Optical Character Recognition (OCR), metoden til at konvertere håndskrevne/trykte tekster til maskinkodet tekst, har altid været et stort forskningsområde inden for computersyn på grund af dets mange anvendelser på tværs af forskellige domæner — Banker bruger OCR til at sammenligne udsagn; Regeringer bruger OCR til indsamling af undersøgelsesfeedback.

På grund af mangfoldigheden i håndskrift og trykte tekststile, inkorporerer nyere tilgange til OCR dyb læring for at opnå en højere nøjagtighed. Da dyb læring kræver enorme mængder data til modeltræning, tager virksomheder som Google et forspring i at producere lovende resultater med deres OCR-tjenester.
Denne artikel dykker ned i detaljerne i Google Vision OCR, herunder en simpel tutorial i python, rækken af applikationer, priser og andre alternativer.
- Hvad er Google Cloud Vision OCR?
- En simpel tutorial
- Hvorfor OCR?
- Eksempler på brugssager
- Priser
- Fremtrædende funktioner i Google Cloud Vision OCR
- Alternativer
- Almindelige problemer
Hvad er Google Cloud Vision?

Google Cloud Vision OCR er en del af Google Cloud Vision API til at udtrække tekst fra billeder. Specifikt er der to annotationer til at hjælpe med tegngenkendelsen:
- Tekst_anmærkning: Det uddrager og udlæser maskinkodede tekster fra ethvert billede (f.eks. fotos af gadeudsigter eller landskaber). Da den oprindeligt blev designet til at kunne bruges under forskellige lyssituationer, er modellen i en vis forstand mere robust til at læse ord af forskellige stilarter, men kun på et mere sparsomt niveau. Den returnerede JSON-fil inkluderer hele strengene såvel som de enkelte ord og deres tilsvarende afgrænsningsfelter.
- Document_Text_Annotation: Dette er specielt designet til tæt præsenterede tekstdokumenter (f.eks. scannede bøger). Mens den understøtter læsning af mindre og mere koncentrerede tekster, er den således mindre tilpasselig til in-the-wild billeder. Oplysninger såsom afsnit, blokke og brud er inkluderet i output-JSON-filen.
Leder du efter en OCR-løsning, der overvinder manglerne ved Google Cloud Vision eller zone OCR? Giv nanonetter™ et spin for højere nøjagtighed, større fleksibilitet og bredere dokumenttyper!
En simpel tutorial
Det følgende afsnit introducerer et simpelt selvstudie i at komme i gang med Google Vision API, især om hvordan man bruger det til Google Cloud Vision OCR-tjenesten.
Enkel oversigt
Ideen bag dette er meget intuitiv og enkel.
1) Du sender i det væsentlige et billede (fjernbetjening eller fra dit lokale lager) til Google Cloud Vision API.
2) Billedet behandles eksternt på Google Cloud og producerer de tilsvarende JSON-formater i forhold til den funktion, du kaldte.
3) JSON-filen returneres som output, efter at funktionen er kaldt.
Opsætning af Google Cloud Vision API
For at bruge tjenester leveret af Google Vision API skal man konfigurere Google Cloud Console og udføre en række trin til godkendelse. Det følgende er en trin-for-trin oversigt over, hvordan du opsætter hele Vision API-tjenesten.
- Opret et projekt i Google Cloud Console — Et projekt skal oprettes for at begynde at bruge en hvilken som helst Vision-tjeneste. Projektet organiserer ressourcer såsom samarbejdspartnere, API'er og prisoplysninger.
- Aktiver fakturering — For at aktivere vision API skal du først aktivere fakturering for dit projekt. Detaljerne om priser vil blive behandlet i senere afsnit.
- Aktiver Vision API
- Opret servicekonto — Opret en servicekonto og link til det oprettede projekt, og opret derefter en servicekontonøgle. Nøglen udlæses og downloades som en JSON-fil til din computer.
- Konfigurer miljøvariabel GOOGLE_APPLICATION_CREDENTIALS; For at opsætte denne miljøvariabel skal du køre denne på Mac/Linux eller Windows.
- Kodeblokke til Mac/Linux
- Kodeblokke til Windows
En mere detaljeret procedure for de førnævnte trin kan findes fra den officielle dokumentation fra Google Cloud herfra:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Simpel Google Vision OCR-funktion i Python
Google Cloud Vision API fungerer med adskillige populære sprog, lige fra Java, Node.js, Python til Googles eget sprog Go. For nemheds skyld introducerer vi en simpel opkaldsmetode i Python.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) Med andre ord kalder metoden derfor funktionen tekst_annotation, udtræk derefter svarene yderligere og print oplysningerne ud. document_text_annotation kan også kaldes ved at bruge samme måde til at hente tætte tekster. Man kan også fjerne billeder ved at indstille billedet via:
image.source.image_uri = urihvor uri er billedets uri.
Flere detaljer om koderne kan hentes her:
https://cloud.google.com/vision
Leder du efter en OCR-løsning, der overvinder manglerne ved Google Cloud Vision? Giv nanonetter™ et spin for højere nøjagtighed, større fleksibilitet og bredere dokumenttyper!
Tilbudt outputniveau
For at hjælpe med yderligere dataanalyse af teksten giver de to Google OCR-funktioner forskellige outputniveauer, som brugerne kan bruge: tekst_annotation, både hele strengene (hvis Google betragter dem som én sætning eller sætning) og de enkelte ord indeni; til document_text_annotation, da modellen er optimeret til tæt tekst, tilbydes side, blok, afsnit, ord og pause alle som en del af outputtet.
Hvor godt virker det dog?
Hvor robuste er modellerne?
Som tidligere nævnt tilbyder Google to funktioner til OCR i to forskellige situationer. Det følgende beskriver to funktioners evne til at hente forskellige typer data.
Udskrevne data
Den nemmeste type data at fortolke er trykte tekstdata, dvs. computerskrevet tekst printet og scannet. OCR er påkrævet, når vi kun har den udskrevne kopi af disse data i stedet for de originale maskinkodede tekster. Da de fleste af disse tekster er stramme og pakket i sider, document_text_annotation ville være en bedre mulighed.
Håndskrevne data
Indhold kan indeholde håndskrevet tekst, og stile af håndskrevne data kan variere drastisk. Ikke desto mindre giver Google Vision OCR en anstændig nøjagtighed, så længe de håndskrevne noter ikke er for rodet. Afhængigt af hvor pakket mediet med de håndskrevne data præsenteres, bruger vi en af de to funktioner fra sag til sag.
Roterede/i-vilde data
Når billederne eller de scannede fotos præsenteres i uortodokse eller ujusterede vinkler, betragter vi dem som in-the-wild data. Tekster kan potentielt være sværere at opdage i første omgang, og derfor bruger vi normalt tekst_annotation funktion, som var designet til at behandle in-the-wild data i første omgang. Baseret på nogle eksperimenter med at passere gennem lodrette tekster og vejskilte fanget i forskellige vinkler, viser vi, at Google Vision OCR faktisk klarer sig anstændigt på data fra forskellige miljøer.
Hvorfor OCR?
Mange af de data, vi har i dag, er i ustruktureret format. For eksempel, givet et billede, et scannet dokument eller et fotografi, mens mennesker hurtigt kan genkende teksterne og yderligere fortolke betydninger, er alle tekstdata blot pixels med farver, der ikke giver nogen reel betydning for maskiner.

Når virksomheder eller store virksomheder beskæftiger sig med enorme mængder papirarbejde, ville den store datamængde gøre det umuligt for enhver klassifikation eller databehandling at blive udført med udelukkende menneskelig indsats - det er her, maskinkodet tekst bliver praktisk.
Efter OCR-konvertering kan informationer derefter analyseres med flere forskellige metoder afhængigt af arten af data:
- For numeriske data kan statistiske metoder anvendes direkte til at analysere for eventuelle korrelationer. Vi kunne også anvende traditionelle maskinlæringsmetoder (f.eks. KNN, K-Means, Linear Regression) eller deep learning-tilgange for at skabe prædiktive modeller for regression og/eller klassifikation.
- For tekstdata kan der være behov for flere stadier af behandlingen. Processen med at analysere og fortolke tekstdata til meningsfuld statistik omtales ofte som naturlig sprogbehandling (NLP). Konkret kunne vi udtrække tal eller endda semantik/atmosfære baseret på givet indhold.
Alle disse analyser kunne give virksomheder, især dem med enorme mængder af nye data hver dag, mulighed for at skabe robuste modeller og endda automatisere en masse processer og erstatte de traditionelle arbejdskrævende og fejlpakkede tilgange. Det følgende afsnit graver i nogle detaljerede eksempler på, hvordan OCR kan bruges.
Leder du efter en OCR-løsning, der overvinder manglerne ved Google Cloud Vision? Giv nanonetter™ et spin for højere nøjagtighed, større fleksibilitet og bredere dokumenttyper!
Eksempler på brugssager
Nummerpladelæsning

Måske er en af de mest almindelige anvendelser af OCR i dag applikationen til nummerpladelæsning. I udviklede lande er parkeringspladser ofte ledsaget af nummerpladelæsningsmodeller for at bestemme indgangstid, udgangstidspunkt og endda den nøjagtige parkerede placering pr. bil. Nogle parkeringspladser er endda forbundet til det statslige netværk for at opkræve parkeringsafgifter direkte til familier - hvilket alt sammen lindrer overflødig menneskelig indsats.
Nummerplade-OCR-modellerne kan også anvendes til detektering i trafikovertrædelser, hvilket letter tiden for politiet til manuelt at indtaste dataene for den krænkende bil.
Kvittering og fakturascanning

Finansielle fremskrivninger og balancering af virksomheders aktiver og passiver er vigtige aktiviteter for enhver virksomhed. Da store virksomheder foretager indkøb i store mængder fra flere sektorer i løbet af året, er de forpligtet til omhyggeligt at indsamle og behandle alle fakturaer og kvitteringer, når de opretter regnskaber.
Ved hjælp af OCR kan vi skabe automatiserede pipelines, der genkende en række fakturaformater og konverter dem til tal. Arbejdsindsats er kun påkrævet til kontrol, og de strukturerede data og tal kan give virksomheden mulighed for hurtigt at balancere ind- og udstrømningen, skabe økonomiske fremskrivninger samt holde øje med eventuelle ondsindede manipulationer af virksomhedens økonomi.
Elektriske lægejournaler

Patientdata er ofte spredt rundt i en region, et land eller endda på tværs af lande afhængigt af individets livsstil. På grund af de forskellige stilarter af klinikker og hospitaler (store hospitaler kan have organiserede databaser, mens læger i mindre klinikker måske bare skriver journalerne ned i hånden), patienters alder (ældre patienter kan blive indsat i en bestemt database før renovering og inkorporering af computere), og enkeltpersoners placering (folk kan flytte til en anden by eller endda til udlandet), kan det faktisk være meget svært at holde en universalmedicinsk læge.
En veltrænet OCR bliver således praktisk, når man overfører EMR fra et hospital til et andet, eller transformerer håndskrevne data til maskintekst - begge dele kan fremskynde processen med at forstå patienters sygehistorie på en hurtig og kortfattet måde.
Formularer og undersøgelser

Organisationer (uanset om de er statslige eller ikke-statslige) kan ofte kræve feedback fra kunder eller borgere for at forbedre deres nuværende salgsfremmende planer og produkter. Da formularer normalt skrives i hånden, ville det potentielt være vanskeligt at udføre nogen direkte statistisk analyse. Derfor kan processen med at konvertere ustrukturerede data og håndskrevne undersøgelser til numeriske tal for at lette beregninger hjælpes og fremskyndes af OCR.
Leder du efter en OCR-løsning, der overvinder manglerne ved Google Cloud Vision? Giv nanonetter™ et spin for højere nøjagtighed, større fleksibilitet og bredere dokumenttyper!
Cloud Vision-priser
Ifølge Google hjemmeside, begge tekst_annotation , document_text_annotation tilbydes til samme prisniveau som følgende:
For hver måned gives de første 1000 enheder gratis, med de 1000-5000000 opkrævet til $1.5 pr. 1000 enheder. Efter at have ramt 5000000-mærket, falder prisen til $0.6 pr. 1000 enheder (Hvert billede, der sendes via Google Vision API, betragtes som én enhed).
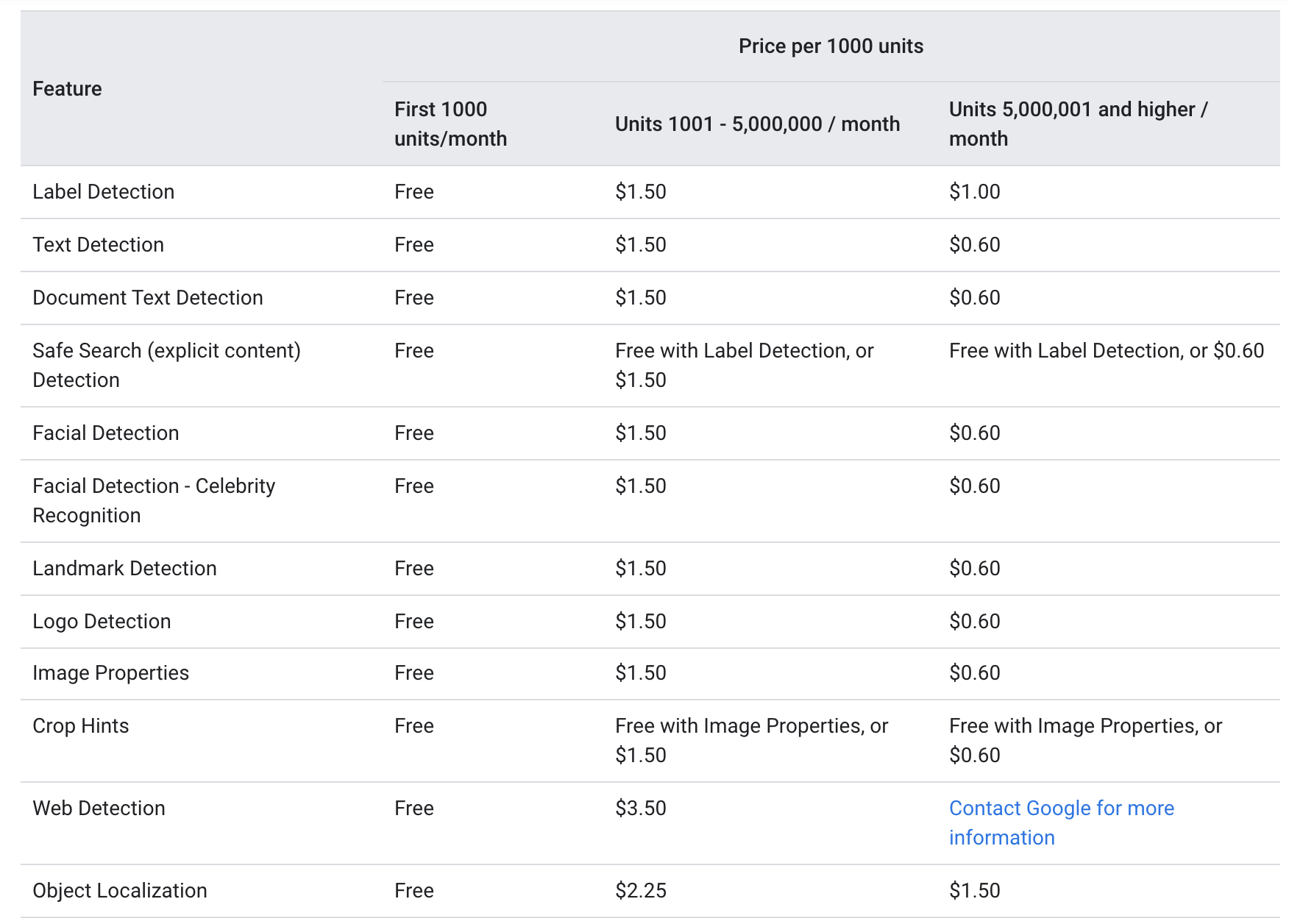
Ovenstående prissætning tyder på, at OCR-tjenesten er relativt overkommelig for både små virksomheder med mindre hyppige anvendelser såvel som store virksomheder, hvor tjenesten er påkrævet meget mere end 5000000 gange om måneden.
Fremtrædende funktioner i Google Cloud Vision OCR
Google OCR har forskellige fordele, her beskriver vi nogle af de vigtigste fordele:
- Robust — De to funktioner, der betjener to typer tekstdokumenter afhængigt af brugernes beslutning, gør Google Vision OCR forholdsvis mere robust end enkeltmodel OCR-motorer.
- Sprogstøtte - Med den måske største sprogdatabase, har Google oplyst, at dens OCR kan anvendes på mere end 60 sprog, eksperimenterer på et par snese mere og kortlægger mange af resten til en anden sprogkode eller generel sproggenkendelse.
- Brugervenlighed - Selve modellen er en del af det indbyggede Google Vision-bibliotek. Efter den lidt mere irriterende proces med at konfigurere API-nøglen (som kræves af næsten alle OCR-motorer), kan funktionsopkaldsmetoden bruges på adskillige sprog på en meget ligetil måde.
- Skalerbarhed - Googles prisstrategi opfordrer brugerne til at opskalere brugen af API'en, da mere brug fører til en billigere gennemsnitspris.
- Fart - Google Clouds lagringsplatform ledsager vidunderligt API-brugen. Ved at uploade billederne til drevet kan responstiden for API være meget hurtig og skalerbar.

Leder du efter en OCR-løsning, der overvinder manglerne ved Google Cloud Vision? Giv nanonetter™ et spin for højere nøjagtighed, større fleksibilitet og bredere dokumenttyper!
Alternativer
Følgende er nogle alternative OCR-tjenester ud over Google Vision API, sammen med fordele og ulemper ved hver tjeneste.
ABBYY
ABBYY FineReader PDF er en OCR udviklet af ABBYY, som især fokuserer på pdf-læsning.
- Fordele: ABBYY er meget mere omkostningsvenlig for individuelle brugere, da priserne er opdelt i mindre sektorer (1000, 2000 sider osv.). Den er også rettet mod ikke-ingeniørkunder, da det er en kommercialiseret app.
- Ulemper: Softwaren fokuserer kun på PDF-format, og prisen bliver meget dyr, når du laver OCR i stor skala.
- Hvornår skal du bruge: For individuelle brugere, der blot ønsker at håndtere PDF'er hurtigt, kan ABBYY være en mere levedygtig mulighed end Google Vision API, som giver mere fleksibilitet, men kræver ekstra koder.
microsoft
Microsoft Azure tilbyder også Read API til OCR.
- Fordele: Microsoft giver en billigere pris for et endnu større antal data, der skal bruges. Azure cloud storage tilbyder lignende tjenester som Google Cloud.
- Ulemper: Der er ikke noget gratis niveau, hvorimod andre muligheder giver gratis API-opkald til lavt forbrug.
- Hvornår skal du bruge: Meget storstilede OCR-produktionspipelines kunne drage fordel af Microsofts prissætning.
cofax
I lighed med ABBYY tilbyder Kofax også OCR-læsning af PDF'er
- Fordele: Prisen er fast for individuel brug, og der tilbydes rabatter til virksomheder. 24/7 kundesupport tilbydes også.
- Ulemper: Kvaliteten hævdes ikke at være så høj som ABBYY's.
- Hvornår skal du bruge: Små virksomheder med lave krav til brug.
AWS Textract
AWS Textract tjener en meget lignende rolle sammenlignet med Google Vision API. Deres tjenester og priser er meget ens, og så hvilken man skal bruge er helt baseret på kundernes præferencer.
Nanonetter
I modsætning til de tidligere omtalte tjenester er Nanonets' OCR'er yderligere kategoriseret i specifikke kategorier, med robuste modeller trænet på hver datatype (f.eks. kvitteringer, fakturaer, kørekort).
- Fordele: Kategorispecifikke OCR'er, hvilket giver endnu bedre resultater med hensyn til nøjagtighed, når virksomheder kræver OCR til målspecifikke applikationer.
- Ulemper: Nanonets OCR kan være mindre anvendelig til in-the-wild indstillinger på grund af de meget specifikke og skræddersyede modeller
- Hvornår skal du bruge: Hvis virksomheder kræver OCR for en bestemt type data, såsom fakturaer, kan Nanonets være en omkostningsvenlig og meget nøjagtig mulighed.
Du kan prøv Nanonets Online OCR her.
Almindelige problemer med Cloud Vision
I dette sidste afsnit sigter vi mod at besvare nogle spørgsmål fra Stackoverflow vedrørende dokumentscanning og OCR
Genkendelse af dokumenter ved hjælp af neurale netværk
Dette er den nøjagtige brug af Google OCR! Følg trinene ovenfor for at scanne dokumenter og udføre teksthentning.
Få fat i de vigtigste detaljer efter OCR
Ideen med at analysere det mest meningsfulde indhold i ethvert dokument kaldes naturlig sprogbehandling. Da hvert dokument indeholder sådanne oplysninger i forskellige formater, vil det anbefales at anvende nogle ML-tilgange til at gøre det. Selvfølgelig, hvis alle kort er i samme format, burde regelbaserede metoder til at hente teksterne med bestemte nøgletegn (f.eks. hvis det indeholder @ er det en e-mail) også fungere.
Kan det køre offline?
Forbindelse: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Desværre ikke. API'en kalder Google Cloud OCR eksternt, og du kan ikke arbejde offline, da API'en koster penge.
Kan den registrere, om en tekst er med fed eller kursiv?
Nej. Google OCR vil højst sandsynligt registrere tekstindholdet, selv når det er med fed eller kursiv skrift, men OCR-modellen er ikke designet til at forstå skrifttyper.
Update: Tilføjet mere info baseret på forespørgsler fra læsere.
- &
- a
- accelereret
- Konto
- præcis
- tværs
- aktiviteter
- adresse
- fordele
- Alle
- alternativ
- alternativer
- altid
- beløb
- analyse
- analysere
- En anden
- api
- API'er
- app
- anvendelig
- Anvendelse
- applikationer
- anvendt
- tilgange
- OMRÅDE
- omkring
- artikel
- Aktiver
- Godkendelse
- automatisere
- Automatiseret
- gennemsnit
- Azure
- Azure Cloud
- baggrund
- Banker
- grundlag
- før
- gavner det dig
- fordele
- fakturerings- og
- Bloker
- pin
- Bøger
- grænse
- pauser
- bil
- Kort
- vis
- tegn
- afgift
- opladet
- billigere
- kontrol
- By
- klassificering
- Cloud
- Cloud Storage
- kode
- Fælles
- Virksomheder
- selskab
- sammenlignet
- fuldstændig
- computer
- computere
- tilsluttet
- Overvej
- Konsol
- indeholder
- indhold
- indhold
- Konvertering
- Selskaber
- Tilsvarende
- Omkostninger
- kunne
- lande
- land
- skabe
- oprettet
- Oprettelse af
- Nuværende
- kunde
- Kunde support
- Kunder
- data
- dataanalyse
- databehandling
- Database
- databaser
- dag
- beskæftiger
- beslutning
- dyb
- afhængig
- Afhængigt
- beskrive
- konstrueret
- detaljeret
- detaljer
- opdaget
- Bestem
- udviklet
- forskellige
- svært
- direkte
- direkte
- Mangfoldighed
- Læger
- dokumenter
- Domæner
- ned
- køre
- kørsel
- hver
- lempelse
- Edge
- indsats
- indsats
- opstået
- muliggøre
- tilskynder
- virksomheder
- Miljø
- især
- væsentlige
- etc.
- eksempler
- Udgang
- Uddrag
- familier
- FAST
- Funktionalitet
- tilbagemeldinger
- Gebyrer
- økonomi
- finansielle
- Firm
- Fornavn
- fast
- Fleksibilitet
- fokuserer
- følger
- efter
- format
- formularer
- fundet
- Gratis
- fra
- funktion
- funktioner
- yderligere
- Generelt
- få
- statslige
- regeringer
- større
- håndtere
- hjælpe
- link.
- Høj
- højere
- stærkt
- historie
- sygehuse
- Hvordan
- How To
- HTTPS
- menneskelig
- Mennesker
- idé
- billede
- billeder
- vigtigt
- umuligt
- Forbedre
- medtaget
- omfatter
- Herunder
- individuel
- enkeltpersoner
- info
- oplysninger
- instans
- intuitiv
- spørgsmål
- IT
- selv
- Java
- holde
- Nøgle
- arbejdskraft
- Sprog
- Sprog
- stor
- større
- største
- Leads
- læring
- Niveau
- niveauer
- Bibliotek
- Licens
- licenser
- livsstil
- Sandsynlig
- LINK
- lokale
- placering
- placeringer
- Lang
- maskine
- machine learning
- Maskiner
- større
- lave
- måde
- manuelt
- Maps
- markere
- massive
- betyder
- meningsfuld
- medicinsk
- medium
- nævnte
- metoder
- microsoft
- ML
- model
- modeller
- penge
- Måned
- mere
- mest
- bevæge sig
- flere
- Natural
- Natur
- behov
- netværk
- Ikke desto mindre
- Noter
- nummer
- numre
- talrige
- tilbydes
- Tilbud
- officiel
- offline
- online
- optimeret
- Option
- Indstillinger
- ordrer
- Organiseret
- Andet
- egen
- pakket
- parkering
- del
- særlig
- især
- Passing
- Mennesker
- måske
- planer
- perron
- Police
- Populær
- vigtigste
- pris
- prissætning
- behandle
- Processer
- forarbejdning
- produktion
- Produkter
- projekt
- fremskrivninger
- lovende
- salgsfremmende
- give
- forudsat
- giver
- leverer
- indkøb
- kvalitet
- hurtigt
- rækkevidde
- spænder
- RE
- læsere
- Læsning
- nylige
- genkende
- optegnelser
- om
- region
- fjern
- kræver
- påkrævet
- Krav
- Kræver
- forskning
- Ressourcer
- svar
- REST
- Resultater
- vej
- roller
- Kør
- samme
- skalerbar
- Scale
- scanne
- scanning
- Sektorer
- forstand
- Series
- tjeneste
- Tjenester
- servering
- sæt
- indstilling
- signifikant
- Skilte
- lignende
- Simpelt
- siden
- lille
- So
- Software
- solid
- løsninger
- nogle
- specifikke
- specifikt
- Spin
- etaper
- påbegyndt
- udsagn
- statistiske
- statistik
- opbevaring
- Strategi
- gade
- struktureret
- support
- Understøtter
- Kortlægge
- vilkår
- derfor
- Gennem
- hele
- tid
- gange
- i dag
- mod
- traditionelle
- Trafik
- Kurser
- Overførsel
- omdanne
- typer
- under
- forstå
- forståelse
- enheder
- Universal
- brug
- brugere
- sædvanligvis
- forskellige
- vision
- bind
- Ur
- hvorvidt
- mens
- WHO
- bredere
- vinduer
- inden for
- ord
- Arbejde
- virker
- ville
- X
- år
- Din