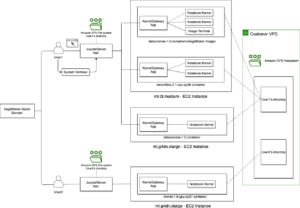
Dette er et fælles indlæg skrevet af AWS og Voxel51. Voxel51 er virksomheden bag FiftyOne, open source-værktøjssættet til opbygning af datasæt af høj kvalitet og computervisionsmodeller.
En detailvirksomhed er ved at bygge en mobilapp for at hjælpe kunder med at købe tøj. For at oprette denne app har de brug for et datasæt af høj kvalitet, der indeholder tøjbilleder, mærket med forskellige kategorier. I dette indlæg viser vi, hvordan man genbruger et eksisterende datasæt via datarensning, forbehandling og præ-mærkning med en nul-skuds klassificeringsmodel i Enoghalvtreds, og justere disse etiketter med Amazon SageMaker Ground Truth.
Du kan bruge Ground Truth og FiftyOne til at fremskynde dit datamærkningsprojekt. Vi illustrerer, hvordan man problemfrit bruger de to applikationer sammen til at skabe mærkede datasæt af høj kvalitet. Til vores eksempel use case arbejder vi med Fashion200K datasæt, udgivet på ICCV 2017.
Løsningsoversigt
Ground Truth er en fuldt selvbetjent og administreret datamærkningstjeneste, der giver dataforskere, maskinlæringsingeniører (ML) og forskere mulighed for at bygge datasæt af høj kvalitet. Enoghalvtreds by Voxel51 er et open source-værktøjssæt til at kurere, visualisere og evaluere datasæt over computervisioner, så du kan træne og analysere bedre modeller ved at accelerere dine use cases.
I de følgende afsnit viser vi, hvordan du gør følgende:
- Visualiser datasættet i FiftyOne
- Rens datasættet med filtrering og billeddeduplikering i FiftyOne
- Formærk de rensede data med nul-skudsklassificering i FiftyOne
- Mærk det mindre kurerede datasæt med Ground Truth
- Injicer mærkede resultater fra Ground Truth i FiftyOne og gennemgå mærkede resultater i FiftyOne
Brug case oversigt
Antag, at du ejer en detailvirksomhed og ønsker at bygge en mobilapplikation til at give personlige anbefalinger for at hjælpe brugerne med at beslutte, hvad de skal have på. Dine potentielle brugere leder efter en applikation, der fortæller dem, hvilke tøjartikler i deres skab der fungerer godt sammen. Du ser en mulighed her: Hvis du kan identificere gode outfits, kan du bruge dette til at anbefale nye tøjartikler, der komplementerer det tøj, en kunde allerede ejer.
Du ønsker at gøre tingene så nemme som muligt for slutbrugeren. Ideelt set behøver nogen, der bruger din applikation, kun at tage billeder af tøjet i deres garderobe, og dine ML-modeller arbejder med deres magi bag kulisserne. Du kan træne en model til generelle formål eller finjustere en model til hver brugers unikke stil med en form for feedback.
Først skal du dog identificere, hvilken type tøj brugeren fanger. Er det en skjorte? Et par bukser? Eller noget andet? Når alt kommer til alt, vil du sandsynligvis ikke anbefale et outfit, der har flere kjoler eller flere hatte.
For at løse denne indledende udfordring vil du generere et træningsdatasæt bestående af billeder af forskellige tøjartikler med forskellige mønstre og stilarter. For at prototype med et begrænset budget, vil du bootstrap ved hjælp af et eksisterende datasæt.
For at illustrere og lede dig gennem processen i dette indlæg, bruger vi Fashion200K-datasættet, der blev udgivet på ICCV 2017. Det er et etableret og velciteret datasæt, men det er ikke direkte egnet til din brugssituation.
Selvom tøjartikler er mærket med kategorier (og underkategorier) og indeholder en række nyttige tags, der er udtrukket fra de originale produktbeskrivelser, er dataene ikke systematisk mærket med mønster- eller stilinformation. Dit mål er at omdanne dette eksisterende datasæt til et robust træningsdatasæt til dine tøjklassificeringsmodeller. Du skal rense dataene og udvide mærkningsskemaet med stiletiketter. Og du vil gerne gøre det hurtigt og med så lidt forbrug som muligt.
Download dataene lokalt
Download først women.tar zip-filen og labels-mappen (med alle dens undermapper) ved at følge instruktionerne i Fashion200K dataset GitHub repository. Når du har pakket dem begge ud, skal du oprette en overordnet mappe fashion200k og flytte etiketterne og kvindemapperne ind i denne. Heldigvis er disse billeder allerede blevet beskåret til objektdetektions afgrænsningsfelter, så vi kan fokusere på klassificering i stedet for at bekymre os om objektdetektering.
På trods af "200K" i dets moniker, indeholder kvindekataloget, vi udpakkede, 338,339 billeder. For at generere det officielle Fashion200K-datasæt gennemgik datasættets forfattere mere end 300,000 produkter online, og kun produkter med beskrivelser indeholdende mere end fire ord klarede snittet. Til vores formål, hvor produktbeskrivelsen ikke er afgørende, kan vi bruge alle de crawlede billeder.
Lad os se på, hvordan disse data er organiseret: i kvindemappen er billeder arrangeret efter artikeltype på øverste niveau (nederdele, toppe, bukser, jakker og kjoler) og artikeltype-underkategori (bluser, t-shirts, langærmede) toppe).
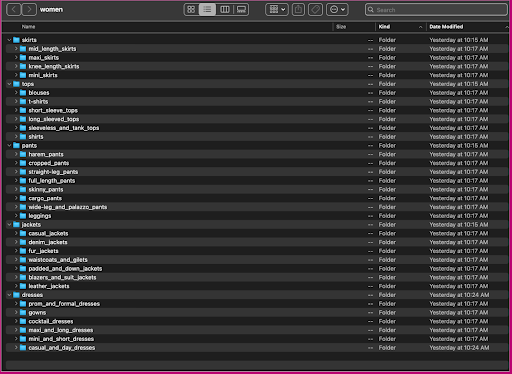
Inden for underkategorikatalogerne er der en undermappe for hver produktliste. Hver af disse indeholder et variabelt antal billeder. Underkategorien cropped_pants indeholder for eksempel følgende produktlister og tilhørende billeder.
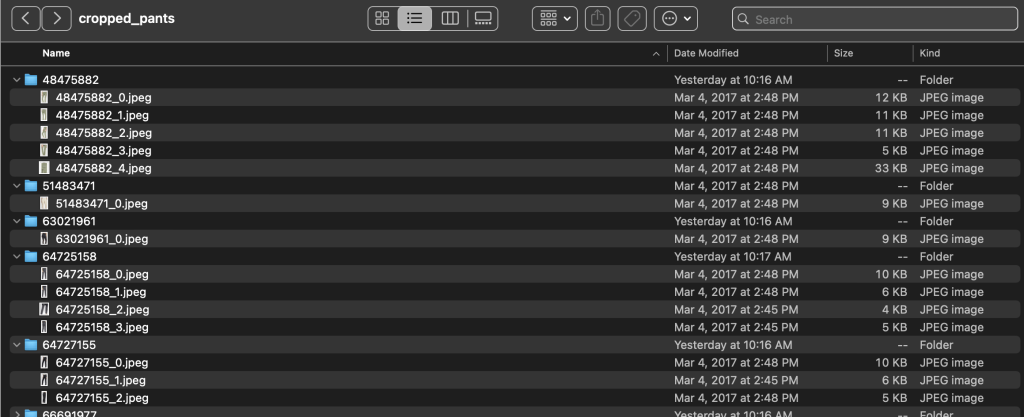
Mappen Etiketter indeholder en tekstfil for hver artikeltype på øverste niveau, for både tog- og testopdelinger. Inden for hver af disse tekstfiler er en separat linje for hvert billede, der angiver den relative filsti, en score og tags fra produktbeskrivelsen.
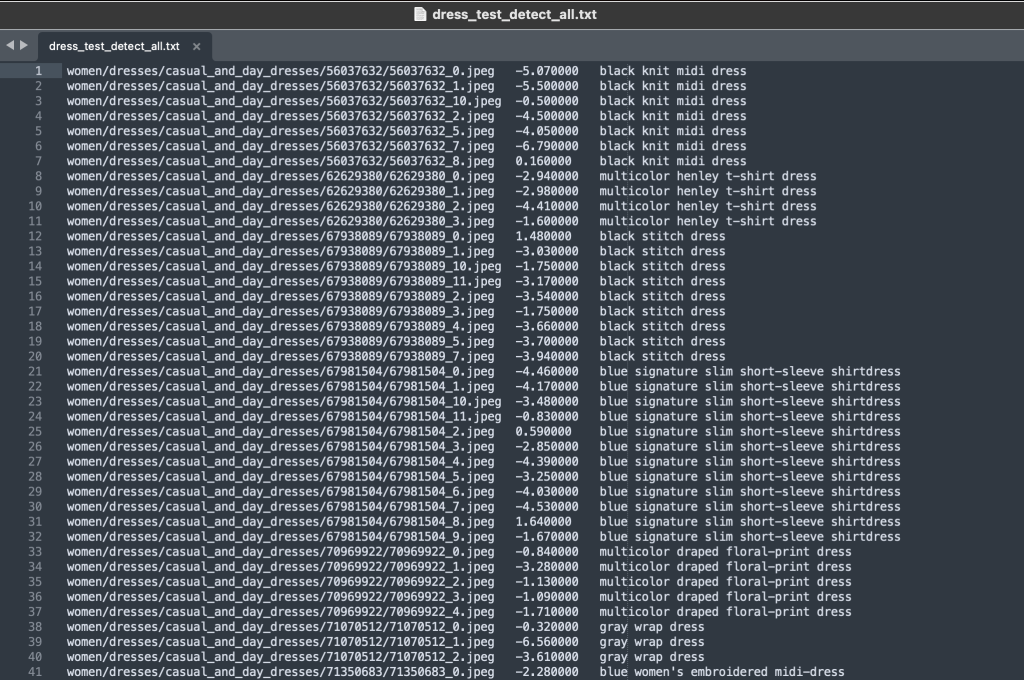
Fordi vi omformåler datasættet, kombinerer vi alle tog- og testbillederne. Vi bruger disse til at generere et applikationsspecifikt datasæt af høj kvalitet. Når vi har fuldført denne proces, kan vi tilfældigt opdele det resulterende datasæt i nye tog- og testopdelinger.
Injicer, se og sammensæt et datasæt i FiftyOne
Hvis du ikke allerede har gjort det, skal du installere open source FiftyOne ved hjælp af pip:
En bedste praksis er at gøre det i et nyt virtuelt (venv eller conda) miljø. Importer derefter de relevante moduler. Importer basisbiblioteket, fiftyone, FiftyOne Brain, som har indbyggede ML-metoder, FiftyOne Zoo, hvorfra vi vil indlæse en model, der vil generere nul-shot-etiketter til os, og ViewField, som lader os effektivt filtrere data i vores datasæt:
Du vil også importere glob- og os Python-modulerne, som vil hjælpe os med at arbejde med stier og mønstermatch over mappeindhold:
Nu er vi klar til at indlæse datasættet i FiftyOne. Først opretter vi et datasæt ved navn fashion200k og gør det persistent, hvilket giver os mulighed for at gemme resultaterne af beregningsintensive operationer, så vi kun behøver at beregne de nævnte mængder én gang.
Vi kan nu iterere gennem alle underkategorikataloger og tilføje alle billederne i produktkatalogerne. Vi tilføjer en FiftyOne-klassificeringsetiket til hver prøve med feltnavnet artikeltype, udfyldt af billedets artikelkategori på øverste niveau. Vi tilføjer også information om både kategori og underkategori som tags:
På dette tidspunkt kan vi visualisere vores datasæt i FiftyOne-appen ved at starte en session:
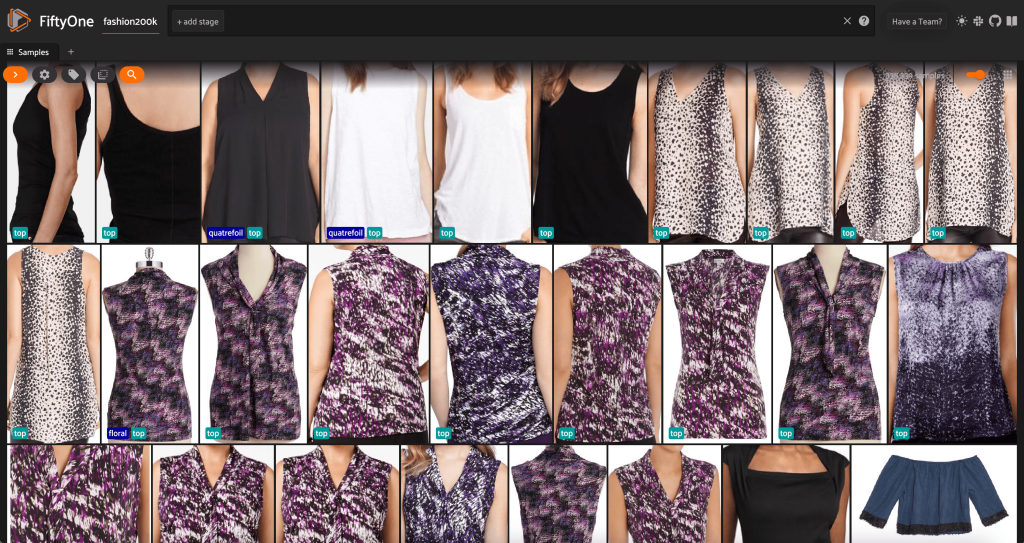
Vi kan også udskrive en oversigt over datasættet i Python ved at køre print(dataset):
Vi kan også tilføje tags fra labels mappe til prøverne i vores datasæt:
Når man ser på dataene, bliver et par ting klart:
- Nogle af billederne er ret kornede med lav opløsning. Dette skyldes sandsynligvis, at disse billeder blev genereret ved at beskære indledende billeder i afgrænsningsfelter for objektdetektering.
- Noget tøj bæres af en person, og noget er fotograferet på egen hånd. Disse detaljer er indkapslet af
viewpointejendom. - Mange af billederne af det samme produkt er meget ens, så i det mindste til at begynde med, at inkludere mere end ét billede pr. produkt, tilføjer måske ikke meget forudsigelseskraft. For det meste er det første billede af hvert produkt (ender på
_0.jpeg) er den reneste.
I første omgang vil vi måske træne vores tøjstilklassificeringsmodel på en kontrolleret delmængde af disse billeder. Til dette formål bruger vi billeder i høj opløsning af vores produkter og begrænser vores visning til én repræsentativ prøve pr. produkt.
Først filtrerer vi billederne i lav opløsning fra. Vi bruger compute_metadata() metode til at beregne og gemme billedbredde og -højde i pixels for hvert billede i datasættet. Vi bruger derefter FiftyOne ViewField at filtrere billeder fra baseret på de mindst tilladte bredde- og højdeværdier. Se følgende kode:
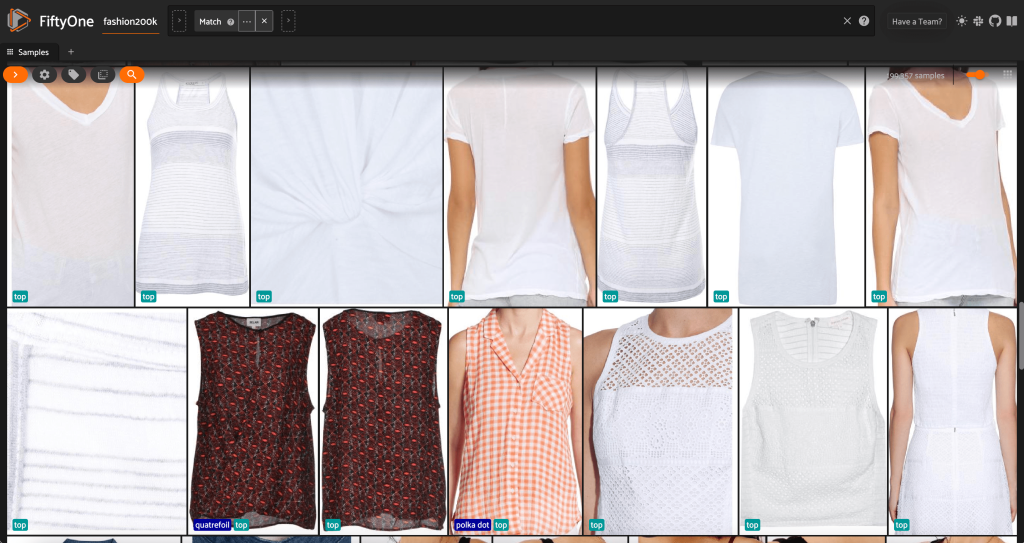
Denne højopløselige delmængde har lige under 200,000 prøver.
Fra denne visning kan vi oprette en ny visning i vores datasæt, der kun indeholder én repræsentativ prøve (højst) for hvert produkt. Vi bruger ViewField endnu en gang, mønstermatchning for filstier, der ender med _0.jpeg:
Lad os se en tilfældigt blandet rækkefølge af billeder i denne undergruppe:
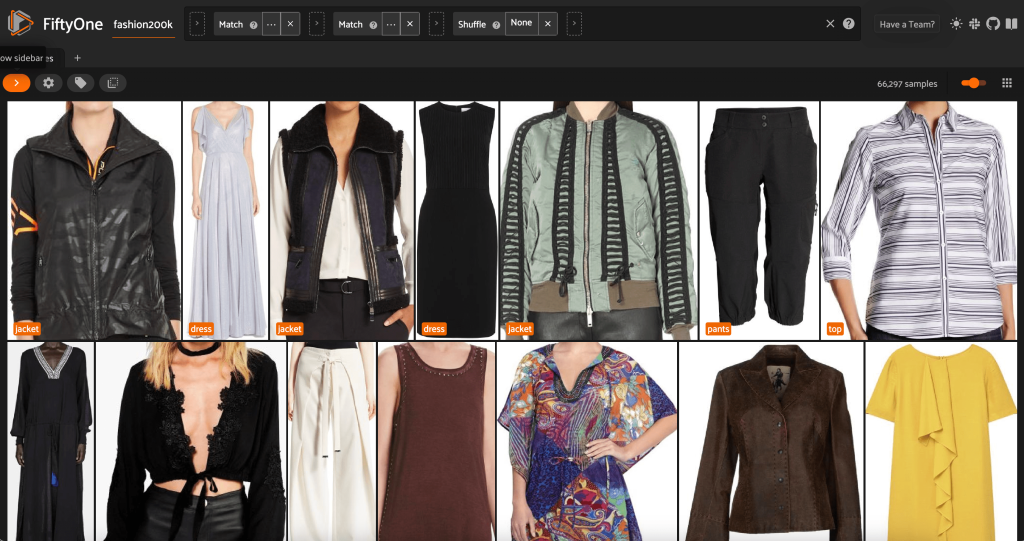
Fjern overflødige billeder i datasættet
Denne visning indeholder 66,297 billeder eller lidt over 19% af det originale datasæt. Når vi ser på udsigten, ser vi dog, at der er mange meget lignende produkter. At beholde alle disse kopier vil sandsynligvis kun øge omkostningerne til vores mærkning og modeltræning uden at forbedre ydeevnen mærkbart. Lad os i stedet slippe af med de næsten dubletter for at skabe et mindre datasæt, der stadig pakker den samme punch.
Fordi disse billeder ikke er nøjagtige dubletter, kan vi ikke kontrollere for pixelmæssig lighed. Heldigvis kan vi bruge FiftyOne-hjernen til at hjælpe os med at rense vores datasæt. Især vil vi beregne en indlejring for hvert billede - en lavere dimensionel vektor, der repræsenterer billedet - og derefter kigge efter billeder, hvis indlejringsvektorer er tæt på hinanden. Jo tættere vektorerne er, jo mere ens billederne.
Vi bruger en CLIP-model til at generere en 512-dimensionel indlejringsvektor for hvert billede og gemmer disse indlejringer i feltindlejringerne på prøverne i vores datasæt:
Derefter beregner vi nærheden mellem indlejringer ved hjælp af cosinus lighedog hævder, at alle to vektorer, hvis lighed er større end en eller anden tærskel, sandsynligvis er tæt på dubletter. Cosinus-lighedsscorer ligger i området [0, 1], og ser man på dataene, ser en tærskelscore på tærskel=0.5 ud til at være nogenlunde rigtig. Igen, dette behøver ikke at være perfekt. Nogle få næsten-duplikerede billeder vil sandsynligvis ikke ødelægge vores forudsigelsesevne, og at smide et par ikke-duplikerede billeder væk påvirker ikke modellens ydeevne væsentligt.
Vi kan se de påståede dubletter for at bekræfte, at de faktisk er overflødige:
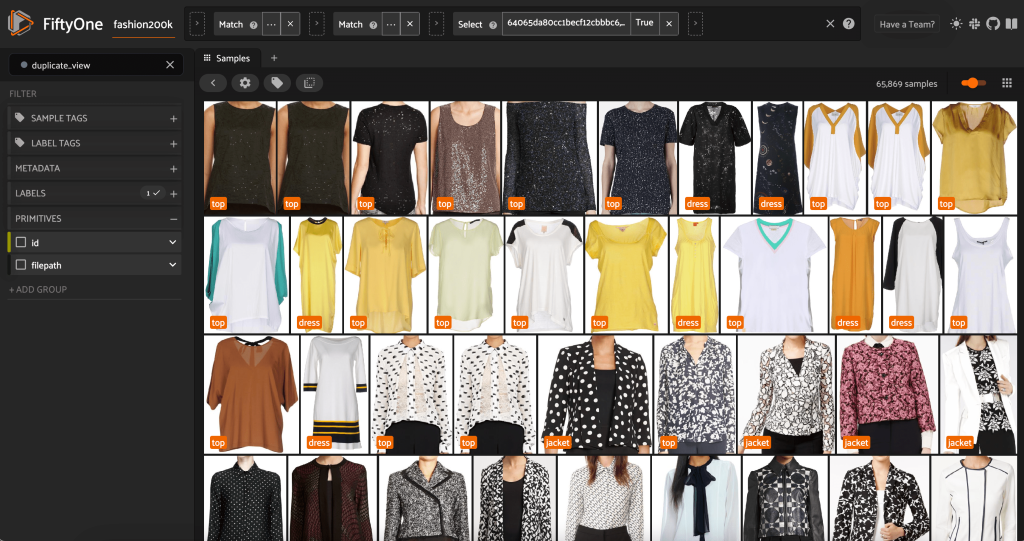
Når vi er tilfredse med resultatet og mener, at disse billeder faktisk er næsten dubletter, kan vi vælge en prøve fra hvert sæt af lignende prøver at beholde, og ignorere de andre:
Nu har denne visning 3,729 billeder. Ved at rense dataene og identificere et højkvalitetsundersæt af Fashion200K-datasættet lader FiftyOne os begrænse vores fokus fra mere end 300,000 billeder til lige under 4,000, hvilket repræsenterer en reduktion på 98 %. Alene brugen af indlejringer til at fjerne næsten duplikerede billeder bragte vores samlede antal billeder under overvejelse ned med mere end 90 %, med ringe om nogen effekt på nogen modeller, der skulle trænes på disse data.
Før vi præ-mærker denne delmængde, kan vi bedre forstå dataene ved at visualisere de indlejringer, vi allerede har beregnet. Vi kan bruge FiftyOne Brain's indbyggede compute_visualization() metode, som anvender uniform manifold approksimation (UMAP) teknik til at projicere de 512-dimensionelle indlejringsvektorer ind i todimensionelt rum, så vi kan visualisere dem:
Vi åbner en ny Indstøbningspanel i FiftyOne-appen og farvelægning efter artikeltype, og vi kan se, at disse indlejringer nogenlunde koder for en forestilling om artikeltype (blandt andet!).
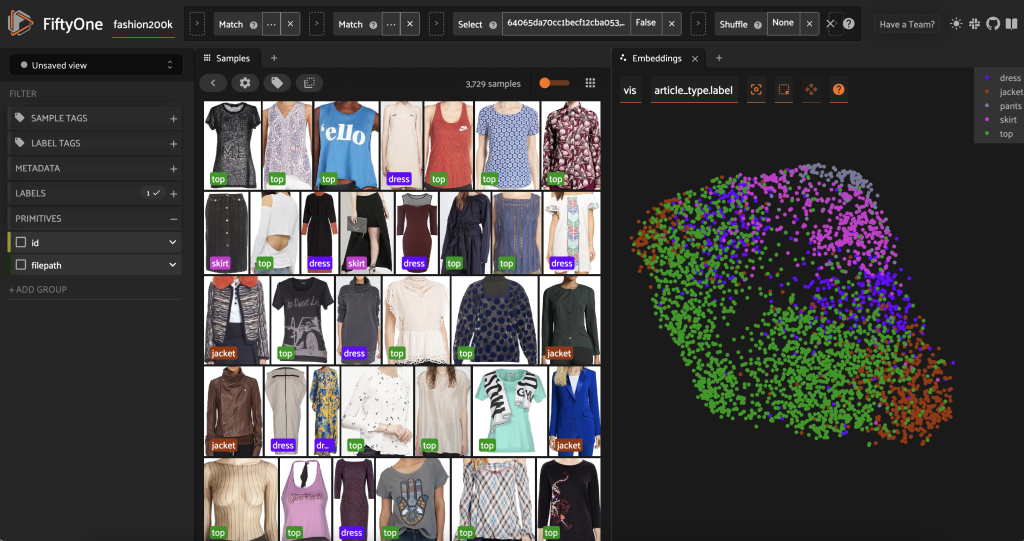
Nu er vi klar til at præmærke disse data.
Ved at inspicere disse meget unikke billeder i høj opløsning, kan vi generere en anstændig indledende liste over stilarter til brug som klasser i vores præ-mærkning nul-shot klassificering. Vores mål med at præ-mærke disse billeder er ikke nødvendigvis at mærke hvert billede korrekt. Vores mål er snarere at give et godt udgangspunkt for menneskelige annotatorer, så vi kan reducere mærkningstiden og -omkostningerne.
Vi kan derefter instansiere en nul-skuds klassificeringsmodel for denne applikation. Vi bruger en CLIP-model, som er en generel model, der er trænet i både billeder og naturligt sprog. Vi instansierer en CLIP-model med tekstprompten "Tøj i stilen", så givet et billede, vil modellen udskrive den klasse, som "Tøj i stilen [klasse]" passer bedst til. CLIP er ikke uddannet i detail- eller modespecifikke data, så dette vil ikke være perfekt, men det kan spare dig i mærknings- og annoteringsomkostninger.
Vi anvender derefter denne model på vores reducerede delmængde og gemmer resultaterne i en article_style Mark:
Ved at lancere FiftyOne-appen igen kan vi visualisere billederne med disse forudsagte stiletiketter. Vi sorterer efter forudsigelsestillid, så vi ser de mest sikre stilforudsigelser først:
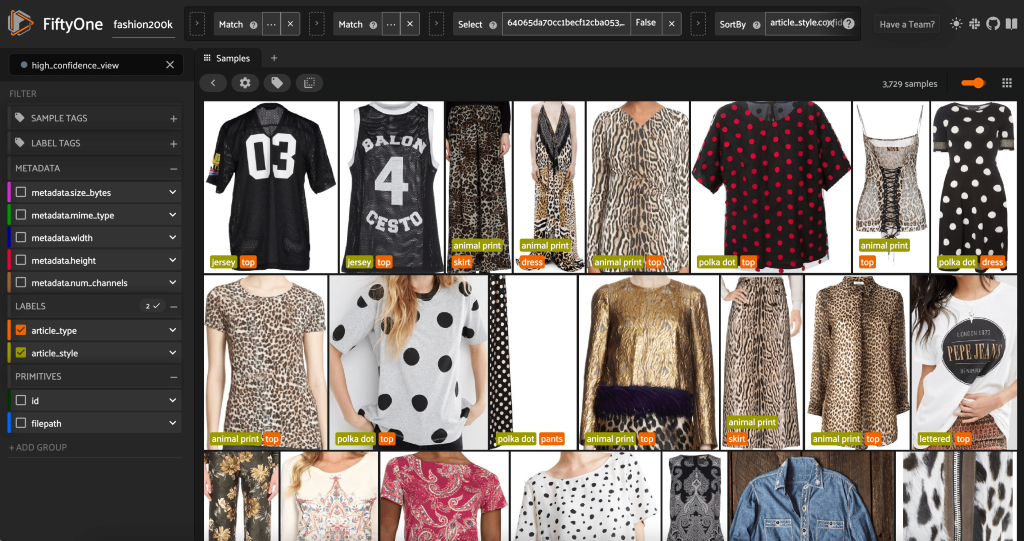
Vi kan se, at de højeste tillidsforudsigelser synes at være for "jersey", "dyretryk", "prikker" og "bogstaver". Dette giver mening, fordi disse stilarter er relativt forskellige. Det ser også ud til, at de forudsagte stiletiketter for det meste er nøjagtige.
Vi kan også se på stilforudsigelserne med den laveste tillid:
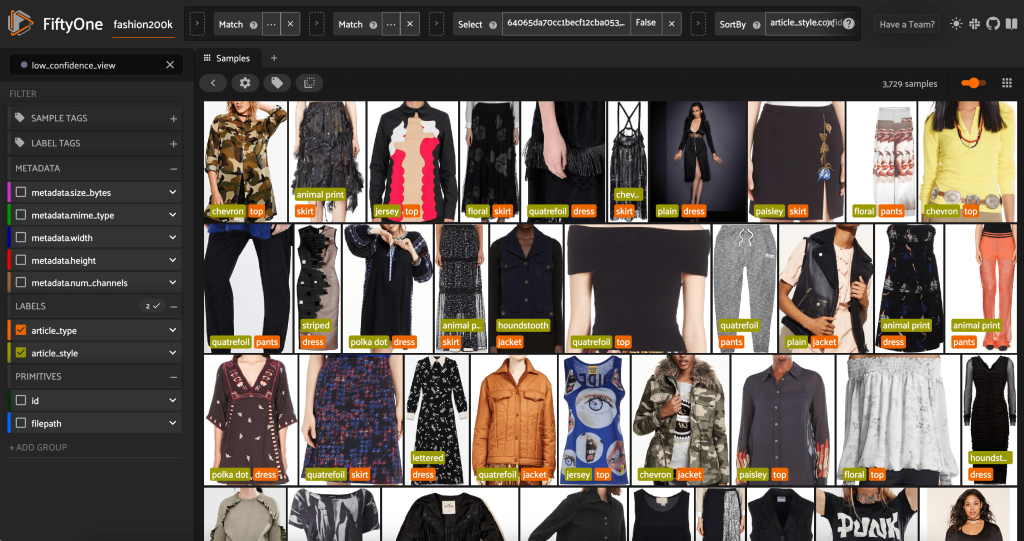
For nogle af disse billeder er den passende stilkategori på den medfølgende liste, og beklædningsgenstanden er forkert mærket. Det første billede i gitteret skal for eksempel klart være "camouflage" og ikke "chevron". I andre tilfælde passer produkterne dog ikke pænt ind i stilkategorierne. Kjolen på det andet billede i anden række er for eksempel ikke ligefrem "stribet", men givet de samme mærkningsmuligheder, kan en menneskelig annotator også have været i konflikt. Når vi bygger vores datasæt ud, skal vi beslutte, om vi skal fjerne kanttilfælde som disse, tilføje nye stilkategorier eller udvide datasættet.
Eksporter det endelige datasæt fra FiftyOne
Eksporter det endelige datasæt med følgende kode:
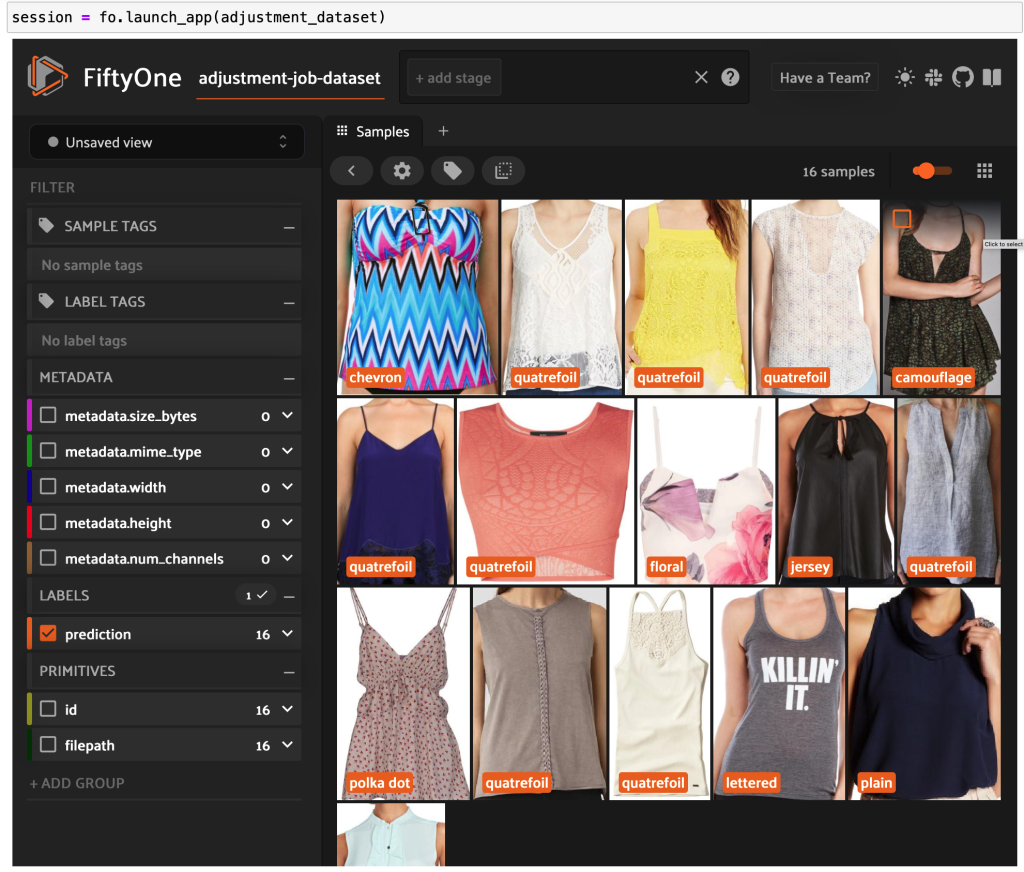
Vi kan eksportere et mindre datasæt, for eksempel 16 billeder, til mappen 200kFashionDatasetExportResult-16Images. Vi opretter et Ground Truth-justeringsjob ved at bruge det:
Upload det reviderede datasæt, konverter etiketformatet til Ground Truth, upload til Amazon S3, og opret en manifestfil til justeringsjobbet
Vi kan konvertere etiketterne i datasættet til at matche output manifest skema af et Ground Truth bounding box job, og upload billederne til en Amazon Simple Storage Service (Amazon S3) spand til at lancere en Ground Truth justeringsjob:
Upload manifestfilen til Amazon S3 med følgende kode:
Opret korrigerede stylede etiketter med Ground Truth
For at annotere dine data med stiletiketter ved hjælp af Ground Truth, skal du fuldføre de nødvendige trin for at starte et afgrænsningsfeltetiketteringsjob ved at følge proceduren, der er beskrevet i Kom godt i gang med Ground Truth guide med datasættet i samme S3-spand.
- På SageMaker-konsollen skal du oprette et Ground Truth-mærkningsjob.
- Indstil Indtast datasætplacering at være det manifest, som vi skabte i de foregående trin.
- Angiv en S3-sti til Outputdatasæts placering.
- Til IAM rolle, vælg Indtast en tilpasset IAM-rolle ARN, indtast derefter rollen ARN.
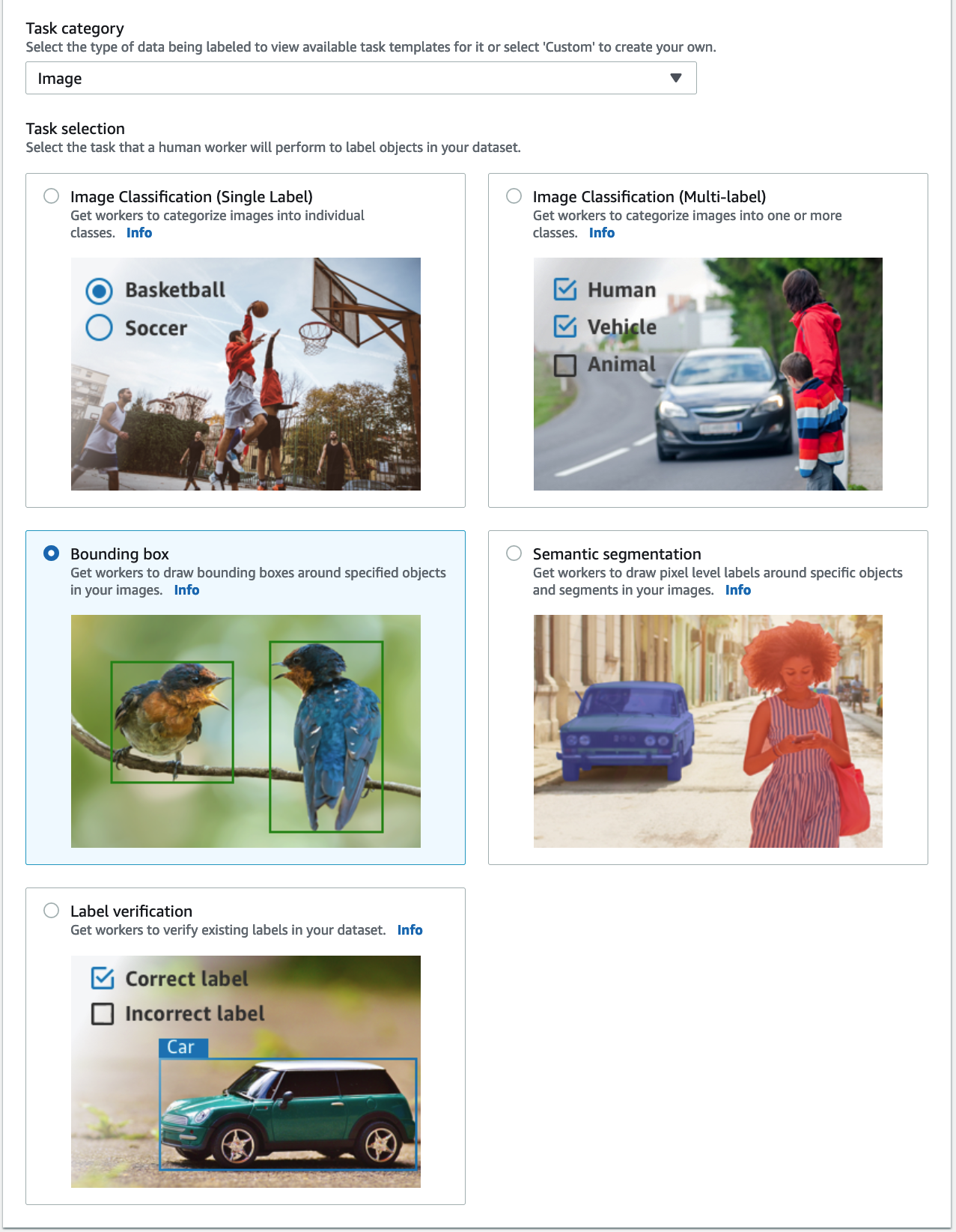
- Til Opgavekategori, vælg Billede og vælg Afgrænsningskasse.
- Vælg Næste.
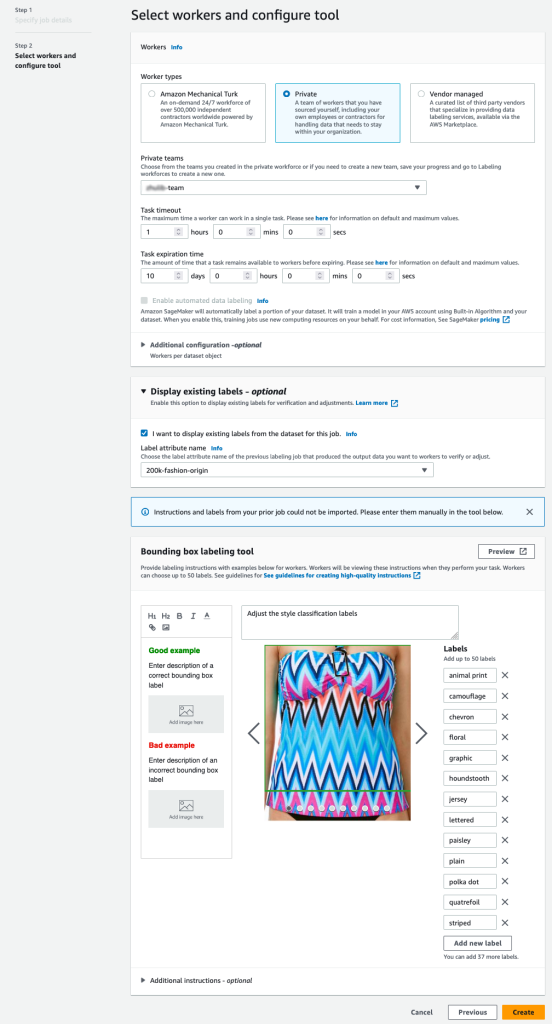
- I Arbejdere skal du vælge den type arbejdsstyrke, du gerne vil bruge.
Du kan vælge en arbejdsstyrke igennem Amazon Mechanical Turk, tredjepartsleverandører eller din egen private arbejdsstyrke. For flere detaljer om dine muligheder for arbejdsstyrke, se Opret og administrer arbejdsstyrker. - Udvid Visningsmuligheder for eksisterende etiketter og vælg Jeg ønsker at vise eksisterende etiketter fra datasættet for dette job.
- Til Etiketattribut navn, skal du vælge det navn fra dit manifest, der svarer til de etiketter, du vil vise til justering.
Du vil kun se etiketattributnavne for etiketter, der matcher den opgavetype, du valgte i de foregående trin. - Indtast manuelt etiketterne for Afgrænsningsboksmærkningsværktøj.
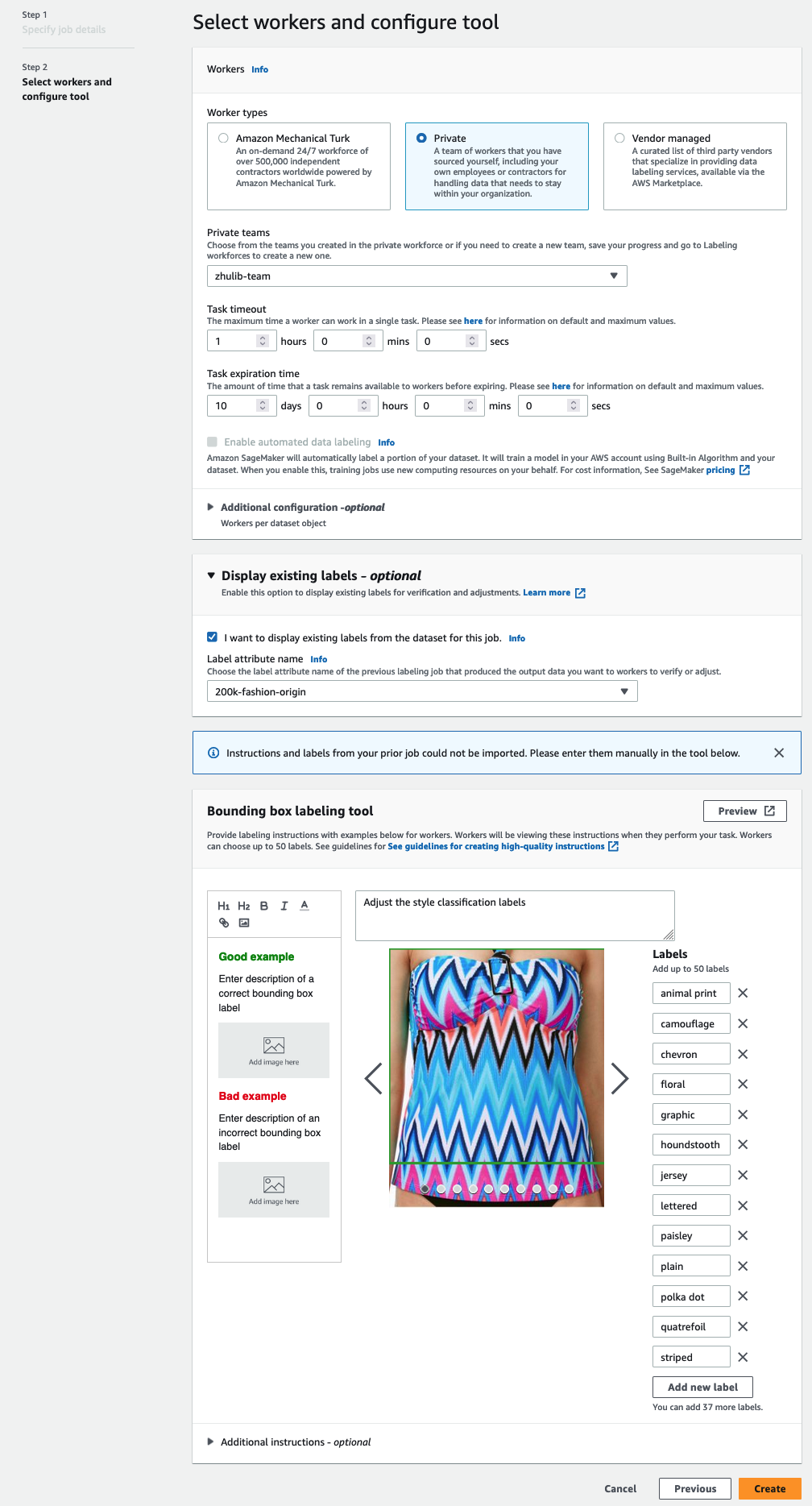 Etiketterne skal indeholde de samme etiketter, som bruges i det offentlige datasæt. Du kan tilføje nye etiketter. Følgende skærmbillede viser, hvordan du kan vælge arbejdere og konfigurere værktøjet til dit etiketteringsjob.
Etiketterne skal indeholde de samme etiketter, som bruges i det offentlige datasæt. Du kan tilføje nye etiketter. Følgende skærmbillede viser, hvordan du kan vælge arbejdere og konfigurere værktøjet til dit etiketteringsjob.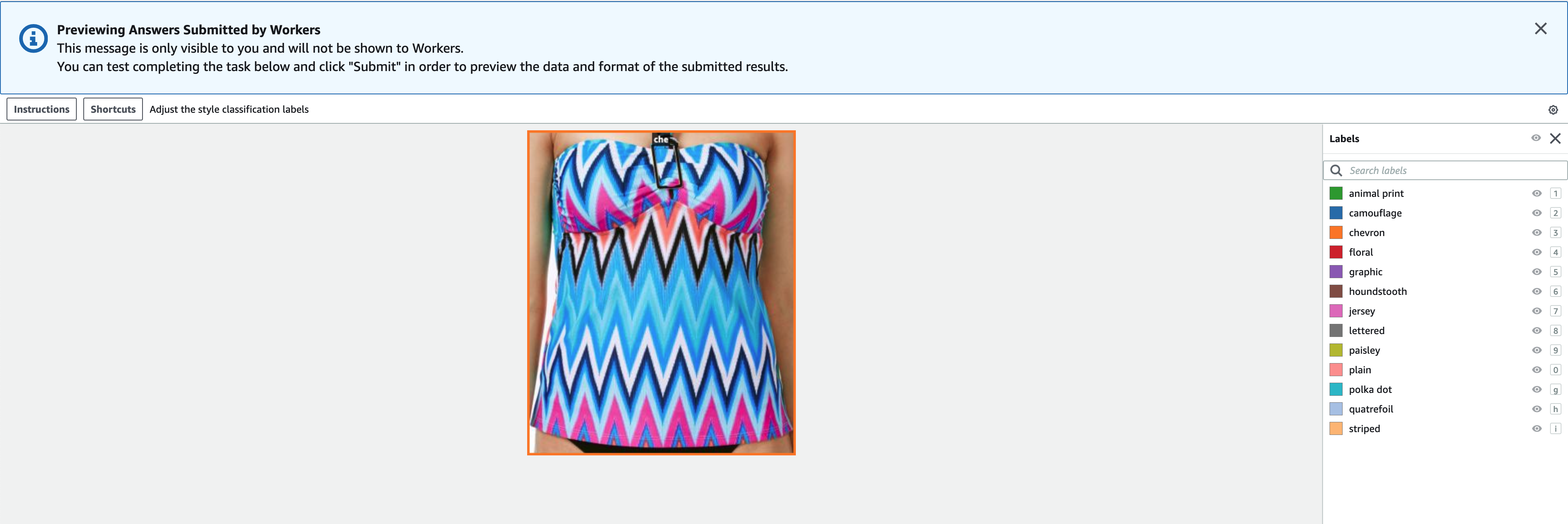
- Vælg Eksempel for at få vist billedet og originale anmærkninger.
Vi har nu oprettet et mærkningsjob i Ground Truth. Når vores job er fuldført, kan vi indlæse de nyligt genererede mærkede data i FiftyOne. Ground Truth producerer outputdata i et Ground Truth outputmanifest. For flere detaljer om output-manifestfilen, se Bounding Box Job Output. Følgende kode viser et eksempel på dette output-manifestformat:
Gennemgå mærkede resultater fra Ground Truth i FiftyOne
Når jobbet er fuldført, skal du downloade outputmanifestet for mærkningsjobbet fra Amazon S3.
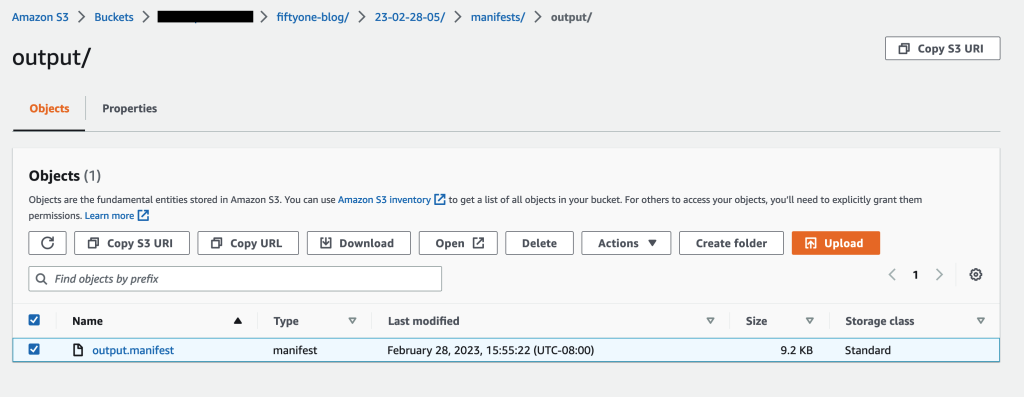
Læs outputmanifestfilen:
Opret et FiftyOne-datasæt og konverter manifestlinjerne til prøver i datasættet:
Du kan nu se mærkede data af høj kvalitet fra Ground Truth i FiftyOne.
Konklusion
I dette indlæg viste vi, hvordan man opbygger datasæt af høj kvalitet ved at kombinere kraften i Enoghalvtreds by Voxel51, et open source-værktøjssæt, der giver dig mulighed for at administrere, spore, visualisere og kurere dit datasæt, og Ground Truth, en datamærkningstjeneste, der giver dig mulighed for effektivt og præcist at mærke de datasæt, der kræves til træning af ML-systemer, ved at give adgang til flere indbyggede -i opgaveskabeloner og adgang til en mangfoldig arbejdsstyrke gennem Mechanical Turk, tredjepartsleverandører eller din egen private arbejdsstyrke.
Vi opfordrer dig til at prøve denne nye funktionalitet ved at installere en FiftyOne-instans og bruge Ground Truth-konsollen til at komme i gang. For at lære mere om Ground Truth, se Etiketdata, Ofte stillede spørgsmål om Amazon SageMaker-datamærkning, og AWS Machine Learning Blog.
Opret forbindelse til Machine Learning & AI-fællesskab hvis du har spørgsmål eller feedback!
Tilmeld dig FiftyOne-fællesskabet!
Slut dig til de tusindvis af ingeniører og dataforskere, der allerede bruger FiftyOne til at løse nogle af de mest udfordrende problemer inden for computersyn i dag!
Om forfatterne
Shalendra Chhabra er i øjeblikket Head of Product Management for Amazon SageMaker Human-in-the-Loop (HIL) Services. Tidligere inkuberede og ledede Shalendra Language and Conversational Intelligence til Microsoft Teams Meetings, var EIR hos Amazon Alexa Techstars Startup Accelerator, VP of Product and Marketing hos Diskuter.io, Head of Product and Marketing hos Clipboard (erhvervet af Salesforce) og Lead Product Manager hos Swype (erhvervet af Nuance). I alt har Shalendra hjulpet med at bygge, sende og markedsføre produkter, der har rørt mere end en milliard liv.
Jacob Marks er Machine Learning Engineer og Developer Evangelist hos Voxel51, hvor han hjælper med at bringe gennemsigtighed og klarhed til verdens data. Før han kom til Voxel51, grundlagde Jacob en startup for at hjælpe nye musikere med at forbinde og dele kreativt indhold med fans. Før det arbejdede han hos Google X, Samsung Research og Wolfram Research. I et tidligere liv var Jacob en teoretisk fysiker, og afsluttede sin ph.d.-grad på Stanford, hvor han undersøgte kvantefaser af stof. I sin fritid nyder Jacob at klatre, løbe og læse science fiction-romaner.
Jason Corso er medstifter og administrerende direktør for Voxel51, hvor han styrer strategien for at hjælpe med at bringe gennemsigtighed og klarhed til verdens data gennem state-of-the-art fleksibel software. Han er også professor i robotteknologi, elektroteknik og datalogi ved University of Michigan, hvor han fokuserer på banebrydende problemer i krydsfeltet mellem computersyn, naturligt sprog og fysiske platforme. I sin fritid nyder Jason at bruge tid med sin familie, læse, være i naturen, spille brætspil og alle mulige kreative aktiviteter.
Brian Moore er medstifter og CTO for Voxel51, hvor han leder teknisk strategi og vision. Han har en ph.d. i elektroteknik fra University of Michigan, hvor hans forskning var fokuseret på effektive algoritmer til maskinlæringsproblemer i stor skala, med særlig vægt på computersynsapplikationer. I sin fritid nyder han badminton, golf, vandreture og at lege med sine tvillinger Yorkshire Terriers.
Zhuling Bai er softwareudviklingsingeniør hos Amazon Web Services. Hun arbejder på at udvikle distribuerede systemer i stor skala til at løse maskinlæringsproblemer.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Køb og sælg aktier i PRE-IPO-virksomheder med PREIPO®. Adgang her.
- Kilde: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :har
- :er
- :ikke
- :hvor
- $OP
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Om
- fremskynde
- accelererende
- accelerator
- adgang
- præcis
- præcist
- erhvervede
- aktiviteter
- tilføje
- tilføje
- adresse
- Justeret
- Justering
- Efter
- igen
- AI
- Alexa
- algoritmer
- Alle
- tillader
- alene
- allerede
- også
- Amazon
- Amazon alexa
- Amazon SageMaker
- Amazon SageMaker Ground Truth
- Amazon Web Services
- blandt
- an
- analysere
- ,
- dyr
- enhver
- app
- Anvendelse
- applikationer
- Indløs
- passende
- ER
- anbragt
- artikel
- artikler
- AS
- forbundet
- At
- forfattere
- væk
- AWS
- bund
- baseret
- BE
- fordi
- bliver
- været
- før
- bag
- bag scenen
- være
- Tro
- BEDSTE
- Bedre
- mellem
- Billion
- board
- Brætspil
- KNOGLE
- Bootstrap
- både
- Boks
- kasser
- Brain
- Pause
- bringe
- bragte
- budget
- bygge
- Bygning
- indbygget
- men
- købe
- by
- CAN
- Optagelse
- tilfælde
- tilfælde
- kategorier
- Boligtype
- Direktør
- udfordre
- udfordrende
- kontrollere
- Vælg
- klarhed
- klasse
- klasser
- klassificering
- Rengøring
- klar
- tydeligt
- kunde
- Klatring
- Luk
- tættere
- tøj
- Tøj
- Medstifter
- kode
- kombinerer
- kombinerer
- selskab
- komplement
- fuldføre
- færdiggøre
- Compute
- computer
- Datalogi
- Computer Vision
- Computer Vision applikationer
- tillid
- sikker
- Tilslut
- overvejelse
- Bestående
- Konsol
- indeholder
- indhold
- indhold
- kontrolleret
- konversation
- konvertere
- kopier
- Core
- korrigeret
- svarer
- Koste
- Omkostninger
- skabe
- oprettet
- Kreativ
- Legitimationsoplysninger
- CTO
- kurateret
- curating
- For øjeblikket
- skik
- kunde
- Kunder
- Klip
- banebrydende
- data
- datasæt
- beslutte
- demonstrere
- Denim
- dybde
- beskrivelse
- detaljer
- Detektion
- Udvikler
- udvikling
- Udvikling
- forskellige
- direkte
- mapper
- Skærm
- distinkt
- distribueret
- distribuerede systemer
- forskelligartede
- do
- Er ikke
- Dog
- gør
- færdig
- Dont
- DOT
- ned
- downloade
- dubletter
- e
- hver
- let
- Edge
- effekt
- effektiv
- effektivt
- Elektroteknik
- indlejring
- smergel
- vægt
- beskæftiger
- bemyndiger
- indkapslet
- tilskynde
- ende
- ingeniør
- Engineering
- Ingeniører
- Indtast
- Miljø
- lighed
- væsentlig
- etableret
- Ether (ETH)
- evaluere
- Evangelist
- præcist nok
- eksempel
- eksisterende
- eksport
- retfærdigt
- familie
- fans
- tilbagemeldinger
- få
- Fiktion
- felt
- Fields
- File (Felt)
- Filer
- filtrere
- filtrering
- endelige
- Fornavn
- passer
- fleksibel
- Fokus
- fokuserede
- fokuserer
- efter
- Til
- formular
- format
- Heldigvis
- Grundlagt
- fire
- Gratis
- fra
- fuldt ud
- funktionalitet
- Spil
- generelle formål
- generere
- genereret
- få
- GitHub
- Giv
- given
- mål
- golf
- godt
- større
- Grid
- Ground
- gruppe
- vejlede
- Gem
- Have
- he
- hoved
- højde
- hjælpe
- hjulpet
- hjælpsom
- hjælper
- link.
- høj kvalitet
- høj opløsning
- højeste
- stærkt
- hiking
- hans
- besidder
- Hvordan
- How To
- Men
- HTML
- http
- HTTPS
- menneskelig
- i
- IAM
- ID
- identificere
- identificere
- id'er
- if
- billede
- billeder
- KIMOs Succeshistorier
- importere
- forbedring
- in
- I andre
- Herunder
- forkert
- inkuberet
- oplysninger
- initial
- i første omgang
- installere
- installation
- instans
- i stedet
- anvisninger
- Intelligens
- vejkryds
- ind
- IT
- ITS
- Jersey
- Job
- sammenføjning
- fælles
- json
- lige
- Holde
- holde
- etiket
- mærkning
- Etiketter
- Sprog
- storstilet
- lancere
- lancering
- føre
- Leads
- LÆR
- læring
- mindst
- Led
- til venstre
- Lets
- Bibliotek
- Livet
- ligesom
- Sandsynlig
- GRÆNSE
- Limited
- Line (linje)
- linjer
- Liste
- notering
- Listings
- lidt
- Lives
- belastning
- Se
- leder
- Lot
- Lav
- maskine
- machine learning
- lavet
- Magic
- lave
- maerker
- administrere
- lykkedes
- ledelse
- leder
- mange
- kort
- Marked
- Marketing
- Match
- matchende
- materielt
- Matter
- Kan..
- mekanisk
- Medier
- møder
- Meta
- Metadata
- metode
- metoder
- Michigan
- microsoft
- microsoft teams
- måske
- minimum
- ML
- Mobil
- Mobil app
- model
- modeller
- Moduler
- mere
- mest
- bevæge sig
- meget
- flere
- musikere
- skal
- navn
- Som hedder
- navne
- Natural
- Naturligt sprog
- Natur
- I nærheden af
- nødvendigvis
- nødvendig
- Behov
- behov
- Ny
- mærkbart
- Begreb
- nu
- Nuance
- nummer
- objekt
- Objektdetektion
- objekter
- of
- officiel
- on
- engang
- ONE
- online
- kun
- åbent
- open source
- Produktion
- Opportunity
- Indstillinger
- or
- Organiseret
- original
- OS
- Andet
- Andre
- vores
- ud
- skitseret
- output
- i løbet af
- egen
- ejer
- Packs
- parret
- del
- særlig
- forbi
- sti
- Mønster
- mønstre
- perfekt
- ydeevne
- person,
- Personlig
- Materiens faser
- fysisk
- pick
- Billeder
- PLAID
- Almindeligt
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- spiller
- Punkt
- befolkede
- mulig
- Indlæg
- magt
- praksis
- forudsagde
- forudsigelse
- Forudsigelser
- Eksempel
- tidligere
- tidligere
- Forud
- private
- sandsynligvis
- problemer
- behandle
- Produkt
- produktstyring
- produktchef
- Produkter
- Professor
- projekt
- ejendom
- prospektive
- prototype
- give
- forudsat
- leverer
- offentlige
- slag
- formål
- Python
- Quantum
- Spørgsmål
- hurtigt
- rækkevidde
- hellere
- Læsning
- klar
- anbefaler
- anbefalinger
- reducere
- Reduceret
- reduktion
- relativt
- frigivet
- relevant
- Fjern
- repræsentativt
- repræsenterer
- påkrævet
- forskning
- forskere
- Løsning
- begrænse
- resultere
- resulterer
- Resultater
- detail
- afkast
- gennemgå
- Rid
- robotteknik
- robust
- roller
- groft
- RÆKKE
- ruin
- kører
- sagemaker
- Said
- salgsstyrke
- samme
- Samsung
- Gem
- scener
- Videnskab
- Science Fiction
- forskere
- score
- problemfrit
- Anden
- Sektion
- sektioner
- se
- synes
- synes
- valgt
- forstand
- adskille
- tjeneste
- Tjenester
- Session
- sæt
- Del
- hun
- bør
- Vis
- Shows
- JA
- lignende
- Simpelt
- mindre
- So
- Software
- softwareudvikling
- SOLVE
- nogle
- Nogen
- noget
- Space
- tilbringe
- udgifterne
- delt
- splits
- Stanford
- starte
- påbegyndt
- Starter
- opstart
- opstart accelerator
- state-of-the-art
- Steps
- Stadig
- opbevaring
- butik
- Strategi
- stil
- stilarter
- RESUMÉ
- Understøttet
- Systemer
- Tag
- Opgaver
- hold
- Teknisk
- techstars
- fortæller
- skabeloner
- prøve
- end
- at
- deres
- Them
- derefter
- teoretisk
- Der.
- Disse
- de
- ting
- tror
- tredjepart
- denne
- tusinder
- tærskel
- Gennem
- Kaste
- tid
- til
- sammen
- værktøj
- toolkit
- top
- øverste niveau
- Toppe
- I alt
- rørt
- spor
- Tog
- uddannet
- Kurser
- Transform
- Gennemsigtighed
- sand
- Sandheden
- TUR
- to
- typen
- typer
- under
- forstå
- enestående
- universitet
- University of Michigan
- Opdatering
- us
- brug
- brug tilfælde
- anvendte
- Bruger
- brugere
- ved brug af
- Værdier
- række
- forskellige
- leverandører
- verificere
- meget
- via
- Specifikation
- Virtual
- vision
- ønsker
- var
- we
- web
- webservices
- GODT
- var
- Hvad
- hvornår
- hvorvidt
- som
- Wikipedia
- vilje
- med
- inden for
- uden
- Dame
- ord
- Arbejde
- arbejdede
- arbejdere
- Workforce
- virker
- Verdens
- bekymre sig
- ville
- skriver
- X
- dig
- Din
- zephyrnet
- Zip
- ZOO