Introduktion
Inden for akademisk forskning kan rejsen fra rå data til indsigtsfulde konklusioner være skræmmende, hvis du er nybegynder eller novice. Men med den rigtige tilgang og værktøjer er det en uhyre givende oplevelse at transformere data til meningsfuld viden. I denne guide vil vi lede dig gennem en typisk arbejdsgang for akademisk dataanalyse ved hjælp af et praktisk eksempel fra en nylig undersøgelse om effektiviteten af forskellige diæter til vægttab.

Indholdsfortegnelse
Læringsmål
Vi bruger en avanceret AI-dataværktøj - Julius, for at udføre analysen. Vores mål er at afmystificere den akademiske forskningsanalyseproces og vise, hvordan data, når de analyseres omhyggeligt og korrekt, kan belyse fascinerende tendenser og give svar på kritiske forskningsspørgsmål.
Navigering i det akademiske dataworkflow med Julius
I akademisk forskning er den måde, vi håndterer data på, nøglen til at afdække ny indsigt. Denne del af vores guide leder dig gennem standardtrinene til at analysere forskningsdata. Fra at starte med et klart spørgsmål til at dele de endelige resultater, er hvert trin afgørende.
Vi viser, hvordan forskere ved at følge denne klare vej kan omdanne rå data til pålidelige og værdifulde resultater. Derefter fører vi dig gennem hvert trin i et eksempel på et casestudie, og viser dig, hvordan du sparer tid, mens du sikrer resultater af højere kvalitet ved at bruge Julius gennem hele processen.
1. Spørgsmålsformulering
Begynd med at definere dit forskningsspørgsmål eller din hypotese klart. Dette guider hele analysen og bestemmer de metoder, du vil bruge.
2. Dataindsamling
Indsaml de nødvendige data, og sørg for, at de stemmer overens med dit forskningsspørgsmål. Dette kan involvere indsamling af nye data eller brug af eksisterende datasæt. Dataene bør omfatte variabler, der er relevante for din undersøgelse.
3. Datarensning og forbehandling
Forbered dit datasæt til analyse. Dette trin involverer sikring af datakonsistens (som standardiserede måleenheder), håndtering af manglende værdier og identifikation af eventuelle fejl eller afvigelser i dine data.
4. Exploratory Data Analysis (EDA)
Foretag en indledende undersøgelse af dataene. Dette omfatter analyse af fordelingen af variabler, identifikation af mønstre eller outliers og forståelse af dit datasæts egenskaber.
5. Metodevalg
- Bestemmelse af analyseteknikker: Vælg passende statistiske metoder eller modeller baseret på dine data og forskningsspørgsmål. Dette kunne involvere at sammenligne grupper, identificere relationer eller forudsige resultater.
- Overvejelser for metodevalg: Udvælgelsen er påvirket af typen af data (f.eks. kategorisk eller kontinuerlig), antallet af grupper, der sammenlignes, og arten af de relationer, du undersøger.
6. Statistisk analyse
- Operationaliserende variabler: Hvis det er nødvendigt, opret nye variabler, der bedre repræsenterer de begreber, du studerer.
- Udførelse af statistiske test: Anvend de valgte statistiske metoder til at analysere dine data. Dette kunne involvere test som t-test, ANOVA, regressionsanalyse osv.
- Regnskab for kovariater: I mere komplekse analyser skal du inkludere andre relevante variabler for at kontrollere deres potentielle virkninger.
7. Fortolkning
Fortolk omhyggeligt resultaterne i sammenhæng med dit forskningsspørgsmål. Dette indebærer at forstå, hvad de statistiske resultater betyder i praksis og overveje eventuelle begrænsninger.
8. Rapportering
Saml dine resultater, metodologi og fortolkninger i en omfattende rapport eller akademisk papir. Dette skal være klart, kortfattet og velstruktureret for effektivt at kommunikere din forskning.
Case Study Introduktion
I dette casestudie undersøger vi, hvordan forskellige diæter påvirker vægttab. Vi har data, herunder alder, køn, startvægt, diættype og vægt efter seks uger. Vores mål er at finde ud af, hvilke diæter der er mest effektive til vægttab, ved at bruge rigtige data fra rigtige mennesker.
Spørgsmålsformulering
I enhver forskning, som vores undersøgelse om diæter og vægttab, begynder alt med et godt spørgsmål. Det er som en køreplan for din forskning, der guider dig til, hvad du skal fokusere på.
Med vores kostdata spurgte vi f.eks. Fører en specifik diæt til et betydeligt vægttab på seks uger?
Dette spørgsmål er ligetil og fortæller os præcis, hvad vi skal kigge efter i vores data, som omfatter detaljer som hver persons diættype, vægt før og efter seks uger, alder og køn. Et klart spørgsmål som dette sikrer, at vi holder os på sporet og ser på de rigtige ting i vores data for at finde de svar, vi har brug for.
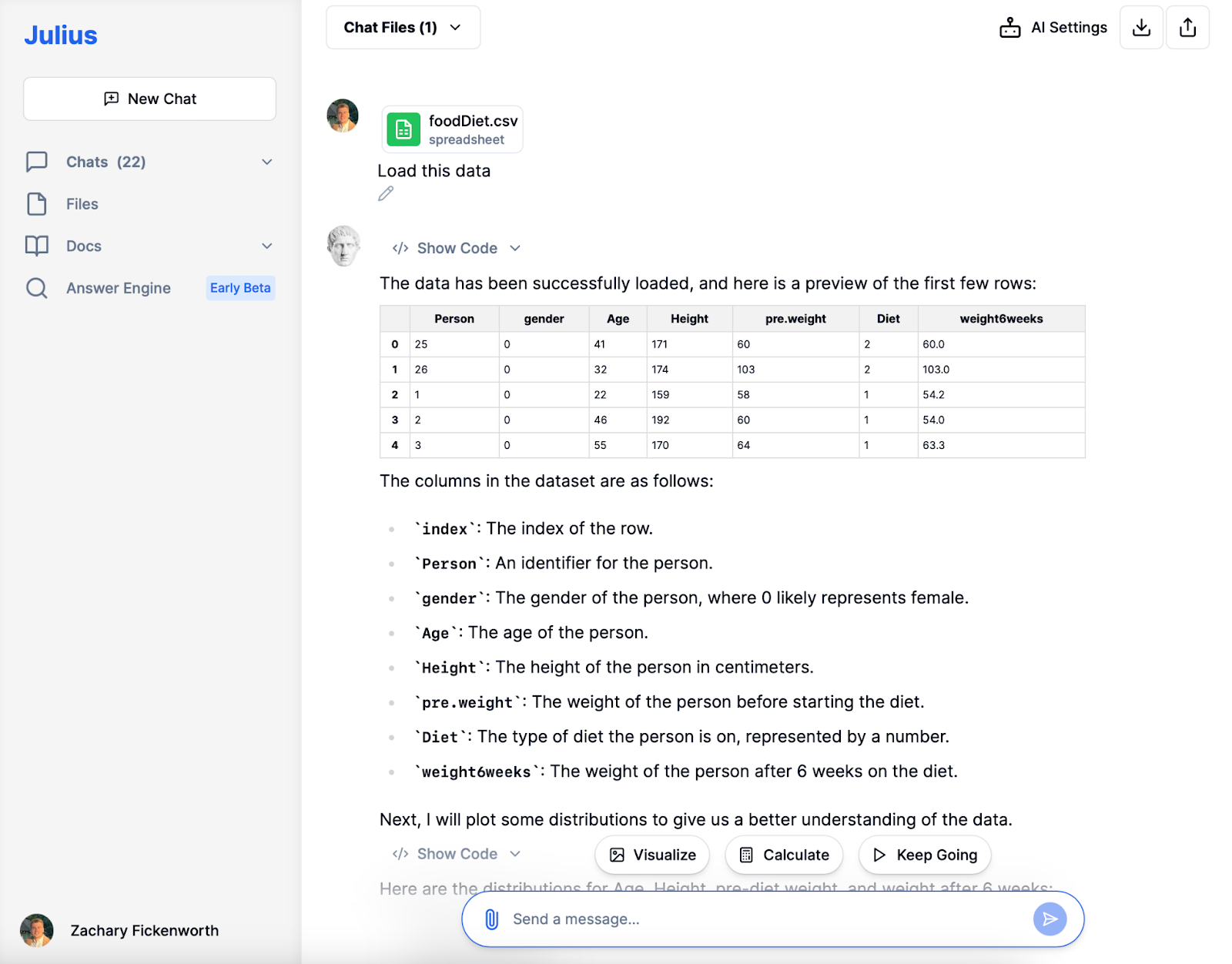
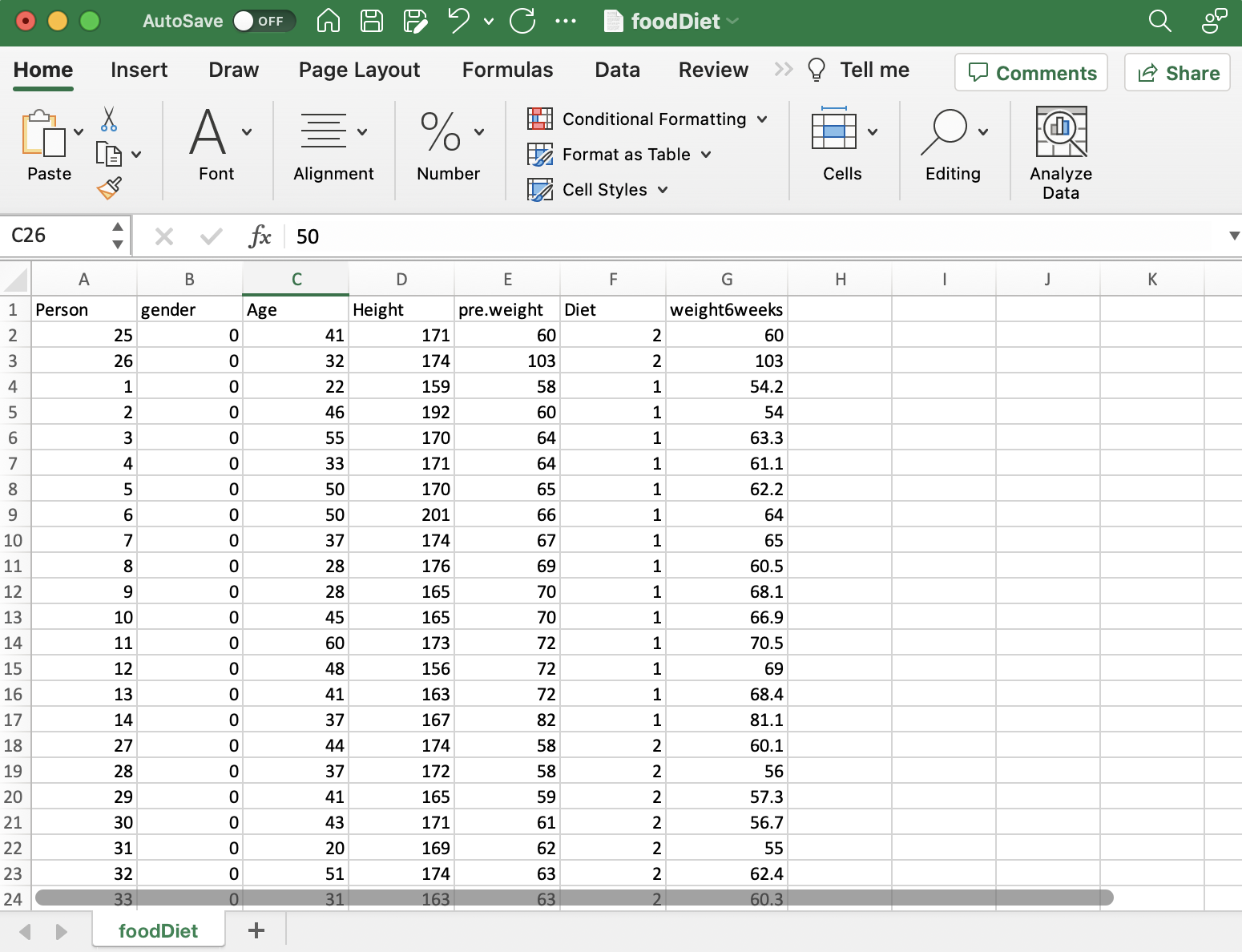
Dataindsamling
Inden for forskning er det vigtigt at indsamle de rigtige data. Til vores undersøgelse af diæter og vægttab indsamlede vi information om hver persons diættype, deres vægt før og efter diæten, alder og køn. Det er vigtigt at sikre, at dataene passer til dit forskningsspørgsmål. I nogle tilfælde skal du muligvis indsamle nye oplysninger, men her brugte vi eksisterende data, som allerede havde alle de detaljer, vi havde brug for. At få gode data er det første store skridt i at finde ud af, hvad du gerne vil vide.
Datarensning og forbehandling
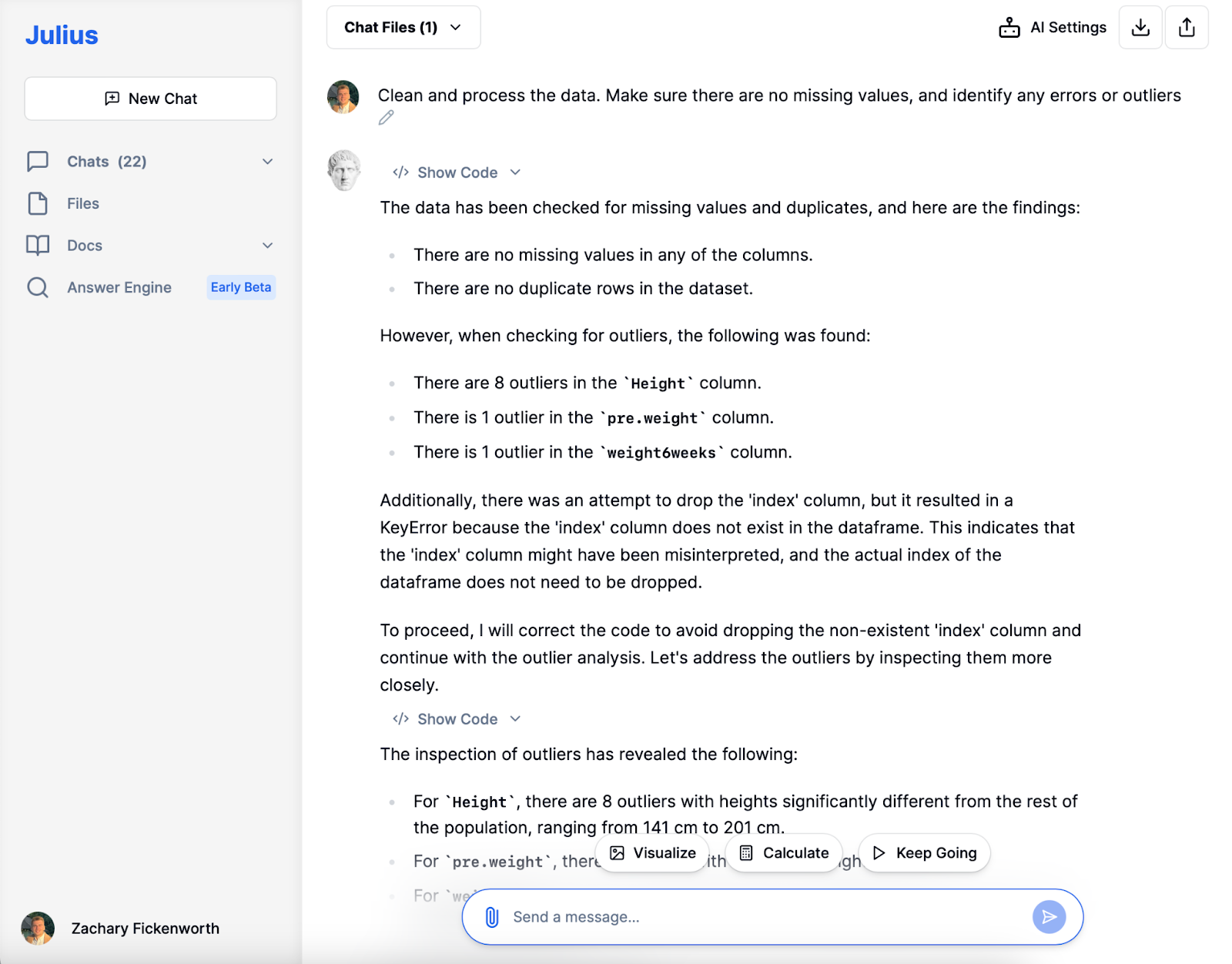
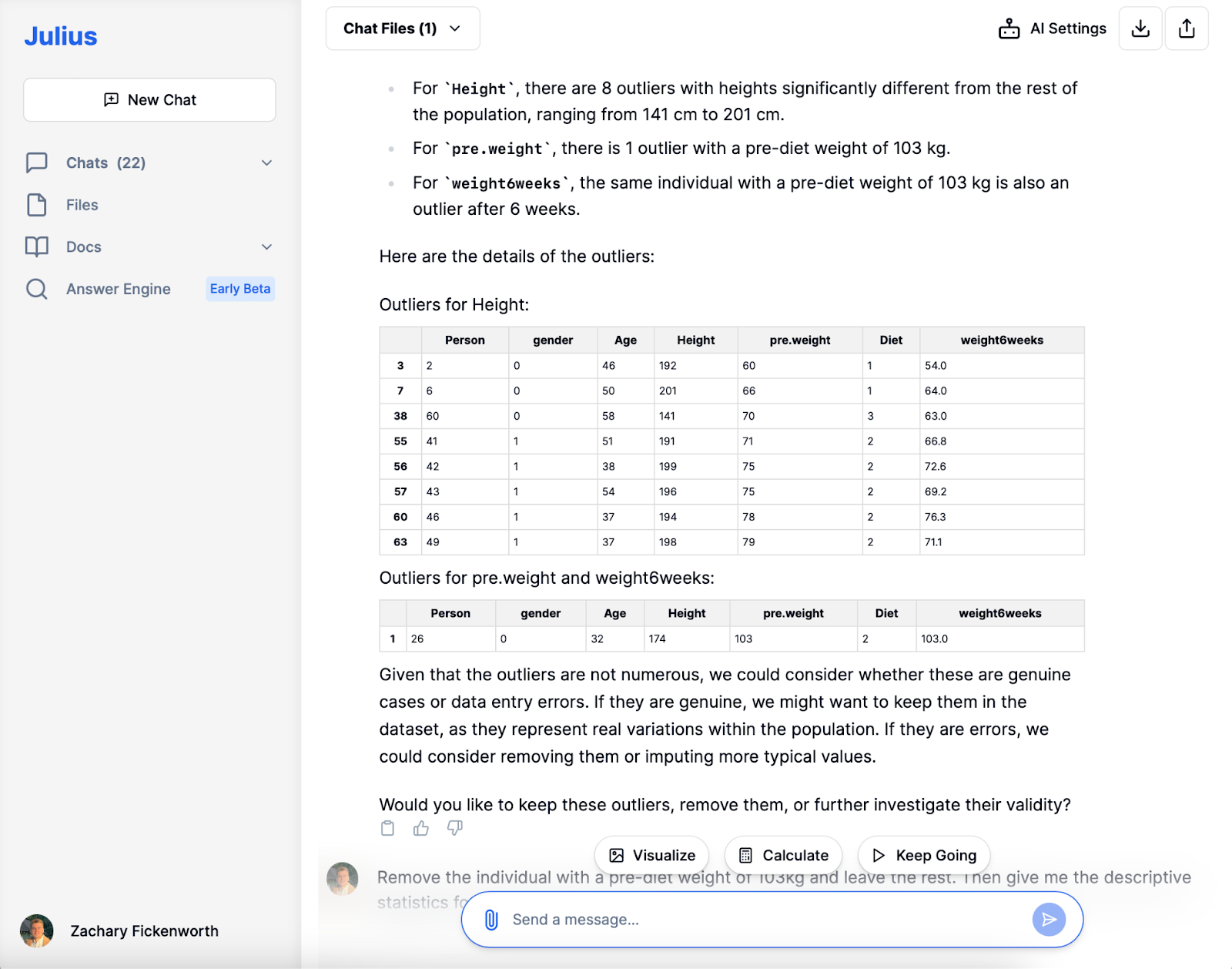
I vores kostundersøgelse var datarensning med Julius afgørende. Efter indlæsning af dataene identificerede Julius manglende værdier og dubletter, hvilket sikrede datasættets klarhed. Samtidig med at vi bevarede afvigelser i højden for diversitet, valgte vi at udelukke et individ med en usædvanlig høj vægt før diæt (103 kg) for at bevare analyseintegriteten og sikre datasættet parat til efterfølgende stadier.
Exploratory Data Analysis (EDA)
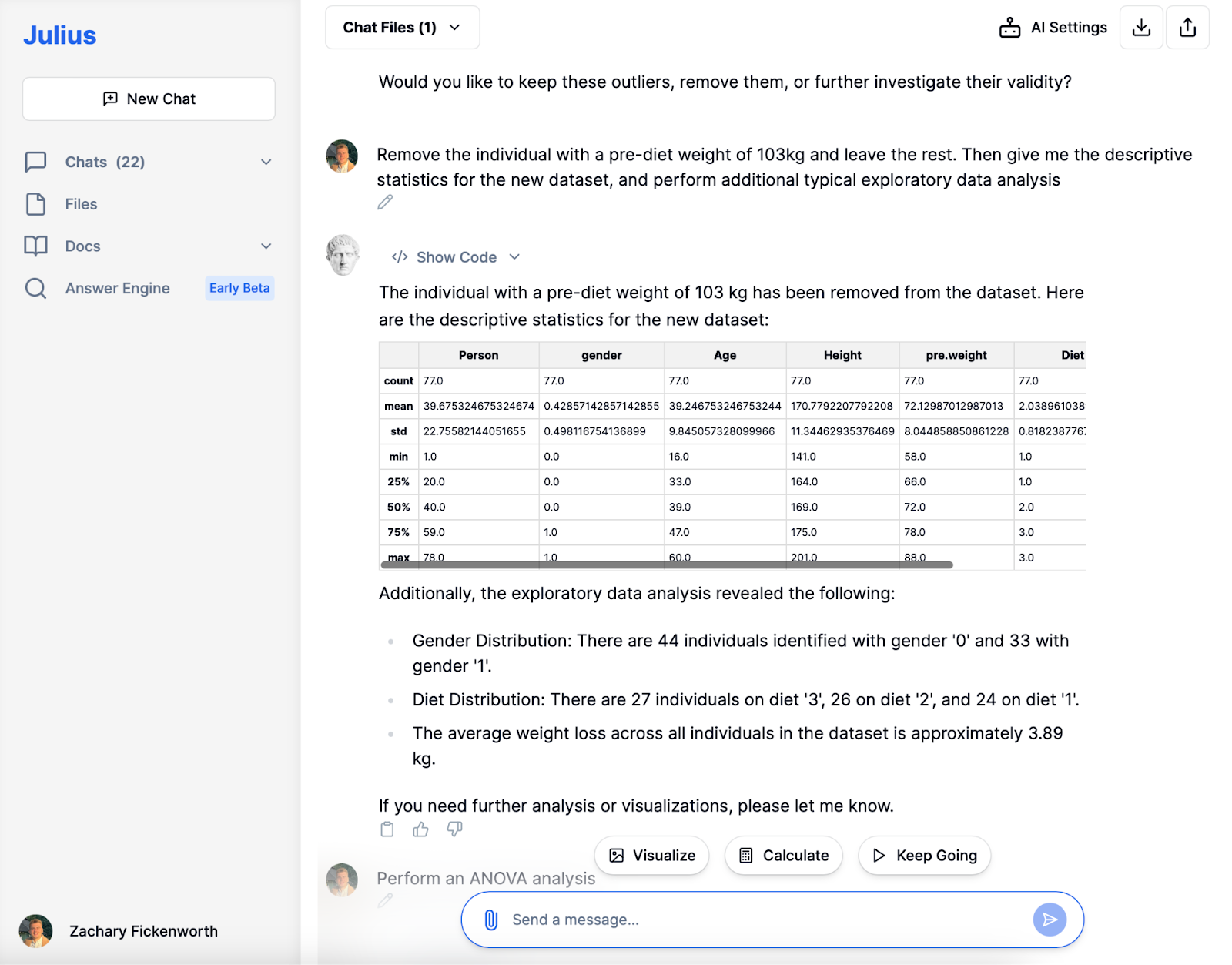
Efter fjernelse af outlieren med en usædvanlig høj vægt før diæt, dykkede vi ind i den eksplorative dataanalyse (EDA) fase. Julius leverede hurtigt friske beskrivende statistikker, hvilket gav et klarere overblik over vores 77 deltagere. At opdage en gennemsnitlig vægt før diæt på cirka 72 kg og et gennemsnitligt vægttab på omkring 3.89 kg gav værdifuld indsigt.
Ud over grundlæggende statistikker faciliterede Julius en undersøgelse af køns- og kostfordelingen. Undersøgelsen afslørede en afbalanceret kønsfordeling og en jævn fordeling på tværs af forskellige kosttyper. Denne EDA opsummerer ikke blot data; den afslører mønstre og tendenser, som er afgørende for en dybere analyse. For eksempel sætter forståelsen af det gennemsnitlige vægttab scenen for at bestemme den mest effektive diæt. Denne AI-drevne fase etablerer grundlaget for efterfølgende detaljeret analyse.
Metodevalg
I vores kostundersøgelse var udvælgelsen af de passende statistiske metoder et afgørende skridt. Vores hovedmål var at sammenligne vægttab på tværs af forskellige diæter, hvilket direkte informerede vores valg af analyseteknikker. Da vi havde mere end to grupper (de forskellige diættyper) at sammenligne, var en variansanalyse (ANOVA) det ideelle valg. ANOVA er kraftfuld i situationer som vores, hvor vi skal forstå, om der er signifikante forskelle i en kontinuerlig variabel (vægttab) på tværs af flere uafhængige grupper (kosttyperne).
Men mens ANOVA fortæller os, om der er forskelle, specificerer den ikke, hvor disse forskelle ligger. For at finde ud af, hvilke specifikke diæter der var mest effektive, havde vi brug for en mere målrettet tilgang. Det var her, Pairwise-sammenligninger kom ind i billedet. Efter at have fundet signifikante resultater med ANOVA, brugte vi Pairwise-sammenligninger til at undersøge vægttabsforskellene mellem hvert par af diættyper.
Denne to-trins tilgang – begyndende med ANOVA for at opdage eventuelle overordnede forskelle, efterfulgt af parvise sammenligninger for at detaljere disse forskelle – var strategisk. Det gav en omfattende forståelse af, hvordan hver diæt klarede sig i forhold til de andre, hvilket sikrede en grundig og nuanceret analyse af vores kostdata.
Statistisk analyse
ANOVA
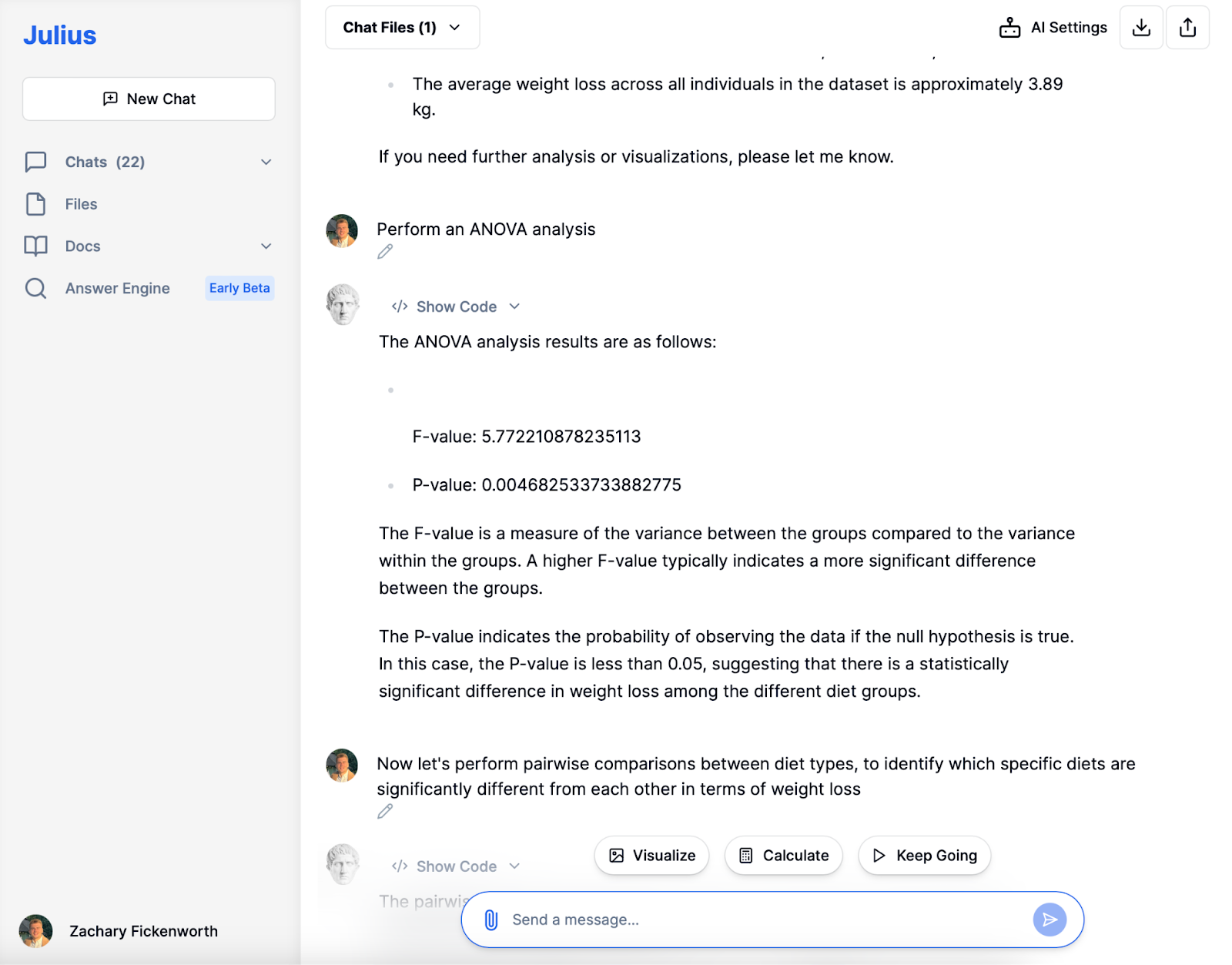
I hjertet af vores statistiske udforskning gennemførte vi en ANOVA analyse for at forstå, om vægttabsforskellene på tværs af de forskellige kosttyper var statistisk signifikante. Resultaterne var ret afslørende. Med en F-værdi på 5.772 antydede analysen en bemærkelsesværdig varians mellem diætgrupperne sammenlignet med variansen inden for hver gruppe. Denne F-værdi, der er højere, var tegn på signifikante forskelle i vægttab på tværs af diæterne.
Mere afgørende var det, at P-værdien, på 0.00468, skilte sig ud. Denne værdi, der ligger et godt stykke under den konventionelle tærskel på 0.05, tydede stærkt på, at de forskelle, vi observerede i vægttab blandt diætgrupperne, ikke kun var tilfældige. I statistiske termer betød det, at vi kunne forkaste nulhypotesen - som ikke ville antage nogen forskel i vægttab på tværs af diæterne - og konkludere, at diættypen faktisk havde en signifikant indflydelse på vægttabet. Dette ANOVA-resultat var en kritisk milepæl, der førte os til yderligere at undersøge præcis, hvilke diæter der adskilte sig fra hinanden.
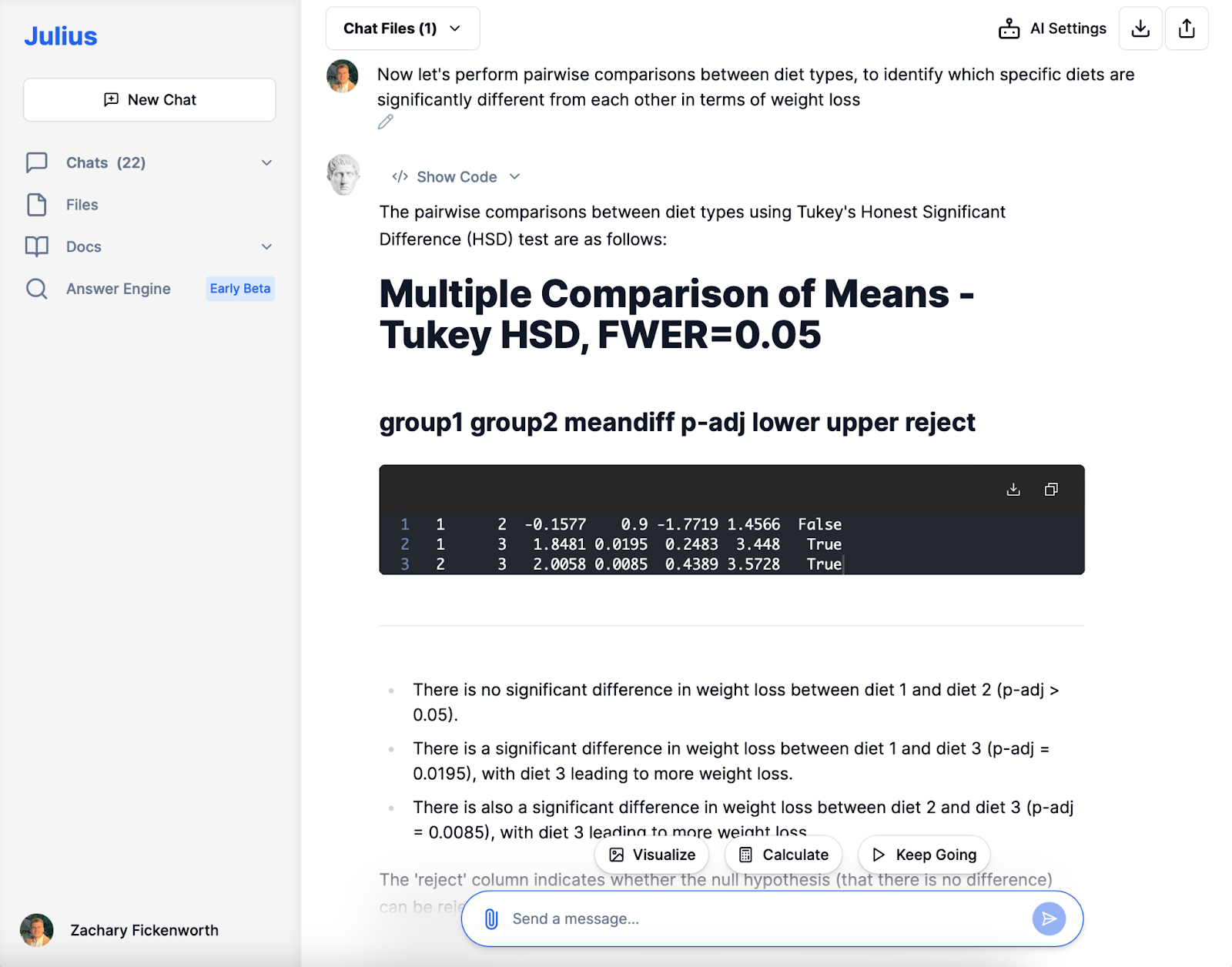
Parvis
I den følgende analysefase med Julius udførte vi parvise sammenligninger mellem diættyper for at identificere specifikke forskelle i vægttab. Tukey HSD-testen viste ingen signifikant forskel mellem kost 1 og kost 2. Den afslørede dog, at kost 3 resulterede i et signifikant større vægttab sammenlignet med både kost 1 og kost 2, understøttet af statistisk signifikante p-værdier. Denne kortfattede, men indsigtsfulde analyse af Julius spillede en afgørende rolle i at forstå den relative effektivitet af hver diæt.
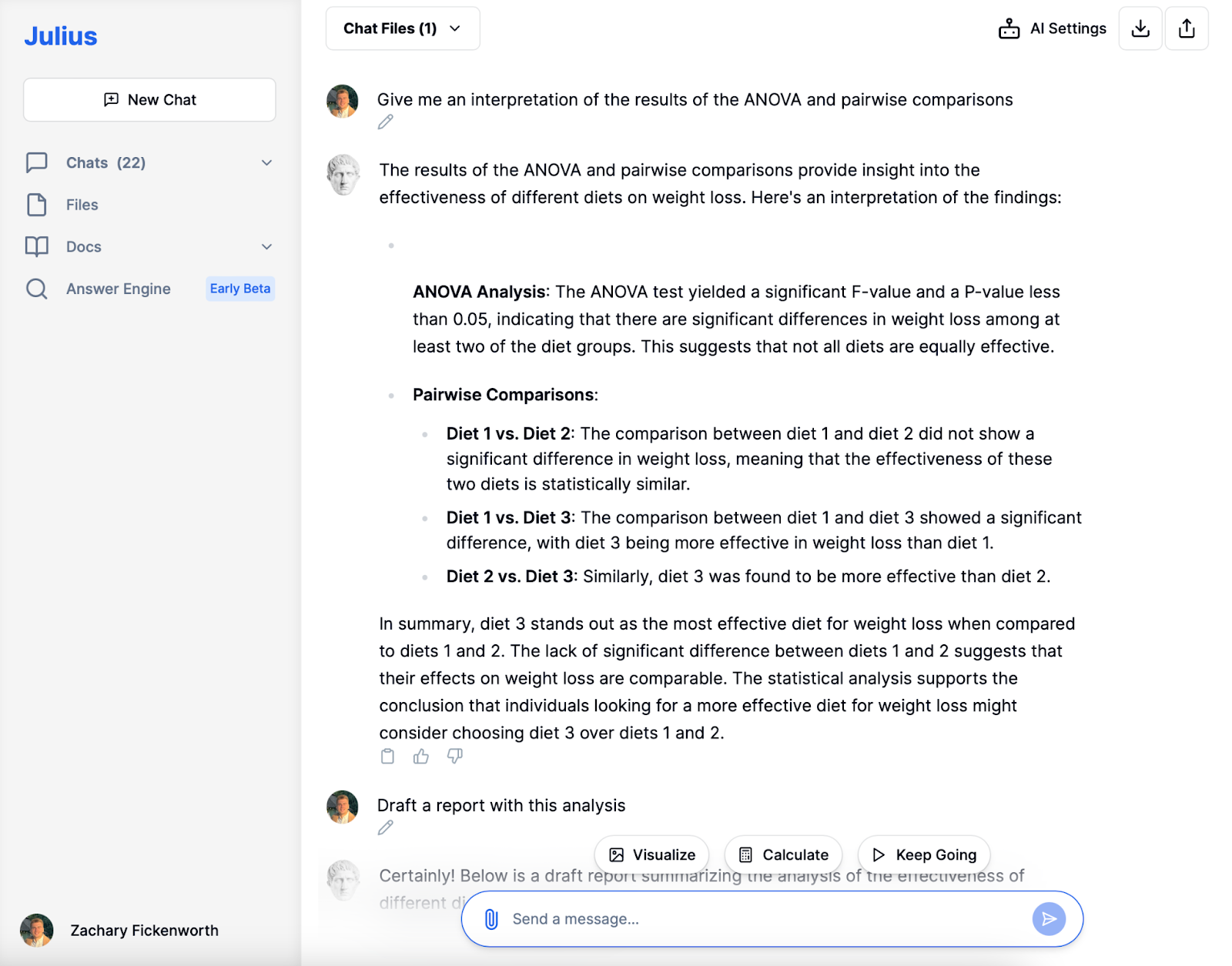
Fortolkning
I vores undersøgelse af diæteffektivitet spillede Julius en nøglerolle i at fortolke og forklare resultaterne af ANOVA og parvise sammenligninger. Sådan hjalp det os med at forstå resultaterne:
ANOVA fortolkning
Den analyserede først ANOVA-resultaterne, som viste en signifikant F-værdi og en P-værdi mindre end 0.05. Dette indikerede, at der var betydningsfulde forskelle i vægttab blandt de forskellige diætgrupper. Det hjalp os med at forstå, at dette betød, at ikke alle diæter i undersøgelsen var lige effektive til at fremme vægttab.
Fortolkning af parvise sammenligninger
- Diæt 1 vs. Diæt 2: Den sammenlignede disse to diæter og fandt ingen signifikant forskel i vægttab. Denne fortolkning betød, at disse to diæter statistisk set var lige effektive.
- Diæt 1 vs. diæt 3 og diæt 2 vs. diæt 3: I begge disse sammenligninger bekræftede jeg, at diæt 3 var signifikant mere effektiv til at fremme vægttab end enten diæt 1 eller diæt 2.
Julius' fortolkning var afgørende for at drage konkrete konklusioner fra vores analyse. Det præciserede, at mens kost 1 og 2 var ens i deres effektivitet, var kost 3 den iøjnefaldende mulighed for vægttab. Denne fortolkning gav os ikke kun et klart resultat af undersøgelsen, men demonstrerede også de praktiske implikationer af vores resultater. Med denne information kan vi med sikkerhed foreslå, at Diet 3 kan være det bedre valg for personer, der søger effektive vægttabsløsninger.
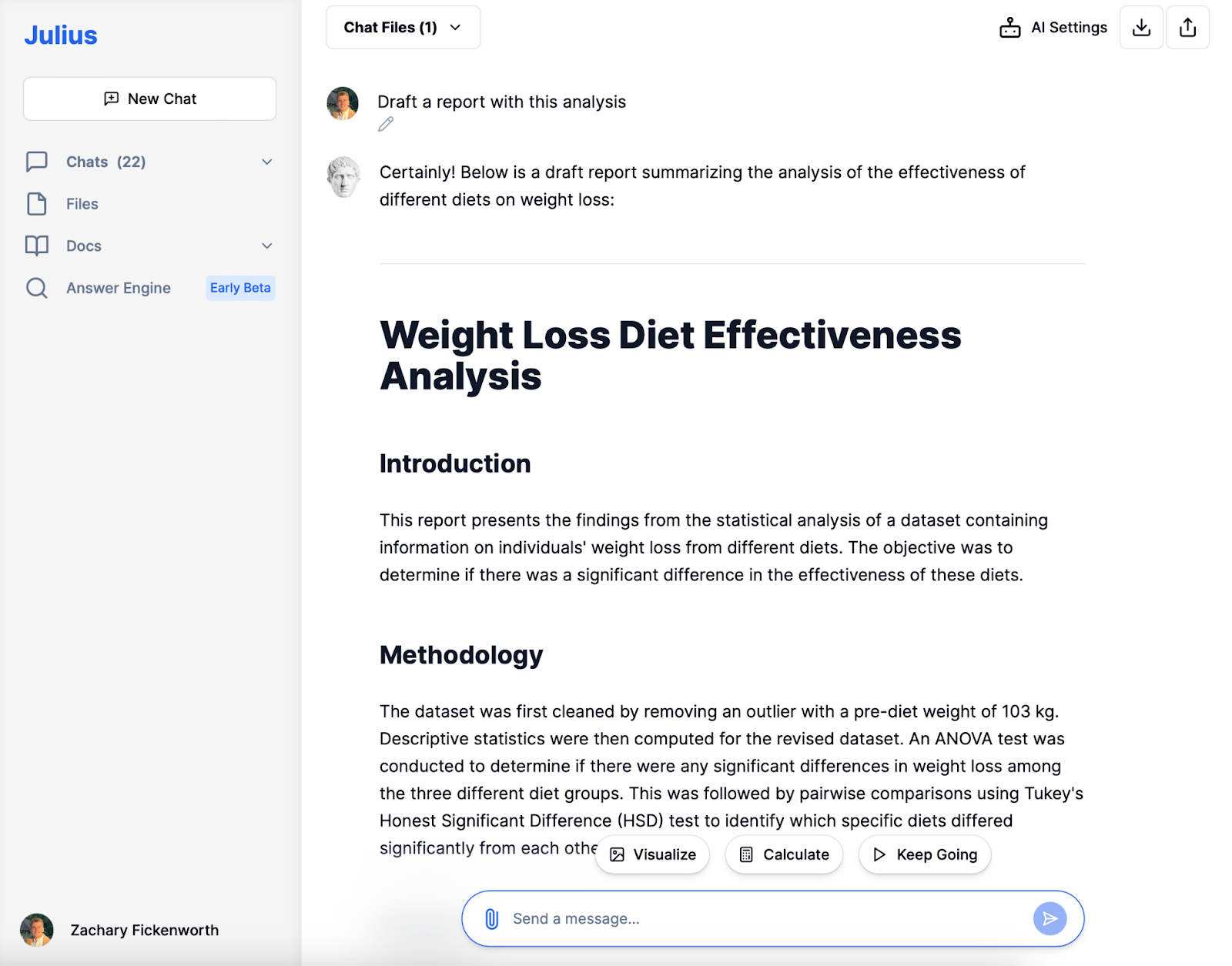
Rapportering
I den sidste fase af vores kostundersøgelse ville vi lave en rapport, der pænt opsummerer hele vores forskningsproces og resultater. Denne rapport, styret af analysen udført med Julius, vil omfatte:
- Introduktion: En kort forklaring på undersøgelsens formål, som er at evaluere effektiviteten af forskellige diæter på vægttab.
- Metode: En kortfattet beskrivelse af, hvordan vi rensede dataene, de anvendte statistiske metoder (ANOVA og Tukey's HSD), og hvorfor de blev valgt.
- Fund og fortolkning: En klar præsentation af resultaterne, herunder de væsentlige forskelle, der er fundet mellem diæterne, især fremhævelse af Diet 3's effektivitet.
- konklusion: At drage endelige konklusioner fra dataene og foreslå praktiske implikationer eller anbefalinger baseret på vores resultater.
- Referencer: Med henvisning til de værktøjer og statistiske metoder, som Julius, der understøttede vores analyse.
Denne rapport vil tjene som en klar, struktureret og omfattende registrering af vores forskning, hvilket gør den tilgængelig og informativ for sine læsere.
Konklusion
Vi er nået til slutningen af vores rejse inden for akademisk forskning, hvor vi forvandler et datasæt om diæter til meningsfuld indsigt. Denne proces, fra det indledende spørgsmål til den endelige rapport, viser, hvordan de rigtige værktøjer og metoder kan gøre dataanalyse tilgængelig, selv for begyndere.
Ved brug af Julius, vores avancerede AI-værktøj, har vi set, hvordan strukturerede trin i dataanalyse kan afsløre vigtige tendenser og besvare vigtige spørgsmål. Vores undersøgelse af diæter og vægttab er blot et eksempel på, hvordan data, når de analyseres omhyggeligt, ikke kun fortæller en historie, men også giver klare, handlingsrettede konklusioner. Vi håber, at denne guide har kastet lys over dataanalyseprocessen, hvilket gør den mindre skræmmende og mere spændende for alle, der er interesseret i at afdække historierne, der er gemt i deres data.
Relaterede
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.analyticsvidhya.com/blog/2024/01/guide-to-academic-data-analysis-with-julius-ai/
- :har
- :er
- :ikke
- :hvor
- 1
- 72
- 77
- a
- akademisk
- akademisk forskning
- tilgængelig
- tværs
- fremskreden
- Efter
- alder
- AI
- AI-drevne
- sigte
- Justerer
- Alle
- allerede
- også
- blandt
- an
- analyser
- analyse
- analysere
- analyseret
- analysere
- ,
- besvare
- svar
- enhver
- nogen
- tilgang
- tilgængelig
- passende
- cirka
- ER
- OMRÅDE
- omkring
- AS
- antage
- At
- gennemsnit
- Balanceret
- baseret
- grundlæggende
- BE
- før
- Begynder
- begyndere
- være
- jf. nedenstående
- Bedre
- mellem
- Big
- både
- men
- by
- kom
- CAN
- omhyggeligt
- tilfælde
- casestudie
- tilfælde
- chance
- karakteristika
- valg
- valgt
- afklaret
- klarhed
- Rengøring
- klar
- klarere
- tydeligt
- indsamler
- Indsamling
- samling
- Kom
- kommunikere
- sammenligne
- sammenlignet
- sammenligne
- sammenligninger
- komplekse
- omfattende
- begreber
- kortfattet
- konkluderer
- beton
- gennemført
- trygt
- Overvejer
- sammenhæng
- kontinuerlig
- kontrol
- konventionelle
- kunne
- skabe
- kritisk
- afgørende
- afgørende
- data
- dataanalyse
- datasæt
- dybere
- definere
- demonstreret
- afmystificere
- beskrivelse
- detail
- detaljeret
- detaljer
- opdage
- bestemmer
- bestemmelse
- DID
- Kost
- forskel
- forskelle
- forskellige
- direkte
- opdage
- fordeling
- Mangfoldighed
- Er ikke
- færdig
- tegning
- dubletter
- e
- hver
- Effektiv
- effektivt
- effektivitet
- effekter
- enten
- ende
- sikring
- Hele
- lige
- fejl
- især
- indfører
- etc.
- Ether (ETH)
- evaluere
- Endog
- at alt
- præcist nok
- undersøgelse
- undersøge
- Undersøgelse
- eksempel
- undtagelsesvis
- spændende
- eksisterende
- erfaring
- forklarer
- forklaring
- udforskning
- Udforskende dataanalyse
- lettes
- fascinerende
- endelige
- Finde
- finde
- fund
- Fornavn
- passer
- Fokus
- efterfulgt
- efter
- Til
- formulering
- fundet
- frisk
- fra
- yderligere
- indsamlede
- gav
- Køn
- få
- given
- mål
- godt
- større
- fundament
- gruppe
- Gruppens
- vejlede
- guidet
- Guides
- vejledende
- havde
- håndtere
- Håndtering
- Have
- Hjerte
- højde
- hjulpet
- link.
- Skjult
- Høj
- højere
- fremhæve
- håber
- Hvordan
- How To
- Men
- HTTPS
- i
- ideal
- identificeret
- identificere
- identificere
- if
- belyse
- uhyre
- KIMOs Succeshistorier
- implikationer
- vigtigt
- in
- omfatter
- omfatter
- Herunder
- uafhængig
- angivet
- vejledende
- individuel
- enkeltpersoner
- påvirket
- oplysninger
- informative
- informeret
- initial
- indsigtsfuld
- indsigt
- integritet
- interesseret
- fortolkning
- ind
- undersøge
- involvere
- involverer
- IT
- ITS
- rejse
- Julius
- lige
- bare en
- Nøgle
- Kend
- viden
- føre
- førende
- mindre
- ligge
- lys
- ligesom
- begrænsninger
- lastning
- Se
- off
- Main
- vedligeholde
- lave
- maerker
- Making
- max-bredde
- Kan..
- betyde
- meningsfuld
- betød
- måling
- blot
- metode
- Metode
- metoder
- måske
- milepæl
- mangler
- modeller
- mere
- mest
- Natur
- nødvendig
- Behov
- behov
- Ny
- ingen
- bemærkelsesværdig
- novice
- nuanceret
- nummer
- objektiv
- observeret
- of
- tilbyde
- on
- ONE
- kun
- Option
- or
- Andet
- Andre
- vores
- ud
- Resultat
- udfald
- outlier
- samlet
- par
- Papir
- del
- deltagere
- sti
- mønstre
- Mennesker
- udføre
- udføres
- fase
- afgørende
- plato
- Platon Data Intelligence
- PlatoData
- spillet
- potentiale
- vigtigste
- Praktisk
- forudsige
- præsentation
- bevare
- behandle
- Fremme
- korrekt
- give
- forudsat
- giver
- kvalitet
- spørgsmål
- Spørgsmål
- helt
- Raw
- rådata
- læsere
- Readiness
- ægte
- nylige
- anbefalinger
- optage
- regression
- relation
- Relationer
- relative
- relevant
- fjernelse
- indberette
- repræsentere
- forskning
- forskere
- resultere
- resulteret
- Resultater
- afsløre
- Revealed
- afslørende
- givende
- højre
- køreplan
- roller
- Gem
- søger
- set
- udvælgelse
- valg
- tjener
- sæt
- flere
- deling
- kaste
- bør
- Vis
- viste
- viser
- Shows
- signifikant
- betydeligt
- lignende
- Tilsvarende
- situationer
- SIX
- Løsninger
- nogle
- specifikke
- delt
- Stage
- etaper
- standard
- standardiseret
- skille sig ud
- Starter
- statistiske
- statistisk
- statistik
- forblive
- Trin
- Steps
- stod
- Historier
- Story
- ligetil
- Strategisk
- kraftigt
- struktureret
- Studere
- studere
- efterfølgende
- tyder
- Understøttet
- sikker
- SVG
- hurtigt
- målrettet
- teknikker
- fortæller
- vilkår
- prøve
- tests
- end
- at
- Området
- deres
- derefter
- Der.
- Disse
- de
- ting
- denne
- tærskel
- Gennem
- hele
- tid
- til
- værktøj
- værktøjer
- spor
- omdanne
- Tendenser
- troværdig
- TUR
- Drejning
- to
- typen
- typer
- typisk
- forstå
- forståelse
- enheder
- afsløret
- Løfter sløret
- us
- brug
- anvendte
- ved brug af
- Værdifuld
- værdi
- Værdier
- variabel
- forskellige
- Specifikation
- vs
- gå
- gåture
- ønsker
- var
- Vej..
- we
- uger
- vægt
- GODT
- var
- Hvad
- hvornår
- hvorvidt
- som
- mens
- hvorfor
- vilje
- med
- inden for
- workflow
- ville
- endnu
- dig
- Din
- zach
- zephyrnet