আপনার ডাটা সায়েন্স পাইপলাইন অপটিমাইজ করার জন্য 15 পাইথন স্নিপেট
আপনার ডেটা বিজ্ঞান চক্রকে সাহায্য করার জন্য দ্রুত পাইথন সমাধান।
By লুকাস সোয়ারেস, K1 ডিজিটালে মেশিন লার্নিং ইঞ্জিনিয়ার

দ্বারা ফোটো কার্লোস মুজা on Unsplash
ডেটা বিজ্ঞানের জন্য স্নিপেটগুলি কেন গুরুত্বপূর্ণ
আমার দৈনন্দিন রুটিনে আমাকে csv ফাইল লোড করা থেকে শুরু করে ডেটা ভিজ্যুয়ালাইজ করা পর্যন্ত অনেকগুলি একই পরিস্থিতি মোকাবেলা করতে হবে। সুতরাং, আমার প্রক্রিয়াটিকে স্ট্রিমলাইন করতে সাহায্য করার জন্য আমি কোডের স্নিপেটগুলি সংরক্ষণ করার অভ্যাস তৈরি করেছি যা csv ফাইলগুলি লোড করা থেকে ডেটা ভিজ্যুয়ালাইজ করা পর্যন্ত বিভিন্ন পরিস্থিতিতে সহায়ক।
এই পোস্টে আমি আপনার ডেটা বিশ্লেষণ পাইপলাইনের বিভিন্ন দিকগুলিতে সহায়তা করার জন্য কোডের 15 স্নিপেট শেয়ার করব
1. গ্লোব এবং তালিকা বোঝার সাথে একাধিক ফাইল লোড করা হচ্ছে
import glob
import pandas as pd
csv_files = glob.glob("path/to/folder/with/csvs/*.csv")
dfs = [pd.read_csv(filename) for filename in csv_files]2. একটি কলাম টেবিল থেকে অনন্য মান পাওয়া
import pandas as pd
df = pd.read_csv("path/to/csv/file.csv")
df["Item_Identifier"].unique()array(['FDA15', 'DRC01', 'FDN15', ..., 'NCF55', 'NCW30', 'NCW05'], dtype=object)3. পান্ডা ডেটাফ্রেমগুলি পাশাপাশি প্রদর্শন করুন
from IPython.display import display_html
from itertools import chain,cycledef display_side_by_side(*args,titles=cycle([''])): # source: https://stackoverflow.com/questions/38783027/jupyter-notebook-display-two-pandas-tables-side-by-side html_str='' for df,title in zip(args, chain(titles,cycle(['</br>'])) ): html_str+='<th style="text-align:center"><td style="vertical-align:top">' html_str+="<br>" html_str+=f'<h2>{title}</h2>' html_str+=df.to_html().replace('table','table style="display:inline"') html_str+='</td></th>' display_html(html_str,raw=True)
df1 = pd.read_csv("file.csv")
df2 = pd.read_csv("file2")
display_side_by_side(df1.head(),df2.head(), titles=['Sales','Advertising'])
### Output
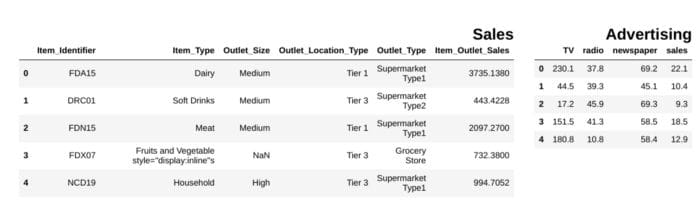
লেখকের ছবি
4. পান্ডাস ডেটাফ্রেমের সমস্ত NaN সরান৷
df = pd.DataFrame(dict(a=[1,2,3,None]))
df
df.dropna(inplace=True)
df

5. DataFrame কলামে NaN এন্ট্রির সংখ্যা দেখান
def findNaNCols(df): for col in df: print(f"Column: {col}") num_NaNs = df[col].isnull().sum() print(f"Number of NaNs: {num_NaNs}")
df = pd.DataFrame(dict(a=[1,2,3,None],b=[None,None,5,6]))
findNaNCols(df)# OutputColumn: a
Number of NaNs: 1
Column: b
Number of NaNs: 26. সঙ্গে কলাম রূপান্তর .apply এবং ল্যাম্বডা ফাংশন
df = pd.DataFrame(dict(a=[10,20,30,40,50]))
square = lambda x: x**2
df["a"]=df["a"].apply(square)
df

7. 2টি ডেটাফ্রেম কলামকে একটি অভিধানে রূপান্তর করা হচ্ছে
df = pd.DataFrame(dict(a=["a","b","c"],b=[1,2,3]))
df_dictionary = dict(zip(df["a"],df["b"]))
df_dictionary{'a': 1, 'b': 2, 'c': 3}8. কলামে শর্তসাপেক্ষে ডিস্ট্রিবিউশনের প্লট করা গ্রিড
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
import pandas as pd df = pd.DataFrame(dict(a=np.random.randint(0,100,100),b=np.arange(0,100,1)))
plt.figure(figsize=(15,7))
plt.subplot(1,2,1)
df["b"][df["a"]>50].hist(color="green",label="bigger than 50")
plt.legend()
plt.subplot(1,2,2)
df["b"][df["a"]<50].hist(color="orange",label="smaller than 50")
plt.legend()
plt.show()
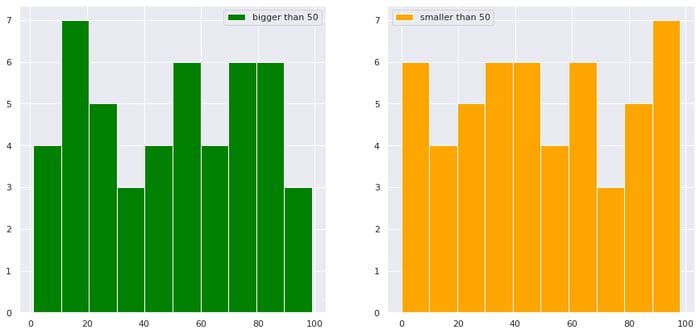
লেখকের ছবি
9. পান্ডায় বিভিন্ন কলামের মানের জন্য টি-পরীক্ষা চালানো হচ্ছে
from scipy.stats import ttest_rel data = np.arange(0,1000,1)
data_plus_noise = np.arange(0,1000,1) + np.random.normal(0,1,1000)
df = pd.DataFrame(dict(data=data, data_plus_noise=data_plus_noise))
print(ttest_rel(df["data"],df["data_plus_noise"]))# Output
Ttest_relResult(statistic=-1.2717454718006775, pvalue=0.20375954602300195)10. একটি প্রদত্ত কলামে ডেটাফ্রেম মার্জ করা
df1 = pd.DataFrame(dict(a=[1,2,3],b=[10,20,30],col_to_merge=["a","b","c"]))
df2 = pd.DataFrame(dict(d=[10,20,100],col_to_merge=["a","b","c"]))
df_merged = df1.merge(df2, on='col_to_merge')
df_merged

11. sklearn সহ একটি পান্ডাস কলামে মান স্বাভাবিক করা
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scores = scaler.fit_transform(df["a"].values.reshape(-1,1))12. পান্ডায় একটি নির্দিষ্ট কলামে NaN ড্রপ করা
df.dropna(subset=["col_to_remove_NaNs_from"],inplace=True)13. শর্তাবলী সহ একটি ডেটাফ্রেমের উপসেট নির্বাচন করা এবং or বিবৃতি
df = pd.DataFrame(dict(result=["Pass","Fail","Pass","Fail","Distinction","Distinction"]))
pass_index = (df["result"]=="Pass") | (df["result"]=="Distinction")
df_pass = df[pass_index]
df_pass

14. মৌলিক পাই চার্ট
import matplotlib.pyplot as plt df = pd.DataFrame(dict(a=[10,20,50,10,10],b=["A","B","C","D","E"]))
labels = df["b"]
sizes = df["a"]
plt.pie(sizes, labels=labels, autopct='%1.1f%%', shadow=True, startangle=140)
plt.axis('equal')
plt.show()

15. ব্যবহার করে একটি সংখ্যাসূচক মান একটি শতাংশ স্ট্রিং পরিবর্তন .apply()
def change_to_numerical(x): try: x = int(x.strip("%")[:2]) except: x = int(x.strip("%")[:1]) return x df = pd.DataFrame(dict(a=["A","B","C"],col_with_percentage=["10%","70%","20%"]))
df["col_with_percentage"] = df["col_with_percentage"].apply(change_to_numerical)
df

উপসংহার
আমি মনে করি কোডের স্নিপেটগুলি অত্যন্ত মূল্যবান, কোড পুনর্লিখন করা সময়ের অপচয় হতে পারে তাই আপনার ডেটা বিশ্লেষণ প্রক্রিয়াকে স্ট্রিমলাইন করার জন্য প্রয়োজনীয় সমস্ত সহজ সমাধানগুলির সাথে একটি সম্পূর্ণ টুলকিট থাকা অনেক সহায়ক হতে পারে।
আপনি যদি এই পোস্টটি পছন্দ করেন তবে আমার সাথে যোগাযোগ করুন Twitter, লিঙ্কডইন এবং আমাকে অনুসরণ করুন মধ্যম. ধন্যবাদ এবং পরের বার দেখা হবে! 🙂
এ আরো কন্টেন্ট plaineenglish.io
বায়ো: লুকাস সোয়ারেস একজন এআই প্রকৌশলী হচ্ছেন বিস্তৃত সমস্যার জন্য গভীর শিক্ষার অ্যাপ্লিকেশনে কাজ করছেন।
মূল। অনুমতি নিয়ে পোস্ট করা।
সম্পর্কিত:
সূত্র: https://www.kdnuggets.com/2021/08/15-python-snippets-optimize-data-science-pipeline.html
- '
- "
- &
- 100
- 7
- বিজ্ঞাপন
- AI
- সব
- বিশ্লেষণ
- আবেদন
- অ্যাপ্লিকেশন
- গাড়ী
- ডেস্কটপ AWS
- কোড
- স্তম্ভ
- সাধারণ
- বিষয়বস্তু
- উপাত্ত
- তথ্য বিশ্লেষণ
- তথ্য বিজ্ঞান
- লেনদেন
- গভীর জ্ঞানার্জন
- Director
- প্রকৌশলী
- বৈশিষ্ট্য
- প্রথম
- অনুসরণ করা
- জিপিইউ
- মহান
- Green
- গ্রিড
- কিভাবে
- কিভাবে
- HTTPS দ্বারা
- সাক্ষাত্কার
- লেবেলগুলি
- শিখতে
- শিক্ষা
- লিঙ্কডইন
- তালিকা
- মেশিন লার্নিং
- মধ্যম
- ML
- নিউরাল
- খোলা
- ওপেন সোর্স
- পাইথন
- পরিসর
- কারণে
- প্রত্যাগতি
- দৌড়
- বিক্রয়
- বিজ্ঞান
- বিজ্ঞানীরা
- শেয়ার
- সহজ
- So
- সলিউশন
- বর্গক্ষেত্র
- পরিসংখ্যান
- খবর
- TD
- পরীক্ষামূলক
- সময়
- শীর্ষ
- রূপান্তর
- মূল্য
- X