Billede af forfatter
Når du dykker ned i en verden af datavidenskab og maskinlæring, er en af de grundlæggende færdigheder, du vil møde, kunsten at læse data. Hvis du allerede har lidt erfaring med det, er du sikkert bekendt med JSON (JavaScript Object Notation) – et populært format til både lagring og udveksling af data.
Tænk på, hvordan NoSQL-databaser som MongoDB elsker at gemme data i JSON, eller hvordan REST API'er ofte reagerer i samme format.
Men selvom JSON er perfekt til opbevaring og udveksling, er den ikke helt klar til dybdegående analyse i sin rå form. Det er her, vi forvandler det til noget mere analytisk venligt – et tabelformat.
Så uanset om du har at gøre med et enkelt JSON-objekt eller en dejlig række af dem, i Pythons termer, håndterer du i det væsentlige en diktat eller en liste over diktater.
Lad os sammen undersøge, hvordan denne transformation udfolder sig, hvilket gør vores data modne til analyse ????
I dag vil jeg forklare en magisk kommando, der giver os mulighed for nemt at parse enhver JSON til et tabelformat på få sekunder.
Og det er... pd.json_normalize()
Så lad os se, hvordan det virker med forskellige typer JSON'er.
Den første type JSON, som vi kan arbejde med, er JSON'er på et niveau med nogle få nøgler og værdier. Vi definerer vores første simple JSON'er som følger:
Kode efter forfatter
Så lad os simulere behovet for at arbejde med disse JSON. Vi ved alle, at der ikke er meget at gøre i deres JSON-format. Vi er nødt til at transformere disse JSON'er til et eller andet læsbart og modificerbart format... hvilket betyder Pandas DataFrames!
1.1 Håndtering af simple JSON-strukturer
Først skal vi importere pandas-biblioteket, og derefter kan vi bruge kommandoen pd.json_normalize(), som følger:
import pandas as pd
pd.json_normalize(json_string)
Ved at anvende denne kommando på en JSON med en enkelt post får vi den mest grundlæggende tabel. Men når vores data er en lille smule mere komplekse og præsenterer en liste over JSON'er, kan vi stadig bruge den samme kommando uden yderligere komplikationer, og outputtet vil svare til en tabel med flere poster.

Billede af forfatter
Nemt... ikke?
Det næste naturlige spørgsmål er, hvad der sker, når nogle af værdierne mangler.
1.2 Håndtering af nulværdier
Forestil dig, at nogle af værdierne ikke er informeret, som f.eks. mangler indkomstposten for David. Når vi transformerer vores JSON til en simpel panda-dataramme, vises den tilsvarende værdi som NaN.
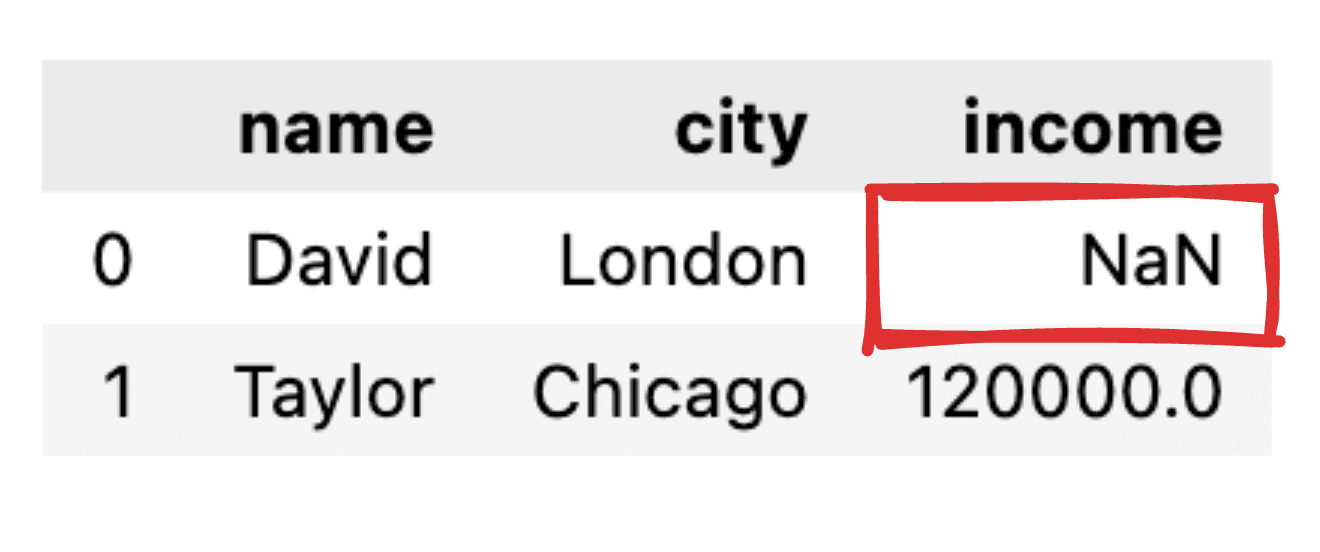
Billede af forfatter
Og hvad hvis jeg kun vil have nogle af felterne?
1.3 Vælg kun de kolonner af interesse
Hvis vi bare ønsker at transformere nogle specifikke felter til en tabelformet pandas DataFrame, tillader kommandoen json_normalize() os ikke at vælge, hvilke felter der skal transformeres.
Derfor bør der udføres en lille forbehandling af JSON, hvor vi filtrerer netop de kolonner af interesse.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Så lad os gå til en mere avanceret JSON-struktur.
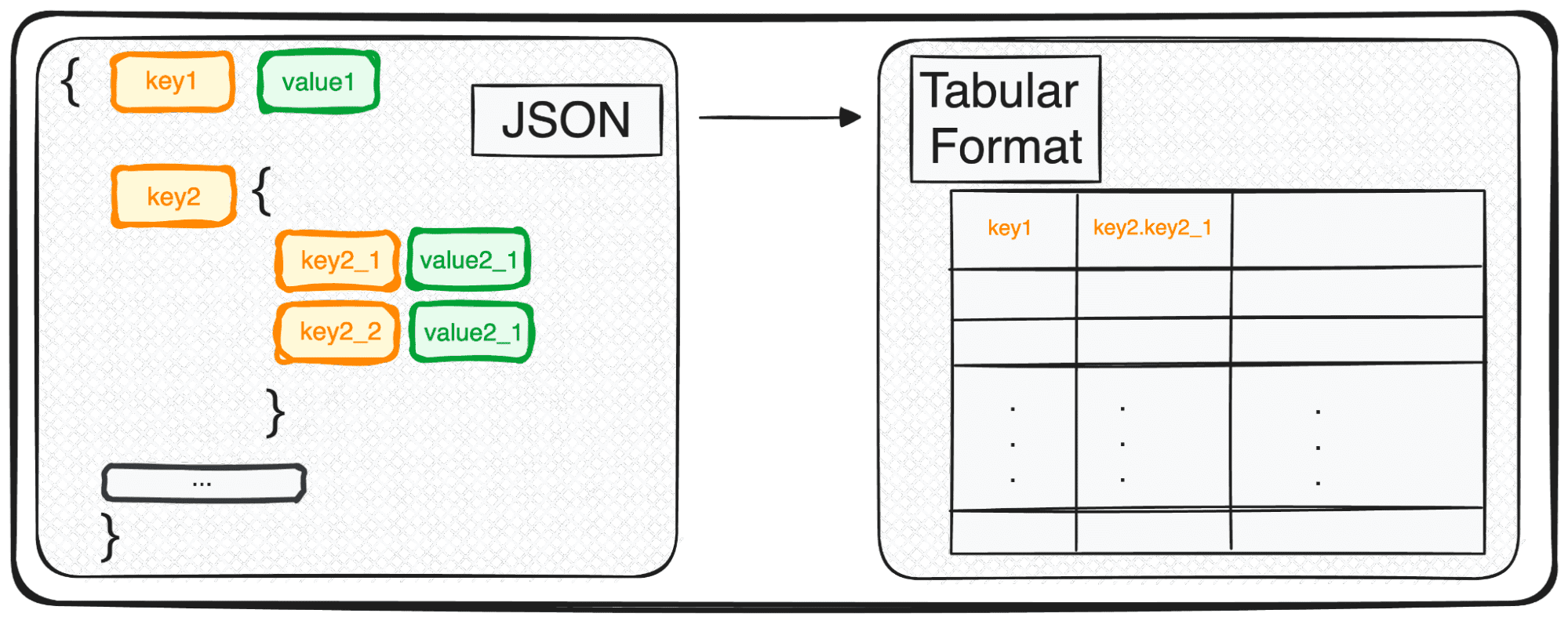
Når vi har at gøre med JSON'er på flere niveauer, befinder vi os med indlejrede JSON'er inden for forskellige niveauer. Proceduren er den samme som før, men i dette tilfælde kan vi vælge, hvor mange niveauer vi vil transformere. Som standard vil kommandoen altid udvide alle niveauer og generere nye kolonner, der indeholder det sammenkædede navn på alle de indlejrede niveauer.
Så hvis vi normaliserer følgende JSON'er.
Kode efter forfatter
Vi ville få følgende tabel med 3 kolonner under feltfærdighederne:
- skills.python
- færdigheder.SQL
- færdigheder.GCP
og 4 kolonner under feltrollerne
- roller.projektleder
- roller.dataingeniør
- roller.data scientist
- roller.dataanalytiker

Billede af forfatter
Forestil dig dog, at vi bare ønsker at transformere vores topniveau. Det kan vi gøre ved specifikt at definere parameteren max_level til 0 (det max_level vi ønsker at udvide).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
De ventende værdier vil blive vedligeholdt i JSON'er i vores pandas DataFrame.
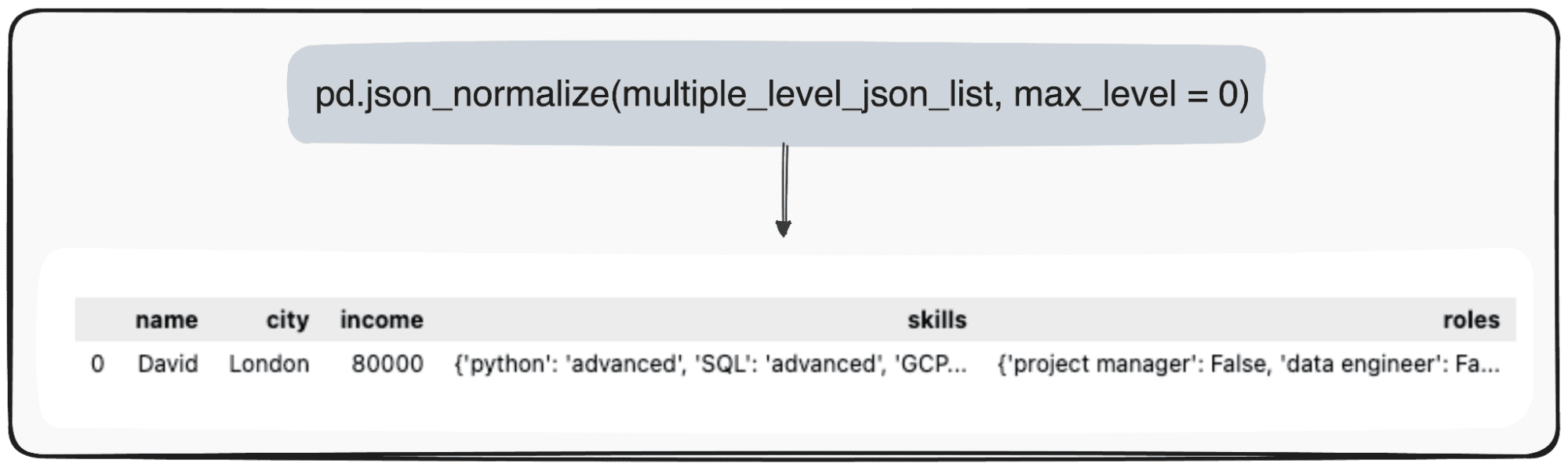
Billede af forfatter
Det sidste tilfælde, vi kan finde, er at have en indlejret liste i et JSON-felt. Så vi definerer først vores JSON'er, der skal bruges.
Kode efter forfatter
Vi kan effektivt administrere disse data ved hjælp af Pandas i Python. Funktionen pd.json_normalize() er særlig nyttig i denne sammenhæng. Det kan udjævne JSON-data, inklusive den indlejrede liste, til et struktureret format, der er egnet til analyse. Når denne funktion anvendes på vores JSON-data, producerer den en normaliseret tabel, der inkorporerer den indlejrede liste som en del af dens felter.
Desuden tilbyder Pandas muligheden for at forfine denne proces yderligere. Ved at bruge record_path-parameteren i pd.json_normalize(), kan vi dirigere funktionen til specifikt at normalisere den indlejrede liste.
Denne handling resulterer i en dedikeret tabel udelukkende til listens indhold. Som standard vil denne proces kun udfolde elementerne på listen. Men for at berige denne tabel med yderligere kontekst, såsom at bevare et tilknyttet ID for hver post, kan vi bruge metaparameteren.

Billede af forfatter
Sammenfattende er transformationen af JSON-data til CSV-filer ved hjælp af Pythons Pandas-bibliotek nem og effektiv.
JSON er stadig det mest almindelige format i moderne datalagring og -udveksling, især i NoSQL-databaser og REST API'er. Det giver dog nogle vigtige analytiske udfordringer, når man håndterer data i dets råformat.
Den centrale rolle for Pandas' pd.json_normalize() fremstår som en fantastisk måde at håndtere sådanne formater og konvertere vores data til pandas DataFrame.
Jeg håber, at denne guide var nyttig, og næste gang du har at gøre med JSON, kan du gøre det på en mere effektiv måde.
Du kan gå og tjekke den tilsvarende Jupyter Notebook i efter GitHub repo.
Josep Ferrer er en analyseingeniør fra Barcelona. Han er uddannet i fysikingeniør og arbejder i øjeblikket inden for datavidenskab, der anvendes på menneskelig mobilitet. Han er en deltidsindholdsskaber med fokus på datavidenskab og teknologi. Du kan kontakte ham på LinkedIn, Twitter or Medium.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :er
- :ikke
- :hvor
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- Om
- Handling
- Yderligere
- fremskreden
- Alle
- tillade
- tillader
- allerede
- altid
- an
- analyse
- analytiker
- Analytisk
- analytics
- ,
- enhver
- API'er
- vises
- anvendt
- Anvendelse
- ER
- Array
- Kunst
- AS
- forbundet
- Barcelona
- grundlæggende
- BE
- før
- Bit
- både
- men
- by
- CAN
- kapacitet
- tilfælde
- udfordringer
- kontrollere
- Vælg
- By
- Kolonner
- Fælles
- komplekse
- komplikationer
- kontakt
- indhold
- indhold
- sammenhæng
- konvertere
- konvertering af
- svarer
- Tilsvarende
- skaberen
- For øjeblikket
- data
- dataanalytiker
- dataingeniør
- datalogi
- dataforsker
- data opbevaring
- databaser
- David
- beskæftiger
- dedikeret
- Standard
- definere
- definere
- dejlige
- DICT
- forskellige
- direkte
- do
- gør
- hver
- nemt
- let
- Effektiv
- effektivt
- elementer
- fremgår
- møde
- ingeniør
- Engineering
- berige
- væsentlige
- udveksling
- udveksling
- udelukkende
- Udvid
- erfaring
- forklarer
- udforske
- bekendt
- få
- felt
- Fields
- Filer
- filtrere
- Finde
- Fornavn
- fokuserede
- efter
- følger
- Til
- formular
- format
- venlige
- fra
- funktion
- fundamental
- yderligere
- GCP
- generere
- få
- GitHub
- Go
- stor
- vejlede
- håndtere
- Håndtering
- sker
- Have
- have
- he
- ham
- håber
- Hvordan
- Men
- HTTPS
- menneskelig
- i
- SYG
- ID
- if
- billede
- importere
- vigtigt
- in
- dybdegående
- omfatter
- Herunder
- Indkomst
- inkorporerer
- informeret
- instans
- interesse
- ind
- isn
- IT
- ITS
- JavaScript
- json
- Jupyter Notebook
- lige
- KDnuggets
- Nøgle
- nøgler
- Kend
- Efternavn
- læring
- Niveau
- niveauer
- Bibliotek
- ligesom
- Liste
- lidt
- ll
- kærlighed
- maskine
- machine learning
- Magic
- opretholdes
- Making
- administrere
- leder
- mange
- midler
- Meta
- mangler
- mobilitet
- Moderne
- MongoDB
- mere
- mest
- bevæge sig
- meget
- flere
- navn
- Natural
- Behov
- indlejrede
- Ny
- næste
- ingen
- især
- notesbog
- objekt
- opnå
- of
- Tilbud
- tit
- on
- ONE
- kun
- or
- vores
- os selv
- output
- pandaer
- parameter
- del
- især
- verserende
- perfekt
- udføres
- Fysik
- afgørende
- plato
- Platon Data Intelligence
- PlatoData
- Populær
- gaver
- sandsynligvis
- procedure
- behandle
- producerer
- projekt
- Python
- spørgsmål
- helt
- Raw
- RE
- Læsning
- klar
- optage
- optegnelser
- raffinere
- Svar
- REST
- Resultater
- tilbageholdende
- højre
- roller
- s
- samme
- Videnskab
- Videnskab og Teknologi
- Videnskabsmand
- sekunder
- se
- udvælgelse
- bør
- Simpelt
- simulere
- enkelt
- færdigheder
- lille
- So
- nogle
- noget
- specifikke
- specifikt
- SQL
- Stadig
- opbevaring
- butik
- struktur
- struktureret
- sådan
- egnede
- RESUMÉ
- T
- bord
- Teknologier
- vilkår
- at
- verdenen
- deres
- Them
- derefter
- Disse
- denne
- dem
- tid
- til
- sammen
- top
- Transform
- Transformation
- omdanne
- typen
- typer
- under
- us
- brug
- nyttigt
- ved brug af
- Ved hjælp af
- værdi
- Værdier
- ønsker
- var
- Vej..
- we
- Hvad
- hvornår
- hvorvidt
- som
- mens
- vilje
- med
- inden for
- Arbejde
- arbejder
- virker
- world
- ville
- dig
- zephyrnet