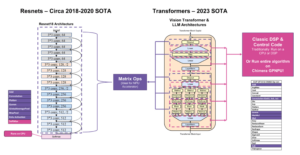
Et teknisk papir med titlen "Massive Data-Centric Parallelism in the Chiplet Era" blev offentliggjort af forskere ved Princeton University.
Abstract:
"Traditionelt udføres massivt parallelle applikationer på distribuerede systemer, hvor computerknudepunkter er tilstrækkeligt fjerne til, at paralleliseringsskemaerne skal minimere kommunikation og synkronisering for at opnå skalerbarhed. Kortlægning af kommunikationsintensive arbejdsbelastninger til distribuerede systemer kræver kompliceret problemopdeling og datasætforbehandling. Med den nuværende AI-drevne trend med at have tusindvis af indbyrdes forbundne processorer pr. chip, er der mulighed for at genoverveje disse kommunikationsflaskehalsede arbejdsbelastninger. Denne flaskehals opstår ofte fra datastrukturgennemgange, som forårsager uregelmæssige hukommelsesadgange og dårlig cache-lokalitet.
Nylige værker har introduceret opgavebaserede paralleliseringsordninger for at accelerere grafgennemgang og andre sparsomme arbejdsbelastninger. Datastrukturgennemgange er opdelt i opgaver og pipelinet på tværs af behandlingsenheder (PU'er). Dalorex demonstrerede den højeste skalerbarhed (op til tusindvis af PU'er på en enkelt chip) ved at have hele datasættet on-chip, spredt på tværs af PU'er og udføre opgaverne på PU'en, hvor dataene er lokale. Men det rejste også spørgsmål om, hvordan man skalerer til større datasæt, når al hukommelsen er på chip, og til hvilken pris.
For at løse disse udfordringer foreslår vi en skalerbar arkitektur, der består af et gitter af Data-Centric Reconfigurable Array (DCRA)-chiplets. Pakketidsomkonfiguration gør det muligt at skabe chipprodukter, der optimerer til forskellige målmålinger, såsom tid-til-løsning, energi eller omkostninger, mens softwareomkonfigurationer undgår netværksmætning, når der skaleres til millioner af PU'er på tværs af mange chippakker. Vi evaluerer seks applikationer og fire datasæt med adskillige konfigurationer og hukommelsesteknologier for at give en detaljeret analyse af ydeevnen, kraften og omkostningerne ved data-lokal eksekvering i skala. Vores parallelisering af Breadth-First-Search med RMAT-26 på tværs af en million PU'er når 3323 GTEPS."
Find det tekniske papir her. Udgivet april 2023 (fortryk).
Orenes-Vera, Marcelo, Esin Tureci, David Wentzlaf og Margaret Martonosi. "Massiv datacentreret parallelisme i Chiplet-æraen." arXiv fortryk arXiv:2304.09389 (2023).
Relaterede
Mini-konsortier, der dannes omkring chips
Kommercielle chiplet-markedspladser er stadig i den fjerne horisont, men virksomheder kommer tidligt i gang med flere kommanditselskaber.
Chiplet-sikkerhedsrisici undervurderet
Størrelsen af sikkerhedsudfordringerne for kommercielle chiplets er skræmmende.
Kapløbet mod blandede støberi-chiplets
Udfordringerne med at samle chiplets fra forskellige støberier er lige begyndt at dukke op.
Designovervejelser og seneste fremskridt i chiplets (UC Berkeley/Peking University)
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Kilde: https://semiengineering.com/data-centric-reconfigurable-array-dcra-chiplets-princeton/
- :er
- :hvor
- $OP
- 2023
- a
- fremskynde
- opnå
- tværs
- adresse
- fremskridt
- Alle
- også
- an
- analyse
- ,
- applikationer
- april
- arkitektur
- ER
- omkring
- Array
- AS
- At
- Begyndelse
- men
- by
- cache
- Årsag
- udfordringer
- chip
- kommerciel
- Kommunikation
- Virksomheder
- kompliceret
- sammensat
- computing
- overvejelser
- Koste
- Oprettelse af
- Nuværende
- data
- datasæt
- David
- demonstreret
- detaljeret
- forskellige
- Fjern
- distribueret
- distribuerede systemer
- Tidligt
- muliggør
- energi
- nok
- Hele
- Era
- evaluere
- udførelse
- udførelse
- Til
- fire
- fra
- få
- graf
- Grid
- Have
- have
- højeste
- horisont
- Hvordan
- How To
- Men
- HTTPS
- in
- sammenkoblet
- ind
- introduceret
- IT
- lige
- større
- Limited
- lokale
- mange
- kortlægning
- markedspladser
- massivt
- Hukommelse
- Metrics
- million
- millioner
- mere
- netværk
- noder
- of
- on
- Opportunity
- Optimer
- or
- Andet
- vores
- pakker
- Papir
- Parallel
- partnerskaber
- Peking
- ydeevne
- plato
- Platon Data Intelligence
- PlatoData
- fattige
- magt
- Princeton
- Problem
- forarbejdning
- processorer
- Produkter
- foreslå
- give
- offentliggjort
- Spørgsmål
- Løb
- hævet
- når
- nylige
- Kræver
- forskere
- risici
- Skalerbarhed
- skalerbar
- Scale
- skalering
- spredt
- ordninger
- sikkerhed
- sikkerhedsrisici
- flere
- enkelt
- SIX
- Software
- delt
- starte
- Stadig
- struktur
- sådan
- synkronisering
- Systemer
- mål
- opgaver
- Teknisk
- Teknologier
- at
- Der.
- Disse
- denne
- tusinder
- titlen
- til
- mod
- Trend
- enheder
- universitet
- var
- we
- Hvad
- som
- mens
- med
- virker
- zephyrnet