Amazonas Athena er en interaktiv forespørgselstjeneste, der gør det nemt at analysere data i Amazon Simple Storage Service (Amazon S3) og datakilder, der findes i AWS, lokale eller andre cloud-systemer, der bruger SQL eller Python. Athena er bygget på open source Trino- og Presto-motorer og Apache Spark-frameworks uden behov for klargøring eller konfiguration. Athena er serverløs, så der er ingen infrastruktur at administrere, og du betaler kun for de forespørgsler, du kører.
Apache isbjerg er et åbent tabelformat til meget store analytiske datasæt. Det administrerer store samlinger af filer som tabeller, og det understøtter moderne analytiske datasø-operationer såsom indsættelse, opdatering, sletning og tidsrejseforespørgsler på rekordniveau. Athena understøtter læse-, tidsrejse-, skrive- og DDL-forespørgsler til Apache Iceberg-tabeller, der bruger Apache Parquet-formatet til data og AWS Glue Data Katalog for deres metastore.
Funktionsteknik er en proces med at identificere og transformere rådata (billeder, tekstfiler, videoer og så videre), udfylde manglende data og tilføje et eller flere meningsfulde dataelementer for at give kontekst, så en maskinlæringsmodel (ML) kan lære af det. Datamærkning er påkrævet til forskellige brugssager, herunder prognoser, computersyn, naturlig sprogbehandling og talegenkendelse.
Kombineret med Athenas muligheder leverer Apache Iceberg en forenklet arbejdsgang for dataforskere til at skabe nye datafunktioner uden at skulle kopiere eller genskabe hele datasættet. Du kan oprette funktioner ved hjælp af standard SQL på Athena uden at bruge nogen anden tjeneste til funktionsudvikling. Dataforskere kan reducere den tid, der bruges på at forberede og kopiere datasæt, og i stedet fokusere på datafunktionsudvikling, eksperimentering og analyse af data i stor skala.
I dette indlæg gennemgår vi fordelene ved at bruge Athena med Apache Iceberg-tabelformatet, og hvordan det forenkler almindelige funktionsingeniøropgaver for dataforskere. Vi demonstrerer, hvordan Athena kan konvertere en eksisterende tabel i Apache Iceberg-format, derefter tilføje kolonner, slette kolonner og ændre dataene i tabellen uden at genskabe eller kopiere datasættet, og bruge disse muligheder til at skabe nye funktioner på Apache Iceberg-tabeller.
Løsningsoversigt
Dataforskere er generelt vant til at arbejde med store datasæt. Datasæt gemmes normalt i enten JSON, CSV, ORC eller Apache parket format eller lignende læseoptimerede formater for hurtig læseydelse. Dataforskere skaber ofte nye datafunktioner og udfylder sådanne datafunktioner med aggregerede og supplerende data. Historisk set blev denne opgave udført ved at skabe en visning oven på tabellen med de underliggende data i Apache Parquet-format, hvor sådanne kolonner og data blev tilføjet under kørsel eller ved at oprette en ny tabel med yderligere kolonner. Selvom denne arbejdsgang er velegnet til mange brugssager, er den ineffektiv for store datasæt, fordi data skal genereres på runtime, eller datasæt skal kopieres og transformeres.
Athena har introduceret ACID (Atomicitet, Konsistens, Isolation, Holdbarhed) transaktion funktioner, der tilføjer INSERT, UPDATE, DELETE, MERGE og tidsrejseoperationer baseret på Apache Iceberg borde. Disse funktioner gør det muligt for datavidenskabsfolk at skabe nye datafunktioner og droppe eksisterende datafunktioner på eksisterende datasæt uden at bekymre sig om at kopiere eller transformere datasættet eller abstrahere det med en visning. Dataforskere kan fokusere på funktionsingeniørarbejde og undgå at kopiere og transformere datasættene.
Athena Iceberg UPDATE-operationen skriver Apache Iceberg-positionssletningsfiler og nyligt opdaterede rækker som datafiler i samme transaktion. Du kan foretage registreringskorrektioner via en enkelt UPDATE-erklæring.
Med udgivelsen af Athena engine version 3 forbedres mulighederne for Apache Iceberg-borde med understøttelse af operationer som f.eks. OPRET TABEL SOM SELECT (CTAS) og MERGE-kommandoer, der strømliner livscyklusstyringen af dine Iceberg-data. CTAS gør det hurtigt og effektivt at oprette tabeller fra andre formater såsom Apache Paquet og SLUT TIL betingede opdateringer, sletter eller indsætter rækker i en Iceberg-tabel. En enkelt erklæring kan kombinere opdatering, sletning og indsæt handlinger.
Forudsætninger
Konfigurer en Athena-arbejdsgruppe med Athena-motor version 3 til at bruge CTAS- og MERGE-kommandoer med et Apache Iceberg-bord. For at opgradere din eksisterende Athena-motor til version 3 i din Athena-arbejdsgruppe skal du følge instruktionerne i Opgrader til Athena engine version 3 for at øge forespørgselsydeevnen og få adgang til flere analysefunktioner eller henvise til Ændring af motorversionen i Athena-konsollen.
datasæt
Til demonstration bruger vi et Apache Parket-bord, der indeholder flere millioner registreringer af tilfældigt distribuerede fiktive salgsdata fra de sidste mange år, gemt i en S3-spand. Hent datasættet, udpak det til din lokale computer og upload det til din S3-bøtte. I dette indlæg uploadede vi vores datasæt til s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/.
Følgende tabel viser layoutet for tabellen customer_orders.
| Kolonnenavn | Datatype | Beskrivelse |
| ordrenøgle | streng | Ordrenummer for ordren |
| kundenøgle | streng | Kundens identifikationsnummer |
| ordre status | streng | Status for ordren |
| total pris | streng | Samlet pris for ordren |
| bestillingsdato | streng | Dato for ordren |
| ordreprioritet | streng | Ordrens prioritet |
| ekspedient | streng | Navn på ekspedienten, der behandlede ordren |
| skibsprioritet | streng | Prioritet på forsendelsen |
| navn | streng | Kundenavn |
| adresse | streng | Kundeadresse |
| nationsnøgle | streng | Kundens nationsnøgle |
| telefon | streng | Kundens telefonnummer |
| acctbal | streng | Kundekontosaldo |
| mktsegment | streng | Kundemarkedssegment |
Udfør feature engineering
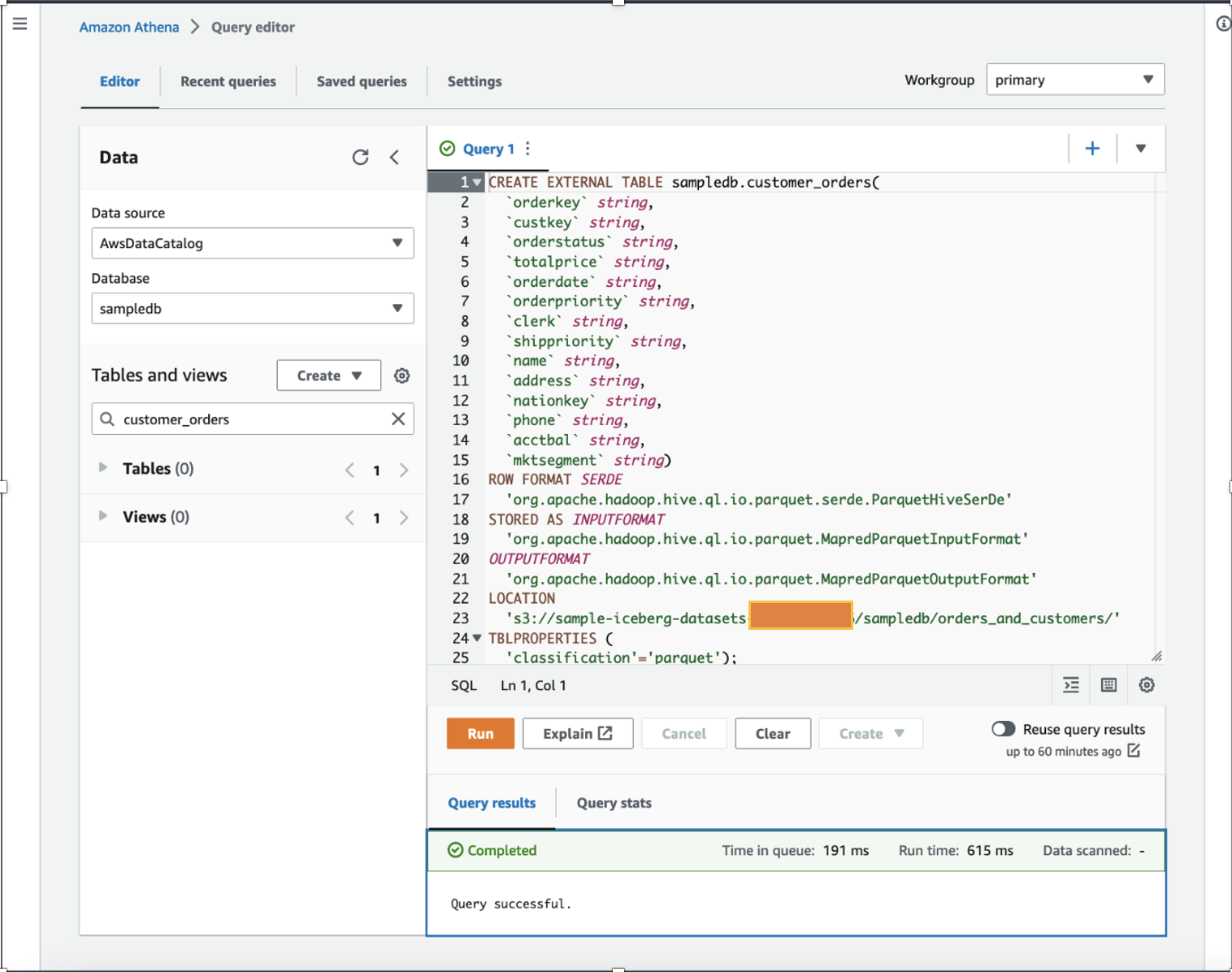
Som data scientist vil vi gerne præstere funktionsteknik på kundeordredata ved at tilføje beregnede et års samlede indkøb og et års gennemsnitlige indkøb for hver kunde i det eksisterende datasæt. Til demonstrationsformål skabte vi customer_orders bord i sampledb database ved hjælp af Athena som vist i følgende DDL-kommando. (Du kan bruge et hvilket som helst af dine eksisterende datasæt og følge trinene nævnt i dette indlæg.) Den customer_orders Datasættet blev genereret og gemt på S3-bøtteplaceringen s3://sample-iceberg-datasets-xxxxxxxxxxx/sampledb/orders_and_customers/ i parketformat. Dette bord er ikke et Apache Iceberg-bord.
![]()
Valider dataene i tabellen ved at køre en forespørgsel:
![]()
Vi ønsker at tilføje nye funktioner til denne tabel for at få en dybere forståelse af kundesalg, hvilket kan resultere i hurtigere modeltræning og mere værdifuld indsigt. For at tilføje nye funktioner til datasættet skal du konvertere customer_orders Athena bord til Apache Iceberg bord på Athena. Udgave a CTAS forespørgselserklæring for at oprette en ny tabel med Apache Iceberg-format fra customer_orders bord. Mens du gør det, tilføjes en ny funktion for at få det samlede købsbeløb i det seneste år (maks. år af datasættet) af hver kunde.
I den følgende CTAS-forespørgsel hedder en ny kolonne one_year_sales_aggregate med standardværdien som 0.0 af datatype double er tilføjet og table_type er sat til ICEBERG:
![]()
Udsted følgende forespørgsel for at bekræfte dataene i Apache Iceberg-tabellen med den nye kolonne one_year_sales_aggregate værdier som 0.0:
![]()
Vi ønsker at udfylde værdierne for den nye funktion one_year_sales_aggregate i datasættet for at få det samlede købsbeløb for hver kunde baseret på deres køb i det seneste år (max år for datasættet). Udsted en MERGE-forespørgselserklæring til Apache Iceberg-tabellen ved hjælp af Athena til at udfylde værdier for one_year_sales_aggregate funktionen:
![]()
Udsend følgende forespørgsel for at validere den opdaterede værdi for det samlede forbrug af hver kunde i det seneste år:
![]()
Vi beslutter at tilføje endnu en funktion til et eksisterende Apache Iceberg-bord for at beregne og gemme det gennemsnitlige købsbeløb i det seneste år for hver kunde. Udsted en ALTER-forespørgselserklæring for at tilføje en ny kolonne til en eksisterende tabel for funktion one_year_sales_average:
![]()
Før du udfylder værdierne til denne nye funktion, kan du indstille standardværdien for funktionen one_year_sales_average til 0.0. Brug den samme Apache Iceberg-tabel på Athena, udgiv en UPDATE-forespørgselserklæring for at udfylde værdien for den nye funktion som 0.0:
![]()
Udsend følgende forespørgsel for at bekræfte, at den opdaterede værdi for hver kundes gennemsnitlige forbrug i det seneste år er indstillet til 0.0:
![]()
Nu vil vi udfylde værdierne for den nye funktion one_year_sales_average i datasættet for at få det gennemsnitlige købsbeløb for hver kunde baseret på deres køb i det seneste år (max år for datasættet). Udsted en MERGE-forespørgselserklæring til den eksisterende Apache Iceberg-tabel på Athena ved hjælp af Athena-motoren til at udfylde værdier for funktionen one_year_sales_average:
![]()
Udsend følgende forespørgsel for at bekræfte de opdaterede værdier for hver kundes gennemsnitlige forbrug:
![]()
Når yderligere datafunktioner er blevet tilføjet til datasættet, fortsætter datavidenskabsmænd generelt med at træne ML-modeller og drage konklusioner ved hjælp af Amazon Sagemaker eller tilsvarende værktøjssæt.
Konklusion
I dette indlæg demonstrerede vi, hvordan man udfører feature engineering ved hjælp af Athena med Apache Iceberg. Vi demonstrerede også brugen af CTAS-forespørgslen til at oprette en Apache Iceberg-tabel på Athena fra et eksisterende datasæt i Apache Parquet-format, tilføje nye funktioner i en eksisterende Apache Iceberg-tabel på Athena ved hjælp af ALTER-forespørgslen og bruge UPDATE- og MERGE-forespørgselsudsagn til at opdatere funktionsværdier for eksisterende kolonner.
Vi opfordrer dig til at bruge CTAS-forespørgsler til at oprette tabeller hurtigt og effektivt, og bruge MERGE-forespørgselserklæringen til at synkronisere tabeller i ét trin for at forenkle dataforberedelser og opdateringsopgaver, når du transformerer funktionerne ved hjælp af Athena med Apache Iceberg. Hvis du har kommentarer eller feedback, bedes du efterlade dem i kommentarfeltet.
Om forfatterne
![]() Vivek Gautam er dataarkitekt med speciale i datasøer hos AWS Professional Services. Han arbejder med virksomhedskunder, der bygger dataprodukter, analyseplatforme og løsninger på AWS. Når vi ikke bygger og designer moderne dataplatforme, er Vivek en madentusiast, der også kan lide at udforske nye rejsemål og tage på vandreture.
Vivek Gautam er dataarkitekt med speciale i datasøer hos AWS Professional Services. Han arbejder med virksomhedskunder, der bygger dataprodukter, analyseplatforme og løsninger på AWS. Når vi ikke bygger og designer moderne dataplatforme, er Vivek en madentusiast, der også kan lide at udforske nye rejsemål og tage på vandreture.
![]() Mikhail Vaynshteyn er en løsningsarkitekt med Amazon Web Services. Mikhail arbejder med kunder inden for sundheds- og biovidenskab for at bygge løsninger, der hjælper med at forbedre patienternes resultater. Mikhail har specialiseret sig i dataanalysetjenester.
Mikhail Vaynshteyn er en løsningsarkitekt med Amazon Web Services. Mikhail arbejder med kunder inden for sundheds- og biovidenskab for at bygge løsninger, der hjælper med at forbedre patienternes resultater. Mikhail har specialiseret sig i dataanalysetjenester.
![]() Naresh Gautam er en dataanalyse- og AI/ML-leder hos AWS med 20 års erfaring, som nyder at hjælpe kunder med at bygge højtilgængelige, højtydende og omkostningseffektive dataanalyse- og AI/ML-løsninger for at give kunderne datadrevet beslutningstagning . I sin fritid nyder han at meditere og lave mad.
Naresh Gautam er en dataanalyse- og AI/ML-leder hos AWS med 20 års erfaring, som nyder at hjælpe kunder med at bygge højtilgængelige, højtydende og omkostningseffektive dataanalyse- og AI/ML-løsninger for at give kunderne datadrevet beslutningstagning . I sin fritid nyder han at meditere og lave mad.
![]() Harsha Tadiparthi er specialist Principal Solutions Architect, Analytics hos AWS. Han nyder at løse komplekse kundeproblemer i databaser og analyser og levere succesfulde resultater. Uden for arbejdet elsker han at tilbringe tid med sin familie, se film og rejse, når det er muligt.
Harsha Tadiparthi er specialist Principal Solutions Architect, Analytics hos AWS. Han nyder at løse komplekse kundeproblemer i databaser og analyser og levere succesfulde resultater. Uden for arbejdet elsker han at tilbringe tid med sin familie, se film og rejse, når det er muligt.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- EVM Finans. Unified Interface for Decentralized Finance. Adgang her.
- Quantum Media Group. IR/PR forstærket. Adgang her.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Kilde: https://aws.amazon.com/blogs/big-data/accelerate-data-science-feature-engineering-on-transactional-data-lakes-using-amazon-athena-with-apache-iceberg/
- :har
- :er
- :ikke
- :hvor
- $OP
- 10
- 100
- 12
- 17
- 20
- 20 år
- 23
- 27
- 7
- a
- Om
- fremskynde
- adgang
- gennemført
- Konto
- aktioner
- tilføje
- tilføjet
- tilføje
- Yderligere
- adresse
- AI / ML
- også
- Skønt
- Amazon
- Amazonas Athena
- Amazon SageMaker
- Amazon Web Services
- beløb
- an
- Analytisk
- Analytisk
- analytics
- analysere
- analysere
- ,
- En anden
- enhver
- Apache
- Apache Spark
- ER
- AS
- At
- til rådighed
- gennemsnit
- undgå
- AWS
- AWS Professional Services
- baseret
- BE
- fordi
- været
- fordele
- bygge
- Bygning
- bygget
- by
- beregnet
- CAN
- kapaciteter
- tilfælde
- klassificering
- Cloud
- samlinger
- Kolonne
- Kolonner
- kombinerer
- kommentarer
- Fælles
- komplekse
- Compute
- computer
- Computer Vision
- Konfiguration
- indeholder
- sammenhæng
- konvertere
- madlavning
- kopiering
- Rettelser
- omkostningseffektiv
- skabe
- oprettet
- Oprettelse af
- kunde
- Kunder
- data
- Dataanalyse
- Data Lake
- datalogi
- dataforsker
- datastyret
- Database
- databaser
- datasæt
- Dato
- beslutte
- Beslutningstagning
- dybere
- Standard
- leverer
- leverer
- demonstrere
- demonstreret
- designe
- destinationer
- distribueret
- gør
- fordoble
- Drop
- holdbarhed
- hver
- let
- effektiv
- effektivt
- indsats
- enten
- elementer
- bemyndige
- muliggøre
- tilskynde
- Engine (Motor)
- Engineering
- Motorer
- forbedret
- Enterprise
- virksomhedskunder
- entusiast
- Hele
- Ækvivalent
- Ether (ETH)
- eksisterende
- erfaring
- udforske
- ekstern
- falsk
- familie
- FAST
- hurtigere
- Feature
- Funktionalitet
- tilbagemeldinger
- Filer
- Fokus
- følger
- efter
- mad
- Til
- format
- rammer
- Gratis
- fra
- generelt
- genereret
- få
- Go
- gruppe
- Hadoop
- Have
- he
- sundhedspleje
- hjælpe
- hjælpe
- Høj ydeevne
- stærkt
- Hikes
- hans
- historisk
- Hive
- Hvordan
- How To
- HTML
- HTTPS
- Identifikation
- identificere
- if
- billeder
- Forbedre
- in
- Herunder
- Forøg
- ineffektiv
- Infrastruktur
- Indsætter
- indsigt
- i stedet
- anvisninger
- interaktiv
- ind
- introduceret
- isolation
- spørgsmål
- IT
- jpg
- json
- mærkning
- sø
- Sprog
- stor
- Efternavn
- Layout
- leder
- LÆR
- læring
- Forlade
- Livet
- Life Sciences
- livscyklus
- GRÆNSE
- lokale
- placering
- elsker
- maskine
- machine learning
- lave
- maerker
- administrere
- ledelse
- administrerer
- mange
- Marked
- matchede
- max
- meningsfuld
- Meditation
- nævnte
- Flet
- million
- mangler
- ML
- model
- modeller
- Moderne
- ændre
- mere
- Film
- navn
- Som hedder
- nation
- Natural
- Naturligt sprog
- Natural Language Processing
- Behov
- behøve
- Ny
- ny funktion
- Nye funktioner
- nyligt
- ingen
- nummer
- of
- tit
- on
- ONE
- kun
- åbent
- open source
- drift
- Produktion
- or
- ordrer
- Andet
- vores
- udfald
- uden for
- forbi
- Betal
- udføre
- ydeevne
- telefon
- Platforme
- plato
- Platon Data Intelligence
- PlatoData
- Vær venlig
- position
- mulig
- Indlæg
- forberede
- pris
- Main
- problemer
- behandle
- bearbejdet
- forarbejdning
- Produkter
- professionel
- give
- køb
- indkøb
- formål
- Python
- forespørgsler
- hurtigt
- Raw
- rådata
- Læs
- anerkendelse
- optage
- optegnelser
- reducere
- frigive
- påkrævet
- resultere
- gennemgå
- RÆKKE
- Kør
- kører
- sagemaker
- salg
- samme
- Scale
- Videnskab
- VIDENSKABER
- Videnskabsmand
- forskere
- Sektion
- Serverless
- tjeneste
- Tjenester
- sæt
- flere
- vist
- Shows
- lignende
- Simpelt
- forenklet
- forenkle
- enkelt
- So
- Løsninger
- Løsning
- Kilder
- Spark
- specialist
- specialiseret
- tale
- Talegenkendelse
- tilbringe
- brugt
- SQL
- standard
- Statement
- udsagn
- Trin
- Steps
- opbevaring
- butik
- opbevaret
- strømline
- String
- vellykket
- sådan
- support
- Understøtter
- Systemer
- bord
- Opgaver
- opgaver
- at
- Fusionen
- deres
- Them
- derefter
- Der.
- Disse
- denne
- tid
- tidsrejser
- til
- top
- I alt
- Tog
- Kurser
- transaktion
- transaktionsbeslutning
- omdannet
- omdanne
- rejse
- typen
- underliggende
- forståelse
- Opdatering
- opdateret
- opdateringer
- opgradering
- uploadet
- brug
- ved brug af
- sædvanligvis
- VALIDATE
- Værdifuld
- værdi
- Værdier
- forskellige
- verificere
- udgave
- meget
- via
- Videoer
- Specifikation
- vision
- ønsker
- var
- Ur
- we
- web
- webservices
- var
- hvornår
- når
- som
- mens
- WHO
- med
- uden
- Arbejde
- workflow
- arbejdsgruppe
- arbejder
- virker
- ville
- skriver
- år
- år
- dig
- Din
- zephyrnet
- Zip