Apache Hudi er et åbent tabelformat, der bringer database- og datavarehusfunktioner til datasøer. Apache Hudi hjælper dataingeniører med at håndtere komplekse udfordringer, såsom at administrere datasæt i konstant udvikling med transaktioner, samtidig med at forespørgselsydeevnen opretholdes. Dataingeniører bruger Apache Hudi til streaming af arbejdsbelastninger samt til at skabe effektive inkrementelle datapipelines. Hudi sørger for tabeller, transaktioner, effektive upserts og sletninger, avancerede indekser, tjenester til streamingindtagelse, data klyngedannelse , komprimering optimeringer, og samtidighedskontrol, alt imens du holder dine data i open source-filformater. Hudis avancerede ydeevneoptimeringer gør analytiske arbejdsbelastninger hurtigere med enhver af de populære forespørgselsmotorer, herunder Apache Spark, Presto, Trino, Hive og så videre.
Mange AWS-kunder adopterede Apache Hudi på deres datasøer bygget oven på Amazon S3 vha AWS Lim, en serverløs dataintegrationstjeneste, der gør det nemmere at opdage, forberede, flytte og integrere data fra flere kilder til analyse, maskinlæring (ML) og applikationsudvikling. AWS limcrawler er en komponent i AWS Glue, som giver dig mulighed for at oprette tabelmetadata fra dataindhold automatisk uden at kræve manuel definition af metadataene.
AWS Glue-crawlere understøtter nu Apache Hudi-tabeller, hvilket forenkler vedtagelsen af AWS Glue Data Katalog som kataloget for Hudi-borde. Et typisk brugstilfælde er at registrere Hudi-tabeller, som ikke har katalogtabeldefinition. En anden typisk anvendelse er migrering fra andre Hudi-kataloger, såsom Hive metastore. Når du migrerer fra andre Hudi-kataloger, kan du oprette og planlægge en AWS Glue-crawler og give en eller flere Amazon S3-stier, hvor Hudi-tabelfilerne er placeret. Du har mulighed for at give den maksimale dybde af Amazon S3-stier, som AWS Glue-crawleren kan krydse. Med hver kørsel vil AWS Glue-crawlere udtrække skema- og partitionsoplysninger og opdatere AWS Glue Data Catalog med skema- og partitionsændringerne. AWS Glue-crawlere opdaterer den seneste metadatafilplacering i AWS Glue Data Catalogue, som AWS analytiske motorer kan bruge direkte.
Med denne lancering kan du oprette og planlægge en AWS Glue-crawler til at registrere Hudi-tabeller i AWS Glue Data Catalog. Du kan derefter angive en eller flere Amazon S3-stier, hvor Hudi-tabellerne er placeret. Du har mulighed for at give den maksimale dybde af Amazon S3-stier, som crawlere kan krydse. Med hver crawlerkørsel inspicerer crawleren hver af S3-stierne og katalogiserer skemaoplysningerne, såsom nye tabeller, sletninger og opdateringer til skemaer i AWS Glue Data Catalog. Crawlere inspicerer partitionsoplysninger og tilføjer nyligt tilføjede partitioner til AWS Glue Data Catalog. Crawlere opdaterer også den seneste metadatafilplacering i AWS Glue Data Catalog, som AWS analytiske motorer kan bruge direkte.
Dette indlæg demonstrerer, hvordan denne nye evne til at gennemgå Hudi-tabeller fungerer.
Sådan fungerer AWS Glue crawler med Hudi-borde
Hudi-tabeller har to kategorier, med specifikke implikationer for hver:
- Kopier ved skrivning (CoW) – Data gemmes i et kolonneformat (Parquet), og hver opdatering opretter en ny version af filer under en skrivning.
- Flet ved læsning (MoR) – Data gemmes ved hjælp af en kombination af søjleformede (Parquet) og rækkebaserede (Avro) formater. Opdateringer logges til rækkebaseret
deltafiler og komprimeres efter behov for at skabe nye versioner af søjlefilerne.
Med CoW-datasæt omskrives filen, der indeholder posten, hver gang der er en opdatering til en post med de opdaterede værdier. Med et MoR-datasæt, hver gang der er en opdatering, skriver Hudi kun rækken for den ændrede post. MoR er bedre egnet til skrive- eller ændringstunge arbejdsbelastninger med færre læsninger. CoW er bedre egnet til læsetunge arbejdsbelastninger på data, der ændrer sig sjældnere.
Hudi giver tre forespørgselstyper til at få adgang til dataene:
- Snapshot-forespørgsler – Forespørgsler, der ser det seneste øjebliksbillede af tabellen som en given commit eller komprimeringshandling. For MoR-tabeller afslører snapshot-forespørgsler den seneste tilstand af tabellen ved at flette basis- og deltafilerne for det seneste filudsnit på tidspunktet for forespørgslen.
- Inkrementelle forespørgsler – Forespørgsler ser kun nye data skrevet til tabellen, da en given commit eller komprimering. Dette giver effektivt ændringsstrømme for at muliggøre inkrementelle datapipelines.
- Læs optimerede forespørgsler – For MoR-tabeller, se forespørgsler de seneste data komprimeret. For CoW-tabeller, se forespørgsler de seneste begåede data.
For kopier-på-skriv-tabeller opretter crawlere en enkelt tabel i AWS Glue Data Catalog med ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
For flette-på-læs-tabeller opretter crawlere to tabeller i AWS Glue Data Catalog for den samme tabelplacering:
- En tabel med suffiks
_ro, som bruger ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - En tabel med suffiks
_rt, som bruger RealTime Serde, der tillader Snapshot-forespørgsler:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Under hver gennemgang foretager crawlere for hver angivne Hudi-sti et Amazon S3-liste API-kald, filter baseret på .hoodie mapper, og find den seneste metadatafil under den Hudi-tabelmetadatamappe.
Crawl et Hudi CoW bord ved hjælp af AWS Glue crawler
Lad os i dette afsnit gennemgå, hvordan man crawler en Hudi CoW ved hjælp af AWS Glue-crawlere.
Forudsætninger
Her er forudsætningerne for denne tutorial:
- Installer og konfigurer AWS Command Line Interface (AWS CLI).
- Lav din S3-spand, hvis du ikke har den.
- Opret din IAM-rolle for AWS Glue hvis du ikke har det. Du mangler
s3:GetObjectforums3://your_s3_bucket/data/sample_hudi_cow_table/. - Kør følgende kommando for at kopiere Hudi-eksemplet til din S3-bøtte. (Erstatte
your_s3_bucketmed dit S3-spandnavn.)
Denne instruktion guider dig til at kopiere eksempeldata, men du kan nemt oprette alle Hudi-tabeller ved hjælp af AWS Glue. Lær mere i Introduktion af indbygget support til Apache Hudi, Delta Lake og Apache Iceberg på AWS Glue for Apache Spark, del 2: AWS Glue Studio Visual Editor.
Opret en Hudi-crawler
I denne instruktion skal du oprette crawleren gennem konsollen. Udfør følgende trin for at oprette en Hudi-crawler:
- På AWS Glue-konsollen skal du vælge Crawlere.
- Vælg Opret crawler.
- Til Navn, gå ind
hudi_cow_crawler. Vælg Næste. - Under Datakildekonfiguration, vælg Tilføj datakilde.
- Til Datakilde, vælg Hudi.
- Til Inkluder hudi-bordstier, gå ind
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Erstatteyour_s3_bucketmed dit S3-spandnavn.) - Vælg Tilføj Hudi-datakilde.
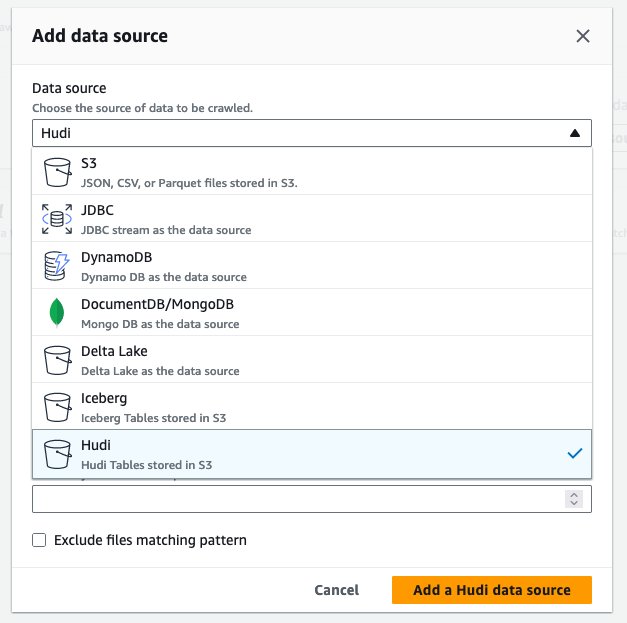
- Vælg Næste.
- Til Eksisterende IAM-rolle, vælg din IAM-rolle, og vælg derefter Næste.
- Til Måldatabase, vælg Tilføj database, så den Tilføj database dialogboksen vises. Til Databasens navn, gå ind
hudi_crawler_blog, Og vælg derefter Opret. Vælg Næste. - Vælg Opret crawler.
Nu er en ny Hudi-crawler blevet oprettet. Crawleren kan udløses til at køre gennem konsollen eller gennem SDK eller AWS CLI ved hjælp af StartCrawl API. Det kan også planlægges via konsollen til at udløse crawlerne på bestemte tidspunkter. I denne instruktion skal du køre crawleren gennem konsollen.
- Vælg Kør crawler.
- Vent på, at webcrawleren er færdig.
Efter at crawleren er kørt, kan du se Hudi-tabelldefinitionen i AWS Glue-konsollen:
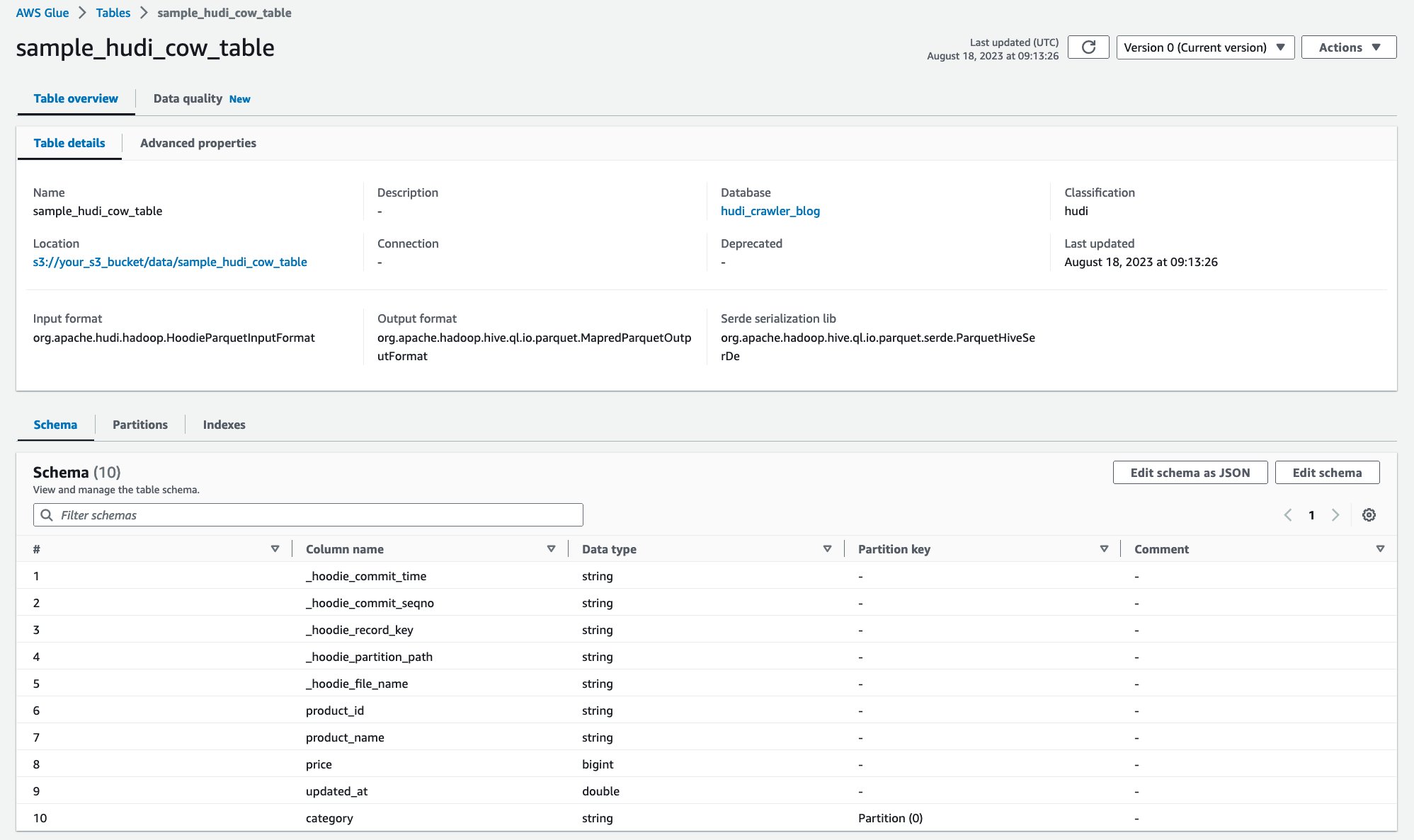
Du har crawlet Hudi CoR-tabellen med data på Amazon S3 og oprettet en AWS Glue Data Catalog-tabel med skemaet udfyldt. Når du har oprettet tabeldefinitionen på AWS Glue Data Catalog, er AWS-analysetjenester såsom Amazon Athena i stand til at forespørge i Hudi-tabellen.
Udfør følgende trin for at starte forespørgsler på Athena:
- Åbn Amazon Athena-konsollen.
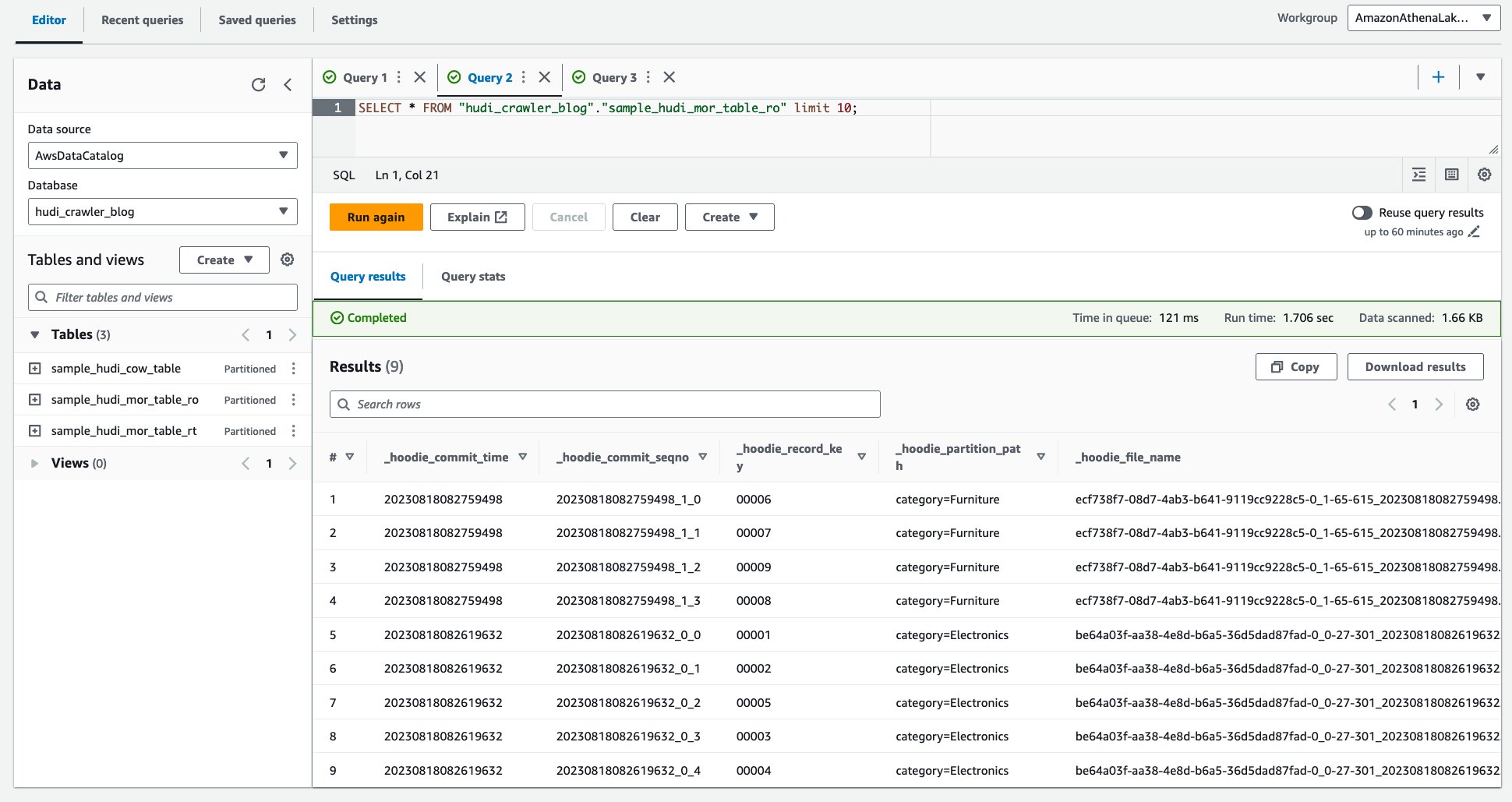
- Kør følgende forespørgsel.
Følgende skærmbillede viser vores output:
Gennemgå en Hudi MoR-tabel ved hjælp af AWS Glue-crawler med AWS Lake Formation-datatilladelser
Lad os i dette afsnit gennemgå, hvordan man gennemgår et Hudi MoR-bord ved hjælp af AWS Glue. Denne gang bruger du AWS Lake Formation-datatilladelse til at gennemgå Amazon S3-datakilder i stedet for IAM- og Amazon S3-tilladelse. Dette er valgfrit, men det forenkler tilladelseskonfigurationer, når din datasø administreres af AWS Lake Formation-tilladelser.
Forudsætninger
Her er forudsætningerne for denne tutorial:
- Installer og konfigurer AWS Command Line Interface (AWS CLI).
- Lav din S3-spand, hvis du ikke har den.
- Opret din IAM-rolle for AWS Glue hvis du ikke har det. Du mangler
lakeformation:GetDataAccess. Men du behøver ikkes3:GetObjectforums3://your_s3_bucket/data/sample_hudi_mor_table/fordi vi bruger Lake Formation-datatilladelse til at få adgang til filerne. - Kør følgende kommando for at kopiere Hudi-eksemplet til din S3-bøtte. (Erstatte
your_s3_bucketmed dit S3-spandnavn.)
Ud over behandlingstrinnene skal du udføre følgende trin for at opdatere AWS Glue Data Catalog-indstillingerne for at bruge Lake Formation-tilladelser til at kontrollere katalogressourcer i stedet for IAM-baseret adgangskontrol:
- Log ind på Lake Formation-konsollen som datasø-administrator.
- Hvis det er første gang, du får adgang til Lake Formation-konsollen, tilføje dig selv som data sø-administrator.
- Under Administration, vælg Indstillinger for datakatalog.
- Til Standardtilladelser for nyoprettede databaser og tabeller, fravælg Brug kun IAM-adgangskontrol til nye databaser , Brug kun IAM-adgangskontrol til nye tabeller i nye databaser.
- Til Indstilling for version på tværs af konti, vælg Version 3.
- Vælg Gem.
Det næste trin er at registrere din S3-spand i Lake Formation-datasøplaceringer:
- Vælg på Lake Formation-konsollen Placering af datasøer, og vælg Registrer placering.
- Til Amazon S3-sti, gå ind
s3://your_s3_bucket/. (Erstatteyour_s3_bucketmed dit S3-spandnavn.) - Vælg Registrer placering.
Giv derefter Glue-crawler-rolleadgang til dataplacering, så crawleren kan bruge Lake Formation-tilladelse til at få adgang til dataene og oprette tabeller på placeringen:
- Vælg på Lake Formation-konsollen Dataplaceringer Og vælg Grant.
- Til IAM brugere og roller, vælg den IAM-rolle, du brugte til crawleren.
- Til Opbevaringssted, gå ind
s3://your_s3_bucket/data/. (Erstatteyour_s3_bucketmed dit S3-spandnavn.) - Vælg Grant.
Giv derefter crawler-rolle til at oprette tabeller under databasen hudi_crawler_blog:
- Vælg på Lake Formation-konsollen Data sø-tilladelser.
- Vælg Grant.
- Til Rektorer, vælg IAM brugere og roller, og vælg crawler-rollen.
- Til LF-tags eller katalogressourcer, vælg Navngivne datakatalogressourcer.
- Til Database, vælg databasen
hudi_crawler_blog. - Under Databasetilladelser, Vælg Opret tabel.
- Vælg Grant.
Opret en Hudi-crawler med Lake Formation-datatilladelser
Udfør følgende trin for at oprette en Hudi-crawler:
- På AWS Glue-konsollen skal du vælge Crawlere.
- Vælg Opret crawler.
- Til Navn, gå ind
hudi_mor_crawler. Vælg Næste. - Under Datakildekonfiguration, vælg Tilføj datakilde.
- Til Datakilde, vælg Hudi.
- Til Inkluder hudi-bordstier, gå ind
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Erstatteyour_s3_bucketmed dit S3-spandnavn.) - Vælg Tilføj Hudi-datakilde.
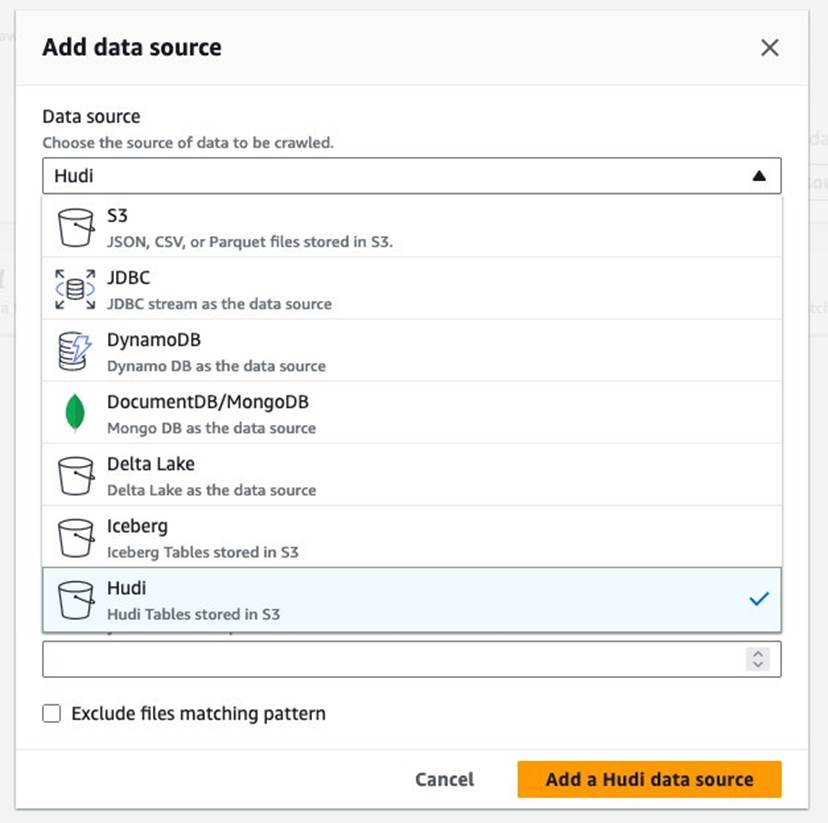
- Vælg Næste.
- Til Eksisterende IAM-rolle, vælg din IAM-rolle.
- Under Søformationskonfiguration – valgfri, Vælg Brug Lake Formation-legitimationsoplysninger til at gennemgå S3-datakilden.
- Vælg Næste.
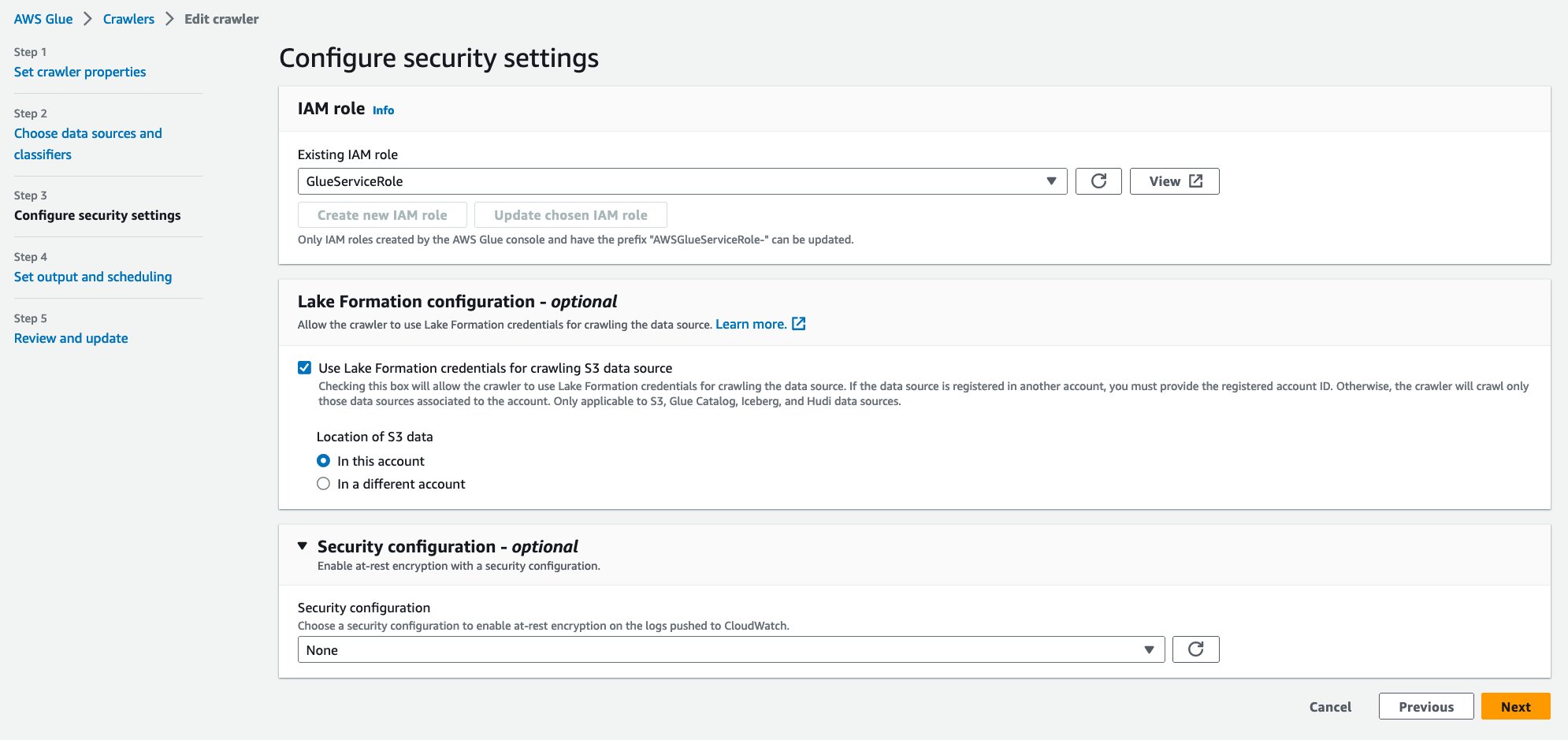
- Til Måldatabase, vælg
hudi_crawler_blog. Vælg Næste. - Vælg Opret crawler.
Nu er en ny Hudi-crawler blevet oprettet. Webcrawleren bruger Lake Formation-legitimationsoplysninger til at crawle Amazon S3-filer. Lad os køre den nye crawler:
- Vælg Kør crawler.
- Vent på, at webcrawleren er færdig.
Efter at crawleren er kørt, kan du se to tabeller af Hudi-tabelldefinitionen i AWS Glue-konsollen:
sample_hudi_mor_table_ro(læs optimeret tabel)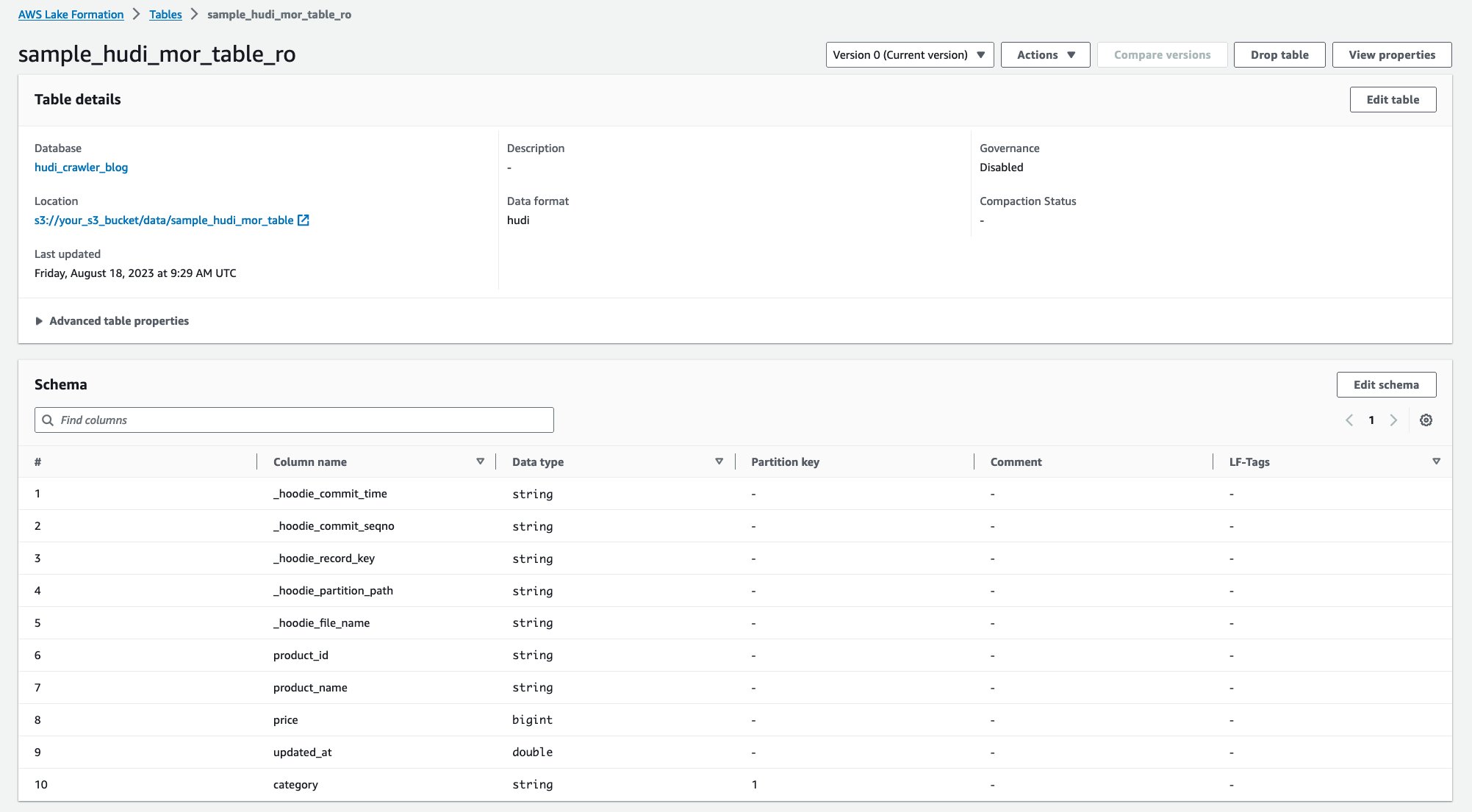
sample_hudi_mor_table_rt(tidstabel i realtid)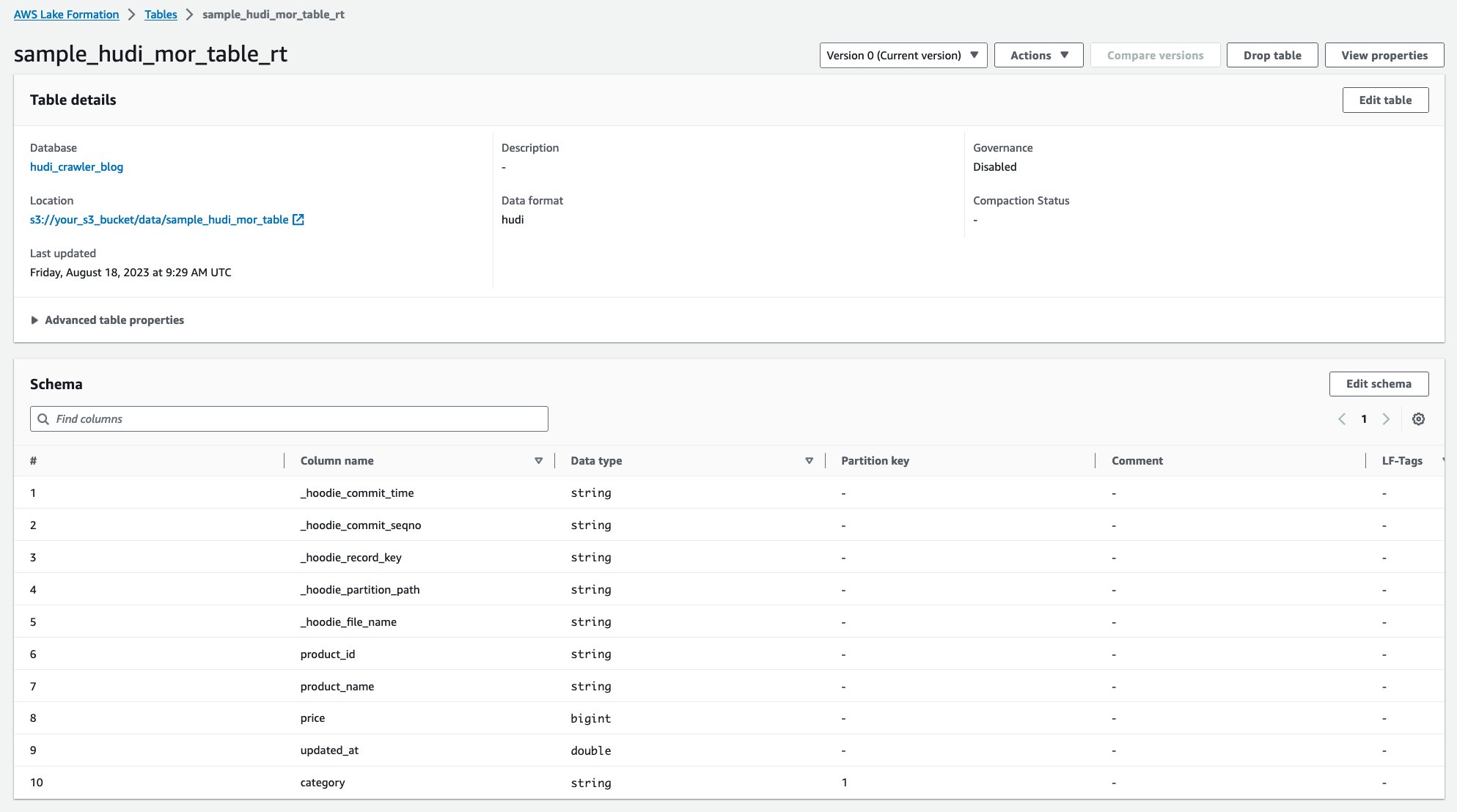
Du registrerede datasøen med Lake Formation og aktiverede gennemgangsadgang til datasøen ved hjælp af Lake Formation-tilladelser. Du har crawlet Hudi MoR-tabellen med data på Amazon S3 og oprettet en AWS Glue Data Catalog-tabel med skemaet udfyldt. Når du har oprettet tabeldefinitionerne på AWS Glue Data Catalog, er AWS-analysetjenester såsom Amazon Athena i stand til at forespørge i Hudi-tabellen.
Udfør følgende trin for at starte forespørgsler på Athena:
- Åbn Amazon Athena-konsollen.
- Kør følgende forespørgsel.
Følgende skærmbillede viser vores output:
- Kør følgende forespørgsel.
Følgende skærmbillede viser vores output:
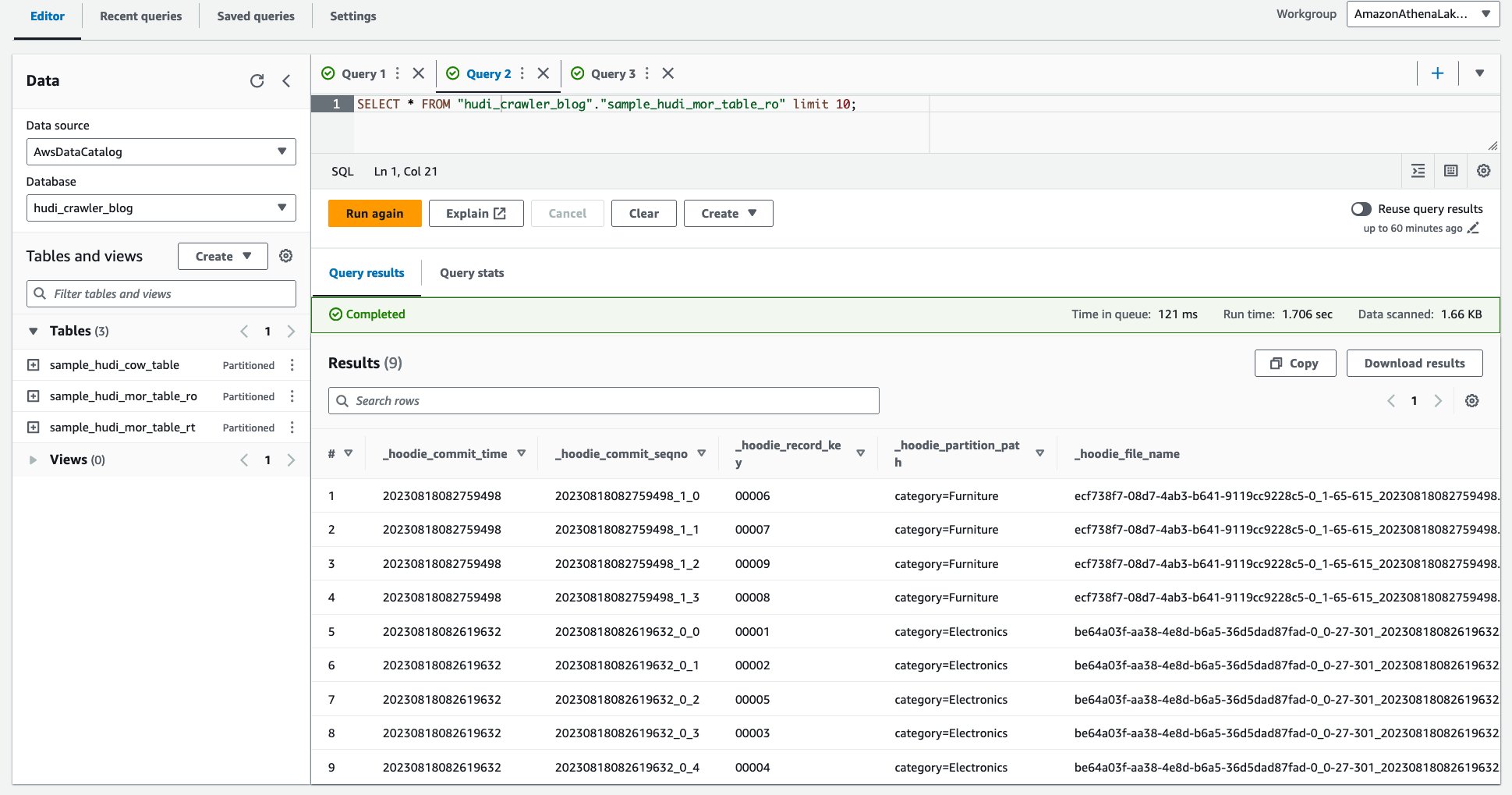
Finmasket adgangskontrol ved hjælp af AWS Lake Formation-tilladelser
For at anvende finkornet adgangskontrol på Hudi-bordet kan du drage fordel af AWS Lake Formation-tilladelser. Lake Formation-tilladelser giver dig mulighed for at begrænse adgangen til specifikke tabeller, kolonner eller rækker og derefter forespørge Hudi-tabellerne gennem Amazon Athena med finmasket adgangskontrol. Lad os konfigurere Lake Formation-tilladelsen for Hudi MoR-tabellen.
Forudsætninger
Her er forudsætningerne for denne tutorial:
- Fuldfør forrige afsnit Gennemgå en Hudi MoR-tabel ved hjælp af AWS Glue-crawler med AWS Lake Formation-datatilladelser.
- Opret en IAM-bruger DataAnalyst, som har AWS-styret politik AmazonAthenaFuld adgang.
Opret et søformationsdatacellefilter
Lad os først opsætte et filter til den MoR-læsningsoptimerede tabel.
- Log ind på Lake Formation-konsollen som datasø-administrator.
- Vælg Datafiltre.
- Vælg Opret nyt filter.
- Til Datafilternavn, gå ind
exclude_product_price. - Til Måldatabase, vælg databasen
hudi_crawler_blog. - Til Måltabel, vælg bordet
sample_hudi_mor_table_ro. - Til Kolonneniveau adgang, vælg Ekskluder kolonner, og vælg kolonneprisen.
- Til Rækkefilterudtryk, gå ind
true. - Vælg Opret filter.
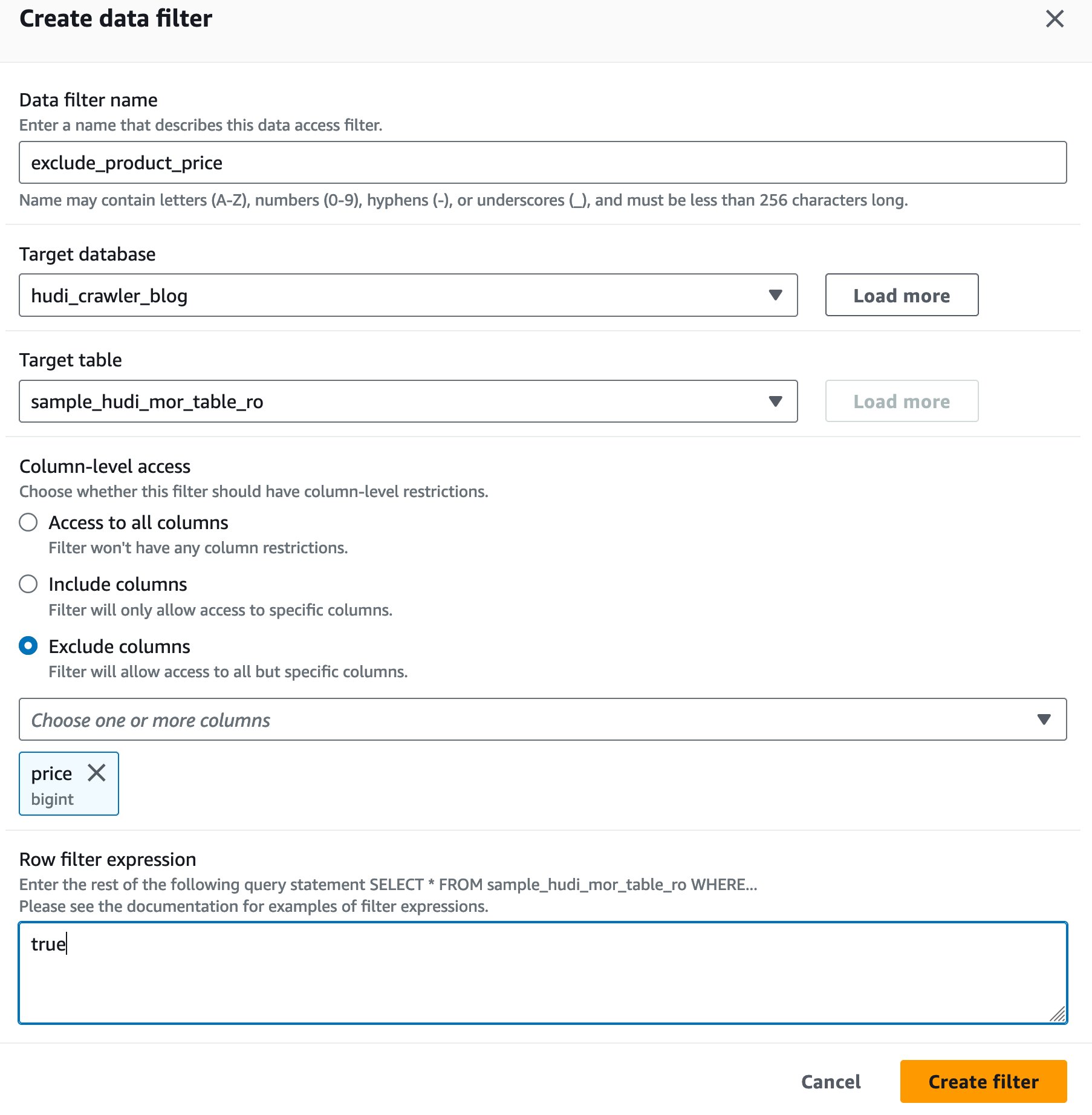
Giv Lake Formation-tilladelser til DataAnalyst-brugeren
Udfør følgende trin for at give Lake Formation tilladelse til DataAnalyst bruger
- Vælg på Lake Formation-konsollen Data sø-tilladelser.
- Vælg Grant.
- Til Rektorer, vælg IAM brugere og roller, og vælg brugeren
DataAnalyst. - Til LF-tags eller katalogressourcer, vælg Navngivne datakatalogressourcer.
- Til Database, vælg databasen
hudi_crawler_blog. - Til Bord – valgfrit, vælg bordet
sample_hudi_mor_table_ro. - Til Datafiltre – valgfrit, Vælg
exclude_product_price. - Til Datafiltertilladelser, Vælg Type.
- Vælg Grant.
Du har givet Lake Formation tilladelse til databasen hudi_crawler_blog og bordet sample_hudi_mor_table_ro, eksklusive kolonnen price til DataAnalyst-brugeren. Lad os nu validere brugeradgang til dataene ved hjælp af Athena.
- Log ind på Athena-konsollen som DataAnalyst-bruger.
- Kør følgende forespørgsel i forespørgselseditoren:
Følgende skærmbillede viser vores output:
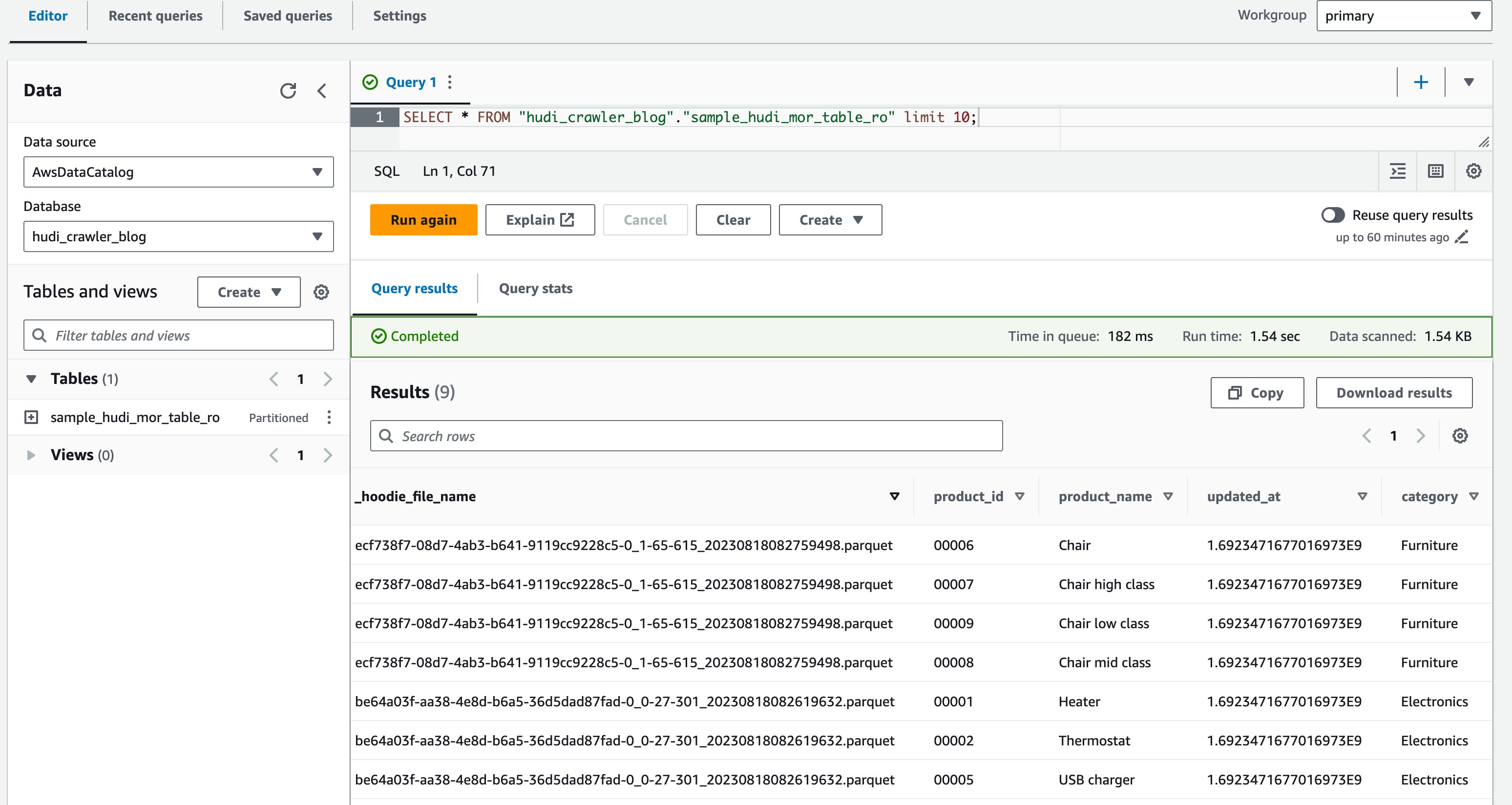
Nu har du bekræftet, at kolonnen price vises ikke, men de andre kolonner product_id, product_name, update_atog category vises.
Ryd op
For at undgå uønskede debiteringer på din AWS-konto skal du slette følgende AWS-ressourcer:
- Slet AWS Glue database
hudi_crawler_blog. - Slet AWS Glue crawlere
hudi_cow_crawler,hudi_mor_crawler. - Slet Amazon S3-filer under
s3://your_s3_bucket/data/sample_hudi_cow_table/,s3://your_s3_bucket/data/sample_hudi_mor_table/.
Konklusion
Dette indlæg demonstrerede, hvordan AWS Glue-crawlere fungerer til Hudi-borde. Med understøttelsen af Hudi-crawler kan du hurtigt gå over til at bruge AWS Glue Data Catalog som dit primære Hudi-tabelkatalog. Du kan begynde at bygge din serverløse transaktionsdatasø ved hjælp af Hudi på AWS ved hjælp af AWS Glue, AWS Glue Data Catalog og Lake Formation finkornede adgangskontroller til tabeller og formater, der understøttes af AWS analytiske motorer.
Om forfatterne
 Noritaka Sekiyama er Principal Big Data Architect på AWS Glue-teamet. Han arbejder med base i Tokyo, Japan. Han er ansvarlig for at bygge softwareartefakter for at hjælpe kunder. I sin fritid nyder han at cykle med sin landevejscykel.
Noritaka Sekiyama er Principal Big Data Architect på AWS Glue-teamet. Han arbejder med base i Tokyo, Japan. Han er ansvarlig for at bygge softwareartefakter for at hjælpe kunder. I sin fritid nyder han at cykle med sin landevejscykel.
 Kyle Duong er softwareudviklingsingeniør på AWS Glue and Lake Formation-teamet. Han brænder for at bygge big data-teknologier og distribuerede systemer.
Kyle Duong er softwareudviklingsingeniør på AWS Glue and Lake Formation-teamet. Han brænder for at bygge big data-teknologier og distribuerede systemer.
 Sandeep Adwankar er Senior Technical Product Manager hos AWS. Baseret i California Bay-området arbejder han med kunder over hele kloden for at omsætte forretningsmæssige og tekniske krav til produkter, der sætter kunder i stand til at forbedre, hvordan de administrerer, sikrer og får adgang til data.
Sandeep Adwankar er Senior Technical Product Manager hos AWS. Baseret i California Bay-området arbejder han med kunder over hele kloden for at omsætte forretningsmæssige og tekniske krav til produkter, der sætter kunder i stand til at forbedre, hvordan de administrerer, sikrer og får adgang til data.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :har
- :er
- :ikke
- :hvor
- $OP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- I stand
- Om
- adgang
- Adgang til data
- Adgang
- Konto
- Handling
- tilføje
- tilføjet
- Desuden
- vedtaget
- Vedtagelse
- fremskreden
- Efter
- Alle
- tillade
- tillade
- tillader
- også
- Amazon
- Amazonas Athena
- Amazon Web Services
- an
- Analytisk
- analytics
- ,
- En anden
- enhver
- Apache
- Apache Spark
- api
- kommer til syne
- Anvendelse
- Application Development
- Indløs
- ER
- OMRÅDE
- omkring
- AS
- At
- automatisk
- undgå
- AWS
- AWS Lim
- AWS søformation
- bund
- baseret
- Bugt
- BE
- fordi
- været
- gavner det dig
- Bedre
- Big
- Big data
- Bringer
- Bygning
- bygget
- virksomhed
- men
- by
- california
- ringe
- CAN
- kapaciteter
- kapacitet
- tilfælde
- katalog
- kataloger
- kategorier
- celle
- udfordringer
- lave om
- ændret
- Ændringer
- afgifter
- Vælg
- Kolonne
- Kolonner
- kombination
- begå
- engageret
- fuldføre
- komplekse
- komponent
- Konfiguration
- Konsol
- indeholder
- indhold
- kontinuerligt
- kontrol
- kontrol
- kunne
- crawler
- skabe
- oprettet
- skaber
- Legitimationsoplysninger
- Kunder
- data
- dataintegration
- Data Lake
- datalager
- Database
- databaser
- datasæt
- definition
- definitioner
- Delta
- demonstreret
- demonstrerer
- dybde
- Udvikling
- direkte
- opdage
- distribueret
- distribuerede systemer
- do
- gør
- i løbet af
- hver
- lettere
- nemt
- editor
- effektivt
- effektiv
- muliggøre
- aktiveret
- ingeniør
- Ingeniører
- Motorer
- Indtast
- Ether (ETH)
- udviklende
- Eksklusive
- ekstrakt
- hurtigere
- færre
- File (Felt)
- Filer
- filtrere
- Filtre
- Finde
- Fornavn
- første gang
- efter
- Til
- format
- formation
- hyppigt
- fra
- given
- kloden
- Go
- indrømme
- bevilget
- Guides
- Hadoop
- Have
- he
- hjælpe
- hjælper
- hans
- Hive
- Hvordan
- How To
- HTML
- HTTPS
- IAM
- if
- implikationer
- Forbedre
- in
- Herunder
- inkremental
- oplysninger
- i stedet
- integrere
- integration
- grænseflade
- ind
- indføre
- IT
- Japan
- jpg
- holde
- sø
- søer
- seneste
- lancere
- LÆR
- læring
- mindre
- GRÆNSE
- Line (linje)
- Liste
- placeret
- placering
- placeringer
- logget
- maskine
- machine learning
- opretholdelse
- lave
- maerker
- administrere
- lykkedes
- leder
- styring
- manuel
- maksimal
- sammenlægning
- Metadata
- migrere
- migration
- ML
- mere
- mest
- bevæge sig
- flere
- navn
- indfødte
- Behov
- behov
- Ny
- nyligt
- næste
- nu
- of
- on
- ONE
- kun
- åbent
- open source
- optimeret
- Option
- or
- Andet
- vores
- output
- del
- lidenskabelige
- sti
- stier
- ydeevne
- tilladelse
- Tilladelser
- plato
- Platon Data Intelligence
- PlatoData
- Populær
- befolkede
- Indlæg
- Forbered
- forudsætninger
- tidligere
- pris
- primære
- Main
- forarbejdning
- Produkt
- produktchef
- Produkter
- give
- forudsat
- giver
- forespørgsler
- hurtigt
- Læs
- ægte
- realtid
- realtime
- nylige
- optage
- register
- registreret
- erstatte
- Krav
- Ressourcer
- ansvarlige
- begrænse
- vej
- roller
- RÆKKE
- Kør
- samme
- planlægge
- planlagt
- SDK
- Sektion
- sikker
- se
- Vælg
- senior
- Serverless
- tjeneste
- Tjenester
- sæt
- indstillinger
- vist
- Shows
- forenkler
- siden
- enkelt
- Slice
- Snapshot
- So
- Software
- softwareudvikling
- Kilde
- Kilder
- Spark
- specifikke
- starte
- Tilstand
- Trin
- Steps
- opbevaret
- streaming
- vandløb
- Studio
- Succesfuld
- sådan
- support
- Understøttet
- synkronisere.
- Systemer
- bord
- hold
- Teknisk
- Teknologier
- at
- deres
- derefter
- Der.
- de
- denne
- tre
- Gennem
- tid
- gange
- til
- tokyo
- top
- transaktionsbeslutning
- Transaktioner
- Oversætte
- krydse
- udløse
- udløst
- tutorial
- to
- typer
- typisk
- under
- uønsket
- Opdatering
- opdateret
- opdateringer
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- bruger
- ved brug af
- VALIDATE
- valideret
- Værdier
- udgave
- visuel
- Warehouse
- we
- web
- webservices
- GODT
- hvornår
- som
- mens
- WHO
- vilje
- med
- uden
- Arbejde
- virker
- skriver
- skriftlig
- dig
- Din
- dig selv
- zephyrnet