I nutidens datadrevne forretningsmiljø står organisationer over for udfordringen med effektivt at forberede og transformere store mængder data til analytiske og datavidenskabelige formål. Virksomheder skal bygge datavarehuse og datasøer baseret på driftsdata. Dette er drevet af behovet for at centralisere og integrere data, der kommer fra forskellige kilder.
Samtidig stammer driftsdata ofte fra applikationer, der understøttes af ældre datalagre. Modernisering af applikationer kræver en mikroservicearkitektur, som igen nødvendiggør konsolidering af data fra flere kilder for at konstruere et operationelt datalager. Uden modernisering kan ældre applikationer medføre stigende vedligeholdelsesomkostninger. Modernisering af applikationer involverer at ændre den underliggende databasemotor til en moderne dokumentbaseret database som MongoDB.
Disse to opgaver (opbygning af datasøer eller datavarehuse og applikationsmodernisering) involverer databevægelse, som bruger en udtræks-, transformations- og indlæsningsproces (ETL). ETL-jobbet er en nøglefunktionalitet for at have en velstruktureret proces for at lykkes.
AWS Lim er en serverløs dataintegrationstjeneste, der gør det nemt at opdage, forberede, flytte og integrere data fra flere kilder til analyse, maskinlæring (ML) og applikationsudvikling. MongoDB Atlas er en integreret suite af cloud-database og datatjenester, der kombinerer transaktionsbehandling, relevansbaseret søgning, realtidsanalyse og mobil-til-sky-datasynkronisering i en elegant og integreret arkitektur.
Ved at bruge AWS Glue med MongoDB Atlas kan organisationer strømline deres ETL-processer. Med sin fuldt administrerede, skalerbare og sikre databaseløsning giver MongoDB Atlas et fleksibelt og pålideligt miljø til lagring og styring af driftsdata. Sammen er AWS Glue ETL og MongoDB Atlas en kraftfuld løsning til organisationer, der ønsker at optimere, hvordan de bygger datasøer og datavarehuse, og for at modernisere deres applikationer for at forbedre virksomhedens ydeevne, reducere omkostningerne og drive vækst og succes.
I dette indlæg viser vi, hvordan man migrerer data fra Amazon Simple Storage Service (Amazon S3) buckets til MongoDB Atlas ved hjælp af AWS Glue ETL, og hvordan man udtrækker data fra MongoDB Atlas til en Amazon S3-baseret datasø.
Løsningsoversigt
I dette indlæg udforsker vi følgende use cases:
- Udtræk data fra MongoDB – MongoDB er en populær database, der bruges af tusindvis af kunder til at gemme applikationsdata i stor skala. Virksomhedskunder kan centralisere og integrere data, der kommer fra flere datalagre, ved at bygge datasøer og datavarehuse. Denne proces involverer udtrækning af data fra de operationelle datalagre. Når dataene er ét sted, kan kunderne hurtigt bruge dem til business intelligence-behov eller til ML.
- Indlæsning af data i MongoDB – MongoDB fungerer også som en no-SQL-database til at gemme applikationsdata og opbygge operationelle datalagre. Modernisering af applikationer involverer ofte migrering af det operationelle lager til MongoDB. Kunder skal udtrække eksisterende data fra relationelle databaser eller fra flade filer. Mobil- og webapps kræver ofte, at dataingeniører bygger datapipelines for at skabe en enkelt visning af data i Atlas, mens de indtager data fra flere siled-kilder. Under denne migrering skal de tilslutte sig forskellige databaser for at oprette dokumenter. Denne komplekse joinoperation ville kræve betydelig engangsberegningskraft. Udviklere skal også bygge dette hurtigt for at migrere dataene.
AWS Glue er praktisk i disse tilfælde med pay-as-you-go-modellen og dens evne til at køre komplekse transformationer på tværs af enorme datasæt. Udviklere kan bruge AWS Glue Studio til effektivt at skabe sådanne datapipelines.
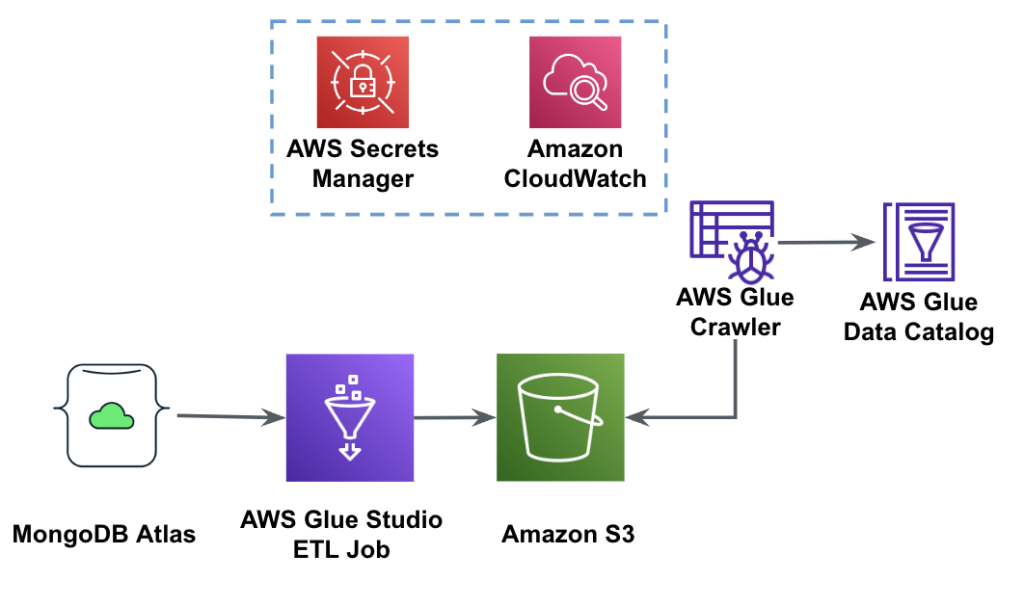
Følgende diagram viser dataekstraktionsarbejdsgangen fra MongoDB Atlas til en S3-spand ved hjælp af AWS Glue Studio.
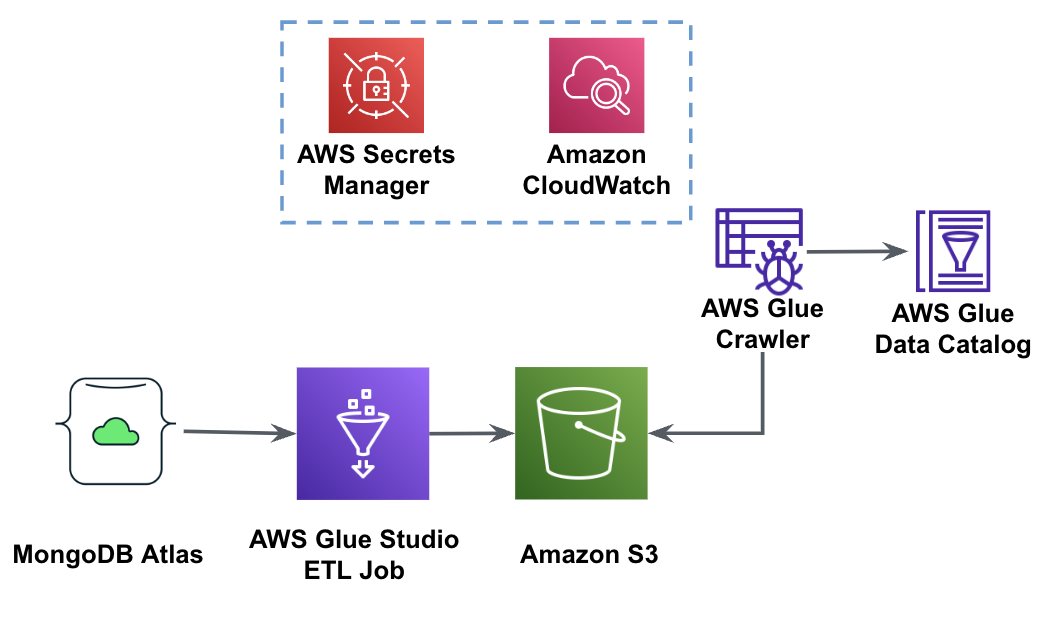
For at implementere denne arkitektur skal du bruge en MongoDB Atlas-klynge, en S3-spand og en AWS identitets- og adgangsstyring (IAM) rolle for AWS Glue. For at konfigurere disse ressourcer, se de nødvendige trin i det følgende GitHub repo.
Følgende figur viser arbejdsgangen for dataindlæsning fra en S3-spand til MongoDB Atlas ved hjælp af AWS Glue.
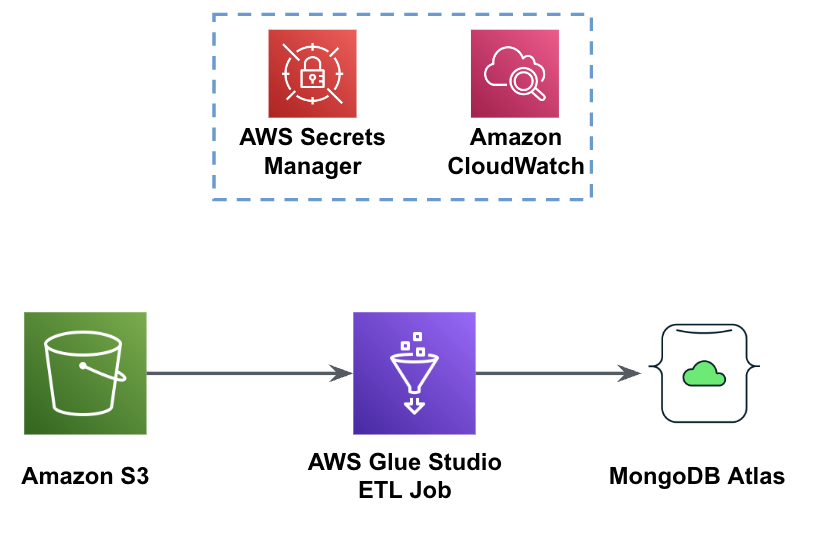
De samme forudsætninger er nødvendige her: en S3-spand, IAM-rolle og en MongoDB Atlas-klynge.
Indlæs data fra Amazon S3 til MongoDB Atlas ved hjælp af AWS Glue
De følgende trin beskriver, hvordan man indlæser data fra S3-bøtten til MongoDB Atlas ved hjælp af et AWS-limjob. Udtrækningsprocessen fra MongoDB Atlas til Amazon S3 er meget ens, med undtagelse af scriptet, der bruges. Vi fremhæver forskellene mellem de to processer.
- Opret en gratis klynge i MongoDB Atlas.
- Upload eksempel JSON-fil til din S3-spand.
- Opret et nyt AWS Glue Studio-job med Spark script editor valgmulighed.

- Afhængigt af om du vil indlæse eller udtrække data fra MongoDB Atlas-klyngen, skal du indtaste indlæse script or uddrag script i AWS Glue Studio script editor.
Følgende skærmbillede viser et kodestykke til at indlæse data i MongoDB Atlas-klyngen.

Koden bruger AWS Secrets Manager for at hente MongoDB Atlas-klyngenavnet, brugernavnet og adgangskoden. Derefter skaber det en DynamicFrame for S3-bøtten og filnavnet, der er sendt til scriptet som parametre. Koden henter database- og samlingsnavnene fra jobparametrenes konfiguration. Til sidst skriver koden DynamicFrame til MongoDB Atlas-klyngen ved hjælp af de hentede parametre.
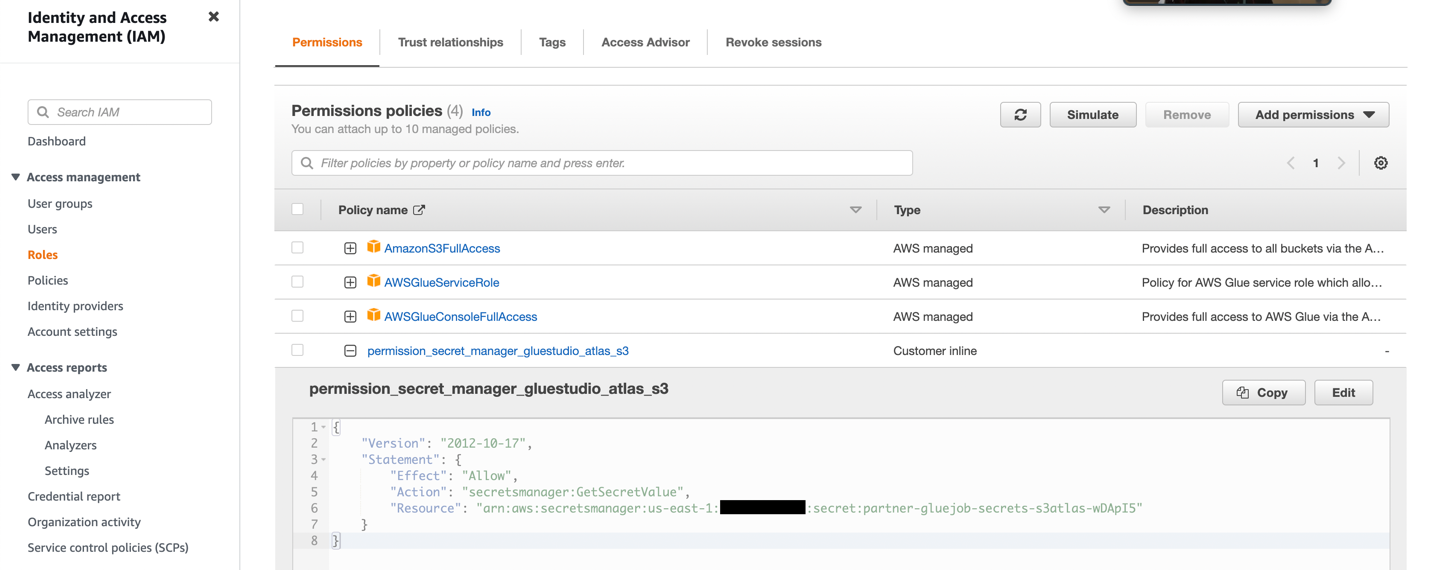
- Opret en IAM-rolle med tilladelserne som vist på det følgende skærmbillede.
For flere detaljer henvises til Konfigurer en IAM-rolle til dit ETL-job.
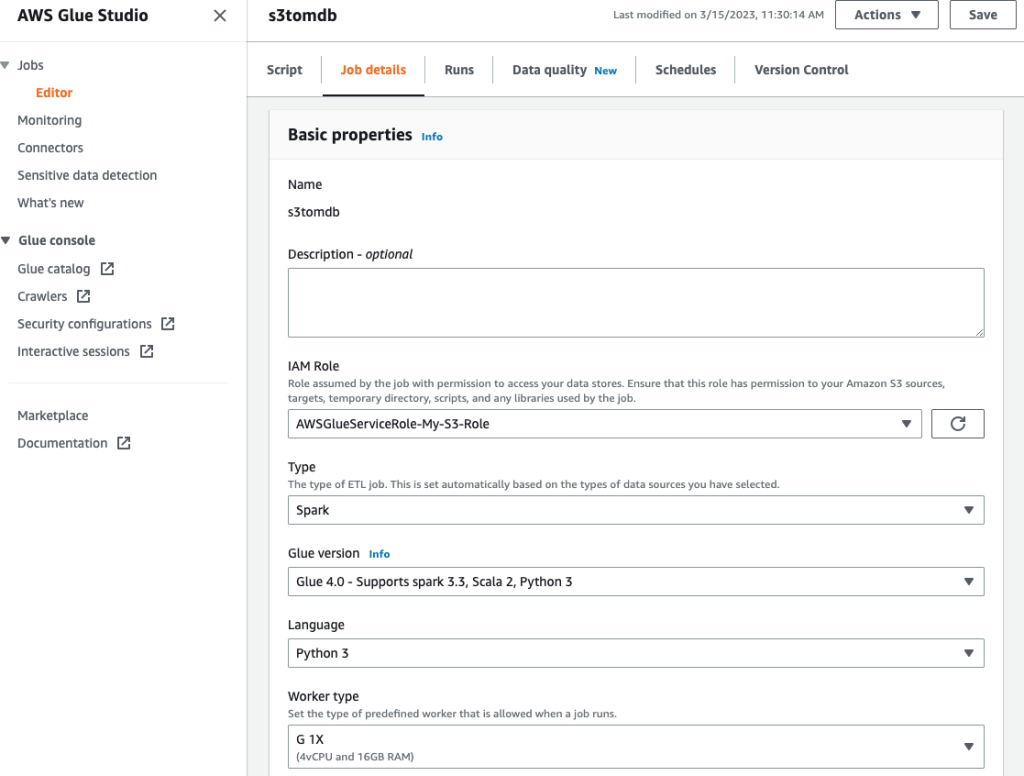
- Giv jobbet et navn og angiv den IAM-rolle, der blev oprettet i det foregående trin på Joboplysninger fane.
- Du kan lade resten af parametrene være standard, som vist på de følgende skærmbilleder.
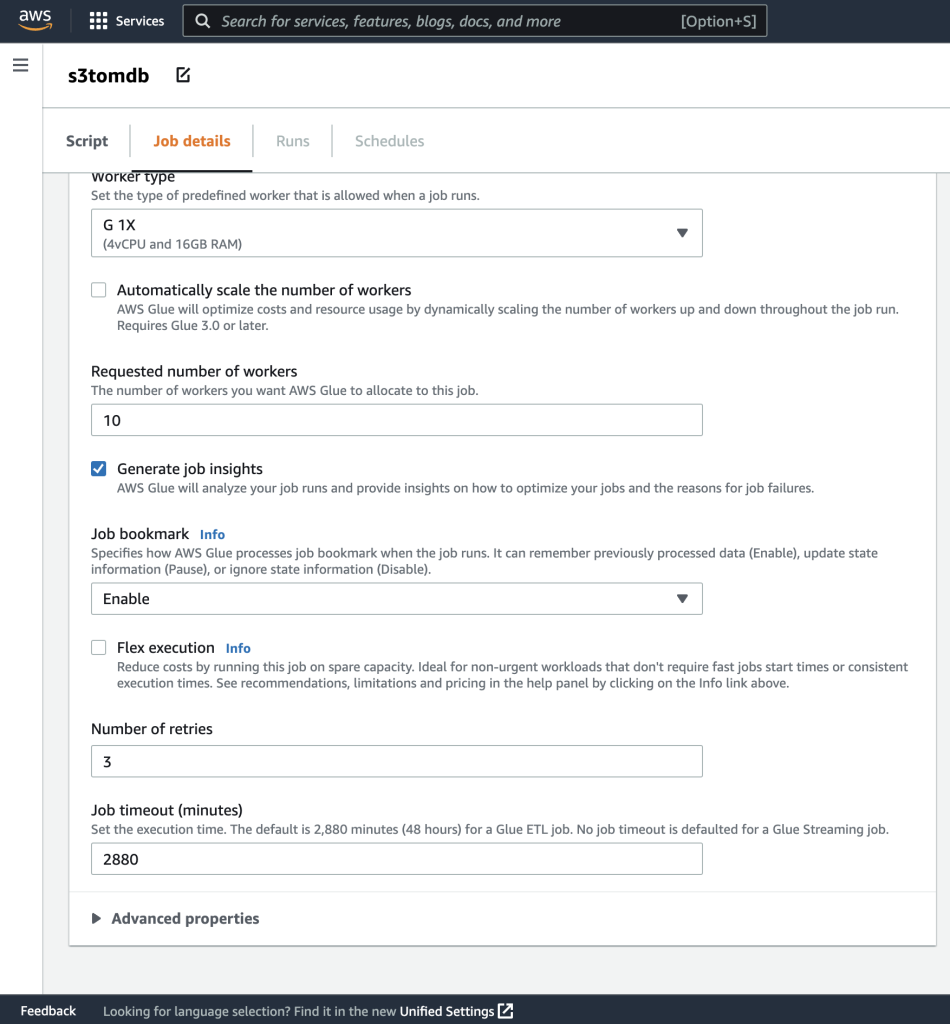
- Derefter skal du definere de jobparametre, som scriptet bruger, og angive standardværdierne.
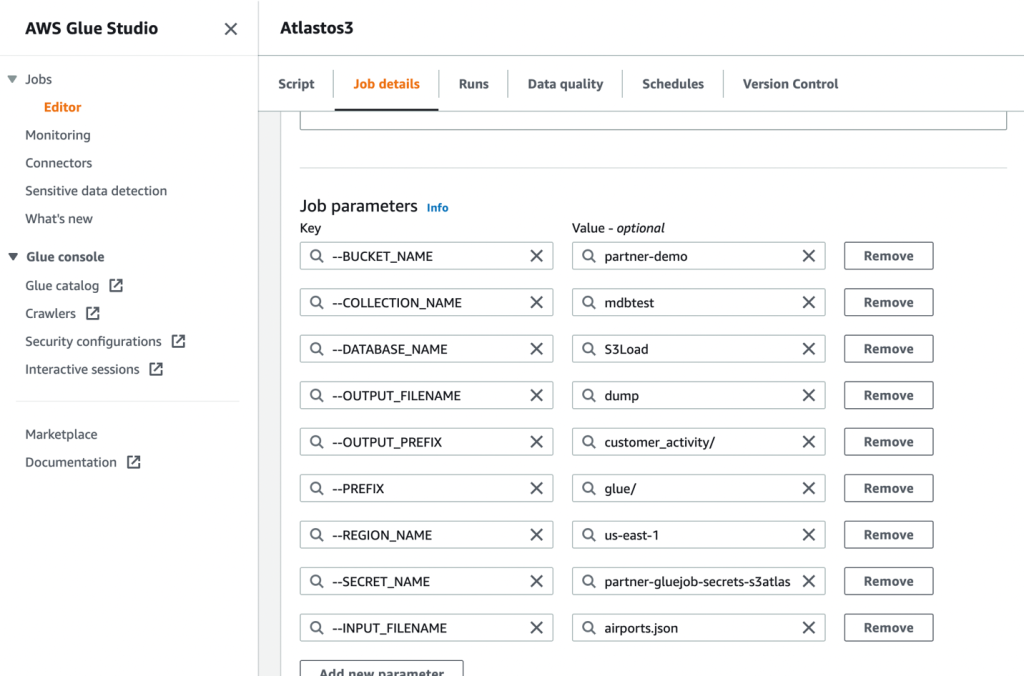
- Gem jobbet og kør det.
- For at bekræfte en vellykket kørsel skal du observere indholdet af MongoDB Atlas-databasesamlingen, hvis dataene indlæses, eller S3-bøtten, hvis du udførte et udtræk.



Følgende skærmbillede viser resultaterne af en vellykket dataindlæsning fra en Amazon S3-spand til MongoDB Atlas-klyngen. Dataene er nu tilgængelige for forespørgsler i MongoDB Atlas UI.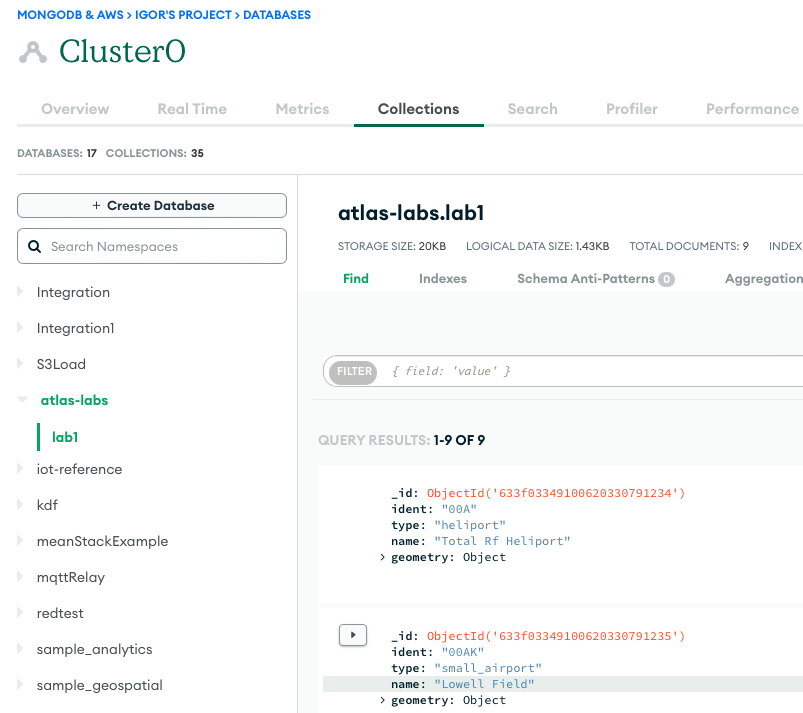
- For at fejlfinde dine løbeture skal du gennemgå amazoncloudwatch logger ved hjælp af linket på jobbet Kør fane.
Følgende skærmbillede viser, at jobbet kørte med succes, med yderligere detaljer såsom links til CloudWatch-logfilerne.

Konklusion
I dette indlæg beskrev vi, hvordan man udtrækker og indtager data til MongoDB Atlas ved hjælp af AWS Glue.
Med AWS Glue ETL-job kan vi nu overføre data fra MongoDB Atlas til AWS Glue-kompatible kilder og omvendt. Du kan også udvide løsningen til at bygge analyser ved hjælp af AWS AI- og ML-tjenester.
For at lære mere, se GitHub repository for trin-for-trin instruktioner og prøvekode. Du kan anskaffe MongoDB Atlas på AWS Marketplace.
Om forfatterne

Igor Alekseev er Senior Partner Solution Architect hos AWS i data- og analysedomæne. I sin rolle arbejder Igor med strategiske partnere, der hjælper dem med at bygge komplekse, AWS-optimerede arkitekturer. Før han kom til AWS, implementerede han som Data/Solution Architect mange projekter i Big Data-domænet, herunder flere datasøer i Hadoop-økosystemet. Som dataingeniør var han involveret i at anvende AI/ML til svindeldetektion og kontorautomatisering.
 Babu Srinivasan er Senior Partner Solutions Architect hos MongoDB. I sin nuværende rolle arbejder han sammen med AWS for at bygge de tekniske integrationer og referencearkitekturer til AWS- og MongoDB-løsningerne. Han har mere end to årtiers erfaring med database- og cloud-teknologier. Han brænder for at levere tekniske løsninger til kunder, der arbejder med flere globale systemintegratorer (GSI'er) på tværs af flere geografiske områder.
Babu Srinivasan er Senior Partner Solutions Architect hos MongoDB. I sin nuværende rolle arbejder han sammen med AWS for at bygge de tekniske integrationer og referencearkitekturer til AWS- og MongoDB-løsningerne. Han har mere end to årtiers erfaring med database- og cloud-teknologier. Han brænder for at levere tekniske løsninger til kunder, der arbejder med flere globale systemintegratorer (GSI'er) på tværs af flere geografiske områder.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Køb og sælg aktier i PRE-IPO-virksomheder med PREIPO®. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :har
- :er
- 100
- 11
- a
- evne
- Om
- adgang
- tværs
- Yderligere
- AI
- AI / ML
- også
- Amazon
- beløb
- an
- analytics
- ,
- Anvendelse
- Application Development
- applikationer
- Anvendelse
- apps
- arkitektur
- ER
- AS
- At
- atlas
- Automation
- til rådighed
- AWS
- AWS Lim
- AWS Marketplace
- Backed
- baseret
- være
- mellem
- Big
- Big data
- bygge
- Bygning
- virksomhed
- business intelligence
- forretningsresultater
- virksomheder
- by
- ringe
- CAN
- tilfælde
- udfordre
- skiftende
- Cloud
- Cluster
- kode
- samling
- kombinerer
- kommer
- kommer
- komplekse
- Compute
- Konfiguration
- Bekræfte
- konsolidering
- konstruere
- indhold
- fortsatte
- Omkostninger
- skabe
- oprettet
- skaber
- skabelse
- Nuværende
- Kunder
- data
- dataingeniør
- dataintegration
- Data Lake
- datalogi
- datavarehuse
- datastyret
- Database
- databaser
- datasæt
- årtier
- Standard
- demonstrere
- beskrive
- beskrevet
- detaljer
- Detektion
- udviklere
- Udvikling
- forskelle
- forskellige
- opdage
- dårskab
- dokumenter
- domæne
- køre
- drevet
- i løbet af
- økosystem
- editor
- effektivt
- Engine (Motor)
- ingeniør
- Ingeniører
- Indtast
- Enterprise
- virksomhedskunder
- Miljø
- Ether (ETH)
- undtagelse
- eksisterende
- erfaring
- udforske
- udvide
- ekstrakt
- udvinding
- Ansigtet
- Figur
- File (Felt)
- Filer
- Endelig
- flad
- fleksibel
- efter
- Til
- bedrageri
- bedrageri afsløring
- Gratis
- fra
- fuldt ud
- funktionalitet
- geografier
- Global
- Vækst
- Hadoop
- praktisk
- have
- he
- hjælpe
- link.
- hans
- Hvordan
- How To
- HTML
- http
- HTTPS
- kæmpe
- IAM
- Identity
- if
- gennemføre
- implementeret
- Forbedre
- in
- Herunder
- stigende
- indgang
- anvisninger
- integrere
- integreret
- integration
- integrationer
- Intelligens
- ind
- involvere
- involverede
- IT
- ITS
- Job
- Karriere
- deltage
- sammenføjning
- json
- Nøgle
- sø
- stor
- LÆR
- læring
- Forlade
- Legacy
- ligesom
- LINK
- links
- belastning
- lastning
- leder
- maskine
- machine learning
- vedligeholdelse
- maerker
- lykkedes
- styring
- mange
- markedsplads
- Kan..
- migrere
- migration
- ML
- Mobil
- model
- Moderne
- modernisering
- modernisere
- MongoDB
- mere
- bevæge sig
- bevægelse
- flere
- navn
- navne
- Behov
- behov
- behov
- Ny
- nu
- observere
- of
- Office
- tit
- on
- ONE
- drift
- operationelle
- Optimer
- Option
- or
- ordrer
- organisationer
- ud
- parametre
- partner
- partnere
- Bestået
- lidenskabelige
- Adgangskode
- ydeevne
- udfører
- Tilladelser
- Place
- plato
- Platon Data Intelligence
- PlatoData
- Populær
- Indlæg
- magt
- vigtigste
- Forbered
- forberede
- forudsætninger
- tidligere
- Forud
- behandle
- Processer
- forarbejdning
- projekter
- giver
- leverer
- formål
- forespørgsler
- hurtigt
- realtid
- reducere
- pålidelig
- kræver
- Kræver
- Ressourcer
- REST
- Resultater
- gennemgå
- roller
- Kør
- samme
- skalerbar
- Scale
- Videnskab
- screenshots
- Søg
- sikker
- senior
- Serverless
- tjener
- tjeneste
- Tjenester
- flere
- vist
- Shows
- signifikant
- lignende
- Simpelt
- enkelt
- løsninger
- Løsninger
- Kilder
- Trin
- Steps
- opbevaring
- butik
- forhandler
- ligetil
- Strategisk
- strategiske partnere
- strømline
- Studio
- lykkes
- succes
- vellykket
- Succesfuld
- sådan
- suite
- forsyne
- synkronisering
- systemet
- opgaver
- Teknisk
- Teknologier
- end
- at
- deres
- Them
- derefter
- Disse
- de
- denne
- tusinder
- tid
- til
- nutidens
- sammen
- transaktionsbeslutning
- overførsel
- Transform
- transformationer
- omdanne
- TUR
- to
- ui
- underliggende
- brug
- anvendte
- Bruger
- ved brug af
- Værdier
- meget
- Specifikation
- ønsker
- var
- we
- web
- var
- hvornår
- hvorvidt
- som
- mens
- vilje
- med
- uden
- workflow
- arbejder
- ville
- dig
- Din
- zephyrnet