Værdien af data er tidsfølsom. Realtidsbehandling gør datadrevne beslutninger nøjagtige og handlingsrettede på sekunder eller minutter i stedet for timer eller dage. Change data capture (CDC) refererer til processen med at identificere og fange ændringer foretaget i data i en database og derefter levere disse ændringer i realtid til et downstream-system. Opfangning af enhver ændring fra transaktioner i en kildedatabase og flytning af dem til målet i realtid holder systemerne synkroniserede og hjælper med brugssager i realtid og databasemigreringer uden nedetid. Følgende er et par fordele ved CDC:
- Det eliminerer behovet for bulk load opdatering og ubelejlige batchvinduer ved at muliggøre trinvis indlæsning eller realtidsstreaming af dataændringer til dit mållager.
- Det sikrer, at data i flere systemer forbliver synkroniseret. Dette er især vigtigt, hvis du træffer tidsfølsomme beslutninger i et datamiljø med høj hastighed.
Kafka Connect er en open source-komponent af Apache Kafka, der fungerer som en centraliseret datahub til simpel dataintegration mellem databaser, nøgleværdilagre, søgeindekser og filsystemer. Det AWS Lim Schema Registry giver dig mulighed for centralt at opdage, kontrollere og udvikle datastrømsskemaer. Kafka Connect og Schema Registry integreres for at fange skemaoplysninger fra connectors. Kafka Connect giver en mekanisme til at konvertere data fra de interne datatyper, der bruges af Kafka Connect, til datatyper repræsenteret som Avro, Protobuf eller JSON Schema. AvroConverter, ProtobufConverter og JsonSchemaConverter registrerer automatisk skemaer genereret af Kafka-forbindelser (kilde), der producerer data til Kafka. Connectors (sink), der forbruger data fra Kafka, modtager skemaoplysninger ud over dataene for hver besked. Dette giver sink-forbindelser mulighed for at kende strukturen af dataene for at give muligheder som at vedligeholde et databasetabelskema i et datakatalog.
Indlægget demonstrerer, hvordan man bygger en ende-til-ende CDC ved hjælp af Amazon MSK Connect, en AWS-administreret tjeneste til at implementere og køre Kafka Connect-applikationer og AWS Glue Schema Registry, som giver dig mulighed for centralt at opdage, kontrollere og udvikle datastrømskemaer.
Løsningsoversigt
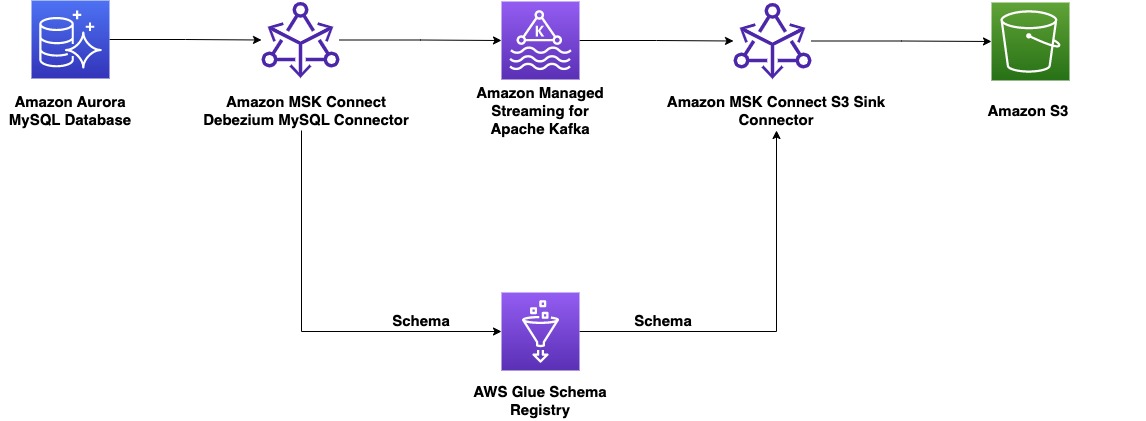
På producentsiden vælger vi til dette eksempel en MySQL-kompatibel Amazon Aurora database som datakilde, og vi har en Debezium MySQL-stik til at udføre CDC. Debezium-forbindelsen overvåger kontinuerligt databaserne og skubber ændringer på rækkeniveau til et Kafka-emne. Connectoren henter skemaet fra databasen for at serialisere posterne til en binær form. Hvis skemaet ikke allerede findes i registreringsdatabasen, vil skemaet blive registreret. Hvis skemaet eksisterer, men serializeren bruger en ny version, kontrollerer skemaregistret kompatibilitetstilstand af skemaet før opdatering af skemaet. I denne løsning bruger vi bagudkompatibilitetstilstand. Skemaregistret returnerer en fejl, hvis en ny version af skemaet ikke er bagudkompatibel, og vi kan konfigurere Kafka Connect til at sende inkompatible beskeder til dødbogstavskøen.
På forbrugersiden bruger vi en Amazon Simple Storage Service (Amazon S3) synkestik til at deserialisere pladen og gemme ændringer til Amazon S3. Vi bygger og implementerer Debezium-stikket og Amazon S3-vasken ved hjælp af MSK Connect.
Eksempel skema
Til dette indlæg bruger vi følgende skema som den første version af tabellen:
Forudsætninger
Før vi konfigurerer MSK-producent- og forbrugerforbindelserne, skal vi først konfigurere en datakilde, MSK-klynge og et nyt skemaregister. Vi leverer en AWS CloudFormation skabelon til at generere de understøttende ressourcer, der er nødvendige for løsningen:
- En MySQL-kompatibel Aurora-database som datakilde. For at udføre CDC aktiverer vi binær logning i DB-klyngeparametergruppe.
- En MSK-klynge. For at forenkle netværksforbindelsen bruger vi den samme VPC til Aurora-databasen og MSK-klyngen.
- To skemaregistre til at håndtere skemaer for meddelelsesnøgle og meddelelsesværdi.
- Én S3-spand som datavask.
- MSK Connect-plugins og arbejderkonfiguration er nødvendig for denne demo.
- Én Amazon Elastic Compute Cloud (Amazon EC2) instans til at køre databasekommandoer.
For at konfigurere ressourcer på din AWS-konto skal du udføre følgende trin i en AWS-region, der understøtter Amazon MSK, MSK Connect og AWS Glue Schema Registry:
- Vælg Start Stack:
- Vælg Næste.
- Til Staknavn, indtast passende navn.
- Til Database adgangskode, indtast den adgangskode, du ønsker til databasebrugeren.
- Behold andre værdier som standard.
- Vælg Næste.
- Vælg på næste side Næste.
- Gennemgå detaljerne på den sidste side, og vælg Jeg anerkender, at AWS CloudFormation kan skabe IAM-ressourcer.
- Vælg Opret stak.
Brugerdefineret plugin til kilde- og destinationsstikket
Et brugerdefineret plugin er et sæt JAR-filer, der indeholder implementeringen af en eller flere konnektorer, transformere eller konvertere. Amazon MSK installerer plugin'et på arbejderne i MSK Connect-klyngen, hvor stikket kører. Som en del af denne demo bruger vi open source til kildeforbindelsen Debezium MySQL-stik JAR'er, og til destinationsforbindelsen bruger vi Confluent-fællesskabet licenseret Amazon S3 vask-stik JAR'er. Begge plugins er også tilføjet med biblioteker til Avro Serializers og Deserializers af AWS Glue Schema Registry. Disse brugerdefinerede plugins er allerede oprettet som en del af CloudFormation-skabelonen, der blev implementeret i det forrige trin.
Brug AWS Glue Schema Registry med Debezium-stikket på MSK Connect som MSK-producent
Vi implementerer først kildestikket ved hjælp af Debezium MySQL-plugin til at streame data fra en Amazon Aurora MySQL-kompatibel udgave database til Amazon MSK. Udfør følgende trin:
- På Amazon MSK-konsollen, i navigationsruden, under MSK Connect, vælg Stik.
- Vælg Opret forbindelse.
- Vælg Brug eksisterende brugerdefineret plugin og vælg derefter det brugerdefinerede plugin, hvor navnet starter
msk-blog-debezium-source-plugin. - Vælg Næste.
- Indtast et passende navn som f.eks
debezium-mysql-connectorog en valgfri beskrivelse. - Til Apache Kafka klynge, vælg MSK klynge og vælg den klynge, der er oprettet af CloudFormation-skabelonen.
- In Stikkonfiguration, slet standardværdierne og brug følgende konfigurationsnøgle-værdi-par og med de relevante værdier:
- navn – Navnet, der bruges til stikket.
- database.værtsnavn – CloudFormation-outputtet for Database slutpunkt.
- database.bruger og database.adgangskode – De parametre, der sendes i CloudFormation-skabelonen.
- database.history.kafka.bootstrap.servere – CloudFormation-outputtet for Kafka støvlestrap.
- key.converter.region og value.converter.region – Din region.
Nogle af disse indstillinger er generiske og bør specificeres for ethvert stik. For eksempel:
- connector.class er Java-klassen for connectoren
- tasks.max er det maksimale antal opgaver, der skal oprettes for denne connector
nogle indstillinger (database.*, transforms.*) er specifikke for Debezium MySQL-stikket. Henvise til Debezium MySQL Source Connector Configuration Properties for mere information.
nogle indstillinger (key.converter.* , value.converter.*) er specifikke for Schema Registry. Vi bruger AWSKafkaAvroConverter fra AWS Glue Schema Registry Library som formatkonverter. At konfigurere AWSKafkaAvroConverter, bruger vi værdien af strengkonstantens egenskaber i AWSchemaRegistryConstants klasse:
key.converter,value.converterstyre formatet af de data, der vil blive skrevet til Kafka for kildestik eller læst fra Kafka for vaskkonnektorer. Vi brugerAWSKafkaAvroConvertertil Avro-format.key.converter.registry.name,value.converter.registry.namedefinere hvilken skemaregistrering der skal bruges.key.converter.compatibility,value.converter.compatibilitydefinere kompatibilitetsmodellen.
Der henvises til Brug af Kafka Connect med AWS Glue Schema Registry for mere information.
- Dernæst konfigurerer vi Konnektorkapacitet. Vi kan vælge Forsynet og lad andre egenskaber være standard
- Til Arbejderkonfiguration, skal du vælge den tilpassede arbejderkonfiguration, hvor navnet starter
msk-gsr-blogoprettet som en del af CloudFormation-skabelonen. - Til Adgangstilladelser, brug AWS identitets- og adgangsstyring (IAM)-rolle genereret af CloudFormation-skabelonen
MSKConnectRole. - Vælg Næste.
- Til Sikkerhed, vælg standardindstillingerne.
- Vælg Næste.
- Til Log levering, Vælg Lever til Amazon CloudWatch Logs og søg efter loggruppen oprettet af CloudFormation-skabelonen (
msk-connector-logs). - Vælg Næste.
- Gennemgå indstillingerne og vælg Opret forbindelse.
Efter et par minutter skifter stikket til kørestatus.
Brug AWS Glue Schema Registry med Confluent S3 vaskekonnektoren, der kører på MSK Connect som MSK-forbruger
Vi installerer sink-stikket ved hjælp af Confluent S3 sink-plugin til at streame data fra Amazon MSK til Amazon S3. Udfør følgende trin:
-
- På Amazon MSK-konsollen, i navigationsruden, under MSK Connect, vælg Stik.
- Vælg Opret forbindelse.
- Vælg Brug eksisterende brugerdefineret plugin og vælg det brugerdefinerede plugin med navnet begyndende
msk-blog-S3sink-plugin. - Vælg Næste.
- Indtast et passende navn som f.eks
s3-sink-connectorog en valgfri beskrivelse. - Til Apache Kafka klynge, vælg MSK klynge og vælg den klynge, der er oprettet af CloudFormation-skabelonen.
- In Stikkonfiguration, slet de angivne standardværdier og brug følgende konfigurationsnøgleværdipar med passende værdier:
-
- navn – Det samme navn bruges til stikket.
- s3.bucket.name – CloudFormation-outputtet for Navn på spand.
- s3.region, key.converter.region og value.converter.region – Din region.
-
- Dernæst konfigurerer vi Konnektorkapacitet. Vi kan vælge Forsynet og lad andre egenskaber være standard
- Til Arbejderkonfiguration, skal du vælge den tilpassede arbejderkonfiguration, hvor navnet starter
msk-gsr-blogoprettet som en del af CloudFormation-skabelonen. - Til Adgangstilladelser, brug IAM-rollen genereret af CloudFormation-skabelonen
MSKConnectRole. - Vælg Næste.
- Til Sikkerhed, vælg standardindstillingerne.
- Vælg Næste.
- Til Log levering, Vælg Lever til Amazon CloudWatch Logs og søg efter loggruppen, der er oprettet af CloudFormation-skabelonen
msk-connector-logs. - Vælg Næste.
- Gennemgå indstillingerne og vælg Opret forbindelse.
Efter et par minutter kører stikket.
Test ende-til-ende CDC-logstreamen
Nu hvor både Debezium- og S3-vaskestikkene er oppe og køre, skal du udføre følgende trin for at teste ende-til-ende CDC:
- På Amazon EC2-konsollen skal du navigere til Sikkerhedsgrupper .
- Vælg sikkerhedsgruppen
ClientInstanceSecurityGroupOg vælg Rediger indgående regler. - Tilføj en indgående regel, der tillader SSH-forbindelse fra dit lokale netværk.
- På tilfælde side, skal du vælge forekomsten
ClientInstanceOg vælg Tilslut. - På EC2 Instance Connect fanebladet, vælg Tilslut.
- Sørg for, at din nuværende arbejdsmappe er
/home/ec2-userog den har filernecreate_table.sql,alter_table.sql,initial_insert.sqloginsert_data_with_new_column.sql. - Opret en tabel i din MySQL-database ved at køre følgende kommando (giv databaseværtsnavnet fra CloudFormations skabelonoutput):
- Når du bliver bedt om en adgangskode, skal du indtaste adgangskoden fra CloudFormations skabelonparametre.
- Indsæt nogle eksempeldata i tabellen med følgende kommando:
- Når du bliver bedt om en adgangskode, skal du indtaste adgangskoden fra CloudFormations skabelonparametre.
- På AWS Glue-konsollen skal du vælge Skema registre i navigationsruden, og vælg derefter skemaer.
- Naviger til
db1.sampledatabase.moviesversion 1 for at kontrollere det nye skema oprettet til filmtabellen:
Der oprettes en separat S3-mappe for hver partition af Kafka-emnet, og data for emnet skrives i den mappe.
- På Amazon S3-konsollen skal du tjekke for data skrevet i parketformat i mappen til dit Kafka-emne.
Skema udvikling
Når det indledende skema er defineret, skal applikationer muligvis udvikle det over tid. Når dette sker, er det afgørende for downstream-forbrugerne at kunne håndtere data kodet med både det gamle og det nye skema problemfrit. Kompatibilitetstilstande giver dig mulighed for at kontrollere, hvordan skemaer kan eller ikke kan udvikle sig over tid. Disse tilstande danner kontrakten mellem applikationer, der producerer og forbruger data. For detaljerede oplysninger om forskellige kompatibilitetstilstande tilgængelige i AWS Glue Schema Registry, se AWS Lim Schema Registry. I vores eksempel bruger vi baglæns combability for at sikre, at forbrugerne kan læse både den nuværende og tidligere skemaversioner. Udfør følgende trin:
- Tilføj en ny kolonne til tabellen ved at køre følgende kommando:
- Indsæt nye data i tabellen ved at køre følgende kommando:
- På AWS Glue-konsollen skal du vælge Skema registre i navigationsruden, og vælg derefter skemaer.
- Naviger til skemaet
db1.sampledatabase.moviesversion 2 for at kontrollere den nye version af skemaet, der er oprettet til filmtabelfilmene, inklusive landekolonnen, som du tilføjede:
- På Amazon S3-konsollen skal du tjekke for data skrevet i parketformat i mappen for Kafka-emnet.
Ryd op
For at hjælpe med at forhindre uønskede debiteringer på din AWS-konto skal du slette de AWS-ressourcer, du brugte i dette indlæg:
- På Amazon S3-konsollen skal du navigere til S3-bøtten, der er oprettet af CloudFormation-skabelonen.
- Vælg alle filer og mapper, og vælg Slette.
- Indtast Slet permanent som anvist, og vælg Slet objekter.
- På AWS CloudFormation-konsollen skal du slette den stak, du har oprettet.
- Vent på, at stakstatus ændres til DELETE_COMPLETE.
Konklusion
Dette indlæg demonstrerede, hvordan man bruger Amazon MSK, MSK Connect og AWS Glue Schema Registry til at bygge en CDC-logstrøm og udvikle skemaer til datastrømme, efterhånden som forretningsbehov ændrer sig. Du kan anvende dette arkitekturmønster på andre datakilder med forskellige Kafka-forbindelser. For mere information, se MSK Connect eksempler.
Om forfatteren
 Kalyan Janaki er Senior Big Data & Analytics Specialist hos Amazon Web Services. Han hjælper kunder med at udforme og bygge meget skalerbare, effektive og sikre cloud-baserede løsninger på AWS.
Kalyan Janaki er Senior Big Data & Analytics Specialist hos Amazon Web Services. Han hjælper kunder med at udforme og bygge meget skalerbare, effektive og sikre cloud-baserede løsninger på AWS.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :er
- $OP
- 1
- 10
- 11
- 7
- 8
- a
- I stand
- Om
- adgang
- Konto
- præcis
- anerkende
- tilføjet
- Desuden
- Alle
- tillade
- tillader
- allerede
- Amazon
- Amazon EC2
- Amazon Web Services
- analytics
- ,
- Apache
- Apache Kafka
- applikationer
- Indløs
- passende
- arkitektur
- ER
- AS
- Aurora
- automatisk
- til rådighed
- AWS
- AWS CloudFormation
- AWS Lim
- BE
- før
- fordele
- mellem
- Big
- Big data
- Bootstrap
- bygge
- virksomhed
- by
- CAN
- kapaciteter
- fange
- Optagelse
- tilfælde
- katalog
- CDC
- centraliseret
- lave om
- Ændringer
- afgifter
- kontrollere
- Kontrol
- Vælg
- klasse
- Cluster
- Kolonne
- samfund
- kompatibilitet
- kompatibel
- fuldføre
- komponent
- Compute
- Konfiguration
- krydset
- Tilslut
- tilslutning
- Konsol
- konstant
- forbruge
- forbruger
- Forbrugere
- kontinuerligt
- kontrakt
- kontrol
- land
- skabe
- oprettet
- kritisk
- Nuværende
- skik
- Kunder
- data
- dataintegration
- datastyret
- Database
- databaser
- Dage
- afgørelser
- Standard
- defaults
- definerede
- leverer
- Demo
- demonstreret
- demonstrerer
- indsætte
- indsat
- beskrivelse
- destination
- detaljeret
- detaljer
- forskellige
- opdage
- Er ikke
- Drop
- hver
- eliminerer
- muliggør
- ende til ende
- sikre
- sikrer
- Indtast
- Miljø
- fejl
- især
- Ether (ETH)
- Hver
- udvikle sig
- eksempel
- eksisterende
- eksisterer
- få
- Fields
- File (Felt)
- Filer
- endelige
- Fornavn
- efter
- Til
- formular
- format
- fra
- generere
- genereret
- gruppe
- Gruppens
- håndtere
- Håndtering
- sker
- Have
- hjælpe
- hjælper
- stærkt
- historie
- host
- HOURS
- Hvordan
- How To
- HTML
- http
- HTTPS
- Hub
- IAM
- identificere
- Identity
- implementering
- vigtigt
- in
- Herunder
- indekser
- oplysninger
- initial
- installere
- instans
- i stedet
- integrere
- integration
- interne
- IT
- Java
- jpg
- json
- Kafka
- Nøgle
- Kend
- Forlade
- biblioteker
- Licenseret
- ligesom
- belastning
- lastning
- lokale
- Lang
- lavet
- maerker
- Making
- lykkedes
- Master
- max
- maksimal
- mekanisme
- besked
- beskeder
- måske
- minutter
- model
- modes
- skærme
- mere
- Film
- flytning
- flere
- MySQL
- navn
- Naviger
- Navigation
- Behov
- behov
- behov
- netværk
- Ny
- næste
- nummer
- of
- Gammel
- on
- ONE
- open source
- Andet
- output
- side
- par
- brød
- parameter
- parametre
- del
- Bestået
- Adgangskode
- Mønster
- udføre
- permanent
- pick
- plato
- Platon Data Intelligence
- PlatoData
- plugin
- Plugins
- Indlæg
- forhindre
- tidligere
- behandle
- forarbejdning
- producere
- producent
- egenskaber
- give
- forudsat
- giver
- Læs
- ægte
- realtid
- modtage
- optage
- optegnelser
- refererer
- region
- register
- registreret
- register
- Repository
- repræsenteret
- Ressourcer
- afkast
- roller
- Herske
- Kør
- kører
- samme
- skalerbar
- problemfrit
- Søg
- sekunder
- sikker
- sikkerhed
- senior
- følsom
- adskille
- tjeneste
- Tjenester
- sæt
- indstillinger
- bør
- Simpelt
- forenkle
- løsninger
- Løsninger
- nogle
- Kilde
- Kilder
- specialist
- specifikke
- specificeret
- stable
- Starter
- Status
- Trin
- Steps
- opbevaring
- butik
- forhandler
- strøm
- streaming
- vandløb
- struktur
- egnede
- Støtte
- Understøtter
- synkronisere.
- systemet
- Systemer
- bord
- mål
- opgaver
- skabelon
- prøve
- at
- The Source
- Them
- Disse
- tid
- tidsfølsom
- Titel
- til
- emne
- Transaktioner
- TUR
- typer
- under
- uønsket
- opdatering
- brug
- Bruger
- værdi
- Værdier
- udgave
- web
- webservices
- som
- vilje
- vinduer
- med
- arbejdstager
- arbejdere
- arbejder
- virker
- skriftlig
- Din
- zephyrnet