- indsætte
- indsat
- implementering
- implementering
- implementeringer
- Design
- designproces
- ønske
- ønskes
- detaljeret
- detaljer
- Detektion
- Bestem
- bestemmes
- udvikle
- Udvikler
- udviklere
- Udvikling
- DICT
- forskellige
- digital
- digital kunst
- Handicap
- opdage
- diskrimination
- diskutere
- do
- gør
- Narkotika
- Duke
- hertug universitet
- e
- hver
- tidligere
- Tidligt
- nemt
- Økonomisk
- økosystem
- Uddannelse
- effekter
- nemt
- muliggøre
- muliggør
- tilskynde
- ende
- ende til ende
- Endpoint
- endpoints
- engagere
- ingeniør
- Engineering
- sikre
- sikrer
- Miljø
- lige
- især
- Ether (ETH)
- etisk
- evaluere
- evalueringer
- begivenheder
- eksempel
- Undtagen
- undtagelse
- ophidset
- Eksklusive
- udførelse
- eksisterende
- dyrt
- udforske
- Express
- udvide
- Ansigtet
- konfronteret
- falsk
- familie
- Med
- få
- finansielle
- økonomiske forbrydelser
- Finde
- skydevåben
- Fornavn
- Markeret
- Flyde
- Fokus
- følger
- efterfulgt
- efter
- følger
- Til
- format
- fremme
- Foundation
- Gratis
- fra
- fuld
- funktioner
- yderligere
- fremtiden
- Køn
- Generelt
- generere
- genereret
- genererer
- generere
- generation
- generative
- Generativ AI
- få
- GitHub
- given
- Give
- Go
- gå
- fik
- større
- Greedy
- garantier
- Guard
- vejledning
- GUNS
- skade
- seletøj
- hader
- Have
- he
- Helse
- hjælpe
- hjælper
- hende
- link.
- højere
- hiking
- hans
- historisk
- hostede
- Hvordan
- How To
- HTML
- HTTPS
- Hub
- Hubs
- i
- ICLR
- ID
- Identifikation
- Identity
- if
- Ulovlig
- Illinois
- straks
- importere
- Forbedre
- in
- omfatter
- omfatter
- Herunder
- uafhængig
- angiver
- angiver
- angiver
- oplysninger
- Informational
- indgroet
- initial
- initiativ
- Innovation
- indgang
- indgange
- instans
- anvisninger
- medvirkende
- integrere
- integreret
- interesseret
- interesser
- grænseflade
- ind
- involverer
- IT
- ITS
- jpg
- Kill
- Kend
- kendt
- Kyle
- landing
- destinationsside
- Sprog
- stor
- Efternavn
- Love
- Leads
- læring
- forlader
- Længde
- lad
- Licens
- Licenseret
- licenser
- ligesom
- sandsynlighed
- Sandsynlig
- synes godt om
- Limited
- Line (linje)
- linux
- Liste
- Lytte
- Llama
- lokale
- UDSEENDE
- lavere
- maskine
- machine learning
- vedligeholde
- lave
- manuelt
- fremstillet
- mange
- herres
- Kan..
- betyder
- foranstaltninger
- Medier
- mentale
- Mental sundhed
- besked
- beskeder
- Meta
- metode
- metoder
- måske
- minutter
- afbødning
- blande
- ML
- model
- modeller
- moderat
- mådehold
- overvågning
- mere
- mest
- Musik
- skal
- Skal læses
- national
- behov
- net
- Neural
- neurale netværk
- NeurIPS
- aldrig
- Ny
- New York
- New York
- næste
- ingen
- notesbog
- notesbøger
- Varsel..
- nu
- nummer
- objekt
- of
- tilbyde
- on
- ONE
- kun
- åbent
- åbent
- operationelle
- Option
- Indstillinger
- or
- Oprindelse
- Andet
- vores
- ud
- Resultat
- output
- udgange
- i løbet af
- egen
- ejerskab
- side
- Papir
- papirer
- parameter
- parametre
- del
- særlig
- parter
- passerer
- Passing
- lidenskabelige
- Mennesker
- per
- udføre
- udfører
- person,
- personale
- phd
- Almindeligt
- fly
- planlægning
- plato
- Platon Data Intelligence
- PlatoData
- politik
- Populær
- positiv
- mulig
- Indlæg
- potentiale
- potentielt
- praksis
- forud
- Predictor
- forberede
- forelagt
- forhindre
- Main
- Prioriter
- sandsynlighed
- behandle
- Processer
- Produkt
- produktion
- projekt
- prompter
- velstand
- give
- forudsat
- udbydere
- giver
- offentligt
- offentliggjort
- Publicering
- formål
- sætte
- Python
- pytorch
- kvalitet
- hurtigt
- Løb
- tilfældighed
- rækkevidde
- hellere
- nå
- når
- Læs
- modtaget
- nylige
- anbefales
- henvise
- om
- reguleret
- regler
- relaterede
- frigive
- relevant
- religion
- gentaget
- erstatte
- anmodninger
- påkrævet
- forskning
- forsker
- Ressourcer
- respekt
- reagere
- svar
- ansvarlige
- ansvarligt
- REST
- resultere
- Resultater
- afkast
- gennemgå
- Rise
- Risiko
- Risikabel
- køreplan
- roller
- roller
- regler
- Kør
- løber
- sikker
- sikkerhedsforanstaltninger
- Sikkerhed
- sagemaker
- SageMaker Inference
- skalerbar
- Scale
- Videnskab
- Videnskabsmand
- SDK
- Søg
- søgning
- Anden
- Sektion
- sektioner
- sikker
- sikkerhed
- se
- Vælg
- senior
- følsom
- dømme
- følelser
- Sequence
- Series
- tjeneste
- Tjenester
- sæt
- Seksuel
- delt
- bør
- Vis
- viste
- viser
- vist
- enkelt
- So
- Social
- sociale medier
- Samfund
- Software
- Software Engineer
- løsninger
- Løsninger
- særligt
- specifikke
- specificeret
- udgifterne
- standarder
- påbegyndt
- Starter
- statistiske
- statistik
- Trin
- Steps
- Stadig
- stopper
- Strategisk
- strategier
- Studio
- vellykket
- sådan
- Selvmord
- support
- Understøtter
- sikker
- syntaks
- systemet
- Systemer
- Tag
- Opgaver
- opgaver
- hold
- skabelon
- skabeloner
- tensorflow
- vilkår
- prøve
- afprøvet
- tekst
- tekstgenerering
- end
- at
- Fremtiden
- oplysninger
- tyveri
- deres
- Them
- selv
- derefter
- Der.
- Disse
- de
- Tredje
- tredje partier
- tredjepart
- denne
- dem
- Gennem
- tid
- Tidsserier
- til
- tobak
- i dag
- sammen
- token
- Tokens
- værktøj
- værktøjer
- Emner
- menneskehandel
- Tog
- uddannet
- Kurser
- Oversættelse
- Traveling
- sand
- Stol
- prøv
- TUR
- typer
- typisk
- ui
- Ultimativt
- under
- forstå
- universitet
- University of California
- låse
- indtil
- us
- Brug
- brug
- brug tilfælde
- anvendte
- Bruger
- bruger
- ved brug af
- værdi
- Værdier
- række
- udgave
- Specifikation
- krænket
- Overtrædelse
- vision
- visuel
- gå
- ønsker
- Vej..
- we
- Våben
- web
- webservices
- web-baseret
- Hvad
- hvornår
- hvorvidt
- som
- WHO
- Hele
- bred
- vilje
- med
- inden for
- uden
- ord
- ord
- Arbejde
- workflow
- arbejder
- ville
- york
- dig
- Din
- zephyrnet