At finde lignende kolonner i en data sø har vigtige applikationer inden for datarensning og annotering, skemamatchning, dataopdagelse og analyser på tværs af flere datakilder. Manglende evne til nøjagtigt at finde og analysere data fra forskellige kilder repræsenterer en potentiel effektivitetsdræber for alle fra datavidenskabsmænd, medicinske forskere, akademikere til finans- og regeringsanalytikere.
Konventionelle løsninger involverer leksikalsk søgeordssøgning eller matchning af regulære udtryk, som er følsomme over for datakvalitetsproblemer såsom manglende kolonnenavne eller forskellige kolonnenavnekonventioner på tværs af forskellige datasæt (f.eks. zip_code, zcode, postalcode).
I dette indlæg demonstrerer vi en løsning til at søge efter lignende kolonner baseret på kolonnenavn, kolonneindhold eller begge dele. Løsningen bruger omtrentlige algoritmer for nærmeste naboer tilgængelig i Amazon OpenSearch Service at søge efter semantisk lignende kolonner. For at lette søgningen opretter vi egenskabsrepræsentationer (indlejringer) for individuelle kolonner i datasøen ved hjælp af fortrænede transformatormodeller fra sætnings-transformere bibliotek in Amazon SageMaker. Til sidst, for at interagere med og visualisere resultater fra vores løsning, bygger vi en interaktiv Strømbelyst webapplikation kører på AWS Fargate.
Vi inkluderer en kode tutorial for at du kan implementere ressourcerne til at køre løsningen på eksempeldata eller dine egne data.
Løsningsoversigt
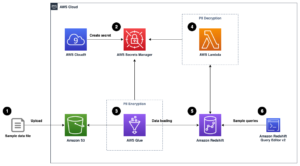
Følgende arkitekturdiagram illustrerer to-trins arbejdsgangen til at finde semantisk lignende kolonner. Første etape løber en AWS-trinfunktioner arbejdsgang, der opretter indlejringer fra tabelkolonner og opbygger OpenSearch Service-søgeindekset. Den anden fase, eller online-inferensfasen, kører en Streamlit-applikation gennem Fargate. Webapplikationen indsamler inputsøgeforespørgsler og henter fra OpenSearch Service-indekset de omtrentlige k-mest-lignende kolonner til forespørgslen.

Figur 1. Løsningsarkitektur
Den automatiserede arbejdsgang fortsætter i følgende trin:
- Brugeren uploader tabeldatasæt til en Amazon Simple Storage Service (Amazon S3) spand, som påberåber sig en AWS Lambda funktion, der starter Trinfunktioner-arbejdsgangen.
- Arbejdsgangen begynder med en AWS Lim job, der konverterer CSV-filerne til Apache parket dataformat.
- Et SageMaker Processing-job opretter indlejringer for hver kolonne ved hjælp af forudtrænede modeller eller brugerdefinerede kolonneindlejringsmodeller. SageMaker Processing-jobbet gemmer kolonneindlejringerne for hver tabel i Amazon S3.
- En Lambda-funktion opretter OpenSearch Service-domænet og -klyngen for at indeksere de kolonneindlejringer, der blev produceret i det foregående trin.
- Endelig er en interaktiv Streamlit webapplikation implementeret med Fargate. Webapplikationen giver brugeren en grænseflade til at indtaste forespørgsler for at søge i OpenSearch Service-domænet efter lignende kolonner.
Du kan downloade kodevejledningen fra GitHub at prøve denne løsning på eksempeldata eller dine egne data. Instruktioner om, hvordan du implementerer de nødvendige ressourcer til dette selvstudie, er tilgængelige på Github.
Forudsætninger
For at implementere denne løsning har du brug for følgende:
- An AWS-konto.
- Grundlæggende kendskab til AWS-tjenester som f.eks AWS Cloud Development Kit (AWS CDK), Lambda, OpenSearch Service og SageMaker Processing.
- Et tabeldatasæt til at oprette søgeindekset. Du kan medbringe dine egne tabeldata eller downloade prøvedatasættene på GitHub.
Opbyg et søgeindeks
Den første fase opbygger kolonnesøgemaskineindekset. Følgende figur illustrerer arbejdsgangen Trinfunktioner, der kører denne fase.

Figur 2 – Trinfunktions arbejdsgang – flere indlejringsmodeller
datasæt
I dette indlæg bygger vi et søgeindeks til at inkludere over 400 kolonner fra over 25 tabeldatasæt. Datasættene stammer fra følgende offentlige kilder:
For den fulde liste over de tabeller, der er inkluderet i indekset, se kodevejledningen om GitHub.
Du kan medbringe dit eget tabeldatasæt for at udvide prøvedataene eller bygge dit eget søgeindeks. Vi inkluderer to Lambda-funktioner, der starter Step Functions-arbejdsgangen for at opbygge søgeindekset for henholdsvis individuelle CSV-filer eller en batch af CSV-filer.
Omdan CSV til Parket
Rå CSV-filer konverteres til Parquet-dataformat med AWS Glue. Parket er et søjleorienteret filformat, der foretrækkes i big data-analyse, der giver effektiv komprimering og kodning. I vores eksperimenter tilbød Parquet-dataformatet betydelig reduktion i lagerstørrelse sammenlignet med rå CSV-filer. Vi brugte også Parquet som et almindeligt dataformat til at konvertere andre dataformater (for eksempel JSON og NDJSON), fordi det understøtter avancerede indlejrede datastrukturer.
Opret søjleindlejringer i tabelform
For at udtrække indlejringer for individuelle tabelkolonner i eksempeldatasætene i tabelform i dette indlæg, bruger vi følgende præ-trænede modeller fra sentence-transformers bibliotek. For yderligere modeller, se Foruddannede modeller.
SageMaker Processing-jobbet kører create_embeddings.py(kode) for en enkelt model. For at udtrække indlejringer fra flere modeller kører arbejdsgangen parallelle SageMaker Processing-job som vist i arbejdsgangen Trinfunktioner. Vi bruger modellen til at skabe to sæt indlejringer:
- kolonnenavn_indlejringer – Indlejringer af kolonnenavne (overskrifter)
- column_content_embeddings – Gennemsnitlig indlejring af alle rækkerne i kolonnen
For mere information om kolonneindlejringsprocessen, se kodevejledningen om GitHub.
Et alternativ til SageMaker Processing-trinnet er at oprette en SageMaker batchtransformation for at få kolonneindlejringer på store datasæt. Dette ville kræve implementering af modellen til et SageMaker-slutpunkt. For mere information, se Brug Batch Transform.
Indeksindlejringer med OpenSearch Service
I det sidste trin af dette trin tilføjer en Lambda-funktion kolonneindlejringerne til en OpenSearch Service omtrentlig k-Nærmeste-Nabo (kNN) søgeindeks. Hver model tildeles sit eget søgeindeks. For mere information om de omtrentlige kNN-søgeindeksparametre, se k-NN.
Online inferens og semantisk søgning med en webapp
Den anden fase af arbejdsgangen kører en Strømbelyst webapplikation, hvor du kan levere input og søge efter semantisk lignende kolonner indekseret i OpenSearch Service. Applikationslaget bruger en Application Load Balancer, Fargate og Lambda. Applikationsinfrastrukturen implementeres automatisk som en del af løsningen.
Applikationen giver dig mulighed for at give input og søge efter semantisk lignende kolonnenavne, kolonneindhold eller begge dele. Derudover kan du vælge indlejringsmodel og antallet af nærmeste naboer, der skal returneres fra søgningen. Applikationen modtager input, indlejrer input med den angivne model og bruger kNN-søgning i OpenSearch Service at søge i indekserede kolonneindlejringer og finde de kolonner, der ligner det givne input mest. De viste søgeresultater inkluderer tabelnavne, kolonnenavne og lighedsscore for de identificerede kolonner samt placeringen af dataene i Amazon S3 til yderligere udforskning.
Følgende figur viser et eksempel på webapplikationen. I dette eksempel søgte vi efter kolonner i vores datasø, der har lignende Column Names (nyttelast type) Til district (nyttelast). Den anvendte applikation all-MiniLM-L6-v2 som indlejringsmodel og vendte tilbage 10 (k) nærmeste naboer fra vores OpenSearch Service-indeks.
Ansøgningen vendte tilbage transit_district, city, boroughog location som de fire mest lignende kolonner baseret på data indekseret i OpenSearch Service. Dette eksempel demonstrerer søgemetodens evne til at identificere semantisk lignende kolonner på tværs af datasæt.

Figur 3: Webapplikations brugergrænseflade
Ryd op
For at slette de ressourcer, der er oprettet af AWS CDK i denne øvelse, skal du køre følgende kommando:
cdk destroy --allKonklusion
I dette indlæg præsenterede vi en ende-til-ende arbejdsgang til at bygge en semantisk søgemaskine til tabelkolonner.
Kom i gang i dag med dine egne data med vores kodevejledning tilgængelig på GitHub. Hvis du vil have hjælp til at fremskynde din brug af ML i dine produkter og processer, bedes du kontakte Amazon Machine Learning Solutions Lab.
Om forfatterne
![]() Kachi Odoemene er en anvendt videnskabsmand ved AWS AI. Han bygger AI/ML-løsninger til at løse forretningsproblemer for AWS-kunder.
Kachi Odoemene er en anvendt videnskabsmand ved AWS AI. Han bygger AI/ML-løsninger til at løse forretningsproblemer for AWS-kunder.
![]() Taylor McNally er Deep Learning Architect hos Amazon Machine Learning Solutions Lab. Han hjælper kunder fra forskellige industrier med at bygge løsninger, der udnytter AI/ML på AWS. Han nyder en god kop kaffe, udelivet og tid med sin familie og energiske hund.
Taylor McNally er Deep Learning Architect hos Amazon Machine Learning Solutions Lab. Han hjælper kunder fra forskellige industrier med at bygge løsninger, der udnytter AI/ML på AWS. Han nyder en god kop kaffe, udelivet og tid med sin familie og energiske hund.
![]() Austin Welch er dataforsker i Amazon ML Solutions Lab. Han udvikler tilpassede deep learning-modeller for at hjælpe AWS-kunder i den offentlige sektor med at accelerere deres AI og cloud-adoption. I sin fritid nyder han at læse, rejse og jiu-jitsu.
Austin Welch er dataforsker i Amazon ML Solutions Lab. Han udvikler tilpassede deep learning-modeller for at hjælpe AWS-kunder i den offentlige sektor med at accelerere deres AI og cloud-adoption. I sin fritid nyder han at læse, rejse og jiu-jitsu.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- Platoblokkæde. Web3 Metaverse Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- evne
- Om
- fraværende
- fremskynde
- accelererende
- præcist
- tværs
- Yderligere
- Derudover
- Tilføjer
- Vedtagelse
- fremskreden
- AI
- AI / ML
- Alle
- tillader
- alternativ
- Amazon
- Amazon maskinindlæring
- Amazon ML Solutions Lab
- Analytikere
- analytics
- analysere
- ,
- Apache
- Anvendelse
- applikationer
- anvendt
- tilgang
- arkitektur
- tildelt
- Automatiseret
- automatisk
- til rådighed
- gennemsnit
- AWS
- AWS Lim
- baseret
- fordi
- Big
- Big data
- bringe
- bygge
- Bygning
- bygger
- virksomhed
- Rengøring
- Cloud
- cloud adoption
- Cluster
- kode
- Kaffe
- indsamler
- Kolonne
- Kolonner
- Fælles
- sammenlignet
- kontakt
- indhold
- Konventioner
- konvertere
- konverteret
- skabe
- oprettet
- skaber
- Kop
- skik
- Kunder
- data
- Dataanalyse
- Data Lake
- datakvalitet
- dataforsker
- datasæt
- dyb
- dyb læring
- demonstrere
- demonstrerer
- indsætte
- indsat
- implementering
- ødelægge
- Udvikling
- udvikler
- forskellige
- opdagelse
- dårskab
- forskelligartede
- Dog
- domæne
- downloade
- hver
- effektivitet
- effektiv
- ende til ende
- Endpoint
- Engine (Motor)
- Ether (ETH)
- alle
- eksempel
- udforskning
- ekstrakt
- lette
- Kendskab
- familie
- Funktionalitet
- Figur
- File (Felt)
- Filer
- endelige
- Endelig
- finansielle
- Finde
- finde
- Fornavn
- efter
- format
- fra
- fuld
- funktion
- funktioner
- yderligere
- få
- given
- godt
- Regering
- headers
- hjælpe
- hjælper
- Hvordan
- How To
- HTML
- HTTPS
- identificeret
- identificere
- gennemføre
- vigtigt
- in
- manglende evne
- omfatter
- medtaget
- indeks
- individuel
- industrier
- oplysninger
- Infrastruktur
- indlede
- Indleder
- indgang
- anvisninger
- interagere
- interaktiv
- grænseflade
- påberåber sig
- involvere
- spørgsmål
- IT
- Job
- Karriere
- json
- lab
- sø
- stor
- lag
- læring
- løftestang
- Bibliotek
- Liste
- belastning
- placeringer
- maskine
- machine learning
- matchende
- medicinsk
- ML
- model
- modeller
- mere
- mest
- flere
- navn
- navne
- navngivning
- Behov
- naboer
- nummer
- tilbydes
- online
- Andet
- udendørs
- egen
- Parallel
- parametre
- del
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- Indlæg
- potentiale
- foretrækkes
- forelagt
- tidligere
- problemer
- udbytte
- behandle
- Processer
- forarbejdning
- produceret
- Produkter
- give
- giver
- offentlige
- kvalitet
- Raw
- Læsning
- modtager
- fast
- repræsenterer
- kræver
- påkrævet
- forskere
- Ressourcer
- henholdsvis
- Resultater
- afkast
- Kør
- kører
- sagemaker
- Videnskabsmand
- forskere
- Søg
- søgemaskine
- søgning
- Anden
- sektor
- tjeneste
- Tjenester
- sæt
- vist
- Shows
- signifikant
- lignende
- Simpelt
- enkelt
- Størrelse
- løsninger
- Løsninger
- SOLVE
- Kilder
- specificeret
- Stage
- påbegyndt
- Trin
- Steps
- opbevaring
- sådan
- Understøtter
- modtagelig
- bord
- deres
- Gennem
- tid
- til
- i dag
- Transform
- transformers
- Traveling
- tutorial
- brug
- Bruger
- Brugergrænseflade
- forskellige
- web
- Webapplikation
- som
- workflow
- ville
- Din
- zephyrnet