Vi lever i en tidsalder med data og indsigt i realtid, drevet af applikationer til datastreaming med lav latens. I dag forventer alle en personlig oplevelse i enhver applikation, og organisationer innoverer konstant for at øge deres hastighed i forretningsdrift og beslutningstagning. Mængden af producerede tidsfølsomme data stiger hurtigt, med forskellige dataformater, der introduceres på tværs af nye virksomheder og kundeanvendelsessager. Derfor er det afgørende for organisationer at omfavne en lav-latency, skalerbar og pålidelig datastreaming-infrastruktur for at levere forretningsapplikationer i realtid og bedre kundeoplevelser.
Dette er det første indlæg til en blogserie, der tilbyder almindelige arkitektoniske mønstre i opbygningen af realtidsdatastreaminginfrastrukturer ved hjælp af Kinesis Data Streams til en bred vifte af brugssager. Det sigter mod at give en ramme til at skabe streamingapplikationer med lav latens på AWS Cloud ved hjælp af Amazon Kinesis datastrømme , AWS specialbyggede dataanalysetjenester.
I dette indlæg vil vi gennemgå de fælles arkitektoniske mønstre for to use cases: Time Series Data Analysis og Event Driven Microservices. I det efterfølgende indlæg i vores serie vil vi udforske de arkitektoniske mønstre i opbygningen af streamingpipelines til BI-dashboards i realtid, kontaktcenteragent, finansdata, personlig anbefaling i realtid, loganalyse, IoT-data, Change Data Capture og ægte -tidsmarkedsføringsdata. Alle disse arkitekturmønstre er integreret med Amazon Kinesis Data Streams.
Realtidsstreaming med Kinesis Data Streams
Amazon Kinesis Data Streams er en cloud-native, serverløs streamingdatatjeneste, der gør det nemt at fange, behandle og gemme realtidsdata i enhver skala. Med Kinesis Data Streams kan du indsamle og behandle hundredvis af gigabyte data i sekundet fra hundredtusindvis af kilder, så du nemt kan skrive applikationer, der behandler information i realtid. De indsamlede data er tilgængelige på millisekunder for at tillade brugssager med analyser i realtid, såsom dashboards i realtid, afsløring af anomalier i realtid og dynamisk prissætning. Som standard gemmes dataene i Kinesis Data Stream i 24 timer med mulighed for at øge dataopbevaringen til 365 dage. Hvis kunder ønsker at behandle de samme data i realtid med flere applikationer, kan de bruge funktionen Enhanced Fan-Out (EFO). Før denne funktion delte hver applikation, der forbruger data fra streamen, output på 2 MB/sekund/shard. Ved at konfigurere stream-forbrugere til at bruge forbedret fan-out, modtager hver dataforbruger dedikeret 2MB/sekund pipe of read throughput pr. shard for yderligere at reducere latensen i datahentning.
For høj tilgængelighed og holdbarhed opnår Kinesis Data Streams høj holdbarhed ved synkront at replikere de streamede data på tværs af tre tilgængelighedszoner i en AWS-region og giver dig mulighed for at opbevare data i op til 365 dage. Af sikkerhedsmæssige årsager leverer Kinesis Data Streams serversidekryptering, så du kan opfylde strenge dataadministrationskrav ved at kryptere dine data i hvile og Amazon Virtual Private Cloud (VPC) grænsefladeslutpunkter for at holde trafikken mellem din Amazon VPC og Kinesis Data Streams privat.
Kinesis Data Streams har native integrationer med andre AWS-tjenester som f.eks AWS Lim , Amazon Eventbridge at bygge streaming-applikationer i realtid på AWS. Se Amazon Kinesis Data Streams integrationer for yderligere detaljer.
Moderne datastreaming-arkitektur med Kinesis Data Streams
En moderne streamingdataarkitektur med Kinesis Data Streams kan designes som en stak af fem logiske lag; hvert lag er sammensat af flere specialbyggede komponenter, der opfylder specifikke krav, som illustreret i følgende diagram:
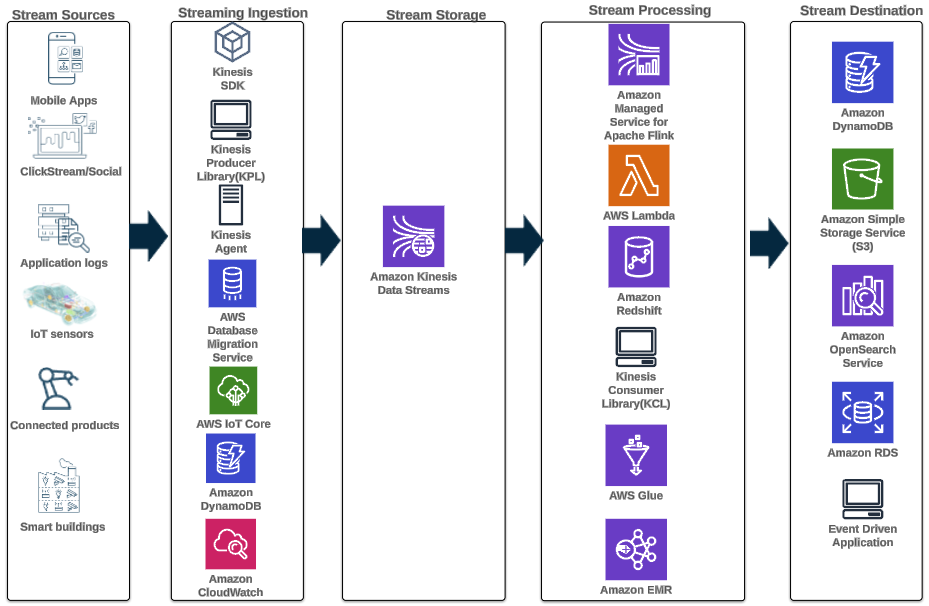
Arkitekturen består af følgende nøglekomponenter:
- Streaming kilder – Din kilde til streamingdata inkluderer datakilder som klikstrømsdata, sensorer, sociale medier, Internet of Things (IoT) enheder, logfiler genereret ved at bruge dine web- og mobilapplikationer og mobile enheder, der genererer semistrukturerede og ustrukturerede data som kontinuerlige streams ved høj hastighed.
- Stream indtagelse – Strømindtagelseslaget er ansvarligt for at indlæse data i strømlagringslaget. Det giver mulighed for at indsamle data fra titusindvis af datakilder og indtage i realtid. Du kan bruge Kinesis SDK til indlæsning af streamingdata gennem API'er, Kinesis Producer Library til opbygning af højtydende og langvarige streamingproducenter, eller en Kinesis agent til at indsamle et sæt filer og indsætte dem i Kinesis Data Streams. Derudover kan du bruge mange pre-build integrationer som f.eks AWS Database Migration Service (AWS DMS), Amazon DynamoDBog AWS IoT Core at indtage data uden kode. Du kan også indtage data fra tredjepartsplatforme såsom Apache Spark og Apache Kafka Connect
- Stream lager – Kinesis Data Streams tilbyder to tilstande til at understøtte datagennemstrømningen: On-Demand og Provisioned. On-Demand-tilstand, nu standardvalget, kan skaleres elastisk for at absorbere variable gennemløb, så kunderne ikke behøver at bekymre sig om kapacitetsstyring og betale efter datagennemstrømning. On-Demand-tilstanden skalerer automatisk 2x streamkapaciteten op i forhold til dens historiske maksimale dataindtagelse for at give tilstrækkelig kapacitet til uventede stigninger i dataindtagelse. Alternativt kan kunder, der ønsker detaljeret kontrol over strømressourcer, bruge den forudsatte tilstand og proaktivt skalere op og ned antallet af Shards for at opfylde deres gennemløbskrav. Derudover kan Kinesis Data Streams gemme streamingdata op til 24 timer som standard, men kan forlænges til 7 dage eller 365 dage afhængigt af brugssituationer. Flere applikationer kan forbruge den samme strøm.
- Stream behandling – Strømbehandlingslaget er ansvarlig for at transformere data til en forbrugstilstand gennem datavalidering, oprydning, normalisering, transformation og berigelse. Streamingposterne læses i den rækkefølge, de produceres, hvilket giver mulighed for realtidsanalyse, opbygning af hændelsesdrevne applikationer eller streaming af ETL (ekstrahere, transformere og indlæse). Du kan bruge Amazon Managed Service til Apache Flink til kompleks strømdatabehandling, AWS Lambda til statsløs strømdatabehandling, og AWS Lim & Amazon EMR til næsten-realtidsberegning. Du kan også bygge tilpassede forbrugerapplikationer med Kinesis Consumer Library, som vil tage sig af mange komplekse opgaver forbundet med distribueret computing.
- Destination – Destinationslaget er som en specialbygget destination afhængigt af din brugssituation. Du kan streame data direkte til Amazon rødforskydning til data warehousing og Amazon EventBridge til opbygning af begivenhedsdrevne applikationer. Du kan også bruge Amazon Kinesis Data Firehose til streaming-integration, hvor du kan lette stream-behandling med AWS Lambda og derefter levere behandlet streaming til destinationer som f.eks. Amazon S3 data lake, OpenSearch Service til operationel analyse, et Redshift data warehouse, No-SQL databaser som Amazon DynamoDB og relationelle databaser som f.eks. Amazon RDS at forbruge realtidsstrømme til forretningsapplikationer. Destinationen kan være en begivenhedsdrevet applikation til dashboards i realtid, automatiske beslutninger baseret på behandlede streamingdata, ændring i realtid og mere.
Realtidsanalysearkitektur til tidsserier
Tidsseriedata er en sekvens af datapunkter registreret over et tidsinterval til måling af hændelser, der ændrer sig over tid. Eksempler er aktiekurser over tid, webside-klikstrømme og enhedslogfiler over tid. Kunder kan bruge tidsseriedata til at overvåge ændringer over tid, så de kan opdage anomalier, identificere mønstre og analysere, hvordan visse variabler påvirkes over tid. Tidsseriedata genereres typisk fra flere kilder i store mængder, og de skal indsamles omkostningseffektivt i næsten realtid.
Typisk er der tre primære mål, som kunderne ønsker at opnå ved behandling af tidsseriedata:
- Få indsigt i realtid i systemets ydeevne og opdage uregelmæssigheder
- Forstå slutbrugeres adfærd for at spore trends og forespørge/bygge visualiseringer ud fra denne indsigt
- Har en holdbar lagringsløsning til at indtage og gemme både arkiverede og ofte tilgåede data.
Med Kinesis Data Streams kan kunder kontinuerligt fange terabyte af tidsseriedata fra tusindvis af kilder til rengøring, berigelse, opbevaring, analyse og visualisering.
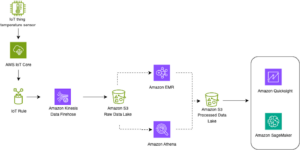
Følgende arkitekturmønster illustrerer, hvordan realtidsanalyse kan opnås for tidsseriedata med Kinesis Data Streams:
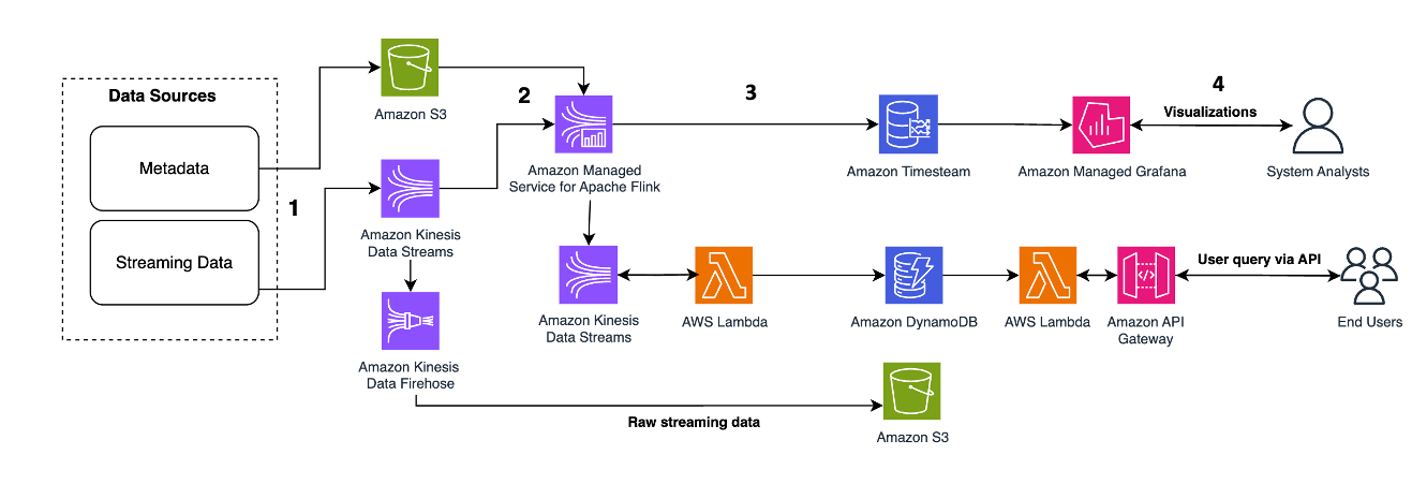
Workflow-trinene er som følger:
- Dataindtagelse og lagring – Kinesis Data Streams kan kontinuerligt fange og gemme terabyte af data fra tusindvis af kilder.
- Stream behandling – En applikation oprettet med Amazon Managed Service til Apache Flink kan læse registreringerne fra datastrømmen for at opdage og rense eventuelle fejl i tidsseriedataene og berige dataene med specifikke metadata for at optimere operationelle analyser. Brug af en datastrøm i midten giver fordelen ved at bruge tidsseriedataene i andre processer og løsninger på samme tid. En Lambda-funktion aktiveres derefter med disse hændelser og kan udføre tidsserieberegninger i hukommelsen.
- Destinationer – Efter rensning og berigelse kan de behandlede tidsseriedata streames til Amazon Timestream database til dashboarding og analyse i realtid eller gemt i databaser såsom DynamoDB til slutbrugerforespørgsler. Rådataene kan streames til Amazon S3 til arkivering.
- Visualisering og få indsigt – Kunder kan forespørge, visualisere og oprette advarsler vha Amazon Managed Service til Grafana. Grafana understøtter datakilder, der er lagerbackends for tidsseriedata. For at få adgang til dine data fra Timestream skal du installere Timestream-pluginnet til Grafana. Slutbrugere kan forespørge data fra DynamoDB-tabellen med Amazon API Gateway fungerer som fuldmægtig.
Der henvises til Nær realtidsbehandling med Amazon Kinesis, Amazon Timestream og Grafana fremvisning af en serverløs streamingpipeline til at behandle og lagre enhedstelemetri IoT-data i en tidsserieoptimeret datalager såsom Amazon Timestream.
Berig og genafspilning af data i realtid til event-sourcing-mikrotjenester
Mikrotjenester er en arkitektonisk og organisatorisk tilgang til softwareudvikling, hvor software er sammensat af små uafhængige tjenester, der kommunikerer over veldefinerede API'er. Ved opbygning af hændelsesdrevne mikrotjenester ønsker kunder at opnå 1. høj skalerbarhed til at håndtere mængden af indkommende hændelser og 2. pålidelighed af hændelsesbehandling og vedligeholde systemfunktionalitet i lyset af fejl.
Kunder bruger mikroservicearkitekturmønstre til at accelerere innovation og time-to-market for nye funktioner, fordi det gør applikationer nemmere at skalere og hurtigere at udvikle. Det er dog udfordrende at berige og afspille dataene i et netværksopkald til en anden mikrotjeneste, fordi det kan påvirke applikationens pålidelighed og gøre det vanskeligt at fejlfinde og spore fejl. For at løse dette problem er event-sourcing et effektivt designmønster, der centraliserer historiske optegnelser over alle tilstandsændringer til berigelse og genafspilning og afkobler læse- og skrivebelastninger. Kunder kan bruge Kinesis Data Streams som den centraliserede begivenhedsbutik til hændelsessourcing-mikrotjenester, fordi KDS kan 1/ håndtere gigabyte datagennemstrømning pr. sekund pr. stream og streame dataene på millisekunder for at opfylde kravet om høj skalerbarhed og næsten realtid latency, 2/ integrere med Flink og S3 for databerigelse og opnåelse, mens den er fuldstændig afkoblet fra mikrotjenesterne, og 3/ tillad genforsøg og asynkron læsning på et senere tidspunkt, fordi KDS beholder dataposten i en standard på 24 timer, og eventuelt op til 365 dage.
Følgende arkitektoniske mønster er en generisk illustration af, hvordan Kinesis Data Streams kan bruges til Event-Sourcing Microservices:
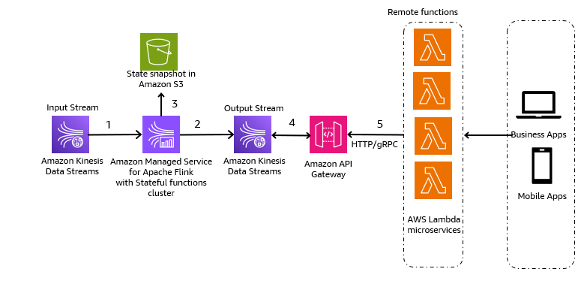
Trinene i arbejdsgangen er som følger:
- Dataindtagelse og lagring – Du kan samle input fra dine mikrotjenester til dine Kinesis Data Streams til opbevaring.
- Stream behandling - Apache Flink Stateful Functions forenkler opbygning af distribuerede stateful begivenhedsdrevne applikationer. Den kan modtage begivenhederne fra en input Kinesis datastrøm og dirigere den resulterende strøm til en outputdatastrøm. Du kan oprette en stateful funktionsklynge med Apache Flink baseret på din applikations forretningslogik.
- State snapshot i Amazon S3 – Du kan gemme tilstandsbilledet i Amazon S3 til sporing.
- Outputstrømme – Outputstrømmene kan forbruges gennem Lambda-fjernfunktioner via HTTP/gRPC-protokol gennem API Gateway.
- Lambda fjernbetjening funktioner – Lambda-funktioner kan fungere som mikrotjenester for forskellige applikations- og forretningslogikker til at betjene forretningsapplikationer og mobilapps.
For at lære, hvordan andre kunder byggede deres begivenhedsbaserede mikrotjenester med Kinesis Data Streams, skal du se følgende:
Nøgleovervejelser og bedste praksis
Følgende er overvejelser og bedste praksis at huske på:
- Dataopdagelse bør være dit første skridt i at bygge moderne datastreaming-applikationer. Du skal definere forretningsværdien og derefter identificere dine streamingdatakilder og brugerpersoner for at opnå de ønskede forretningsresultater.
- Vælg dit værktøj til streamingdataindtagelse baseret på din dampende datakilde. For eksempel kan du bruge Kinesis SDK til indlæsning af streamingdata gennem API'er, Kinesis Producer Library til opbygning af højtydende og langvarige streamingproducenter, en Kinesis agent for at indsamle et sæt filer og indlæse dem i Kinesis Data Streams, AWS DMS til CDC-streamingbrug, og AWS IoT Core til indlæsning af IoT-enhedsdata i Kinesis Data Streams. Du kan indtage streamingdata direkte i Amazon Redshift for at bygge streamingapplikationer med lav latens. Du kan også bruge tredjepartsbiblioteker som Apache Spark og Apache Kafka til at indsætte streamingdata i Kinesis Data Streams.
- Du skal vælge dine streamingdatabehandlingstjenester baseret på din specifikke brugssituation og forretningskrav. For eksempel kan du bruge Amazon Kinesis Managed Service til Apache Flink til avancerede streamingbrugssager med flere streamingdestinationer og kompleks stateful streambehandling, eller hvis du vil overvåge forretningsmålinger i realtid (såsom hver time). Lambda er god til begivenhedsbaseret og statsløs behandling. Du kan bruge Amazon EMR til streaming af databehandling for at bruge dine foretrukne open source big data-rammer. AWS Glue er god til nær-real-tids streaming databehandling til brugssituationer såsom streaming ETL.
- Kinesis Data Streams on-demand-tilstand opkræver efter brug og skalerer automatisk ressourcekapaciteten op, så det er godt til spidse streaming-arbejdsbelastninger og håndfri vedligeholdelse. Provisioneret tilstand opkræves efter kapacitet og kræver proaktiv kapacitetsstyring, så den er god til forudsigelige streaming-arbejdsbelastninger.
- Du kan bruge Kinesis delt lommeregner for at beregne antallet af shards, der skal bruges til klargjort tilstand. Du behøver ikke være bekymret for shards med on-demand-tilstand.
- Når du giver tilladelser, bestemmer du, hvem der får hvilke tilladelser til hvilke Kinesis Data Streams-ressourcer. Du aktiverer specifikke handlinger, som du vil tillade på disse ressourcer. Derfor bør du kun give de tilladelser, der er nødvendige for at udføre en opgave. Du kan også kryptere data i hvile ved at bruge en KMS-kundeadministreret nøgle (CMK).
- Du kan opdatere opbevaringsperioden via Kinesis Data Streams-konsollen eller ved at bruge ForøgStreamRetentionPeriod og ReducerStreamRetentionPeriod operationer baseret på dine specifikke use cases.
- Kinesis Data Streams understøtter omskæring. Den anbefalede API til denne funktion er OpdaterShardCount, som giver dig mulighed for at ændre antallet af shards i din stream for at tilpasse sig ændringer i dataflowhastigheden gennem streamen. Resharding API'erne (Split og Merge) bruges typisk til at håndtere hot shards.
Konklusion
Dette indlæg demonstrerede forskellige arkitektoniske mønstre til at bygge streamingapplikationer med lav latens med Kinesis Data Streams. Du kan bygge dine egne lav-latency dampende applikationer med Kinesis Data Streams ved hjælp af oplysningerne i dette indlæg.
For detaljerede arkitektoniske mønstre henvises til følgende ressourcer:
Hvis du ønsker at opbygge en datavision og strategi, så tjek den AWS datadrevet alt (D2E) program.
Om forfatterne
 Raghavarao Sodabatathina er Principal Solutions Architect hos AWS, med fokus på Data Analytics, AI/ML og cloud-sikkerhed. Han engagerer sig med kunder for at skabe innovative løsninger, der løser kundernes forretningsproblemer og for at fremskynde adoptionen af AWS-tjenester. I sin fritid nyder Raghavarao at bruge tid med sin familie, læse bøger og se film.
Raghavarao Sodabatathina er Principal Solutions Architect hos AWS, med fokus på Data Analytics, AI/ML og cloud-sikkerhed. Han engagerer sig med kunder for at skabe innovative løsninger, der løser kundernes forretningsproblemer og for at fremskynde adoptionen af AWS-tjenester. I sin fritid nyder Raghavarao at bruge tid med sin familie, læse bøger og se film.
 Hæng Zuo er Senior Product Manager på Amazon Kinesis Data Streams-teamet hos Amazon Web Services. Han brænder for at udvikle intuitive produktoplevelser, der løser komplekse kundeproblemer og sætter kunder i stand til at nå deres forretningsmål.
Hæng Zuo er Senior Product Manager på Amazon Kinesis Data Streams-teamet hos Amazon Web Services. Han brænder for at udvikle intuitive produktoplevelser, der løser komplekse kundeproblemer og sætter kunder i stand til at nå deres forretningsmål.
 Shwetha Radhakrishnan er Solutions Architect for AWS med fokus på Data Analytics. Hun har bygget løsninger, der driver cloud-adoption og hjælper organisationer med at træffe datadrevne beslutninger inden for den offentlige sektor. Uden for arbejdet elsker hun at danse, tilbringe tid med venner og familie og at rejse.
Shwetha Radhakrishnan er Solutions Architect for AWS med fokus på Data Analytics. Hun har bygget løsninger, der driver cloud-adoption og hjælper organisationer med at træffe datadrevne beslutninger inden for den offentlige sektor. Uden for arbejdet elsker hun at danse, tilbringe tid med venner og familie og at rejse.
 Brittany Ly er Solutions Architect hos AWS. Hun er fokuseret på at hjælpe virksomhedskunder med deres cloud-adoption og moderniseringsrejse og har en interesse i sikkerheds- og analyseområdet. Uden for arbejdet elsker hun at tilbringe tid med sin hund og spille pickleball.
Brittany Ly er Solutions Architect hos AWS. Hun er fokuseret på at hjælpe virksomhedskunder med deres cloud-adoption og moderniseringsrejse og har en interesse i sikkerheds- og analyseområdet. Uden for arbejdet elsker hun at tilbringe tid med sin hund og spille pickleball.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk dig selv. Adgang her.
- PlatoAiStream. Web3 intelligens. Viden forstærket. Adgang her.
- PlatoESG. Kulstof, CleanTech, Energi, Miljø, Solenergi, Affaldshåndtering. Adgang her.
- PlatoHealth. Bioteknologiske og kliniske forsøgs intelligens. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/architectural-patterns-for-real-time-analytics-using-amazon-kinesis-data-streams-part-1/
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 100
- 24
- 7
- a
- evne
- Om
- fremskynde
- adgang
- af udleverede
- opnå
- opnået
- opnår
- opnå
- tværs
- Lov
- handler
- aktioner
- tilpasse
- Desuden
- Yderligere
- Derudover
- adresse
- Vedtagelse
- fremskreden
- Fordel
- Efter
- alder
- Agent
- aggregat
- AI / ML
- målsætninger
- indberetninger
- Alle
- tillade
- tillade
- tillader
- også
- Amazon
- Amazon Kinesis
- Amazon Timestream
- Amazon Web Services
- an
- analyse
- analytics
- analysere
- ,
- afsløring af anomalier
- En anden
- enhver
- Apache
- Apache Kafka
- Apache Spark
- api
- API'er
- Anvendelse
- applikationer
- tilgang
- apps
- arkitektonisk
- arkitektur
- ER
- AS
- forbundet
- At
- Automatisk Ur
- automatisk
- tilgængelighed
- til rådighed
- AWS
- AWS Lim
- AWS Lambda
- baseret
- BE
- fordi
- været
- adfærd
- være
- BEDSTE
- bedste praksis
- Bedre
- mellem
- Big
- Big data
- Blog
- Bøger
- både
- bygge
- Bygning
- bygget
- virksomhed
- Business Applications
- virksomheder
- men
- by
- beregne
- ringe
- CAN
- Kapacitet
- fange
- hvilken
- tilfælde
- tilfælde
- CDC
- center
- centraliseret
- vis
- udfordrende
- lave om
- Ændringer
- afgifter
- kontrollere
- valg
- Vælg
- ren
- Rengøring
- Cloud
- cloud adoption
- Cloud Security
- Cluster
- indsamler
- Indsamling
- Fælles
- kommunikere
- fuldstændig
- komplekse
- komponenter
- sammensat
- Compute
- computing
- pågældende
- konfigurering
- overvejelser
- består
- Konsol
- konstant
- forbruge
- forbruges
- forbruger
- Forbrugere
- kontakt
- kontaktcenter
- kontinuerlig
- kontinuerligt
- kontrol
- skabe
- oprettet
- kritisk
- kunde
- Kunder
- tilpassede
- Dancing
- dashboards
- data
- dataanalyse
- Dataanalyse
- data berigelse
- Data Lake
- datastyring
- datapunkter
- databehandling
- datalager
- datastyret
- Database
- databaser
- Dage
- beslutte
- beslutning
- Beslutningstagning
- afgørelser
- afkoblet
- dedikeret
- Standard
- definere
- levere
- demonstreret
- Afhængigt
- Design
- konstrueret
- ønskes
- destination
- destinationer
- detaljeret
- detaljer
- opdage
- Detektion
- udvikle
- udvikling
- Udvikling
- enhed
- Enheder
- forskellige
- svært
- direkte
- opdagelse
- distribueret
- distribueret computing
- do
- Dog
- Dont
- ned
- køre
- drevet
- holdbarhed
- dynamisk
- hver
- lettere
- nemt
- let
- Effektiv
- omfavne
- muliggøre
- kryptering
- endpoints
- indgreb
- forbedret
- berige
- Enterprise
- virksomhedskunder
- fejl
- Ether (ETH)
- begivenhed
- begivenheder
- Hver
- alle
- eksempel
- eksempler
- forventer
- erfaring
- Oplevelser
- udforske
- udvide
- ekstrakt
- Ansigtet
- fejl
- familie
- Mode
- hurtigere
- Favorit
- Feature
- Funktionalitet
- felt
- Filer
- Fornavn
- fem
- flow
- Fokus
- fokuserede
- fokusering
- efter
- følger
- Til
- Framework
- rammer
- hyppigt
- venner
- fra
- funktion
- funktionalitet
- funktioner
- yderligere
- Gevinst
- gateway
- generere
- genereret
- få
- GitHub
- giver
- Mål
- godt
- indrømme
- tildeling
- håndtere
- Hænge
- he
- hjælpe
- hjælpe
- hende
- Høj
- Høj ydeevne
- hans
- historisk
- HOT
- time
- HOURS
- Hvordan
- Men
- HTML
- http
- HTTPS
- Hundreder
- identificere
- if
- illustrerer
- KIMOs Succeshistorier
- in
- I andre
- omfatter
- Indgående
- Forøg
- stigende
- uafhængig
- påvirket
- oplysninger
- Infrastruktur
- infrastruktur
- fornyelse
- Innovation
- innovativ
- indgang
- indsigt
- installere
- integrere
- integreret
- integration
- integrationer
- interesse
- grænseflade
- Internet
- tingenes internet
- ind
- introduceret
- intuitiv
- påberåbes
- tingenes internet
- IoT-enhed
- IT
- ITS
- rejse
- jpg
- Kafka
- Holde
- Nøgle
- Kinesis datastrømme
- sø
- Latency
- senere
- lag
- lag
- LÆR
- Ledger
- biblioteker
- Bibliotek
- lys
- ligesom
- levende
- belastning
- log
- logik
- logisk
- elsker
- vedligeholde
- vedligeholdelse
- lave
- maerker
- Making
- lykkedes
- ledelse
- leder
- mange
- Marketing
- maksimal
- måling
- Medier
- Mød
- Hukommelse
- Flet
- Metadata
- Metrics
- microservices
- Mellemøsten
- migration
- millisekunder
- tankerne
- Mobil
- Mobile applikationer
- mobilenheder
- mobil-apps
- tilstand
- Moderne
- modernisering
- modes
- ændre
- Overvåg
- mere
- Film
- flere
- skal
- indfødte
- I nærheden af
- Behov
- behov
- behov
- netværk
- Ny
- Nye funktioner
- nu
- nummer
- of
- tilbyde
- Tilbud
- on
- On-Demand
- kun
- åbent
- open source
- drift
- operationelle
- Produktion
- Optimer
- optimeret
- Option
- or
- ordrer
- organisatorisk
- organisationer
- Andet
- vores
- ud
- udfald
- output
- uden for
- i løbet af
- egen
- del
- lidenskabelige
- Mønster
- mønstre
- Betal
- per
- udføre
- ydeevne
- Tilladelser
- Personlig
- rør
- pipeline
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Leg
- plugin
- punkter
- Indlæg
- praksis
- Forudsigelig
- Priser
- prissætning
- primære
- Main
- Forud
- private
- Proaktiv
- Problem
- problemer
- behandle
- bearbejdet
- Processer
- forarbejdning
- produceret
- producent
- Producenter
- Produkt
- produktchef
- Program
- protokol
- give
- giver
- proxy
- offentlige
- rækkevidde
- hurtigt
- Sats
- Raw
- rådata
- Læs
- Læsning
- ægte
- realtid
- data i realtid
- modtage
- modtager
- Anbefaling
- anbefales
- optage
- registreres
- optegnelser
- reducere
- henvise
- region
- pålidelighed
- pålidelig
- fjern
- påkrævet
- krav
- Krav
- Kræver
- ressource
- Ressourcer
- ansvarlige
- REST
- resulterer
- tilbageholde
- bevarer
- tilbageholdelse
- gennemgå
- R
- samme
- Skalerbarhed
- skalerbar
- Scale
- skalaer
- Anden
- sektor
- sikkerhed
- senior
- sensorer
- Sequence
- Series
- tjener
- Serverless
- tjeneste
- Tjenester
- sæt
- delt
- hun
- bør
- fremvisning
- forenkler
- lille
- Snapshot
- So
- Social
- sociale medier
- Software
- softwareudvikling
- løsninger
- Løsninger
- SOLVE
- Kilde
- Kilder
- Spark
- specifikke
- hastighed
- tilbringe
- udgifterne
- spikes
- delt
- stable
- Tilstand
- Trin
- Steps
- bestand
- opbevaring
- butik
- opbevaret
- Strategi
- strøm
- streamet
- streaming
- vandløb
- streng
- efterfølgende
- sådan
- tilstrækkeligt
- support
- Understøtter
- systemet
- bord
- Tag
- Opgaver
- opgaver
- hold
- tiere
- at
- oplysninger
- Staten
- deres
- Them
- derefter
- Der.
- derfor
- Disse
- de
- ting
- tredjepart
- denne
- dem
- tusinder
- tre
- Gennem
- kapacitet
- tid
- Tidsserier
- tidsfølsom
- til
- i dag
- værktøj
- spore
- spor
- Sporing
- Trafik
- Transform
- Transformation
- omdanne
- Traveling
- Tendenser
- to
- typisk
- Uventet
- på
- Brug
- brug
- brug tilfælde
- anvendte
- Bruger
- ved brug af
- udnytte
- validering
- værdi
- variabel
- forskellige
- VeloCity
- via
- Virtual
- vision
- visualisering
- Visualiser
- bind
- mængder
- ønsker
- Warehouse
- Warehousing
- ser
- we
- web
- webservices
- veldefinerede
- Hvad
- hvornår
- som
- mens
- WHO
- bred
- Bred rækkevidde
- vilje
- med
- inden for
- Arbejde
- workflow
- bekymre sig
- skriver
- dig
- Din
- zephyrnet
- zoner