Velkommen til dataens æra. Alene mængden af data, der registreres dagligt, fortsætter med at vokse, hvilket kræver, at platforme og løsninger udvikler sig. Tjenester som f.eks Amazon Simple Storage Service (Amazon S3) tilbyder en skalerbar løsning, der tilpasser sig, men forbliver omkostningseffektiv til voksende datasæt. Det Amazon Sustainability Data Initiative (ASDI) bruger funktionerne i Amazon S3 til at levere en gratis løsning, så du kan gemme og dele klimavidenskabelige arbejdsbelastninger over hele kloden. Amazons Open Data Sponsorship Program giver organisationer mulighed for at hoste gratis på AWS.
I løbet af det sidste årti har vi set en stigning i datavidenskabelige rammer, der er kommet til virkelighed, sammen med masseadoption fra datavidenskabssamfundet. En sådan ramme er Dashboard, som er kraftfuld for sin evne til at levere en orkestrering af worker compute noder og derved accelerere kompleks analyse på store datasæt.
I dette indlæg viser vi dig, hvordan du implementerer en brugerdefineret AWS Cloud Development Kit (AWS CDK) løsning, der udvider Dasks funktionalitet til at arbejde interregionalt på tværs af Amazons globale netværk. AWS CDK-løsningen implementerer et netværk af Dask-arbejdere på tværs af to AWS-regioner, der forbinder til en klientregion. For mere information, se Vejledning til distribueret databehandling med Cross Regional Dask på AWS og GitHub repo for open source-kode.
Efter implementeringen vil brugeren have adgang til en Jupyter notesbog, hvor de kan interagere med to datasæt fra ASDI på AWS: Coupled Model Intercomparison Project 6 (CMIP6) , ECMWF ERA5 reanalyse. CMIP6 fokuserer på den sjette fase af globalt koblet hav-atmosfære generelt cirkulationsmodelensemble; ERA5 er den femte generation af ECMWF atmosfæriske reanalyser af det globale klima, og den første reanalyse produceret som en operationel service.
Denne løsning er inspireret af arbejde med en vigtig AWS-kunde, the UK Met Office. The Met Office blev grundlagt i 1854 og er den nationale meteorologiske tjeneste for Storbritannien. De giver vejr- og klimaforudsigelser for at hjælpe dig med at træffe bedre beslutninger for at forblive sikker og trives. Et samarbejde mellem Met Office og EUMETSAT, detaljeret i Data nær beregning på en Dask Cluster fordelt mellem datacentre, fremhæver det voksende behov for at udvikle en bæredygtig, effektiv og skalerbar datavidenskabsløsning. Denne løsning opnår dette ved at bringe computeren tættere på dataene i stedet for at tvinge dataene til at komme tættere på computerressourcerne, hvilket tilføjer omkostninger, latens og energi.
Løsningsoversigt
Hver dag producerer UK Met Office op til 300 TB vejr- og klimadata, hvoraf en del offentliggøres til ASDI. Disse datasæt er distribueret over hele verden og hostet til offentlig brug. Met Office vil gerne gøre det muligt for forbrugere at få mere ud af deres data for at hjælpe med at informere kritiske beslutninger om at løse problemer som bedre forberedelse til klimaforandringer-inducerede naturbrande og oversvømmelser og reducere fødevareusikkerhed gennem bedre afgrødeudbytteanalyse.
Traditionelle løsninger, der bruges i dag, især med klimadata, er tidskrævende og uholdbare, og replikerer datasæt på tværs af regioner. Unødvendig dataoverførsel på petabyte-skalaen er dyr, langsom og forbruger energi.
Vi vurderede, at hvis denne praksis blev vedtaget af Met Office-brugerne, ville der kunne spares svarende til 40 hjems daglige strømforbrug hver dag, og de kunne også reducere overførslen af data mellem regioner.
Følgende diagram illustrerer løsningsarkitekturen.
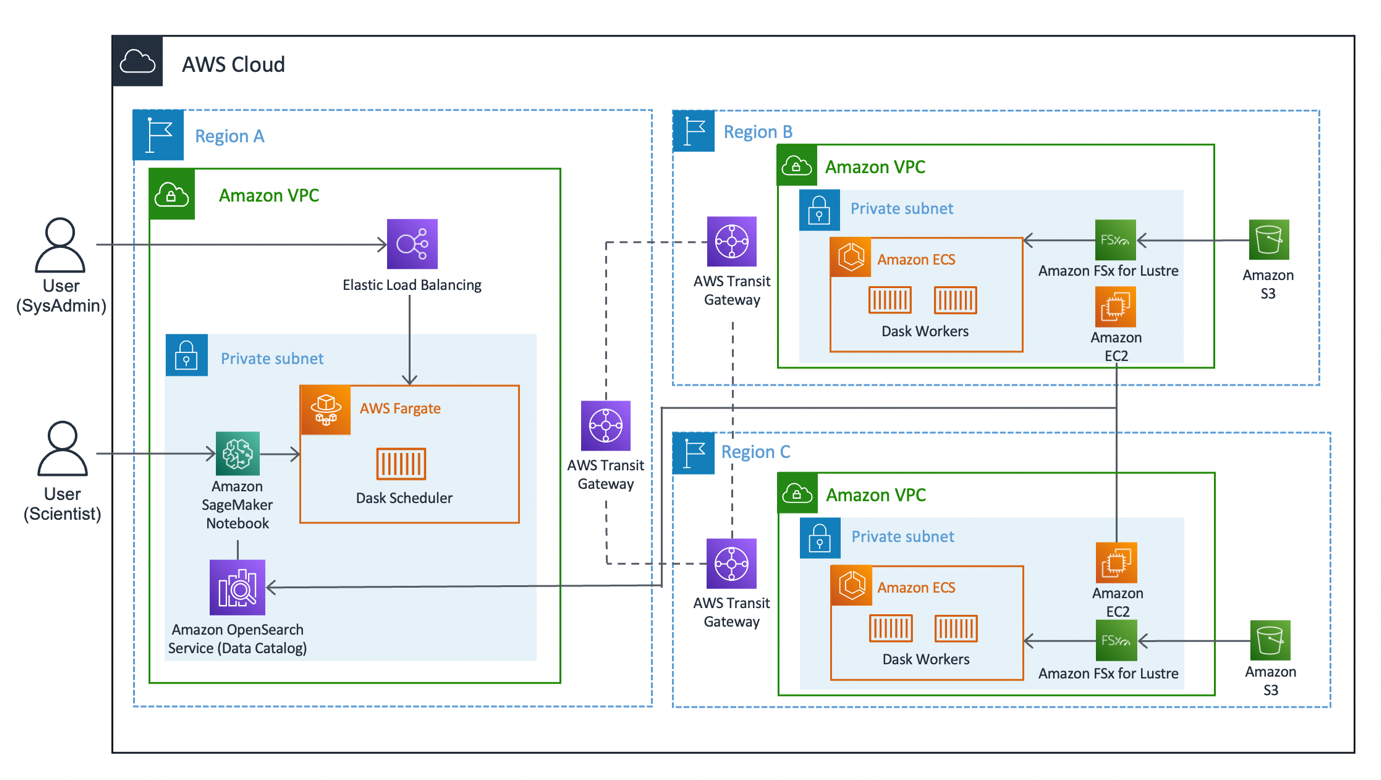
Løsningen kan opdeles i tre hovedsegmenter: klient, arbejdere og netværk. Lad os dykke ned i hver og se, hvordan de hænger sammen.
Klient
Klienten repræsenterer kilderegionen, hvor dataforskere forbinder. Denne region (Region A i diagrammet) indeholder en Amazon SageMaker notesbog, en Amazon OpenSearch Service domæne og et Dask planlægger som nøglekomponenter. Systemadministratorer har adgang til det indbyggede Dask-dashboard eksponeret via en Elastisk Load Balancer.
Dataforskere har adgang til Jupyter-notebooken, der er hostet på SageMaker. Den bærbare computer er i stand til at forbinde og køre arbejdsbelastninger på Dask-planlæggeren. OpenSearch Service-domænet gemmer metadata på de datasæt, der er tilsluttet i regionerne. Notebook-brugere kan forespørge på denne service for at hente detaljer såsom den korrekte Region of Dask-medarbejdere uden at skulle kende dataens regionale placering på forhånd.
Worker
Hver af arbejderregionerne (region B og C i diagrammet) består af en Amazon Elastic Container Service (Amazon ECS) klynge af Dask arbejdere, en Amazon FSx til Luster filsystem og et selvstændigt Amazon Elastic Compute Cloud (Amazon EC2) forekomst. FSx for Luster giver Dask-arbejdere mulighed for at få adgang til og behandle Amazon S3-data fra et højtydende filsystem ved at linke dine filsystemer til S3-buckets. Det giver forsinkelser på under millisekunder, op til hundredvis af GBs/sek. gennemløb og millioner af IOPS. En nøglefunktion ved Luster er, at kun filsystemets metadata synkroniseres. Luster styrer balancen mellem filer, der skal indlæses og holdes varme, baseret på efterspørgsel.
Arbejderklynger skaleres baseret på CPU-brug, sørger for yderligere medarbejdere i længere perioder med efterspørgsel og skalerer ned, efterhånden som ressourcer bliver ledige.
Hver nat kl. 0:00 UTC beder et datasynkroniseringsjob Luster-filsystemet om at gensynkronisere med den vedhæftede S3-bøtte og trækker et opdateret metadatakatalog over bøtten. Efterfølgende skubber den selvstændige EC2-instans disse opdateringer ind i OpenSearch Service i forhold til den pågældende regions indeks. OpenSearch Service giver den nødvendige information til klienten om, hvilken pulje af arbejdere der skal tilkaldes til et bestemt datasæt.
Netværk
Netværk udgør kernen i denne løsning, ved at bruge Amazons interne backbone-netværk. Ved hjælp af AWS Transit Gateway, er vi i stand til at forbinde hver af regionerne med hinanden uden at skulle krydse det offentlige internet. Hver af arbejderne er i stand til at oprette forbindelse dynamisk til Dask-planlæggeren, hvilket giver dataforskere mulighed for at køre interregionale forespørgsler gennem Dask.
Forudsætninger
AWS CDK-pakken bruger TypeScript-programmeringssproget. Følg trinene i Kom godt i gang for AWS CDK for at konfigurere dit lokale miljø og bootstrap din udviklingskonto (du bliver nødt til at bootstrap alle regioner angivet i GitHub repo).
For en vellykket implementering skal du bruge Docker installeret og kører på din lokale maskine.
Implementer AWS CDK-pakken
Det er ligetil at implementere en AWS CDK-pakke. Når du har installeret forudsætningerne og bootstrap din konto, kan du fortsætte med at downloade kodebasen.
- Download GitHub repository:
- Installer nodemoduler:
- Implementer AWS CDK:
Stakken kan tage over halvanden time at implementere.
Kodegennemgang
I dette afsnit inspicerer vi nogle af nøglefunktionerne i kodebasen. Hvis du gerne vil inspicere den fulde kodebase, skal du se GitHub repository.
Konfigurer og tilpas din stak
I filen bin/variables.ts, finder du to variable erklæringer: en for klienten og en for arbejdere. Klienterklæringen er en ordbog med reference til et område og et CIDR-område. Tilpasning af disse variabler vil ændre både regions- og CIDR-området for, hvor klientressourcer vil blive implementeret.
Arbejdervariablen kopierer den samme funktionalitet; det er dog en liste over ordbøger for at imødekomme tilføjelse eller fratrækning af datasæt, som brugeren ønsker at inkludere. Derudover indeholder hver ordbog de tilføjede felter af dataset , lustreFileSystemPath. Datasæt bruges til at angive den forbindende S3 URI, som Luster skal oprette forbindelse til. Det lustreFileSystemPath variabel bruges som en kortlægning for, hvordan brugeren ønsker, at datasættet skal kortlægges lokalt på arbejderfilsystemet. Se følgende kode:
Udgiv dynamisk planlæggerens IP
En udfordring, der ligger i dette projekts tværregionale karakter, var at opretholde en dynamisk forbindelse mellem Dask-arbejderne og planlæggeren. Hvordan kunne vi udgive en IP-adresse, som er i stand til at ændre, på tværs af AWS-regioner? Vi var i stand til at opnå dette ved at bruge AWS Cloud-kort , associate-vpc-with-hosted-zone. Tjenestens abstracts gør det muligt for AWS at administrere dette DNS-navneområde privat. Se følgende kode:
Jupyter notebook UI
Jupyter-notebooken, der er hostet på SageMaker, giver videnskabsfolk et færdigt miljø til implementering, så de nemt kan forbinde og eksperimentere med de indlæste datasæt. Vi brugte en livscykluskonfigurationsscript at klargøre notebook'en med et forudkonfigureret udviklermiljø og eksempelkodebase. Se følgende kode:
Dask worker noder
Når det kommer til Dask-arbejderne, tilbydes der større tilpasningsmuligheder, mere specifikt på instanstype, tråde pr. container og skaleringsalarmer. Som standard monterer arbejderne på instanstypen m5d.4xlarge til Luster-filsystemet ved lancering og underinddeler dets arbejdere og tråde dynamisk til porte. Alt dette kan tilpasses valgfrit. Se følgende kode:
Performance (Præstation)
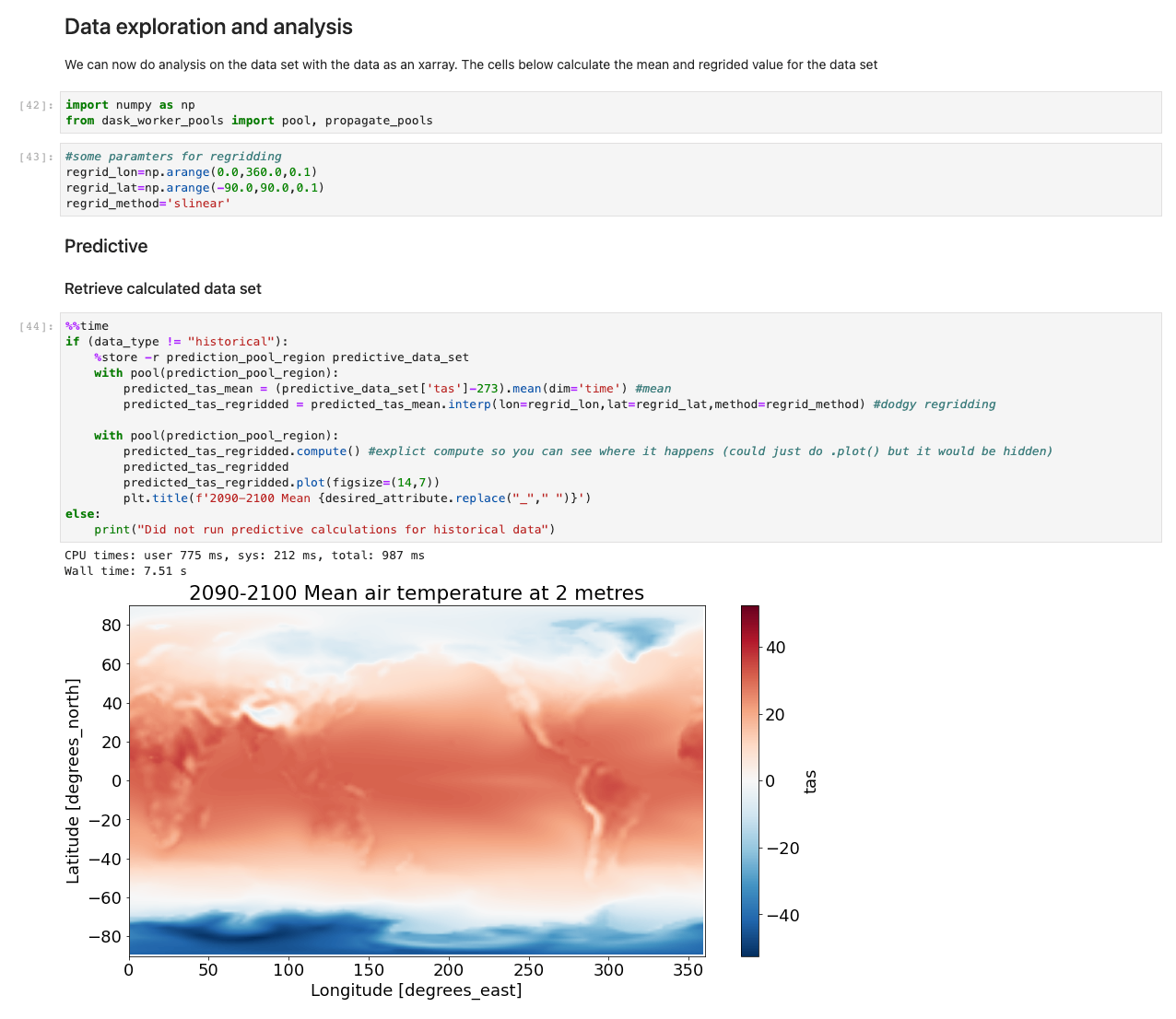
For at vurdere ydeevnen bruger vi en prøveberegning og plotning af lufttemperatur ved 2 meter baseret på forskellen mellem CMIP6-forudsigelse for en måned og ERA5 middellufttemperatur i 10 år. Vi sætter et benchmark på to arbejdere i hver region og vurderer forskellen i tidsreduktion i takt med, at der blev tilføjet flere medarbejdere. I teorien, efterhånden som løsningen skaleres, skulle der være en produktiv materialeforskel i at reducere den samlede tid.
Følgende tabel opsummerer vores datasætdetaljer.
| datasæt | Variabler | Diskstørrelse | Xarray-datasætstørrelse | Område |
| ERA5 | 2011-2020 (120 netcdf-filer) | 53.5GB | 364.1 DK | os-øst-1 |
| CMIP6 | 1.13GB | 0.11 DK | us-vest-2 |
Følgende tabel viser de indsamlede resultater og viser tiden (i sekunder) for hver beregning og forudsigelse i tre trin i beregning af CMIP6-forudsigelse, ERA5 og forskel.
| . | . | Antal arbejdere | |||
| Compute | Område | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2 (CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
us-vest-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
os-øst-1 | 1512 | 711 | 427 | 202 |
Forskel (propogated pool) |
us-west-2 og us-east-1 | 1527 | 906 | 469 | 251 |
Følgende graf visualiserer ydeevnen og skalaen.
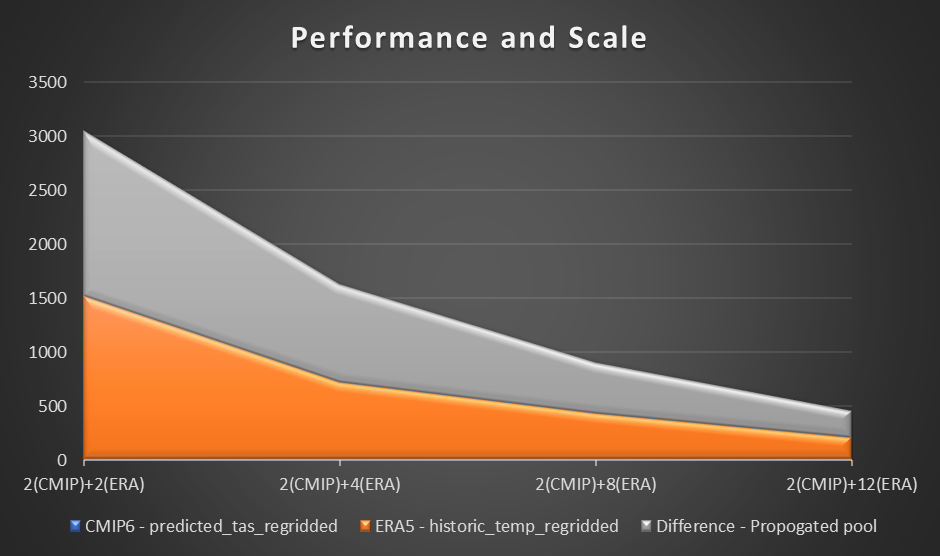
Fra vores eksperiment observerede vi en lineær forbedring af beregningen for ERA5-datasættet, efterhånden som antallet af arbejdere steg. Efterhånden som antallet af arbejdere steg, blev beregningstiderne til tider halveret.
Jupyter notesbog
Som en del af løsningslanceringen implementerer vi en prækonfigureret Jupyter-notebook for at hjælpe med at teste den tværregionale Dask-løsning. Notesbogen demonstrerer den fjernede bekymring for at skulle kende den regionale placering af datasæt, i stedet for at forespørge et katalog gennem en række Jupyter-notebooks, der kører i baggrunden.
For at komme i gang skal du følge instruktionerne i dette afsnit.
Koden til notesbøgerne kan findes i lib/SagemakerCode med den primære notesbog ux_notebook.ipynb. Denne notesbog kalder på andre notesbøger og udløser hjælpescripts. ux_notebook er designet til at være indgangspunktet for videnskabsmænd, uden at det er nødvendigt at gå andre steder hen.
For at komme i gang skal du åbne denne notesbog i SageMaker, efter du har installeret AWS CDK. AWS CDK'en opretter en notesbogsforekomst med alle filerne i depotet indlæst og sikkerhedskopieret til en AWS CodeCommit repository.
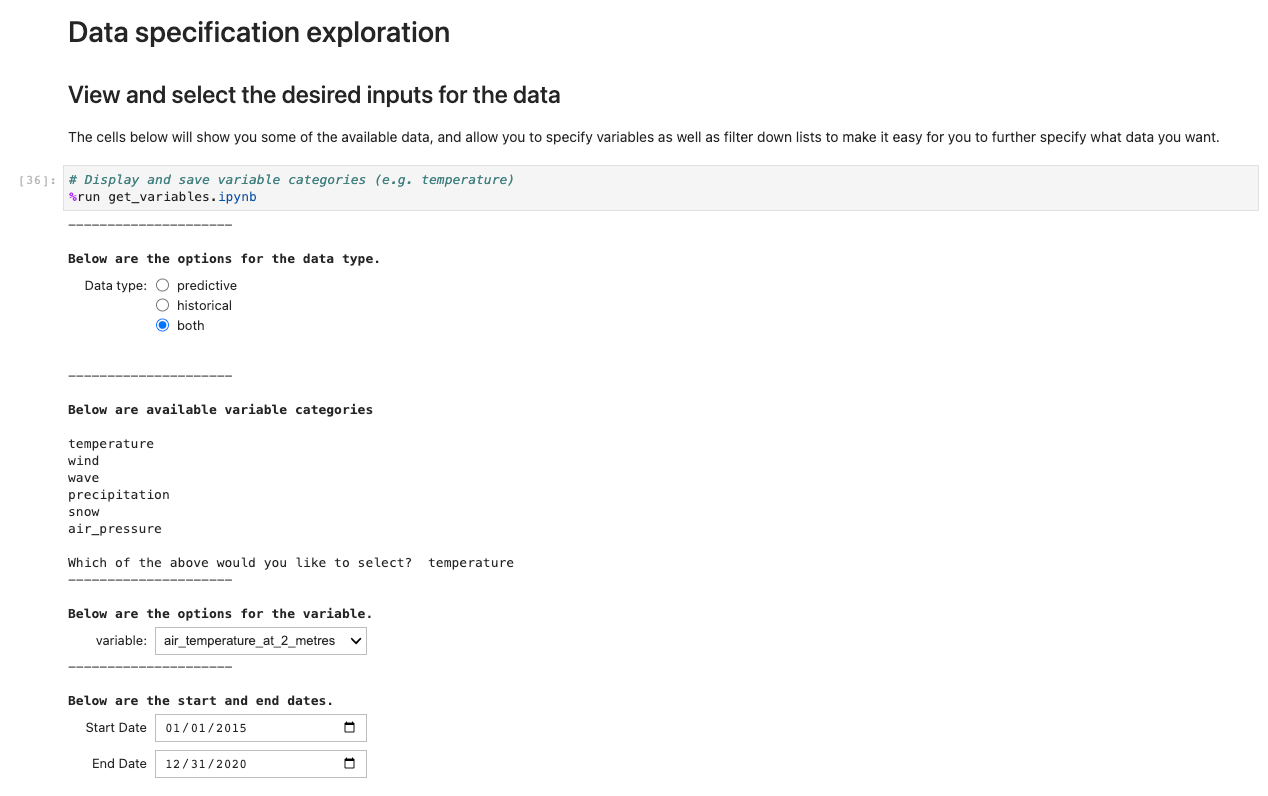
For at køre programmet skal du åbne og køre den første celle af ux_notebook. Denne celle kører get_variables notesbog i baggrunden, som beder dig om input til de data, du gerne vil vælge. Vi inkluderer et eksempel; Bemærk dog, at spørgsmål først vises, efter at den forrige mulighed er valgt. Dette er med vilje til at begrænse valgmulighederne i rullemenuen og kan eventuelt konfigureres ved at redigere get_variables notesbog.
Den foregående kode gemmer variabler globalt, så andre notebooks kan hente og indlæse dit udvalg af valg. Til demonstration skal den næste celle udsende gemte variabler fra før.
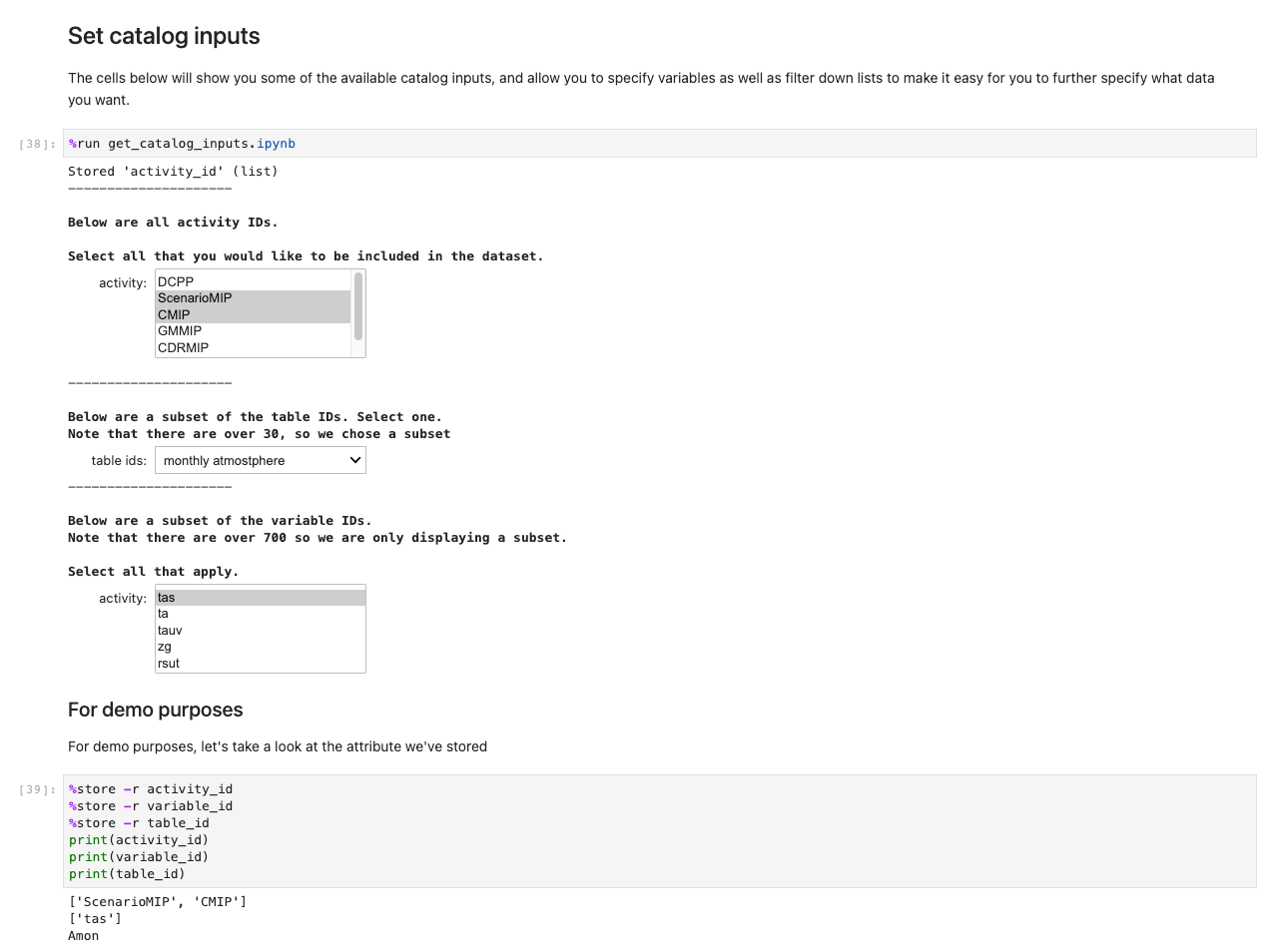
Derefter vises en prompt om yderligere dataspecifikationer. Denne celle forfiner de data, du leder efter, ved at præsentere id'erne for tabeller i et menneskeligt læsbart format. Brugere vælger, som om det var en formular, men titlerne er knyttet til tabeller i baggrunden, der hjælper systemet med at hente de relevante datasæt.
Når du har gemt alle dine valg og udvalgte celler, skal du indlæse dataene i regionerne ved at køre cellen i Henter data sæt afsnit. %%capture-kommandoen vil undertrykke unødvendige output fra get_data notesbog. Bemærk, at du kan fjerne dette for at inspicere output fra de andre notebooks. Data hentes derefter i backend.
Mens andre notebooks køres i baggrunden, er det eneste berøringspunkt for brugeren ux_notebook. Dette er for at abstrahere den kedelige proces med at importere data til et format, som enhver bruger er i stand til at følge med lethed.
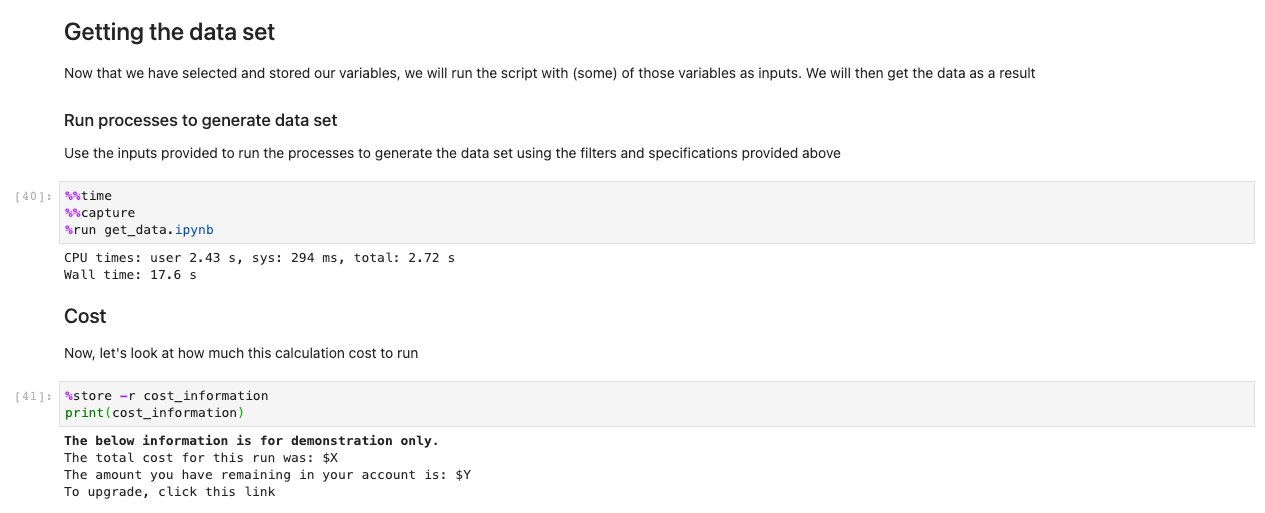
Med dataene nu indlæst, kan vi begynde at interagere med dem. De følgende celler er eksempler på beregninger, du kan køre på vejrdata. Ved brug af røntgenbilleder, vi importerer, beregner og plotter derefter disse datasæt.
Vores eksempel illustrerer et plot af forudsigende data, der henter data, kører beregningen og plotter resultaterne på under 7.5 sekunder - størrelsesordener hurtigere end en typisk tilgang.
Under kølerhjelmen
Notesbøgerne get_catalog_input , get_variables bruge biblioteket ipywidgets for at vise widgets såsom rullemenuer og valg af flere felter. Disse muligheder gemmes globalt ved hjælp af %%store-kommandoen, så de kan tilgås fra ux_notebook. En af mulighederne beder dig om, hvorvidt du vil have historiske data, forudsigelige data eller begge dele. Denne variabel overføres til get_data notesbog for at bestemme, hvilke efterfølgende notesbøger der skal køres.
get_data notebook henter først det delte OpenSearch Service-domæne, der er gemt på AWS Systems Manager Parameter Store. Dette domæne giver vores notesbog mulighed for at køre en forespørgsel om indsamling af information, der vil indikere, hvor de valgte datasæt er gemt regionalt. Med disse datasæt lokaliseret regionalt, vil notebook'en forsøge at oprette forbindelse til Dask-planlæggeren og videregive oplysningerne indsamlet fra OpenSearch Service. Dask-planlæggeren vil til gengæld være i stand til at kalde på arbejdere i de korrekte regioner.
Hvordan man tilpasser og fortsætter udviklingen
Disse notesbøger er beregnet til at være et eksempel på, hvordan du kan skabe en måde, hvorpå brugere kan interface og interagere med dataene. Notesbogen i dette indlæg tjener som en illustration til, hvad der er muligt, og vi inviterer dig til at fortsætte med at bygge videre på løsningen for yderligere at forbedre brugerengagementet. Kernedelen af denne løsning er backend-teknologien, men uden en eller anden mekanisme til at interagere med denne backend, vil brugerne ikke realisere det fulde potentiale af løsningen.
Slet ressourcerne for at undgå fremtidige gebyrer. Lad os ødelægge vores installerede løsning med følgende kommando:
Konklusion
Dette indlæg viser udvidelsen af Dask inter-Regionalt på AWS og en mulig integration med offentlige datasæt på AWS. Løsningen blev bygget som et generisk mønster, og yderligere datasæt kan indlæses for at accelerere høje I/O-analyser på komplekse data.
Data transformerer hvert felt og enhver virksomhed. Men da data vokser hurtigere end de fleste virksomheder kan holde styr på, er det en udfordring at indsamle data og få værdi ud af disse data. En moderne datastrategi kan hjælpe dig med at skabe bedre forretningsresultater med data. AWS leverer det mest komplette sæt af tjenester til end-to-end datarejsen for at hjælpe dig med at låse op for værdi fra dine data og omdanne dem til indsigt.
For at lære mere om de forskellige måder at bruge dine data på i skyen, besøg AWS Big Data Blog. Vi inviterer dig yderligere til at kommentere med dine tanker om dette indlæg, og om det er en løsning, du planlægger at prøve.
Om forfatterne
 Patrick O'Connor er en WWSO Prototyping Engineer baseret i London. Han er en kreativ problemløser, der kan tilpasses på tværs af en bred vifte af teknologier, såsom IoT, serverløs teknologi, 3D rumlig teknologi og ML/AI, sammen med en ubarmhjertig nysgerrighed på, hvordan teknologi kan fortsætte med at udvikle hverdagens tilgange.
Patrick O'Connor er en WWSO Prototyping Engineer baseret i London. Han er en kreativ problemløser, der kan tilpasses på tværs af en bred vifte af teknologier, såsom IoT, serverløs teknologi, 3D rumlig teknologi og ML/AI, sammen med en ubarmhjertig nysgerrighed på, hvordan teknologi kan fortsætte med at udvikle hverdagens tilgange.
 Chakra Nagarajan er en Principal Machine Learning Prototyping SA med 21 års erfaring inden for machine learning, big data og højtydende computing. I sin nuværende rolle hjælper han kunder med at løse komplekse forretningsproblemer i den virkelige verden ved at bygge prototyper med end-to-end AI/ML-løsninger i cloud- og edge-enheder. Hans ML-specialisering omfatter computersyn, naturlig sprogbehandling, tidsserieprognoser og personalisering.
Chakra Nagarajan er en Principal Machine Learning Prototyping SA med 21 års erfaring inden for machine learning, big data og højtydende computing. I sin nuværende rolle hjælper han kunder med at løse komplekse forretningsproblemer i den virkelige verden ved at bygge prototyper med end-to-end AI/ML-løsninger i cloud- og edge-enheder. Hans ML-specialisering omfatter computersyn, naturlig sprogbehandling, tidsserieprognoser og personalisering.
 Val Cohen er en senior WWSO Prototyping Engineer baseret i London. Val er en problemløser af natur og nyder at skrive kode til at automatisere processer, bygge kundebesatte værktøjer og skabe infrastruktur til forskellige applikationer til sin globale kundebase. Val har erfaring på tværs af en bred vifte af teknologier, såsom front-end webudvikling, backend-arbejde og AI/ML.
Val Cohen er en senior WWSO Prototyping Engineer baseret i London. Val er en problemløser af natur og nyder at skrive kode til at automatisere processer, bygge kundebesatte værktøjer og skabe infrastruktur til forskellige applikationer til sin globale kundebase. Val har erfaring på tværs af en bred vifte af teknologier, såsom front-end webudvikling, backend-arbejde og AI/ML.
 Niall Robinson er chef for produktfutures på UK Met Office. Han og hans team udforsker nye måder, hvorpå Met Office kan levere værdi gennem produktinnovation og strategiske partnerskaber. Han har haft en varieret karriere, hvor han har ledet et tværfagligt informatik-F&U-team, akademisk forskning i datavidenskab og feltforsker sammen med ekspertise inden for klimamodeller.
Niall Robinson er chef for produktfutures på UK Met Office. Han og hans team udforsker nye måder, hvorpå Met Office kan levere værdi gennem produktinnovation og strategiske partnerskaber. Han har haft en varieret karriere, hvor han har ledet et tværfagligt informatik-F&U-team, akademisk forskning i datavidenskab og feltforsker sammen med ekspertise inden for klimamodeller.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Udmøntning af fremtiden med Adryenn Ashley. Adgang her.
- Køb og sælg aktier i PRE-IPO-virksomheder med PREIPO®. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- :har
- :er
- :hvor
- $OP
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- evne
- I stand
- Om
- over
- ABSTRACT
- abstracts
- akademisk
- akademisk forskning
- fremskynde
- accelererende
- adgang
- af udleverede
- imødekomme
- udrette
- Konto
- opnår
- tværs
- tilpasser
- tilføjet
- tilføje
- Yderligere
- Derudover
- adresse
- adressering
- Tilføjer
- administratorer
- vedtaget
- Vedtagelse
- Efter
- AI / ML
- LUFT
- Alle
- tillade
- tillader
- sammen
- også
- Amazon
- Amazon EC2
- an
- analyse
- ,
- enhver
- vises
- Anvendelse
- applikationer
- tilgang
- tilgange
- passende
- arkitektur
- ER
- AS
- At
- Atmosfære
- atmosfærisk
- automatisere
- undgå
- AWS
- AWS kunde
- Backbone
- Backed
- Bagende
- baggrund
- Balance
- bund
- baseret
- BE
- bliver
- været
- før
- være
- jf. nedenstående
- benchmark
- Bedre
- mellem
- Big
- Big data
- Bootstrap
- både
- Bringe
- Broken
- bygge
- Bygning
- bygget
- indbygget
- virksomhed
- men
- by
- beregne
- ringe
- kaldet
- ringer
- Opkald
- CAN
- kapaciteter
- stand
- Karriere
- katalog
- CD
- Celler
- udfordre
- udfordrende
- lave om
- skiftende
- afgift
- afgifter
- valg
- Circulation
- kunde
- Klima
- tættere
- Cloud
- Cluster
- CO
- kode
- kodebase
- samarbejde
- Indsamling
- Kom
- kommer
- kommer
- KOMMENTAR
- samfund
- Virksomheder
- fuldføre
- komplekse
- komponenter
- Indeholder
- beregning
- Compute
- computer
- Computer Vision
- computing
- Konfiguration
- Tilslut
- tilsluttet
- Tilslutning
- tilslutning
- Forbrugere
- forbrug
- Container
- indeholder
- fortsæt
- fortsætter
- kopier
- Core
- korrigere
- Koste
- omkostningseffektiv
- kunne
- koblede
- CPU
- skabe
- skaber
- Kreativ
- kritisk
- afgrøde
- Cross
- nysgerrighed
- Nuværende
- skik
- kunde
- Kunder
- tilpasses
- tilpasse
- dagligt
- instrumentbræt
- data
- datalogi
- datastrategi
- datasæt
- dag
- årti
- afgørelser
- Standard
- Efterspørgsel
- demonstrerer
- indsætte
- indsat
- implementering
- udruller
- konstrueret
- ødelægge
- detaljeret
- detaljer
- Bestem
- udvikle
- Udvikler
- Udvikling
- Enheder
- forskel
- deaktiveret
- opdagelse
- Skærm
- distribueret
- distribueret computing
- dns
- Docker
- domæne
- ned
- dynamisk
- dynamisk
- hver
- lette
- nemt
- Edge
- redigering
- effektiv
- andetsteds
- muliggøre
- ende til ende
- energi
- engagement
- ingeniør
- indrejse
- Miljø
- Ækvivalent
- Era
- anslået
- Ether (ETH)
- Hver
- hver dag
- hverdagen
- udvikle sig
- eksempel
- eksempler
- erfaring
- eksperiment
- ekspertise
- udforske
- eksport
- udsat
- udvidelse
- hurtigere
- Feature
- Funktionalitet
- felt
- Fields
- File (Felt)
- Filer
- Finde
- Fornavn
- fokuserer
- følger
- efter
- mad
- Til
- formular
- format
- formularer
- fundet
- Grundlagt
- Framework
- rammer
- Gratis
- fra
- bære frugt
- fuld
- funktionalitet
- yderligere
- fremtiden
- Futures
- Generelt
- generation
- få
- få
- Git
- Global
- globalt netværk
- Globalt
- kloden
- gå
- graf
- større
- Grid
- Grow
- Dyrkning
- havde
- Halvdelen
- halveret
- Have
- he
- hoved
- hjælpe
- hjælper
- hende
- Høj
- Høj ydeevne
- højdepunkter
- hans
- historisk
- host
- hostede
- time
- Hvordan
- How To
- Men
- HTML
- HTTPS
- læsbar
- Hundreder
- tomgang
- id'er
- if
- illustrerer
- importere
- importere
- Forbedre
- in
- omfatter
- omfatter
- øget
- indeks
- angiver
- informere
- oplysninger
- Infrastruktur
- iboende
- Innovation
- indgang
- usikkerhed
- indsigt
- inspirerede
- installere
- instans
- i stedet
- anvisninger
- integration
- Forsætlig
- interagere
- interaktion
- grænseflade
- interne
- Internet
- ind
- invitere
- tingenes internet
- IP
- IP-adresse
- spørgsmål
- IT
- ITS
- Job
- rejse
- jpg
- Jupyter Notebook
- Holde
- Nøgle
- Kend
- Sprog
- stor
- Efternavn
- Latency
- lancere
- førende
- LÆR
- læring
- Bibliotek
- livscyklus
- ligesom
- Linking
- Liste
- belastning
- lokale
- lokalt
- placeret
- placering
- London
- maskine
- machine learning
- større
- lave
- administrere
- leder
- administrerer
- kort
- kortlægning
- Masse
- Masseadoption
- materiale
- Kan..
- betyde
- mekanisme
- Metadata
- millioner
- ML
- model
- Moderne
- Moduler
- Måned
- månedligt
- månedlige data
- mere
- mest
- MONTERING
- tværfaglig
- navn
- national
- Natural
- Naturligt sprog
- Natural Language Processing
- Natur
- nødvendig
- Behov
- behøve
- netværk
- Ny
- næste
- nat
- node
- noder
- notesbog
- notesbøger
- nu
- nummer
- numre
- of
- tilbyde
- Office
- on
- ONE
- kun
- åbent
- åbne data
- open source
- open source-kode
- operationelle
- Option
- Indstillinger
- or
- orkestrering
- organisationer
- Andet
- vores
- ud
- udfald
- output
- i løbet af
- samlet
- pakke
- parameter
- del
- særlig
- især
- partnerskaber
- Bestået
- Passing
- Mønster
- ydeevne
- perioder
- Personalisering
- petabytes
- fase
- fly
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Punkt
- pool
- porte
- mulig
- Indlæg
- potentiale
- magt
- vigtigste
- praksis
- forudsigelse
- Forudsigelser
- forudsætninger
- tidligere
- primære
- Main
- private
- Problem
- problemer
- behandle
- Processer
- forarbejdning
- produceret
- Produkt
- Produkt Innovation
- produktiv
- Program
- Programmering
- projekt
- prototyper
- prototyping
- give
- forudsat
- giver
- bestemmelse
- offentlige
- offentliggøre
- offentliggjort
- Sweatre & trøjer
- forespørgsler
- Spørgsmål
- F & U
- rækkevidde
- hellere
- færdiglavet
- virkelige verden
- indse
- reducere
- reducere
- reduktion
- region
- regional
- regioner
- ubarmhjertig
- resterne
- Fjern
- fjernet
- Repository
- repræsenterer
- forskning
- Ressourcer
- dem
- Resultater
- roller
- Kør
- kører
- SA
- sikker
- sagemaker
- samme
- Gem
- skalerbar
- Scale
- skalaer
- skalering
- Videnskab
- Videnskabsmand
- forskere
- scripts
- sekunder
- Sektion
- se
- set
- segmenter
- valgt
- valg
- senior
- Series
- Serverless
- tjener
- tjeneste
- Tjenester
- sæt
- Del
- delt
- bør
- Vis
- fremvisning
- Shows
- Simpelt
- ganske enkelt
- 6.
- langsom
- So
- løsninger
- Løsninger
- SOLVE
- nogle
- Kilde
- rumlige
- specifikt
- specifikationer
- specificeret
- sponsorering
- stable
- etaper
- standalone
- starte
- påbegyndt
- forblive
- Steps
- opbevaring
- butik
- opbevaret
- forhandler
- ligetil
- Strategisk
- strategiske partnerskaber
- Strategi
- efterfølgende
- Efterfølgende
- vellykket
- sådan
- overflade
- bølge
- Bæredygtighed
- bæredygtig
- systemet
- Systemer
- bord
- Tag
- hold
- tech
- Teknologier
- Teknologier
- prøve
- end
- at
- oplysninger
- The Source
- UK
- verdenen
- deres
- derefter
- Der.
- derved
- Disse
- de
- denne
- dem
- tre
- Trives
- Gennem
- kapacitet
- tid
- Tidsserier
- gange
- titler
- til
- i dag
- sammen
- værktøjer
- spor
- Sporing
- overførsel
- omdanne
- transit
- udløsning
- TUR
- to
- typen
- maskinskrift
- typisk
- Uk
- under
- låse
- uholdbar
- up-to-date
- opdateringer
- på
- URI
- Brug
- brug
- anvendte
- Bruger
- brugere
- ved brug af
- UTC
- Ved hjælp af
- VAL
- værdi
- række
- forskellige
- via
- vision
- Besøg
- bind
- ønsker
- ønsker
- varm
- var
- Vej..
- måder
- we
- Vejr
- web
- Web udvikling
- var
- hvorvidt
- som
- bred
- Bred rækkevidde
- vilje
- ønsker
- med
- uden
- Arbejde
- arbejdstager
- arbejdere
- world
- bekymre sig
- ville
- skrivning
- år
- endnu
- Udbytte
- dig
- Din
- zephyrnet