Amazon rødforskydning, et meget brugt cloud data warehouse, har udviklet sig markant for at opfylde ydeevnekravene for de mest krævende arbejdsbelastninger. Dette indlæg dækker en sådan ny funktion - den multidimensionelle datalayoutsorteringsnøgle.
Amazon Redshift forbedrer nu din forespørgselsydeevne ved at understøtte multidimensionelle datalayoutsorteringsnøgler, som er en ny type sorteringsnøgle, der sorterer en tabels data efter filterprædikater i stedet for fysiske kolonner i tabellen. Multidimensionelle datalayoutsorteringsnøgler vil forbedre ydeevnen af tabelscanninger markant, især når din forespørgselsbelastning indeholder gentagne scanningsfiltre.
Amazon Redshift giver allerede mulighed for automatisk tabeloptimering (ATO), som automatisk optimerer designet af tabeller ved at anvende sorterings- og distributionsnøgler uden behov for administratorindgreb. I dette indlæg introducerer vi multidimensionelle datalayoutsorteringsnøgler som en ekstra funktion, der tilbydes af ATO og forstærket af Amazon Redshifts sorteringsnøglerådgiveralgoritme.
Multidimensionelle datalayoutsorteringsnøgler
Når du definerer en tabel med AUTO-sorteringsnøglen, vil Amazon Redshift ATO analysere din forespørgselshistorik og automatisk vælge enten en enkelt-kolonne sorteringsnøgle eller multidimensionel datalayoutsorteringsnøgle til din tabel, baseret på hvilken mulighed der er bedst for din arbejdsbyrde. Når multidimensionelt datalayout er valgt, vil Amazon Redshift konstruere en multidimensionel sorteringsfunktion, der samlokaliserer rækker, som typisk tilgås af de samme forespørgsler, og sorteringsfunktionen bruges efterfølgende under forespørgselskørsel til at springe datablokke over og endda springe scanning af det enkelte prædikat over. kolonner.
Overvej følgende brugerforespørgsel, som er et dominerende forespørgselsmønster i brugerens arbejdsbyrde:
Amazon Redshift gemmer data for hver kolonne i 1 MB diskblokke og gemmer minimums- og maksimumværdierne i hver blok som en del af tabellens metadata. Hvis en forespørgsel bruger en rækkevidde-begrænset prædikat, kan Amazon Redshift bruge minimums- og maksimumværdierne til hurtigt at springe over et stort antal blokke under tabelscanninger. Denne forespørgsels filter på underregionskolonnen kan dog ikke bruges til at bestemme, hvilke blokke der skal springes over baseret på minimums- og maksimumværdier, og som et resultat scanner Amazon Redshift alle rækker fra titeltabellen:
Når brugerens forespørgsel blev kørt med titles ved at bruge en enkelt-kolonne sorteringsnøgle på subregion, resultatet af den foregående forespørgsel er som følger:
Dette viser, at tabelscanningen læste 2,164,081,640 rækker.
For at forbedre scanninger på titles tabel, kan Amazon Redshift automatisk beslutte at bruge en multidimensionel datalayoutsorteringsnøgle. Alle rækker, der opfylder lower(subregion) like '%United States%' prædikatet ville være samlokaliseret til et dedikeret område af tabellen, og derfor vil Amazon Redshift kun scanne datablokke, der opfylder prædikatet.
Når brugerens forespørgsel køres med titles ved hjælp af en multidimensional datalayoutsorteringsnøgle, der inkluderer lower(subregion) like '%United States%' som et prædikat, resultatet af sys_query_detail forespørgslen er som følger:
Dette viser, at tabelscanningen læste 152,324,046 rækker, hvilket kun er 7 % af originalen, og den brugte den multidimensionelle datalayoutsorteringsnøgle.
Bemærk, at dette eksempel bruger en enkelt forespørgsel til at vise den multidimensionelle datalayout-funktion, men Amazon Redshift vil overveje alle de forespørgsler, der kører mod tabellen, og kan oprette flere områder for at opfylde de mest almindeligt kørte prædikater.
Lad os tage et andet eksempel med mere komplekse prædikater og flere forespørgsler denne gang.
Forestil dig at have et bord items (cost int, available int, demand int) med fire rækker som vist i følgende eksempel.
| #id | koste | til rådighed | efterspørgsel |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Din dominerende arbejdsbyrde består af to forespørgsler:
- 70 % forespørgselsmønster:
- 20 % forespørgselsmønster:
Med traditionelle sorteringsteknikker kan du vælge at sortere tabellen over omkostningskolonnen, således at evalueringen af cost > 3 vil drage fordel af den slags. Så varerne tabel efter sortering ved hjælp af en enkelt cost kolonnen vil se ud som følgende.
| #id | koste | til rådighed | efterspørgsel |
| Region #1, med pris <= 3 | |||
| Region #2, med pris > 3 | |||
| #id | koste | til rådighed | efterspørgsel |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Ved at bruge denne traditionelle sortering kan vi straks udelukke de to øverste (blå) rækker med ID 4 og ID 2, fordi de ikke opfylder cost > 3.
På den anden side vil tabellen med en multidimensionel datalayoutsorteringsnøgle blive sorteret baseret på en kombination af de to almindeligt forekommende prædikater i brugerens arbejdsbyrde, som er cost > 3 , available < demand. Som et resultat sorteres tabellens rækker i fire områder.
| #id | koste | til rådighed | efterspørgsel |
| Region #1, med pris <= 3 og tilgængelig < efterspørgsel | |||
| Region #2, med pris <= 3 og tilgængelig >= efterspørgsel | |||
| Region #3, med pris > 3 og tilgængelig < efterspørgsel | |||
| Region #4, med pris > 3 og tilgængelig >= efterspørgsel | |||
| #id | koste | til rådighed | efterspørgsel |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Dette koncept er endnu mere kraftfuldt, når det anvendes på hele blokke i stedet for enkelte rækker, når det anvendes på komplekse prædikater, der bruger operatorer, der ikke er egnede til traditionelle sorteringsteknikker (som f.eks. like), og når de anvendes på mere end to prædikater.
System tabeller
Følgende Amazon Redshift-systemtabeller viser brugerne, om der bruges multidimensionelle datalayouts på deres tabeller og forespørgsler:
- For at afgøre, om en bestemt tabel bruger en flerdimensionel datalayoutsorteringsnøgle, kan du kontrollere, om
sortkey1in svv_tabel_info er lig medAUTO(SORTKEY(padb_internal_mddl_key_col)). - For at afgøre, om en bestemt forespørgsel bruger multidimensionelt datalayout til at fremskynde tabelscanninger, kan du kontrollere
step_attributei sys_query_detail udsigt. Værdien vil være lig medmulti-dimensionalhvis tabellens multidimensionelle datalayoutsorteringsnøgle blev brugt under scanningen.
Ydeevne benchmarks
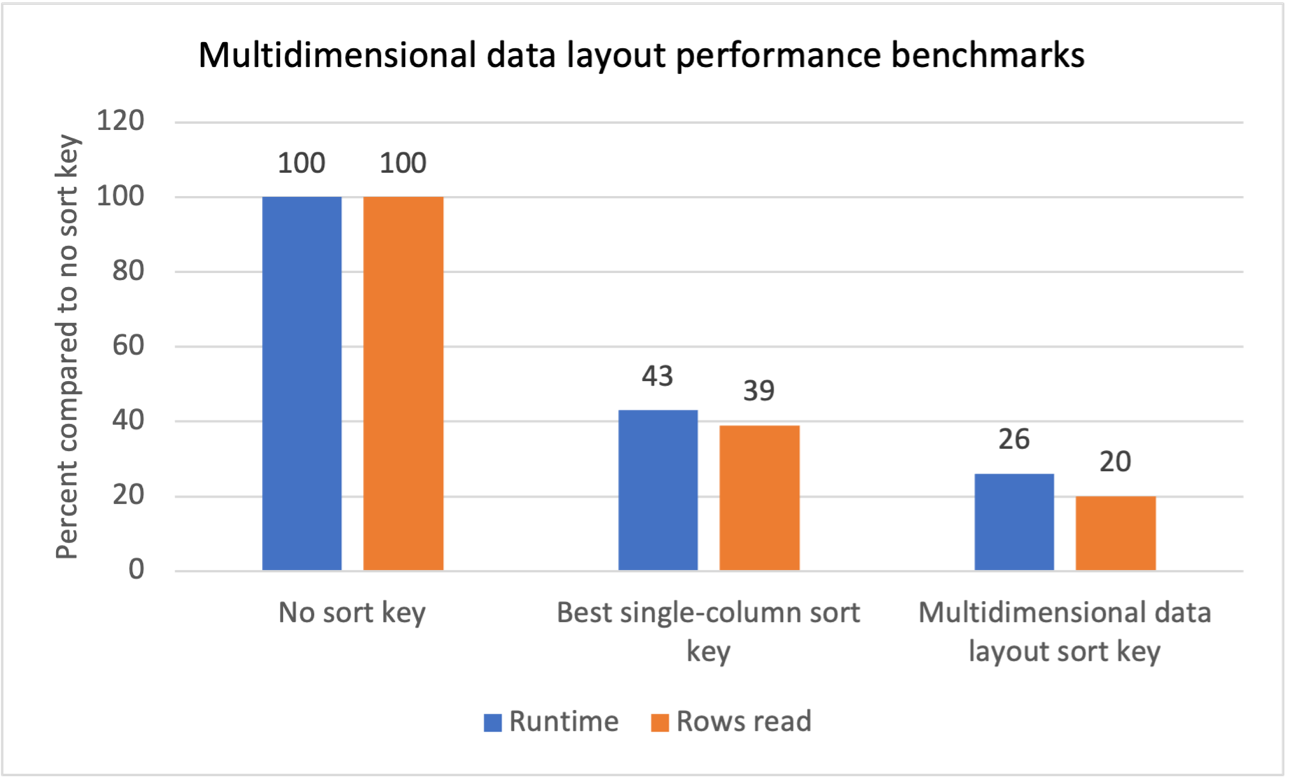
Vi udførte intern benchmark-test for flere arbejdsbelastninger med gentagne scanningsfiltre og så, at introduktion af multidimensionelle datalayoutsorteringsnøgler gav følgende resultater:
- En 74 % reduktion af samlet køretid sammenlignet med at have ingen sorteringsnøgle.
- En 40 % total reduktion af kørselstid sammenlignet med at have den bedste enkeltkolonne sorteringsnøgle på hver tabel.
- En 80 % reduktion i det samlede antal rækker, der læses fra tabeller, sammenlignet med at have ingen sorteringsnøgle.
- En reduktion på 47 % i det samlede antal rækker, der læses fra tabeller, sammenlignet med at have den bedste enkeltkolonne sorteringsnøgle på hver tabel.
Funktionssammenligning
Med introduktionen af multidimensionelle datalayoutsorteringsnøgler kan dine tabeller nu sorteres efter udtryk baseret på de almindeligt forekommende filterprædikater i din arbejdsbelastning. Følgende tabel giver en sammenligning af funktioner for Amazon Redshift med to konkurrenter.
| Feature | Amazon rødforskydning | Konkurrent A | Konkurrent B |
| Understøttelse af sortering på kolonner | Ja | Ja | Ja |
| Understøttelse af sortering efter udtryk | Ja | Ja | Ingen |
| Automatisk kolonnevalg til sortering | Ja | Ingen | Ja |
| Automatisk valg af udtryk til sortering | Ja | Ingen | Ingen |
| Automatisk valg mellem kolonnesortering eller udtrykssortering | Ja | Ingen | Ingen |
| Automatisk brug af sorteringsegenskaber for udtryk under scanninger | Ja | Ingen | Ingen |
Overvejelser
Husk følgende, når du bruger et multidimensionelt datalayout:
- Multidimensionelt datalayout er aktiveret, når du indstiller din tabel som SORTKEY AUTO.
- Amazon Redshift Advisor vil automatisk vælge enten en enkelt-kolonne sorteringsnøgle eller multidimensionelt datalayout til tabellen ved at analysere din historiske arbejdsbyrde.
- Amazon Redshift ATO justerer de multidimensionelle datalayoutsorteringsresultater baseret på den måde, hvorpå igangværende forespørgsler interagerer med arbejdsbyrden.
- Amazon Redshift ATO vedligeholder multidimensionelle datalayoutsorteringsnøgler på samme måde, som det i øjeblikket gør for eksisterende sorteringsnøgler. Henvise til Arbejder med automatisk tabeloptimering for flere detaljer om ATO.
- Multidimensionelle datalayoutsorteringsnøgler fungerer med både klargjorte klynger og serverløse arbejdsgrupper.
- Multidimensionelle datalayoutsorteringsnøgler fungerer med dine eksisterende data, så længe AUTO SORTKEY er aktiveret på din tabel, og en arbejdsbelastning med gentagne scanningsfiltre er registreret. Tabellen vil blive reorganiseret baseret på resultaterne af multidimensional sorteringsfunktion.
- For at deaktivere flerdimensionelle datalayoutsorteringsnøgler for en tabel skal du bruge ændringstabel:
ALTER TABLE table_name ALTER SORTKEY NONE. Dette deaktiverer funktionen AUTO sorteringsnøgle på bordet. - Multidimensionelle datalayoutsorteringsnøgler bevares, når din klargjorte klynge gendannes eller migreres til en serverløs klynge eller omvendt.
Konklusion
I dette indlæg viste vi, at flerdimensionelle datalayoutsorteringsnøgler kan forbedre forespørgsels runtime-ydeevne markant for arbejdsbelastninger, hvor dominerende forespørgsler har gentagne scanningsfiltre.
For at oprette en forhåndsvisningsklynge fra Amazon Redshift-konsollen skal du navigere til Klynger side og vælg Opret forhåndsvisningsklynge. Du kan oprette en klynge i regionerne US East (Ohio), US East (N. Virginia), US West (Oregon), Asia Pacific (Tokyo), Europa (Irland) og Europa (Stockholm) og teste dine arbejdsbelastninger.
Vi vil meget gerne høre din feedback om denne nye funktion og ser frem til dine kommentarer til dette indlæg.
Om forfatterne
 Milind Oke er en Data Warehouse Specialist Solutions Architect baseret i New York. Han har bygget datavarehusløsninger i over 15 år og har specialiseret sig i Amazon Redshift.
Milind Oke er en Data Warehouse Specialist Solutions Architect baseret i New York. Han har bygget datavarehusløsninger i over 15 år og har specialiseret sig i Amazon Redshift.
 Jialin Ding er en anvendt videnskabsmand i Learned Systems Group, med speciale i at anvende maskinlæring og optimeringsteknikker til at forbedre ydeevnen af datasystemer såsom Amazon Redshift.
Jialin Ding er en anvendt videnskabsmand i Learned Systems Group, med speciale i at anvende maskinlæring og optimeringsteknikker til at forbedre ydeevnen af datasystemer såsom Amazon Redshift.
 Yanzhu Ji er produktchef i Amazon Redshift-teamet. Hun har erfaring med produktvision og strategi i brancheførende dataprodukter og platforme. Hun har enestående færdigheder i at bygge betydelige softwareprodukter ved hjælp af webudvikling, systemdesign, database og distribuerede programmeringsteknikker. I sit personlige liv kan Yanzhu lide at male, fotografere og spille tennis.
Yanzhu Ji er produktchef i Amazon Redshift-teamet. Hun har erfaring med produktvision og strategi i brancheførende dataprodukter og platforme. Hun har enestående færdigheder i at bygge betydelige softwareprodukter ved hjælp af webudvikling, systemdesign, database og distribuerede programmeringsteknikker. I sit personlige liv kan Yanzhu lide at male, fotografere og spille tennis.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :har
- :er
- :ikke
- :hvor
- 1
- 100
- 15 år
- 15 %
- 152
- 7
- 8
- 9
- a
- fremskynde
- af udleverede
- Yderligere
- rådgiver
- Efter
- mod
- algoritme
- Alle
- allerede
- Amazon
- Amazon Web Services
- an
- analysere
- analysere
- ,
- En anden
- anvendt
- Anvendelse
- ER
- AS
- asia
- asien pacific
- auto
- Automatisk Ur
- automatisk
- til rådighed
- AWS
- baseret
- BE
- fordi
- været
- benchmark
- gavner det dig
- BEDSTE
- Bedre
- mellem
- Bloker
- Blocks
- Blå
- både
- Bygning
- men
- by
- CAN
- kapacitet
- kontrollere
- Vælg
- Cloud
- Cluster
- Kolonne
- Kolonner
- kombination
- kommentarer
- almindeligt
- sammenlignet
- sammenligning
- konkurrenter
- komplekse
- Konceptet
- Overvej
- består
- Konsol
- konstruere
- indeholder
- Koste
- dækker
- skabe
- For øjeblikket
- data
- datalager
- Database
- beslutte
- dedikeret
- definere
- Efterspørgsel
- krævende
- Design
- detaljer
- opdaget
- Bestem
- Udvikling
- distribueret
- fordeling
- gør
- dominerende
- Dont
- i løbet af
- hver
- Øst
- enten
- aktiveret
- Hele
- lige
- især
- Ether (ETH)
- Europa
- evaluering
- Endog
- udviklet sig
- eksempel
- eksisterende
- erfaring
- udtryk
- Feature
- tilbagemeldinger
- filtrere
- Filtre
- efter
- følger
- Til
- Videresend
- fire
- fra
- funktion
- gruppe
- hånd
- Have
- have
- he
- høre
- hende
- historisk
- historie
- Men
- HTML
- HTTPS
- ID
- if
- straks
- Forbedre
- forbedrer
- in
- omfatter
- individuel
- brancheførende
- i stedet
- interagere
- interne
- indgriben
- ind
- indføre
- indføre
- Introduktion
- irland
- IT
- Varer
- Nøgle
- nøgler
- stor
- Layout
- lærte
- læring
- Livet
- ligesom
- synes godt om
- Lang
- Se
- ligner
- kærlighed
- maskine
- machine learning
- fastholder
- leder
- måde
- maksimal
- Mød
- Metadata
- måske
- migrere
- tankerne
- minimum
- mere
- mest
- flere
- Naviger
- Behov
- Ny
- ny funktion
- New York
- ingen
- nu
- numre
- forekommende
- of
- off
- tilbydes
- Ohio
- on
- ONE
- igangværende
- kun
- Operatører
- optimering
- Optimerer
- Option
- or
- ordrer
- Oregon
- original
- Andet
- ud
- udestående
- i løbet af
- Pacific
- maleri
- del
- særlig
- Mønster
- ydeevne
- udføres
- personale
- fotografering
- fysisk
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Indlæg
- vigtigste
- bevaret
- Eksempel
- produceret
- Produkt
- produktchef
- Produkter
- Programmering
- egenskaber
- giver
- forespørgsler
- hurtigt
- Læs
- reduktion
- henvise
- region
- regioner
- repetitiv
- Krav
- genoprette
- resultere
- Resultater
- Kør
- kører
- løber
- samme
- scanne
- scanning
- scanninger
- Videnskabsmand
- Sæson
- se
- Vælg
- valgt
- valg
- Serverless
- Tjenester
- sæt
- hun
- Vis
- udstillingsvindue
- viste
- vist
- Shows
- betydeligt
- enkelt
- dygtighed
- So
- Software
- Løsninger
- specialist
- specialiseret
- speciale
- forhandler
- Strategi
- Efterfølgende
- væsentlig
- sådan
- egnede
- Støtte
- systemet
- Systemer
- bord
- Tag
- hold
- teknikker
- tennis
- prøve
- Test
- end
- at
- deres
- derfor
- de
- denne
- tid
- titler
- til
- tokyo
- top
- I alt
- traditionelle
- to
- typen
- typisk
- us
- brug
- anvendte
- Bruger
- brugere
- bruger
- ved brug af
- værdi
- Værdier
- vice
- Specifikation
- Virginia
- vision
- Warehouse
- var
- Vej..
- we
- web
- Web udvikling
- webservices
- Vest
- hvornår
- hvorvidt
- som
- bredt
- vilje
- med
- uden
- Arbejde
- ville
- år
- york
- dig
- Din
- zephyrnet