
Billede fra forfatter | Bing Image Creator
dolly 2.0 er en open source, instruktionsfølt, stor sprogmodel (LLM), der blev finjusteret på et menneskeskabt datasæt. Det kan bruges til både forsknings- og kommercielle formål.
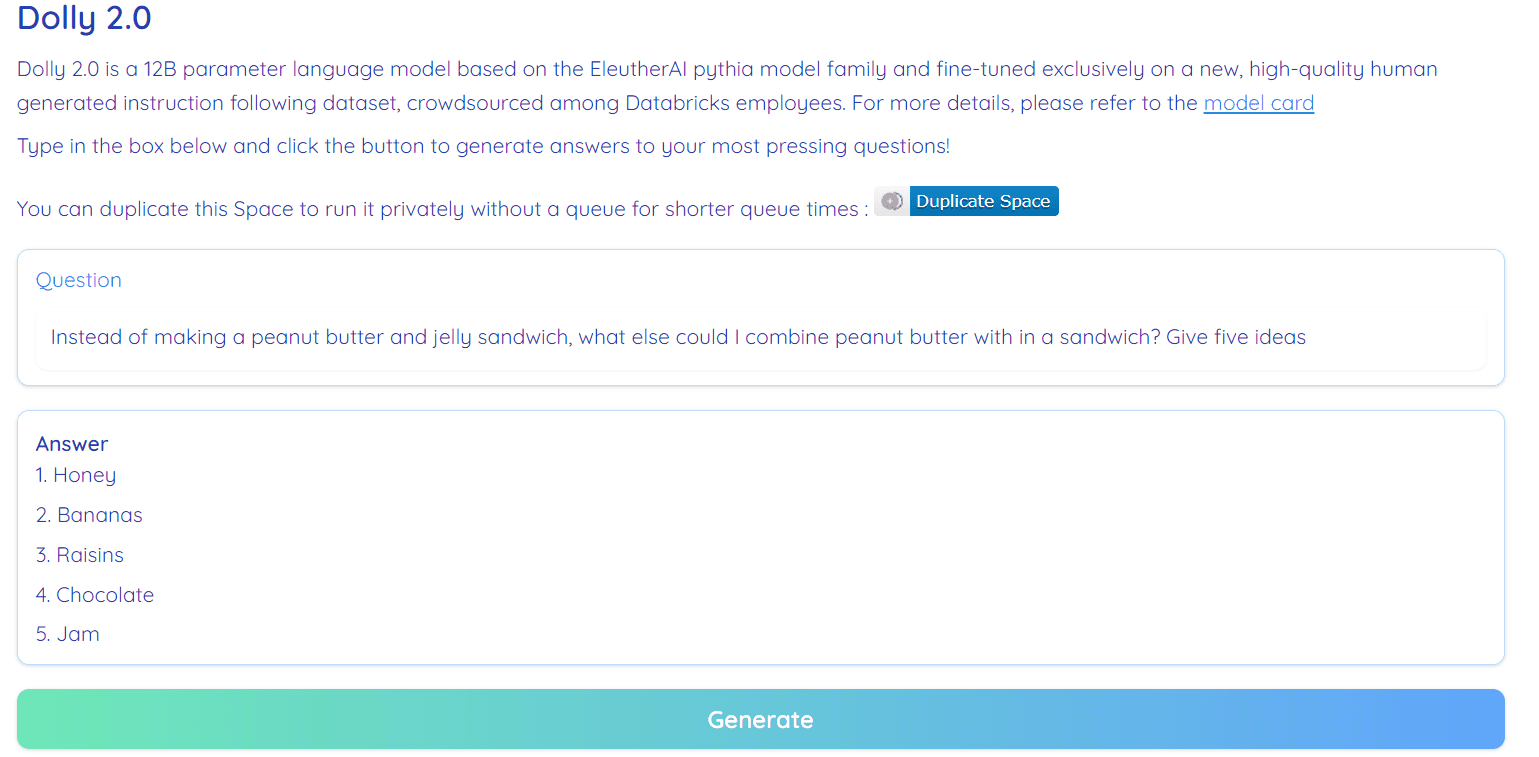
Billede fra Hugging Face Space af RamAnanth1
Tidligere udgav Databricks-teamet dolly 1.0, LLM, som udviser ChatGPT-lignende instruktion efter evner og koster mindre end $30 at træne. Det brugte Stanford Alpaca-teamdatasættet, som var under en begrænset licens (kun forskning).
Dolly 2.0 har løst dette problem ved at finjustere 12B parameter sprogmodellen (Pythia) på en menneskeskabt instruktion af høj kvalitet i følgende datasæt, som blev mærket af en Datbricks-medarbejder. Både model og datasæt er tilgængelige til kommerciel brug.
Dolly 1.0 blev trænet på et Stanford Alpaca-datasæt, som blev oprettet ved hjælp af OpenAI API. Datasættet indeholder output fra ChatGPT og forhindrer nogen i at bruge det til at konkurrere med OpenAI. Kort sagt kan du ikke bygge en kommerciel chatbot eller sprogapplikation baseret på dette datasæt.
De fleste af de seneste modeller udgivet i de sidste par uger led af de samme problemer, f.eks Alpaca, Koala, GPT4Allog Vicuna. For at komme rundt skal vi skabe nye datasæt af høj kvalitet, som kan bruges til kommerciel brug, og det er, hvad Databricks-teamet har gjort med databricks-dolly-15k-datasættet.
Det nye datasæt indeholder 15,000 højkvalitets menneskemærkede prompt/svar-par, der kan bruges til at designe instruktionsjustering af store sprogmodeller. Det databricks-dolly-15k datasæt følger med Creative Commons Attribution-ShareAlike 3.0 Unported-licens, som giver enhver mulighed for at bruge den, ændre den og oprette en kommerciel applikation på den.
Hvordan oprettede de databricks-dolly-15k-datasættet?
OpenAI-forskningen papir angiver, at den originale InstructGPT-model blev trænet på 13,000 prompter og svar. Ved at bruge disse oplysninger begyndte Databricks-teamet at arbejde på det, og det viser sig, at det var en vanskelig opgave at generere 13 spørgsmål og svar. De kan ikke bruge syntetiske data eller AI-generative data, og de skal generere originale svar på hvert spørgsmål. Det er her, de har besluttet at bruge 5,000 ansatte hos Databricks til at skabe menneskeskabte data.
Databricks har oprettet en konkurrence, hvor de 20 bedste etiketter vil modtage en stor pris. I denne konkurrence deltog 5,000 Databricks-medarbejdere, som var meget interesserede i LLM'er
Dolly-v2-12b er ikke en state-of-the-art model. Den klarer sig dårligere end dolly-v1-6b i nogle evalueringsbenchmarks. Det kan skyldes sammensætningen og størrelsen af de underliggende finjusteringsdatasæt. Dolly-modelfamilien er under aktiv udvikling, så du vil muligvis se en opdateret version med bedre ydeevne i fremtiden.
Kort sagt har dolly-v2-12b-modellen klaret sig bedre end EleutherAI/gpt-neox-20b og EleutherAI/pythia-6.9b.

Billede fra Gratis Dolly
Dolly 2.0 er 100 % open source. Den leveres med træningskode, datasæt, modelvægte og inferenspipeline. Alle komponenterne er velegnede til kommerciel brug. Du kan prøve modellen på Hugging Face Spaces Dolly V2 af RamAnanth1.
Billede fra Knusende ansigt
Resource:
Dolly 2.0 Demo: Dolly V2 af RamAnanth1
Abid Ali Awan (@1abidaliawan) er en certificeret dataforsker, der elsker at bygge maskinlæringsmodeller. I øjeblikket fokuserer han på indholdsskabelse og skriver tekniske blogs om maskinlæring og datavidenskabsteknologier. Abid har en kandidatgrad i teknologiledelse og en bachelorgrad i telekommunikationsingeniør. Hans vision er at bygge et AI-produkt ved hjælp af et grafisk neuralt netværk til studerende, der kæmper med psykisk sygdom.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :har
- :er
- :ikke
- $OP
- 000
- 1
- 20
- a
- evne
- aktiv
- AI
- Alle
- tillader
- alternativ
- an
- ,
- svar
- nogen
- api
- Anvendelse
- ER
- omkring
- forfatter
- til rådighed
- tildeling
- baseret
- BE
- Benchmarks
- Berkeley
- Bedre
- Big
- Bing
- blogs
- både
- bygge
- Bygning
- by
- CAN
- kan ikke
- Certificeret
- chatbot
- ChatGPT
- kode
- kommerciel
- Commons
- konkurrere
- komponenter
- indeholder
- indhold
- indholdsskabelse
- konkurrence
- Omkostninger
- skabe
- oprettet
- skabelse
- For øjeblikket
- data
- datalogi
- dataforsker
- Databrikker
- datasæt
- besluttede
- Degree
- Demo
- Design
- Udvikling
- DID
- svært
- dukke
- Medarbejder
- medarbejdere
- Engineering
- evaluering
- Hver
- udstillinger
- Ansigtet
- familie
- få
- fokusering
- efter
- Til
- fra
- fremtiden
- generere
- generere
- generative
- få
- graf
- Graf neuralt netværk
- Have
- he
- høj kvalitet
- besidder
- HTML
- HTTPS
- sygdom
- billede
- in
- oplysninger
- interesseret
- spørgsmål
- spørgsmål
- IT
- jpg
- KDnuggets
- Sprog
- stor
- Efternavn
- seneste
- læring
- Licens
- ligesom
- maskine
- machine learning
- ledelse
- Master
- mentale
- Psykisk sygdom
- måske
- model
- modeller
- ændre
- Behov
- netværk
- Neural
- neurale netværk
- Ny
- of
- on
- kun
- åbent
- open source
- OpenAI
- or
- original
- output
- par
- parameter
- deltog
- ydeevne
- pipeline
- plato
- Platon Data Intelligence
- PlatoData
- Produkt
- professionel
- formål
- spørgsmål
- Spørgsmål
- frigivet
- forskning
- løst
- begrænset
- s
- samme
- Videnskab
- Videnskabsmand
- sæt
- Kort
- Størrelse
- So
- nogle
- Kilde
- Space
- rum
- Stanford
- påbegyndt
- state-of-the-art
- Stater
- Kæmper
- Studerende
- egnede
- syntetisk
- syntetiske data
- Opgaver
- hold
- Teknisk
- Teknologier
- Teknologier
- telekommunikation
- end
- at
- Fremtiden
- de
- denne
- til
- top
- Tog
- uddannet
- Kurser
- under
- underliggende
- opdateret
- brug
- anvendte
- ved brug af
- udgave
- vision
- var
- we
- uger
- var
- Hvad
- som
- WHO
- med
- Arbejde
- ville
- skrivning
- dig
- zephyrnet










