I dagens verden administrerer kunder enorme mængder data i deres Amazon Simple Storage Service (Amazon S3) datasøer, som kræver indviklede datapipelines for løbende at forstå ændringerne i datalayoutet og gøre dem tilgængelige for forbrugende systemer. AWS Lim crawlere giver en ligetil måde at katalogisere data i AWS Glue Data Catalog, der fjerner de tunge løft, når det kommer til skemastyring og dataklassificering. AWS Glue-crawlere udtrækker dataskemaet og partitionerne fra Amazon S3 for automatisk at udfylde datakataloget og holde metadataene aktuelle.
Men med data, der vokser eksponentielt over tid, kan antallet af partitioner i en given tabel vokse betydeligt. Fordi analysetjenester som Amazonas Athena forespørger i en tabel, der indeholder millioner af partitioner, øges den tid, der er nødvendig for at hente partitionen, og det kan få forespørgslens køretid til at øges.
I dag er AWS Glue-crawler-understøttelse blevet udvidet til automatisk at tilføje partitionsindekser for nyligt opdagede tabeller for at optimere forespørgselsbehandlingen på det partitionerede datasæt. Når crawleren nu opretter en ny datakatalogtabel under en crawlerkørsel, opretter den som standard også et partitionsindeks med den største permutation af alle numeriske og strengtype-partitionskolonner som nøgler. Datakataloget opretter derefter et søgbart indeks baseret på disse nøgler, hvilket reducerer den tid, der kræves til at hente og filtrere partitionsmetadata på tabeller med millioner af partitioner. Oprettelsen af partitionsindekser gavner de analytiske arbejdsbelastninger, der kører på Athena, Amazon EMR, Amazon Redshift Spectrum, og AWS Lim.
I dette indlæg beskriver vi, hvordan du opretter partitionsindekser med en AWS Glue-crawler og sammenligner forbedringen af forespørgselsydeevnen, når du får adgang til de gennemgåede data med og uden et partitionsindeks fra Athena.
Løsningsoversigt
Vi bruger en AWS CloudFormation skabelon til at skabe vores løsningsressourcer. I de følgende trin demonstrerer vi, hvordan man konfigurerer AWS Glue-crawleren til at oprette et partitionsindeks ved hjælp af enten AWS Glue-konsollen eller AWS kommandolinjegrænseflade (AWS CLI). Derefter sammenligner vi forbedringerne af forespørgselsydeevnen ved hjælp af Athena.
Forudsætninger
For at følge med i dette indlæg skal du have adgang til en AWS identitets- og adgangsstyring (IAM) administratorrolle til at oprette ressourcer ved hjælp af AWS CloudFormation.
Konfigurer dine løsningsressourcer
CloudFormation-skabelonen genererer følgende ressourcer:
- IAM roller og politikker
- En AWS Glue-database til at holde skemaet
- En AWS Glue-crawler, der peger på et meget opdelt datasæt
- En Athena-arbejdsgruppe og -spand til at gemme forespørgselsresultater
Udfør følgende trin for at konfigurere løsningsressourcerne:
- Log ind på AWS Management Console som IAM-administrator.
- Vælg Start Stack for at implementere CloudFormation-skabelonen:

- Til Databasenavn, bevar standard
blog_partition_index_crawlerdb.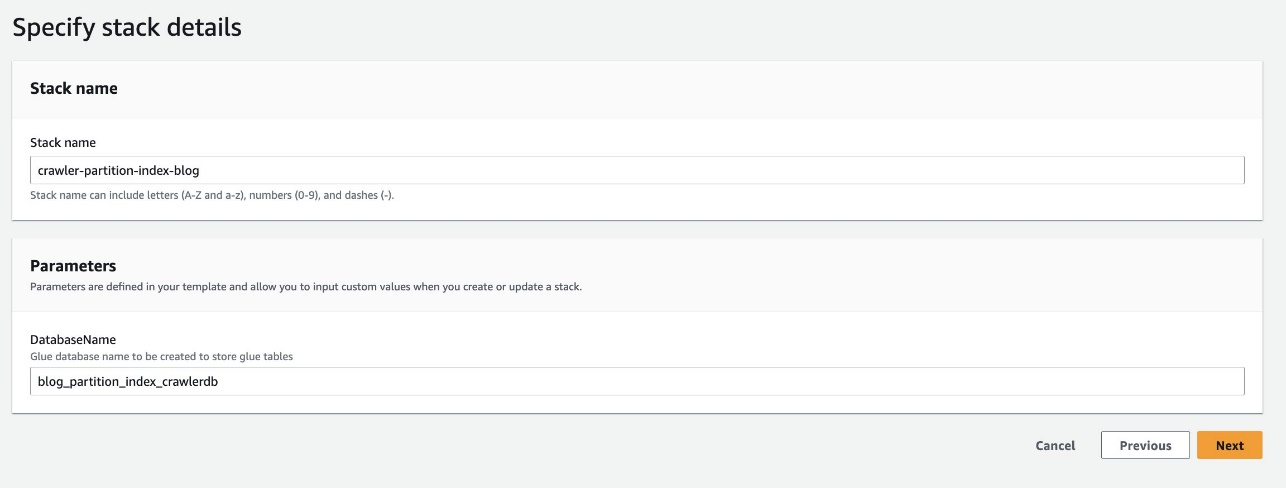
- Vælg Næste.
- Gennemgå detaljerne på den sidste side, og vælg Jeg anerkender, at AWS CloudFormation kan skabe IAM-ressourcer.
- Vælg Opret stak.
- Når stakken er færdig, skal du på AWS CloudFormation-konsollen navigere til Udgange fanen på stakken.
- Notér værdier på
DatabaseName,GlueCrawlerName.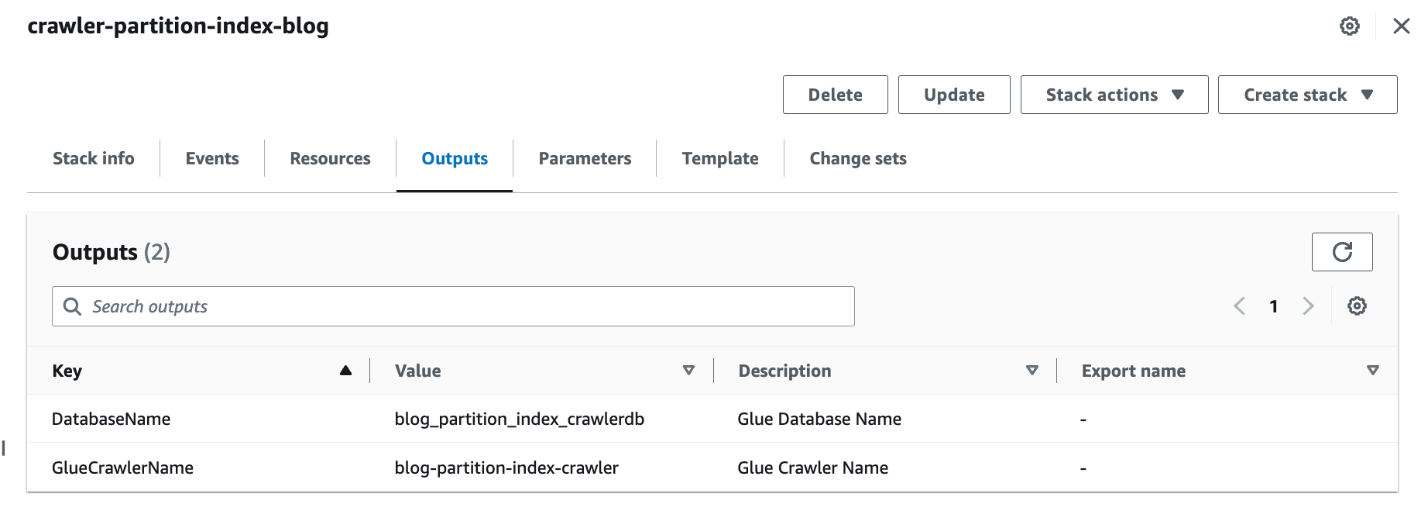
Nogle af de ressourcer, som denne stak implementerer, medfører omkostninger, når de er i brug.
Rediger og kør AWS Glue-crawleren
For at konfigurere og køre AWS Glue-crawleren skal du udføre følgende trin:
- På AWS Glue-konsollen skal du vælge Crawlere i navigationsruden.
- Find den
crawler blog-partition-index-crawlerOg vælg Redigere.
- I Indstil output og planlægning afsnit under Avancerede indstillinger, Vælg Opret partitionsindekser automatisk.
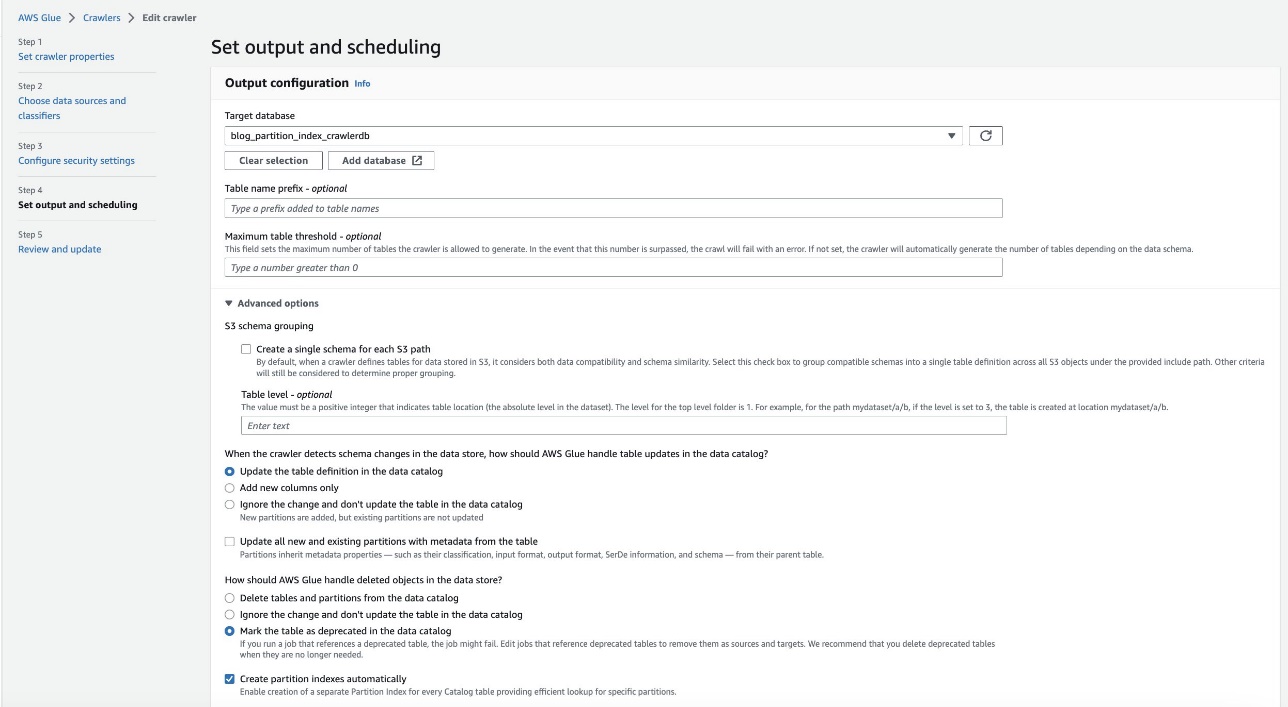
- Gennemgå og opdater webcrawlerindstillingerne.
Alternativt kan du konfigurere din webcrawler ved hjælp af AWS CLI (angiv din IAM-rolle og region):
- Kør nu crawleren og bekræft, at crawlerkørslen er fuldført.
Dette er meget opdelt datasæt og vil tage cirka 90 minutter at fuldføre.
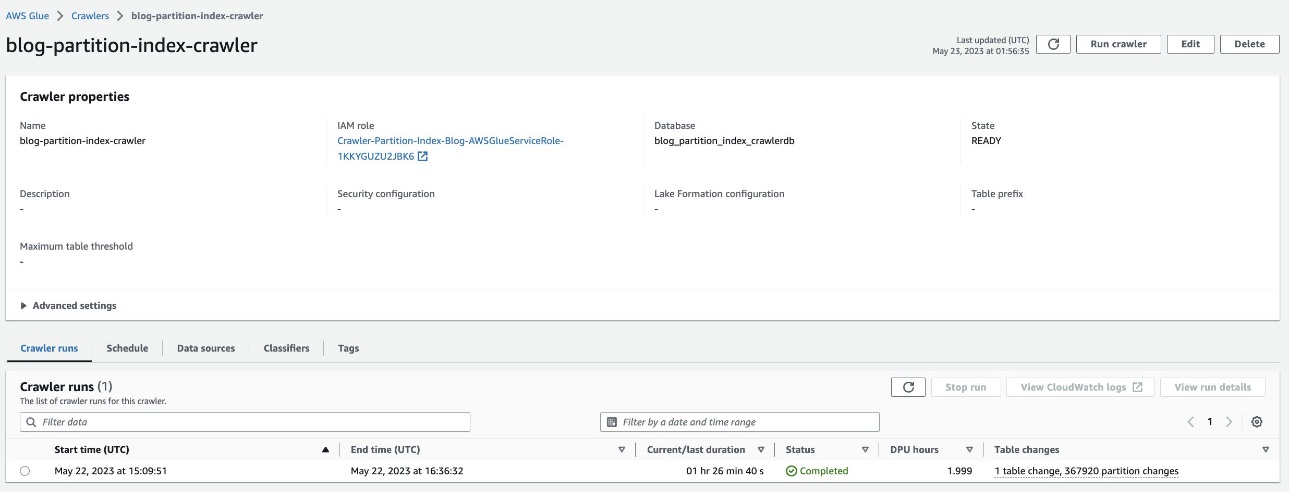
Bekræft den opdelte tabel
I AWS Glue-databasen blog_partition_index_crawlerdb, verificere, at tabellen highly_partitioned_table oprettes.
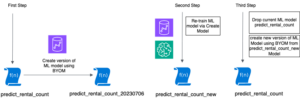
Som standard bestemmer webcrawleren et indeks baseret på den største permutation af partitionskolonner med gyldige kolonnetyper i samme rækkefølge af partitionskolonner, som enten er numeriske eller strenge. For tabellen oprettet af webcrawleren (highly_partitioned_table), har vi partitionskolonner year (snor), month (snor), day (streng), og hour (snor).
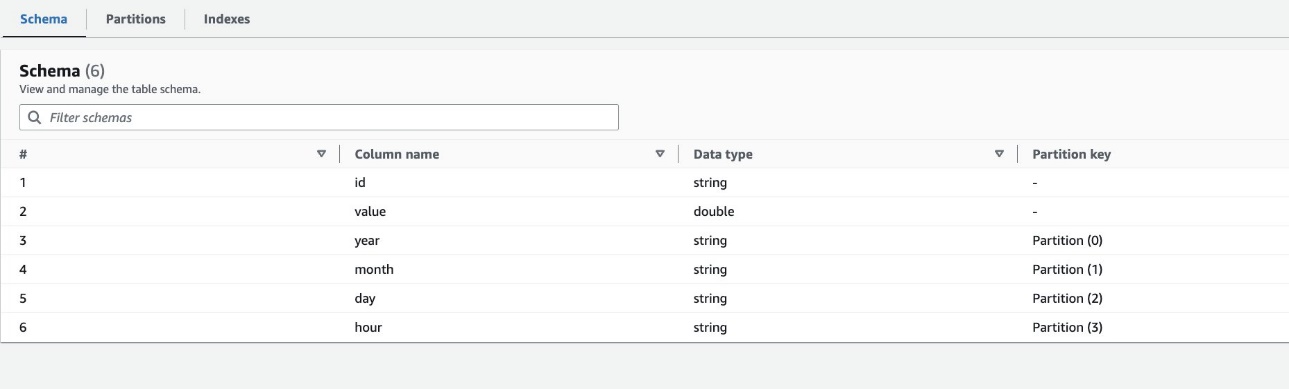
Baseret på denne definition oprettede webcrawleren et indeks over permutationen af år, måned, dag og time. Webcrawleren oprettede indekserne med præfiks crawler_ på ethvert partitionsindeks, der er oprettet som standard.
Bekræft det samme ved at navigere til tabellen highly_partitioned_table på AWS Lim-konsollen og vælge Indexes fane.
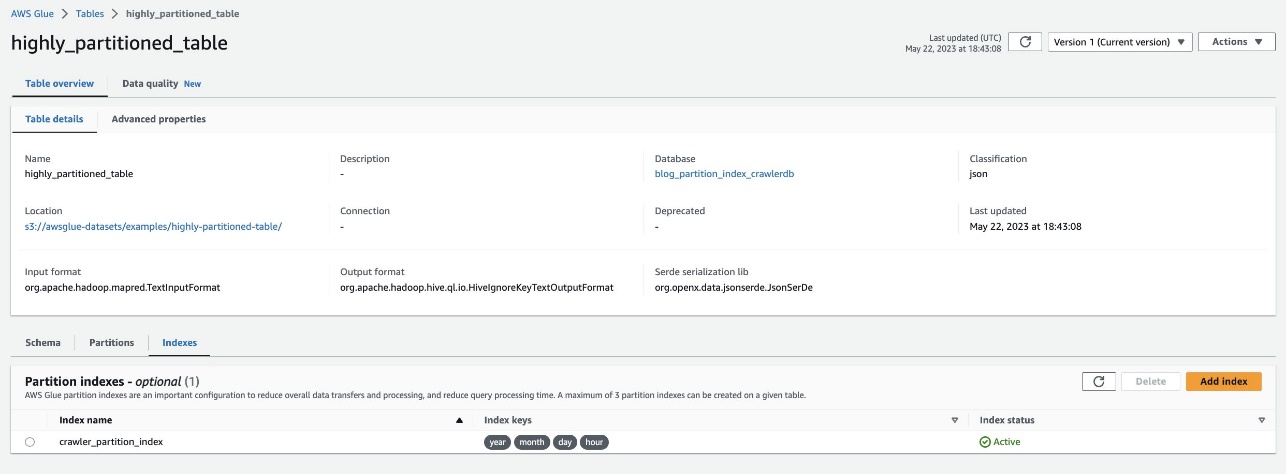
Webcrawleren var i stand til at gennemgå S3-datakilden og udfylde partitionsindekserne for tabellen.
Sammenlign forbedringerne af forespørgselsydeevnen ved hjælp af Athena
Først forespørger vi tabellen i Athena uden at bruge partitionsindekset. For at verificere tabellerne ved hjælp af Athena skal du udføre følgende trin:
- Vælg på Athena-konsollen
crawler-primary-workgroupsom Athena-arbejdsgruppen og vælg Anerkende.
- Kør følgende forespørgsel:
Følgende skærmbillede viser, at forespørgslen tog cirka 32 sekunder uden filtrering aktiveret ved hjælp af partitionsindekset.
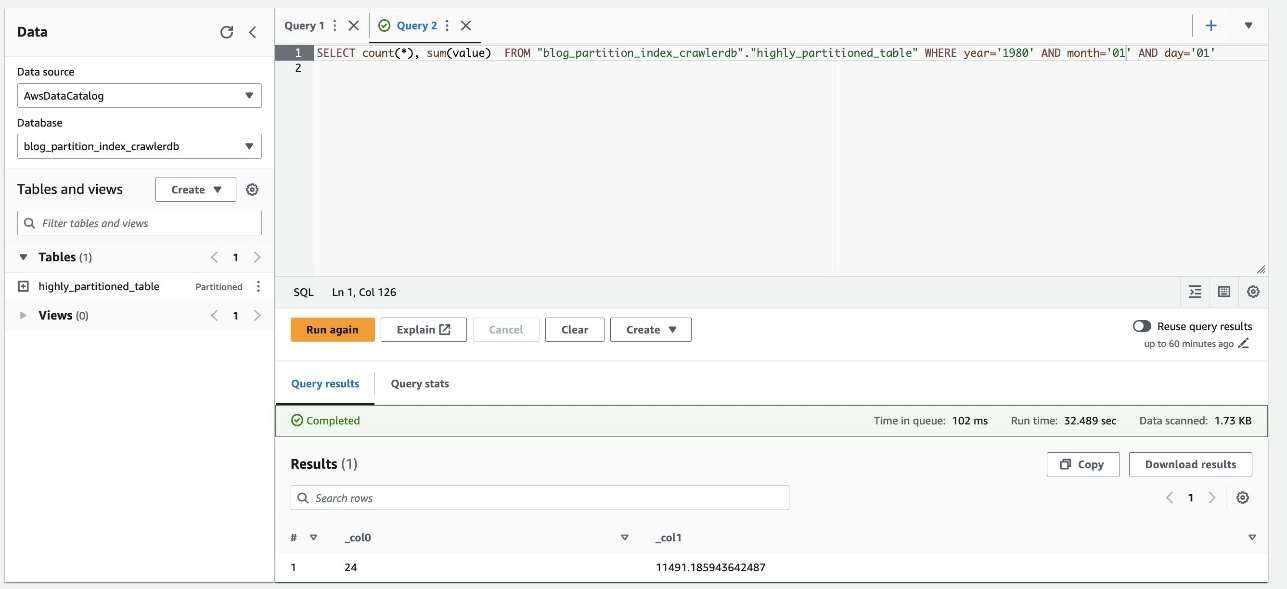
- Nu aktiverer vi partitionsindekset på Athena-forespørgslen:
- Kør følgende forespørgsel igen, og noter kørselstiden:
Følgende skærmbillede viser, at forespørgslen kun tog 700 millisekunder, hvilket er meget hurtigere med filtrering aktiveret ved hjælp af partitionsindekset.
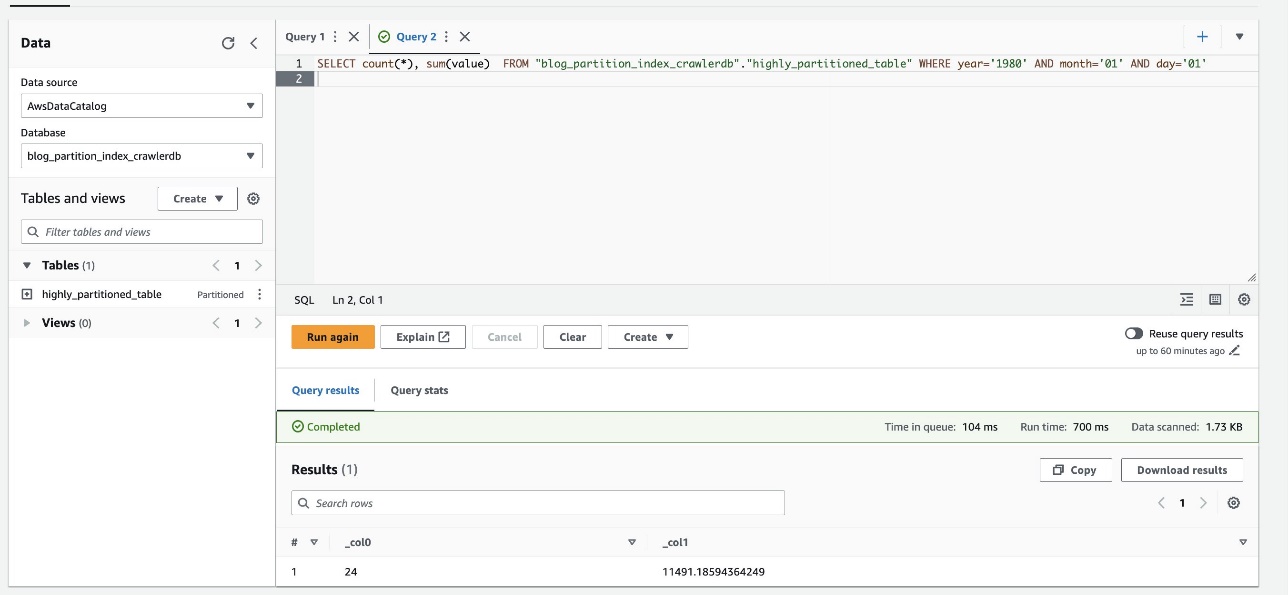
Ryd op
For at undgå uønskede debiteringer på din AWS-konto kan du slette AWS-ressourcerne:
- Log ind på CloudFormation-konsollen som den IAM-administrator, der blev brugt til at oprette CloudFormation-stakken.
- Slet den CloudFormation-stak, du har oprettet.
Konklusion
I dette indlæg forklarede vi, hvordan man konfigurerer en AWS-crawler til at oprette partitionsindekser og sammenlignede forespørgselsydeevnen ved adgang til dataene med indekser fra Athena.
Hvis der ikke findes partitionsindekser på tabellen, indlæser AWS Glue alle tabellens partitioner og filtrerer derefter de indlæste partitioner, hvilket resulterer i ineffektiv hentning af metadata. Analysetjenester som Redshift Spectrum, Amazon EMR og AWS Glue ETL Spark DataFrames kan nu bruge indekser til at hente partitioner, hvilket resulterer i betydelig forespørgselsydeevne.
For mere information om partitionsindekser og forespørgselsydeevne på tværs af forskellige analytiske motorer, se Forbedre Amazon Athena-forespørgselsydeevnen ved hjælp af AWS Glue Data Catalog-partitionsindekser , Forbedre forespørgselsydeevne ved hjælp af AWS Glue-partitionsindekser.
Særlig tak til alle, der har bidraget til lanceringen af denne crawler-funktion: Yuhang Chen, Kyle Duong og Mita Gavade.
Om forfatterne
 Srividya Parthasarathy er Senior Big Data Architect på AWS Lake Formation-teamet. Hun nyder at bygge data mesh-løsninger og dele dem med fællesskabet.
Srividya Parthasarathy er Senior Big Data Architect på AWS Lake Formation-teamet. Hun nyder at bygge data mesh-løsninger og dele dem med fællesskabet.
 Sandeep Adwankar er Senior Technical Product Manager hos AWS. Baseret i California Bay-området arbejder han med kunder over hele kloden for at omsætte forretningsmæssige og tekniske krav til produkter, der sætter kunder i stand til at forbedre, hvordan de administrerer, sikrer og får adgang til data.
Sandeep Adwankar er Senior Technical Product Manager hos AWS. Baseret i California Bay-området arbejder han med kunder over hele kloden for at omsætte forretningsmæssige og tekniske krav til produkter, der sætter kunder i stand til at forbedre, hvordan de administrerer, sikrer og får adgang til data.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- EVM Finans. Unified Interface for Decentralized Finance. Adgang her.
- Quantum Media Group. IR/PR forstærket. Adgang her.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :har
- :er
- :hvor
- $OP
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- I stand
- adgang
- Adgang
- Konto
- anerkende
- tværs
- tilføje
- admin
- igen
- Alle
- sammen
- også
- Amazon
- Amazonas Athena
- Amazon EMR
- Amazon Web Services
- beløb
- an
- Analytisk
- analytics
- ,
- enhver
- cirka
- ER
- OMRÅDE
- omkring
- AS
- At
- automatisk
- til rådighed
- undgå
- AWS
- AWS CloudFormation
- AWS Lim
- AWS søformation
- baseret
- Bugt
- fordi
- været
- fordele
- Big
- Big data
- Bygning
- virksomhed
- by
- california
- CAN
- katalog
- Årsag
- Ændringer
- afgifter
- chen
- Vælg
- vælge
- klassificering
- Kolonne
- Kolonner
- kommer
- samfund
- sammenligne
- sammenlignet
- fuldføre
- Konsol
- kontinuerligt
- bidrog
- Omkostninger
- crawler
- skabe
- oprettet
- skaber
- Oprettelse af
- skabelse
- Nuværende
- Kunder
- data
- dataadgang
- Data Lake
- Database
- dag
- Standard
- demonstrere
- indsætte
- udruller
- beskrive
- detaljer
- bestemmer
- opdaget
- ned
- i løbet af
- effektivt
- enten
- muliggøre
- aktiveret
- Motorer
- Ether (ETH)
- alle
- udvidet
- forklarede
- eksponentielt
- ekstrakt
- udtrække dataene
- hurtigere
- Feature
- filtrere
- filtrering
- Filtre
- endelige
- følger
- efter
- Til
- formation
- fra
- genererer
- given
- kloden
- Grow
- Dyrkning
- Have
- he
- tunge
- tunge løft
- stærkt
- hold
- time
- Hvordan
- How To
- HTML
- http
- HTTPS
- IAM
- Identity
- Forbedre
- forbedringer
- in
- Forøg
- Stigninger
- indeks
- indekser
- ineffektiv
- oplysninger
- ind
- IT
- jpg
- Holde
- holde
- nøgler
- sø
- største
- lancere
- Layout
- løft
- ligesom
- Line (linje)
- belastninger
- lave
- administrere
- ledelse
- leder
- mesh
- Metadata
- måske
- millioner
- minutter
- Måned
- mere
- meget
- skal
- Naviger
- navigering
- Navigation
- behov
- Ny
- nyligt
- ingen
- nu
- nummer
- of
- on
- kun
- Optimer
- or
- ordrer
- vores
- output
- i løbet af
- side
- brød
- sti
- ydeevne
- plato
- Platon Data Intelligence
- PlatoData
- Indlæg
- præsentere
- forarbejdning
- Produkt
- produktchef
- Produkter
- give
- reducere
- region
- påkrævet
- Krav
- Kræver
- Ressourcer
- resulterer
- Resultater
- roller
- roller
- Kør
- kører
- samme
- sekunder
- Sektion
- sikker
- senior
- Tjenester
- sæt
- indstillinger
- deling
- hun
- Shows
- signifikant
- betydeligt
- Simpelt
- løsninger
- Løsninger
- Kilde
- Spark
- Spectrum
- stable
- Steps
- opbevaring
- butik
- ligetil
- String
- Succesfuld
- support
- Systemer
- bord
- Tag
- hold
- Teknisk
- skabelon
- tak
- at
- deres
- Them
- derefter
- Disse
- de
- denne
- tid
- til
- nutidens
- tog
- Oversætte
- sand
- typen
- typer
- under
- forstå
- uønsket
- Opdatering
- brug
- anvendte
- ved brug af
- udnytte
- værdi
- Værdier
- forskellige
- Vast
- verificere
- udgave
- var
- Vej..
- we
- web
- webservices
- hvornår
- som
- WHO
- vilje
- med
- uden
- arbejdsgruppe
- virker
- world
- yaml
- år
- dig
- Din
- zephyrnet