দ্বারা চিত্র jcomp on Freepik
টাইম সিরিজ হল ডেটা বিজ্ঞান ক্ষেত্রের মধ্যে একটি অনন্য ডেটাসেট। ডেটা সময়-ফ্রিকোয়েন্সিতে রেকর্ড করা হয় (যেমন, দৈনিক, সাপ্তাহিক, মাসিক, ইত্যাদি), এবং প্রতিটি পর্যবেক্ষণ অন্যটির সাথে সম্পর্কিত। সময় সিরিজের ডেটা মূল্যবান যখন আপনি সময়ের সাথে আপনার ডেটার কী ঘটবে তা বিশ্লেষণ করতে চান এবং ভবিষ্যতের পূর্বাভাস তৈরি করতে চান।
টাইম সিরিজ ফোরকাস্টিং হল ঐতিহাসিক টাইম সিরিজ ডেটার উপর ভিত্তি করে ভবিষ্যত ভবিষ্যদ্বাণী তৈরি করার একটি পদ্ধতি। সময় সিরিজের পূর্বাভাসের জন্য অনেক পরিসংখ্যান পদ্ধতি আছে, যেমন আরিমা or সূচক মসৃণকরণ.
টাইম সিরিজের পূর্বাভাস প্রায়ই ব্যবসায় সম্মুখীন হয়, তাই ডেটা সায়েন্টিস্টের জন্য কীভাবে টাইম সিরিজ মডেল তৈরি করা যায় তা জানা উপকারী। এই নিবন্ধে, আমরা শিখব কিভাবে দুটি জনপ্রিয় পূর্বাভাস পাইথন প্যাকেজ ব্যবহার করে টাইম সিরিজের পূর্বাভাস দিতে হয়; পরিসংখ্যান মডেল এবং নবী। এর মধ্যে প্রবেশ করা যাক.
সার্জারির পরিসংখ্যান মডেল পাইথন প্যাকেজ হল একটি ওপেন সোর্স প্যাকেজ যা বিভিন্ন পরিসংখ্যানগত মডেল অফার করে, যার মধ্যে টাইম সিরিজের পূর্বাভাস মডেল রয়েছে। আসুন একটি উদাহরণ ডেটাসেট সহ প্যাকেজটি চেষ্টা করে দেখি। এই নিবন্ধটি ব্যবহার করবে ডিজিটাল কারেন্সি টাইম সিরিজ Kaggle থেকে ডেটা (CC0: পাবলিক ডোমেন)।
আসুন ডেটা পরিষ্কার করি এবং আমাদের কাছে থাকা ডেটাসেটটি একবার দেখে নেওয়া যাক।
import pandas as pd df = pd.read_csv('dc.csv') df = df.rename(columns = {'Unnamed: 0' : 'Time'})
df['Time'] = pd.to_datetime(df['Time'])
df = df.iloc[::-1].set_index('Time') df.head()
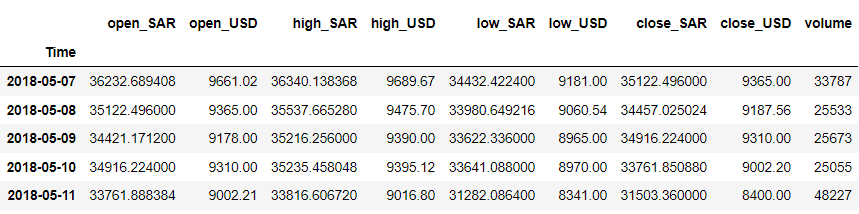
আমাদের উদাহরণের জন্য, ধরা যাক আমরা 'close_USD' ভেরিয়েবলের পূর্বাভাস দিতে চাই। চলুন দেখি কিভাবে সময়ের সাথে ডাটা প্যাটার্ন।
import matplotlib.pyplot as plt plt.plot(df['close_USD'])
plt.show()
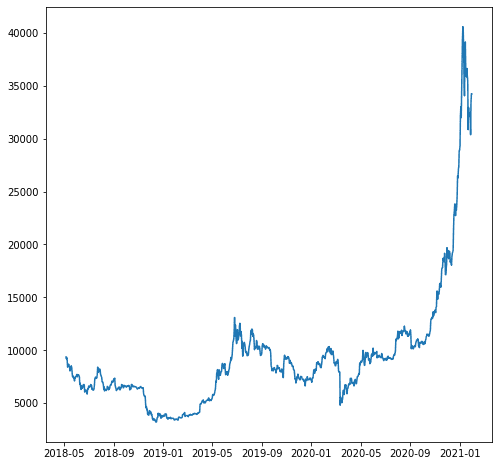
আমাদের উপরের তথ্যের উপর ভিত্তি করে পূর্বাভাস মডেল তৈরি করা যাক। মডেলিং করার আগে, আসুন ট্রেন এবং পরীক্ষার ডেটাতে ডেটা বিভক্ত করি।
# Split the data
train = df.iloc[:-200] test = df.iloc[-200:]
আমরা এলোমেলোভাবে ডেটা বিভক্ত করি না কারণ এটি সময় সিরিজের ডেটা, এবং আমাদের অর্ডারটি সংরক্ষণ করতে হবে। পরিবর্তে, আমরা আগের থেকে ট্রেনের ডেটা এবং সর্বশেষ ডেটা থেকে পরীক্ষার ডেটা রাখার চেষ্টা করি।
একটি পূর্বাভাস মডেল তৈরি করতে statsmodels ব্যবহার করা যাক। দ্য পরিসংখ্যান মডেল অনেক সময় সিরিজ মডেল API প্রদান করে, কিন্তু আমরা আমাদের উদাহরণ হিসাবে ARIMA মডেল ব্যবহার করব।
from statsmodels.tsa.arima.model import ARIMA #sample parameters
model = ARIMA(train, order=(2, 1, 0)) results = model.fit() # Make predictions for the test set
forecast = results.forecast(steps=200)
forecast
আমাদের উপরের উদাহরণে, আমরা statsmodels থেকে ARIMA মডেলটিকে পূর্বাভাস মডেল হিসাবে ব্যবহার করি এবং পরবর্তী 200 দিনের ভবিষ্যদ্বাণী করার চেষ্টা করি।
মডেল ফলাফল ভাল? আসুন তাদের মূল্যায়ন করার চেষ্টা করি। টাইম সিরিজ মডেল মূল্যায়ন সাধারণত রিগ্রেশন মেট্রিক্স যেমন গড় পরম ত্রুটি (MAE), রুট গড় স্কোয়ার ত্রুটি (RMSE), এবং MAPE (মান পরম শতাংশ ত্রুটি) এর সাথে প্রকৃত এবং ভবিষ্যদ্বাণীর তুলনা করার জন্য একটি ভিজ্যুয়ালাইজেশন গ্রাফ ব্যবহার করে।
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as np #mean absolute error
mae = mean_absolute_error(test, forecast) #root mean square error
mse = mean_squared_error(test, forecast)
rmse = np.sqrt(mse) #mean absolute percentage error
mape = (forecast - test).abs().div(test).mean() print(f"MAE: {mae:.2f}")
print(f"RMSE: {rmse:.2f}")
print(f"MAPE: {mape:.2f}%")
MAE: 7956.23 RMSE: 11705.11 MAPE: 0.35%
উপরের স্কোরটি ভাল দেখাচ্ছে, কিন্তু দেখা যাক যখন আমরা তাদের কল্পনা করি তখন এটি কেমন হয়।
plt.plot(train.index, train, label='Train')
plt.plot(test.index, test, label='Test')
plt.plot(forecast.index, forecast, label='Forecast')
plt.legend()
plt.show()
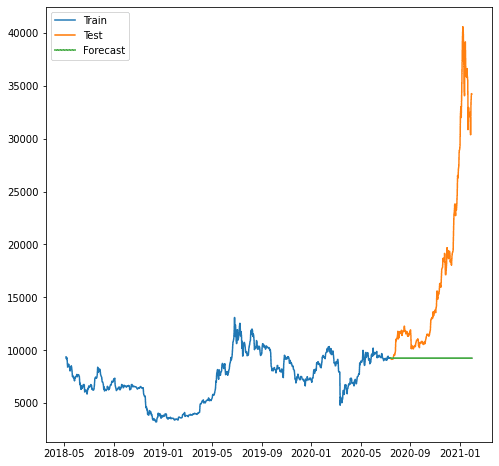
আমরা দেখতে পাচ্ছি, পূর্বাভাস আরও খারাপ ছিল কারণ আমাদের মডেল ক্রমবর্ধমান প্রবণতার পূর্বাভাস দিতে পারে না। আমরা যে মডেলটি ARIMA ব্যবহার করি তা পূর্বাভাসের জন্য খুব সহজ বলে মনে হয়।
আমরা স্ট্যাটমডেলের বাইরে অন্য মডেল ব্যবহার করার চেষ্টা করলে হয়তো ভালো হয়। চলুন ফেইসবুক থেকে বিখ্যাত নবী প্যাকেজটি ট্রাই করে দেখি।
নবী একটি টাইম সিরিজ পূর্বাভাস মডেল প্যাকেজ যা ঋতুগত প্রভাব সহ ডেটাতে সেরা কাজ করে। নবীকে একটি শক্তিশালী পূর্বাভাস মডেল হিসাবেও বিবেচনা করা হয়েছিল কারণ এটি অনুপস্থিত ডেটা এবং বহিরাগতদের পরিচালনা করতে পারে।
আসুন নবী প্যাকেজ চেষ্টা করে দেখুন. প্রথমত, আমাদের প্যাকেজটি ইনস্টল করতে হবে।
pip install prophet
এর পরে, আমাদের অবশ্যই পূর্বাভাস মডেল প্রশিক্ষণের জন্য আমাদের ডেটাসেট প্রস্তুত করতে হবে। নবীর একটি নির্দিষ্ট প্রয়োজনীয়তা রয়েছে: সময় কলামকে 'ds' এবং মানটিকে 'y' হিসাবে নামকরণ করা দরকার।
df_p = df.reset_index()[["Time", "close_USD"]].rename( columns={"Time": "ds", "close_USD": "y"}
)
আমাদের ডেটা প্রস্তুত সহ, আসুন ডেটার উপর ভিত্তি করে পূর্বাভাস পূর্বাভাস তৈরি করার চেষ্টা করি।
import pandas as pd
from prophet import Prophet model = Prophet() # Fit the model
model.fit(df_p) # create date to predict
future_dates = model.make_future_dataframe(periods=365) # Make predictions
predictions = model.predict(future_dates) predictions.head()
মহানবী সম্পর্কে যা ছিল তা হল প্রতিটি পূর্বাভাসের ডেটা পয়েন্ট আমাদের ব্যবহারকারীদের বোঝার জন্য বিস্তারিত ছিল। যাইহোক, শুধুমাত্র তথ্য থেকে ফলাফল বোঝা কঠিন। সুতরাং, আমরা নবী ব্যবহার করে তাদের কল্পনা করার চেষ্টা করতে পারি।
model.plot(predictions)
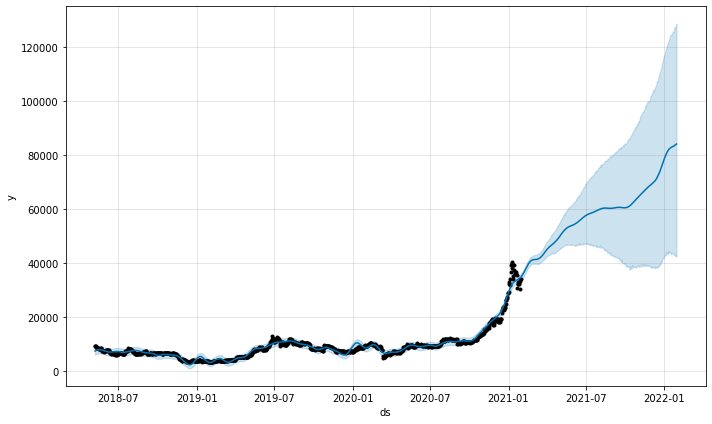
মডেল থেকে ভবিষ্যদ্বাণী প্লট ফাংশন আমাদের প্রদান করবে ভবিষ্যদ্বাণীগুলি কতটা আত্মবিশ্বাসী ছিল৷ উপরের প্লট থেকে, আমরা দেখতে পাচ্ছি যে ভবিষ্যদ্বাণীটির একটি ঊর্ধ্বমুখী প্রবণতা রয়েছে তবে বর্ধিত অনিশ্চয়তার সাথে ভবিষ্যদ্বাণীগুলি তত দীর্ঘ হবে৷
নিম্নলিখিত ফাংশন দিয়ে পূর্বাভাসের উপাদানগুলি পরীক্ষা করাও সম্ভব।
model.plot_components(predictions)
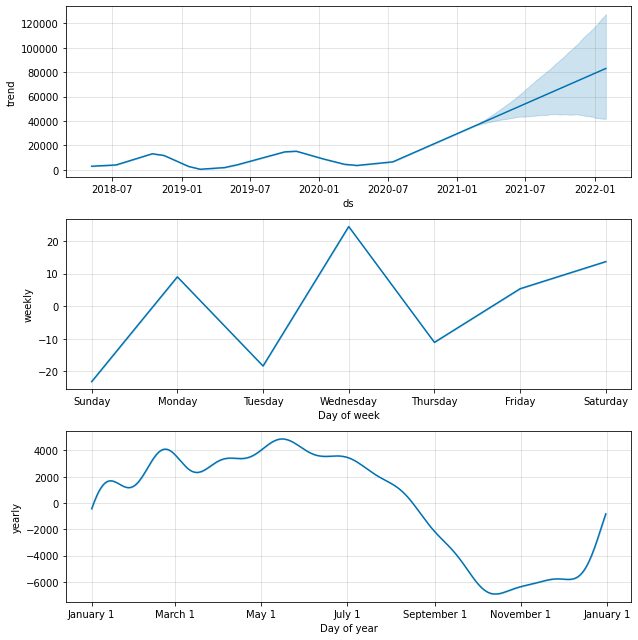
ডিফল্টরূপে, আমরা বার্ষিক এবং সাপ্তাহিক ঋতুর সাথে ডেটা প্রবণতা পেতে পারি। আমাদের ডেটার সাথে কী ঘটে তা ব্যাখ্যা করার এটি একটি ভাল উপায়।
নবী মডেলকেও কি মূল্যায়ন করা সম্ভব হবে? একেবারে। নবীর একটি ডায়গনিস্টিক পরিমাপ রয়েছে যা আমরা ব্যবহার করতে পারি: সময় সিরিজ ক্রস বৈধতা. পদ্ধতিটি ঐতিহাসিক ডেটার অংশ ব্যবহার করে এবং প্রতিবার কাটঅফ পয়েন্ট পর্যন্ত ডেটা ব্যবহার করে মডেলের সাথে ফিট করে। তখন নবীজি ভবিষ্যদ্বাণীগুলোকে প্রকৃত ভবিষ্যদ্বাণীগুলোর সাথে তুলনা করতেন। কোড ব্যবহার করে দেখুন.
from prophet.diagnostics import cross_validation, performance_metrics # Perform cross-validation with initial 365 days for the first training data and the cut-off for every 180 days. df_cv = cross_validation(model, initial='365 days', period='180 days', horizon = '365 days') # Calculate evaluation metrics
res = performance_metrics(df_cv) res
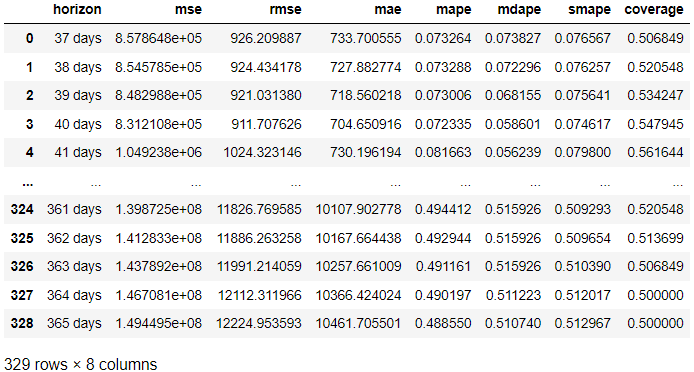
উপরের ফলাফলে, আমরা প্রতিটি পূর্বাভাসের দিনে পূর্বাভাসের তুলনায় প্রকৃত ফলাফল থেকে মূল্যায়নের ফলাফল অর্জন করেছি। নিম্নলিখিত কোড দিয়ে ফলাফলটি কল্পনা করাও সম্ভব।
from prophet.plot import plot_cross_validation_metric
#choose between 'mse', 'rmse', 'mae', 'mape', 'coverage' plot_cross_validation_metric(df_cv, metric= 'mape')
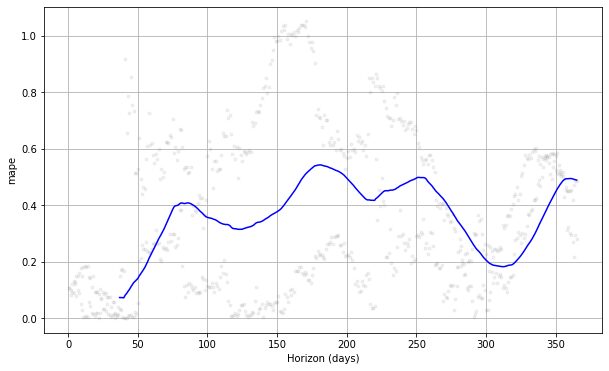
যদি আমরা উপরের প্লটটি দেখি, আমরা দেখতে পাব যে ভবিষ্যদ্বাণী ত্রুটিটি পরবর্তী দিনগুলিতে পরিবর্তিত হয়েছিল এবং এটি কিছু পয়েন্টে 50% ত্রুটি অর্জন করতে পারে। এইভাবে, আমরা ত্রুটিটি ঠিক করতে মডেলটিকে আরও পরিবর্তন করতে চাই। আপনি চেক করতে পারেন ডকুমেন্টেশন আরও অনুসন্ধানের জন্য।
পূর্বাভাস ব্যবসায় ঘটে এমন একটি সাধারণ ঘটনা। একটি পূর্বাভাস মডেল তৈরি করার একটি সহজ উপায় হল পরিসংখ্যান পূর্বাভাস এবং নবী পাইথন প্যাকেজগুলি ব্যবহার করা। এই নিবন্ধে, আমরা শিখব কিভাবে একটি পূর্বাভাস মডেল তৈরি করতে হয় এবং পরিসংখ্যান পূর্বাভাস এবং নবীর সাথে তাদের মূল্যায়ন করতে হয়।
কর্নেলিয়াস যুধা বিজয়া একজন ডেটা বিজ্ঞান সহকারী ব্যবস্থাপক এবং ডেটা লেখক। আলিয়াঞ্জ ইন্দোনেশিয়াতে পূর্ণ-সময় কাজ করার সময়, তিনি সোশ্যাল মিডিয়া এবং লেখার মাধ্যমে পাইথন এবং ডেটা টিপস শেয়ার করতে পছন্দ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://www.kdnuggets.com/2023/03/time-series-forecasting-statsmodels-prophet.html?utm_source=rss&utm_medium=rss&utm_campaign=time-series-forecasting-with-statsmodels-and-prophet
- : হয়
- $ ইউপি
- 1
- 11
- 7
- 8
- 9
- a
- সম্পর্কে
- উপরে
- পরম
- একেবারে
- অর্জন করা
- অর্জিত
- আলিয়াঞ্জ
- বিশ্লেষণ করা
- এবং
- অন্য
- API গুলি
- রয়েছি
- প্রবন্ধ
- AS
- সহায়ক
- At
- ভিত্তি
- BE
- কারণ
- আগে
- উপকারী
- সর্বোত্তম
- উত্তম
- মধ্যে
- নির্মাণ করা
- ব্যবসায়
- by
- গণনা করা
- CAN
- মামলা
- CC0
- চেক
- কোড
- স্তম্ভ
- কলাম
- সাধারণ
- তুলনা করা
- তুলনা
- উপাদান
- সুনিশ্চিত
- বিবেচিত
- পারা
- কভারেজ
- সৃষ্টি
- মুদ্রা
- দৈনিক
- উপাত্ত
- তথ্য বিজ্ঞান
- তথ্য বিজ্ঞানী
- তারিখ
- দিন
- দিন
- dc
- ডিফল্ট
- বিশদ
- বিকাশ
- ডোমেইন
- Dont
- e
- প্রতি
- পূর্বে
- প্রভাব
- ভুল
- ইত্যাদি
- মূল্যায়ন
- মূল্যায়ন
- প্রতি
- উদাহরণ
- ব্যাখ্যা করা
- অন্বেষণ
- ফেসবুক
- বিখ্যাত
- ক্ষেত্র
- জরিমানা
- প্রথম
- ফিট
- ঠিক করা
- অনুসরণ
- জন্য
- পূর্বাভাস
- থেকে
- ক্রিয়া
- অধিকতর
- ভবিষ্যৎ
- পাওয়া
- GitHub
- ভাল
- চিত্রলেখ
- মহান
- হাতল
- এরকম
- কঠিন
- আছে
- ঐতিহাসিক
- দিগন্ত
- কিভাবে
- কিভাবে
- যাহোক
- এইচটিএমএল
- HTTPS দ্বারা
- আমদানি
- in
- অন্তর্ভুক্ত
- সুদ্ধ
- বর্ধিত
- ক্রমবর্ধমান
- সূচক
- ইন্দোনেশিয়া
- প্রারম্ভিক
- ইনস্টল
- পরিবর্তে
- IT
- JPG
- কেডনুগেটস
- জানা
- সর্বশেষ
- শিখতে
- লিঙ্কডইন
- আর
- দেখুন
- সৌন্দর্য
- করা
- পরিচালক
- অনেক
- matplotlib
- মিডিয়া
- পদ্ধতি
- পদ্ধতি
- ছন্দোবিজ্ঞান
- হতে পারে
- অনুপস্থিত
- মডেল
- মূর্তিনির্মাণ
- মডেল
- মাসিক
- নামে
- প্রয়োজন
- চাহিদা
- পরবর্তী
- অসাড়
- প্রাপ্ত
- of
- নৈবেদ্য
- on
- ONE
- ওপেন সোর্স
- ক্রম
- অন্যান্য
- বাহিরে
- প্যাকেজ
- প্যাকেজ
- পান্ডাস
- পরামিতি
- অংশ
- প্যাটার্ন
- শতকরা হার
- সম্পাদন করা
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- বিন্দু
- পয়েন্ট
- জনপ্রিয়
- সম্ভব
- ভবিষ্যদ্বাণী করা
- ভবিষ্যদ্বাণী
- ভবিষ্যতবাণী
- প্রস্তুত করা
- প্রদান
- উপলব্ধ
- প্রকাশ্য
- পাইথন
- প্রস্তুত
- নথিভুক্ত
- প্রত্যাগতি
- সংশ্লিষ্ট
- প্রয়োজন
- ফল
- ফলাফল
- শক্তসমর্থ
- শিকড়
- বিজ্ঞান
- বিজ্ঞানী
- মনে হয়
- ক্রম
- সেট
- শেয়ার
- সহজ
- So
- সামাজিক
- সামাজিক মাধ্যম
- কিছু
- নির্দিষ্ট
- বিভক্ত করা
- বর্গক্ষেত্র
- পরিসংখ্যানসংক্রান্ত
- এমন
- গ্রহণ করা
- পরীক্ষা
- যে
- সার্জারির
- তাহাদিগকে
- সময়
- সময় সিরিজ
- পরামর্শ
- থেকে
- অত্যধিক
- রেলগাড়ি
- প্রশিক্ষণ
- প্রবণতা
- অনিশ্চয়তা
- বোঝা
- অনন্য
- নামহীন
- ঊর্ধ্বাভিমুখী
- us
- ব্যবহার
- ব্যবহারকারী
- সাধারণত
- দামি
- মূল্য
- বিভিন্ন
- মাধ্যমে
- কল্পনা
- উপায়..
- সাপ্তাহিক
- আমরা একটি
- কি
- যখন
- উইকিপিডিয়া
- ইচ্ছা
- সঙ্গে
- মধ্যে
- কাজ
- কাজ
- would
- লেখক
- লেখা
- আপনার
- zephyrnet