
Billede fra Bing Image Creator
Exploratory Data Analysis (EDA) er den vigtigste opgave at udføre i begyndelsen af ethvert datavidenskabsprojekt.
I bund og grund involverer det en grundig undersøgelse og karakterisering af dine data for at finde deres underliggende karakteristika, muligt abnormaliteter, og skjult mønstre , relationer.
Denne forståelse af dine data er, hvad der i sidste ende vil guide gennem de følgende trin af din maskinlæringspipeline, fra dataforbehandling til modelopbygning og analyse af resultater.
EDA-processen består grundlæggende af tre hovedopgaver:
- Trin 1: Datasætoversigt og beskrivende statistik
- Trin 2: Funktionsvurdering og visualiseringog
- Trin 3: Evaluering af datakvalitet
Som du måske har gættet, kan hver af disse opgaver indebære en ganske omfattende mængde analyser, som nemt vil have dig skære, udskrive og plotte dine panda-datarammer som en gal.
Medmindre du vælger det rigtige værktøj til jobbet.
I denne artikel, vi dykker ned i hvert trin i en effektiv EDA-proces, og diskuter hvorfor du skal vende ydata-profilering ind i din one-stop-shop for at mestre det.
Til demonstrere bedste praksis og undersøge indsigt, vil vi bruge Voksentællingsindkomstdatasæt, frit tilgængelig på Kaggle eller UCI Repository (Licens: CC0: Public Domain).
Når vi først får fingrene i et ukendt datasæt, dukker der en automatisk tanke op med det samme: Hvad arbejder jeg med?
Vi skal have en dyb forståelse af vores data for at håndtere dem effektivt i fremtidige maskinlæringsopgaver
Som en tommelfingerregel starter vi traditionelt med at karakterisere dataene i forhold til antallet af observationer, nummer og typer af funktioner, samlet set manglende sats, og procentdel af duplikere observationer.
Med noget panda-manipulation og det rigtige cheatsheet kunne vi til sidst udskrive ovenstående information med nogle korte kodestykker:
Datasætoversigt: Voksentællingsdatasæt. Antal observationer, funktioner, funktionstyper, duplikerede rækker og manglende værdier. Uddrag af forfatter.
Alt i alt er outputformatet ikke ideelt... Hvis du er fortrolig med pandaer, kender du også standarden Juicy Fruit at starte en EDA-proces — df.describe():
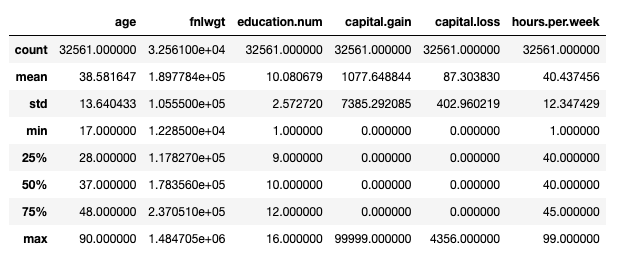
Voksendatasæt: Hovedstatistik præsenteret med df.describe(). Billede af forfatter.
Dette tager dog kun hensyn numeriske funktioner. Vi kunne bruge en df.describe(include='object') at udskrive nogle yderligere oplysninger om kategoriske træk (tælle, unik, tilstand, frekvens), men en simpel kontrol af eksisterende kategorier ville involvere noget lidt mere omfattende:
Datasætoversigt: Voksentællingsdatasæt. Udskrivning af de eksisterende kategorier og respektive frekvenser for hver kategorisk funktion i data. Uddrag af forfatter.
Men vi kan gøre dette - og gæt hvad, alle de efterfølgende EDA-opgaver! — i en enkelt kodelinje, ved brug af ydata-profilering:
Profileringsrapport for voksentællingsdatasættet ved hjælp af ydata-profilering. Uddrag af forfatter.
Ovenstående kode genererer en komplet profileringsrapport af dataene, som vi kan bruge til at flytte vores EDA-proces yderligere uden at skulle skrive mere kode!
Vi gennemgår de forskellige afsnit af rapporten i de følgende afsnit. I hvad angår dataenes overordnede karakteristika, er alle de oplysninger, vi ledte efter, inkluderet i Oversigt sektion:
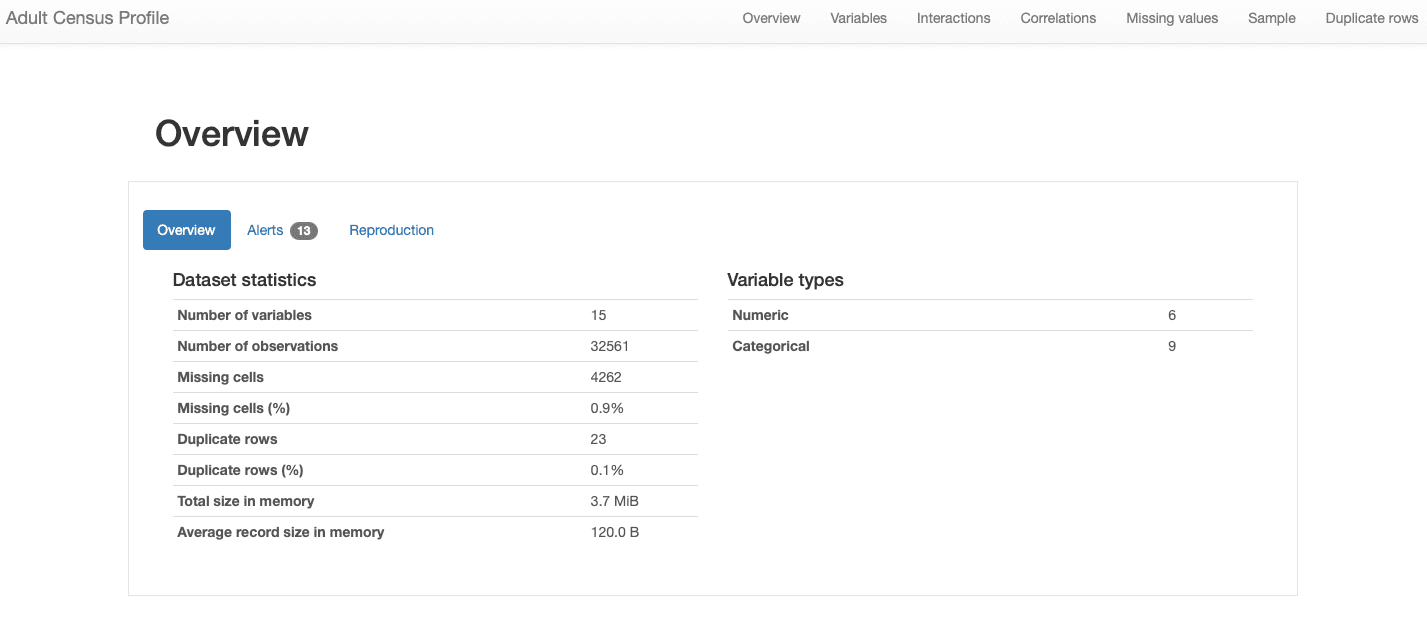
ydata-profiling: Dataprofileringsrapport — Datasætoversigt. Billede af forfatter.
Vi kan se, at vores datasæt omfatter 15 funktioner og 32561 observationer, med 23 duplikerede poster og en samlet manglende andel på 0.9 %.
Derudover er datasættet blevet korrekt identificeret som en tabeldatasæt, og ret heterogene, der præsenterer begge dele numeriske og kategoriske træk. Forum tidsseriedata, som er tidsafhængig og præsenterer forskellige typer mønstre, ydata-profiling ville indarbejde andre statistikker og analyser i rapporten.
Vi kan undersøge nærmere rådata og eksisterende duplikerede poster at have en overordnet forståelse af funktionerne, før du går ind i mere kompleks analyse:
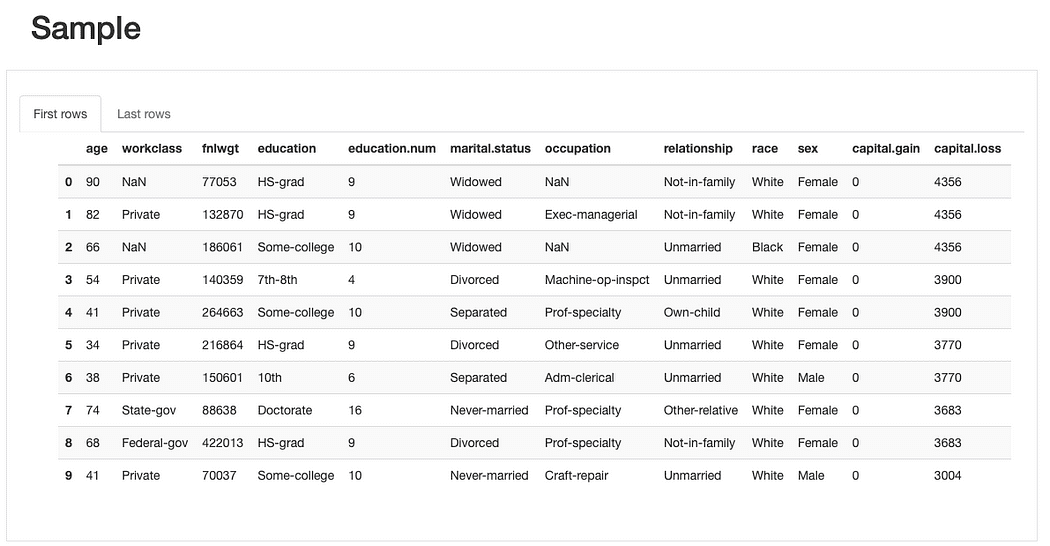
ydata-profiling: Data Profiling Report — Eksempel på forhåndsvisning. Billede af forfatter.
Fra det korte eksempel af dataprøven, kan vi med det samme se, at selvom datasættet har en lav procentdel af manglende data generelt, nogle funktioner kan blive påvirket af det mere end andre. Vi kan også identificere en snarere et stort antal kategorier for nogle funktioner og funktioner med 0 værdi (eller i det mindste med en betydelig mængde 0'er).
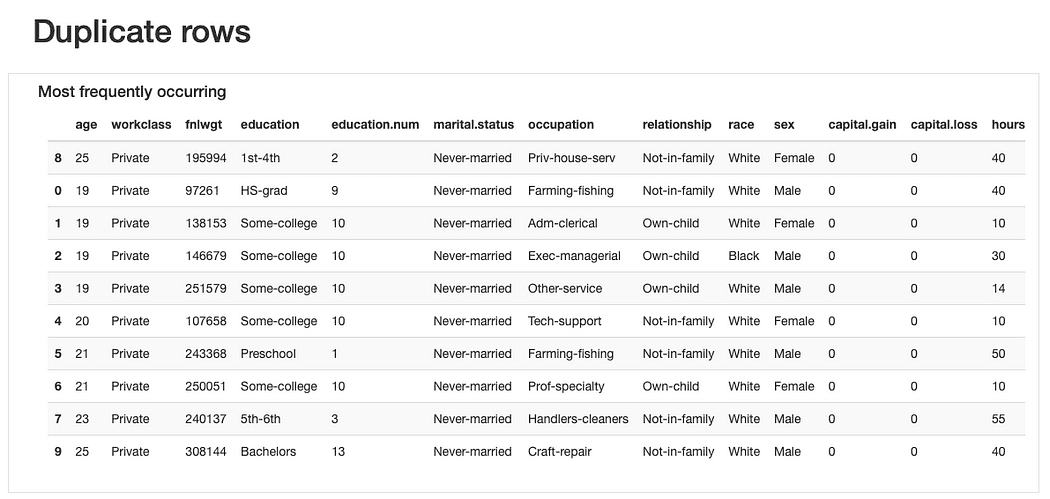
ydata-profiling: Data Profiling Report — Dublerede rækker forhåndsvisning. Billede af forfatter.
Med hensyn til dubletrækkerne, ville det ikke være mærkeligt at finde "gentagne" observationer, da de fleste funktioner repræsenterer kategorier, hvor flere personer kan "passe ind" samtidigt.
Alligevel, måske en "data lugt" kunne være, at disse observationer deler det samme age værdier (hvilket er plausibelt) og nøjagtig det samme fnlwgt hvilket, i betragtning af de præsenterede værdier, synes sværere at tro på. Så yderligere analyse ville være påkrævet, men det burde vi sandsynligvis droppe disse dubletter senere.
Samlet set kan dataoversigten være en simpel analyse, men én yderst virkningsfuld, da det vil hjælpe os med at definere de kommende opgaver i vores pipeline.
Efter at have et kig på de overordnede databeskrivelser, er vi nødt til det zoom ind på vores datasæts funktioner, for at få lidt indsigt i deres individuelle egenskaber — Univariat analyse - samt deres interaktioner og relationer - Multivariat analyse.
Begge opgaver er stærkt afhængige af undersøge tilstrækkelig statistik og visualiseringer, som skal være til skræddersyet til typen af funktion ved hånden (f.eks. numerisk, kategorisk), og adfærden vi søger at dissekere (f.eks. interaktioner, korrelationer).
Lad os tage et kig på bedste praksis for hver opgave.
Univariat analyse
At analysere de individuelle egenskaber ved hver funktion er afgørende, da det vil hjælpe os med at beslutte deres relevans for analysen og type dataforberedelse de kan kræve for at opnå optimale resultater.
For eksempel kan vi finde værdier, der er ekstremt uden for rækkevidde og kan referere til uoverensstemmelser or outliers. Det kan vi blive nødt til standardisere numerisk data eller udføre en one-hot kodning af kategorisk funktioner, afhængigt af antallet af eksisterende kategorier. Eller vi skal muligvis udføre yderligere dataforberedelse for at håndtere numeriske funktioner, der er forskudt eller skæv, hvis den maskinlæringsalgoritme, vi agter at bruge, forventer en bestemt fordeling (normalt Gaussisk).
Bedste praksis kræver derfor en grundig undersøgelse af individuelle egenskaber såsom beskrivende statistik og datadistribution.
Disse vil fremhæve behovet for efterfølgende opgaver med fjernelse af outlier, standardisering, etiketkodning, dataimputering, dataforøgelse og andre former for forbehandling.
Lad os undersøge det race , capital.gain mere detaljeret. Hvad kan vi umiddelbart få øje på?
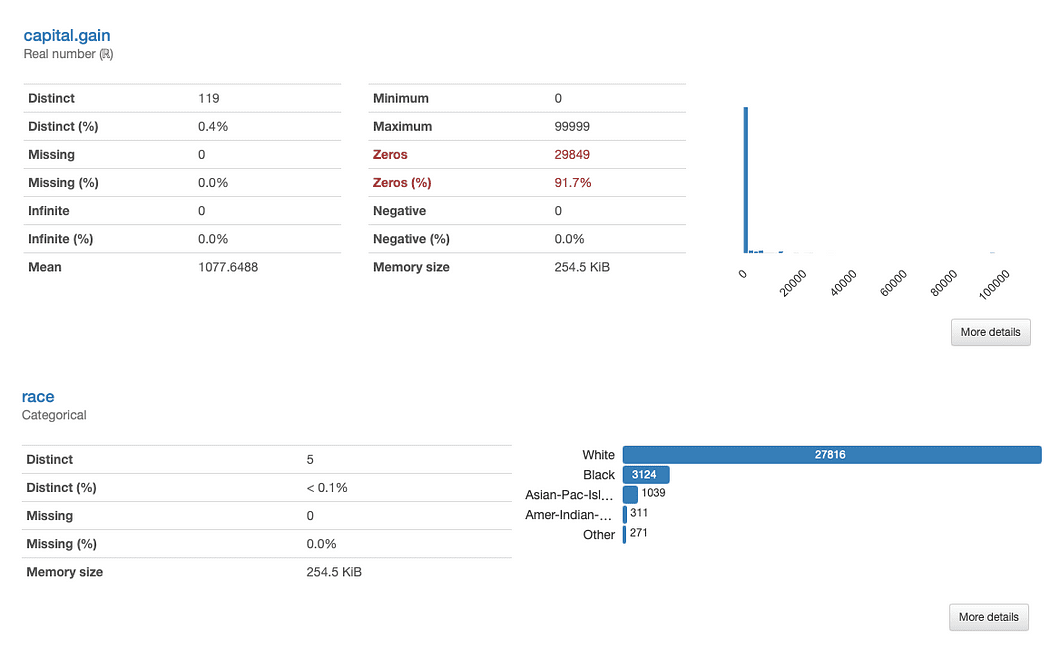
ydata-profiling: Profileringsrapport (race and capital.gain). Billede af forfatter.
Vurderingen af kapitalgevinst er ligetil:
I betragtning af datafordelingen kan vi stille spørgsmålstegn ved, om funktionen tilføjer nogen værdi til vores analyse, da 91.7 % af værdierne er "0".
Analyserer løb er lidt mere kompleks:
Der er en klar underrepræsentation af andre racer end White. Dette leder tankerne hen på to hovedspørgsmål:
- Den ene er den generelle tendens til maskinlæringsalgoritmer til overse mindre repræsenterede begreber, kendt som problemet med små disjunkter, der fører til nedsat læringspræstation;
- Den anden er noget afledt af dette problem: da vi har at gøre med et følsomt træk, kan denne "overseende tendens" have konsekvenser, der er direkte relateret til skævhed , fairness spørgsmål. Noget som vi bestemt ikke vil krybe ind i vores modeller.
Med dette i betragtning, burde vi måske overveje at udføre dataforøgelse betinget af de underrepræsenterede kategorier, samt overvejer retfærdighedsbevidste målinger til modelevaluering, for at kontrollere for eventuelle uoverensstemmelser i ydeevne, der vedrører race værdier.
Vi vil yderligere detaljere om andre dataegenskaber, der skal behandles, når vi diskuterer bedste praksis for datakvalitet (trin 3). Dette eksempel viser bare, hvor meget indsigt vi kan tage ved blot at vurdere hver enkelt funktion egenskaber.
Bemærk endelig, hvordan forskellige funktionstyper, som tidligere nævnt, kræver forskellige statistikker og visualiseringsstrategier:
- Numeriske funktioner omfatter oftest information vedrørende middelværdi, standardafvigelse, skævhed, kurtosis og andre kvantilstatistikker og er bedst repræsenteret ved brug af histogramplot;
- Kategoriske træk er normalt beskrevet ved hjælp af mode-, median- og frekvenstabellerne og repræsenteret ved hjælp af søjleplot til kategorianalyse.
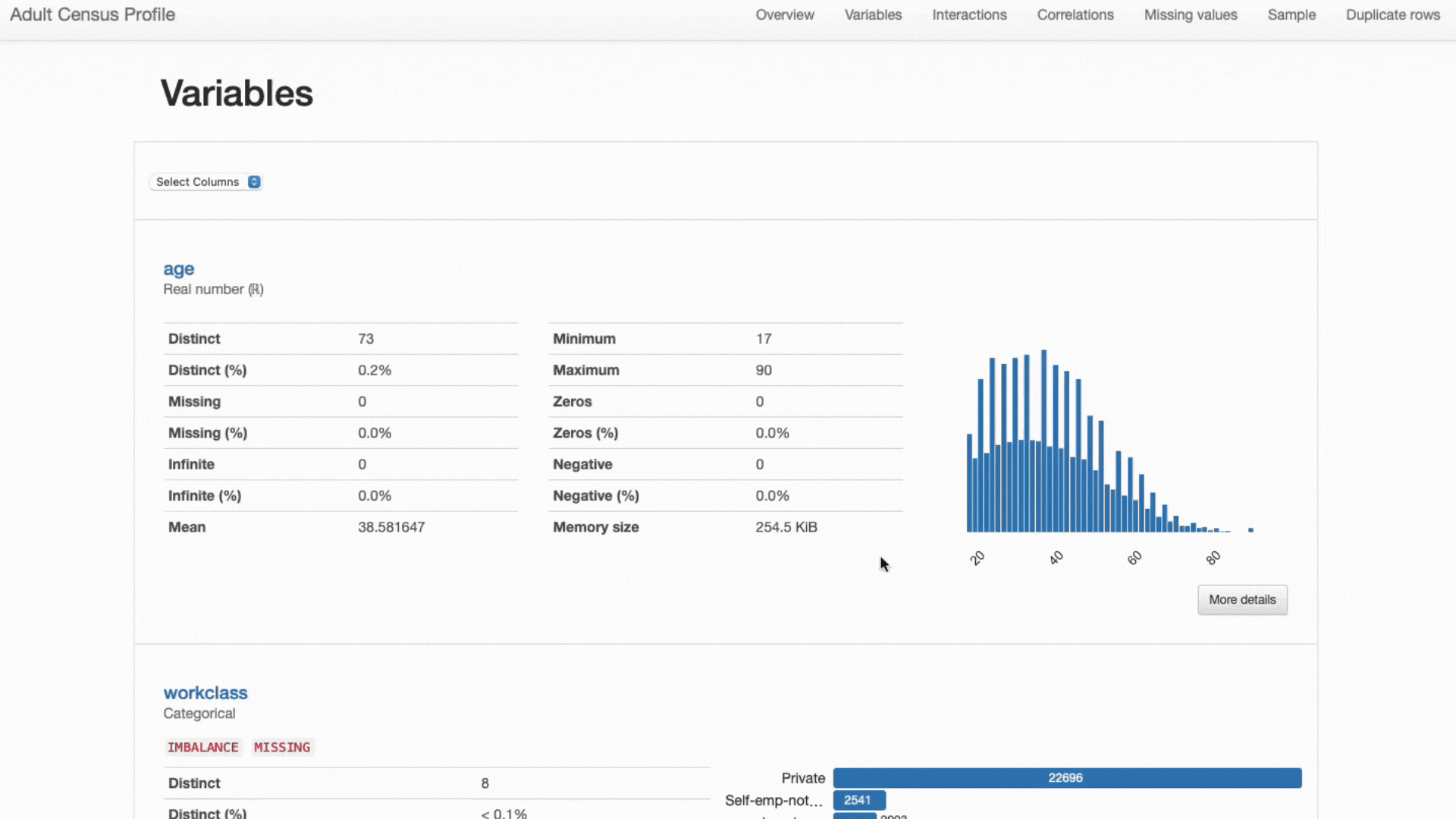
ydata-profiling: Profileringsrapport. Præsenterede statistikker og visualiseringer justeres til hver funktionstype. Screencast af forfatter.
En sådan detaljeret analyse ville være besværlig at udføre med generel pandamanipulation, men heldigvis ydata-profiling har al denne funktionalitet indbygget i ProfileReport for nemheds skyld: ingen ekstra linjer kode blev tilføjet til kodestykket!
Multivariat analyse
For multivariat analyse fokuserer bedste praksis hovedsageligt på to strategier: at analysere interaktioner mellem funktioner og analysere deres korrelationer.
Analyse af interaktioner
Interaktioner lader os udforsk visuelt, hvordan hvert par funktioner opfører sig, dvs. hvordan værdierne af den ene funktion forholder sig til den andens værdier.
For eksempel kan de udstille positiv or negativ relationer, alt efter om stigningen af ens værdier er forbundet med henholdsvis stigning eller fald i den andens værdier.
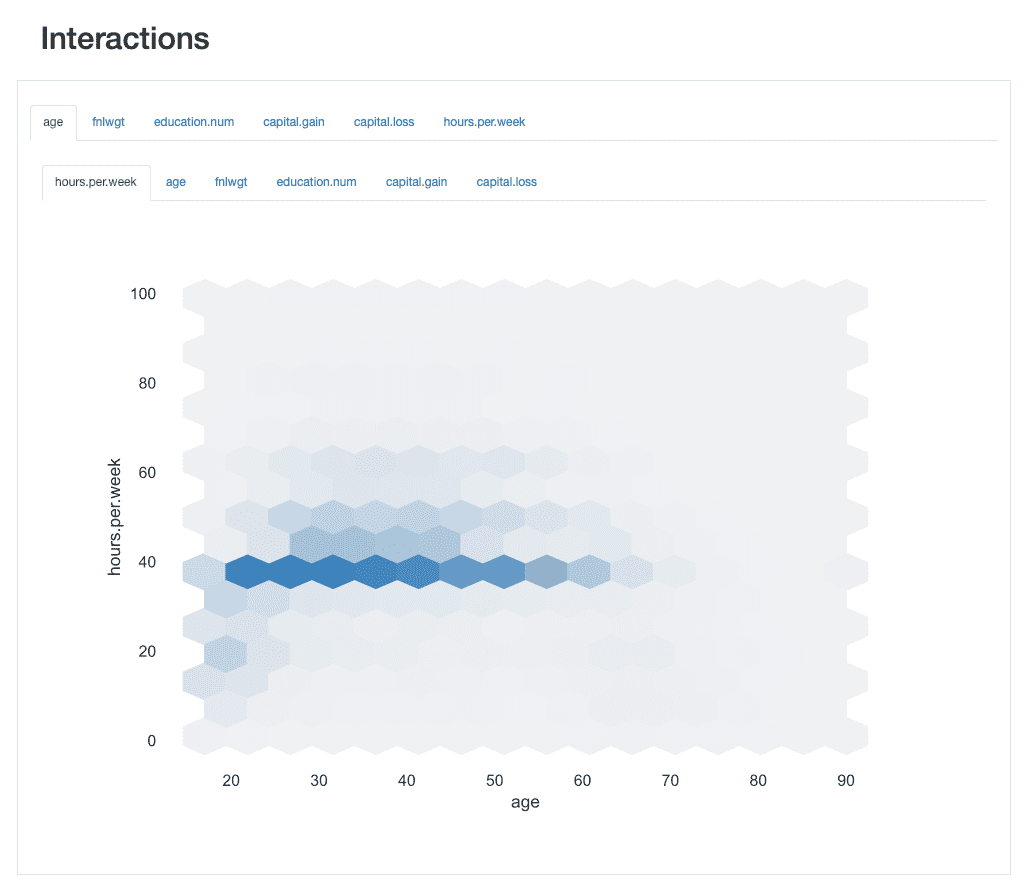
ydata-profiling: Profileringsrapport — Interaktioner. Billede af forfatter.
At tage samspillet mellem age , hours.per.weeksom et eksempel kan vi se, at langt størstedelen af arbejdsstyrken arbejder med en standard på 40 timer. Der er dog nogle "travle bier", der arbejder forbi det (op til 60 eller endda 65 timer) mellem 30 og 45 år. Folk i 20'erne er mindre tilbøjelige til at overanstrenge sig og kan have en mere let arbejdsplan på nogle uger.
Analyse af sammenhænge
På samme måde som interaktioner, sammenhænge lad os analysere forholdet mellem funktioner. Korrelationer "sætter en værdi" på det, så det er lettere for os at bestemme "styrken" af det forhold.
Denne "styrke" er målt ved korrelationskoefficienter og kan analyseres enten numerisk (f.eks. inspektion af en korrelationsmatrix) eller med en heatmap, der bruger farver og skygger til visuelt at fremhæve interessante mønstre:
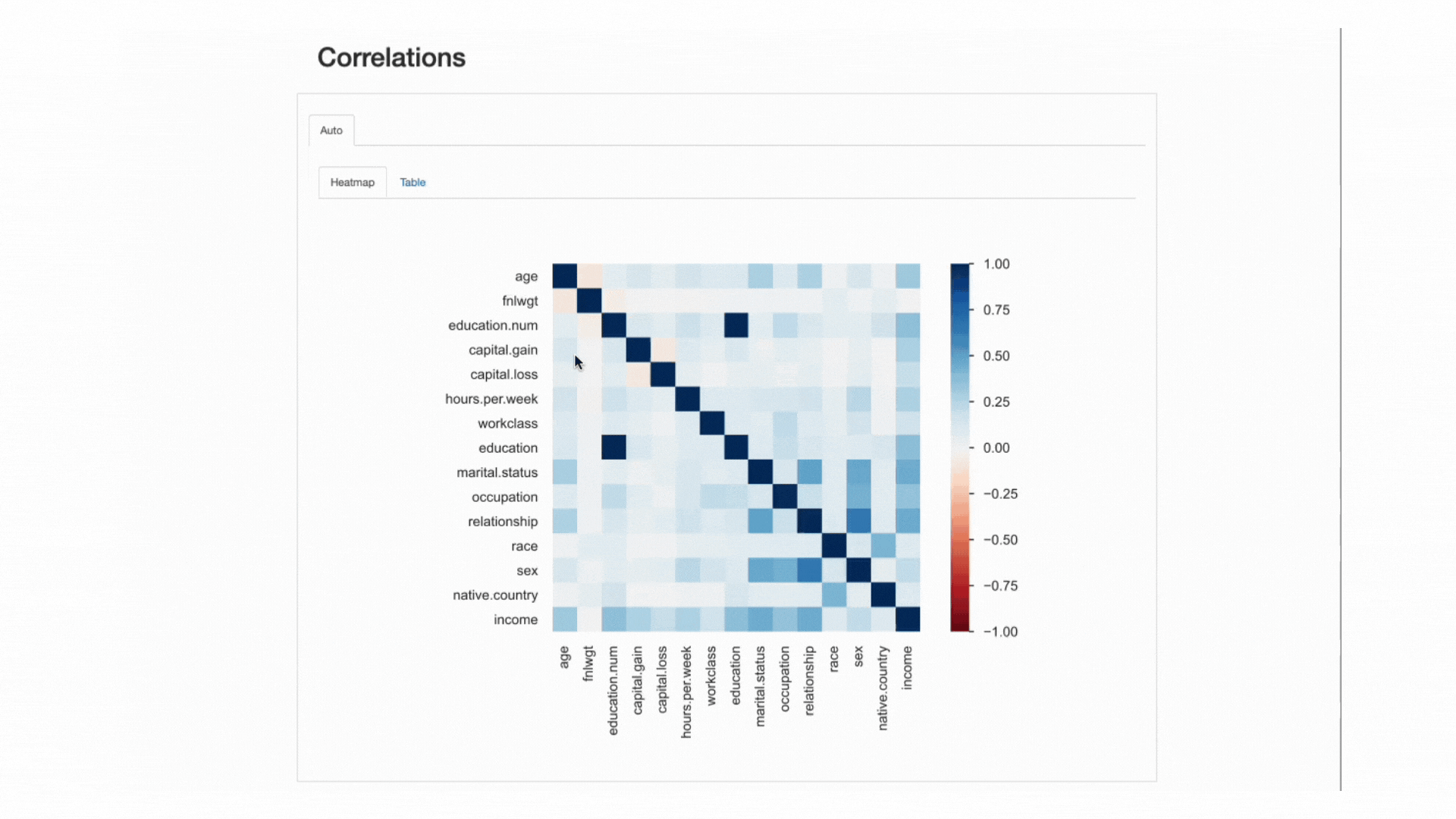
ydata-profiling: Profileringsrapport — Heatmap og korrelationsmatrix. Screencast af forfatter.
Med hensyn til vores datasæt, læg mærke til, hvordan korrelationen mellem education , education.num skiller sig ud. Faktisk, de har samme informationog education.num er blot en binning af education værdier.
Et andet mønster, der fanger øjet, er sammenhængen mellem sex , relationship selvom det igen ikke er særlig informativt: ser vi på værdierne af begge funktioner, vil vi indse, at disse funktioner højst sandsynligt er relaterede pga male , female vil svare til husband , wife, henholdsvis.
Disse typer redundanser kan blive kontrolleret for at se, om vi kan fjerne nogle af disse funktioner fra analysen (marital.status er også relateret til relationship , sex; native.country , race for eksempel blandt andre).
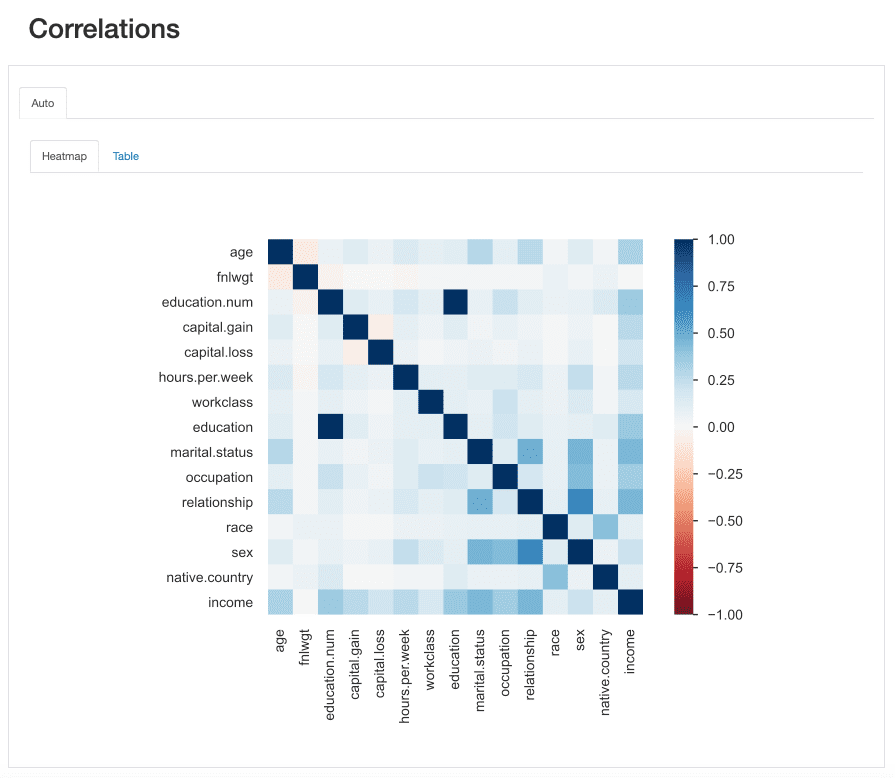
ydata-profiling: Profileringsrapport — Korrelationer. Billede af forfatter.
Der er dog andre sammenhænge, der skiller sig ud og kunne være interessante i forbindelse med vores analyse.
For eksempel sammenhængen mellemsex , occupation eller sex , hours.per.week.
Endelig korrelationerne mellem income og de resterende funktioner er virkelig informative, specielt i tilfælde af at vi forsøger at kortlægge et klassifikationsproblem. At vide hvad er mest korreleret funktioner til vores målgruppe hjælper os med at identificere mest diskriminerende funktioner og samt finde mulige datalækager, der kan påvirke vores model.
Ud fra varmekortet ser det ud til marital.status or relationship er blandt de vigtigste forudsigere, mens fnlwgt synes f.eks. ikke at have stor indflydelse på resultatet.
På samme måde som databeskrivelser og visualiseringer skal interaktioner og korrelationer også tage hensyn til de typer funktioner, der er ved hånden.
Med andre ord vil forskellige kombinationer blive målt med forskellige korrelationskoefficienter. Som standard, ydata-profiling kører korrelationer på auto, hvilket betyder at:
- Numerisk versus Numerisk korrelationer måles vha Spearmans rang korrelationskoefficient;
- Kategorisk versus Kategorisk korrelationer måles vha Cramers V;
- Numerisk versus Kategorisk korrelationer bruger også Cramers V, hvor det numeriske træk først diskretiseres;
Og hvis du vil tjekke andre korrelationskoefficienter (f.eks. Pearson's, Kendall's, Phi) kan du nemt konfigurere rapportens parametre.
Mens vi navigerer mod en datacentreret paradigme af AI-udvikling, være på toppen af mulige komplicerende faktorer der opstår i vores data er afgørende.
Med "komplicerende faktorer" henviser vi til fejl der kan forekomme under dataindsamlingen af behandlingen, eller datas iboende egenskaber som blot er en afspejling af natur af dataene.
Heriblandt mangler data, ubalanceret data, konstant værdier, dubletter, meget korreleret or overflødig funktioner, støjende data blandt andet.
Datakvalitetsproblemer: Fejl og data iboende egenskaber. Billede af forfatter.
At finde disse datakvalitetsproblemer i begyndelsen af et projekt (og overvåge dem løbende under udviklingen) er afgørende.
Hvis de ikke identificeres og behandles inden modelbygningsfasen, kan de bringe hele ML-pipelinen og de efterfølgende analyser og konklusioner, der kan udledes af den, i fare.
Uden en automatiseret proces ville evnen til at identificere og løse disse problemer være overladt helt til den personlige erfaring og ekspertise hos den person, der udfører EDA-analysen, hvilket åbenlyst ikke er ideelt. Plus, hvilken vægt at have på sine skuldre, især i betragtning af højdimensionelle datasæt. Indgående mareridtsalarm!
Dette er en af de mest værdsatte funktioner ved ydata-profiling, automatisk generering af datakvalitetsalarmer:
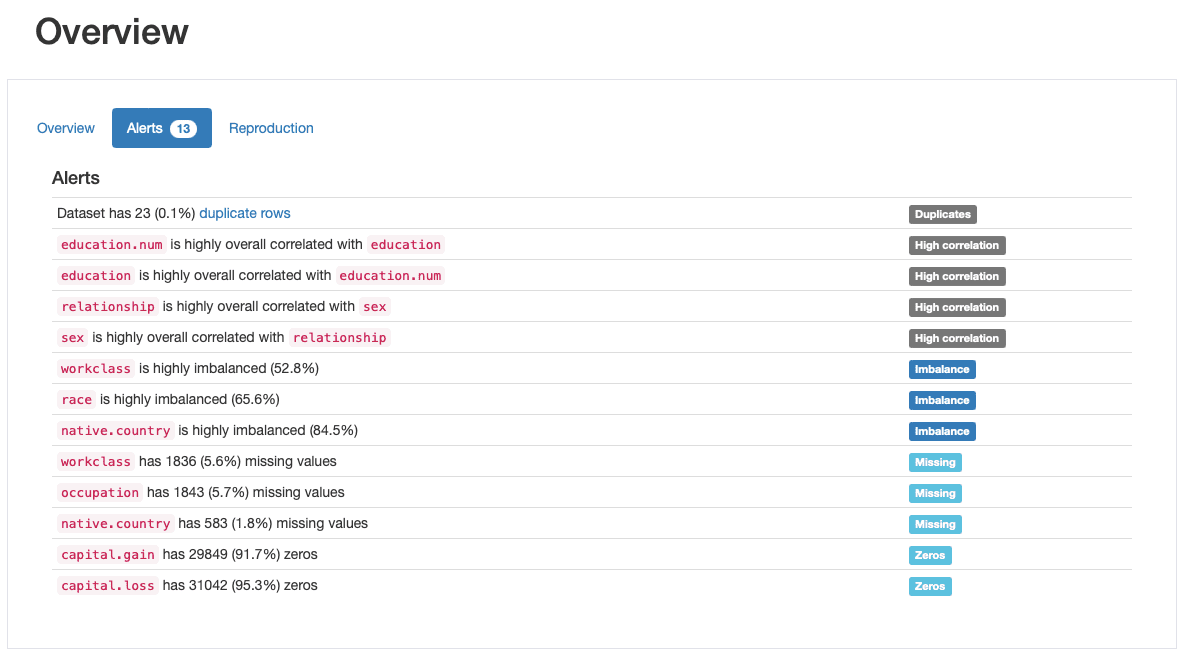
ydata-profiling: Profileringsrapport — Datakvalitetsadvarsler. Billede af forfatter.
Profilen udsender mindst 5 forskellige typer datakvalitetsproblemer, Nemlig duplicates, high correlation, imbalance, missingog zeros.
Vi havde faktisk allerede identificeret nogle af disse før, da vi gik igennem trin 2: race er en meget ubalanceret funktion og capital.gain er overvejende befolket af 0'er. Vi har også set den tætte sammenhæng mellem education , education.numog relationship , sex.
Analyse af manglende datamønstre
Blandt det omfattende omfang af advarsler, der overvejes, ydata-profiling er især nyttig i analysere manglende datamønstre.
Da manglende data er et meget almindeligt problem i domæner i den virkelige verden og kan kompromittere anvendelsen af nogle klassifikatorer helt eller alvorligt påvirke deres forudsigelser, en anden bedste praksis er omhyggeligt at analysere de manglende data procentdel og adfærd, som vores funktioner kan vise:
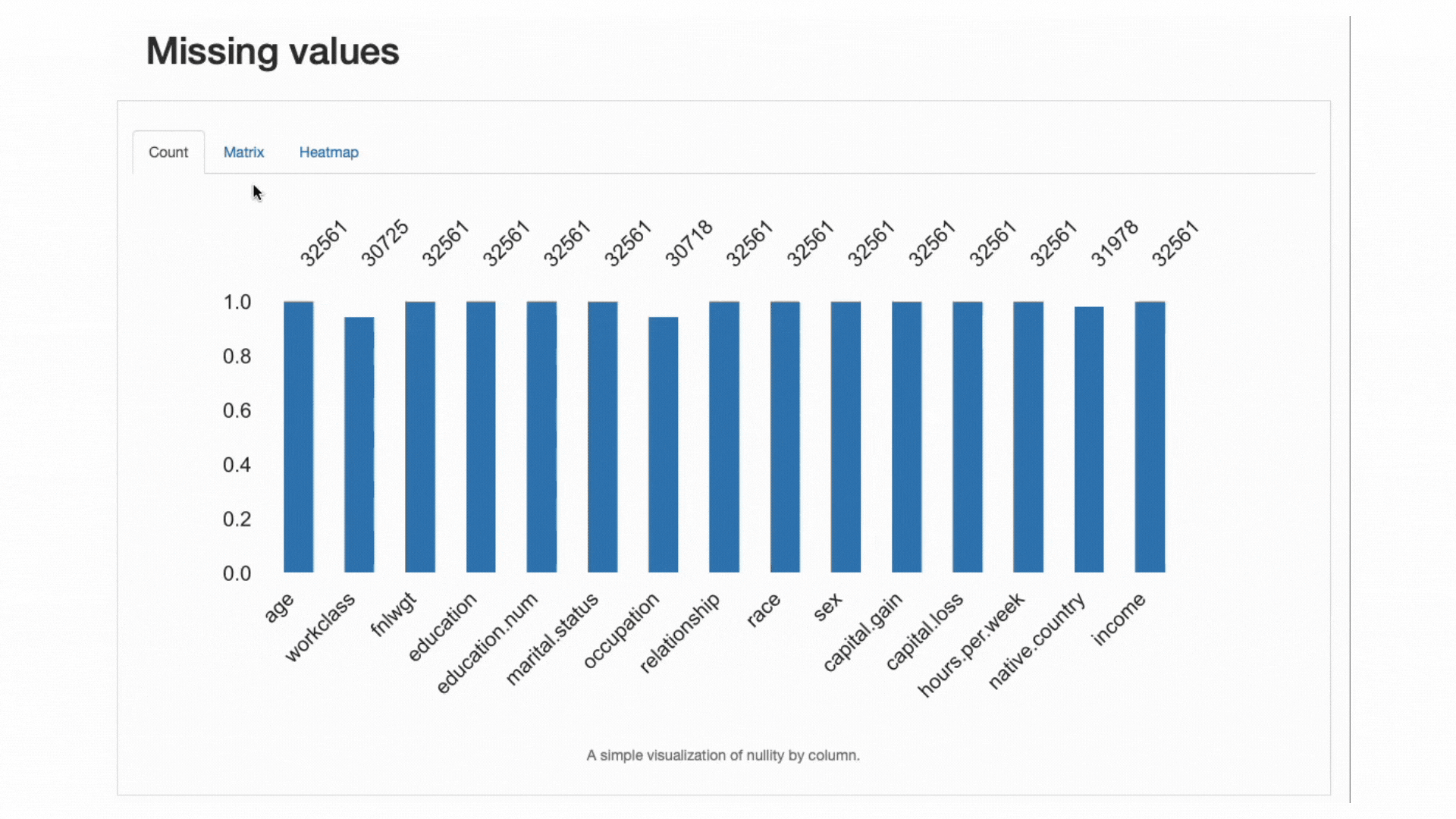
ydata-profiling: Profileringsrapport — Analyse af manglende værdier. Screencast af forfatter.
Fra afsnittet om datavarslinger vidste vi det allerede workclass, occupationog native.country havde fraværende observationer. Varmekortet fortæller os yderligere, at der er en direkte sammenhæng med det manglende mønster in occupation , workclass: når der mangler en værdi i en funktion, vil den anden også mangle.
Nøgleindsigt: Dataprofilering går ud over EDA!
Indtil videre har vi diskuteret de opgaver, der udgør en grundig EDA-proces, og hvordan vurdering af datakvalitetsspørgsmål og karakteristika — en proces, vi kan henvise til som dataprofilering - er bestemt en bedste praksis.
Det er dog vigtigt at få det afklaret dataprofilering går ud over EDA. Mens vi generelt definerer EDA som det undersøgende, interaktive trin, før vi udvikler nogen form for datapipeline, dataprofilering er en iterativ proces, der bør forekomme ved hvert trin af dataforbehandling og modelbygning.
En effektiv EDA lægger grundlaget for en vellykket maskinlæringspipeline.
Det er som at køre en diagnose på dine data, lære alt hvad du behøver at vide om, hvad det indebærer - det egenskaber, relationer, spørgsmål — så du senere kan tage fat på dem bedst muligt.
Det er også starten på vores inspirationsfase: Det er fra EDA, at spørgsmål og hypoteser begynder at opstå, og der er planlagt analyser for at validere eller afvise dem undervejs.
Igennem artiklen har vi dækket de 3 vigtigste grundlæggende trin, der vil guide dig gennem en effektiv EDA, og diskuterede virkningen af at have et førsteklasses værktøj - ydata-profiling — for at pege os i den rigtige retning, og spare os for en enorm mængde tid og mental byrde.
Jeg håber, at denne guide vil hjælpe dig med at mestre kunsten at "spille datadetektiv" og som altid er feedback, spørgsmål og forslag meget værdsat. Fortæl mig, hvilke andre emner jeg gerne vil skrive om, eller endnu bedre, kom og mød mig på Data-Centric AI Community og lad os samarbejde!
Miriam Santos fokus på at uddanne datavidenskabs- og maskinlæringsfællesskaberne i, hvordan man bevæger sig fra rå, beskidte, "dårlige" eller uperfekte data til smarte, intelligente data af høj kvalitet, hvilket gør det muligt for maskinlæringsklassifikatorer at drage nøjagtige og pålidelige slutninger på tværs af flere industrier (Fintech , Healthcare & Pharma, Telecomm og Detail).
Original. Genopslået med tilladelse.
- SEO Powered Content & PR Distribution. Bliv forstærket i dag.
- EVM Finans. Unified Interface for Decentralized Finance. Adgang her.
- Quantum Media Group. IR/PR forstærket. Adgang her.
- PlatoAiStream. Web3 Data Intelligence. Viden forstærket. Adgang her.
- Kilde: https://www.kdnuggets.com/2023/06/data-scientist-essential-guide-exploratory-data-analysis.html?utm_source=rss&utm_medium=rss&utm_campaign=a-data-scientists-essential-guide-to-exploratory-data-analysis
- :har
- :er
- :ikke
- :hvor
- $OP
- 1
- 30
- 40
- 60
- 65
- 91
- a
- evne
- Om
- over
- fraværende
- Konto
- præcis
- opnå
- tværs
- tilføjet
- Yderligere
- yderligere information
- adresse
- Tilføjer
- Justeret
- Voksen
- påvirke
- igen
- Ages
- AI
- indberetninger
- algoritme
- algoritmer
- Alle
- sammen
- allerede
- også
- Skønt
- helt
- altid
- am
- blandt
- blandt
- beløb
- an
- analyse
- analysere
- analyseret
- analysere
- ,
- enhver
- Anvendelse
- ER
- Kunst
- artikel
- AS
- Vurdering
- vurdering
- forbundet
- At
- deltage
- forfatter
- Automatiseret
- Automatisk Ur
- til rådighed
- væk
- Bad
- Bar
- BE
- været
- før
- Begyndelse
- være
- Tro
- BEDSTE
- bedste praksis
- Bedre
- mellem
- Beyond
- skævhed
- Bing
- både
- Bringer
- Bygning
- bygget
- byrde
- men
- by
- ringe
- CAN
- kapital
- omhyggeligt
- bære
- tilfælde
- kategorier
- Boligtype
- Folketælling
- karakteristika
- kontrollere
- afkrydset
- klasse
- klassificering
- klar
- kode
- samling
- farve
- kombinationer
- Kom
- Fælles
- Fællesskaber
- fuldføre
- komplekse
- omfattende
- omfatter
- kompromis
- Bekymringer
- Adfærd
- udførelse
- Konsekvenser
- betragtes
- Overvejer
- kontinuerligt
- bekvemmelighed
- Korrelation
- korrelationskoefficient
- kunne
- kritisk
- afgørende
- data
- dataanalyse
- Dataforberedelse
- datakvalitet
- datalogi
- datasæt
- beskæftiger
- beslutte
- falde
- dyb
- Standard
- definitivt
- Afhængighed
- Afhængigt
- afledte
- beskrevet
- detail
- detaljeret
- Bestem
- udvikling
- Udvikling
- afvigelse
- diagnose
- forskellige
- direkte
- retning
- direkte
- diskutere
- drøftet
- diskuterer
- Skærm
- fordeling
- do
- gør
- Domæner
- Dont
- tegne
- Drop
- i løbet af
- e
- hver
- lettere
- nemt
- uddanne
- Effektiv
- effektiv
- effektivt
- enten
- muliggør
- helt
- fejl
- især
- Essensen
- væsentlig
- Ether (ETH)
- Endog
- til sidst
- Hver
- at alt
- Undersøgelse
- eksempel
- eksisterende
- forventer
- erfaring
- ekspertise
- Udforskende dataanalyse
- udforske
- ekstra
- ekstremt
- øje
- Faktisk
- bekendt
- langt
- Feature
- Funktionalitet
- tilbagemeldinger
- Finde
- fintech
- Fornavn
- Fokus
- efter
- Til
- Tving
- format
- Foundation
- Frekvens
- fra
- funktionalitet
- fundamental
- fundamentalt
- yderligere
- fremtiden
- Gevinst
- Generelt
- generelt
- genererer
- generation
- få
- gif
- given
- Go
- Goes
- gå
- stor
- gættet
- vejlede
- havde
- hånd
- håndtere
- hænder
- Have
- have
- sundhedspleje
- stærkt
- hjælpe
- hjælpsom
- hjælper
- høj kvalitet
- Fremhæv
- stærkt
- hold
- håber
- HOURS
- Hvordan
- How To
- Men
- HTTPS
- i
- ideal
- identificeret
- identificere
- if
- billede
- straks
- KIMOs Succeshistorier
- vigtigt
- in
- medtaget
- Indkomst
- Indgående
- Forøg
- individuel
- industrier
- oplysninger
- informative
- indsigt
- indsigt
- Inspiration
- instans
- Intelligent
- hensigt
- interaktion
- interaktioner
- interaktiv
- interessant
- ind
- iboende
- undersøge
- undersøgelse
- involvere
- spørgsmål
- spørgsmål
- IT
- ITS
- true
- Job
- jpg
- lige
- KDnuggets
- Kendalls
- Kend
- Kendskab til
- kendt
- kurtosis
- etiket
- senere
- Lays
- Leads
- læring
- mindst
- til venstre
- mindre
- Licens
- lys
- ligesom
- Sandsynlig
- Line (linje)
- linjer
- lidt
- Se
- leder
- Lav
- maskine
- machine learning
- Main
- hovedsageligt
- Flertal
- lave
- Håndtering
- kort
- Master
- Matrix
- Kan..
- me
- betyde
- midler
- målt
- Mød
- mentale
- nævnte
- Metrics
- måske
- tankerne
- mangler
- ML
- tilstand
- model
- modeller
- overvågning
- mere
- mest
- bevæge sig
- meget
- Naviger
- Behov
- ingen
- Normalt
- Varsel..
- nummer
- objekt
- Obvious
- forekomme
- of
- tit
- on
- ONE
- kun
- optimal
- or
- ordrer
- Andet
- Andre
- vores
- ud
- Resultat
- output
- samlet
- oversigt
- par
- pandaer
- særlig
- forbi
- Mønster
- mønstre
- Mennesker
- procentdel
- udføre
- ydeevne
- udfører
- måske
- tilladelse
- person,
- personale
- Pharma
- fase
- pick
- pipeline
- planlagt
- plato
- Platon Data Intelligence
- PlatoData
- plausibel
- Punkt
- Pops
- befolkede
- mulig
- praksis
- praksis
- Forudsigelser
- overvejende
- forberedelse
- forelagt
- gaver
- Eksempel
- tidligere
- trykning
- Forud
- Problem
- behandle
- forarbejdning
- Profil
- profilering
- projekt
- egenskaber
- offentlige
- formål
- kvalitet
- spørgsmål
- Spørgsmål
- Løb
- rækkevidde
- Sats
- hellere
- Raw
- virkelige verden
- indse
- optegnelser
- Reduceret
- refleksion
- om
- relaterede
- forhold
- Relationer
- relativt
- pålidelig
- stole
- resterende
- fjernelse
- Fjern
- indberette
- Repository
- repræsentere
- repræsenteret
- kræver
- påkrævet
- dem
- henholdsvis
- Resultater
- detail
- højre
- Herske
- kører
- samme
- planlægge
- Videnskab
- rækkevidde
- Sektion
- sektioner
- se
- synes
- synes
- set
- følsom
- flere
- alvorligt
- Del
- Shop
- Kort
- bør
- Vis
- signifikant
- Simpelt
- ganske enkelt
- samtidigt
- enkelt
- Smart
- So
- nogle
- noget
- noget
- Spot
- Stage
- stå
- standard
- står
- starte
- Starter
- statistik
- Trin
- Steps
- ligetil
- strategier
- efterfølgende
- vellykket
- sådan
- Tag
- mål
- Opgaver
- opgaver
- fortæller
- end
- at
- oplysninger
- deres
- Them
- Der.
- derfor
- Disse
- de
- denne
- grundigt
- tænkte
- tre
- Gennem
- tid
- til
- værktøj
- top
- Emner
- mod
- traditionelt
- enorm
- virkelig
- to
- typen
- typer
- underrepræsenteret
- forståelse
- enestående
- ukendt
- indtil
- kommende
- us
- brug
- bruger
- ved brug af
- sædvanligvis
- VALIDATE
- værdi
- Værdier
- forskellige
- versus
- meget
- visualisering
- ønsker
- Vej..
- we
- uger
- vægt
- GODT
- gik
- var
- Hvad
- hvornår
- hvorvidt
- som
- Hele
- hvorfor
- Wikipedia
- vilje
- med
- uden
- ord
- Arbejde
- arbejder
- virker
- ville
- skriver
- endnu
- dig
- Din
- zephyrnet
- zoom









