Mange organisationer, små og store, arbejder på at migrere og modernisere deres analysearbejdsbelastninger på Amazon Web Services (AWS). Der er mange grunde til, at kunder skal migrere til AWS, men en af hovedårsagerne er muligheden for at bruge fuldt administrerede tjenester i stedet for at bruge tid på at vedligeholde infrastruktur, patching, overvågning, sikkerhedskopier og mere. Ledelses- og udviklingsteams kan bruge mere tid på at optimere nuværende løsninger og endda eksperimentere med nye use cases, i stedet for at vedligeholde den nuværende infrastruktur.
Med evnen til at bevæge sig hurtigt på AWS, skal du også være ansvarlig med de data, du modtager og behandler, mens du fortsætter med at skalere. Disse ansvarsområder omfatter at være i overensstemmelse med love og bestemmelser om databeskyttelse og ikke at opbevare eller udsætte følsomme data som personligt identificerbare oplysninger (PII) eller beskyttede sundhedsoplysninger (PHI) fra upstream-kilder.
I dette indlæg gennemgår vi en arkitektur på højt niveau og en specifik use case, der demonstrerer, hvordan du kan fortsætte med at skalere din organisations dataplatform uden at skulle bruge store mængder udviklingstid på at løse problemer med databeskyttelse. Vi bruger AWS Lim at detektere, maskere og redigere PII-data, før de indlæses i Amazon OpenSearch Service.
Løsningsoversigt
Følgende diagram illustrerer løsningsarkitekturen på højt niveau. Vi har defineret alle lag og komponenter i vores design i overensstemmelse med AWS Well-Architected Framework Data Analytics Lens.
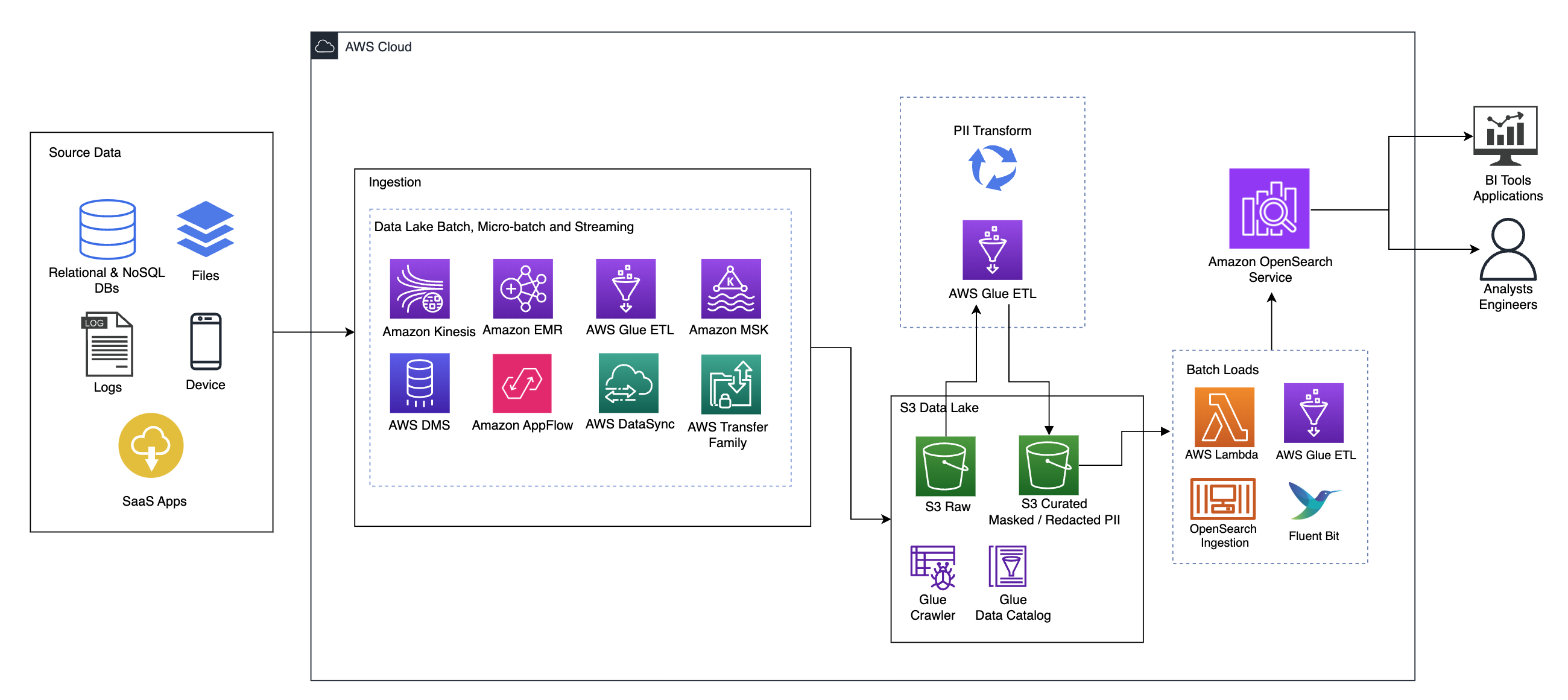
Arkitekturen består af en række komponenter:
Kilde data
Data kan komme fra mange tiere til hundredvis af kilder, herunder databaser, filoverførsler, logfiler, software as a service (SaaS) applikationer og mere. Organisationer har muligvis ikke altid kontrol over, hvilke data der kommer gennem disse kanaler og ind i deres downstream-lagring og applikationer.
Indtagelse: Datasø-batch, mikro-batch og streaming
Mange organisationer lander deres kildedata i deres datasø på forskellige måder, herunder batch-, mikrobatch- og streamingjob. For eksempel, Amazon EMR, AWS Limog AWS Database Migration Service (AWS DMS) kan alle bruges til at udføre batch- og/eller streamingoperationer, der synker til en datasø på Amazon Simple Storage Service (Amazon S3). Amazon App Flow kan bruges til at overføre data fra forskellige SaaS-applikationer til en datasø. AWS DataSync , AWS Transfer Familie kan hjælpe med at flytte filer til og fra en datasø over en række forskellige protokoller. Amazon Kinesis og Amazon MSK har også kapacitet til at streame data direkte til en datasø på Amazon S3.
S3 data sø
Brug af Amazon S3 til din datasø er i tråd med den moderne datastrategi. Det giver lavprislagring uden at ofre ydeevne, pålidelighed eller tilgængelighed. Med denne tilgang kan du bringe computer til dine data efter behov og kun betale for den kapacitet, den skal bruge.
I denne arkitektur kan rådata komme fra en række forskellige kilder (interne og eksterne), som kan indeholde følsomme data.
Ved at bruge AWS Glue-crawlere kan vi opdage og katalogisere dataene, som vil bygge tabelskemaerne for os og i sidste ende gøre det ligetil at bruge AWS Glue ETL med PII-transformationen til at opdage og maskere eller og redigere eventuelle følsomme data, der måtte være landet. i datasøen.
Forretningskontekst og datasæt
For at demonstrere værdien af vores tilgang, lad os forestille os, at du er en del af et dataingeniørteam for en finansiel serviceorganisation. Dine krav er at detektere og maskere følsomme data, når de indlæses i din organisations cloudmiljø. Dataene vil blive forbrugt af downstream analytiske processer. I fremtiden vil dine brugere sikkert kunne søge i historiske betalingstransaktioner baseret på datastrømme indsamlet fra interne banksystemer. Søgeresultater fra driftsteams, kunder og grænsefladeapplikationer skal maskeres i følsomme felter.
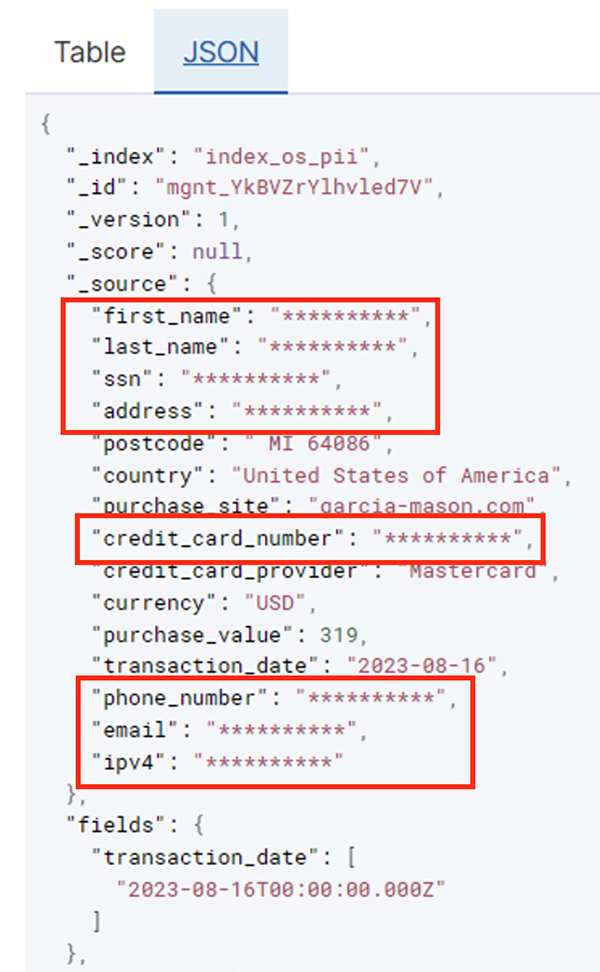
Følgende tabel viser den datastruktur, der er brugt til løsningen. For klarhedens skyld har vi kortlagt rå til kuraterede kolonnenavne. Du vil bemærke, at flere felter i dette skema betragtes som følsomme data, såsom fornavn, efternavn, CPR-nummer (SSN), adresse, kreditkortnummer, telefonnummer, e-mail og IPv4-adresse.
| Rå kolonnenavn | Udvalgt kolonnenavn | Type |
| c0 | fornavn | streng |
| c1 | efternavn | streng |
| c2 | SSN | streng |
| c3 | adresse | streng |
| c4 | postnummer | streng |
| c5 | land | streng |
| c6 | købsside | streng |
| c7 | kreditkortnummer | streng |
| c8 | kredit_kortudbyder | streng |
| c9 | valuta | streng |
| c10 | købsværdi | heltal |
| c11 | Overførselsdato | dato |
| c12 | telefonnummer | streng |
| c13 | streng | |
| c14 | ipv4 | streng |
Use case: PII batch-detektion før indlæsning til OpenSearch Service
Kunder, der implementerer følgende arkitektur, har bygget deres datasø på Amazon S3 for at køre forskellige typer analyser i skala. Denne løsning er velegnet til kunder, der ikke har brug for realtidsoptagelse til OpenSearch Service og planlægger at bruge dataintegrationsværktøjer, der kører efter en tidsplan eller udløses gennem begivenheder.
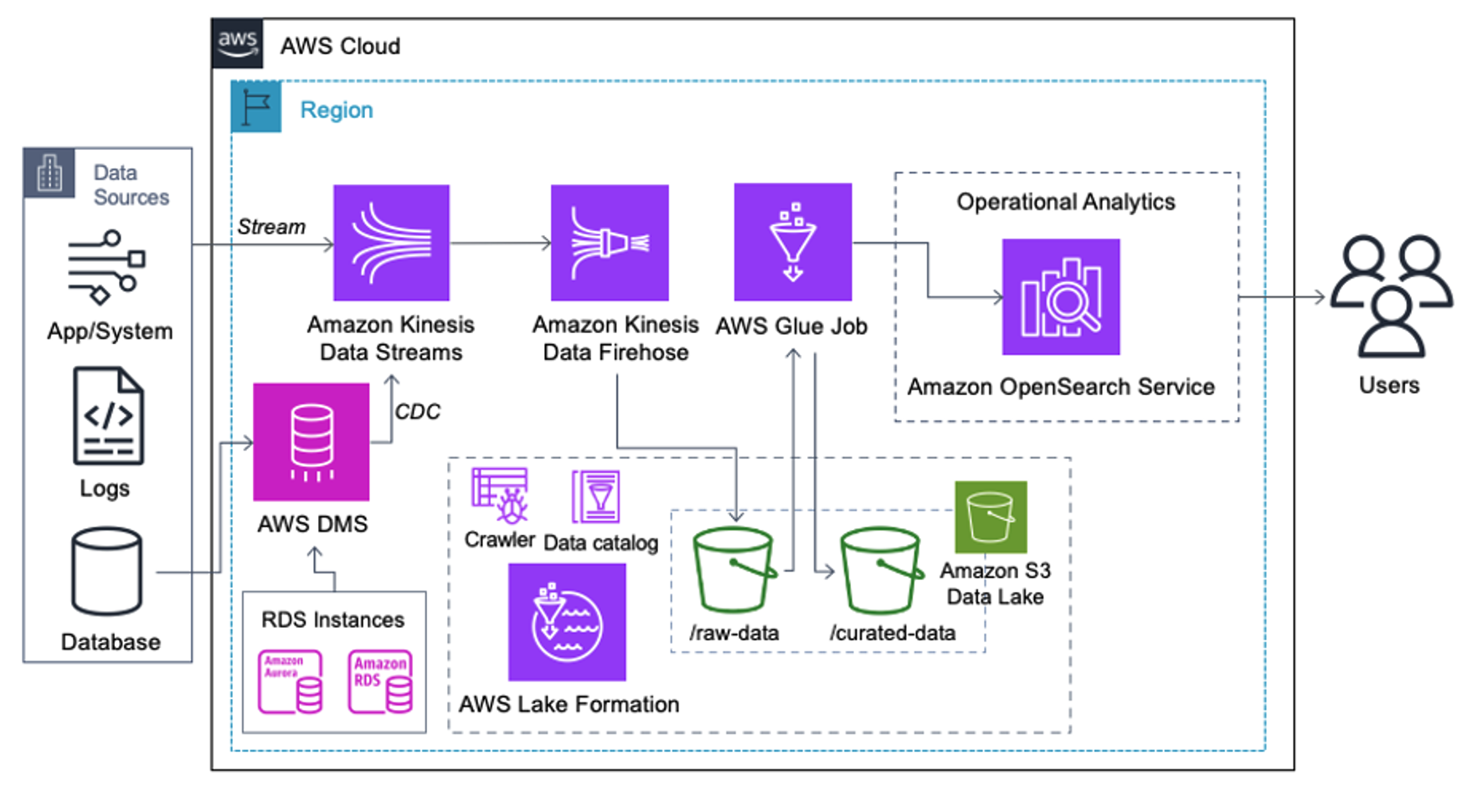
Før dataposter lander på Amazon S3, implementerer vi et indtagelseslag for at bringe alle datastrømme pålideligt og sikkert til datasøen. Kinesis Data Streams er implementeret som et indtagelseslag til accelereret indtagelse af strukturerede og semistrukturerede datastrømme. Eksempler på disse er relationelle databaseændringer, applikationer, systemlogfiler eller klikstrømme. Til ændringsdatafangst (CDC) kan du bruge Kinesis Data Streams som et mål for AWS DMS. Applikationer eller systemer, der genererer streams, der indeholder følsomme data, sendes til Kinesis-datastrømmen via en af de tre understøttede metoder: Amazon Kinesis Agent, AWS SDK for Java eller Kinesis Producer Library. Som et sidste skridt, Amazon Kinesis Data Firehose hjælper os med pålideligt at indlæse batches af data i næsten realtid til vores S3-datasø-destination.
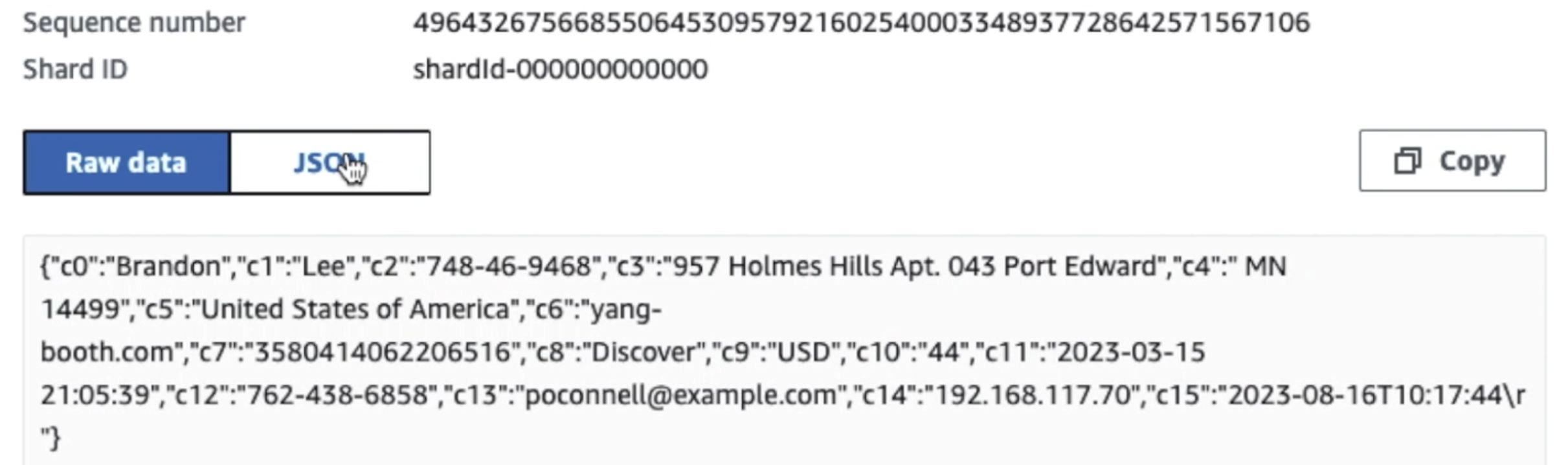
Følgende skærmbillede viser, hvordan data flyder gennem Kinesis Data Streams via Datafremviser og henter eksempeldata, der lander på det rå S3-præfiks. For denne arkitektur fulgte vi datalivscyklussen for S3-præfikser som anbefalet i Data sø fundament.
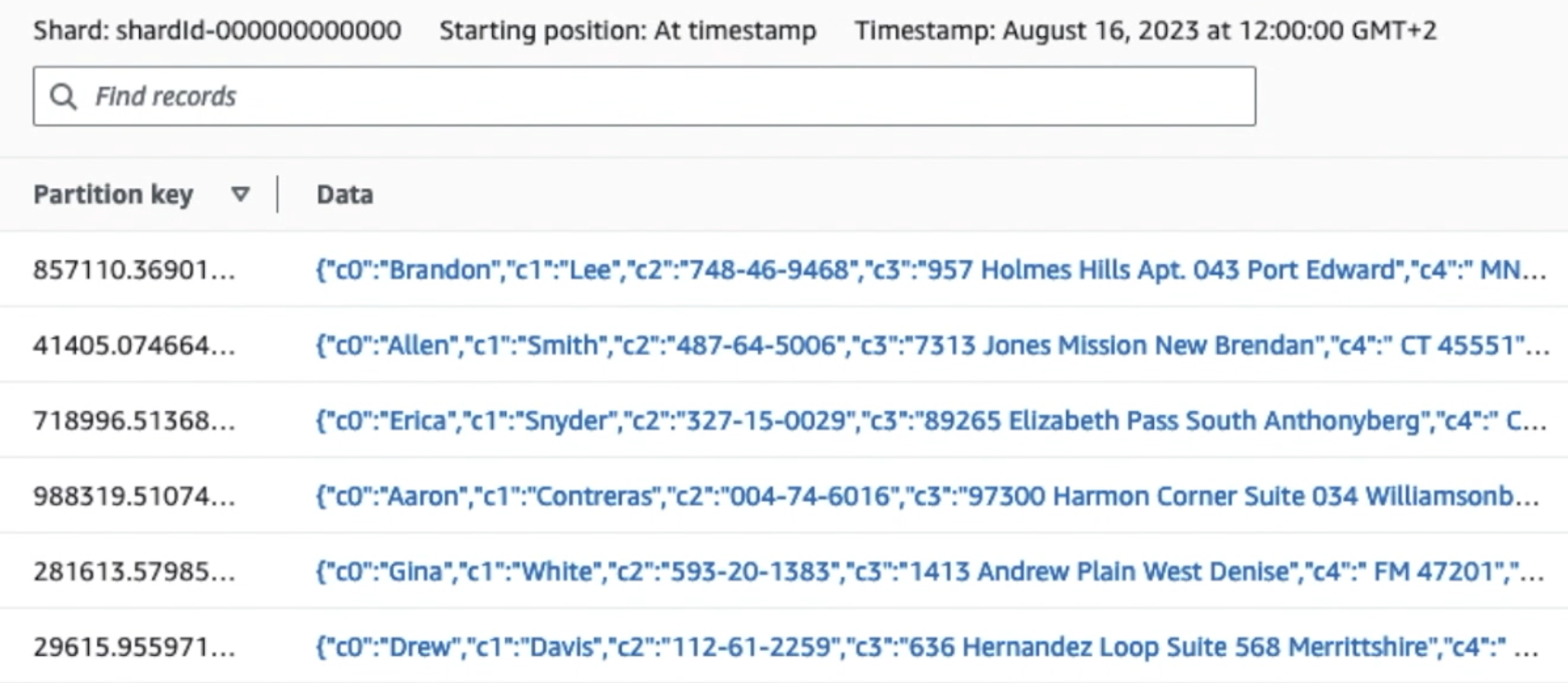
Som du kan se fra detaljerne i den første post i det følgende skærmbillede, følger JSON-nyttelasten det samme skema som i det foregående afsnit. Du kan se de uredigerede data flyde ind i Kinesis-datastrømmen, som vil blive sløret senere i de efterfølgende faser.
Efter at dataene er indsamlet og indtaget i Kinesis Data Streams og leveret til S3-bøtten ved hjælp af Kinesis Data Firehose, overtager arkitekturens behandlingslag. Vi bruger AWS Glue PII-transformationen til at automatisere detektion og maskering af følsomme data i vores pipeline. Som vist i det følgende workflowdiagram tog vi en kodefri, visuel ETL-tilgang til at implementere vores transformationsjob i AWS Glue Studio.
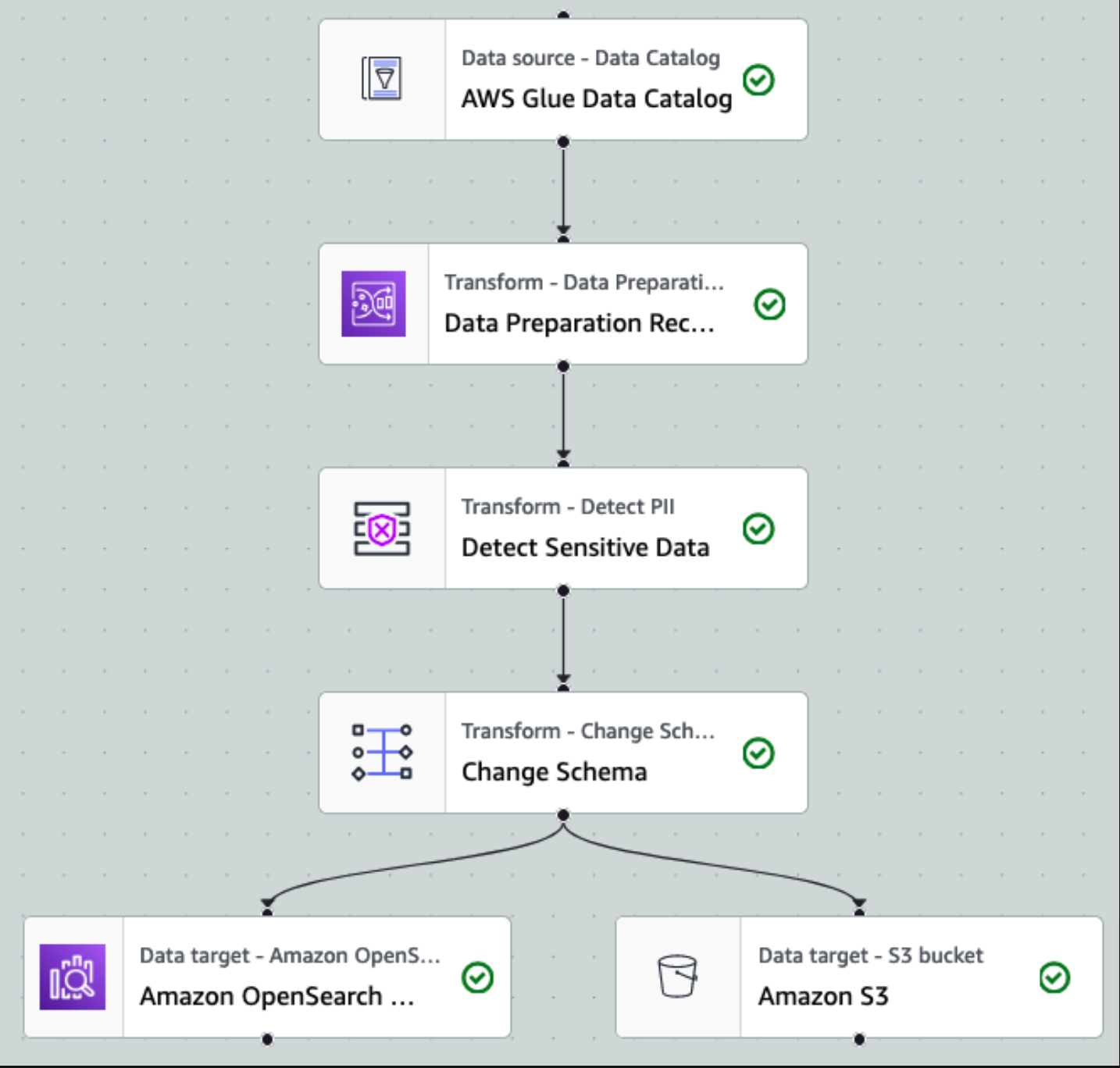
Først får vi adgang til kildedatakatalogtabellen rå fra pii_data_db database. Tabellen har skemastrukturen præsenteret i det foregående afsnit. For at holde styr på de råbehandlede data brugte vi job bogmærker.

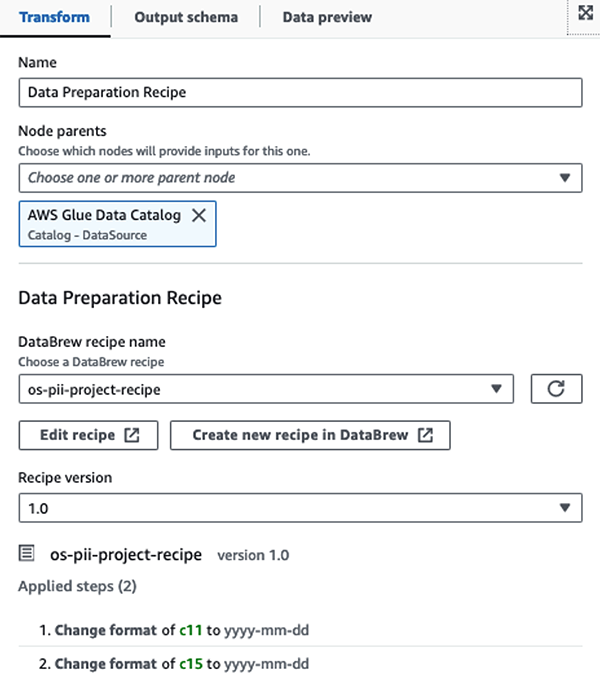
Vi bruger AWS Glue DataBrew-opskrifter i AWS Glue Studio visuelle ETL-jobbet at transformere to datoattributter til at være kompatible med OpenSearch forventet formater. Dette giver os mulighed for at få en fuld kodefri oplevelse.
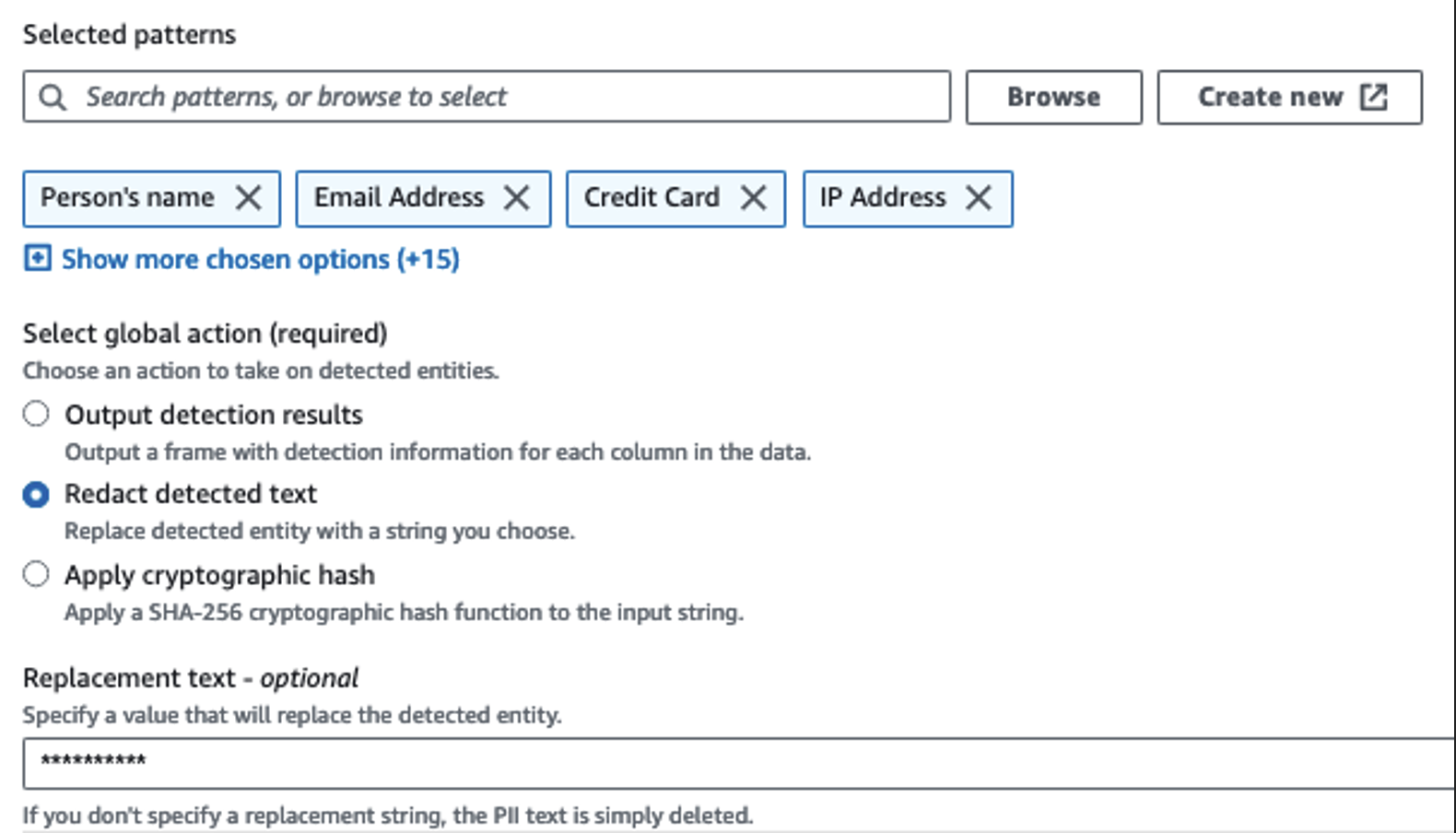
Vi bruger handlingen Detect PII til at identificere følsomme kolonner. Vi lader AWS Glue bestemme dette baseret på udvalgte mønstre, detektionstærskel og prøvedel af rækker fra datasættet. I vores eksempel brugte vi mønstre, der gælder specifikt for USA (såsom SSN'er), og som muligvis ikke registrerer følsomme data fra andre lande. Du kan se efter tilgængelige kategorier og placeringer, der er relevante for dit brugstilfælde eller bruge regulære udtryk (regex) i AWS Glue til at oprette detektionsenheder for følsomme data fra andre lande.
Det er vigtigt at vælge den korrekte prøveudtagningsmetode, som AWS Glue tilbyder. I dette eksempel er det kendt, at de data, der kommer ind fra strømmen, har følsomme data i hver række, så det er ikke nødvendigt at sample 100 % af rækkerne i datasættet. Hvis du har et krav, hvor ingen følsomme data er tilladt til downstream-kilder, kan du overveje at stikprøve 100 % af dataene for de mønstre, du har valgt, eller scanne hele datasættet og handle på hver enkelt celle for at sikre, at alle følsomme data bliver opdaget. Fordelen du får ved at tage prøver er reducerede omkostninger, fordi du ikke behøver at scanne så meget data.

Handlingen Registrer PII giver dig mulighed for at vælge en standardstreng, når du maskerer følsomme data. I vores eksempel bruger vi strengen **********.
Vi bruger tilknytningsoperationen til at omdøbe og fjerne unødvendige kolonner som f.eks ingestion_year, ingestion_monthog ingestion_day. Dette trin giver os også mulighed for at ændre datatypen for en af kolonnerne (purchase_value) fra streng til heltal.

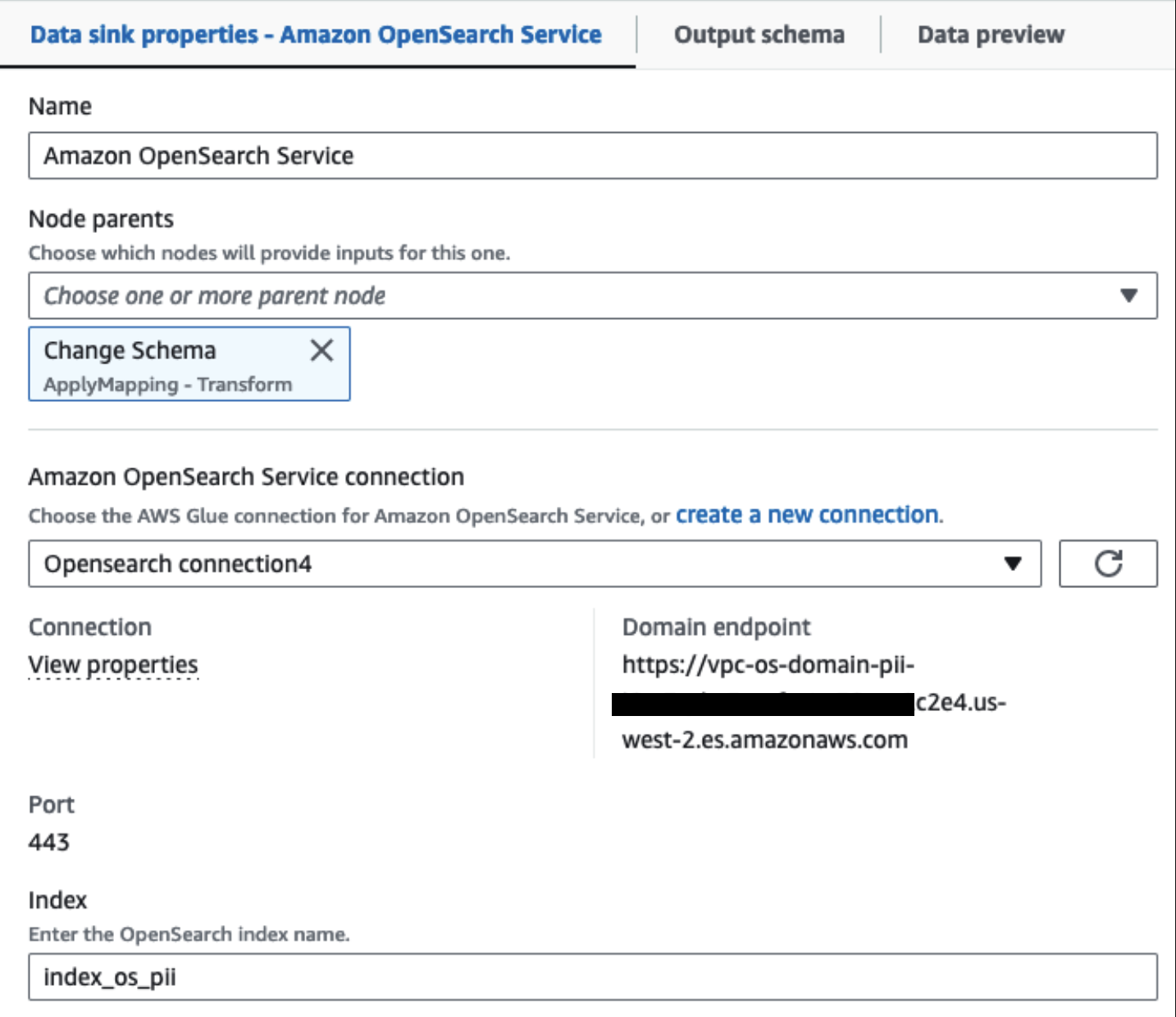
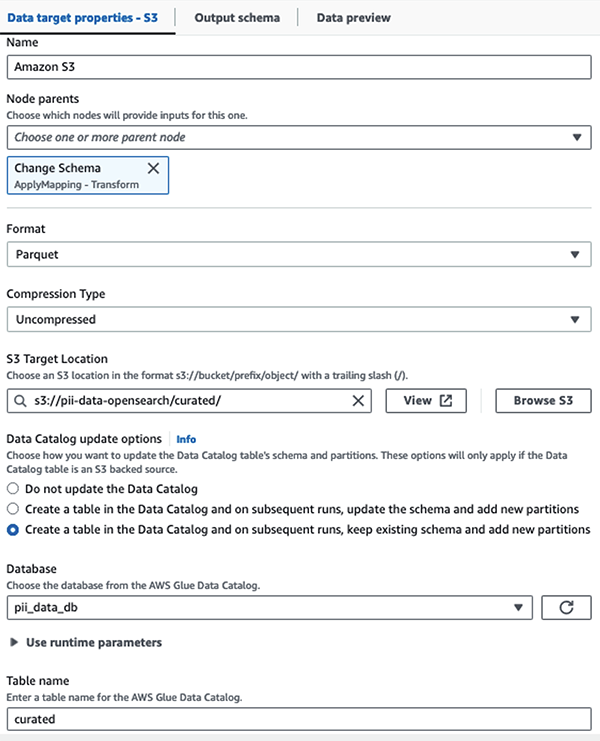
Fra dette tidspunkt opdeles jobbet i to outputdestinationer: OpenSearch Service og Amazon S3.
Vores klargjorte OpenSearch Service-klynge er forbundet via OpenSearch indbygget stik til lim. Vi angiver det OpenSearch-indeks, vi gerne vil skrive til, og connectoren håndterer legitimationsoplysningerne, domænet og porten. I skærmbilledet nedenfor skriver vi til det angivne indeks index_os_pii.
Vi gemmer det maskerede datasæt i det kurerede S3-præfiks. Der har vi data normaliseret til en specifik use case og sikkert forbrug af data scientists eller til ad hoc rapporteringsbehov.
Til ensartet styring, adgangskontrol og revisionsspor for alle datasæt og datakatalogtabeller kan du bruge AWS søformation. Dette hjælper dig med at begrænse adgangen til AWS Glue Data Catalog-tabeller og underliggende data til kun de brugere og roller, der har fået de nødvendige tilladelser til at gøre det.
Når batchjobbet er kørt korrekt, kan du bruge OpenSearch Service til at køre søgeforespørgsler eller rapporter. Som vist i det følgende skærmbillede, maskerede pipelinen følsomme felter automatisk uden kodeudvikling.

Du kan identificere tendenser fra de operationelle data, såsom mængden af transaktioner per dag filtreret af kreditkortudbyderen, som vist på det foregående skærmbillede. Du kan også bestemme de steder og domæner, hvor brugerne foretager køb. Det transaction_date attribut hjælper os med at se disse tendenser over tid. Følgende skærmbillede viser en registrering med alle transaktionens oplysninger redigeret korrekt.
For alternative metoder til, hvordan man indlæser data i Amazon OpenSearch, se Indlæser streamingdata til Amazon OpenSearch Service.
Ydermere kan følsomme data også opdages og maskeres ved hjælp af andre AWS-løsninger. Du kan f.eks. bruge Amazon Macie at opdage følsomme data inde i en S3-bøtte, og derefter bruge Amazon Comprehend at redigere de følsomme data, der blev opdaget. For mere information, se Almindelige teknikker til at detektere PHI- og PII-data ved hjælp af AWS Services.
Konklusion
Dette indlæg diskuterede vigtigheden af at håndtere følsomme data i dit miljø og forskellige metoder og arkitekturer for at forblive kompatible og samtidig tillade din organisation at skalere hurtigt. Du bør nu have en god forståelse af, hvordan du opdager, maskerer eller redigerer og indlæser dine data i Amazon OpenSearch Service.
Om forfatterne
 Michael Hamilton er en Sr Analytics Solutions Architect med fokus på at hjælpe virksomhedskunder med at modernisere og forenkle deres analytiske arbejdsbelastninger på AWS. Han nyder at cykle på mountainbike og tilbringe tid med sin kone og tre børn, når han ikke arbejder.
Michael Hamilton er en Sr Analytics Solutions Architect med fokus på at hjælpe virksomhedskunder med at modernisere og forenkle deres analytiske arbejdsbelastninger på AWS. Han nyder at cykle på mountainbike og tilbringe tid med sin kone og tre børn, når han ikke arbejder.
 Daniel Rozo er en Senior Solutions Architect med AWS, der støtter kunder i Holland. Hans passion er at udvikle simple data- og analyseløsninger og hjælpe kunder med at flytte til moderne dataarkitekturer. Uden for arbejdet nyder han at spille tennis og cykle.
Daniel Rozo er en Senior Solutions Architect med AWS, der støtter kunder i Holland. Hans passion er at udvikle simple data- og analyseløsninger og hjælpe kunder med at flytte til moderne dataarkitekturer. Uden for arbejdet nyder han at spille tennis og cykle.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :har
- :er
- :ikke
- :hvor
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- evne
- I stand
- accelereret
- adgang
- Lov
- Handling
- Ad
- adresse
- Agent
- Alle
- tilladt
- tillade
- tillader
- også
- altid
- Amazon
- Amazon Kinesis
- Amazon Web Services
- Amazon Web Services (AWS)
- beløb
- beløb
- an
- Analytisk
- analytics
- ,
- enhver
- anvendelig
- applikationer
- Indløs
- tilgang
- passende
- arkitektur
- ER
- AS
- At
- attributter
- revision
- automatisere
- automatisk
- tilgængelighed
- til rådighed
- AWS
- AWS Lim
- sikkerhedskopier
- Bank
- Banksystemer
- baseret
- BE
- fordi
- været
- før
- være
- jf. nedenstående
- gavner det dig
- bringe
- bygge
- bygget
- indbygget
- men
- by
- CAN
- kapaciteter
- Kapacitet
- fange
- kort
- tilfælde
- tilfælde
- katalog
- kategorier
- CDC
- celle
- lave om
- Ændringer
- kanaler
- Børn
- valgte
- klarhed
- Cloud
- Cluster
- kode
- Kolonne
- Kolonner
- Kom
- kommer
- kommer
- kompatibel
- kompatibel
- komponenter
- Indeholder
- Compute
- Bekymringer
- tilsluttet
- Overvej
- betragtes
- forbruges
- forbrug
- indeholder
- sammenhæng
- fortsæt
- kontrol
- korrigere
- Omkostninger
- kunne
- lande
- skabe
- Legitimationsoplysninger
- kredit
- kreditkort
- kurateret
- Nuværende
- Kunder
- data
- Dataanalyse
- dataintegration
- Data Lake
- Dataplatform
- databeskyttelse
- datastrategi
- Database
- databaser
- datasæt
- Dato
- dag
- Standard
- definerede
- leveret
- demonstrere
- demonstrerer
- indsat
- Design
- destination
- destinationer
- detaljer
- opdage
- opdaget
- Detektion
- Bestem
- Udvikling
- udviklingsteams
- forskellige
- direkte
- opdage
- opdaget
- drøftet
- do
- domæne
- Domæner
- Dont
- hver
- indsats
- Engineering
- sikre
- Enterprise
- virksomhedskunder
- Hele
- enheder
- Miljø
- Ether (ETH)
- Endog
- begivenheder
- Hver
- eksempel
- eksempler
- forventet
- erfaring
- udtryk
- ekstern
- FAST
- Fields
- File (Felt)
- Filer
- finansielle
- finansielle tjenesteydelser
- Fornavn
- Flowing
- strømme
- fokusering
- efterfulgt
- efter
- følger
- Til
- Framework
- fra
- fuld
- fuldt ud
- fremtiden
- generere
- få
- godt
- regeringsførelse
- bevilget
- Håndterer
- Håndtering
- Have
- he
- Helse
- sundhedsinformation
- hjælpe
- hjælpe
- hjælper
- højt niveau
- hans
- historisk
- Hvordan
- How To
- HTML
- http
- HTTPS
- Hundreder
- identificere
- if
- illustrerer
- billede
- gennemføre
- betydning
- vigtigt
- in
- omfatter
- Herunder
- indeks
- individuel
- oplysninger
- Infrastruktur
- indvendig
- integration
- interne
- ind
- IT
- Java
- Job
- Karriere
- jpg
- json
- Holde
- Kinesis Data Brandslange
- Kinesis datastrømme
- kendt
- sø
- Land
- lander
- stor
- Efternavn
- senere
- Love
- Love og forskrifter
- lag
- lag
- Leadership" (virkelig menneskelig ledelse)
- lad
- Bibliotek
- livscyklus
- ligesom
- Line (linje)
- belastning
- lastning
- placeringer
- Se
- lave omkostninger
- Main
- opretholdelse
- lave
- lykkedes
- mange
- kortlægning
- maske
- Kan..
- metode
- metoder
- migrere
- migration
- Moderne
- modernisere
- overvågning
- mere
- Bjerg
- bevæge sig
- flytning
- meget
- flere
- skal
- navn
- navne
- nødvendig
- Behov
- behov
- behøve
- behov
- Holland
- Ny
- ingen
- noder
- Varsel..
- nu
- nummer
- of
- Tilbud
- on
- ONE
- kun
- drift
- operationelle
- Produktion
- optimering
- Indstillinger
- or
- organisation
- organisationer
- Andet
- vores
- output
- uden for
- i løbet af
- del
- lidenskab
- lappe
- mønstre
- Betal
- betaling
- per
- udføre
- ydeevne
- Tilladelser
- Personligt
- telefon
- PIO
- pipeline
- fly
- perron
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Punkt
- del
- Indlæg
- forud
- forelagt
- tidligere
- Beskyttelse af personlige oplysninger
- lovgivning om beskyttelse af personlige oplysninger
- bearbejdet
- Processer
- forarbejdning
- producent
- beskyttet
- protokoller
- udbyder
- giver
- indkøb
- forespørgsler
- hurtigt
- hellere
- Raw
- rådata
- realtid
- årsager
- modtagende
- Opskrifter
- anbefales
- optage
- optegnelser
- Reduceret
- henvise
- fast
- regler
- pålidelighed
- forblive
- Fjern
- Rapportering
- Rapporter
- kræver
- krav
- Krav
- ansvar
- ansvarlige
- begrænse
- Resultater
- roller
- RÆKKE
- Kør
- løber
- SaaS
- at ofre
- sikker
- sikkert
- samme
- Scale
- scanne
- planlægge
- forskere
- Skærm
- SDK
- Søg
- Sektion
- sikkert
- sikkerhed
- se
- Vælg
- valgt
- senior
- følsom
- sendt
- tjeneste
- Tjenester
- shot
- bør
- vist
- Shows
- Simpelt
- forenkle
- lille
- So
- Social
- Software
- software som en tjeneste
- løsninger
- Løsninger
- Kilde
- Kilder
- specifikke
- specifikt
- specificeret
- tilbringe
- udgifterne
- splits
- etaper
- Stater
- Trin
- opbevaring
- butik
- ligetil
- Strategi
- strøm
- streaming
- vandløb
- String
- struktur
- struktureret
- Studio
- efterfølgende
- Succesfuld
- sådan
- egnede
- Understøttet
- Støtte
- systemet
- Systemer
- bord
- tager
- mål
- hold
- hold
- teknikker
- tennis
- tiere
- end
- at
- Fremtiden
- Holland
- The Source
- deres
- derefter
- Der.
- Disse
- denne
- dem
- tre
- tærskel
- Gennem
- tid
- til
- tog
- værktøjer
- spor
- Transaktioner
- overførsel
- overførsler
- Transform
- Transformation
- Tendenser
- udløst
- to
- typen
- typer
- Ultimativt
- underliggende
- forståelse
- forenet
- Forenet
- Forenede Stater
- us
- brug
- brug tilfælde
- anvendte
- brugere
- ved brug af
- værdi
- række
- forskellige
- via
- visuel
- gå
- var
- måder
- we
- web
- webservices
- Hvad
- hvornår
- som
- mens
- WHO
- kone
- vilje
- med
- inden for
- uden
- Arbejde
- workflow
- arbejder
- skriver
- dig
- Din
- zephyrnet