Amazon rødforskydning er et fuldt administreret og petabyte-skala cloud data warehouse, der bruges af titusindvis af kunder til at behandle exabytes af data hver dag for at drive deres analytiske arbejdsbyrde. Du kan strukturere dine data, måle forretningsprocesser og hurtigt få værdifuld indsigt ved at bruge en dimensionel model. Amazon Redshift giver indbyggede funktioner til at accelerere processen med modellering, orkestrering og rapportering fra en dimensionel model.
I dette indlæg diskuterer vi, hvordan man implementerer en dimensionel model, specifikt Kimball metode. Vi diskuterer implementeringsdimensioner og fakta inden for Amazon Redshift. Vi viser, hvordan man udfører extract, transform and load (ELT), en integrationsproces fokuseret på at få de rå data fra en datasø ind i et iscenesættelseslag for at udføre modelleringen. Samlet set vil indlægget give dig en klar forståelse af, hvordan du bruger dimensionel modellering i Amazon Redshift.
Løsningsoversigt
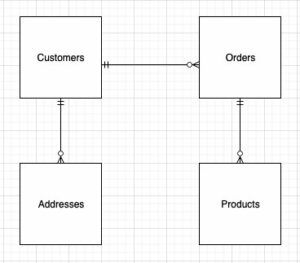
Følgende diagram illustrerer løsningsarkitekturen.

I de følgende afsnit diskuterer og demonstrerer vi først de vigtigste aspekter af den dimensionelle model. Derefter opretter vi en datamart ved hjælp af Amazon Redshift med en dimensionel datamodel inklusive dimensions- og faktatabeller. Data indlæses og iscenesættes ved hjælp af COPY kommandoen indlæses dataene i dimensionerne ved hjælp af FUSIONERE udsagn, og fakta vil blive sammenføjet til de dimensioner, hvorfra indsigt er afledt. Vi planlægger indlæsningen af dimensionerne og fakta ved hjælp af Amazon Redshift Query Editor V2. Til sidst bruger vi Amazon QuickSight at få indsigt i de modellerede data i form af et QuickSight dashboard.
Til denne løsning bruger vi et eksempeldatasæt (normaliseret) leveret af Amazon Redshift til billetsalg til begivenheder. Til dette indlæg har vi indsnævret datasættet for enkelheds- og demonstrationsformål. Følgende tabeller viser eksempler på data for billetsalg og spillesteder.


Ifølge Kimball dimensionel modellering metode, er der fire vigtige trin i design af en dimensionel model:
- Identificer forretningsprocessen.
- Erklære kernen af dine data.
- Identificer og implementer dimensionerne.
- Identificer og implementer fakta.
Derudover tilføjer vi et femte trin til demonstrationsformål, som er at rapportere og analysere forretningsbegivenheder.
Forudsætninger
For denne gennemgang skal du have følgende forudsætninger:
Identificer forretningsprocessen
Kort sagt er identifikation af forretningsprocessen at identificere en målbar hændelse, der genererer data i en organisation. Normalt har virksomheder en form for operationelt kildesystem, der genererer deres data i dets råformat. Dette er et godt udgangspunkt for at identificere forskellige kilder til en forretningsproces.
Forretningsprocessen fortsættes derefter som en datamart i form af dimensioner og fakta. Ser vi på vores eksempeldatasæt nævnt tidligere, kan vi tydeligt se, at forretningsprocessen er salget for en given begivenhed.
En almindelig fejl er at bruge afdelinger i en virksomhed som forretningsproces. Dataene (forretningsprocessen) skal integreres på tværs af forskellige afdelinger, i dette tilfælde kan marketing få adgang til salgsdataene. Det er vigtigt at identificere den korrekte forretningsproces – hvis dette trin bliver forkert, kan det påvirke hele datamarkedet (det kan forårsage, at kornet bliver duplikeret og ukorrekte målinger på de endelige rapporter).
Erklære kernen af dine data
At erklære kornet er handlingen med entydigt at identificere en post i din datakilde. Kornet bruges i faktatabellen til præcist at måle dataene og gøre dig i stand til at rulle yderligere op. I vores eksempel kunne dette være en linjepost i salgsforretningsprocessen.
I vores use case kan et salg entydigt identificeres ved at se på transaktionstidspunktet, hvor salget fandt sted; dette vil være det mest atomare niveau.

Identificer og implementer dimensionerne
Din dimensionstabel beskriver din faktatabel og dens attributter. Når du identificerer den beskrivende kontekst af din forretningsproces, gemmer du teksten i en separat tabel, mens du holder faktatabellen i tankerne. Når du forbinder dimensionstabellen med faktatabellen, bør der kun være en enkelt række tilknyttet faktatabellen. I vores eksempel bruger vi følgende tabel til at blive adskilt i en dimensionstabel; disse felter beskriver de fakta, som vi vil måle.
Når du designer strukturen af den dimensionelle model (skemaet), kan du enten oprette en stjerne or snefnug skema. Strukturen skal være tæt på linje med forretningsprocessen; derfor passer et stjerneskema bedst til vores eksempel. Følgende figur viser vores Entity Relationship Diagram (ERD).

I de følgende afsnit beskriver vi trinene til implementering af dimensionerne.
Iscenesætter kildedataene
Før vi kan oprette og indlæse dimensionstabellen, har vi brug for kildedata. Derfor iscenesætter vi kildedataene til en iscenesættelse eller midlertidig tabel. Dette omtales ofte som iscenesættelseslag, som er den rå kopi af kildedataene. For at gøre dette i Amazon Redshift bruger vi COPY kommando for at indlæse dataene fra dimensional-modeling-in-amazon-redshift offentlige S3-spand placeret på us-east-1 Område. Bemærk, at COPY-kommandoen bruger en AWS identitets- og adgangsstyring (IAM) rolle med adgang til Amazon S3. Rollen skal være knyttet til klyngen. Udfør følgende trin for at iscenesætte kildedataene:
- Opret
venuekildetabel:
- Indlæs spillestedsdata:
- Opret
saleskildetabel:
- Indlæs salgskildedata:
- Opret
calendarbord:
- Indlæs kalenderdata:
Opret dimensionstabellen
Design af dimensionstabellen kan afhænge af dine forretningskrav – skal du for eksempel spore ændringer af dataene over tid? Der er syv forskellige dimensionstyper. Til vores eksempel bruger vi typen 1 fordi vi ikke behøver at spore historiske ændringer. For mere om type 2, se Forenkle dataindlæsning i Type 2 langsomt skiftende dimensioner i Amazon Redshift. Dimensionstabellen vil blive denormaliseret med en primær nøgle, surrogatnøgle og et par tilføjede felter for at angive ændringer i tabellen. Se følgende kode:
Et par bemærkninger om oprettelse af dimensionstabellen:
- Feltnavnene omdannes til erhvervsvenlige navne
- Vores primære nøgle er
VenueID, som vi bruger til entydigt at identificere et sted, hvor salget fandt sted - To yderligere rækker vil blive tilføjet, som angiver, hvornår en post blev indsat og opdateret (for at spore ændringer)
- Vi bruger en AUTO distributionsstil at give Amazon Redshift ansvaret for at vælge og justere distributionsstilen
En anden vigtig faktor at overveje i dimensionel modellering er brugen af surrogatnøgler. Surrogatnøgler er kunstige nøgler, der bruges i dimensionsmodellering til entydigt at identificere hver post i en dimensionstabel. De genereres typisk som et sekventielt heltal, og de har ingen betydning i forretningsdomænet. De tilbyder flere fordele, såsom at sikre unikhed og forbedre ydeevnen i joinforbindelser, fordi de typisk er mindre end naturlige nøgler, og som surrogatnøgler ændres de ikke over tid. Dette giver os mulighed for at være konsekvente og nemmere forbinde fakta og dimensioner.
I Amazon Redshift oprettes surrogatnøgler typisk ved hjælp af søgeordet IDENTITY. For eksempel opretter den foregående CREATE-sætning en dimensionstabel med en VenueSkey surrogatnøgle. Det VenueSkey kolonne udfyldes automatisk med unikke værdier, når nye rækker tilføjes til tabellen. Denne kolonne kan derefter bruges til at slutte spillestedsbordet til FactSaleTransactions tabel.
Et par tips til at designe surrogatnøgler:
- Brug en lille datatype med fast bredde til surrogatnøglen. Dette vil forbedre ydeevnen og reducere lagerplads.
- Brug nøgleordet IDENTITY, eller generer surrogatnøglen ved hjælp af en sekventiel eller GUID-værdi. Dette vil sikre, at surrogatnøglen er unik og ikke kan ændres.
Indlæs dæmpningsbordet ved hjælp af MERGE
Der er mange måder at indlæse dit dæmpede bord på. Visse faktorer skal tages i betragtning - for eksempel ydeevne, datavolumen og måske SLA-indlæsningstider. Med FUSIONERE sætning, udfører vi en upsert uden at skulle angive flere indsættelses- og opdateringskommandoer. Du kan opsætte FUSIONERE udtalelse i en lagret procedure at udfylde dataene. Du planlægger derefter den lagrede procedure til at køre programmatisk via forespørgselseditoren, som vi demonstrerer senere i indlægget. Følgende kode opretter en lagret procedure kaldet SalesMart.DimVenueLoad:
Et par bemærkninger om dimensionsbelastningen:
- Når en post indsættes for første gang, vil den indsatte dato og den opdaterede dato blive udfyldt. Når nogen værdier ændres, opdateres dataene, og den opdaterede dato afspejler datoen, hvor den blev ændret. Den indsatte dato forbliver.
- Fordi dataene vil blive brugt af forretningsbrugere, er vi nødt til at erstatte NULL-værdier, hvis nogen, med mere forretningsegnede værdier.
Identificer og implementer fakta
Nu hvor vi har erklæret vores korn til at være begivenheden for et salg, der fandt sted på et bestemt tidspunkt, vil vores faktatabel gemme de numeriske fakta for vores forretningsproces.
Vi har identificeret følgende numeriske fakta at måle:
- Antal solgte billetter pr. salg
- Kommission for salget
Implementering af fakta
Der er tre typer faktatabeller (transaktionsfakta-tabel, periodisk snapshot-faktatabel og akkumulerende snapshot-faktatabel). Hver serverer et andet syn på forretningsprocessen. Til vores eksempel bruger vi en transaktionsfakta-tabel. Udfør følgende trin:
- Lav faktatabellen
En indsat dato med en standardværdi tilføjes, der angiver, om og hvornår en post blev indlæst. Du kan bruge dette, når du genindlæser faktatabellen for at fjerne de allerede indlæste data for at undgå dubletter.
Indlæsning af faktatabellen består af en simpel indsætningserklæring, der forbinder dine tilknyttede dimensioner. Vi tilslutter os fra DimVenue tabel, der blev oprettet, som beskriver vores fakta. Det er bedste praksis, men valgfrit at have kalender dato dimensioner, som giver slutbrugeren mulighed for at navigere i faktatabellen. Data kan enten indlæses, når der er et nyt salg, eller dagligt; det er her, den indsatte dato eller indlæsningsdato er praktisk.
Vi indlæser faktatabellen ved hjælp af en lagret procedure og bruger en datoparameter.
- Opret den lagrede procedure med følgende kode. For at bevare den samme dataintegritet, som vi anvendte i dimensionsindlæsningen, erstatter vi NULL-værdier, hvis nogen, med mere forretningsegnede værdier:
- Indlæs dataene ved at kalde proceduren med følgende kommando:
Planlæg dataindlæsningen
Vi kan nu automatisere modelleringsprocessen ved at planlægge de lagrede procedurer i Amazon Redshift Query Editor V2. Udfør følgende trin:
- Vi kalder først dimensionsbelastningen, og efter at dimensionsbelastningen kører med succes, begynder faktabelastningen:
Hvis dimensionsbelastningen fejler, vil faktabelastningen ikke køre. Dette sikrer ensartethed i dataene, fordi vi ikke ønsker at indlæse faktatabellen med forældede dimensioner.
- Vælg for at planlægge belastningen Planlæg i Query Editor V2.

- Vi planlægger, at forespørgslen skal køre hver dag kl. 5.
- Du kan eventuelt tilføje fejlmeddelelser ved at aktivere Amazon Simple Notification Service (Amazon SNS) meddelelser.

Rapporter og analyser dataene i Amazon Quicksight
QuickSight er en business intelligence-tjeneste, der gør det nemt at levere indsigt. Som en fuldt administreret tjeneste lader QuickSight dig nemt oprette og udgive interaktive dashboards, som derefter kan tilgås fra enhver enhed og integreres i dine applikationer, portaler og websteder.
Vi bruger vores datamart til visuelt at præsentere fakta i form af et dashboard. For at komme i gang og konfigurere QuickSight, se Oprettelse af et datasæt ved hjælp af en database, der ikke er autoopdaget.
Når du har oprettet din datakilde i QuickSight, samler vi de modellerede data (datamart) baseret på vores surrogatnøgle skey. Vi bruger dette datasæt til at visualisere datamarkedet.

Vores slut-dashboard vil indeholde indsigten fra datamarkedet og besvare kritiske forretningsspørgsmål, såsom samlet kommission pr. spillested og datoer med det højeste salg. Følgende skærmbillede viser det endelige produkt af datamart.

Ryd op
For at undgå fremtidige gebyrer skal du slette alle ressourcer, du har oprettet som en del af dette indlæg.
Konklusion
Vi har nu med succes implementeret en datamart ved hjælp af vores DimVenue, DimCalendarog FactSaleTransactions borde. Vores lager er ikke komplet; da vi kan udvide datamarkedet med flere fakta og implementere flere marts, og efterhånden som forretningsprocessen og kravene vokser over tid, vil datavarehuset også vokse. I dette indlæg gav vi et ende-til-ende syn på forståelse og implementering af dimensionel modellering i Amazon Redshift.
Kom i gang med din Amazon rødforskydning dimensionel model i dag.
Om forfatterne
 Bernard Verster er en erfaren cloud-ingeniør med mange års eksponering i at skabe skalerbare og effektive datamodeller, definere dataintegrationsstrategier og sikre datastyring og sikkerhed. Han brænder for at bruge data til at skabe indsigt, samtidig med at han er i overensstemmelse med forretningskrav og mål.
Bernard Verster er en erfaren cloud-ingeniør med mange års eksponering i at skabe skalerbare og effektive datamodeller, definere dataintegrationsstrategier og sikre datastyring og sikkerhed. Han brænder for at bruge data til at skabe indsigt, samtidig med at han er i overensstemmelse med forretningskrav og mål.
 Abhishek Pan er en WWSO Specialist SA-Analytics, der arbejder med AWS Indiens kunder i den offentlige sektor. Han engagerer sig med kunder for at definere datadrevet strategi, give dybe dykkesessioner om analytics use cases og designe skalerbare og effektive analytiske applikationer. Han har 12 års erfaring og brænder for databaser, analyser og AI/ML. Han er en ivrig rejsende og forsøger at fange verden gennem sit kameraobjektiv.
Abhishek Pan er en WWSO Specialist SA-Analytics, der arbejder med AWS Indiens kunder i den offentlige sektor. Han engagerer sig med kunder for at definere datadrevet strategi, give dybe dykkesessioner om analytics use cases og designe skalerbare og effektive analytiske applikationer. Han har 12 års erfaring og brænder for databaser, analyser og AI/ML. Han er en ivrig rejsende og forsøger at fange verden gennem sit kameraobjektiv.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Automotive/elbiler, Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- BlockOffsets. Modernisering af miljømæssig offset-ejerskab. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 100
- 12
- 15 %
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Om
- fremskynde
- adgang
- af udleverede
- præcist
- tværs
- Lov
- tilføje
- tilføjet
- Yderligere
- Efter
- AI / ML
- tilpasse
- justering
- tillade
- tillader
- allerede
- am
- Amazon
- Amazon Web Services
- an
- analyse
- Analytisk
- analytics
- analysere
- ,
- besvare
- enhver
- applikationer
- anvendt
- passende
- arkitektur
- ER
- kunstig
- AS
- aspekter
- forbundet
- At
- attributter
- auto
- automatisere
- automatisk
- undgå
- AWS
- b
- baseret
- BE
- fordi
- begynde
- fordele
- BEDSTE
- indbygget
- virksomhed
- business intelligence
- Forretningsproces
- forretningsprocesser
- men
- by
- Kalender
- ringe
- kaldet
- ringer
- værelse
- CAN
- fange
- tilfælde
- tilfælde
- Årsag
- vis
- lave om
- ændret
- Ændringer
- skiftende
- karakter
- afgifter
- Vælg
- klar
- tydeligt
- nøje
- Cloud
- kode
- Kolonne
- kommer
- Kommissionen
- Fælles
- Virksomheder
- selskab
- fuldføre
- Overvej
- konsekvent
- består
- sammenhæng
- korrigere
- kunne
- skabe
- oprettet
- skaber
- Oprettelse af
- skabelse
- kritisk
- Kunder
- dagligt
- instrumentbræt
- dashboards
- data
- dataintegration
- Data Lake
- datalager
- datastyret
- Datadrevet strategi
- Database
- databaser
- Dato
- Datoer
- dato tid
- dag
- dyb
- dyb dykke
- Standard
- definere
- levere
- demonstrere
- afdelinger
- Afledt
- beskrive
- Design
- designe
- detail
- enhed
- forskellige
- Dimension
- størrelse
- diskutere
- distinkt
- fordeling
- do
- domæne
- færdig
- Dont
- ned
- køre
- dubletter
- hver
- tidligere
- nemt
- let
- editor
- effektiv
- enten
- indlejret
- muliggøre
- muliggør
- ende
- ende til ende
- indgreb
- ingeniør
- sikre
- sikrer
- sikring
- Hele
- enhed
- Ether (ETH)
- begivenhed
- begivenheder
- Hver
- hver dag
- eksempel
- eksempler
- Udvid
- erfaring
- erfarne
- Eksponering
- ekstrakt
- Faktisk
- faktor
- faktorer
- fakta
- mislykkes
- Manglende
- Funktionalitet
- få
- felt
- Fields
- femte
- Figur
- filtrere
- endelige
- Fornavn
- første gang
- passer
- fokuserede
- efter
- Til
- formular
- format
- fire
- fra
- fuldt ud
- yderligere
- fremtiden
- Gevinst
- generere
- genereret
- genererer
- få
- få
- Giv
- given
- godt
- regeringsførelse
- Grow
- praktisk
- Have
- he
- højeste
- hans
- historisk
- Ferie
- Hvordan
- How To
- HTML
- http
- HTTPS
- IAM
- identificeret
- identificere
- identificere
- Identity
- if
- illustrerer
- KIMOs Succeshistorier
- gennemføre
- implementeret
- gennemføre
- vigtigt
- Forbedre
- forbedring
- in
- Herunder
- Indien
- angiver
- angiver
- info
- indsigt
- integreret
- integration
- integritet
- Intelligens
- interaktiv
- ind
- IT
- ITS
- deltage
- sluttede
- sammenføjning
- Sammenføjninger
- jpg
- Holde
- holde
- Nøgle
- nøgler
- sø
- Sprog
- senere
- seneste
- lag
- til venstre
- Linse
- Lets
- Niveau
- Line (linje)
- belastning
- lastning
- belastninger
- placeret
- leder
- lavet
- maerker
- lykkedes
- Marketing
- matchede
- betyder
- måle
- nævnte
- Flet
- Metrics
- tankerne
- fejltagelse
- model
- modellering
- modellering
- modeller
- Måned
- mere
- mest
- flere
- navne
- Natural
- Naviger
- Behov
- behøve
- behov
- Ny
- Noter
- underretning
- meddelelser
- nu
- talrige
- målsætninger
- of
- tilbyde
- tit
- on
- kun
- operationelle
- or
- organisation
- vores
- i løbet af
- samlet
- parameter
- del
- lidenskabelige
- per
- udføre
- ydeevne
- måske
- periodisk
- Place
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- befolkede
- Indlæg
- magt
- praksis
- forudsætninger
- præsentere
- primære
- procedure
- procedurer
- behandle
- Processer
- Produkt
- give
- forudsat
- giver
- offentlige
- offentliggøre
- formål
- Spørgsmål
- hurtigt
- rejse
- Raw
- rådata
- optage
- optegnelser
- reducere
- benævnt
- afspejler
- region
- forhold
- resterne
- Fjern
- erstatte
- indberette
- Rapportering
- Rapporter
- Krav
- Ressourcer
- ansvar
- roller
- Roll
- RÆKKE
- Kør
- løber
- salg
- salg
- samme
- Eksempeldatasæt
- skalerbar
- planlægge
- planlægning
- sektioner
- sektor
- sikkerhed
- se
- adskille
- tjener
- tjeneste
- Tjenester
- sessioner
- sæt
- flere
- bør
- Vis
- Shows
- Simpelt
- enkelhed
- enkelt
- langsomt
- lille
- mindre
- Snapshot
- So
- solgt
- løsninger
- nogle
- Kilde
- Kilder
- Space
- specialist
- specifikke
- specifikt
- Stage
- iscenesættelse
- Stjerne
- påbegyndt
- Starter
- Statement
- Trin
- Steps
- opbevaring
- butik
- opbevaret
- strategier
- Strategi
- struktur
- vellykket
- Succesfuld
- sådan
- systemet
- bord
- midlertidig
- tiere
- vilkår
- end
- at
- The Source
- verdenen
- deres
- derefter
- Der.
- derfor
- Disse
- de
- denne
- tusinder
- Gennem
- billet
- billetsalg
- billetter
- tid
- gange
- tidsstempel
- tips
- til
- i dag
- sammen
- tog
- I alt
- spor
- transaktion
- Transform
- omdannet
- rejsende
- typen
- typer
- typisk
- forståelse
- enestående
- entydigt
- entydighed
- ukendt
- Opdatering
- opdateret
- us
- Brug
- brug
- brug tilfælde
- anvendte
- brugere
- bruger
- ved brug af
- sædvanligvis
- Værdifuld
- værdi
- Værdier
- forskellige
- Venue
- handelssystemer
- via
- Specifikation
- bind
- går igennem
- ønsker
- Warehouse
- var
- måder
- we
- web
- webservices
- websites
- uge
- hvornår
- som
- mens
- vilje
- med
- inden for
- uden
- arbejder
- world
- Forkert
- år
- år
- dig
- Din
- zephyrnet