في السنوات القليلة الماضية، برزت نماذج اللغات الكبيرة (LLMs) كأدوات متميزة قادرة على فهم النص وتوليده ومعالجته بكفاءة غير مسبوقة. وتمتد تطبيقاتها المحتملة من وكلاء المحادثة إلى إنشاء المحتوى واسترجاع المعلومات، مما يحمل وعدًا بإحداث ثورة في جميع الصناعات. ومع ذلك، فإن تسخير هذه الإمكانات مع ضمان الاستخدام المسؤول والفعال لهذه النماذج يتوقف على العملية الحاسمة لتقييم LLM. التقييم هو مهمة تستخدم لقياس جودة ومسؤولية مخرجات LLM أو خدمة الذكاء الاصطناعي التوليدية. لا يكون الدافع وراء تقييم LLMs هو الرغبة في فهم أداء النموذج فحسب، بل أيضًا الحاجة إلى تنفيذ الذكاء الاصطناعي المسؤول والحاجة إلى التخفيف من مخاطر تقديم معلومات مضللة أو محتوى متحيز وتقليل توليد محتوى ضار وغير آمن وضار وغير أخلاقي. محتوى. علاوة على ذلك، يمكن أن يساعد تقييم LLMs أيضًا في تخفيف المخاطر الأمنية، خاصة في سياق التلاعب الفوري بالبيانات. بالنسبة للتطبيقات المستندة إلى LLM، من الضروري تحديد نقاط الضعف وتنفيذ الضمانات التي تحمي من الانتهاكات المحتملة والتلاعب غير المصرح به بالبيانات.
من خلال توفير الأدوات الأساسية لتقييم LLMs من خلال تكوين مباشر ونهج بنقرة واحدة، توضيح Amazon SageMaker تتيح قدرات تقييم LLM للعملاء الوصول إلى معظم المزايا المذكورة أعلاه. مع وجود هذه الأدوات في متناول اليد، فإن التحدي التالي هو دمج تقييم LLM في دورة حياة التعلم الآلي والتشغيل (MLOps) لتحقيق الأتمتة وقابلية التوسع في العملية. في هذا المنشور، نعرض لك كيفية دمج تقييم Amazon SageMaker Clarify LLM مع Amazon SageMaker Pipelines لتمكين تقييم LLM على نطاق واسع. بالإضافة إلى ذلك، نقدم مثال التعليمات البرمجية في هذا GitHub جيثب: مستودع لتمكين المستخدمين من إجراء تقييم متوازي متعدد النماذج على نطاق واسع، باستخدام أمثلة مثل Llama2-7b-f، وFalcon-7b، ونماذج Llama2-7b المضبوطة بدقة.
من يحتاج إلى إجراء تقييم LLM؟
يحتاج أي شخص يقوم بالتدريب أو الضبط الدقيق أو ببساطة استخدام LLM مُدرب مسبقًا إلى تقييمه بدقة لتقييم سلوك التطبيق المدعوم من LLM هذا. بناءً على هذا المبدأ، يمكننا تصنيف مستخدمي الذكاء الاصطناعي المبدعين الذين يحتاجون إلى قدرات تقييم LLM إلى 3 مجموعات كما هو موضح في الشكل التالي: مقدمو النماذج، والمضبطون الدقيقون، والمستهلكون.
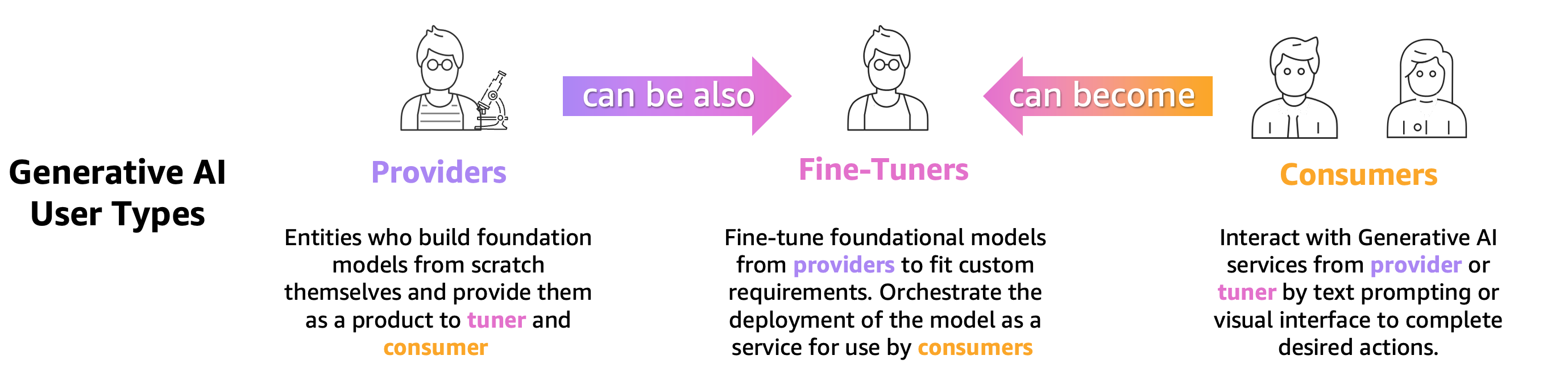
- مقدمو النموذج التأسيسي (FM). نماذج القطارات ذات الأغراض العامة. يمكن استخدام هذه النماذج في العديد من المهام النهائية، مثل استخراج الميزات أو إنشاء المحتوى. يحتاج كل نموذج مُدرب إلى مقارنته بالعديد من المهام، ليس فقط لتقييم أدائه ولكن أيضًا لمقارنته بالنماذج الأخرى الموجودة، لتحديد المجالات التي تحتاج إلى تحسينات، وأخيرًا، لتتبع التطورات في هذا المجال. يحتاج موفرو النماذج أيضًا إلى التحقق من وجود أي تحيزات لضمان جودة مجموعة البيانات الأولية والسلوك الصحيح لنموذجهم. يعد جمع بيانات التقييم أمرًا حيويًا لمقدمي النماذج. علاوة على ذلك، يجب جمع هذه البيانات والمقاييس للامتثال للوائح القادمة. إعتماد ISO-42001أطلقت حملة الأمر التنفيذي لإدارة بايدنو قانون الاتحاد الأوروبي للذكاء الاصطناعي تطوير المعايير والأدوات والاختبارات للمساعدة في ضمان أن أنظمة الذكاء الاصطناعي آمنة ومأمونة وجديرة بالثقة. على سبيل المثال، تم تكليف قانون الاتحاد الأوروبي للذكاء الاصطناعي بتوفير معلومات حول مجموعات البيانات المستخدمة للتدريب، وما هي القوة الحاسوبية المطلوبة لتشغيل النموذج، والإبلاغ عن نتائج النموذج مقابل المعايير العامة/معايير الصناعة ومشاركة نتائج الاختبارات الداخلية والخارجية.
- الموديل ضبط دقيق يريدون حل مهام محددة (مثل تصنيف المشاعر والتلخيص والإجابة على الأسئلة) بالإضافة إلى النماذج المدربة مسبقًا لتبني مهام محددة في المجال. إنهم بحاجة إلى مقاييس التقييم التي أنشأها موفرو النماذج لاختيار النموذج المناسب المُدرب مسبقًا كنقطة بداية.
إنهم بحاجة إلى تقييم نماذجهم المضبوطة بدقة مقابل حالة الاستخدام المرغوبة من خلال مجموعات البيانات الخاصة بالمهمة أو الخاصة بالمجال. في كثير من الأحيان، يجب عليهم تنظيم وإنشاء مجموعات البيانات الخاصة بهم نظرًا لأن مجموعات البيانات المتاحة للجمهور، حتى تلك المصممة لمهمة محددة، قد لا تلتقط بشكل مناسب الفروق الدقيقة المطلوبة لحالة الاستخدام الخاصة بهم.
يعد الضبط الدقيق أسرع وأرخص من التدريب الكامل ويتطلب تكرارًا تشغيليًا أسرع للنشر والاختبار لأنه يتم عادةً إنشاء العديد من النماذج المرشحة. يسمح تقييم هذه النماذج بالتحسين المستمر للنموذج ومعايرته وتصحيح الأخطاء. لاحظ أن المضبطين الدقيقين يمكن أن يصبحوا مستهلكين لنماذجهم الخاصة عندما يقومون بتطوير تطبيقات العالم الحقيقي. - الموديل người tiêu dùng أو يقوم موزعو النماذج بخدمة ومراقبة الأغراض العامة أو النماذج المضبوطة بدقة في الإنتاج، بهدف تعزيز تطبيقاتهم أو خدماتهم من خلال اعتماد LLMs. التحدي الأول الذي يواجههم هو التأكد من أن LLM المختار يتوافق مع احتياجاتهم المحددة والتكلفة وتوقعات الأداء. يعد تفسير وفهم مخرجات النموذج مصدر قلق مستمر، خاصة عندما يتعلق الأمر بالخصوصية وأمن البيانات (على سبيل المثال، لمراجعة المخاطر والامتثال في الصناعات المنظمة، مثل القطاع المالي). يعد التقييم المستمر للنموذج أمرًا بالغ الأهمية لمنع انتشار التحيز أو المحتوى الضار. ومن خلال تنفيذ إطار قوي للرصد والتقييم، يمكن لمستهلكي النماذج تحديد ومعالجة الانحدار في ماجستير إدارة الأعمال بشكل استباقي، مما يضمن احتفاظ هذه النماذج بفعاليتها وموثوقيتها بمرور الوقت.
كيفية إجراء تقييم LLM
يتضمن تقييم النموذج الفعال ثلاثة مكونات أساسية: واحد أو أكثر من نماذج FM أو نماذج دقيقة لتقييم مجموعات بيانات الإدخال (المطالبات أو المحادثات أو المدخلات العادية) ومنطق التقييم.
لاختيار نماذج للتقييم، يجب مراعاة عوامل مختلفة، بما في ذلك خصائص البيانات، وتعقيد المشكلة، والموارد الحسابية المتاحة، والنتيجة المرجوة. يوفر مخزن بيانات الإدخال البيانات اللازمة للتدريب والضبط الدقيق واختبار النموذج المحدد. من المهم أن يكون مخزن البيانات هذا منظمًا بشكل جيد وممثلًا وذو جودة عالية، حيث يعتمد أداء النموذج بشكل كبير على البيانات التي يتعلم منها. وأخيرًا، يحدد منطق التقييم المعايير والمقاييس المستخدمة لتقييم أداء النموذج.
تشكل هذه المكونات الثلاثة معًا إطارًا متماسكًا يضمن التقييم الدقيق والمنهجي لنماذج التعلم الآلي، مما يؤدي في النهاية إلى اتخاذ قرارات مستنيرة وتحسينات في فعالية النموذج.
لا تزال تقنيات التقييم النموذجي مجالًا نشطًا للبحث. تم إنشاء العديد من المعايير والأطر العامة من قبل مجتمع الباحثين في السنوات القليلة الماضية لتغطية مجموعة واسعة من المهام والسيناريوهات مثل GLUE, صمغ ممتاز, القياده, MMLU و مقعد كبير. تحتوي هذه المعايير على لوحات صدارة يمكن استخدامها لمقارنة النماذج التي تم تقييمها وتباينها. تهدف المعايير، مثل HELM، أيضًا إلى تقييم المقاييس التي تتجاوز مقاييس الدقة، مثل الدقة أو درجة F1. يشتمل معيار HELM على مقاييس للعدالة والتحيز والسمية والتي لها نفس القدر من الأهمية في النتيجة الإجمالية لتقييم النموذج.
تتضمن كل هذه المعايير مجموعة من المقاييس التي تقيس كيفية أداء النموذج في مهمة معينة. المقاييس الأكثر شهرة والأكثر شيوعا هي ROUGE (الدراسة الموجهة نحو الاستدعاء لتقييم التسجيل)، الزرقاء (بديل التقييم ثنائي اللغة)، أو METEOR (مقياس تقييم الترجمة بالترتيب الصريح). تعمل هذه المقاييس كأداة مفيدة للتقييم الآلي، حيث توفر مقاييس كمية للتشابه المعجمي بين النص الذي تم إنشاؤه والنص المرجعي. ومع ذلك، فإنها لا تلتقط النطاق الكامل لتوليد اللغة الشبيهة بالبشر، والذي يتضمن الفهم الدلالي، أو السياق، أو الفروق الأسلوبية الدقيقة. على سبيل المثال، لا توفر HELM تفاصيل التقييم ذات الصلة بحالات استخدام محددة، وحلول لاختبار المطالبات المخصصة، والنتائج التي يتم تفسيرها بسهولة والتي يستخدمها غير الخبراء، لأن العملية يمكن أن تكون مكلفة، وليس من السهل توسيع نطاقها، ومهام محددة فقط.
علاوة على ذلك، فإن تحقيق توليد لغة تشبه الإنسان غالبًا ما يتطلب دمج الإنسان في الحلقة لإجراء تقييمات نوعية وحكم بشري لاستكمال مقاييس الدقة الآلية. يعد التقييم البشري طريقة قيمة لتقييم مخرجات LLM ولكنه يمكن أن يكون أيضًا ذاتيًا وعرضة للتحيز لأن المقيمين البشريين المختلفين قد يكون لديهم آراء وتفسيرات متنوعة لجودة النص. علاوة على ذلك، يمكن أن يكون التقييم البشري كثيف الاستخدام للموارد ومكلفًا ويمكن أن يتطلب وقتًا وجهدًا كبيرًا.
دعونا نتعمق في كيفية قيام Amazon SageMaker Clarify بربط النقاط بسلاسة، مما يساعد العملاء في إجراء تقييم شامل للنماذج واختيارها.
تقييم LLM مع Amazon SageMaker Clarify
يساعد Amazon SageMaker Clarify العملاء على أتمتة المقاييس، بما في ذلك على سبيل المثال لا الحصر، الدقة والمتانة والسمية والقوالب النمطية والمعرفة الواقعية للتقييم الآلي والأسلوب والتماسك والملاءمة للتقييم القائم على الإنسان وأساليب التقييم من خلال توفير إطار لتقييم LLMs. والخدمات المستندة إلى LLM مثل Amazon Bedrock. باعتبارها خدمة مُدارة بالكامل، تعمل SageMaker Clarify على تبسيط استخدام أطر عمل التقييم مفتوحة المصدر داخل Amazon SageMaker. يمكن للعملاء تحديد مجموعات بيانات ومقاييس التقييم ذات الصلة لسيناريوهاتهم وتوسيعها باستخدام مجموعات البيانات السريعة وخوارزميات التقييم الخاصة بهم. يقدم SageMaker Clarify نتائج التقييم بتنسيقات متعددة لدعم الأدوار المختلفة في سير عمل LLM. يمكن لعلماء البيانات تحليل النتائج التفصيلية باستخدام مرئيات SageMaker Clarify في دفاتر الملاحظات وبطاقات نموذج SageMaker وتقارير PDF. وفي الوقت نفسه، يمكن لفرق العمليات استخدام Amazon SageMaker GroundTruth لمراجعة العناصر عالية الخطورة التي يحددها SageMaker Clarify والتعليق عليها. على سبيل المثال، عن طريق القوالب النمطية، أو السمية، أو معلومات تحديد الهوية الشخصية (PII) التي تم الهروب منها، أو الدقة المنخفضة.
يتم بعد ذلك استخدام التعليقات التوضيحية والتعلم المعزز للتخفيف من المخاطر المحتملة. تعمل التفسيرات الملائمة للإنسان للمخاطر التي تم تحديدها على تسريع عملية المراجعة اليدوية، وبالتالي تقليل التكاليف. توفر التقارير الموجزة لأصحاب المصلحة في قطاع الأعمال معايير مقارنة بين النماذج والإصدارات المختلفة، مما يسهل اتخاذ القرارات المستنيرة.
يوضح الشكل التالي إطار عمل تقييم LLMs والخدمات المستندة إلى LLM:

تقييم Amazon SageMaker Clarify LLM عبارة عن مكتبة مفتوحة المصدر لتقييم النماذج التأسيسية (FMEval) تم تطويرها بواسطة AWS لمساعدة العملاء على تقييم LLMs بسهولة. تم أيضًا دمج جميع الوظائف في Amazon SageMaker Studio لتمكين تقييم LLM لمستخدميه. في الأقسام التالية، نقدم تكامل قدرات تقييم Amazon SageMaker Clarify LLM مع SageMaker Pipelines لتمكين تقييم LLM على نطاق واسع باستخدام مبادئ MLOps.
دورة حياة Amazon SageMaker MLOps
كما تدوينة "خارطة طريق MLOps التأسيسية للمؤسسات باستخدام Amazon SageMaker"يوضح أن MLOps عبارة عن مزيج من العمليات والأشخاص والتكنولوجيا لإنتاج حالات استخدام تعلم الآلة بكفاءة.
يوضح الشكل التالي دورة حياة MLOps الشاملة:

تبدأ الرحلة النموذجية عندما يقوم عالم البيانات بإنشاء دفتر ملاحظات لإثبات المفهوم (PoC) لإثبات أن تعلم الآلة يمكنه حل مشكلة العمل. طوال عملية تطوير إثبات المفهوم (PoC)، يقع على عاتق عالم البيانات تحويل مؤشرات الأداء الرئيسية للأعمال (KPIs) إلى مقاييس نموذج التعلم الآلي، مثل الدقة أو المعدل الإيجابي الخاطئ، واستخدام مجموعة بيانات اختبار محدودة لتقييم هذه المقاييس. يتعاون علماء البيانات مع مهندسي تعلم الآلة لنقل التعليمات البرمجية من دفاتر الملاحظات إلى المستودعات، وإنشاء مسارات تعلم الآلة باستخدام خطوط أنابيب Amazon SageMaker، التي تربط خطوات ومهام المعالجة المختلفة، بما في ذلك المعالجة المسبقة والتدريب والتقييم والمعالجة اللاحقة، كل ذلك مع دمج الإنتاج الجديد باستمرار بيانات. يعتمد نشر مسارات Amazon SageMaker على تفاعلات المستودع وتنشيط مسارات CI/CD. يحتفظ مسار تعلم الآلة بالنماذج عالية الأداء، وصور الحاويات، ونتائج التقييم، ومعلومات الحالة في سجل نموذجي، حيث يقوم أصحاب المصلحة النموذجيون بتقييم الأداء واتخاذ قرار بشأن التقدم إلى الإنتاج بناءً على نتائج الأداء والمعايير المرجعية، يليها تنشيط خط أنابيب CI/CD آخر للتدريج ونشر الإنتاج. بمجرد بدء الإنتاج، يستخدم مستهلكو تعلم الآلة النموذج عبر الاستدلال الناتج عن التطبيق من خلال الاستدعاء المباشر أو مكالمات واجهة برمجة التطبيقات (API)، مع حلقات ردود الفعل لأصحاب النماذج لتقييم الأداء المستمر.
توضيح Amazon SageMaker وتكامل MLOps
باتباع دورة حياة MLOps، يقوم المولفون الدقيقون أو مستخدمو النماذج مفتوحة المصدر بإنتاج نماذج مضبوطة بدقة أو FM باستخدام خدمات Amazon SageMaker Jumpstart وMLOps، كما هو موضح في تنفيذ ممارسات MLOps مع نماذج Amazon SageMaker JumpStart المدربة مسبقًا. يؤدي هذا إلى مجال جديد لعمليات النموذج الأساسي (FMOps) وعمليات LLM (LLMOps) FMOps/LLMOps: تفعيل الذكاء الاصطناعي التوليدي والاختلافات مع MLOps.
يوضح الشكل التالي دورة حياة LLMOps الشاملة:
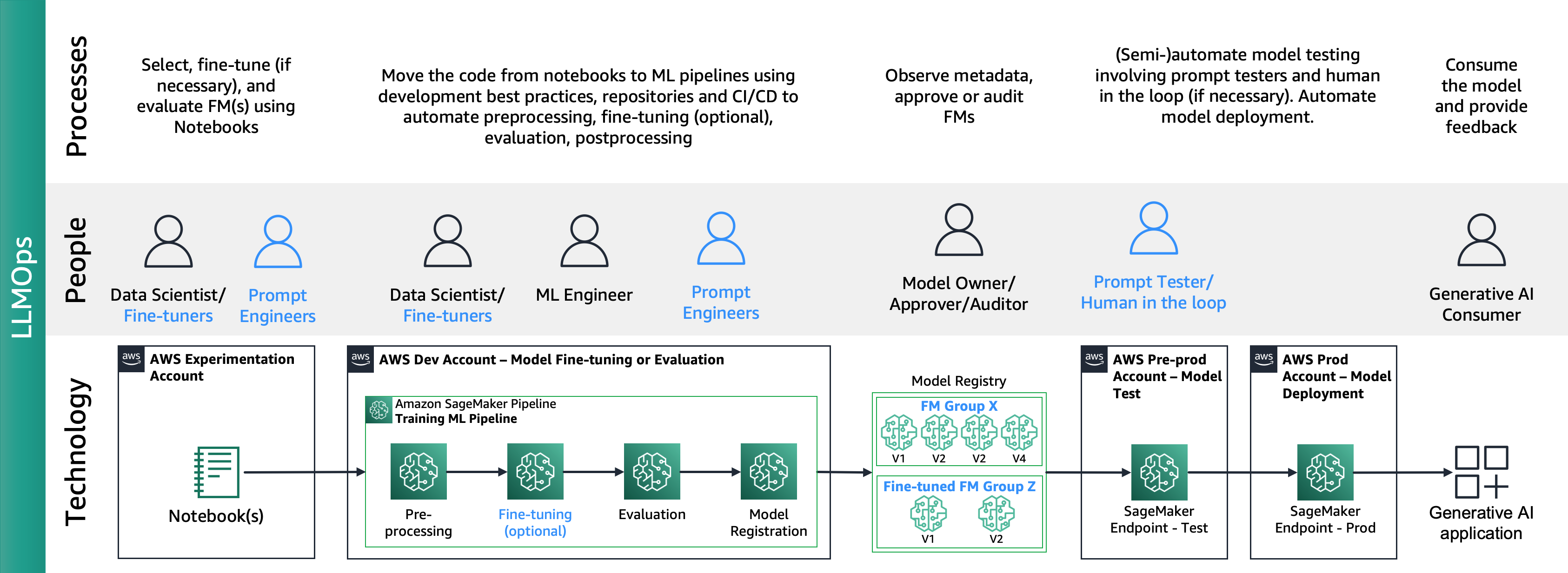
في LLMOps، تتمثل الاختلافات الرئيسية مقارنة بـ MLOps في اختيار النموذج وتقييم النموذج الذي يتضمن عمليات ومقاييس مختلفة. في مرحلة التجربة الأولية، يقوم علماء البيانات (أو المضبطون الدقيقون) باختيار FM الذي سيتم استخدامه في حالة استخدام محددة للذكاء الاصطناعي التوليدي.
يؤدي هذا غالبًا إلى اختبار وضبط العديد من أجهزة FM، وقد يؤدي بعضها إلى نتائج قابلة للمقارنة. بعد اختيار النموذج (النماذج)، يكون المهندسون الفوريون مسؤولين عن إعداد بيانات الإدخال الضرورية والمخرجات المتوقعة للتقييم (على سبيل المثال، مطالبات الإدخال التي تشتمل على بيانات الإدخال والاستعلام) وتحديد المقاييس مثل التشابه والسمية. بالإضافة إلى هذه المقاييس، يجب على علماء البيانات أو المضبطين الدقيقين التحقق من صحة النتائج واختيار FM المناسب ليس فقط على مقاييس الدقة، ولكن أيضًا على القدرات الأخرى مثل زمن الوصول والتكلفة. وبعد ذلك، يمكنهم نشر نموذج على نقطة نهاية SageMaker واختبار أدائه على نطاق صغير. في حين أن مرحلة التجريب قد تنطوي على عملية مباشرة، فإن الانتقال إلى الإنتاج يتطلب من العملاء أتمتة العملية وتعزيز قوة الحل. لذلك، نحتاج إلى التعمق في كيفية أتمتة التقييم، وتمكين المختبرين من إجراء تقييم فعال على نطاق واسع وتنفيذ مراقبة في الوقت الفعلي لمدخلات ومخرجات النموذج.
أتمتة تقييم FM
تقوم Amazon SageMaker Pipelines بأتمتة جميع مراحل المعالجة المسبقة وضبط FM (اختياريًا) والتقييم على نطاق واسع. بالنظر إلى النماذج المحددة أثناء التجربة، يحتاج مهندسو الموجهات إلى تغطية مجموعة أكبر من الحالات من خلال إعداد العديد من الموجهات وتخزينها في مستودع تخزين مخصص يسمى كتالوج الموجهات. لمزيد من المعلومات، راجع FMOps/LLMOps: تفعيل الذكاء الاصطناعي التوليدي والاختلافات مع MLOps. بعد ذلك، يمكن تنظيم مسارات Amazon SageMaker على النحو التالي:
السيناريو 1 – تقييم FMs متعددة: في هذا السيناريو، يمكن لمديري FM تغطية حالة استخدام الأعمال دون إجراء عمليات ضبط دقيقة. يتكون مسار Amazon SageMaker من الخطوات التالية: المعالجة المسبقة للبيانات، والتقييم المتوازي للعديد من نماذج FM، ومقارنة النماذج، والاختيار بناءً على الدقة والخصائص الأخرى مثل التكلفة أو زمن الوصول، وتسجيل عناصر النموذج المحددة، والبيانات الوصفية.
يوضح الرسم البياني التالي هذه العمارة.

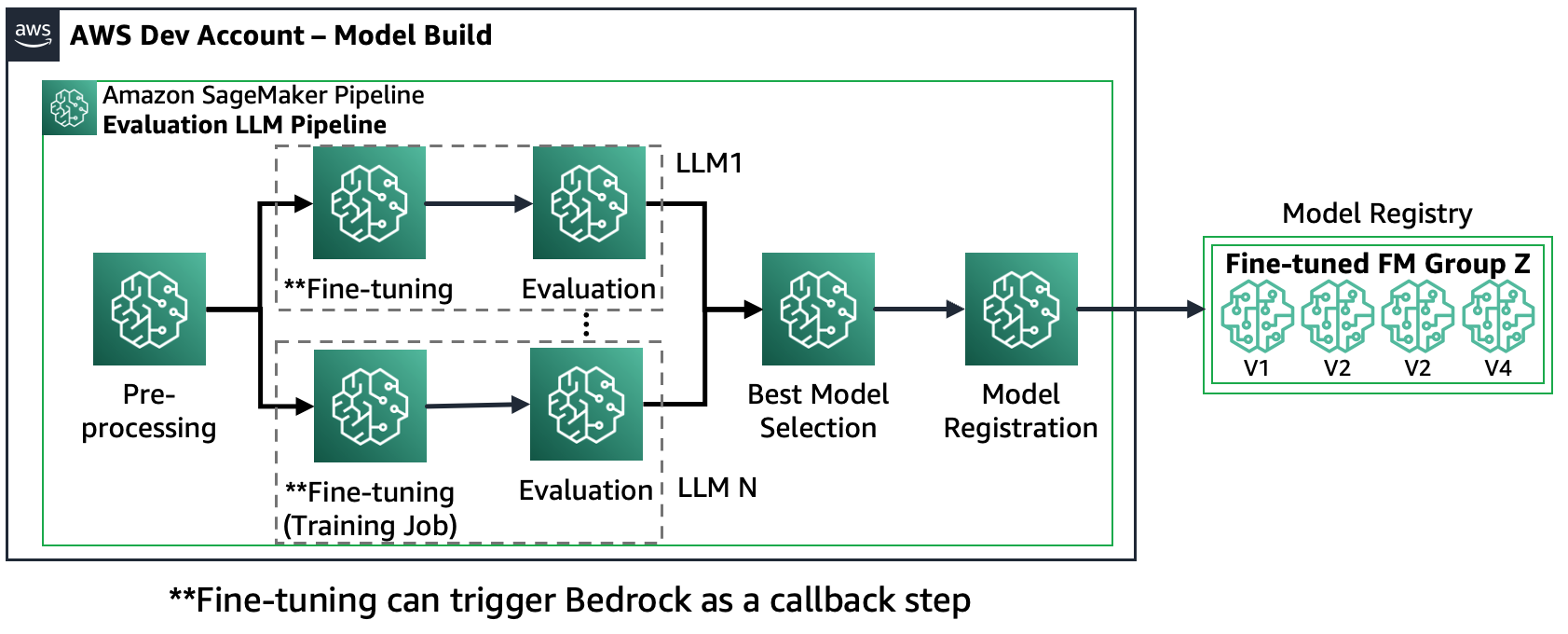
السيناريو 2 – ضبط وتقييم FMs متعددين: في هذا السيناريو، تم تصميم مسار Amazon SageMaker بشكل يشبه إلى حد كبير السيناريو 1، ولكنه يعمل بالتوازي مع كل من خطوات الضبط الدقيق والتقييم لكل FM. سيتم تسجيل أفضل نموذج تم ضبطه في سجل النماذج.
يوضح الرسم البياني التالي هذه العمارة.
السيناريو 3 – تقييم FMs متعددة وFMs المضبوطة بدقة: هذا السيناريو عبارة عن مزيج من تقييم FMs للأغراض العامة وFM المضبوطة بدقة. في هذه الحالة، يرغب العملاء في التحقق مما إذا كان النموذج المضبوط جيدًا يمكنه الأداء بشكل أفضل من FM للأغراض العامة.
يوضح الشكل التالي خطوات خط أنابيب SageMaker الناتجة.
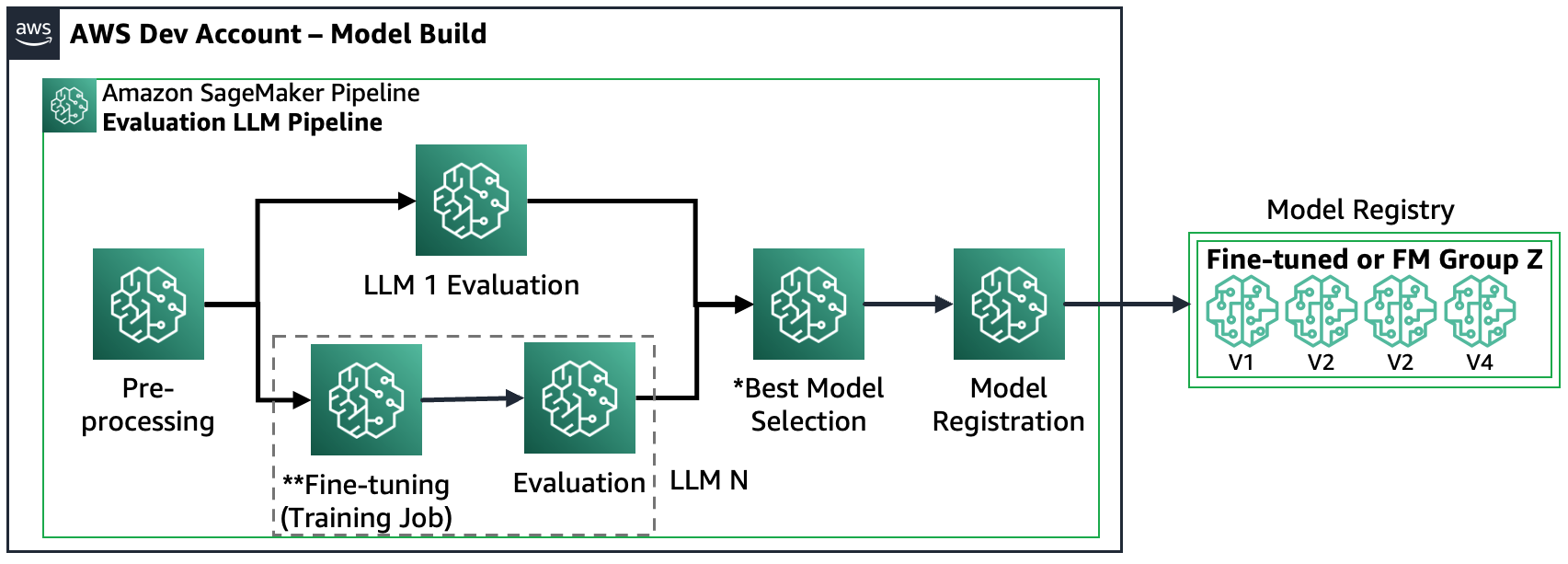
لاحظ أن تسجيل النموذج يتبع نمطين: (أ) تخزين نموذج مفتوح المصدر ومصنوعات يدوية أو (ب) تخزين مرجع إلى FM خاص. لمزيد من المعلومات، راجع FMOps/LLMOps: تفعيل الذكاء الاصطناعي التوليدي والاختلافات مع MLOps.
حل نظرة عامة
لتسريع رحلتك إلى تقييم LLM على نطاق واسع، قمنا بإنشاء حل ينفذ السيناريوهات باستخدام كل من Amazon SageMaker Clarify وAmazon SageMaker Pipelines SDK الجديد. يتوفر مثال التعليمات البرمجية، بما في ذلك مجموعات البيانات ودفاتر الملاحظات المصدر وخطوط أنابيب SageMaker (الخطوات ومسارات ML)، على GitHub جيثب:. لتطوير هذا الحل النموذجي، استخدمنا اثنين من FM: Llama2 وFalcon-7B. في هذا المنشور، ينصب تركيزنا الأساسي على العناصر الأساسية لحل SageMaker Pipeline الذي يتعلق بعملية التقييم.
تكوين التقييم: لغرض توحيد إجراءات التقييم، قمنا بإنشاء ملف تكوين YAML، (evaluation_config.yaml)، الذي يحتوي على التفاصيل اللازمة لعملية التقييم بما في ذلك مجموعة البيانات، والنموذج (النماذج)، والخوارزميات التي سيتم تشغيلها أثناء خطوة تقييم خط أنابيب SageMaker. يوضح المثال التالي ملف التكوين:
pipeline:
name: "llm-evaluation-multi-models-hybrid"
dataset:
dataset_name: "trivia_qa_sampled"
input_data_location: "evaluation_dataset_trivia.jsonl"
dataset_mime_type: "jsonlines"
model_input_key: "question"
target_output_key: "answer"
models:
- name: "llama2-7b-f"
model_id: "meta-textgeneration-llama-2-7b-f"
model_version: "*"
endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f"
deployment_config:
instance_type: "ml.g5.2xlarge"
num_instances: 1
evaluation_config:
output: '[0].generation.content'
content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]]
inference_parameters:
max_new_tokens: 100
top_p: 0.9
temperature: 0.6
custom_attributes:
accept_eula: True
prompt_template: "$feature"
cleanup_endpoint: True
- name: "falcon-7b"
...
- name: "llama2-7b-finetuned"
...
finetuning:
train_data_path: "train_dataset"
validation_data_path: "val_dataset"
parameters:
instance_type: "ml.g5.12xlarge"
num_instances: 1
epoch: 1
max_input_length: 100
instruction_tuned: True
chat_dataset: False
...
algorithms:
- algorithm: "FactualKnowledge"
module: "fmeval.eval_algorithms.factual_knowledge"
config: "FactualKnowledgeConfig"
target_output_delimiter: "<OR>"خطوة التقييم: يوفر SageMaker Pipeline SDK الجديد للمستخدمين المرونة اللازمة لتحديد الخطوات المخصصة في سير عمل تعلم الآلة باستخدام مصمم Python '@step'. لذلك، يحتاج المستخدمون إلى إنشاء نص بايثون أساسي لإجراء التقييم، على النحو التالي:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,):
from fmeval.data_loaders.data_config import DataConfig
from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner
from fmeval.reporting.eval_output_cells import EvalOutputCell
from fmeval.constants import MIME_TYPE_JSONLINES
s3 = boto3.client("s3")
bucket, object_key = parse_s3_url(data_s3_path)
s3.download_file(bucket, object_key, "dataset.jsonl")
config = DataConfig(
dataset_name=data_config["dataset_name"],
dataset_uri="dataset.jsonl",
dataset_mime_type=MIME_TYPE_JSONLINES,
model_input_location=data_config["model_input_key"],
target_output_location=data_config["target_output_key"],
)
evaluation_config = model_config["evaluation_config"]
content_dict = {
"inputs": evaluation_config["content_template"],
"parameters": evaluation_config["inference_parameters"],
}
serializer = JSONSerializer()
serialized_data = serializer.serialize(content_dict)
content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt")
print(content_template)
js_model_runner = JumpStartModelRunner(
endpoint_name=endpoint_name,
model_id=model_config["model_id"],
model_version=model_config["model_version"],
output=evaluation_config["output"],
content_template=content_template,
custom_attributes="accept_eula=true",
)
eval_output_all = []
s3 = boto3.resource("s3")
output_bucket, output_index = parse_s3_url(output_data_path)
for algorithm in algorithm_config:
algorithm_name = algorithm["algorithm"]
module = importlib.import_module(algorithm["module"])
algorithm_class = getattr(module, algorithm_name)
algorithm_config_class = getattr(module, algorithm["config"])
eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"]))
eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,)
print(f"eval_output: {eval_output}")
eval_output_all.append(eval_output)
html = markdown.markdown(str(EvalOutputCell(eval_output[0])))
file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html")
s3_object = s3.Object(bucket_name=output_bucket, key=file_index)
s3_object.put(Body=html)
eval_result = {"model_config": model_config, "eval_output": eval_output_all}
print(f"eval_result: {eval_result}")
return eval_resultخط أنابيب سيج ميكر: بعد إنشاء الخطوات اللازمة، مثل المعالجة المسبقة للبيانات ونشر النموذج وتقييم النموذج، يحتاج المستخدم إلى ربط الخطوات معًا باستخدام SageMaker Pipeline SDK. يقوم SDK الجديد تلقائيًا بإنشاء سير العمل عن طريق تفسير التبعيات بين الخطوات المختلفة عند استدعاء واجهة برمجة التطبيقات لإنشاء SageMaker Pipeline كما هو موضح في المثال التالي:
import os
import argparse
from datetime import datetime
import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step
# Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy
from lib.utils import ConfigParser
from lib.utils import find_model_by_name
if __name__ == "__main__":
os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd()
sagemaker_session = sagemaker.session.Session()
# Define data location either by providing it as an argument or by using the default bucket
default_bucket = sagemaker.Session().default_bucket()
parser = argparse.ArgumentParser()
parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",)
parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",)
args = parser.parse_args()
# Initialize configuration for data, model, and algorithm
if args.config:
config = ConfigParser(args.config).get_config()
else:
config = ConfigParser("pipeline_config.yaml").get_config()
evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S")
pipeline_name = config["pipeline"]["name"]
dataset_config = config["dataset"] # Get dataset configuration
input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"]
output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id)
print("Data input location:", input_data_path)
print("Data output location:", output_data_path)
algorithms_config = config["algorithms"] # Get algorithms configuration
model_config = find_model_by_name(config["models"], "llama2-7b")
model_id = model_config["model_id"]
model_version = model_config["model_version"]
evaluation_config = model_config["evaluation_config"]
endpoint_name = model_config["endpoint_name"]
model_deploy_config = model_config["deployment_config"]
deploy_instance_type = model_deploy_config["instance_type"]
deploy_num_instances = model_deploy_config["num_instances"]
# Construct the steps
processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path)
endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,)
evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,)
last_pipeline_step = evaluation_results
if model_config["cleanup_endpoint"]:
cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name)
get_step(cleanup).add_depends_on([evaluation_results])
last_pipeline_step = cleanup
# Define the SageMaker Pipeline
pipeline = Pipeline(
name=pipeline_name,
steps=[last_pipeline_step],
)
# Build and run the Sagemaker Pipeline
pipeline.upsert(role_arn=sagemaker.get_execution_role())
# pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>")
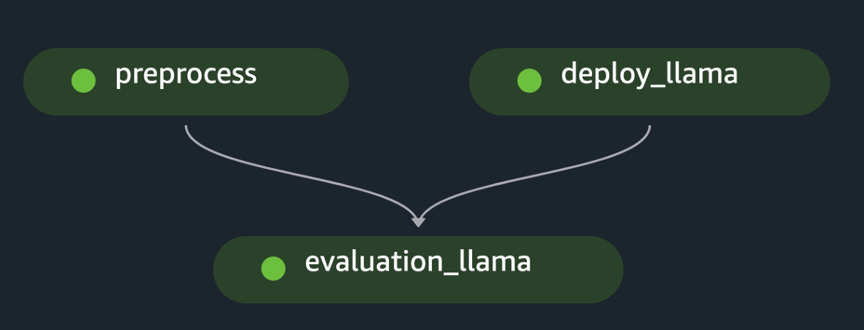
pipeline.start()ينفذ المثال تقييم FM واحد عن طريق المعالجة المسبقة لمجموعة البيانات الأولية، ونشر النموذج، وتشغيل التقييم. يظهر الرسم البياني الحلقي الموجه لخط الأنابيب (DAG) في الشكل التالي.
باتباع نهج مماثل وباستخدام المثال وتخصيصه في قم بضبط نماذج LLaMA 2 على SageMaker JumpStart، قمنا بإنشاء المسار لتقييم نموذج تم ضبطه بدقة، كما هو موضح في الشكل التالي.

باستخدام خطوات SageMaker Pipeline السابقة ككتل "Lego"، قمنا بتطوير الحل للسيناريو 1 والسيناريو 3، كما هو موضح في الأشكال التالية. على وجه التحديد، GitHub جيثب: يمكّن المستودع المستخدم من تقييم FMs متعددة بالتوازي أو إجراء تقييم أكثر تعقيدًا يجمع بين تقييم كل من النماذج الأساسية والنماذج المضبوطة بدقة.

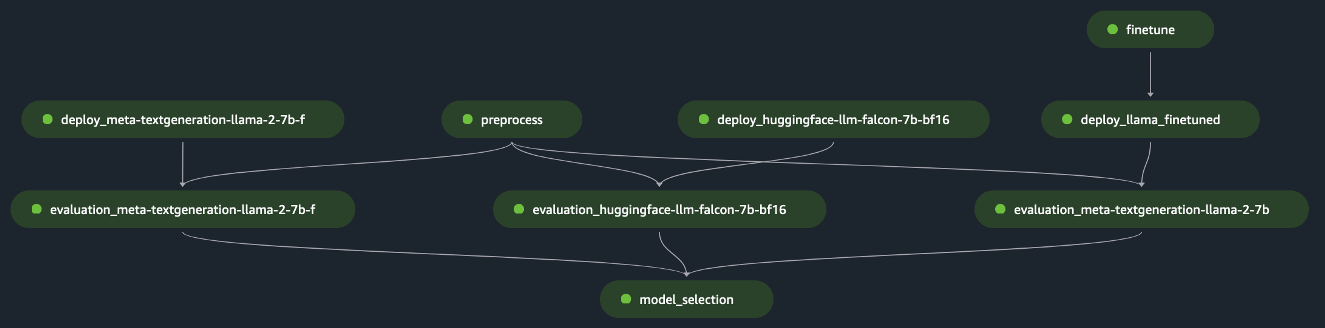
تشمل الوظائف الإضافية المتوفرة في المستودع ما يلي:
- إنشاء خطوة التقييم الديناميكي: يقوم الحل الخاص بنا بإنشاء جميع خطوات التقييم اللازمة ديناميكيًا استنادًا إلى ملف التكوين لتمكين المستخدمين من تقييم أي عدد من النماذج. لقد قمنا بتوسيع الحل لدعم التكامل السهل لأنواع جديدة من النماذج، مثل Hugging Face أو Amazon Bedrock.
- منع إعادة نشر نقطة النهاية: إذا كانت نقطة النهاية موجودة بالفعل، فإننا نتخطى عملية النشر. يتيح ذلك للمستخدم إعادة استخدام نقاط النهاية مع FMs للتقييم، مما يؤدي إلى توفير التكاليف وتقليل وقت النشر.
- تنظيف نقطة النهاية: بعد الانتهاء من التقييم، تم إيقاف تشغيل SageMaker Pipeline لنقاط النهاية المنشورة. يمكن توسيع هذه الوظيفة للحفاظ على أفضل نقطة نهاية للنموذج على قيد الحياة.
- خطوة اختيار النموذج: لقد أضفنا عنصرًا نائبًا لخطوة تحديد النموذج الذي يتطلب منطق الأعمال الخاص باختيار النموذج النهائي، بما في ذلك معايير مثل التكلفة أو زمن الوصول.
- خطوة تسجيل النموذج: يمكن تسجيل أفضل نموذج في Amazon SageMaker Model Registry كإصدار جديد لمجموعة نماذج محددة.
- بركة دافئة: تتيح لك التجمعات الدافئة المُدارة بواسطة SageMaker الاحتفاظ بالبنية الأساسية المتوفرة وإعادة استخدامها بعد اكتمال المهمة لتقليل زمن الوصول لأحمال العمل المتكررة
يوضح الشكل التالي هذه القدرات ومثال تقييم متعدد النماذج يمكن للمستخدمين إنشاؤه بسهولة وديناميكية باستخدام الحل الخاص بنا في هذا GitHub جيثب: مستودع.

لقد أبقينا إعداد البيانات خارج النطاق عن عمد كما سيتم وصفه في منشور مختلف بعمق، بما في ذلك تصميمات الكتالوج السريعة والقوالب السريعة والتحسين السريع. لمزيد من المعلومات وتعريفات المكونات ذات الصلة، راجع FMOps/LLMOps: تفعيل الذكاء الاصطناعي التوليدي والاختلافات مع MLOps.
وفي الختام
في هذا المنشور، ركزنا على كيفية أتمتة وتشغيل تقييم LLM على نطاق واسع باستخدام إمكانات تقييم Amazon SageMaker Clarify LLM وAmazon SageMaker Pipelines. بالإضافة إلى التصاميم المعمارية النظرية، لدينا مثال على التعليمات البرمجية في هذا GitHub جيثب: المستودع (الذي يضم Llama2 وFalcon-7B FMs) لتمكين العملاء من تطوير آليات التقييم القابلة للتطوير الخاصة بهم.
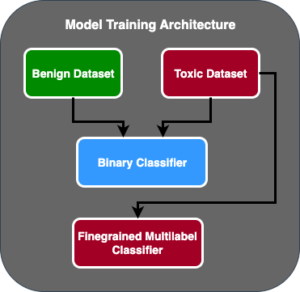
يوضح الرسم التوضيحي التالي بنية تقييم النموذج.
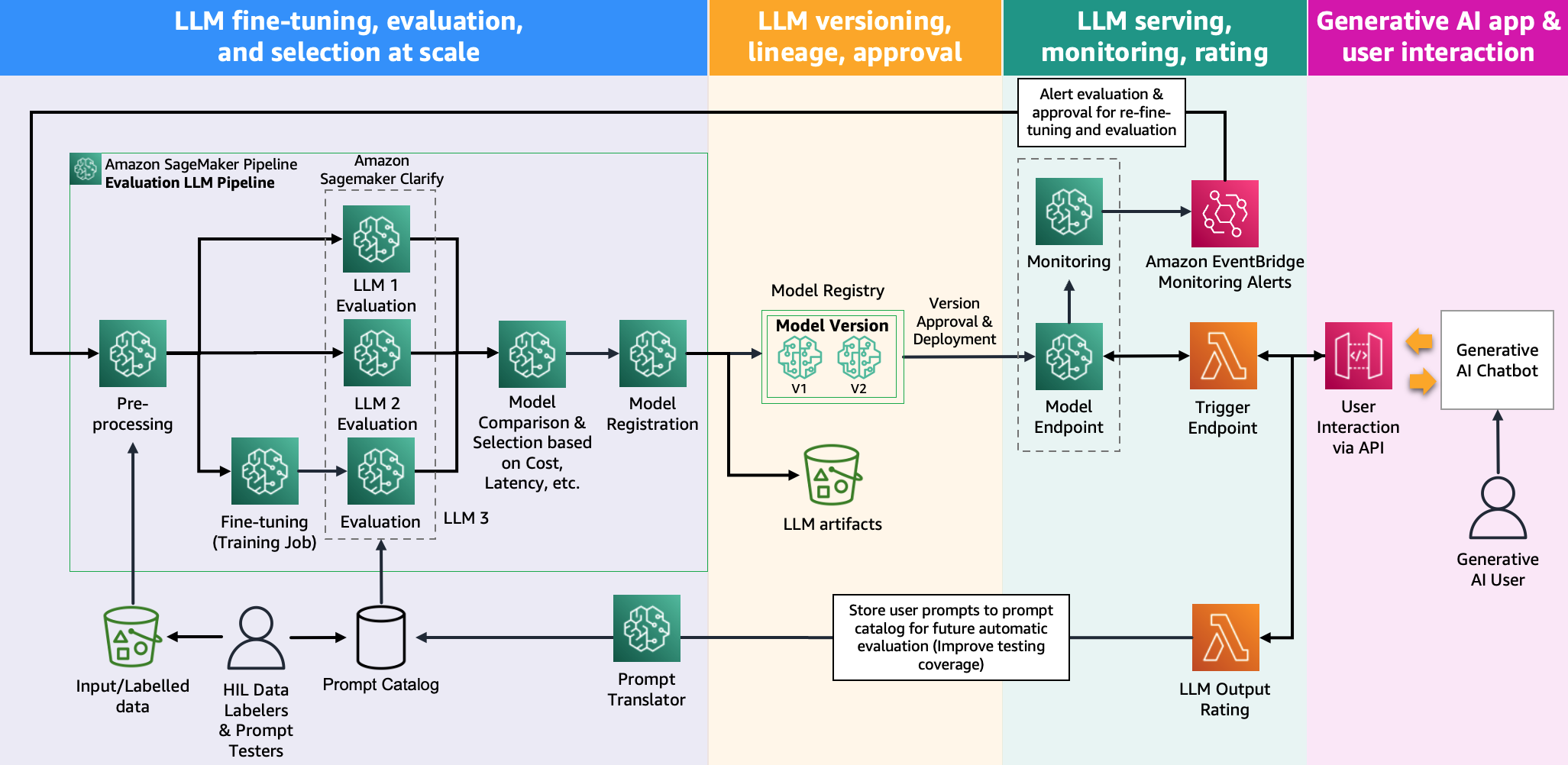
في هذا المنشور، ركزنا على تفعيل تقييم LLM على نطاق واسع كما هو موضح على الجانب الأيسر من الرسم التوضيحي. في المستقبل، سنركز على تطوير أمثلة تفي بدورة الحياة الشاملة لأنظمة FM حتى الإنتاج من خلال اتباع الإرشادات الموضحة في FMOps/LLMOps: تفعيل الذكاء الاصطناعي التوليدي والاختلافات مع MLOps. يتضمن ذلك تقديم LLM ومراقبته وتخزينه لتصنيف المخرجات الذي سيؤدي في النهاية إلى إعادة التقييم والضبط التلقائي، وأخيرًا، استخدام البشر في الحلقة للعمل على البيانات المصنفة أو كتالوج المطالبات.
عن المؤلفين
 د. سقراطيس كارتاكيس هو مهندس الحلول المتخصص الرئيسي في التعلم الآلي والعمليات في Amazon Web Services. يركز Sokratis على تمكين عملاء المؤسسات من تصنيع حلول التعلم الآلي (ML) والذكاء الاصطناعي التوليدية الخاصة بهم من خلال استغلال خدمات AWS وتشكيل نموذج التشغيل الخاص بهم، أي أسس MLOps/FMOps/LLMOps، وخارطة طريق التحول التي تستفيد من أفضل ممارسات التطوير. لقد أمضى ما يزيد عن 15 عامًا في اختراع وتصميم وقيادة وتنفيذ حلول مبتكرة وشاملة لتعلم الآلة والذكاء الاصطناعي على مستوى الإنتاج في مجالات الطاقة وتجارة التجزئة والصحة والتمويل ورياضة السيارات وما إلى ذلك.
د. سقراطيس كارتاكيس هو مهندس الحلول المتخصص الرئيسي في التعلم الآلي والعمليات في Amazon Web Services. يركز Sokratis على تمكين عملاء المؤسسات من تصنيع حلول التعلم الآلي (ML) والذكاء الاصطناعي التوليدية الخاصة بهم من خلال استغلال خدمات AWS وتشكيل نموذج التشغيل الخاص بهم، أي أسس MLOps/FMOps/LLMOps، وخارطة طريق التحول التي تستفيد من أفضل ممارسات التطوير. لقد أمضى ما يزيد عن 15 عامًا في اختراع وتصميم وقيادة وتنفيذ حلول مبتكرة وشاملة لتعلم الآلة والذكاء الاصطناعي على مستوى الإنتاج في مجالات الطاقة وتجارة التجزئة والصحة والتمويل ورياضة السيارات وما إلى ذلك.
 جاجديب سينغ سوني هو مهندس حلول الشركاء الأول في AWS ومقره في هولندا. إنه يستخدم شغفه بأدوات DevOps وGenAI وأدوات البناء لمساعدة كل من تكامل الأنظمة وشركاء التكنولوجيا. يطبق Jagdeep خلفيته في تطوير التطبيقات والهندسة المعمارية لدفع الابتكار داخل فريقه وتعزيز التقنيات الجديدة.
جاجديب سينغ سوني هو مهندس حلول الشركاء الأول في AWS ومقره في هولندا. إنه يستخدم شغفه بأدوات DevOps وGenAI وأدوات البناء لمساعدة كل من تكامل الأنظمة وشركاء التكنولوجيا. يطبق Jagdeep خلفيته في تطوير التطبيقات والهندسة المعمارية لدفع الابتكار داخل فريقه وتعزيز التقنيات الجديدة.
 الدكتور ريكاردو جاتي هو أحد كبار مهندسي حلول الشركات الناشئة ومقره في إيطاليا. وهو مستشار فني للعملاء، حيث يساعدهم على تنمية أعمالهم من خلال اختيار الأدوات والتقنيات المناسبة للابتكار والتوسع بسرعة والانطلاق عالميًا في دقائق. لقد كان دائمًا شغوفًا بالتعلم الآلي والذكاء الاصطناعي التوليدي، حيث قام بدراسة هذه التقنيات وتطبيقها في مجالات مختلفة طوال حياته المهنية. وهو مضيف ومحرر لبودكاست AWS الإيطالي "Casa Startup"، المخصص لقصص مؤسسي الشركات الناشئة والاتجاهات التكنولوجية الجديدة.
الدكتور ريكاردو جاتي هو أحد كبار مهندسي حلول الشركات الناشئة ومقره في إيطاليا. وهو مستشار فني للعملاء، حيث يساعدهم على تنمية أعمالهم من خلال اختيار الأدوات والتقنيات المناسبة للابتكار والتوسع بسرعة والانطلاق عالميًا في دقائق. لقد كان دائمًا شغوفًا بالتعلم الآلي والذكاء الاصطناعي التوليدي، حيث قام بدراسة هذه التقنيات وتطبيقها في مجالات مختلفة طوال حياته المهنية. وهو مضيف ومحرر لبودكاست AWS الإيطالي "Casa Startup"، المخصص لقصص مؤسسي الشركات الناشئة والاتجاهات التكنولوجية الجديدة.
- محتوى مدعوم من تحسين محركات البحث وتوزيع العلاقات العامة. تضخيم اليوم.
- PlatoData.Network Vertical Generative Ai. تمكين نفسك. الوصول هنا.
- أفلاطونايستريم. ذكاء Web3. تضخيم المعرفة. الوصول هنا.
- أفلاطون كربون، كلينتك ، الطاقة، بيئة، شمسي، إدارة المخلفات. الوصول هنا.
- أفلاطون هيلث. التكنولوجيا الحيوية وذكاء التجارب السريرية. الوصول هنا.
- المصدر https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/
- :لديها
- :يكون
- :ليس
- :أين
- $ UP
- 1
- 100
- 9
- a
- من نحن
- تسريع
- الوصول
- دقة
- بدقة
- التأهيل
- تحقيق
- في
- عمل
- تفعيل
- نشط
- اسيكليك
- وأضاف
- إضافة
- وبالإضافة إلى ذلك
- العنوان
- كاف
- إدارة
- اعتماد
- تبني
- التطورات
- المستشار
- بعد
- ضد
- عملاء
- AI
- قانون AI
- أنظمة الذكاء الاصطناعي
- هدف
- تهدف
- خوارزمية
- خوارزميات
- يحاذي
- على قيد الحياة
- الكل
- يسمح
- سابقا
- أيضا
- دائما
- أمازون
- الأمازون SageMaker
- أمازون سيج ميكر جومب ستارت
- خطوط أنابيب Amazon SageMaker
- أمازون ساجميكر ستوديو
- أمازون ويب سيرفيسز
- an
- تحليل
- و
- آخر
- إجابة
- أي وقت
- API
- تطبيق
- تطوير التطبيقات
- التطبيقات
- تطبيقي
- ينطبق
- نهج
- مناسب
- هندسة معمارية
- هي
- المناطق
- حجة
- AS
- تقييم
- تقييم
- التقييم المناسبين
- تقييم
- At
- التدقيق
- أتمتة
- الآلي
- أوتوماتيك
- تلقائيا
- أتمتة
- متاح
- AWS
- b
- خلفية
- على أساس
- الأساسية
- BE
- لان
- أصبح
- كان
- سلوك
- مؤشر
- وقيم
- المعايير
- الفوائد
- أفضل
- أفضل
- ما بين
- Beyond
- انحياز
- انحيازا
- التحيزات
- Blocks
- على حد سواء
- مخالفات
- سعة
- جلب
- نساعدك في بناء
- باني
- الأعمال
- لكن
- by
- تسمى
- دعوات
- CAN
- مرشح
- قدرات
- قادر على
- أسر
- بطاقات
- التوظيف
- حقيبة
- الحالات
- الأقسام
- معين
- تحدى
- الخصائص
- أرخص
- التحقق
- اختار
- اختيار
- تصنيف
- صنف
- نظيف
- الكود
- متماسك
- تعاون
- مجموعة
- الجمع بين
- مشترك
- مجتمع
- مماثل
- قارن
- مقارنة
- مقارنة
- تكملة
- إكمال
- مجمع
- تعقيد
- الالتزام
- الامتثال
- عنصر
- مكونات
- تضم
- الحسابية
- إحصاء
- مفهوم
- قلق
- إدارة
- إجراء
- السلوك
- الاعداد
- التواصل
- يربط
- نظرت
- يتكون
- بناء
- المستهلكين
- وعاء
- يحتوي
- محتوى
- سياق الكلام
- باستمرار
- متواصل
- تباين
- تحادثي
- المحادثات
- تحول
- تصحيح
- التكلفة
- وفورات في التكاليف
- مكلفة
- التكاليف
- بهيكل
- خلق
- خلق
- خلق
- خلق
- المعايير
- حرج
- حاسم
- على
- العملاء
- DAG
- البيانات
- تحضير البيانات
- عالم البيانات
- أمن البيانات
- مجموعة البيانات
- العبث بالبيانات
- قواعد البيانات
- التاريخ والوقت
- تقرر
- اتخاذ القرار
- القرارات
- مخصصة
- عميق
- غوص عميق
- الترتيب
- حدد
- التعاريف
- يسلم
- الطلب
- التبعيات
- يعتمد
- نشر
- نشر
- نشر
- نشر
- عمق
- وصف
- محدد
- تصميم
- تصميم
- تصاميم
- رغبة
- مطلوب
- مفصلة
- تفاصيل
- تطوير
- المتقدمة
- تطوير
- التطوير التجاري
- DevOps
- الخلافات
- مختلف
- مباشرة
- توجه
- غطس
- عدة
- do
- لا
- نطاق
- المجالات
- قيادة
- أثناء
- حيوي
- e
- كل
- بسهولة
- سهل
- رئيس التحرير
- الطُرق الفعّالة
- فعالية
- فعال
- بكفاءة
- جهد
- إما
- عناصر
- آخر
- يعمل
- تمكين
- تمكن
- تمكين
- النهائي إلى نهاية
- نقطة النهاية
- النهاية
- طاقة
- المهندسين
- تعزيز
- ضمان
- يضمن
- ضمان
- مشروع
- عملاء المؤسسة
- الشركات
- عصر
- بالتساوي
- خاصة
- أساسي
- إلخ
- الأثير (ETH)
- EU
- تقييم
- تقييم
- تقييم
- تقييم
- حتى
- في النهاية
- مثال
- أمثلة
- تنفيذي
- القائمة
- التوقعات
- متوقع
- الإسراع
- مد
- مدد
- خارجي
- استخلاص
- f1
- الوجه
- تيسير
- العوامل
- واقعي
- الإنصاف
- شلالات
- زائف
- مشهور
- FAST
- أسرع
- الميزات
- ويتميز
- ردود الفعل
- قليل
- حقل
- الشكل
- الأرقام
- قم بتقديم
- نهائي
- أخيرا
- تمويل
- مالي
- القطاع المالي
- الاسم الأول
- مرونة
- تركز
- ركز
- ويركز
- يتبع
- متابعيك
- متابعات
- في حالة
- النموذج المرفق
- دورة تأسيسية
- أسس
- مؤسسو
- الإطار
- الأطر
- كثيرا
- تبدأ من
- الوفاء
- بالإضافة إلى
- وظائف
- وظيفة
- أساسي
- علاوة على ذلك
- مستقبل
- جمع
- العلاجات العامة
- هدف عام
- توليد
- ولدت
- يولد
- توليد
- جيل
- توليدي
- الذكاء الاصطناعي التوليدي
- دولار فقط واحصل على خصم XNUMX% على جميع
- معطى
- العالمية
- Go
- منح
- رسم بياني
- تجمع
- مجموعات
- متزايد
- يد
- الضارة
- تسخير
- يملك
- وجود
- he
- صحة الإنسان
- بشكل كبير
- مساعدة
- مساعدة
- يساعد
- مرتفع
- مخاطرة عالية
- يتوقف
- له
- عقد
- مضيف
- كيفية
- كيفية
- لكن
- HTML
- HTTPS
- الانسان
- i
- IAM
- محدد
- يحدد
- تحديد
- if
- يوضح
- صور
- تنفيذ
- تحقيق
- الأدوات
- استيراد
- أهمية
- تحسين
- تحسينات
- in
- تتضمن
- يشمل
- بما فيه
- الاشتقاق
- دمج
- من مؤشرات
- الصناعات
- معلومات
- وأبلغ
- البنية التحتية
- في البداية
- الابتكار
- الابتكار
- مبتكرة
- إدخال
- المدخلات
- دمج
- التكامل
- عمدا
- التفاعلات
- داخلي
- إلى
- تقديم
- التذرع
- تنطوي
- المشاركة
- ينطوي
- تنطوي
- ISO
- IT
- الإيطالية
- إيطاليا
- العناصر
- تكرير
- انها
- وظيفة
- رحلة
- JPG
- احتفظ
- أبقى
- القفل
- المعرفة
- لغة
- كبير
- أكبر
- اسم العائلة
- أخيرا
- كمون
- قيادة
- المتصدرين
- قيادة
- تعلم
- اليسار
- اسمحوا
- الاستفادة من
- المكتبة
- دورة حياة
- مثل
- محدود
- LINK
- اللاما نوع من الجمال
- موقع
- منطق
- منخفض
- آلة
- آلة التعلم
- الرئيسية
- المحافظة
- تحتفظ
- تمكن
- التلاعب
- التلاعب
- كتيب
- كثير
- مايو..
- في غضون
- قياس
- الإجراءات
- آليات
- البيانات الوصفية
- طريقة
- طرق
- متري
- المقاييس
- تقليل
- دقائق
- معلومات خاطئة
- تخفيف
- مخففا
- ML
- MLOps
- نموذج
- عارضات ازياء
- وحدة
- مراقبة
- مراقبة
- الأكثر من ذلك
- أكثر
- الدافع
- رياضة السيارات
- كثيرا
- متعدد
- يجب
- الاسم
- ضروري
- حاجة
- إحتياجات
- هولندا
- جديد
- التكنولوجيات الجديدة
- التالي
- غير الخبراء
- لاحظ
- مفكرة
- أجهزة الكمبيوتر المحمولة
- تظليل
- عدد
- of
- عرض
- غالبا
- on
- مرة
- ONE
- جارية
- فقط
- المصدر المفتوح
- تعمل
- عملية
- عمليات
- آراء
- التحسين
- or
- OS
- أخرى
- لنا
- خارج
- نتيجة
- النتائج
- الناتج
- النتائج
- معلقة
- على مدى
- الكلي
- الخاصة
- أصحاب
- موازية
- المعلمات
- خاص
- خاصة
- الشريكة
- شركاء
- شغف
- عاطفي
- مسار
- أنماط
- مجتمع
- نفذ
- أداء
- العروض
- ينفذ
- مرحلة جديدة
- PII
- خط أنابيب
- المكان
- النائب
- أفلاطون
- الذكاء افلاطون البيانات
- أفلاطون داتا
- اضغط لتتحدث
- بودكاست
- البوينت
- تجمع
- حمامات
- منشور
- المعالجة البعدية
- محتمل
- قوة
- مدعوم
- الممارسات
- دقة
- إعداد
- وجود
- منع
- سابق
- ابتدائي
- رئيسي
- مبادئ
- خصوصية
- خاص
- المشكلة
- الإجراءات
- عملية المعالجة
- العمليات
- معالجة
- الإنتــاج
- تقدم
- الشهرة
- وعد
- تعزيز
- مطالبات
- دليل
- دليل على المفهوم
- نشر
- HAS
- الملكية
- حماية
- إثبات
- تزود
- مقدمي
- ويوفر
- توفير
- جمهور
- علانية
- غرض
- بايثون
- نوعي
- جودة
- كمي
- سؤال
- نطاق
- معدل
- تصنيف
- حقيقي
- العالم الحقيقي
- في الوقت الحقيقي
- تخفيض
- عقار مخفض
- تقليص
- الرجوع
- مرجع
- مسجل
- التسجيل
- سجل
- تراجع
- منتظم
- ما هو مقنن
- الصناعات المنظمة
- قوانين
- تعزيز التعلم
- ذات صلة
- مدى صلة
- ذات الصلة
- الموثوقية
- تكرارية
- تقرير
- التقارير
- التقارير
- مستودع
- ممثل
- مطلوب
- يتطلب
- بحث
- الباحثين
- موارد كثيفة
- الموارد
- مسؤولية
- مسؤول
- مما أدى
- النتائج
- بيع بالتجزئة
- احتفظ
- عائد أعلى
- إعادة استخدام
- مراجعة
- ثورة
- حق
- صارم
- ارتفع
- المخاطرة
- المخاطر
- خريطة طريق
- قوي
- متانة
- النوع
- الأدوار
- يجري
- تشغيل
- يدير
- s
- خزنة
- الضمانات
- sagemaker
- خطوط الأنابيب SageMaker
- مدخرات
- التدرجية
- تحجيم
- حجم
- سيناريو
- سيناريوهات
- عالم
- العلماء
- نطاق
- أحرز هدفاً
- سيناريو
- الإستراحة
- بسلاسة
- أقسام
- القطاع
- تأمين
- أمن
- المخاطر الأمنية
- حدد
- مختار
- اختيار
- اختيار
- كبير
- عاطفة
- خدمة
- الخدمة
- خدماتنا
- خدمة
- الجلسة
- طقم
- تشكيل
- مشاركة
- إظهار
- أظهرت
- يظهر
- جانب
- هام
- مماثل
- يبسط
- ببساطة
- منذ
- عزباء
- صغير
- حل
- الحلول
- حل
- بعض
- مصدر
- امتداد
- متخصص
- محدد
- على وجه التحديد
- قضى
- انطلاق
- أصحاب المصلحة
- التوحيد القياسي
- المعايير
- ستانفورد
- ابتداء
- يبدأ
- بدء التشغيل
- الحالة
- خطوة
- خطوات
- لا يزال
- تخزين
- متجر
- قصص
- صريح
- منظم
- مدروس
- ستوديو
- نمط
- بعد ذلك
- هذه
- ملخص
- الدعم
- نظام
- أنظمة
- الخياطة
- مهمة
- المهام
- فريق
- فريق
- تقني
- تقنيات
- التكنولوجية
- التكنولوجيا
- تكنولوجيا
- النماذج
- تجربه بالعربي
- اختبار
- الاختبار
- اختبارات
- نص
- من
- أن
- •
- المستقبل
- من مشاركة
- منهم
- then
- نظري
- وبالتالي
- وبالتالي
- تشبه
- هم
- هؤلاء
- ثلاثة
- عبر
- طوال
- الوقت
- إلى
- سويا
- أداة
- أدوات
- مسار
- قطار
- متدرب
- قادة الإيمان
- القطارات
- تحول
- انتقال
- الانتقال
- خدمات ترجمة
- جديد الموضة
- يثير
- صحيح
- جدير بالثقة
- اثنان
- أنواع
- نموذجي
- في النهاية
- غير مصرح
- فهم
- فهم
- غير مسبوق
- المقبلة
- تستخدم
- حالة الاستخدام
- مستعمل
- مستخدم
- المستخدمين
- يستخدم
- استخدام
- عادة
- الاستفادة من
- التحقق من صحة
- القيمة
- مختلف
- الإصدار
- بواسطة
- حيوي
- نقاط الضعف
- تريد
- دافئ
- we
- الويب
- خدمات ويب
- حسن
- كان
- ابحث عن
- متى
- التي
- في حين
- من الذى
- واسع
- مدى واسع
- ويكيبيديا
- سوف
- مع
- في غضون
- بدون
- للعمل
- سير العمل
- عامل
- العالم
- يامل
- سنوات
- التوزيعات للسهم الواحد
- لصحتك!
- حل متجر العقارات الشامل الخاص بك في جورجيا
- زفيرنت