অনুরূপ কলাম খুঁজে পাওয়া a তথ্য হ্রদ একাধিক ডেটা উত্স জুড়ে ডেটা পরিষ্কার এবং টীকা, স্কিমা ম্যাচিং, ডেটা আবিষ্কার এবং বিশ্লেষণে গুরুত্বপূর্ণ অ্যাপ্লিকেশন রয়েছে। ভিন্ন উত্স থেকে সঠিকভাবে ডেটা খুঁজে বের করতে এবং বিশ্লেষণ করতে অক্ষমতা ডেটা বিজ্ঞানী, চিকিৎসা গবেষক, শিক্ষাবিদ থেকে শুরু করে আর্থিক এবং সরকারী বিশ্লেষক সকলের জন্য একটি সম্ভাব্য দক্ষতা হত্যার প্রতিনিধিত্ব করে।
প্রচলিত সমাধানগুলির মধ্যে আভিধানিক কীওয়ার্ড অনুসন্ধান বা নিয়মিত এক্সপ্রেশন ম্যাচিং জড়িত, যা ডেটা মানের সমস্যাগুলির জন্য সংবেদনশীল যেমন অনুপস্থিত কলামের নাম বা বিভিন্ন ডেটাসেট জুড়ে বিভিন্ন কলাম নামকরণের নিয়মাবলী (উদাহরণস্বরূপ, zip_code, zcode, postalcode).
এই পোস্টে, আমরা কলামের নাম, কলামের বিষয়বস্তু বা উভয়ের উপর ভিত্তি করে অনুরূপ কলামগুলি অনুসন্ধান করার জন্য একটি সমাধান প্রদর্শন করি৷ সমাধান ব্যবহার করে আনুমানিক নিকটতম প্রতিবেশী অ্যালগরিদম সহজলভ্য আমাজন ওপেন সার্চ সার্ভিস শব্দার্থগতভাবে অনুরূপ কলাম অনুসন্ধান করতে. অনুসন্ধানের সুবিধার্থে, আমরা প্রাক-প্রশিক্ষিত ট্রান্সফরমার মডেলগুলি ব্যবহার করে ডেটা লেকের পৃথক কলামগুলির জন্য বৈশিষ্ট্য উপস্থাপনা (এম্বেডিং) তৈরি করি বাক্য-ট্রান্সফরমার লাইব্রেরি in আমাজন সেজমেকার. অবশেষে, আমাদের সমাধানের সাথে ইন্টারঅ্যাক্ট করতে এবং ফলাফলগুলি কল্পনা করতে, আমরা একটি ইন্টারেক্টিভ তৈরি করি স্ট্রিমলিট ওয়েব অ্যাপ্লিকেশন চলছে AWS Fargate.
আমরা একটি অন্তর্ভুক্ত কোড টিউটোরিয়াল আপনার নমুনা ডেটা বা আপনার নিজস্ব ডেটাতে সমাধান চালানোর জন্য সংস্থানগুলি স্থাপন করার জন্য।
সমাধান ওভারভিউ
নিম্নলিখিত স্থাপত্য চিত্রটি শব্দার্থগতভাবে অনুরূপ কলামগুলি সন্ধানের জন্য দুই-পর্যায়ের কর্মপ্রবাহকে চিত্রিত করে। প্রথম পর্যায়ে একটি সঞ্চালিত হয় এডাব্লুএস স্টেপ ফাংশন ওয়ার্কফ্লো যা ট্যাবুলার কলাম থেকে এম্বেডিং তৈরি করে এবং OpenSearch Service সার্চ ইনডেক্স তৈরি করে। দ্বিতীয় পর্যায়, বা অনলাইন অনুমান পর্যায়ে, ফার্গেটের মাধ্যমে একটি স্ট্রিমলিট অ্যাপ্লিকেশন চালায়। ওয়েব অ্যাপ্লিকেশানটি ইনপুট অনুসন্ধানের প্রশ্নগুলি সংগ্রহ করে এবং ওপেনসার্চ পরিষেবা সূচী থেকে আনুমানিক কে-সবচেয়ে-সদৃশ কলামগুলি কোয়েরির সাথে পুনরুদ্ধার করে।

চিত্র 1. সমাধান আর্কিটেকচার
স্বয়ংক্রিয় কর্মপ্রবাহ নিম্নলিখিত ধাপে এগিয়ে যায়:
- ব্যবহারকারী একটি টেবুলার ডেটাসেট আপলোড করে আমাজন সিম্পল স্টোরেজ সার্ভিস (Amazon S3) বালতি, যা একটি আহ্বান করে এডাব্লুএস ল্যাম্বদা ফাংশন যা স্টেপ ফাংশন ওয়ার্কফ্লো শুরু করে।
- কর্মপ্রবাহ একটি দিয়ে শুরু হয় এডাব্লুএস আঠালো কাজ যা CSV ফাইলকে রূপান্তর করে Apache Parquet উপাত্ত বিন্যাস.
- একটি সেজমেকার প্রসেসিং কাজ প্রাক-প্রশিক্ষিত মডেল বা কাস্টম কলাম এমবেডিং মডেল ব্যবহার করে প্রতিটি কলামের জন্য এমবেডিং তৈরি করে। SageMaker প্রসেসিং কাজ Amazon S3-এ প্রতিটি টেবিলের জন্য কলাম এম্বেডিং সংরক্ষণ করে।
- একটি Lambda ফাংশন পূর্ববর্তী ধাপে উত্পাদিত কলাম এমবেডিংগুলিকে সূচী করার জন্য OpenSearch পরিষেবা ডোমেন এবং ক্লাস্টার তৈরি করে।
- অবশেষে, একটি ইন্টারেক্টিভ স্ট্রিমলিট ওয়েব অ্যাপ্লিকেশন ফার্গেটের সাথে স্থাপন করা হয়েছে। ওয়েব অ্যাপ্লিকেশানটি ব্যবহারকারীকে অনুরূপ কলামগুলির জন্য OpenSearch Service ডোমেন অনুসন্ধান করতে ইনপুট প্রশ্নগুলির জন্য একটি ইন্টারফেস প্রদান করে৷
আপনি থেকে কোড টিউটোরিয়াল ডাউনলোড করতে পারেন GitHub নমুনা ডেটা বা আপনার নিজের ডেটাতে এই সমাধানটি চেষ্টা করতে। এই টিউটোরিয়ালের জন্য প্রয়োজনীয় সংস্থানগুলি কীভাবে স্থাপন করতে হয় তার নির্দেশাবলী এখানে উপলব্ধ গিটহাব.
পূর্বশর্ত
এই সমাধান বাস্তবায়ন করতে, আপনার নিম্নলিখিত প্রয়োজন:
- An এডাব্লুএস অ্যাকাউন্ট.
- AWS পরিষেবাগুলির সাথে প্রাথমিক পরিচিতি যেমন এডাব্লুএস ক্লাউড ডেভেলপমেন্ট কিট (AWS CDK), Lambda, OpenSearch Service, এবং SageMaker প্রসেসিং।
- অনুসন্ধান সূচক তৈরি করার জন্য একটি সারণী ডেটাসেট। আপনি আপনার নিজস্ব ট্যাবুলার ডেটা আনতে পারেন বা নমুনা ডেটাসেট ডাউনলোড করতে পারেন GitHub.
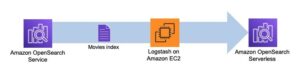
একটি অনুসন্ধান সূচক তৈরি করুন
প্রথম পর্যায়ে কলাম সার্চ ইঞ্জিন সূচক তৈরি করে। নিম্নলিখিত চিত্রটি এই ধাপে চলা স্টেপ ফাংশন ওয়ার্কফ্লোকে চিত্রিত করে।

চিত্র 2 – স্টেপ ফাংশন ওয়ার্কফ্লো – একাধিক এমবেডিং মডেল
ডেটাসেট
এই পোস্টে, আমরা 400 টিরও বেশি ট্যাবুলার ডেটাসেট থেকে 25 টিরও বেশি কলাম অন্তর্ভুক্ত করার জন্য একটি অনুসন্ধান সূচক তৈরি করি। ডেটাসেটগুলি নিম্নলিখিত পাবলিক উত্স থেকে উদ্ভূত:
সূচীতে অন্তর্ভুক্ত টেবিলের সম্পূর্ণ তালিকার জন্য, কোড টিউটোরিয়াল দেখুন GitHub.
নমুনা ডেটা বাড়াতে বা আপনার নিজস্ব অনুসন্ধান সূচক তৈরি করতে আপনি আপনার নিজস্ব ট্যাবুলার ডেটাসেট আনতে পারেন। আমরা দুটি Lambda ফাংশন অন্তর্ভুক্ত করি যা যথাক্রমে পৃথক CSV ফাইল বা CSV ফাইলের একটি ব্যাচের জন্য অনুসন্ধান সূচক তৈরি করতে ধাপ ফাংশন ওয়ার্কফ্লো শুরু করে।
CSV কে Parquet এ রূপান্তর করুন
কাঁচা CSV ফাইলগুলি AWS Glue দিয়ে Parquet ডেটা ফরম্যাটে রূপান্তরিত হয়। Parquet হল একটি কলাম-ভিত্তিক বিন্যাস ফাইল বিন্যাস যা বড় ডেটা বিশ্লেষণে পছন্দ করা হয় যা দক্ষ কম্প্রেশন এবং এনকোডিং প্রদান করে। আমাদের পরীক্ষায়, Parquet ডেটা বিন্যাস কাঁচা CSV ফাইলগুলির তুলনায় সঞ্চয়স্থানের আকারে উল্লেখযোগ্য হ্রাস প্রস্তাব করেছে৷ আমরা অন্যান্য ডেটা ফর্ম্যাটগুলি (উদাহরণস্বরূপ JSON এবং NDJSON) রূপান্তর করতে একটি সাধারণ ডেটা বিন্যাস হিসাবে Parquet ব্যবহার করেছি কারণ এটি উন্নত নেস্টেড ডেটা স্ট্রাকচার সমর্থন করে৷
ট্যাবুলার কলাম এম্বেডিং তৈরি করুন
এই পোস্টে নমুনা ট্যাবুলার ডেটাসেটে পৃথক টেবিল কলামগুলির জন্য এমবেডিংগুলি বের করতে, আমরা নিম্নলিখিত প্রাক-প্রশিক্ষিত মডেলগুলি ব্যবহার করি sentence-transformers লাইব্রেরি অতিরিক্ত মডেলের জন্য, দেখুন পূর্বপ্রশিক্ষিত মডেল.
সেজমেকার প্রসেসিং কাজ চলে create_embeddings.py(কোড) একটি একক মডেলের জন্য। একাধিক মডেল থেকে এমবেডিং বের করার জন্য, ওয়ার্কফ্লো সমান্তরাল সেজমেকার প্রসেসিং কাজ চালায় যেমন স্টেপ ফাংশন ওয়ার্কফ্লোতে দেখানো হয়েছে। এমবেডিংয়ের দুটি সেট তৈরি করতে আমরা মডেলটি ব্যবহার করি:
- কলাম_নাম_এম্বেডিং - কলামের নামের এম্বেডিং (হেডার)
- column_content_embeddings - কলামের সমস্ত সারিগুলির গড় এম্বেডিং
কলাম এমবেডিং প্রক্রিয়া সম্পর্কে আরও তথ্যের জন্য, কোড টিউটোরিয়াল দেখুন GitHub.
সেজমেকার প্রসেসিং ধাপের একটি বিকল্প হল বড় ডেটাসেটে কলাম এমবেডিং পেতে সেজমেকার ব্যাচ ট্রান্সফর্ম তৈরি করা। এর জন্য মডেলটিকে সেজমেকার এন্ডপয়েন্টে স্থাপন করা প্রয়োজন। আরও তথ্যের জন্য, দেখুন ব্যাচ ট্রান্সফর্ম ব্যবহার করুন.
OpenSearch পরিষেবার সাথে সূচী এম্বেডিং
এই পর্যায়ের চূড়ান্ত ধাপে, একটি Lambda ফাংশন একটি OpenSearch পরিষেবাতে আনুমানিক k-Nearest-Neighbour (kNN) অনুসন্ধান সূচক. প্রতিটি মডেল তার নিজস্ব অনুসন্ধান সূচক বরাদ্দ করা হয়. আনুমানিক kNN অনুসন্ধান সূচক প্যারামিটার সম্পর্কে আরও তথ্যের জন্য, দেখুন k-NN.
একটি ওয়েব অ্যাপের মাধ্যমে অনলাইন অনুমান এবং শব্দার্থিক অনুসন্ধান
কর্মপ্রবাহের দ্বিতীয় পর্যায়টি চালায় a স্ট্রিমলিট ওয়েব অ্যাপ্লিকেশন যেখানে আপনি ইনপুট প্রদান করতে পারেন এবং ওপেন সার্চ সার্ভিসে সূচীকৃত শব্দার্থগতভাবে অনুরূপ কলামগুলি অনুসন্ধান করতে পারেন। অ্যাপ্লিকেশন স্তর একটি ব্যবহার করে অ্যাপ্লিকেশন লোড ব্যালেন্সার, Fargate, এবং Lambda. সমাধানের অংশ হিসাবে অ্যাপ্লিকেশন পরিকাঠামো স্বয়ংক্রিয়ভাবে স্থাপন করা হয়।
অ্যাপ্লিকেশনটি আপনাকে একটি ইনপুট প্রদান করতে এবং শব্দার্থগতভাবে অনুরূপ কলামের নাম, কলাম সামগ্রী বা উভয়ের জন্য অনুসন্ধান করতে দেয়। অতিরিক্তভাবে, আপনি অনুসন্ধান থেকে ফিরে আসার জন্য এমবেডিং মডেল এবং নিকটতম প্রতিবেশীদের সংখ্যা নির্বাচন করতে পারেন। অ্যাপ্লিকেশন ইনপুট গ্রহণ করে, নির্দিষ্ট মডেলের সাথে ইনপুট এম্বেড করে এবং ব্যবহার করে OpenSearch Service-এ kNN অনুসন্ধান করুন সূচীকৃত কলাম এমবেডিং অনুসন্ধান করতে এবং প্রদত্ত ইনপুটের সাথে সর্বাধিক অনুরূপ কলামগুলি সন্ধান করতে। প্রদর্শিত অনুসন্ধান ফলাফলের মধ্যে রয়েছে টেবিলের নাম, কলামের নাম এবং চিহ্নিত কলামগুলির জন্য সাদৃশ্য স্কোর, সেইসাথে আরও অন্বেষণের জন্য Amazon S3-এ ডেটার অবস্থান।
নিম্নলিখিত চিত্রটি ওয়েব অ্যাপ্লিকেশনের একটি উদাহরণ দেখায়। এই উদাহরণে, আমরা আমাদের ডেটা লেকের কলামগুলির জন্য অনুসন্ধান করেছি যেগুলির অনুরূপ রয়েছে৷ Column Names (পেলোড প্রকার) থেকে district (পে লোড) ব্যবহৃত অ্যাপ্লিকেশন all-MiniLM-L6-v2 যেমন এমবেডিং মডেল এবং ফিরে 10 (k) আমাদের ওপেন সার্চ সার্ভিস সূচক থেকে নিকটতম প্রতিবেশী।
আবেদন ফিরে transit_district, city, borough, এবং location ওপেনসার্চ সার্ভিসে ইনডেক্স করা ডেটার উপর ভিত্তি করে চারটি সবচেয়ে অনুরূপ কলাম হিসেবে। এই উদাহরণটি ডেটাসেট জুড়ে শব্দার্থগতভাবে অনুরূপ কলাম সনাক্ত করতে অনুসন্ধান পদ্ধতির ক্ষমতা প্রদর্শন করে।

চিত্র 3: ওয়েব অ্যাপ্লিকেশন ব্যবহারকারী ইন্টারফেস
পরিষ্কার কর
এই টিউটোরিয়ালে AWS CDK দ্বারা তৈরি সংস্থানগুলি মুছতে, নিম্নলিখিত কমান্ডটি চালান:
cdk destroy --allউপসংহার
এই পোস্টে, আমরা ট্যাবুলার কলামগুলির জন্য একটি শব্দার্থিক অনুসন্ধান ইঞ্জিন তৈরির জন্য একটি এন্ড-টু-এন্ড ওয়ার্কফ্লো উপস্থাপন করেছি।
আমাদের কোড টিউটোরিয়াল উপলব্ধ সহ আপনার নিজের ডেটাতে আজই শুরু করুন GitHub. আপনি যদি আপনার পণ্য এবং প্রক্রিয়াগুলিতে আপনার ML-এর ব্যবহার ত্বরান্বিত করতে সহায়তা চান তবে অনুগ্রহ করে যোগাযোগ করুন আমাজন মেশিন লার্নিং সলিউশন ল্যাব.
লেখক সম্পর্কে
![]() কাচি ওডোমেন AWS AI এর একজন ফলিত বিজ্ঞানী। তিনি AWS গ্রাহকদের ব্যবসায়িক সমস্যা সমাধানের জন্য AI/ML সমাধান তৈরি করেন।
কাচি ওডোমেন AWS AI এর একজন ফলিত বিজ্ঞানী। তিনি AWS গ্রাহকদের ব্যবসায়িক সমস্যা সমাধানের জন্য AI/ML সমাধান তৈরি করেন।
![]() টেলর ম্যাকনালি অ্যামাজন মেশিন লার্নিং সলিউশন ল্যাবের একজন ডিপ লার্নিং আর্কিটেক্ট। তিনি বিভিন্ন শিল্পের গ্রাহকদের AWS-এ AI/ML ব্যবহার করে সমাধান তৈরি করতে সাহায্য করেন। তিনি একটি ভাল কাপ কফি, বাইরে, এবং তার পরিবার এবং উদ্যমী কুকুরের সাথে সময় উপভোগ করেন।
টেলর ম্যাকনালি অ্যামাজন মেশিন লার্নিং সলিউশন ল্যাবের একজন ডিপ লার্নিং আর্কিটেক্ট। তিনি বিভিন্ন শিল্পের গ্রাহকদের AWS-এ AI/ML ব্যবহার করে সমাধান তৈরি করতে সাহায্য করেন। তিনি একটি ভাল কাপ কফি, বাইরে, এবং তার পরিবার এবং উদ্যমী কুকুরের সাথে সময় উপভোগ করেন।
![]() অস্টিন ওয়েলচ অ্যামাজন এমএল সলিউশন ল্যাবে একজন ডেটা সায়েন্টিস্ট। AWS পাবলিক সেক্টরের গ্রাহকদের তাদের AI এবং ক্লাউড গ্রহণকে ত্বরান্বিত করতে সাহায্য করার জন্য তিনি কাস্টম ডিপ লার্নিং মডেল তৈরি করেন। অবসর সময়ে, তিনি পড়া, ভ্রমণ এবং জিউ-জিতসু উপভোগ করেন।
অস্টিন ওয়েলচ অ্যামাজন এমএল সলিউশন ল্যাবে একজন ডেটা সায়েন্টিস্ট। AWS পাবলিক সেক্টরের গ্রাহকদের তাদের AI এবং ক্লাউড গ্রহণকে ত্বরান্বিত করতে সাহায্য করার জন্য তিনি কাস্টম ডিপ লার্নিং মডেল তৈরি করেন। অবসর সময়ে, তিনি পড়া, ভ্রমণ এবং জিউ-জিতসু উপভোগ করেন।
- এসইও চালিত বিষয়বস্তু এবং পিআর বিতরণ। আজই পরিবর্ধিত পান।
- প্লেটোব্লকচেন। Web3 মেটাভার্স ইন্টেলিজেন্স। জ্ঞান প্রসারিত. এখানে প্রবেশ করুন.
- উত্স: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- ক্ষমতা
- সম্পর্কে
- অনুপস্থিত
- দ্রুততর করা
- ত্বরক
- সঠিক
- দিয়ে
- অতিরিক্ত
- উপরন্তু
- যোগ করে
- গ্রহণ
- অগ্রসর
- AI
- এআই / এমএল
- সব
- অনুমতি
- বিকল্প
- মর্দানী স্ত্রীলোক
- অ্যামাজন মেশিন লার্নিং
- অ্যামাজন এমএল সলিউশন ল্যাব
- বিশ্লেষকরা
- বৈশ্লেষিক ন্যায়
- বিশ্লেষণ করা
- এবং
- এ্যাপাচি
- আবেদন
- অ্যাপ্লিকেশন
- ফলিত
- অভিগমন
- স্থাপত্য
- নির্ধারিত
- অটোমেটেড
- স্বয়ংক্রিয়ভাবে
- সহজলভ্য
- গড়
- ডেস্কটপ AWS
- এডাব্লুএস আঠালো
- ভিত্তি
- কারণ
- বিশাল
- বড় ডেটা
- আনা
- নির্মাণ করা
- ভবন
- তৈরী করে
- ব্যবসায়
- পরিস্কার করা
- মেঘ
- মেঘ গ্রহণ
- গুচ্ছ
- কোড
- কফি
- সংগ্রহ
- স্তম্ভ
- কলাম
- সাধারণ
- তুলনা
- যোগাযোগ
- বিষয়বস্তু
- কনভেনশন
- রূপান্তর
- ধর্মান্তরিত
- সৃষ্টি
- নির্মিত
- সৃষ্টি
- কাপ
- প্রথা
- গ্রাহকদের
- উপাত্ত
- ডেটা বিশ্লেষণ
- ডেটা লেক
- উপাত্ত গুণমান
- তথ্য বিজ্ঞানী
- ডেটাসেট
- গভীর
- গভীর জ্ঞানার্জন
- প্রদর্শন
- প্রমান
- স্থাপন
- মোতায়েন
- মোতায়েন
- ধ্বংস
- উন্নয়ন
- বিকাশ
- বিভিন্ন
- আবিষ্কার
- অসম
- বিচিত্র
- কুকুর
- ডোমেইন
- ডাউনলোড
- প্রতি
- দক্ষতা
- দক্ষ
- সর্বশেষ সীমা
- শেষপ্রান্ত
- ইঞ্জিন
- থার (eth)
- সবাই
- উদাহরণ
- অন্বেষণ
- নির্যাস
- সহজতর করা
- ঘনিষ্ঠতা
- পরিবার
- বৈশিষ্ট্য
- ব্যক্তিত্ব
- ফাইল
- নথি পত্র
- চূড়ান্ত
- পরিশেষে
- আর্থিক
- আবিষ্কার
- আবিষ্কার
- প্রথম
- অনুসরণ
- বিন্যাস
- থেকে
- সম্পূর্ণ
- ক্রিয়া
- ক্রিয়াকলাপ
- অধিকতর
- পাওয়া
- প্রদত্ত
- ভাল
- সরকার
- হেডার
- সাহায্য
- সাহায্য
- কিভাবে
- কিভাবে
- এইচটিএমএল
- HTTPS দ্বারা
- চিহ্নিত
- সনাক্ত করা
- বাস্তবায়ন
- গুরুত্বপূর্ণ
- in
- অক্ষমতা
- অন্তর্ভুক্ত করা
- অন্তর্ভুক্ত
- সূচক
- স্বতন্ত্র
- শিল্প
- তথ্য
- পরিকাঠামো
- আরম্ভ করা
- initiates
- ইনপুট
- নির্দেশাবলী
- গর্ভনাটিকা
- ইন্টারেক্টিভ
- ইন্টারফেস
- পূজা
- জড়িত করা
- সমস্যা
- IT
- কাজ
- জবস
- JSON
- গবেষণাগার
- হ্রদ
- বড়
- স্তর
- শিক্ষা
- উপজীব্য
- লাইব্রেরি
- তালিকা
- বোঝা
- অবস্থানগুলি
- মেশিন
- মেশিন লার্নিং
- ম্যাচিং
- চিকিৎসা
- ML
- মডেল
- মডেল
- অধিক
- সেতু
- বহু
- নাম
- নাম
- নামকরণ
- প্রয়োজন
- প্রতিবেশী
- সংখ্যা
- প্রদত্ত
- অনলাইন
- অন্যান্য
- বিদেশে
- নিজের
- সমান্তরাল
- পরামিতি
- অংশ
- Plato
- প্লেটো ডেটা ইন্টেলিজেন্স
- প্লেটোডাটা
- দয়া করে
- পোস্ট
- সম্ভাব্য
- পছন্দের
- উপস্থাপন
- আগে
- সমস্যা
- আয়
- প্রক্রিয়া
- প্রসেস
- প্রক্রিয়াজাতকরণ
- প্রযোজনা
- পণ্য
- প্রদান
- উপলব্ধ
- প্রকাশ্য
- গুণ
- কাঁচা
- পড়া
- পায়
- নিয়মিত
- প্রতিনিধিত্ব করে
- প্রয়োজন
- প্রয়োজনীয়
- গবেষকরা
- Resources
- যথাক্রমে
- ফলাফল
- প্রত্যাবর্তন
- চালান
- দৌড়
- ঋষি নির্মাতা
- বিজ্ঞানী
- বিজ্ঞানীরা
- সার্চ
- খোঁজ যন্ত্র
- অনুসন্ধানের
- দ্বিতীয়
- সেক্টর
- সেবা
- সেবা
- সেট
- প্রদর্শিত
- শো
- গুরুত্বপূর্ণ
- অনুরূপ
- সহজ
- একক
- আয়তন
- সমাধান
- সলিউশন
- সমাধান
- সোর্স
- নিদিষ্ট
- পর্যায়
- শুরু
- ধাপ
- প্রারম্ভিক ব্যবহারের নির্দেশাবলী
- স্টোরেজ
- এমন
- সমর্থন
- কার্যক্ষম
- টেবিল
- সার্জারির
- তাদের
- দ্বারা
- সময়
- থেকে
- আজ
- রুপান্তর
- ট্রান্সফরমার
- ভ্রমণ
- অভিভাবকসংবঁধীয়
- ব্যবহার
- ব্যবহারকারী
- ব্যবহারকারী ইন্টারফেস
- বিভিন্ন
- ওয়েব
- ওয়েব অ্যাপ্লিকেশন
- যে
- কর্মপ্রবাহ
- would
- আপনার
- zephyrnet