I dag er vi glade for at kunne annoncere tilgængeligheden af Llama 2-inferens og finjusterende support på AWS Trainium , AWS-inferens tilfælde i Amazon SageMaker JumpStart. Brug af AWS Trainium- og Inferentia-baserede instanser gennem SageMaker kan hjælpe brugerne med at sænke finjusteringsomkostningerne med op til 50 % og sænke implementeringsomkostningerne med 4.7x, samtidig med at forsinkelsen pr. token reduceres. Llama 2 er en autoregressiv generativ tekstsprogmodel, der bruger en optimeret transformerarkitektur. Som en offentligt tilgængelig model er Llama 2 designet til mange NLP-opgaver såsom tekstklassificering, sentimentanalyse, sprogoversættelse, sprogmodellering, tekstgenerering og dialogsystemer. Finjustering og implementering af LLM'er, som Llama 2, kan blive dyrt eller udfordrende at opfylde realtidsydelse for at levere en god kundeoplevelse. Trainium og AWS Inferentia, aktiveret af AWS Neuron softwareudviklingskit (SDK), tilbyder en højtydende og omkostningseffektiv mulighed for træning og konklusioner af Llama 2-modeller.
I dette indlæg viser vi, hvordan man implementerer og finjusterer Llama 2 på Trainium- og AWS Inferentia-forekomster i SageMaker JumpStart.
Løsningsoversigt
I denne blog vil vi gennemgå følgende scenarier:
- Implementer Llama 2 på AWS Inferentia-forekomster i begge Amazon SageMaker Studio UI, med en installationsoplevelse med et enkelt klik og SageMaker Python SDK.
- Finjuster Llama 2 på Trainium-forekomster i både SageMaker Studio UI og SageMaker Python SDK.
- Sammenlign ydeevnen af den finjusterede Llama 2-model med den fortrænede model for at vise effektiviteten af finjustering.
For at få fat i, se GitHub eksempel notesbog.
Implementer Llama 2 på AWS Inferentia-instanser ved hjælp af SageMaker Studio UI og Python SDK
I dette afsnit demonstrerer vi, hvordan man implementerer Llama 2 på AWS Inferentia-instanser ved hjælp af SageMaker Studio UI til en implementering med et enkelt klik og Python SDK.
Oplev Llama 2-modellen på SageMaker Studio UI
SageMaker JumpStart giver adgang til både offentligt tilgængelige og proprietære fundament modeller. Foundation-modeller er indbygget og vedligeholdt fra tredjeparts- og proprietære udbydere. Som sådan frigives de under forskellige licenser som angivet af modelkilden. Sørg for at gennemgå licensen for enhver fundamentmodel, du bruger. Du er ansvarlig for at gennemgå og overholde alle gældende licensvilkår og sikre dig, at de er acceptable for din brugssituation, før du downloader eller bruger indholdet.
Du kan få adgang til Llama 2-fundamentmodellerne gennem SageMaker JumpStart i SageMaker Studio UI og SageMaker Python SDK. I dette afsnit gennemgår vi, hvordan du opdager modellerne i SageMaker Studio.
SageMaker Studio er et integreret udviklingsmiljø (IDE), der giver en enkelt webbaseret visuel grænseflade, hvor du kan få adgang til specialbyggede værktøjer til at udføre alle udviklingstrin for maskinlæring (ML), fra forberedelse af data til opbygning, træning og implementering af din ML modeller. For flere detaljer om, hvordan du kommer i gang og opsætter SageMaker Studio, se Amazon SageMaker Studio.
Når du er i SageMaker Studio, kan du få adgang til SageMaker JumpStart, som indeholder forudtrænede modeller, notebooks og præbyggede løsninger under Præbyggede og automatiserede løsninger. For mere detaljeret information om, hvordan du får adgang til proprietære modeller, se Brug proprietære fundamentmodeller fra Amazon SageMaker JumpStart i Amazon SageMaker Studio.
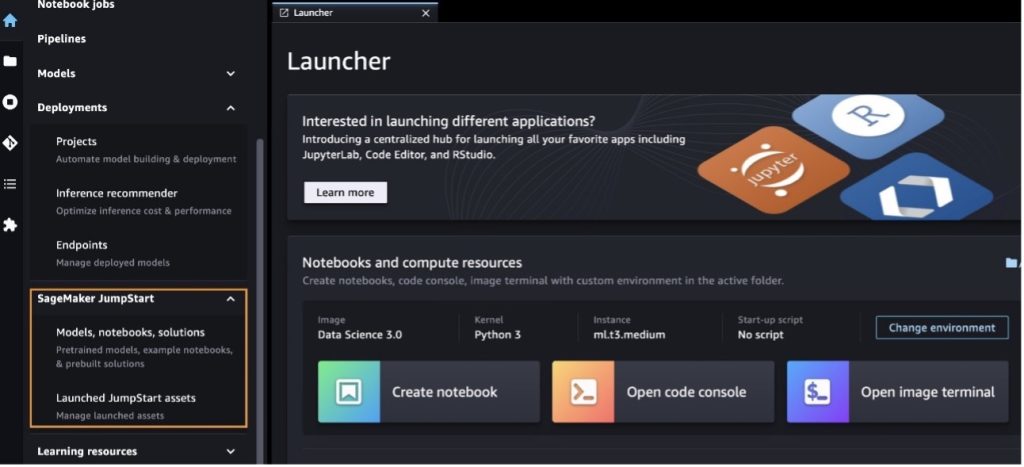
Fra SageMaker JumpStart-destinationssiden kan du søge efter løsninger, modeller, notebooks og andre ressourcer.
Hvis du ikke kan se Llama 2-modellerne, skal du opdatere din SageMaker Studio-version ved at lukke ned og genstarte. For mere information om versionsopdateringer, se Luk ned og opdater Studio Classic Apps.

Du kan også finde andre modelvarianter ved at vælge Udforsk alle tekstgenereringsmodeller eller søger efter llama or neuron i søgefeltet. Du vil være i stand til at se Llama 2 Neuron-modellerne på denne side.
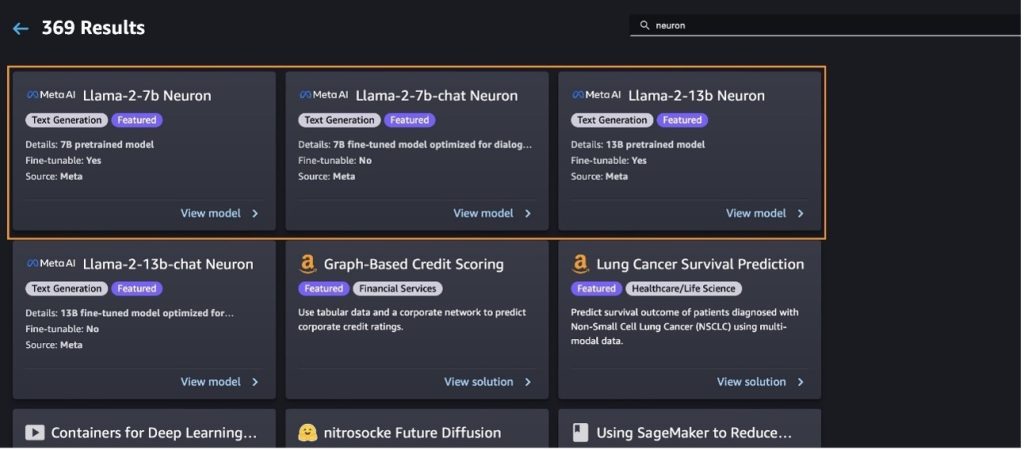
Implementer Llama-2-13b-modellen med SageMaker Jumpstart
Du kan vælge modelkortet for at se detaljer om modellen, såsom licens, data brugt til at træne, og hvordan du bruger det. Du kan også finde to knapper, Implementer , Åbn notesbog, som hjælper dig med at bruge modellen ved hjælp af dette eksempel uden kode.
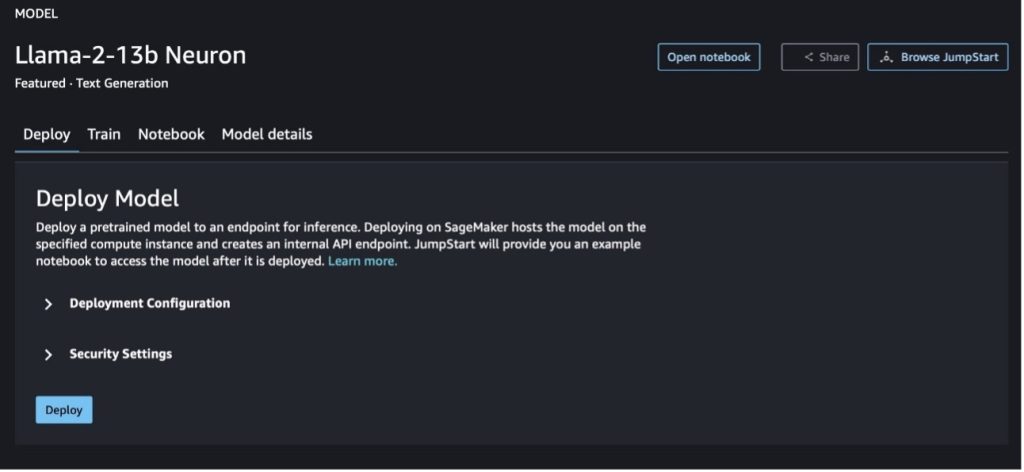
Når du vælger en af knapperne, vil en pop-up vise slutbrugerlicensaftalen og politik for acceptabel brug (AUP), som du kan anerkende.
Når du har anerkendt politikkerne, kan du implementere modellens slutpunkt og bruge det via trinene i næste afsnit.
Implementer Llama 2 Neuron-modellen via Python SDK
Når du vælger Implementer og anerkend vilkårene, vil modelimplementeringen begynde. Alternativt kan du implementere gennem eksempelnotesbogen ved at vælge Åbn notesbog. Eksemplet på notesbogen giver ende-til-ende vejledning om, hvordan man implementerer modellen til slutninger og renser ressourcer.
For at implementere eller finjustere en model på Trainium- eller AWS Inferentia-forekomster skal du først ringe til PyTorch Neuron (fakkel-neuronx) for at kompilere modellen til en Neuron-specifik graf, som vil optimere den til Inferentias NeuronCores. Brugere kan instruere compileren til at optimere til laveste latenstid eller højeste gennemløb, afhængigt af formålet med applikationen. I JumpStart prækompilerede vi Neuron-graferne til en række forskellige konfigurationer for at give brugerne mulighed for at nippe til kompileringstrin, hvilket muliggør hurtigere finjustering og implementering af modeller.
Bemærk, at den prækompilerede Neuron-graf er oprettet baseret på en specifik version af Neuron Compiler-versionen.
Der er to måder at implementere LIama 2 på AWS Inferentia-baserede forekomster. Den første metode udnytter den forudbyggede konfiguration og giver dig mulighed for at implementere modellen på kun to linjer kode. I den anden har du større kontrol over konfigurationen. Lad os starte med den første metode, med den forudbyggede konfiguration, og bruge den fortrænede Llama 2 13B Neuron Model som eksempel. Følgende kode viser, hvordan man implementerer Llama 13B med kun to linjer:
For at udføre slutninger om disse modeller, skal du specificere argumentet accept_eula at være True som en del af model.deploy() opkald. Ved at sætte dette argument til at være sandt, anerkender det, at du har læst og accepteret modellens EULA. EULA'en kan findes i modelkortets beskrivelse eller fra Meta hjemmeside.
Standardinstanstypen for Llama 2 13B er ml.inf2.8xlarge. Du kan også prøve andre understøttede modeller-id'er:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(chat model)meta-textgenerationneuron-llama-2-13b-f(chat model)
Alternativt, hvis du vil have mere kontrol over implementeringskonfigurationerne, såsom kontekstlængde, tensor parallelgrad og maksimal rullende batchstørrelse, kan du ændre dem via miljøvariabler, som vist i dette afsnit. Den underliggende Deep Learning Container (DLC) for implementeringen er Large Model Inference (LMI) NeuronX DLC. Miljøvariablerne er som følger:
- OPTION_N_POSITIONS – Det maksimale antal input- og output-tokens. Hvis du for eksempel kompilerer modellen med
OPTION_N_POSITIONSsom 512, så kan du bruge en input token på 128 (input prompt størrelse) med en maksimal output token på 384 (totalen af input og output tokens skal være 512). For det maksimale output-token er enhver værdi under 384 fint, men du kan ikke gå ud over det (for eksempel input 256 og output 512). - OPTION_TENSOR_PARALLEL_DEGREE – Antallet af NeuronCores til at indlæse modellen i AWS Inferentia-forekomster.
- OPTION_MAX_ROLLING_BATCH_SIZE – Den maksimale batchstørrelse for samtidige anmodninger.
- OPTION_DTYPE – Datotypen for at indlæse modellen.
Kompileringen af Neuron-grafen afhænger af kontekstlængden (OPTION_N_POSITIONS), tensor parallel grad (OPTION_TENSOR_PARALLEL_DEGREE), maksimal batchstørrelse (OPTION_MAX_ROLLING_BATCH_SIZE), og datatype (OPTION_DTYPE) for at indlæse modellen. SageMaker JumpStart har prækompileret Neuron-grafer til en række forskellige konfigurationer for de foregående parametre for at undgå runtime-kompilering. Konfigurationerne af prækompilerede grafer er angivet i følgende tabel. Så længe miljøvariablerne falder ind under en af følgende kategorier, vil kompilering af Neuron-grafer blive sprunget over.
| LIama-2 7B og LIama-2 7B Chat | ||||
| Forekomsttype | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B og LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Det følgende er et eksempel på implementering af Llama 2 13B og indstilling af alle tilgængelige konfigurationer.
Nu hvor vi har implementeret Llama-2-13b-modellen, kan vi køre slutninger med den ved at påkalde slutpunktet. Følgende kodestykke demonstrerer brugen af de understøttede inferensparametre til at styre tekstgenerering:
- max_længde – Modellen genererer tekst, indtil outputlængden (som inkluderer inputkontekstlængden) når
max_length. Hvis det er angivet, skal det være et positivt heltal. - max_new_tokens – Modellen genererer tekst, indtil outputlængden (eksklusive inputkontekstlængden) når
max_new_tokens. Hvis det er angivet, skal det være et positivt heltal. - antal_bjælker – Dette angiver antallet af stråler brugt i den grådige søgning. Hvis det er angivet, skal det være et heltal større end eller lig med
num_return_sequences. - no_repeat_ngram_size – Modellen sikrer, at en række af ord af
no_repeat_ngram_sizegentages ikke i outputsekvensen. Hvis det er angivet, skal det være et positivt heltal større end 1. - temperatur – Dette styrer tilfældigheden i outputtet. En højere temperatur resulterer i en udgangssekvens med ord med lav sandsynlighed; en lavere temperatur resulterer i en udgangssekvens med ord med høj sandsynlighed. Hvis
temperatureer lig med 0, resulterer det i grådig afkodning. Hvis det er angivet, skal det være en positiv flyder. - tidligt_stop - Hvis
True, er tekstgenerering afsluttet, når alle strålehypoteser når slutningen af sætningstokenet. Hvis det er angivet, skal det være boolesk. - do_sample - Hvis
True, modellen prøver det næste ord efter sandsynligheden. Hvis det er angivet, skal det være boolesk. - top_k – I hvert trin af tekstgenerering prøver modellen kun fra
top_khøjst sandsynlige ord. Hvis det er angivet, skal det være et positivt heltal. - top_s – I hvert trin af tekstgenerering prøver modellen fra det mindst mulige sæt af ord med en kumulativ sandsynlighed for
top_p. Hvis det er angivet, skal det være en flyder mellem 0-1. - stoppe – Hvis det er angivet, skal det være en liste over strenge. Tekstgenerering stopper, hvis en af de angivne strenge genereres.
Følgende kode viser et eksempel:
Produktion:
For mere information om parametrene i nyttelasten, se Detaljerede parametre.
Du kan også udforske implementeringen af parametrene i notesbog for at tilføje flere oplysninger om linket til notesbogen.
Finjuster Llama 2-modeller på Trainium-instanser ved hjælp af SageMaker Studio UI og SageMaker Python SDK
Generative AI-fundamentmodeller er blevet et primært fokus i ML og AI, men deres brede generalisering kan komme til kort på specifikke domæner som sundhedspleje eller finansielle tjenester, hvor unikke datasæt er involveret. Denne begrænsning fremhæver behovet for at finjustere disse generative AI-modeller med domænespecifikke data for at forbedre deres ydeevne inden for disse specialiserede områder.
Nu hvor vi har implementeret den fortrænede version af Llama 2-modellen, lad os se på, hvordan vi kan finjustere denne til domænespecifikke data for at øge nøjagtigheden, forbedre modellen med hensyn til hurtige afslutninger og tilpasse modellen til din specifikke business use case og data. Du kan finjustere modellerne ved at bruge enten SageMaker Studio UI eller SageMaker Python SDK. Vi diskuterer begge metoder i dette afsnit.
Finjuster Llama-2-13b Neuron-modellen med SageMaker Studio
I SageMaker Studio skal du navigere til Llama-2-13b Neuron-modellen. På den Implementer fanen, kan du pege på Amazon Simple Storage Service (Amazon S3) spand, der indeholder trænings- og valideringsdatasæt til finjustering. Derudover kan du konfigurere implementeringskonfiguration, hyperparametre og sikkerhedsindstillinger til finjustering. Vælg derefter Tog at starte træningsjobbet på en SageMaker ML-instans.

For at bruge Llama 2-modeller skal du acceptere EULA og AUP. Det vil dukke op, når du vælger Tog. Vælg Jeg har læst og accepterer EULA og AUP for at starte finjusteringsjobbet.
Du kan se status for dit træningsjob for den finjusterede model under på SageMaker-konsollen ved at vælge Træningsjob i navigationsruden.
Du kan enten finjustere din Llama 2 Neuron-model ved hjælp af dette eksempel uden kode eller finjustere via Python SDK, som vist i næste afsnit.
Finjuster Llama-2-13b Neuron-modellen via SageMaker Python SDK
Du kan finjustere datasættet med domænetilpasningsformatet eller instruktionsbaseret finjustering format. Følgende er instruktionerne for, hvordan træningsdataene skal formateres, før de sendes til finjustering:
- Input - A
trainmappe, der indeholder enten en JSON linjer (.jsonl) eller tekst (.txt) formateret fil.- For filen JSON-linjer (.jsonl) er hver linje et separat JSON-objekt. Hvert JSON-objekt skal struktureres som et nøgle-værdi-par, hvor nøglen skal være
text, og værdien er indholdet af ét træningseksempel. - Antallet af filer under togbiblioteket skal være lig med 1.
- For filen JSON-linjer (.jsonl) er hver linje et separat JSON-objekt. Hvert JSON-objekt skal struktureres som et nøgle-værdi-par, hvor nøglen skal være
- Produktion – En trænet model, der kan anvendes til slutninger.
I dette eksempel bruger vi en delmængde af Dolly datasæt i et instruktionsindstillingsformat. Dolly-datasættet indeholder cirka 15,000 instruktionsfølgende poster for forskellige kategorier, såsom besvarelse af spørgsmål, opsummering og informationsudtrækning. Den er tilgængelig under Apache 2.0-licensen. Vi bruger information_extraction eksempler til finjustering.
- Indlæs Dolly-datasættet og opdel det i
train(til finjustering) ogtest(til bedømmelse):
- Brug en promptskabelon til at forbehandle dataene i et instruktionsformat til træningsjobbet:
- Undersøg hyperparametrene og overskriv dem til dit eget brug:
- Finjuster modellen og start et SageMaker træningsjob. De finjusterende scripts er baseret på neuronx-nemo-megatron repository, som er modificerede versioner af pakkerne nemo , Apex der er blevet tilpasset til brug med Neuron- og EC2 Trn1-instanser. Det neuronx-nemo-megatron repository har 3D (data, tensor og pipeline) parallelitet for at give dig mulighed for at finjustere LLM'er i skala. De understøttede Trainium-instanser er ml.trn1.32xlarge og ml.trn1n.32xlarge.
- Til sidst skal du implementere den finjusterede model i et SageMaker-slutpunkt:
Sammenlign svar mellem de fortrænede og finjusterede Llama 2 Neuron-modeller
Nu hvor vi har implementeret den fortrænede version af Llama-2-13b-modellen og finjusteret den, kan vi se nogle af præstationssammenligningerne af de hurtige afslutninger fra begge modeller, som vist i følgende tabel. Vi tilbyder også et eksempel på at finjustere Llama 2 på et SEC-arkiveringsdatasæt i .txt-format. For detaljer, se GitHub eksempel notesbog.
| Vare | Indgange | Grund sandhed | Svar fra ikke-finjusteret model | Svar fra finjusteret model |
| 1 | Nedenfor er en instruktion, der beskriver en opgave, parret med et input, der giver yderligere kontekst. Skriv et svar, der korrekt udfylder anmodningen.nn### Instruktion:nUdtræk universiteter Moret studerede ved og hans eksamensår for hver, og sæt dem i en punktopstilling.nn### Input:nMoret blev født i 1953 i Vevey, Schweiz , og gjorde sine bachelorstudier ved École Polytechnique Fédérale de Lausanne (EPFL), dimitterede i 1975. Han fortsatte med kandidatstudier ved University of Tennessee og opnåede en Ph.D. i 1980. Han kom derefter til fakultetet ved University of New Mexico, hvor han blev indtil 2006, hvor han flyttede til EPFL. Han trak sig tilbage fra EPFL i december 2016.nnI 1996 grundlagde Moret ACM Journal of Experimental Algorithmics, og han forblev chefredaktør for tidsskriftet indtil 2003. I 2001 grundlagde Moret Workshop in Algorithms for Bioinformatics (WABI) og er fortsat på Styrekomité for konferencen.nnI 2018 blev Moret valgt som Fellow i International Society for Computational Biology for hans fremragende bidrag til områderne beregningsbiologi og bioinformatik.nn### Svar:n | * École Polytechnique Fédérale de Lausanne (EPFL) (uddannet 1975)n* University of Tennessee (uddannet 1980) | Moret studerede ved École Polytechnique Fédérale de Lausanne (EPFL) og University of Tennessee og dimitterede i henholdsvis 1975 og 1980. Brug "opdel"-funktionen til at opdele hver sætning i en liste med ord.n- Brug "opdel"-funktionen til at opdele | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexico- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Nedenfor er en instruktion, der beskriver en opgave, parret med et input, der giver yderligere sammenhæng. Skriv et svar, der korrekt udfylder anmodningen.n |
| 2 | Nedenfor er en instruktion, der beskriver en opgave, parret med et input, der giver yderligere kontekst. Skriv et svar, der korrekt fuldender anmodningen.nn### Instruktion:nIdentificer Dionysos egenskaber ud fra passagen. Vis resultaterne i et kommasepareret format.nn### Input:nDionysus (Διόνυσος, Diónusos)/Bacchus (Βάκχος, Bákkhos)nnGud for vin, frugtbarhed, fester, festivaler, galskab, kaos, drukkenskab, drukkenskab, ecsta teater. Han er den to gange fødte søn af Zeus og Semele, idet Zeus snuppede ham fra sin mors mave og syede Dionysos ind i hans eget lår og bar ham, indtil han var klar til at blive født. I kunsten er han afbildet som enten en ældre skægget gud (især før 430 f.Kr.) eller en feminin, langhåret ungdom (især efter 430 f.Kr.). Hans egenskaber omfatter thyrsus, en drikkebæger, vinstokken og en vedbendskrone. Han er ofte i selskab med sine thiasos, en gruppe ledsagere, inklusive satyrer, maenader og hans gamle lærer Silenus. Dionysos ægtefælle var Ariadne. Det blev engang hævdet, at Dionysius var en senere tilføjelse til det græske pantheon, men opdagelsen af lineære B-tavler bekræfter hans status som en guddom fra en tidlig periode. Bacchus var et andet navn for ham på græsk og kom i almindelig brug blandt romerne. Hans hellige dyr omfatter delfiner, slanger, tigre og æsler.nn### Svar:n | thyrsus, en drikkebæger, vinstokken, en vedbendskrone | Dionysos (Διόνυσος, Diónusos)nn Gud for vin, frugtbarhed, fester, festivaler, galskab, kaos, fuldskab, vegetation, ekstase og teatret. Han er den to gange fødte søn af Zeus og Semele, idet Zeus rev ham fra sin mors mave og syede Dionysos ind i hans eget lår | thyrsus, en drikkekop, druevinen, en krone af ivynn Nedenfor er en instruktion, der beskriver en opgave, parret med et input, der giver yderligere sammenhæng. Skriv et svar, der korrekt udfylder anmodningen.nn### Instruktion:nHvad er forskellen mellem Parthian og Arsacid Empire?nn### Input:nThe Parthian Empire, også kendt som Arsacid Empire var et |
| 3 | Nedenfor er en instruktion, der beskriver en opgave, parret med et input, der giver yderligere kontekst. Skriv et svar, der korrekt udfylder anmodningen.nn### Instruktion:nHvorfor indeholder hovedstaden i Usbekistan det største græske samfund?nn### Input:nGrækerne i Usbekistan tæller cirka 9,000. Samfundet består af grækere fra Rusland, der blev deporteret med magt fra dette land til Usbekistan i 1940'erne, og politiske flygtninge fra Grækenland. Omkring 30,000 grækere boede i landet før Anden Verdenskrig, og yderligere 11,000 ankom efter den græske borgerkrig og nederlaget for den græske demokratiske hær. Deres antal er faldet fra et højdepunkt på omkring 40,000 i 1960'erne. Hovedårsagen er emigration til Grækenland efter afslutningen af den kolde krig, da lovene tillod tilbagevenden af alle etniske grækere, der var blevet forvist af politiske årsager efter den græske borgerkrig. Det største græske samfund i landet er i hovedstaden Tasjkent, hvor de fleste af de græske politiske flygtninge blev flyttet af de sovjetiske myndigheder. I oldtiden var den sydlige del af landet en del af det hellenistiske seleukidiske rige, men de få græske samfund der har siden assimileret sig. Den vigtigste organisation, der repræsenterer etniske grækere, er den græske kulturforening i Tashkent. Denne organisations aktiviteter omfatter undervisning i græsk sprog (19 klasser med i alt 571 elever, klasser for voksne) og undervisning i græske danse og musik.nn### Respons:n | De fleste af de græske politiske flygtninge i Usbekistan blev flyttet af de sovjetiske myndigheder til hovedstaden Tasjkent. | n“`nUsbekistans hovedstad indeholder det største græske samfund, fordi grækerne i Usbekistan tæller cirka 9,000. Samfundet består af grækere fra Rusland, der blev deporteret med magt fra dette land til Usbekistan i 1940'erne, og politiske flygtninge fra Grækenland. Omkring 30,000 grækere boede i landet før Anden Verdenskrig og yderligere 11,00 | Hovedstaden i Usbekistan indeholder det største græske samfund, fordi det er her, de fleste af de græske politiske flygtninge blev flyttet af de sovjetiske myndigheder efter at være blevet deporteret fra Grækenland.nn Nedenfor er en instruktion, der beskriver en opgave, parret med et input, der giver yderligere kontekst. Skriv et svar, der korrekt udfylder anmodningen.nn### Instruktion:nHvad er forskellen mellem Parthian og Arsacid Empire?nn### Input:n |
Vi kan se, at svarene fra den finjusterede model viser en betydelig forbedring i præcision, relevans og klarhed sammenlignet med svarene fra den præ-trænede model. I nogle tilfælde er det måske ikke nok at bruge den fortrænede model til dit brugssag, så finjustering af den ved hjælp af denne teknik vil gøre løsningen mere personlig til dit datasæt.
Ryd op
Når du har afsluttet dit træningsjob og ikke ønsker at bruge de eksisterende ressourcer længere, skal du slette ressourcerne ved hjælp af følgende kode:
Konklusion
Implementeringen og finjusteringen af Llama 2 Neuron-modeller på SageMaker demonstrerer et betydeligt fremskridt inden for styring og optimering af generative AI-modeller i stor skala. Disse modeller, inklusive varianter som Llama-2-7b og Llama-2-13b, bruger Neuron til effektiv træning og konklusioner om AWS Inferentia- og Trainium-baserede instanser, hvilket forbedrer deres ydeevne og skalerbarhed.
Muligheden for at implementere disse modeller gennem SageMaker JumpStart UI og Python SDK giver fleksibilitet og brugervenlighed. Neuron SDK muliggør, med sin understøttelse af populære ML-frameworks og højtydende kapaciteter, effektiv håndtering af disse store modeller.
Finjustering af disse modeller på domænespecifikke data er afgørende for at forbedre deres relevans og nøjagtighed på specialiserede områder. Processen, som du kan udføre gennem SageMaker Studio UI eller Python SDK, giver mulighed for tilpasning til specifikke behov, hvilket fører til forbedret modelydelse i form af hurtige afslutninger og svarkvalitet.
Til sammenligning kan de fortrænede versioner af disse modeller, selvom de er stærke, give mere generiske eller gentagne svar. Finjustering skræddersyer modellen til specifikke kontekster, hvilket resulterer i mere præcise, relevante og forskelligartede svar. Denne tilpasning er især tydelig, når man sammenligner svar fra fortrænede og finjusterede modeller, hvor sidstnævnte demonstrerer en mærkbar forbedring i kvaliteten og specificiteten af output. Som konklusion repræsenterer implementeringen og finjusteringen af Neuron Llama 2-modeller på SageMaker en robust ramme til styring af avancerede AI-modeller, der tilbyder betydelige forbedringer i ydeevne og anvendelighed, især når de er skræddersyet til specifikke domæner eller opgaver.
Kom i gang i dag ved at henvise til eksempel SageMaker notesbog.
For mere information om implementering og finjustering af fortrænede Llama 2-modeller på GPU-baserede instanser, se Finjuster Llama 2 til tekstgenerering på Amazon SageMaker JumpStart , Llama 2 foundation-modeller fra Meta er nu tilgængelige i Amazon SageMaker JumpStart.
Forfatterne vil gerne anerkende de tekniske bidrag fra Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne og Mike James.
Om forfatterne
 Xin Huang er en Senior Applied Scientist for Amazon SageMaker JumpStart og Amazon SageMaker indbyggede algoritmer. Han fokuserer på at udvikle skalerbare maskinlæringsalgoritmer. Hans forskningsinteresser er inden for området naturlig sprogbehandling, forklarlig dyb læring på tabeldata og robust analyse af ikke-parametrisk rum-tid-klynger. Han har udgivet mange artikler i ACL, ICDM, KDD-konferencer og Royal Statistical Society: Series A.
Xin Huang er en Senior Applied Scientist for Amazon SageMaker JumpStart og Amazon SageMaker indbyggede algoritmer. Han fokuserer på at udvikle skalerbare maskinlæringsalgoritmer. Hans forskningsinteresser er inden for området naturlig sprogbehandling, forklarlig dyb læring på tabeldata og robust analyse af ikke-parametrisk rum-tid-klynger. Han har udgivet mange artikler i ACL, ICDM, KDD-konferencer og Royal Statistical Society: Series A.
 Nitin Eusebius er Sr. Enterprise Solutions Architect hos AWS, erfaren i Software Engineering, Enterprise Architecture og AI/ML. Han er dybt passioneret omkring at udforske mulighederne for generativ AI. Han samarbejder med kunder for at hjælpe dem med at bygge veldesignede applikationer på AWS-platformen og er dedikeret til at løse teknologiske udfordringer og hjælpe med deres cloud-rejse.
Nitin Eusebius er Sr. Enterprise Solutions Architect hos AWS, erfaren i Software Engineering, Enterprise Architecture og AI/ML. Han er dybt passioneret omkring at udforske mulighederne for generativ AI. Han samarbejder med kunder for at hjælpe dem med at bygge veldesignede applikationer på AWS-platformen og er dedikeret til at løse teknologiske udfordringer og hjælpe med deres cloud-rejse.
 Madhur Prashant arbejder i det generative AI-rum hos AWS. Han brænder for krydsfeltet mellem menneskelig tænkning og generativ AI. Hans interesser ligger i generativ AI, specifikt at bygge løsninger, der er hjælpsomme og harmløse og mest af alt optimale for kunderne. Uden for arbejdet elsker han at lave yoga, vandre, tilbringe tid med sin tvilling og spille guitar.
Madhur Prashant arbejder i det generative AI-rum hos AWS. Han brænder for krydsfeltet mellem menneskelig tænkning og generativ AI. Hans interesser ligger i generativ AI, specifikt at bygge løsninger, der er hjælpsomme og harmløse og mest af alt optimale for kunderne. Uden for arbejdet elsker han at lave yoga, vandre, tilbringe tid med sin tvilling og spille guitar.
 Dewan Choudhury er softwareudviklingsingeniør hos Amazon Web Services. Han arbejder på Amazon SageMakers algoritmer og JumpStart-tilbud. Udover at bygge AI/ML-infrastrukturer, brænder han også for at bygge skalerbare distribuerede systemer.
Dewan Choudhury er softwareudviklingsingeniør hos Amazon Web Services. Han arbejder på Amazon SageMakers algoritmer og JumpStart-tilbud. Udover at bygge AI/ML-infrastrukturer, brænder han også for at bygge skalerbare distribuerede systemer.
 Hao Zhou er forsker hos Amazon SageMaker. Før det arbejdede han med at udvikle maskinlæringsmetoder til svindeldetektion til Amazon Fraud Detector. Han brænder for at anvende maskinlæring, optimering og generative AI-teknikker på forskellige problemer i den virkelige verden. Han har en PhD i elektroteknik fra Northwestern University.
Hao Zhou er forsker hos Amazon SageMaker. Før det arbejdede han med at udvikle maskinlæringsmetoder til svindeldetektion til Amazon Fraud Detector. Han brænder for at anvende maskinlæring, optimering og generative AI-teknikker på forskellige problemer i den virkelige verden. Han har en PhD i elektroteknik fra Northwestern University.
 Qing Lan er softwareudviklingsingeniør i AWS. Han har arbejdet på adskillige udfordrende produkter i Amazon, herunder højtydende ML-inferensløsninger og højtydende logningssystem. Qings team lancerede med succes den første Billion-parameter model i Amazon Advertising med meget lav forsinkelse påkrævet. Qing har indgående viden om infrastrukturoptimering og Deep Learning acceleration.
Qing Lan er softwareudviklingsingeniør i AWS. Han har arbejdet på adskillige udfordrende produkter i Amazon, herunder højtydende ML-inferensløsninger og højtydende logningssystem. Qings team lancerede med succes den første Billion-parameter model i Amazon Advertising med meget lav forsinkelse påkrævet. Qing har indgående viden om infrastrukturoptimering og Deep Learning acceleration.
 Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker indbyggede algoritmer og hjælper med at udvikle machine learning algoritmer. Han fik sin ph.d. fra University of Illinois Urbana-Champaign. Han er en aktiv forsker i maskinlæring og statistisk inferens og har publiceret mange artikler i NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP konferencer.
Dr. Ashish Khetan er en Senior Applied Scientist med Amazon SageMaker indbyggede algoritmer og hjælper med at udvikle machine learning algoritmer. Han fik sin ph.d. fra University of Illinois Urbana-Champaign. Han er en aktiv forsker i maskinlæring og statistisk inferens og har publiceret mange artikler i NeurIPS, ICML, ICLR, JMLR, ACL og EMNLP konferencer.
 Dr. Li Zhang er en Principal Product Manager-Technical for Amazon SageMaker JumpStart og Amazon SageMaker indbyggede algoritmer, en tjeneste, der hjælper dataforskere og maskinlæringsudøvere med at komme i gang med at træne og implementere deres modeller, og bruger forstærkende læring med Amazon SageMaker. Hans tidligere arbejde som primær forskningsmedarbejder og mesteropfinder hos IBM Research har vundet test of time paper-prisen hos IEEE INFOCOM.
Dr. Li Zhang er en Principal Product Manager-Technical for Amazon SageMaker JumpStart og Amazon SageMaker indbyggede algoritmer, en tjeneste, der hjælper dataforskere og maskinlæringsudøvere med at komme i gang med at træne og implementere deres modeller, og bruger forstærkende læring med Amazon SageMaker. Hans tidligere arbejde som primær forskningsmedarbejder og mesteropfinder hos IBM Research har vundet test of time paper-prisen hos IEEE INFOCOM.
 Kamran Khan, Sr. Technical Business Development Manager for AWS Inferentina/Trianium hos AWS. Han har over ti års erfaring med at hjælpe kunder med at implementere og optimere deep learning-træning og slutningsarbejdsbelastninger ved hjælp af AWS Inferentia og AWS Trainium.
Kamran Khan, Sr. Technical Business Development Manager for AWS Inferentina/Trianium hos AWS. Han har over ti års erfaring med at hjælpe kunder med at implementere og optimere deep learning-træning og slutningsarbejdsbelastninger ved hjælp af AWS Inferentia og AWS Trainium.
 Joe Senerchia er Senior Product Manager hos AWS. Han definerer og bygger Amazon EC2-instanser til deep learning, kunstig intelligens og højtydende computerarbejdsbelastninger.
Joe Senerchia er Senior Product Manager hos AWS. Han definerer og bygger Amazon EC2-instanser til deep learning, kunstig intelligens og højtydende computerarbejdsbelastninger.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :har
- :er
- :ikke
- :hvor
- $OP
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15 %
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- evne
- I stand
- Om
- acceleration
- Acceptere
- acceptabel
- accepteret
- adgang
- nøjagtighed
- præcis
- anerkende
- ACM
- aktiv
- aktiviteter
- Adam
- tilpasse
- tilpasning
- tilpasset
- tilføje
- Desuden
- voksne
- fremskreden
- fremgang
- Reklame
- Efter
- Aftale
- AI
- AI modeller
- AI / ML
- algoritmer
- Alle
- tillade
- tilladt
- tillader
- også
- Amazon
- Amazon EC2
- Amazon svindeldetektor
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- blandt
- an
- analyse
- Ancient
- ,
- dyr
- Annoncere
- En anden
- enhver
- længere
- Apache
- fra hinanden
- anvendelig
- Anvendelse
- applikationer
- anvendt
- Anvendelse
- passende
- cirka
- arkitektur
- ER
- OMRÅDE
- områder
- argument
- Army
- ankom
- Kunst
- kunstig
- kunstig intelligens
- AS
- bistår
- Association
- At
- Ledsagere
- attributter
- Myndigheder
- forfattere
- Automatiseret
- tilgængelighed
- til rådighed
- undgå
- AWS
- AWS-inferens
- b
- baseret
- BE
- Beam
- fordi
- bliver
- været
- før
- være
- Tro
- jf. nedenstående
- mellem
- Beyond
- Største
- biologi
- Blog
- født
- både
- Boks
- bred
- bygge
- Bygning
- bygger
- indbygget
- virksomhed
- forretningsudvikling
- men
- .
- knapper
- by
- ringe
- kom
- CAN
- kapaciteter
- kapital
- kort
- gennemføres
- tilfælde
- tilfælde
- kategorier
- Boligtype
- udfordringer
- udfordrende
- lave om
- Chaos
- chatte
- chef
- valg
- Vælg
- vælge
- Christopher
- By
- civile
- klarhed
- klasser
- Classic
- klassificering
- ren
- Cloud
- klyngedannelse
- kode
- forkølelse
- udvalg
- Fælles
- Fællesskaber
- samfund
- selskab
- sammenlignet
- sammenligne
- sammenligninger
- Afsluttet
- Fuldender
- beregningsmæssige
- computing
- konklusion
- konkurrent
- Adfærd
- Konference
- konferencer
- Konfiguration
- Bekræfte
- Konsol
- indeholder
- Container
- indeholder
- indhold
- sammenhæng
- sammenhænge
- bidrag
- kontrol
- kontrol
- Koste
- kostbar
- Omkostninger
- land
- oprettet
- Crown
- afgørende
- kulturelle
- Kop
- kunde
- Kundeoplevelse
- Kunder
- tilpasning
- data
- datasæt
- Dato
- de
- årti
- december
- Dekodning
- dedikeret
- dyb
- dyb læring
- dybt
- Standard
- definerer
- Degree
- levere
- demokratisk
- demonstrere
- demonstreret
- demonstrerer
- Afhængigt
- afhænger
- indsætte
- indsat
- implementering
- implementering
- beskriver
- beskrivelse
- udpeget
- konstrueret
- detaljeret
- detaljer
- Detektion
- udvikle
- udvikling
- Udvikling
- Dialog
- DID
- forskel
- forskellige
- opdage
- opdagelse
- diskutere
- Skærm
- distribueret
- distribuerede systemer
- forskelligartede
- gør
- gør
- dukke
- domæne
- Domæner
- Dont
- ned
- hver
- Tidligt
- Optjening
- lette
- brugervenlighed
- editor
- Effektiv
- effektivitet
- effektiv
- enten
- valgt
- Elektroteknik
- Empire
- aktiveret
- muliggør
- muliggør
- ende
- ende til ende
- Endpoint
- ingeniør
- Engineering
- forbedre
- styrke
- nok
- sikrer
- Enterprise
- Enterprise Solutions
- Miljø
- miljømæssige
- lige
- Lig
- især
- Ether (ETH)
- evaluere
- evaluering
- indlysende
- eksempel
- eksempler
- ophidset
- Eksklusive
- eksisterende
- erfaring
- erfarne
- eksperimenterende
- udforske
- Udforskning
- udvinding
- Fall
- falsk
- hurtigere
- fyr
- festivaler
- få
- Fields
- File (Felt)
- Filer
- Arkivering
- finansielle
- finansielle tjenesteydelser
- Finde
- ende
- Fornavn
- Fleksibilitet
- Flyde
- Fokus
- fokuserer
- efter
- følger
- Til
- Tving
- format
- fundet
- Foundation
- Grundlagt
- Framework
- rammer
- bedrageri
- bedrageri afsløring
- fra
- funktion
- yderligere
- genereret
- genererer
- generation
- generative
- Generativ AI
- få
- Go
- Gud
- godt
- fik
- eksamen
- graf
- grafer
- større
- Grækenland
- Greedy
- græsk
- gruppe
- vejledning
- guitar
- havde
- Håndtering
- hænder
- Gem
- Have
- he
- sundhedspleje
- Held
- hjælpe
- hjælpsom
- hjælpe
- hjælper
- Høj
- Høj ydeevne
- højere
- højeste
- højdepunkter
- hiking
- ham
- hans
- besidder
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- menneskelig
- i
- IBM
- ICLR
- identificere
- id'er
- IEEE
- if
- ii
- Illinois
- implementering
- importere
- vigtigt
- Forbedre
- forbedret
- forbedringer
- in
- dybdegående
- omfatter
- omfatter
- Herunder
- Forøg
- angiver
- oplysninger
- informationsudtræk
- Infrastruktur
- infrastruktur
- indgang
- indgange
- instans
- forekomster
- anvisninger
- integreret
- Intelligens
- interesser
- grænseflade
- internationalt
- vejkryds
- ind
- involverede
- IT
- ITS
- james
- Job
- Karriere
- sluttede
- jonathan
- tidsskrift
- rejse
- jpg
- json
- lige
- Nøgle
- Kingdom
- kit
- Kit (SDK)
- viden
- kendt
- landing
- destinationsside
- Sprog
- stor
- storstilet
- Latency
- senere
- lanceret
- Love
- førende
- læring
- Længde
- li
- Licens
- licenser
- ligge
- Livet
- ligesom
- sandsynlighed
- Sandsynlig
- begrænsning
- Line (linje)
- linjer
- LINK
- Liste
- Børsnoterede
- Llama
- belastning
- lokale
- logning
- Lang
- Se
- elsker
- Lav
- lavere
- sænkning
- laveste
- maskine
- machine learning
- lavet
- Main
- lave
- Making
- leder
- styring
- Manan Shah
- mange
- Master
- maksimal
- Kan..
- betyder
- Mød
- medlem
- Meta
- metode
- metoder
- Mexico
- måske
- mike
- tankerne
- ML
- model
- modellering
- modeller
- modificeret
- ændre
- mere
- mest
- flyttet
- Musik
- skal
- navn
- Natural
- Naturligt sprog
- Natural Language Processing
- Naviger
- Navigation
- Behov
- behov
- NeurIPS
- Ny
- næste
- NLP
- Northwestern University
- notesbog
- notesbøger
- nu
- nummer
- numre
- objekt
- målsætninger
- of
- tilbyde
- tilbyde
- tilbud
- Tilbud
- tit
- Gammel
- ældre
- on
- engang
- ONE
- kun
- optimal
- optimering
- Optimer
- optimeret
- optimering
- Option
- or
- organisation
- Andet
- output
- uden for
- udestående
- i løbet af
- egen
- pakker
- side
- par
- parret
- brød
- Papir
- papirer
- Parallel
- parametre
- del
- især
- parter
- passage
- lidenskabelige
- forbi
- per
- udføre
- ydeevne
- periode
- Personlig
- phd
- pipeline
- perron
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Vær venlig
- Punkt
- politikker
- politik
- politisk
- pop-up
- Populær
- positiv
- muligheder
- mulig
- Indlæg
- vigtigste
- forud
- Precision
- forberede
- primære
- Main
- sandsynlighed
- problemer
- behandle
- forarbejdning
- Produkt
- produktchef
- Produkter
- proprietære
- give
- udbydere
- giver
- offentligt
- offentliggjort
- sætte
- Python
- pytorch
- kvalitet
- spørgsmål
- tilfældighed
- nå
- når
- Læs
- klar
- ægte
- virkelige verden
- realtid
- grund
- årsager
- optegnelser
- henvise
- henvisninger
- flygtninge
- frigivet
- relevans
- relevant
- flyttet
- forblevet
- resterne
- gentaget
- repetitiv
- erstatte
- Repository
- repræsentere
- repræsenterer
- anmode
- anmodninger
- påkrævet
- forskning
- forsker
- Ressourcer
- henholdsvis
- svar
- reaktioner
- ansvarlige
- resulterer
- Resultater
- afkast
- gennemgå
- gennemgå
- robust
- Rullende
- Royal
- Kør
- Rusland
- sagemaker
- Skalerbarhed
- skalerbar
- Scale
- scenarier
- Videnskabsmand
- forskere
- scripts
- SDK
- Søg
- søgning
- SEK
- SEC arkivering
- Anden
- Sektion
- sikkerhed
- se
- senior
- sendt
- dømme
- stemningen
- adskille
- Sequence
- Series
- Serie A
- tjeneste
- Tjenester
- sæt
- indstilling
- indstillinger
- flere
- Kort
- bør
- Vis
- vist
- Shows
- signifikant
- Simpelt
- siden
- enkelt
- Størrelse
- uddrag
- So
- Samfund
- Software
- softwareudvikling
- softwareudviklingssæt
- software Engineering
- løsninger
- Løsninger
- Løsning
- nogle
- dens
- Kilde
- Syd
- sovjetiske
- Space
- specialiserede
- specifikke
- specifikt
- specificitet
- specificeret
- udgifterne
- delt
- Personale
- starte
- påbegyndt
- Tilstand
- statistiske
- Status
- styretøj
- Trin
- Steps
- stopper
- opbevaring
- struktureret
- Studerende
- studeret
- undersøgelser
- Studio
- Succesfuld
- sådan
- support
- Understøttet
- sikker
- Schweiz
- systemet
- Systemer
- bord
- skræddersyet
- Opgaver
- opgaver
- Undervisning
- hold
- Teknisk
- teknik
- teknikker
- Teknologier
- skabelon
- tennessee
- vilkår
- prøve
- tekst
- Tekstklassificering
- tekstgenerering
- end
- at
- Området
- Hovedstaden
- Teater
- deres
- Them
- derefter
- Der.
- Disse
- de
- Tænker
- tredjepart
- denne
- dem
- Gennem
- kapacitet
- Tigers
- tid
- gange
- til
- i dag
- token
- Tokens
- værktøjer
- I alt
- Tog
- uddannet
- Kurser
- transformer
- Oversættelse
- sand
- prøv
- tvilling
- to
- typen
- ui
- under
- underliggende
- enestående
- Universiteter
- universitet
- indtil
- Opdatering
- opdateringer
- Brug
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- bruger
- ved brug af
- udnytter
- Usbekistan
- validering
- værdi
- række
- forskellige
- udgave
- meget
- via
- Specifikation
- vin
- visuel
- gå
- ønsker
- krig
- var
- måder
- we
- web
- webservices
- web-baseret
- gik
- var
- hvornår
- som
- mens
- WHO
- vilje
- VIN
- med
- Vandt
- ord
- ord
- Arbejde
- arbejdede
- arbejder
- virker
- værksted
- world
- ville
- skriver
- år
- Yoga
- dig
- Din
- ungdom
- zephyrnet
- Zeus