Som Roblox er vokset i løbet af de sidste 16+ år, er omfanget og kompleksiteten af den tekniske infrastruktur, der understøtter millioner af fordybende 3D-samoplevelser, også vokset. Antallet af maskiner, vi understøtter, er mere end tredoblet i løbet af de sidste to år, fra cirka 36,000 pr. 30. juni 2021 til næsten 145,000 i dag. At understøtte disse altid-på-oplevelser for mennesker over hele verden kræver mere end 1,000 interne tjenester. For at hjælpe os med at kontrollere omkostninger og netværksforsinkelse implementerer og administrerer vi disse maskiner som en del af en specialbygget og hybrid privat cloud-infrastruktur, der primært kører på stedet.
Vores infrastruktur understøtter i øjeblikket mere end 70 millioner daglige aktive brugere rundt om i verden, inklusive de skabere, der stoler på Roblox's økonomi for deres virksomheder. Alle disse millioner af mennesker forventer et meget højt niveau af pålidelighed. I betragtning af vores oplevelsers fordybende karakter er der en ekstrem lav tolerance for forsinkelser eller latency, endsige udfald. Roblox er en platform for kommunikation og forbindelse, hvor mennesker mødes i fordybende 3D-oplevelser. Når folk kommunikerer som deres avatarer i et fordybende rum, er selv mindre forsinkelser eller fejl mere mærkbare, end de er på en teksttråd eller et telefonmøde.
I oktober 2021 oplevede vi et system-dækkende nedbrud. Det startede i det små, med et problem i én komponent i ét datacenter. Men det spredte sig hurtigt, mens vi efterforskede og resulterede i sidste ende i en 73-timers afbrydelse. På det tidspunkt delte vi begge dele detaljer om, hvad der skete og nogle af vores tidlige erfaringer fra problemet. Siden da har vi studeret disse erfaringer og arbejdet på at øge vores infrastrukturs modstandsdygtighed over for de typer fejl, der opstår i alle store systemer på grund af faktorer som ekstreme trafikstigninger, vejr, hardwarefejl, softwarefejl eller bare mennesker laver fejl. Når disse fejl opstår, hvordan sikrer vi, at et problem i en enkelt komponent eller gruppe af komponenter ikke spredes til hele systemet? Dette spørgsmål har været vores fokus i de sidste to år, og mens arbejdet er i gang, giver det, vi har gjort indtil videre, allerede pote. For eksempel sparede vi i første halvdel af 2023 125 millioner engagementstimer om måneden sammenlignet med første halvdel af 2022. I dag deler vi det arbejde, vi allerede har udført, samt vores langsigtede vision for byggeri et mere robust infrastruktursystem.
Opbygning af et bagstopper
Inden for store infrastruktursystemer sker der småfejl mange gange om dagen. Hvis en maskine har et problem og skal tages ud af drift, er det overskueligt, fordi de fleste virksomheder opretholder flere forekomster af deres back-end-tjenester. Så når en enkelt instans fejler, samler andre arbejdsbyrden op. For at løse disse hyppige fejl er anmodninger generelt indstillet til automatisk at prøve igen, hvis de får en fejl.
Dette bliver udfordrende, når et system eller en person prøver for aggressivt igen, hvilket kan blive en måde, hvorpå disse småfejl kan spredes gennem hele infrastrukturen til andre tjenester og systemer. Hvis netværket eller en bruger forsøger vedvarende nok, vil det i sidste ende overbelaste hver forekomst af den pågældende tjeneste og potentielt andre systemer globalt. Vores 2021-afbrydelse var resultatet af noget, der er ret almindeligt i store systemer: En fejl starter i det små, forplanter sig derefter gennem systemet og bliver så hurtigt stor, at det er svært at løse, før alt går ned.
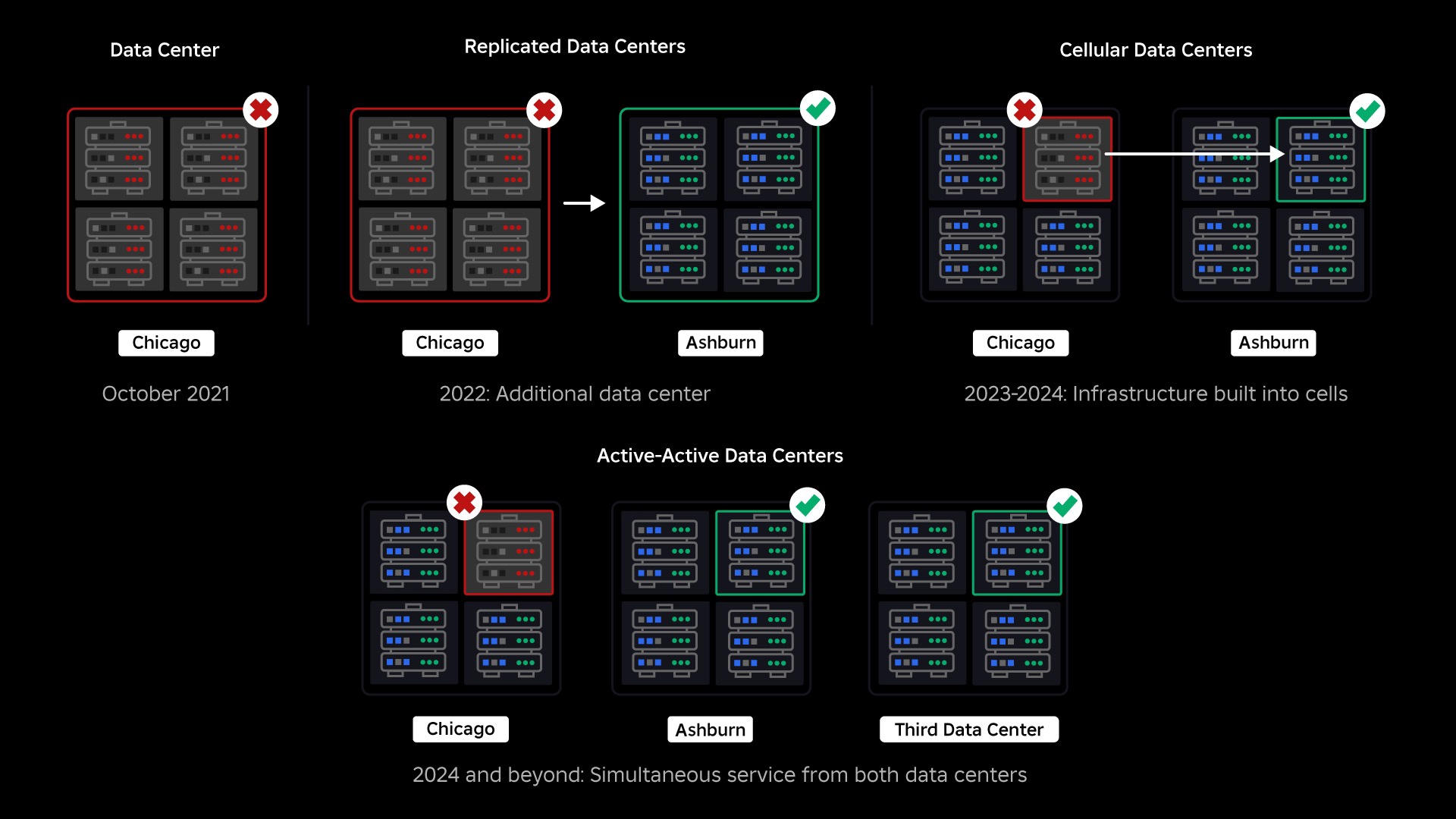
På tidspunktet for vores afbrydelse havde vi ét aktivt datacenter (med komponenter i det, der fungerede som backup). Vi havde brug for muligheden for at fejle manuelt til et nyt datacenter, når et problem bragte det eksisterende ned. Vores første prioritet var at sikre, at vi havde en backup-implementering af Roblox, så vi byggede den backup i et nyt datacenter, der ligger i et andet geografisk område. Den ekstra beskyttelse for det værst tænkelige scenarie: et udfald, der spreder sig til nok komponenter i et datacenter, til at det bliver fuldstændig ubrugeligt. Vi har nu et datacenter, der håndterer arbejdsbelastninger (aktivt) og et på standby, der fungerer som backup (passivt). Vores langsigtede mål er at gå fra denne aktiv-passive konfiguration til en aktiv-aktiv konfiguration, hvor begge datacentre håndterer arbejdsbelastninger, med en belastningsbalancer, der fordeler anmodninger mellem dem baseret på latenstid, kapacitet og sundhed. Når dette er på plads, forventer vi at have endnu højere pålidelighed for hele Roblox og være i stand til at fejle over næsten øjeblikkeligt snarere end over flere timer. 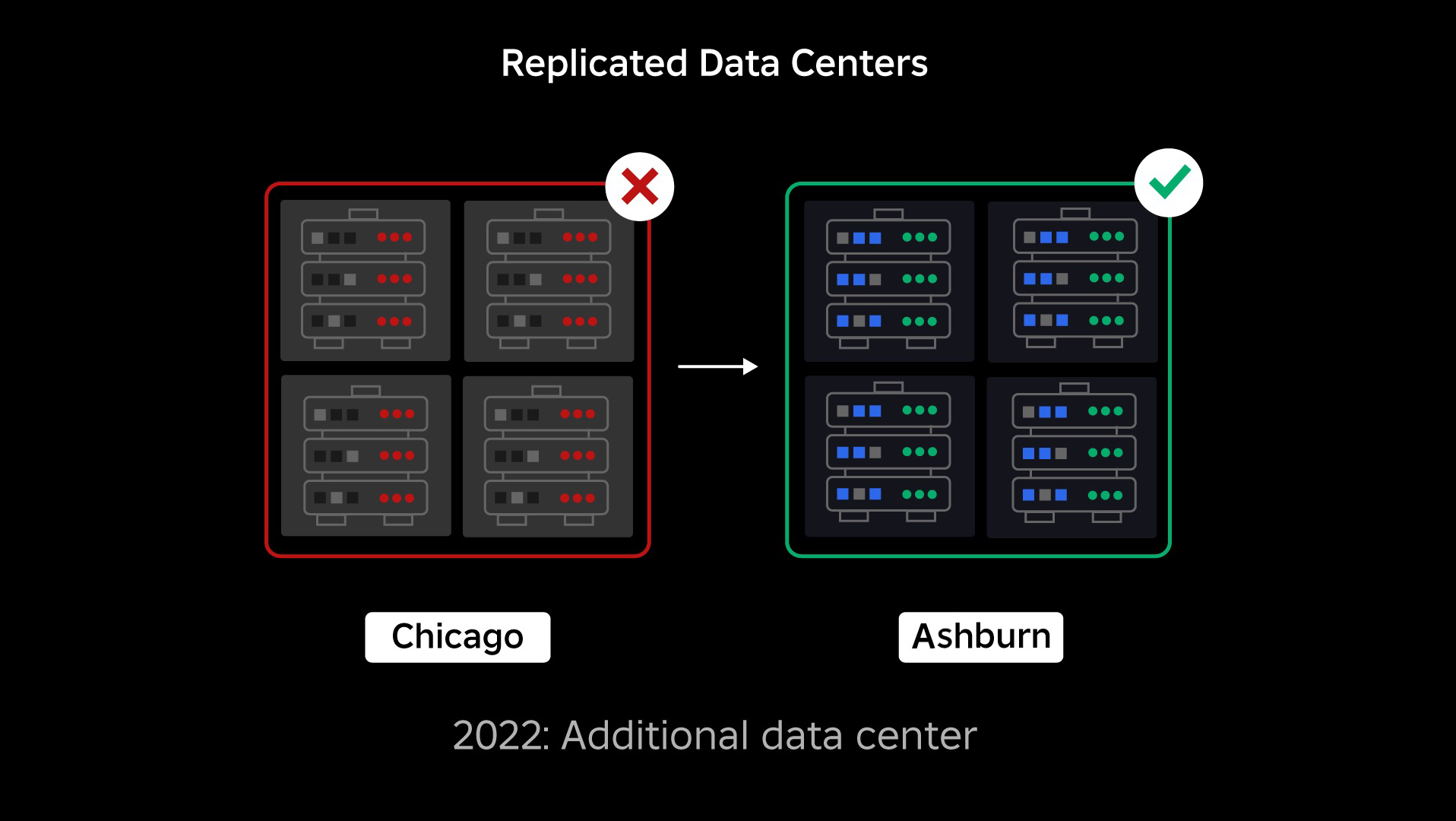
Flytning til en cellulær infrastruktur
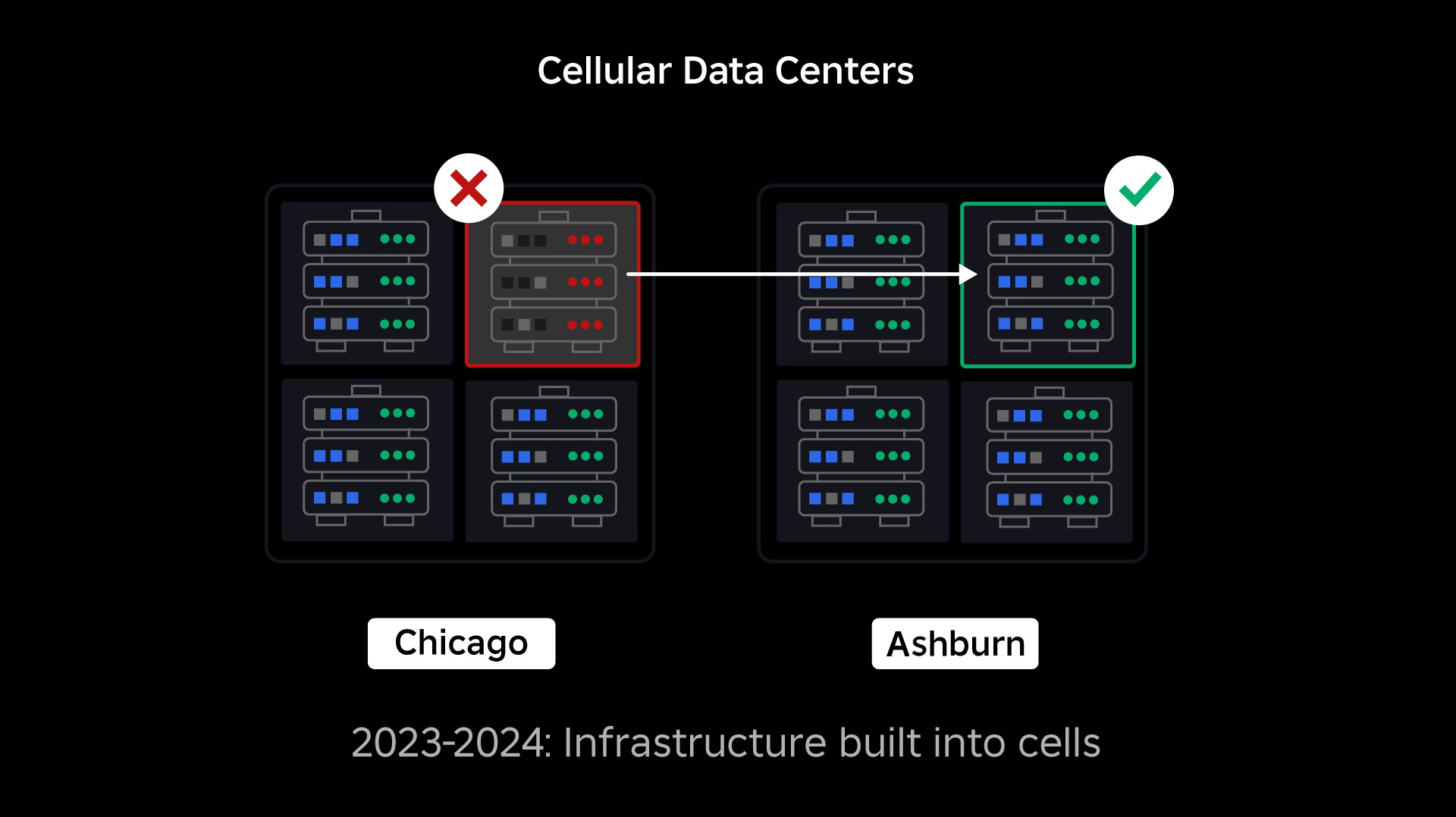
Vores næste prioritet var at skabe stærke eksplosionsvægge inde i hvert datacenter for at reducere muligheden for, at et helt datacenter svigter. Celler (nogle virksomheder kalder dem klynger) er i bund og grund et sæt maskiner, og det er den måde, vi skaber disse vægge. Vi replikerer tjenester både inden for og på tværs af celler for ekstra redundans. I sidste ende ønsker vi, at alle tjenester hos Roblox kører i celler, så de kan drage fordel af både stærke sprængvægge og redundans. Hvis en celle ikke længere fungerer, kan den sikkert deaktiveres. Replikering på tværs af celler gør det muligt for tjenesten at blive ved med at køre, mens cellen repareres. I nogle tilfælde kan cellereparation betyde en fuldstændig reprovisionering af cellen. På tværs af industrien er det ret almindeligt at tørre og omprovisionere en individuel maskine eller et lille sæt maskiner, men at gøre dette for en hel celle, som indeholder ~1,400 maskiner, er det ikke.
For at dette kan fungere, skal disse celler stort set være ensartede, så vi hurtigt og effektivt kan flytte arbejdsbelastninger fra en celle til en anden. Vi har sat visse krav, som tjenester skal opfylde, før de kører i en celle. For eksempel skal tjenester være containeriseret, hvilket gør dem meget mere bærbare og forhindrer nogen i at foretage konfigurationsændringer på OS-niveau. Vi har vedtaget en infrastruktur-som-kode-filosofi for celler: I vores kildekodelager inkluderer vi definitionen af alt, hvad der er i en celle, så vi hurtigt kan genopbygge det fra bunden ved hjælp af automatiserede værktøjer.
Ikke alle tjenester opfylder i øjeblikket disse krav, så vi har arbejdet på at hjælpe tjenesteejere med at opfylde dem, hvor det er muligt, og vi har bygget nye værktøjer, der gør det nemt at migrere tjenester til celler, når de er klar. For eksempel "striber" vores nye implementeringsværktøj automatisk en serviceimplementering på tværs af celler, så tjenesteejere ikke behøver at tænke på replikeringsstrategien. Dette niveau af stringens gør migreringsprocessen meget mere udfordrende og tidskrævende, men det langsigtede udbytte vil være et system, hvor:
- Det er langt lettere at begrænse en fejl og forhindre den i at sprede sig til andre celler;
- Vores infrastrukturingeniører kan være mere effektive og bevæge sig hurtigere; og
- De ingeniører, der bygger de tjenester på produktniveau, der i sidste ende implementeres i celler, behøver ikke at vide eller bekymre sig om, hvilke celler deres tjenester kører i.
Løsning af større udfordringer
På samme måde som branddøre bruges til at begrænse flammer, fungerer celler som stærke eksplosionsvægge i vores infrastruktur for at hjælpe med at begrænse det problem, der udløser en fejl i en enkelt celle. Til sidst vil alle de tjenester, der udgør Roblox, blive implementeret redundant inde i og på tværs af celler. Når dette arbejde er afsluttet, kan problemer stadig forplante sig bredt nok til at gøre en hel celle ubrugelig, men det ville være ekstremt svært for et problem at forplante sig ud over den celle. Og hvis det lykkes os at gøre celler udskiftelige, vil genopretningen være markant hurtigere fordi vi vil være i stand til at fejle over til en anden celle og forhindre, at problemet påvirker slutbrugerne.
Hvor dette bliver vanskeligt, er at adskille disse celler nok til at reducere muligheden for at sprede fejl, samtidig med at tingene holdes performante og funktionelle. I et komplekst infrastruktursystem skal tjenester kommunikere med hinanden for at dele forespørgsler, information, arbejdsbelastninger osv. Når vi replikerer disse tjenester til celler, skal vi være betænksomme over, hvordan vi håndterer krydskommunikation. I en ideel verden omdirigerer vi trafik fra én usund celle til andre sunde celler. Men hvordan håndterer vi en "dødsspørgsmål" - sådan en forårsager en celle for at være usund? Hvis vi omdirigerer den forespørgsel til en anden celle, kan det forårsage, at den celle bliver usund på den måde, vi forsøger at undgå. Vi er nødt til at finde mekanismer til at flytte "god" trafik fra usunde celler, mens vi opdager og dæmper den trafik, der får celler til at blive usunde.
På kort sigt har vi implementeret kopier af computertjenester til hver computercelle, så de fleste anmodninger til datacentret kan betjenes af en enkelt celle. Vi er også belastningsbalancerende trafik på tværs af celler. Ser vi længere ud, er vi begyndt at bygge en næste generations serviceopdagelsesproces, der vil blive udnyttet af et servicenetværk, som vi håber at fuldføre i 2024. Dette vil give os mulighed for at implementere sofistikerede politikker, der kun tillader kommunikation på tværs af celler, når det vil ikke påvirke failover-cellerne negativt. Der kommer også i 2024 en metode til at dirigere afhængige anmodninger til en serviceversion i samme celle, hvilket vil minimere krydscelletrafik og derved reducere risikoen for udbredelse af fejl på tværs af celler.
På toppen bliver mere end 70 procent af vores back-end servicetrafik serveret uden for celler, og vi har lært meget om, hvordan man opretter celler, men vi forventer mere forskning og test, efterhånden som vi fortsætter med at migrere vores tjenester gennem 2024 og ud over. Efterhånden som vi gør fremskridt, vil disse sprængningsvægge blive stadig stærkere.
Migrering af en infrastruktur, der altid er tændt
Roblox er en global platform, der understøtter brugere over hele verden, så vi kan ikke flytte tjenester i lav- eller "nedetid", hvilket yderligere komplicerer processen med at migrere alle vores maskiner til celler og vores tjenester til at køre i disse celler . Vi har millioner af altid-på-oplevelser, som skal fortsætte med at blive understøttet, selvom vi flytter de maskiner, de kører på, og de tjenester, der understøtter dem. Da vi startede denne proces, havde vi ikke titusindvis af maskiner, der bare sad ubrugte og tilgængelige til at migrere disse arbejdsbelastninger til.
Vi havde dog et lille antal ekstra maskiner, som blev købt i forventning om fremtidig vækst. Til at starte med byggede vi nye celler ved hjælp af disse maskiner og migrerede derefter arbejdsbelastninger til dem. Vi værdsætter effektivitet såvel som pålidelighed, så i stedet for at gå ud og købe flere maskiner, når vi løb tør for "reserve"-maskiner, byggede vi flere celler ved at slette og omprovisionere de maskiner, vi var migreret fra. Vi migrerede derefter arbejdsbelastninger til de omprovisionerede maskiner og startede processen forfra. Denne proces er kompleks - efterhånden som maskiner udskiftes og frigøres til at blive indbygget i celler, frigøres de ikke på en ideel og velordnet måde. De er fysisk fragmenteret på tværs af datahaller, hvilket efterlader os at klargøre dem på en stykkevis måde, hvilket kræver en defragmenteringsproces på hardwareniveau for at holde hardwareplaceringerne på linje med store fysiske fejldomæner.
En del af vores infrastrukturingeniørteam er fokuseret på at migrere eksisterende arbejdsbelastninger fra vores gamle eller "præ-celle" miljø til celler. Dette arbejde vil fortsætte, indtil vi har migreret tusindvis af forskellige infrastrukturtjenester og tusindvis af back-end-tjenester til nybyggede celler. Vi forventer, at dette vil tage hele næste år og muligvis ind i 2025 på grund af nogle komplicerende faktorer. For det første kræver dette arbejde robust værktøj for at blive bygget. For eksempel har vi brug for værktøj til automatisk at rebalancere et stort antal tjenester, når vi implementerer en ny celle – uden at påvirke vores brugere. Vi har også set tjenester, der er bygget med antagelser om vores infrastruktur. Vi er nødt til at revidere disse tjenester, så de ikke er afhængige af ting, der kan ændre sig i fremtiden, når vi bevæger os ind i celler. Vi har også implementeret både en måde at søge efter kendte designmønstre, der ikke fungerer godt med cellulær arkitektur, såvel som en metodisk testproces for hver tjeneste, der er migreret. Disse processer hjælper os med at afværge eventuelle brugervendte problemer forårsaget af en tjeneste, der er inkompatibel med celler.
I dag bliver tæt på 30,000 maskiner administreret af celler. Det er kun en brøkdel af vores samlede flåde, men det har været en meget glidende overgang indtil videre uden negativ spillerpåvirkning. Vores ultimative mål er, at vores systemer skal opnå 99.99 procent brugeroppetid hver måned, hvilket betyder, at vi ikke vil forstyrre mere end 0.01 procent af engagementstimerne. I hele branchen kan nedetid ikke helt elimineres, men vores mål er at reducere enhver Roblox-nedetid i en grad, så den er næsten umærkelig.
Fremtidssikrer, når vi skalerer
Selvom vores tidlige indsats viser sig at være vellykket, er vores arbejde med celler langt fra færdigt. Efterhånden som Roblox fortsætter med at skalere, vil vi fortsætte med at arbejde på at forbedre effektiviteten og robustheden af vores systemer gennem denne og andre teknologier. Efterhånden som vi går, vil platformen blive stadig mere modstandsdygtig over for problemer, og eventuelle problemer, der opstår, bør gradvist blive mindre synlige og forstyrrende for folk på vores platform.
Sammenfattende har vi til dato:
- Byggede et andet datacenter og opnåede med succes aktiv/passiv status.
- Oprettede celler i vores aktive og passive datacentre og migrerede med succes mere end 70 procent af vores back-end servicetrafik til disse celler.
- Indstil de krav og bedste praksis, vi skal følge for at holde alle celler ensartede, mens vi fortsætter med at migrere resten af vores infrastruktur.
- Startede en kontinuerlig proces med at bygge stærkere "sprængningsvægge" mellem celler.
Efterhånden som disse celler bliver mere udskiftelige, vil der være mindre krydstale mellem celler. Dette åbner op for nogle meget interessante muligheder for os med hensyn til at øge automatiseringen omkring overvågning, fejlfinding og endda automatisk skiftende arbejdsbyrder.
I september begyndte vi også at køre aktive/aktive eksperimenter på tværs af vores datacentre. Dette er en anden mekanisme, vi tester for at forbedre pålideligheden og minimere failover-tider. Disse eksperimenter hjalp med at identificere en række systemdesignmønstre, hovedsageligt omkring dataadgang, som vi skal omarbejde, mens vi skubber på at blive fuldt aktive-aktive. Generelt var eksperimentet vellykket nok til at lade det køre for trafikken fra et begrænset antal af vores brugere.
Vi er glade for at blive ved med at drive dette arbejde fremad for at bringe større effektivitet og modstandsdygtighed til platformen. Dette arbejde med celler og aktiv-aktiv infrastruktur vil sammen med vores andre indsats gøre det muligt for os at vokse til et pålideligt, højtydende værktøj for millioner af mennesker og fortsætte med at skalere, mens vi arbejder på at forbinde en milliard mennesker i virkeligheden tid.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :har
- :er
- :ikke
- :hvor
- $OP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- evne
- I stand
- Om
- adgang
- opnå
- opnået
- tværs
- Lov
- handler
- aktiv
- tilføjet
- Yderligere
- adresse
- vedtaget
- igen
- aggressivt
- justeret
- Alle
- tillade
- alene
- sammen
- allerede
- også
- an
- ,
- En anden
- foregribe
- forventning
- enhver
- nogen
- cirka
- arkitektur
- ER
- omkring
- AS
- antagelser
- At
- Automatiseret
- automatisk
- Automation
- til rådighed
- avatars
- undgå
- Back-end
- backup
- swing
- afbalancering
- baseret
- BE
- fordi
- bliver
- bliver
- blive
- været
- før
- begyndt
- være
- gavner det dig
- BEDSTE
- bedste praksis
- mellem
- Beyond
- Big
- større
- Billion
- Blog
- både
- bringe
- bragte
- bugs
- bygge
- Bygning
- bygget
- virksomheder
- men
- Købe
- by
- ringe
- CAN
- kan ikke
- Kapacitet
- tilfælde
- Årsag
- forårsagede
- forårsager
- celle
- Celler
- cellulære
- center
- Centers
- vis
- udfordrende
- lave om
- Ændringer
- Luk
- Cloud
- sky infrastruktur
- kode
- Kom
- kommer
- Fælles
- kommunikere
- kommunikere
- Kommunikation
- Virksomheder
- sammenlignet
- fuldføre
- fuldstændig
- komplekse
- kompleksitet
- komponent
- komponenter
- Compute
- computing
- Konference
- Konfiguration
- Tilslut
- tilslutning
- indeholder
- indeholder
- fortsæt
- fortsætter
- kontinuerlig
- kontrol
- kopier
- Omkostninger
- kunne
- skabe
- Oprettelse af
- skabere
- For øjeblikket
- Specialbyggede
- dagligt
- data
- dataadgang
- Data Center
- datacentre
- Dato
- dag
- definition
- Degree
- forsinkelser
- afhænge
- afhængig
- indsætte
- indsat
- implementering
- Design
- design mønstre
- DID
- forskellige
- svært
- lede
- opdagelse
- Afbryde
- forstyrrende
- distribution
- do
- gør
- gør
- Domæner
- færdig
- Dont
- døre
- ned
- nedetid
- kørsel
- grund
- i løbet af
- hver
- Tidligt
- lettere
- let
- effektivitet
- effektiv
- effektivt
- indsats
- elimineret
- muliggør
- ende
- engagement
- Engineering
- Ingeniører
- nok
- sikre
- Hele
- helt
- Miljø
- fejl
- fejl
- væsentlige
- etc.
- Endog
- til sidst
- Hver
- at alt
- eksempel
- ophidset
- eksisterende
- forvente
- erfarne
- Oplevelser
- eksperiment
- eksperimenter
- ekstrem
- ekstremt
- faktorer
- FAIL
- svigtende
- mislykkes
- Manglende
- fejl
- retfærdigt
- langt
- Mode
- hurtigere
- Finde
- Brand
- Fornavn
- FLÅDE
- Fokus
- fokuserede
- følger
- Til
- Videresend
- fraktion
- fragmenteret
- Gratis
- hyppig
- fra
- fuld
- fuldt ud
- funktionel
- yderligere
- fremtiden
- fremtidig vækst
- generelt
- geografiske
- få
- få
- given
- Global
- Globalt
- Go
- mål
- Goes
- gå
- større
- gruppe
- Grow
- voksen
- Vækst
- havde
- Halvdelen
- håndtere
- Håndtering
- ske
- Hård Ost
- Hardware
- Have
- hoved
- Helse
- sund
- hjælpe
- hjulpet
- Høj
- højere
- håber
- HOURS
- Hvordan
- How To
- Men
- HTTPS
- Mennesker
- Hybrid
- ideal
- identificere
- if
- fordybende
- KIMOs Succeshistorier
- påvirker
- gennemføre
- implementeret
- Forbedre
- in
- omfatter
- Herunder
- uforenelige
- Forøg
- stigende
- stigende
- individuel
- industrien
- oplysninger
- Infrastruktur
- indvendig
- instans
- forekomster
- øjeblikkeligt
- interessant
- interne
- ind
- spørgsmål
- spørgsmål
- IT
- juni
- lige
- Holde
- holde
- Kend
- kendt
- stor
- storstilet
- vid udstrækning
- Latency
- lærte
- Forlade
- forlader
- Legacy
- mindre
- lad
- Niveau
- gearede
- ligesom
- Limited
- belastning
- placeret
- placeringer
- langsigtet
- længere
- leder
- Lot
- Lav
- maskine
- Maskiner
- vedligeholde
- lave
- maerker
- Making
- administrere
- lykkedes
- manuelt
- mange
- max-bredde
- betyde
- betyder
- mekanisme
- mekanismer
- Mød
- mesh
- metode
- metodisk
- måske
- migrere
- migreret
- migrere
- migration
- million
- millioner
- minimere
- mindre
- fejl
- overvågning
- Måned
- mere
- mere effektiv
- mest
- bevæge sig
- meget
- flere
- skal
- Natur
- næsten
- Behov
- behov
- negativ
- negativt
- netværk
- Ny
- nyligt
- næste
- næste generation
- ingen
- nu
- nummer
- numre
- forekomme
- oktober
- of
- off
- on
- engang
- ONE
- igangværende
- kun
- Muligheder
- Opportunity
- or
- OS
- Andet
- Andre
- vores
- ud
- nedbrud
- udfald
- i løbet af
- samlet
- ejere
- del
- passive
- forbi
- mønstre
- betale
- Peak
- Mennesker
- per
- procent
- udfører
- vedvarende
- person,
- filosofi
- fysisk
- Fysisk
- pick
- Place
- perron
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- politikker
- bærbare
- del
- Muligheden
- mulig
- eventuelt
- potentielt
- praksis
- forhindre
- forhindrer
- primært
- prioritet
- private
- behandle
- Processer
- Progress
- gradvist
- formering
- beskyttelse
- bevise
- bestemmelse
- købt
- Skub ud
- forespørgsler
- spørgsmål
- hurtigt
- hellere
- klar
- ægte
- realtid
- rebalancere
- opsving
- omdirigere
- reducere
- region
- pålidelighed
- pålidelig
- stole
- reparere
- udskiftes
- replikation
- Repository
- anmodninger
- Krav
- Kræver
- forskning
- modstandskraft
- elastisk
- løse
- REST
- resultere
- resulteret
- revidere
- Risiko
- Roblox
- robust
- Kør
- kører
- løber
- sikkert
- samme
- gemt
- Scale
- scenarie
- ridse
- Søg
- Anden
- set
- adskille
- september
- serveret
- tjeneste
- Tjenester
- servering
- sæt
- flere
- Del
- delt
- deling
- skifte
- SKIFT
- Kort
- bør
- betydeligt
- siden
- enkelt
- Siddende
- lille
- udjævne
- So
- indtil nu
- Software
- nogle
- noget
- sofistikeret
- Kilde
- kildekode
- Space
- spikes
- spredes
- Spredning
- starte
- påbegyndt
- starter
- Status
- Stadig
- Strategi
- stærk
- stærkere
- studere
- lykkes
- vellykket
- Succesfuld
- RESUMÉ
- support
- Understøttet
- Støtte
- Understøtter
- systemet
- Systemer
- Tag
- taget
- hold
- Teknisk
- Teknologier
- tiere
- semester
- vilkår
- Test
- tekst
- end
- at
- Fremtiden
- verdenen
- deres
- Them
- derefter
- Der.
- derved
- Disse
- de
- ting
- tror
- denne
- dem
- tusinder
- Gennem
- hele
- tid
- gange
- til
- i dag
- sammen
- tolerance
- også
- værktøj
- værktøjer
- I alt
- mod
- Trafik
- overgang
- udløsning
- forsøger
- to
- typer
- ultimativ
- Ultimativt
- låser op
- indtil
- ubrugt
- på
- oppetid
- us
- anvendte
- Bruger
- brugere
- ved brug af
- nytte
- værdi
- udgave
- meget
- synlig
- vision
- ønsker
- var
- Vej..
- we
- Vejr
- GODT
- var
- Hvad
- uanset
- hvornår
- som
- mens
- WHO
- bred
- vilje
- aftørring
- med
- inden for
- Arbejde
- arbejdede
- arbejder
- world
- bekymre sig
- ville
- år
- år
- zephyrnet